嵌入式GPU 平臺下雷達調制信號分析識別
2022-03-31 12:02:56楊博溢汪向陽
艦船電子對抗 2022年1期
楊博溢 汪向陽 陳 濤 李 君
(1.哈爾濱工程大學,黑龍江 哈爾濱 150001;2.解放軍63861部隊,吉林 白城 137001)
0 引言
雷達信號識別往往運用在一些特殊的環境中,比如航天、星載、彈載等,而這些環境對嵌入式應用常常具有一定的要求。因此,在嵌入式平臺上開展對雷達脈內識別信號進行智能識別的研究具有一定的應用前景和實際意義。隨著NVIDIA 公司在AI領域的研究發展,其推出的NVIDIA JESTON AGX Xavier具有體積小、功耗低、運算能力強的特點,為本文的算法移植提供了良好的平臺。因此,本文基于嵌入式GPU 平臺對雷達信號識別系統進行了設計研究。袁智、吳詠輝等利用JESTON 系列設備進行了一系列的應用實現,為本文雷達系統的設計展現了可行性。
隨著雷達技術的迅猛發展,低截獲概率(LPI)雷達信號的出現使得對雷達信號的識別分析不得不開始尋找新的研究方法。在一些傳統的調制識別算法中,往往是通過先估計特定參量再判斷雷達信號的調制方式。因此,在傳輸信道環境良好的情況下,傳統的識別算法可以做到較為精確的識別;但在惡劣環境下,由于特定參數的估計值誤差不可忽略,最終的識別結果往往不盡人意。于是,如何在較低信噪比下仍保持較高識別率、如何在非合作模式下提高信號識別準確度是目前調制方式識別算法中的一個難點。近些年提出的深度學習在圖像識別分類問題中會自動提取圖像中的有用特征信息,不需要人工設置特征量,對噪聲、頻偏等干擾因素起到了一定的抑制作用。因此,將深度學習運用在雷達信號識別領域,具有實際的意義。
隨著深度學習的發展,不斷有研究人員在各領域下利用深度學習對圖像進行分類識別,從而佐證了利用深度學習對二維時頻圖進行分類的可行性。蔣兵等在廣義回歸神經網絡(GRNN)、概率神經網絡(PNN)與瞬時頻率特征提取的基礎上提出了一種新的雷達信號識別算法,使得在雷達調制信號識別中得到了較好的識別率。還有一些研究人員利用深度學習網絡對雷達信號進行識別算法的研究,表現出利用深度學習進行識別具有抗噪性能優異、識別效果好等特點。隨著深度學習算法在雷達信號領域的不斷深入,人們發現,當傳統的卷積神經網絡算法在嵌入式移動端上進行部署時,由于嵌入式設備算力有限等原因,傳統的卷積神經網絡算法會耗費很大的時間精力;因此,不斷有人提出了輕量級的卷積神經網絡。本文正式將輕量級網絡運用在雷達信號識別領域,并在嵌入式移動端上進行實現。
1 算法介紹
1.1 算法流程圖
根據可視化界面的分布情況可以得出其整體的操作流程,如圖1所示。

