基于自編碼預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)分類(lèi)方法
2022-04-02 21:52:48陳蒙蒙
計(jì)算機(jī)應(yīng)用文摘 2022年5期
陳蒙蒙


關(guān)鍵詞 自編碼預(yù)訓(xùn)練 卷積神經(jīng)網(wǎng)絡(luò) 遷移學(xué)習(xí)
1基于自編碼預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)的分類(lèi)
1.1自編碼的原理
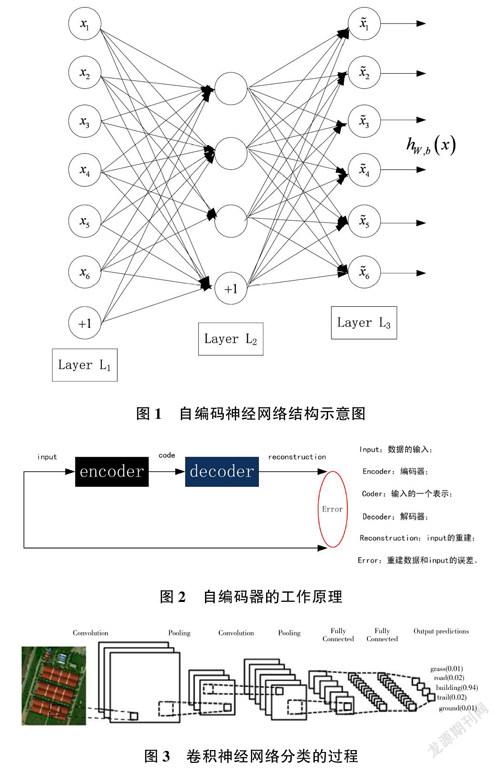
自編碼神經(jīng)網(wǎng)絡(luò)(見(jiàn)圖1)是一個(gè)輸入與輸出相等的人工神經(jīng)網(wǎng)絡(luò)。在該網(wǎng)絡(luò)中,左側(cè)節(jié)點(diǎn)是輸入層,右側(cè)神經(jīng)元是輸出層,中間是隱含層。輸出層的神經(jīng)元數(shù)量等于輸入層的神經(jīng)元數(shù)量。隱藏層的神經(jīng)元數(shù)量少于輸出層的神經(jīng)元數(shù)量。
自編碼器的工作原理如圖2 所示。其中,輸入層和隱含層之間的參數(shù)叫作“編碼器”(encoder),隱含層和輸出層之間的參數(shù)叫作“解碼器”(decoder)。通過(guò)對(duì)編碼和解碼的參數(shù)進(jìn)行調(diào)整和優(yōu)化,可以使模型最小化,從而學(xué)習(xí)重構(gòu)誤差[1] 。當(dāng)模型完成最小化后,得到輸入信息的一個(gè)特征表示,即特征編碼。
1.2基于自編碼初始參數(shù)獲取的卷積神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)通過(guò)標(biāo)記數(shù)據(jù)對(duì)一定結(jié)構(gòu)的網(wǎng)絡(luò)進(jìn)行訓(xùn)練。當(dāng)卷積神經(jīng)網(wǎng)絡(luò)對(duì)圖像進(jìn)行分類(lèi)時(shí),輸入圖像通過(guò)若干層的卷積和池化提取高層次特征,并利用softmax 進(jìn)行分類(lèi),從而判定輸入圖像的類(lèi)別。圖像的分類(lèi)過(guò)程如圖3 所示。
通過(guò)自編碼預(yù)訓(xùn)練可為卷積神經(jīng)網(wǎng)絡(luò)的卷積層提供初值,而不需要大量標(biāo)記樣本。在每層卷積中,將與本層卷積核大小相同的小圖像作為自編碼網(wǎng)絡(luò)的輸入xi ,輸出x^i 為輸入小圖像的特征,將此特征重新排列為ξ^,作為本層卷積核的初始系數(shù),得到本層卷積核之后,進(jìn)入池化層(可要可不要)和激活層,此時(shí)不需要訓(xùn)練初始參數(shù)。
下一個(gè)卷積層重復(fù)上述過(guò)程,不過(guò)本層的輸入是上層輸出的結(jié)果,上層若含有m 個(gè)特征,本層的輸入就為m 維矩陣,圖像大小為:
在式(1)中,InputSize 代表每層輸入圖像的大小,filterSize 代表卷積和池化的大小,pad 代表在圖像邊緣補(bǔ)零的大小,stride 代表步長(zhǎng)。由式(1)計(jì)算出每層輸出的圖像大小,從m 維圖像中分割出若干小圖像,小圖像和本層的卷積核大小相同,將小圖像作為自編碼網(wǎng)絡(luò)的輸入,從而進(jìn)行訓(xùn)練。依此類(lèi)推,凡是有卷積的隱含層和全連接層,就用自編碼進(jìn)行訓(xùn)練,以獲取卷積核的初始參數(shù)。將自編碼訓(xùn)練的初始參數(shù)進(jìn)行組合,得到卷積神經(jīng)網(wǎng)絡(luò)的預(yù)訓(xùn)練模型,此模型的參數(shù)只是在每一層最優(yōu),全局并不最優(yōu)。用少量的標(biāo)記樣本進(jìn)行參數(shù)微調(diào),使卷積核參數(shù)實(shí)現(xiàn)全局最優(yōu)[2] ,進(jìn)而得到適合實(shí)驗(yàn)數(shù)據(jù)分類(lèi)的模型。
