基于Swin-Unet的云分割算法的研究
2022-04-01 03:17:16張文康
儀器儀表用戶 2022年4期
關鍵詞:模型
張文康
(北方工業大學 信息學院,北京 100144)
0 引言
近些年來,在眾多對地觀測手段中,衛星遙感圖像作為一種更加高效的技術受到了包括國防與民生建設、自然災害預測等多行業的青睞。鑒于其擁有其巨大的市場和應用,形成了遙感圖像處理這樣的學術研究領域,取得了長足的發展。云作為一種典型的氣象和氣候要素,廣泛的存在于光學衛星遙感圖像當中(例如:我國四川盆地常年云覆蓋率超過60%)。此外,云的形狀,亮度和紋理在一定程度上是隨機的,并時常隨著時間,高度、厚度、太陽仰角等因素而變化。這將導致云的局部形狀可能與某些地物有較高的相似度,同時,卷云本身亮度較低,存在大量的紋理。相比于厚云,卷云特征在某種程度上更加接近于地物,云的這些特性大大影響了圖像的完整性和價值,增加了提取地面信息的難度。此外,這種低價值的圖片還極大的占用了衛星下行鏈路的帶寬以及儲存空間,形成了資源的浪費。因此,準確識別衛星圖像中的云區域是一個關鍵的課題。
在早期,機器學習是衛星應用的主要方法,其包括了單波段和多光譜數據,后者由于包含了更多的地物反射信息,具有更高的精準度。但在某些特定情況下,如夜晚、下墊面為沙漠、海岸線、河、冰川和內陸湖時,由于云與下墊面反射率類似,系統很難正確區分。因此,這些干擾的存在會導致錯誤的檢測與識別,進而影響后續的分析與處理結果。與此同時,多變的云圖特性會使閾值法的效果受到很多方面因素的干擾。例如:云的種類、高度、厚度和太陽高度角等。傳統的遙感圖像分割技術在分割過程中,容易忽略遙感圖像中同一個地物的類內差異或紋理相似度較高的不同地物之間的差異。這是因為其主要技術為針對灰度或紋理差異較大的不同地物。
深度學習是機器學習領域中一個新的研究方向,其在視覺處理、數據挖掘、自然語言處理等領域都取得了很好的成果。目標識別作為其中的一種,已經在人臉識別、車輛檢測、衛星圖像分析當中取得了廣泛的應用。在遙感領域,基于深度學習來進行云分割的方法也受到了研究人員的青睞。在之前的研究中,卷積神經網絡(CNN)在目標識別網絡中取得了里程碑式的進展,在多種圖像處理任務中取得了優秀的成績,但是,由于卷積操作的局限性所限,其無法學習全局,完成遠端的信息交互。Swin-Unet是一種基于圖像分割經典模型U-Net改進的純Transformer模型,相比于其他圖像分割算法,其在U型架構中,將圖像塊通過跳躍連接送到基于Transformer的U形編碼器-譯碼器架構中,更好的進行了局部以及全局的語義特征學習,取得了更優的性能。后續,Swin-Unet也被應用于包括車輛檢測在內的其他圖像分割領域,提升分割的準確率。因此在本文中,也將借鑒深度學習領域的Swin-Unet分割模型完成遙感圖像中的云區域識別。
1 網絡結構
目前的圖像分割主要基于全卷積神經網絡(FCNN),其中以U型網絡結構最為常用。傳統的U型網絡,如U-Net,是一個對稱的編碼-解碼網絡結構,并且包含跨層連接(skip connection)。編碼器通過一系列卷積和下采樣操作提取不同感受視野下的語義特征;解碼器通過上采樣操作將提取到的特征圖恢復到原始分辨率,進行像素級別的密集預測;跨層連接則負責將同層的編碼器提取的信息與解碼器進行融合,從而減少因為下采樣操作導致的空間信息丟失問題。通過精巧的結構設計,U-Net已經在諸多圖像分割任務中取得優異的效果,但其仍然局限于CNN模型,無法捕捉全局和長程的語義信息。
受Transformer在NLP領域中的啟發,目前研究人員正將Transformer遷移到計算機視覺領域。本文中使用的Swin-Unet即是一種純Transformer架構。與CNN相比,其計算兩個位置之間的關聯所需的操作次數不隨距離增長,這意味著其可以更好地捕捉到全局的語義信息。此外,Transformer的自注意力(Selfattention)機制可以產生更具可解釋性的模型,各個注意頭(Attention head)可以學會執行不同的任務。
1.1 面向云分割的Swin-Unet網絡
整個Swin-Unet網絡框架可以分為以下3個部分:編碼器(左側部分),解碼器(右側部分)以及skip connection(中間跨線部分),如圖1所示。其中,Swin-Unet網絡的基礎模塊Swin Transformer在2.2節進行詳細介紹,而本節著重從框架層面介紹各個部分的結構和功能。

