基于自監督深度學習的心肌磁共振T1量化成像運動校正算法研究
2022-04-01 07:11:28吳春燕李雨澤丁海艷陳慧軍
中國醫療設備 2022年3期
吳春燕,李雨澤,丁海艷,陳慧軍
清華大學 醫學院 生物醫學工程系,北京 100084
引言
心臟磁共振T1量化成像可以指示心肌組織的一系列病理改變,特別是心臟的炎癥、急(慢)性心肌瘢痕以及纖維化引起的細胞外間質重組[1-2]。臨床上,改良Look-Locker 反轉恢復(Modified Look-Locker Inversion Recovery,MOLLI)序列是標準的心肌T1參數量化序列,但是掃描過程中心臟及呼吸運動將導致圖像質量降低,需對采集的不同幀圖像進行配準以提高圖像質量及T1量化精度。
國際上已有許多研究者對心肌的T1量化提出了運動校正方法,Roujol等[3]提出一個基于光流法的局部非剛性配準架構,同時估計運動場和信號強度變化;El-Rewaidy等[4]利用一種活動形狀模型分割得到的心肌輪廓實現配準,提高了各心肌節段T1參數量化的準確度和精度;Tilborghs等[5]提出一種結合數據驅動初始化和基于模型的精細改良的配準方法,實現了更加魯棒的T1參數量化。但是,這些傳統配準方法需要多次迭代優化,耗時長,降低效率[6-7]。Fahmy等[8]提出一種基于深度學習的自動心肌T1參數量化方法,然而,這一深度學習算法為監督式的,需要人工標注數據,且在自動分割效果不佳時需要額外的后處理操作。
為了克服前述算法的缺點,本研究提出一種基于深度學習的心肌T1參數量化成像運動校正算法,無需傳統方法的多次迭代優化,可大幅度降低運算時間;同時,采用自監督的訓練方法,無需人工標注的金標準圖像,大大降低了醫生的工作量,為大規模臨床應用提供了可能。
1 材料與方法
1.1 數據集
實驗數據來自47例健康志愿者(30例男性,17例女性,年齡30~64歲),納入標準:① 既往無心源性或系統性疾病;② 既往CMR掃描無心臟形態和功能異常;③ 無磁共振檢查禁忌證。所有受試者均簽署了知情同意書。
實驗使用3.0 T磁共振掃描儀(Achieva TX,Philips,荷蘭),32通道的心臟線圈,所有受試者在屏氣情況下進行成像。采用MOLLI序列進行掃描,每名志愿者采集1~3層圖像,掃描方位為左心室短軸位,每層圖像包含8幀T1加權圖像。序列的具體掃描參數如下:重復時間2.59 ms;回波時間1.31 ms;觸發延遲(Trigger Delay,TD)時間為舒張末期;完成一次掃描的時間為8~34 s;翻轉角35°;掃描視野30 cm×15 cm;分辨率1.25 mm×1.25 mm;層厚8 mm。