圖1 算法流程圖
1.2 MobileNet V3網絡
MobileNet V3發表于2019年,該V3版本結合了V1的深度可分離卷積、V2的Inverted Residuals和Linear Bottleneck、壓縮機激勵(SE)模塊,利用神經結構搜索(NAS)來搜索網絡的配置和參數。其最大的優點在于使用了深度可分離卷積的操作代替了傳統的卷積操作,如圖2所示。
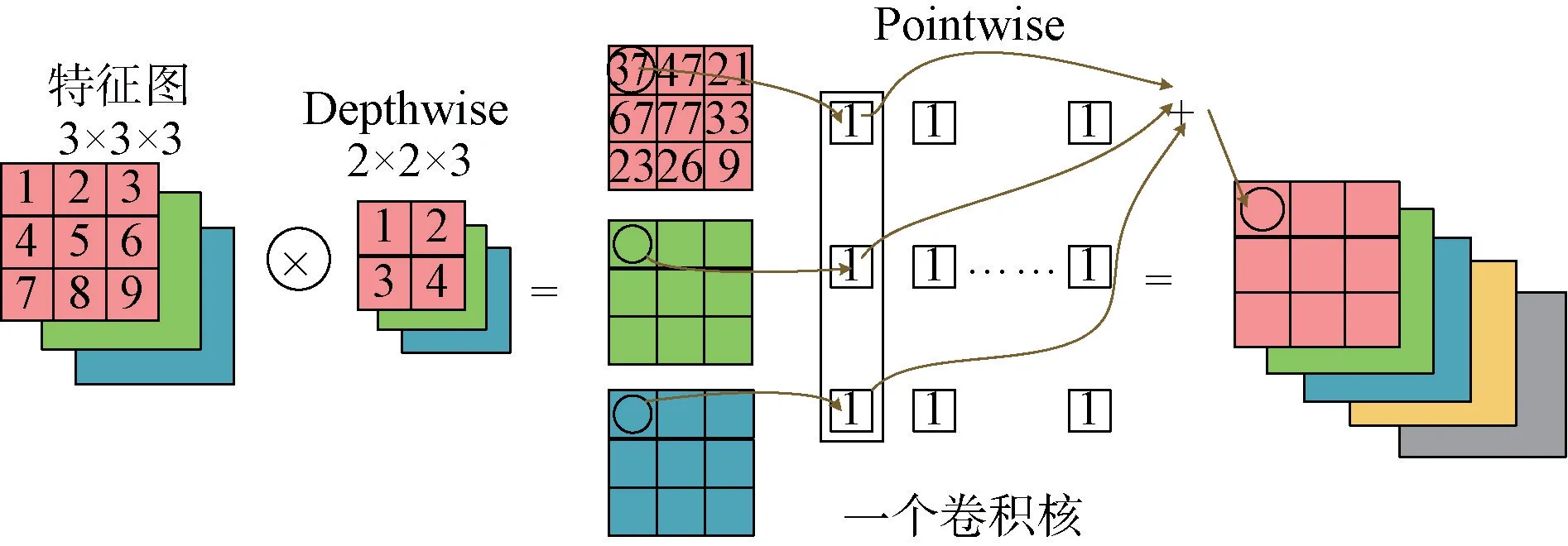
圖2 深度可分離卷積
對于傳統卷積核計算,設D 為輸入特征數據,D 為傳統卷積核的大小,、對應輸入輸出數據維數,則計算量可表示為D ×D ×M ×D ×D 。而深度可分離卷積將傳統卷積的2步進行分離,分別是Depthwise和Pointwise。如圖2,首先按照通道進行計算,按位相乘,此時通道數不改變;然后得到第1步的結果,于是深度可分離卷積操作的計算量為D ×D ×M×D ×D +11×M×N×D ×D 。

其次,輕量化網絡充分考慮其部署在移動端的情況下改善了激活函數,使其計算精度和計算效率得到了一定的提升。其數學表達式為:

式中:和為激活函數。
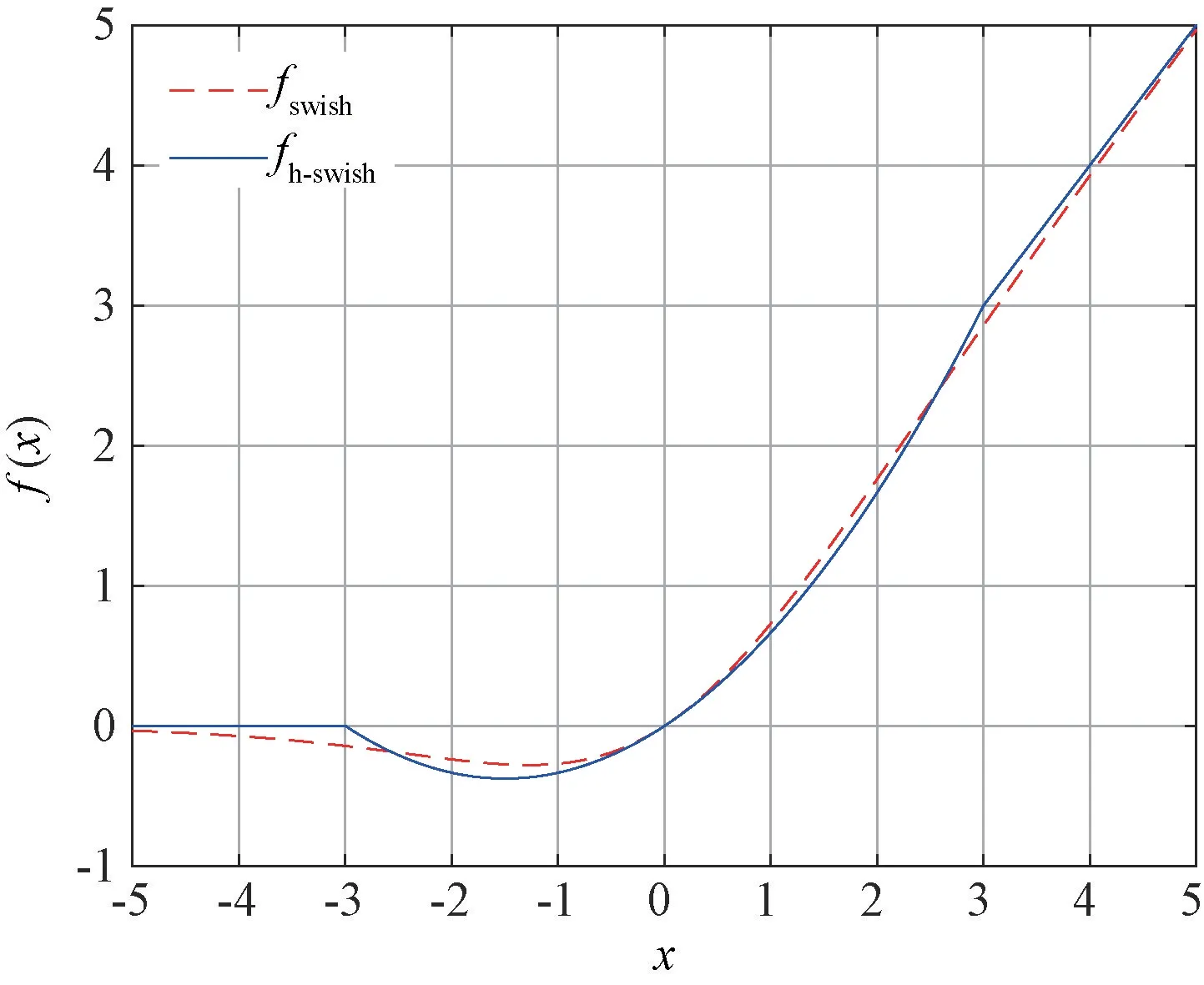
圖3 fh-swish 和fswish 激活函數的曲線圖
的非線性具有很多的優勢,其改進的結果雖然使模型的耗時增加,但是由于其非線性改變帶來的網絡效應極大地改善了精度和延時,因此其所帶來的額外延時增加可以接受,且同時可以通過V3網絡結構中某些卷積層的移除而消除其延時增長影響,其次目前多數硬件平臺對激活函數都有較好的支持性。
2 算法移植
算法移植主要是將PC端初步調試的算法在圖形處理器(GPU)平臺上實現,分為2步:第1步為平臺環境搭建;第2步為算法移植調試。
2.1 平臺環境搭建
2.1.1 Xavier簡介
該平臺為Nvidia Jeston Xavier,各參數如表1所示。

表1 Jeston AGX Xavier參數
2.1.2 對Xavier進行初始化
首先需要對Xavier設備進行初始化操作,目的是使Xavier設備具有MobileNet網絡需要的環境。在使用jetpack4.2 對其進行刷機時,設備安裝CUDA,利用CUDA 結合Xavier的DL Accelerator硬件結構對深度學習進行加速操作。Mobile Net網絡結構需要pytorch環境,在jetpack 刷機成功后,下載編譯好的torch-1.5.0-aarch64 進行環境的配置。
2.2 模型參數設計
在輕量級網絡MobileNet識別算法中,根據不同的訓練參數網絡訓練效率和識別效果表現情況選出一種較好的實驗參數,如表2所示。