通過(guò)自編碼獲取預(yù)訓(xùn)練模型,首先要設(shè)計(jì)卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu),在此結(jié)構(gòu)基礎(chǔ)上,利用自編碼訓(xùn)練網(wǎng)絡(luò)每層卷積核的初始系數(shù),即預(yù)訓(xùn)練模型。具體流程如圖4 所示。
2實(shí)驗(yàn)環(huán)境和流程介紹
經(jīng)過(guò)測(cè)試,在使用深度學(xué)習(xí)庫(kù)MatConvNet 的訓(xùn)練過(guò)程中,使用GPU 加速訓(xùn)練的速度約是CPU 訓(xùn)練速度的7 倍,使用“GPU+cuDNN”的并行加速框架訓(xùn)練的速度約是CPU 訓(xùn)練速度的10 倍(如圖5 所示)。在本實(shí)驗(yàn)中,硬件為擁有2GB 顯存的NVIDIA GTX950顯卡搭配12GB 內(nèi)存;軟件方面,在Windows 7 平臺(tái)下使用Matlab2014a 搭配CUDA7.5 加速;卷積神經(jīng)網(wǎng)絡(luò)庫(kù)選用MatConvNet 的1.0?bata18 版本[3] 。
利用自編碼訓(xùn)練卷積網(wǎng)預(yù)訓(xùn)練模型的方法對(duì)遙感圖像進(jìn)行分類(lèi)(流程如圖6)的具體步驟為:(1)使用自編碼的非監(jiān)督方式,通過(guò)無(wú)標(biāo)記的遙感圖像樣本對(duì)已設(shè)計(jì)的卷積神經(jīng)網(wǎng)絡(luò)每層的卷積核進(jìn)行預(yù)訓(xùn)練,將學(xué)習(xí)的特征作為卷積神經(jīng)網(wǎng)絡(luò)的參數(shù)值,得到預(yù)訓(xùn)練模型;(2)用少量的帶有標(biāo)記的遙感圖像數(shù)據(jù)進(jìn)行訓(xùn)練,微調(diào)預(yù)訓(xùn)練模型的參數(shù),得到適合研究區(qū)域遙感圖像的分類(lèi)模型,實(shí)現(xiàn)實(shí)驗(yàn)數(shù)據(jù)的分類(lèi),從而進(jìn)行分類(lèi)結(jié)果評(píng)價(jià)。
在獲得預(yù)訓(xùn)練模型之后,利用少量標(biāo)記的遙感影像樣本重新訓(xùn)練網(wǎng)絡(luò),實(shí)現(xiàn)模型參數(shù)的微調(diào)整,從而得到適合分類(lèi)實(shí)驗(yàn)數(shù)據(jù)遙感影像的模型,并用于遙感圖像的分類(lèi)[4] 。具體流程如圖7 所示。
由于兩個(gè)實(shí)驗(yàn)的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置和卷積層數(shù)不同,因此將卷積和池化層用虛線(xiàn)框表示,不同的實(shí)驗(yàn)數(shù)據(jù)使用不同的卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