1.2 基于深度學習的心肌T1參數量化成像運動校正算法
本方法的總體流程主要包括兩個部分:① 利用基于深度學習的自監督配準網絡將MOLLI圖像中除固定圖像以外的所有圖像配準到固定圖像上;② 對配準后的T1加權圖像進行參數擬合得到T1量化圖像。
1.2.1 基于自監督深度學習的非剛性配準算法
配準流程圖如圖1所示。圖像配準通常是將一幅移動(或待配準)圖像配準到固定(或參考)圖像上。令m、f分別表示定義在2D空間域Ω∩R2上的移動、固定圖像,利用卷積神經網絡(Convolutional Neural Network,CNN)對配準運動場u建模,即gθ(f,m)=u,其中g為神經網絡,θ是可學習參數。網絡可學習每一組輸入對(m,f)之間的配準變換;接著,運動場利用空間變換函數(o)作用到移動圖像m上,可得到運動校正后的圖像m'。具體地,對于成像空間中每個像素p,經運動場u的空間交換(°)得到的m′(p)是其周圍8個像素點的線性插值,見式(1)。
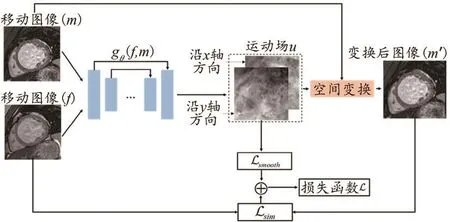
圖1 基于自監督深度學習的非剛性配準算法
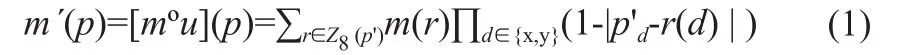
其中,Ζ8(p')表示p'的8像素鄰域,p'=p+u(p)。
本方法中的自監督體現在,由于固定圖像來源于直接采集到的圖像,無需人為標注或額外的處理,經過運動場作用后的圖像m'與固定圖像進行損失函數計算并反向傳播優化網絡,達到自監督學習的目的。
1.2.2 神經網絡結構
圖2為本方法使用的神經網絡的結構。該網絡采用Unet結構[9],主要由編碼器和解碼器兩個部分組成:編碼器利用卷積層增加CNN的感受野,降低CNN的空間尺寸,同時學習不同尺度下的圖像信息;解碼器采用上采樣恢復圖像尺寸,并利用跳躍連接融合編碼器和解碼器部分的多尺度信息。編碼和解碼階段都采用尺寸為3×3、步長為2的卷積和Leaky ReLU激活函數(小于0部分的斜率為0.2)。
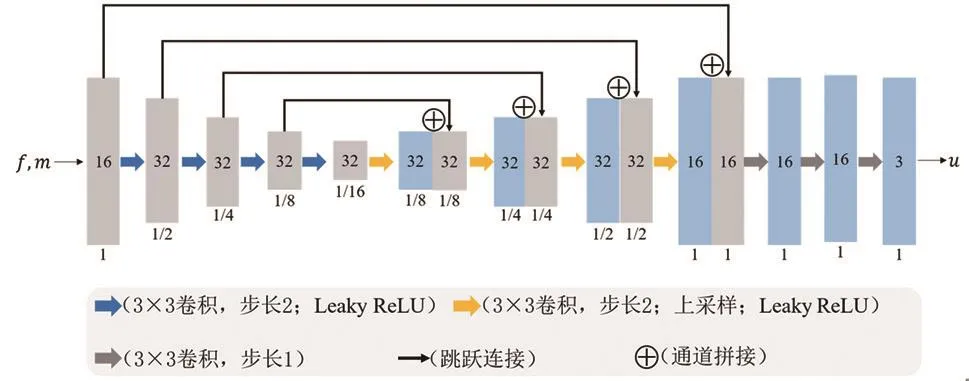
圖2 運動場估計的網絡結構圖
1.2.3 損失函數
本方法的損失函數由兩部分構成,一部分為自監督損失函數,即圖1中的sim,sim衡量的是校正后圖像與固定圖像的相似度。考慮到T1加權圖像不同幀之間對比度相差大,直接采用基于信號強度的相似性測度效果不佳[10],im選擇對于對比度變化不敏感的互相關(Cross-Correlation,CC)和互信息(Mutual Information,MI)作為相似性測度,見式(2)~(3)。