圖1 Swin-Unet網絡架構Fig.1 Swin-Unet Network architecture
1)編碼器
該模塊首先將輸入的圖片切分成大小互不重疊的分塊,隨后對輸入分塊進行線性映射。隨后映射過的token被送入Swin Transformer模塊和patch merge層用來生成不同尺度的特征表述;Swin Transformer模塊負責學習特征,patch merge層負責下采樣操作。
2)解碼器
解碼器由多個Swin Transformer模塊和patch expanding層組成,跨線依舊負責特征融合,彌補原始信息的丟失,patch expanding層則進行的是上采樣操作,將該層feature map擴充至2x分辨率;最后一個patch expanding層會擴充至4x分辨率;然后通過線性層進行像素級別的預測。
3)跨線連接
和傳統的U-Net一樣,跨線會以級聯的方式將特征圖輸送到解碼器當中,以此來融合多尺度特征。
1.2 Swin Transformer基礎模塊
Swin Transformer是整個網絡最基礎的模塊,和傳統的MSA結構并不一樣,Swin Transformer主要是基于滑動窗口(shifted window)構建的,圖2展示了兩個串聯的Swin Transformer模塊。

圖2 Swin Transformer模塊Fig.2 Swin Transformer module
每個Swin Transformer由層歸一化(Layer Norm,LN)層、多頭自注意力模塊、殘差連接和2個包含有激活函數GELU的多層感知機組成。
在2個連續的Transformer模塊中分別采用了基于窗口的多頭自注意力模塊(Window-based Multihead Self-attention)和基于移動窗口的多頭自注意力模塊(Shifted Window-based Multi-head Self attention),前者用w(g)表示,后者用s(g)表示。因此,基于這種窗口劃分機制的連續Swin Transformer Block可表示為:


其中,LN(g)對應層歸一化網絡層;MLP(g)表示包含有激活函數GELU的多層感知機;和Z l分別表示(SWMSA)模塊和第l塊的MLP模塊的輸出。
2 實驗與評價
2.1 數據集
數據集是訓練神經網絡的關鍵要素,數據集的選擇決定了神經網絡訓練效果的好壞。因此,選擇一個好的數據集格外重要。本文采用了38-Cloud數據集進行訓練。該數據集包含38幅Landsat 8場景圖像及其手動提取的像素級地物真實標簽,用于云檢測。這些場景的整個圖像被裁剪成384×384個斑塊,以適合于基于深度學習的語義分割算法。數據集被劃分為8400個斑塊進行訓練,9201個補丁進行測試。每幅圖像有4個相應的波段,分別是紅色(波段4)、綠色(波段3)、藍色(波段2)和近紅外(波段5)。

圖3 數據集圖片示例Fig.3 Example of a dataset image
在本文中,數據集被劃分為訓練集、驗證集和測試集。將數據集8400張圖片,5000張劃分為訓練集,1000張劃分為驗證集,剩余的2400張則為測試集。
2.2 評估標準
1)Dice系數
Dice系數(Dice Coefficient)本質上是為了衡量兩個樣本的重疊部分。此度量范圍為0~1,其中Dice系數為1時表示兩樣本完全重合。
Dice系數的計算公式如下:

2)準確率
在本文研究的云區域分割任務中,預測過程將圖片信息分為兩類:云像素為正類,地物像素為負類。則準確率的計算公式如下:
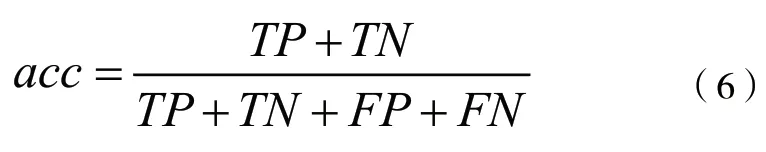
其中,TP代表正確識別云像素的個數;TN代表正確識別地物像素的個數;分子為兩者之和,代表所有正確識別的像素個數;FP代表錯誤識別云像素的個數;FN代表錯誤識別的物像素的個數;分母為所有像素個數。
2.3 與其他模型進行對比
本文測試了在不同學習率下的模型表現。此外,也將傳統的U-Net網絡作為對照組,進行對比。
1)Swin-Unet最優模型選擇
本文分別對Swin-Unet選取了不同的學習率進行了訓練,并通過驗證集的最大準確率選擇最佳模型,在不同學習率下Swin-Unet模型的表現結果見表1。根據實驗結果,選取了學習率為0.0001時的模型為最優模型,其驗證集和測試集在此時都達到了最優值(測試集準確率為0.9830,測試集Dice系數為0.9745)。