對(duì)由實(shí)驗(yàn)數(shù)據(jù)分割得到的訓(xùn)練小圖像塊進(jìn)行如下預(yù)處理:(1)0 均值是最常用的圖像預(yù)處理方法,即把數(shù)據(jù)的每一維減去每一維的均值,使得數(shù)據(jù)變?yōu)?均值形式;(2)由于每類(lèi)的數(shù)據(jù)樣本數(shù)差異可能很大,為保證數(shù)據(jù)平衡,刪除類(lèi)別過(guò)多的數(shù)據(jù),然后通過(guò)如圖像翻轉(zhuǎn)的方法增加數(shù)據(jù)量較少的類(lèi)別個(gè)數(shù),保證數(shù)據(jù)的平衡性。
2.1基于自編碼和遷移學(xué)習(xí)的卷積神經(jīng)網(wǎng)絡(luò)分類(lèi)實(shí)驗(yàn)
是否運(yùn)用遷移學(xué)習(xí)方法取決于多種因素,但在訓(xùn)練樣本較少的情況下,最重要的是保證目標(biāo)數(shù)據(jù)集與源數(shù)據(jù)集在內(nèi)容上保持較高相似度[5] 。實(shí)驗(yàn)數(shù)據(jù)源于QuickBird 的彩色合成圖像裁剪的區(qū)域,在內(nèi)容上的相似度較高,因此將實(shí)驗(yàn)數(shù)據(jù)的預(yù)訓(xùn)練與精調(diào)參數(shù)后的兩種模型分別作為源域模型,進(jìn)行遷移學(xué)習(xí),從而對(duì)實(shí)驗(yàn)數(shù)據(jù)進(jìn)行分類(lèi),使輸入圖像與同圖像的大小保持一致。重新訓(xùn)練網(wǎng)絡(luò)可以實(shí)現(xiàn)參數(shù)微調(diào),選擇標(biāo)記樣本的5%,即每類(lèi)地物標(biāo)記的50 張圖像,剩下的標(biāo)記點(diǎn)用于測(cè)試,實(shí)驗(yàn)數(shù)據(jù)2 非監(jiān)督預(yù)訓(xùn)練的方法記為Un_pre,非監(jiān)督基礎(chǔ)上精調(diào)的模型記為Un_pre_f,兩種模型測(cè)試精度如表1 所示。
由兩種非監(jiān)督預(yù)訓(xùn)練的分類(lèi)結(jié)果可以得出:在樣本較少的情況下進(jìn)行遷移學(xué)習(xí), 圖像之間的內(nèi)容相似度較高時(shí),非監(jiān)督預(yù)訓(xùn)練的模型與非監(jiān)督基礎(chǔ)上經(jīng)過(guò)精調(diào)參數(shù)的模型,兩種預(yù)訓(xùn)練模型用作源域模型進(jìn)行遷移學(xué)習(xí)時(shí),均可以得到較高的分類(lèi)精度,即在訓(xùn)練樣本較少的情況下,網(wǎng)絡(luò)對(duì)于預(yù)訓(xùn)練的模型依賴(lài)度較高,避免了對(duì)標(biāo)記樣本的過(guò)擬合。而非監(jiān)督的預(yù)訓(xùn)練模型是由圖像不同位置訓(xùn)練獲得,因此對(duì)于訓(xùn)練樣本的測(cè)試與訓(xùn)練樣本差異較大的圖像分類(lèi)都較好[6] 。
3總結(jié)

- 計(jì)算機(jī)應(yīng)用文摘的其它文章
- Flash動(dòng)畫(huà)制作技術(shù)與網(wǎng)頁(yè)設(shè)計(jì)的融合路徑分析
- 基于營(yíng)銷(xiāo)資源系統(tǒng)云化后的數(shù)據(jù)庫(kù)查詢(xún)性能優(yōu)化探究
- 基于策略的計(jì)算機(jī)網(wǎng)絡(luò)管理技術(shù)研究
- 計(jì)算機(jī)網(wǎng)絡(luò)信息安全中心數(shù)據(jù)加密技術(shù)研究
- 基于IFC標(biāo)準(zhǔn)的存儲(chǔ)格式優(yōu)化研究
- 耳片接頭結(jié)構(gòu)的參數(shù)化設(shè)計(jì)與優(yōu)化