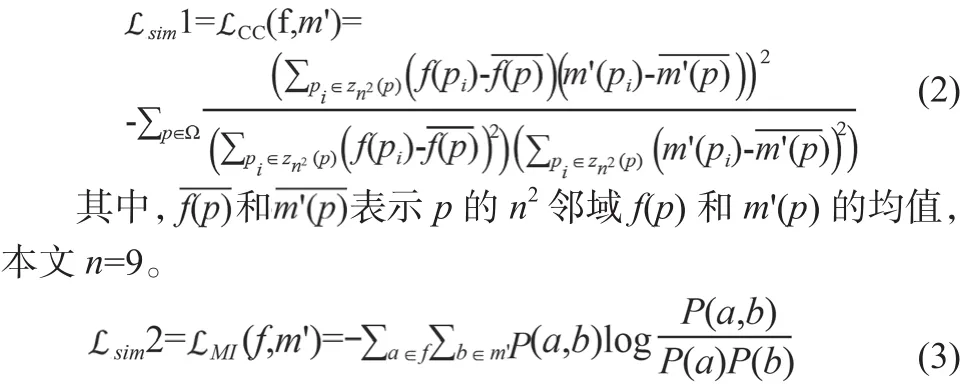
P(a)是f中信號強度等于a的像素比例,P(b)是m'中信號強度等于b的像素比例,P(a,b)是f和m'信號強度的聯合分布。為了使損失函數可微分以便于神經網絡的反向傳播,使用Parzen窗法近似公式中的概率分布[11],見式(4)~(6)。
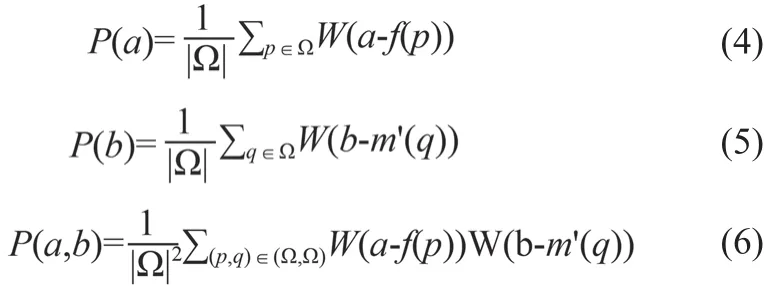
其中,窗函數W選擇高斯窗。
另外,為了對比采用基于信號強度的相似性測度的運動校正效果,實驗也驗證了sim取均方誤差(Mean Square Error,MSE)的情況,見式(7)。
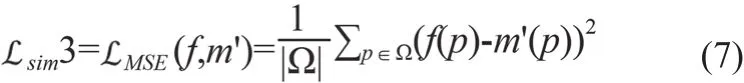
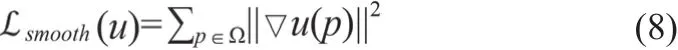
綜上,網絡的總損失函數如式(9)所示。
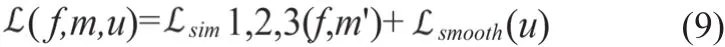
本研究測試不同的相似性測度(MSE、CC、MI)以尋找最優的損失函數。
1.2.4 訓練與測試
網絡使用TensorFlow 2.1.0框架實現,優化器為Adam,學習率設置為1e-4,beta1=0.9,beta2=0.999;采用的計算服務器配置為I7-6950K CPU, NVIDIA TITAN Xp 12 GB GPU及32 GB內存。在本研究中,固定圖像為MOLLI序列采集到的T1加權圖像中的第8幀,因為此時心肌-血池對比度較高,移動圖像則為其他幀的圖像。47例受試者數據中,36例(2035張圖像)用于網絡訓練,11例(650張圖像)用于測試。
此外,本文對比了一種傳統配準方法:基于互相關的B樣條自由形變模型配準算法[12],由Matlab醫學圖像配準工具箱(Medical Image Registration Toolbox,MIRT)實現。
1.3 T1參數擬合
圖像經過配準后,還需經過T1擬合才可得到T1量化圖像。如圖3所示,本實驗采用的MOLLI序列由兩次ECG觸發的Look-Locker(LL)實驗(LL1、LL2)組成,分別由三、五次單次激發讀出。每個LL實驗中,反轉脈沖和TD之后,在遞增的反轉恢復時間(Inversion Time,TI)心臟舒張末期采集信號,LL1和LL2之間至少間隔4 s保證完全的信號恢復。