表1 不同學習率下,Swin-Unet最優模型訓練集的Loss、驗證集準確率和Dice系數、測試集準確率和Dice系數對比Table 1 Comparison of Loss, validation set accuracy and Dice coefficient, test set accuracy and Dice coefficient of Swin-Unet optimal model training set under different learning rates
根據實驗結果,選取了學習率為0.0001時的模型為最優模型,其驗證集和測試集在此時都達到了最優值(測試集準確率為0.9830,測試集Dice系數為0.9745)。
2)U-Net網絡最優模型選擇
將傳統的U-Net網絡進行了訓練,在U-Net網絡中,使用交叉熵函數(Cross Entropy Loss)作為網絡的損失函數。交叉熵作為損失函數的好處是使用sigmoid函數在梯度下降時能避免均方誤差損失函數學習速率降低的問題,因為學習速率可以被輸出的誤差所控制。其公式表示如下:

其中,P(x)表示語義分割的標注;q(x)為預測值。
通過對參數的調整,得出傳統U-Net模型在訓練達到最優時測試集準確率達到0.9769,測試集Dice系數為0.9184。
3)與主流模型對比
在訓練過程中發現,傳統U-Net模型在訓練達到第47代時模型達到最優,而Swin-Unet在訓練到第45代時性能最優,這說明了Swin-Unet在云分割領域比傳統的以CNN為架構的U-Net模型收斂更快。
此外,對比不同模型下的最佳表現,傳統U-Net模型在訓練達到最優時測試集準確率達到0.9769,測試集Dice系數為0.9184。而Swin-Unet模型的測試集準確率為0.9830,測試集Dice系數為0.9745。這表明了Swin-Unet在云分割領域擁有更好的識別效果。
2.4 云分割效果
本小節示意圖中均包含3幅小圖像,其中第1幅為輸入樣本,第2幅為真實標記云分布,第3幅圖為經過系統分割后預測的云分布。第2、第3幅圖可以進行直觀對比觀察本文分割模型效果。
1)厚云
如圖4所示,若需分割的云為厚云時,模型可對云進行準確率較高的分割,但在云的邊緣范圍,無法實現較為精準的分割效果,存在一定的誤差。

圖4 厚云輸入下的真實標記和預測結果Fig.4 Ground-truth labeling and prediction results under thick cloud input
2)薄云
如圖5所示,若需分割的云為薄云時,模型可對云進行準確率較高的分割,大致范圍與精標準結果吻合,仍在云和地面交接處存在一定的誤差。

圖5 薄云輸入下的真實標記和預測結果Fig.5 Ground-truth labeling and prediction results under thin cloud input
3)朵云
如圖6所示,若需分割的云為朵云時,模型可對云進行準確率較高的分割,如上述二者相比效果更好。

圖6 朵云輸入下的真實標記和預測結果Fig.6 Ground-truth labeling and prediction results under Duoyun input
4)雪山墊面
如圖7所示,當下墊面為雪山時,地表信息中的雪基本不會對云的分割效果產生極大干擾,云的邊緣無法精準分割,存在小范圍誤差。
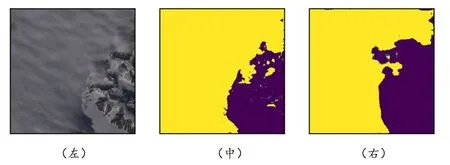
圖7 雪山下墊面輸入下的真實標記和預測結果Fig.7 The real label and prediction results under the input of the underlying surface of the snow mountain
5)海洋墊面
如圖8所示,當下墊面為海洋時,雖然其中的云亮度較低,但可以看出分割效果較好,只存在小范圍的細節無法精準分割,總體分割效果優秀。

圖8 海洋墊面輸入下的真實標記和預測結果Fig. 8 Ground-truth labeling and prediction results under the input of ocean surface
6)平原墊面
當下墊面為平原時,由圖9可以看出無法做出很精細的分割效果,與金標準結果相比,大致輪廓吻合,云的邊緣與細節存在一定程度的誤差。

圖9 平原墊面輸入下的真實標記和預測結果Fig.9 Ground-truth labeling and prediction results under plain mat input
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