表2 算法模型參數
其中學習率不宜太大,太大會導致網絡不能快速收斂,以至于訓練效率低,太小又會使得學習的過程太慢。輟學率的選擇是為了防止網絡出現過擬合現象。每次迭代的學習間隔量可根據實際要求更改,間隔量越小表示每次迭代學習到的特征量越多,但同時所耗費的時間也更多,因此需要做出權衡。
3 實驗仿真
3.1 基于MobileNet V3的信號識別
實驗數據集有Barker、Costas、Frank、線性調頻(LFM)、非線性調頻(NLFM)、P1、P2 共7 種類型的信號構成,其中每種信噪比下每種信號類型生成1 000張不同的時頻圖作為該類信號的樣本。對于每種信號取80%的樣本組成訓練集,剩下的20%組成驗證集。圖4所示為信噪比是-4 d B 時的各信號樣本。

圖4 -4 dB下各信號時頻圖
在上述數據集的基礎上,利用MobileNet V3網絡對各信噪比下的信號進行識別,識別效果見表3。

表3 6種信噪比下識別情況
其各信號的整體識別率隨著信噪比下降的折線圖如圖5所示。

圖5 各信號識別情況
從各個信噪比下驗證集的識別情況可以看出,當信噪比下降到-8 d B時,其整體的識別率仍可以達到93.43%,從表3可以看出各類信號單獨的識別率。
3.2 Res Net與MobileNet對比分析
由于輕量級網絡從卷積層計算的角度有別于傳統卷積網絡的計算,其利用可分離卷積的思想為整個訓練的過程節省了不少的計算量。因此,進行了兩類不同的卷積神經網絡的對比試驗分析。
一般的卷積神經網絡訓練要花費較長的時間,而在嵌入式設備上對其進行開發使用時,又經常對深度學習訓練的時間有一定的需求。因此,從訓練效率角度去對比這2個網絡,從對比試驗參數中選用相同的學習率與優化器,在信噪比為0 dB時對其進行訓練,以觀測信號識別率在達到95%以上時最小迭代數的情況和最小訓練時間。
對比試驗的詳細超參數見表4,其得到的數據結果如圖6,每次迭代訓練的時間見表5。

表4 超參設置

圖6 兩類網絡訓練情況

表5 一個epoch訓練時間
通過分析實驗數據可以得出,2個不同的卷積網絡隨著訓練迭代次數的增加,其識別率都可以達到很高,但是可以發現在要求達到相同識別率下MobileNet網絡更容易被訓練。從表5 中可以看出,2類網絡的訓練時間也是不一樣的,Res Net網絡每次迭代的時間在480 s左右,而MobileNet網絡一次迭代只需要60 s即可完成。且從訓練曲線中可以看出,輕量級網絡的穩定性更強,即出現紋波的幅度和頻率更小。從模型保存數據量角度進行比較時發現,ResNet網絡一個模型所占用的大小約為350 MB左右,而MobileNet則僅需要35 MB 的空間即可,僅從空間占用的角度去考慮可以得出輕量級網絡Mobile Net更適合在嵌入式設備中使用。
3.3 雷達調制信號識別分析可視化界面開發
可視化界面是基于Python語言,利用QT 公司開發的Py Qt5進行設計。由于是基于Python這種腳本語言編程,因此語句更加容易理解,并且也不用再安裝軟件,只需在編譯環境內下載對應庫即可。
3.4 雷達調制信號識別分析結果圖
對設計好的雷達系統進行測試,其實際結果如圖7所示。

圖7 雷達系統實物測試圖
4 結束語
本文在嵌入式GPU 平臺下完成了雷達信號分析系統的設計。由測試結果可以看出,在嵌入式平臺下該算法可以產生7種不同的調制信號,并對其進行時頻分析,從而得到二維時頻圖像。對調制信號的載頻、信噪比、調頻斜率等具體參數進行隨機操作從而得到豐富的數據集和測試集,將得到的數據集進行深度學習,而后利用訓練模型識別測試集,可以得到在=-8 d B 下,其整體的識別率為93.43%;在=0 dB 下,識別率為99.86%。結果表明,當信道中信噪比惡劣到-8 d B 時,識別結果仍然可以達到93.43%以上,且該識別算法對其他信號同樣適用,只需要產生其他信號的數據集訓練識別即可。對比NVIDIA Jetson Xavier和PC端,從小型化和功耗性能方面考慮其優勢遠大于PC端,且在實際應用過程中,可以把訓練過程放在性能更強的PC端進行,而利用Xavier進行信號識別。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環保(2016年3期)2017-01-20 08:15:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