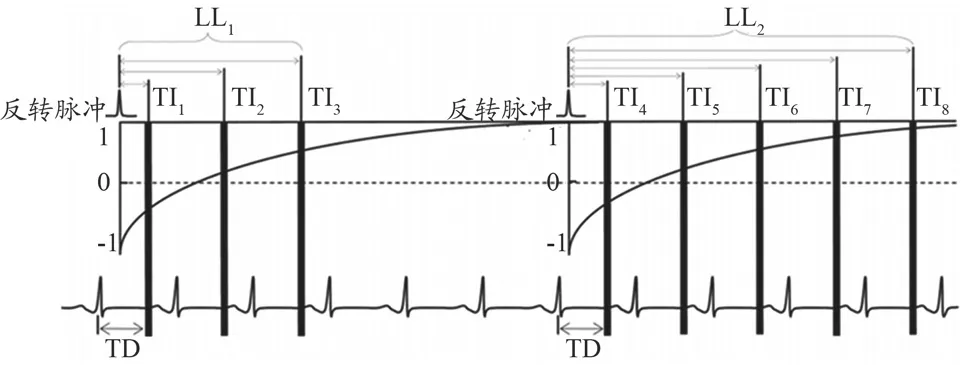
圖3 MOLLI序列信號采集示意圖
本文采用三參數模型進行T1擬合[13],見式(10)。

對于MOLLI序列,擬合得到的T1*經過如下的修正后得到T1:T1=T1*(-B/A-1)。本文采用葉猛[14]提出的結合RD(Reduced Dimension Nonlinear Least Square with Rolarity Restorations)算法和LM(Levenberg-Marquardt)算法的擬合流程,即對運動校正后的T1加權圖像加mask去除背景后,先進行RD擬合,再對擬合殘差過大的點用LM擬合。
1.4 評價指標及統計學分析
本文評價了T1加權圖像的配準效果及T1量化誤差。采用Dice相似系數(Dice Similarity Coefficient,DSC)和平均邊界誤差(Mean Boundary Error,MBE)作為量化評估配準誤差的指標。這兩個指標的獲得需要在原始加權圖像上手動勾畫出心肌內、外輪廓。指標具體計算可參考Tilborghs等[5]的方法。采用T1量化圖像的標準差(Standard Deviation,SD)[15]評估T1參數量化的準確度,可利用T1擬合殘差和測量噪聲的SD近似得到待估計參數的協方差矩陣,從而得到T1參數量化的SD。除了SD 量化圖,本文還計算了心肌部分的平均SD。
本文使用Matlab R2020a軟件進行統計學分析。DSC、MBE和心肌SD表示為±s;對不同方法測量得到的DSC、MBE和心肌SD進行Wilcoxon符號秩檢驗,P<0.05表示具有統計學意義。
2 結果
2.1 T1加權圖像配準結果
經過本文提出的深度學習算法(以CC和MI作為相似性測度)配準后,T1加權圖像的心肌部分得到了較好的運動校正。T1加權圖像配準效果如圖4所示。未配準時(圖4a、 e、 i中藍色箭頭所示),心肌位置相對于固定圖像發生了明顯的運動偏移,采用深度學習算法配準后,相似性測度選擇CC和MI時(圖4c、g、k和圖4d、h、l),心肌位置與固定圖像的基本一致。當心肌和血池對比度很低時(圖4i、k、l),算法也能較好地配準;相似性測度選擇MSE時,配準后T1加權圖像出現明顯的變形、失真(圖4b、f、j中紅色箭頭所示);當心肌和血池對比度很低時(圖4j中紅色箭頭所示),失真情況更加嚴重。

圖4 三例未配準和深度學習算法(MSE、CC、 MI)配準后的T1加權圖像
定量評估算法的配準準確度結果如表1所示。深度學習(CC)配準后DSC較原始未配準顯著提高(P<0.05),而采用傳統算法和深度學習(MI)配準后DSC指標沒有顯著改善(P=0.13和P=0.98)。傳統算法、深度學習算法(CC、MI)配準后MBE均顯著降低(P<0.05),且深度學習算法(CC、MI)的MBE顯著低于傳統算法(P<0.05)。而深度學習(MSE)配準后,DSC和MBE均比未配準時差。綜合DSC和MBE兩個指標,本文提出的深度學習算法(CC)配準準確度最高。
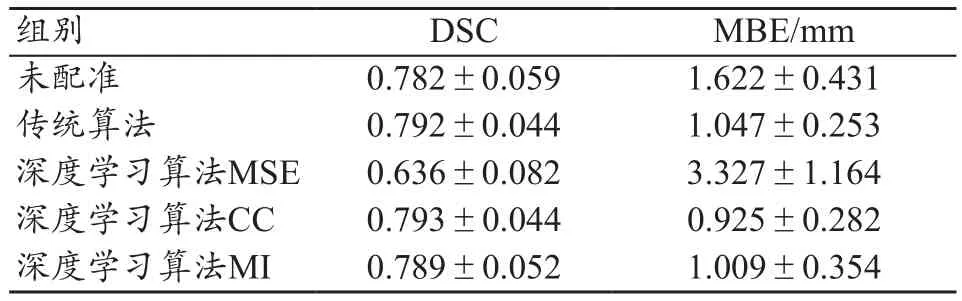
表1 未配準和傳統算法、深度學習算法(MSE、CC、MI)配準后的DSC和MBE
2.2 T1參數量化結果
圖5展示了不同配準算法運動校正結果的實例。從圖5中放大部分可以觀察到,原始T1參數量化圖心肌內膜附近(圖5中箭頭所示)存在運動偽影,降低了T1量化的準確性。傳統算法和深度學習算法(CC、MI)在不同程度上減少了運動偽影,其中深度學習(CC)的運動校正效果最佳。觀察對應的SD量化圖,除深度學習(MSE)之外,應用不同算法配準后,心肌部分的SD在整體上均減小了,深度學習(CC)的心肌SD整體上最小。
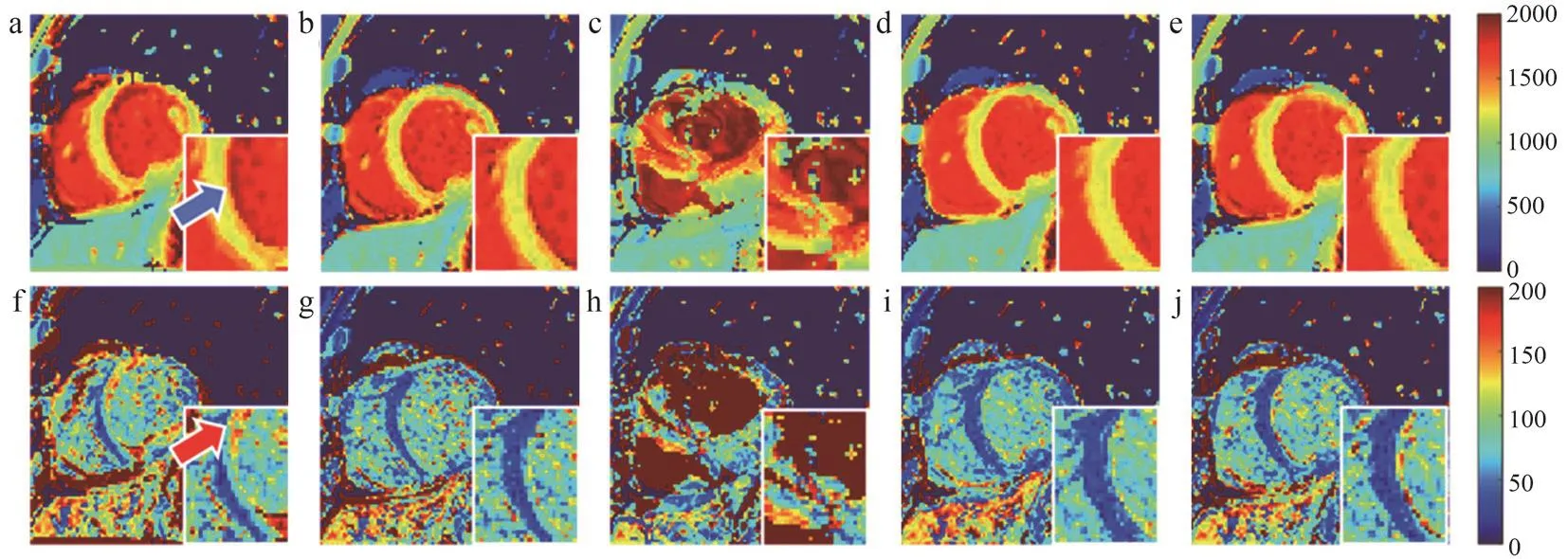
圖5 未配準和傳統算法、深度學習算法(MSE、CC、MI)配準后的T1參數量化圖和對應的SD量化圖
心肌部分的T1參數量化誤差如圖6所示。傳統算法、深度學習(CC)、深度學習(MI)配準后心肌部分的平均SD分別為(68.74±31.27)、(59.22±29.26)、(60.35±28.47)ms,均小于原始圖像心肌部分的平均SD(74.37±33.29) ms,差異有統計學意義(P<0.05),且深度學習(CC)和深度學習(MI)的平均SD明顯小于傳統算法(P<0.05),深度學習(CC)和深度學習(MI)的平均SD無統計學差異(P=0.056)。深度學習(MSE)配準后心肌部分的平均SD增加。
3 討論
本研究提出并驗證了一種基于自監督深度學習的心肌T1參數量化成像運動校正算法。該方法突出優點為基于深度學習的配準算法,提高效率及準確度;另一個優勢為采用了自監督學習框架,無需人工標注數據,大大節省了醫生的工作量,為心臟T1量化在臨床上大面積使用提供可能。

圖6 未配準圖像和傳統算法、深度學習算法(MSE、CC、MI)配準后心肌T1參數量化的平均SD的均值和標準差
首先,深度學習是本方法的優勢之一。深度學習適合處理大數據問題,在圖像識別、分類、分割、配準等計算機視覺任務上取得了許多重大研究成果。區別于傳統配準算法依賴于迭代優化,將深度學習應用于T1加權圖像配準,可達到一步配準,大幅提高計算效率。經過測算,本研究提出的方法完成一例配準平均用時0.4 s,比傳統算法快20倍。在配準精度及T1量化準確度方面,本研究在MOLLI序列采集到的47例受試者的左心室短軸切片數據上驗證了提出的運動校正算法,與傳統的基于互相關的B樣條自由形變模型配準算法相比,深度學習(CC)算法的MBE降低了12%,心肌T1量化SD降低了14%,心肌T1加權圖像的配準準確度和T1參數量化準確度都有所提高。另外一個值得討論的地方是,本研究測試了不同的損失函數,以尋求最適宜本問題的方案。本研究測試的三種損失函數中,CC和MI測度可以有效校正心肌T1參數量化圖中的運動偽影,CC測度的方法也得到了最佳的效果;然而,選擇MSE作為相似性測度時,本文提出的算法無法提供有效的運動校正,可能的原因為誤差無法解決信號強度和對比度變化的圖像配準問題,而CC和MI在衡量圖像相似程度時摒除了圖像對比度變化帶來的影響。
其次,采用自監督學習框架是本方法的另一個優勢。深度學習算法的一個挑戰是訓練真值的獲得,與Fahmy等[8]提出的方法需要大量預先勾畫的心肌輪廓作為訓練集不同,本文提出的方法是自監督的,網絡訓練過程無需真值,實際應用中也不需要預處理和用戶交互。該方法提出的自監督配準網絡引入了空間變換層,使得在訓練階段不需要運動變換真值就可進行損失函數的計算和網絡優化,大大降低了醫生的工作量,可以將本方法自由應用在任何相似的圖像處理應用當中,如造影劑增強的磁共振心臟、肝臟成像等需要運動配準的成像方式中。
在后續的研究中,為了提升算法在運動偏移幅度過大情況下的魯棒性和準確度,將考慮以下改進策略:① 將心肌結構相似性損失加入到目前的損失函數中[16];② 在目前非剛性配準網絡上增加一個仿射配準子網絡[17]以克服運動幅度過大的問題。
4 結論
本文提出了一種基于自監督深度學習的非剛性配準算法,為心肌T1參數量化成像提供了快速、有效的運動校正,增加了T1參數量化成像大規模臨床應用的可能性。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
兒童故事畫報(2019年5期)2019-05-26 14:26:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
新聞傳播(2015年10期)2015-07-18 11:05:40
