高速鐵路設施管理單元區段動態劃分方法
2022-04-06 08:38:32魯思成許玉德
華東交通大學學報 2022年1期
魯思成,許玉德 ,喬 雨
(1. 同濟大學道路與交通工程教育部重點實驗室,上海 201804;2. 同濟大學上海市軌道交通結構耐久與系統安全重點實驗室,上海 201804)
良好的基礎設施質量狀態是高速鐵路行車安全的重要保障[1],軌道不平順會對列車的運行安全產生影響[2-3]。 我國高速鐵路養護維修部門采用單元區段對線路基礎設施進行管理,通過將線路劃分為等長的單元區段,掌握單元區段內基礎設施的狀態變化規律,針對性地進行養護維修作業[4]。 學者對傳統單元區段的劃分進行了研究[5-6]。 然而,我國高速鐵路存在線路條件、結構形式、環境特征多樣且復雜的特點,在運營階段,傳統單元區段劃分方法的問題逐漸顯現[7]。
在新的單元區段劃分方法研究方面,仲春艷等[8]建立了單元區段選擇模型, 實現了結合線路狀態、考慮養修能力的不等長、動態單元區段劃分。 劉明亮[9]通過對設備單元劃分中影響因素的對比分析,提出了劃分的主要參考依據, 分析了具體方法流程,在此基礎上探討了設備單元動態劃分方法。 陶竑宇[10]探討了將單元質量均衡管理思想運用于鐵路軌道管理中的可行性,分析了鐵路線路軌道單元劃分的意義、原則以及劃分的形式。 然而,現有的研究多集中在鐵路工務基礎設施方面,沒能將多專業綜合維修[11]的理念考慮進來,使得提出的單元區段劃分方法仍存在一定的專業局限性。
1 單元區段劃分原則
我國鐵路將200 m 作為線路管理的基本單元長度,高速鐵路線路管理的單元區段則是由若干連續的基本單元組成。 為實現單元區段自動劃分,根據仲春燕等[8]的研究,給定劃分原則及優先級。
1.1 第一原則
第一原則是單元區段最基本的原則, 主要包括:①基本單元的長度為200 m;②軌道質量指數(track quality index,TQI)計算長度與基本單元長度一致;③單元區段的最小長度為200 m,最大長度為2 000 m;④單元區段長度為基本單元區段最小長度200 m 的整倍數。
1.2 第二原則
第二原則是指單元區段劃分的優先級,根據高速鐵路養護維修部門提供的臺賬信息,將不同類型的地段劃為不等長、固定的單元區段。 地段主要包括:①車站;②道岔;③橋梁;④隧道;⑤曲線;⑥坡道;⑦人為指定區段。
根據第一原則和第二原則,可將線路進行第一階段的固定單元區段劃分, 將線路劃分為不等長、不同屬性、固定的單元區段。
1.3 第三原則
第三原則是為了重點掌握狀態較差的地段,在劃分單元區段時,將連續較差的基本單元劃分在一起, 這需要根據連續的線路檢測數據進行篩選,該方法是不等長、動態的區段劃分方法。 該階段也是單元區段劃分的第二階段,主要考慮:①TQI 值;②接觸線高度;③弓網接觸力;④其他連續檢測數據。 結合實際,可選擇上述檢測數據的一種或多種對線路進行動態劃分。
2 單元區段動態劃分方法
以TQI 作為單元區段劃分的標準, 如圖1 所示, 將高速鐵路TQI 檢測數據看作一個數據序列,對于單元區段的動態劃分,找出數據序列中的特征點,基于特征點對數據序列進行分割。 顯然的,數據序列中最為直觀的特征點為數據的極值點,但并非所有的極值點都是單元區段劃分的特征點,這是因為當在某個區間TQI 低于標準中的限值時,不管該區間的極值點情況如何,都不會影響該區間質量狀態的評價結果;因此,必須從數據序列大量的極值點中篩選出有用的特征點。
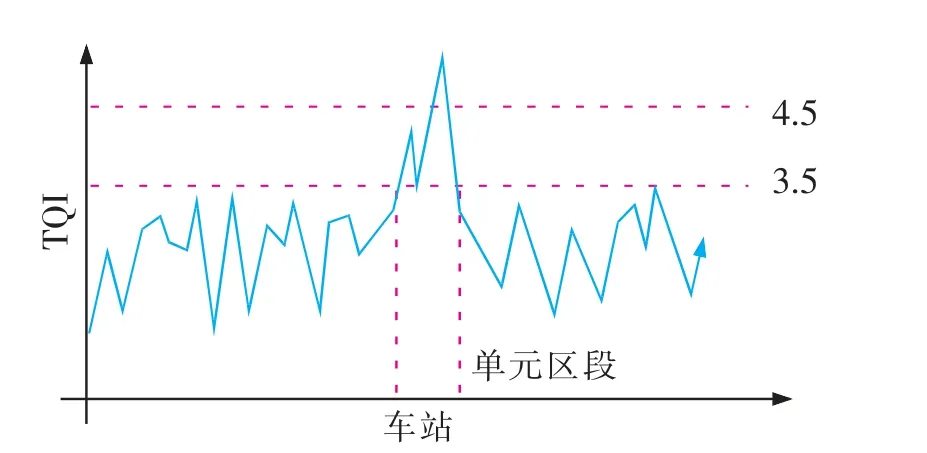
圖1 高速鐵路TQI 數據序列Fig.1 TQI data sequence of the high speed railway
2.1 單元區段自動劃分算法
為實現單元區段自動劃分目的,本文采用自底向上分割算法[15](bottom-up)對TQI 數據序列進行分割。 自底向上算法是從最精細的分割方式(時間序列上相鄰兩點組成最小分割片段)出發,然后計算合并兩個相鄰分割片段所產生的分割誤差,合并分割誤差最小的兩個鄰接分割片段,直到分割誤差超過某個指定門限值停止合并。 對于數據序列分割時產生的誤差,本文則采用最大誤差標準。
單元區段自動劃分的算法思路:
Step1 輸入一段長度為n,幅值為A 的單維時間序列T=(t1,t2,…,tn),預定的合并代價閾值參數設為p;
Step2 篩選序列中所有極值點, 極值點為{e1,e2,…,em};
Step3 計算每個備選分割點與右臨備選分割點的合并代價;
Step4 將當前具有最小合并代價的備選分割點s 與其右臨備選分割點合并,并從備選分割點集合S 中刪去s;
Step5 更新s 點左右臨近備選分割點的合并代價;
Step6 如果最小合并代價大于預定閾值p 時,輸出序列分割點集合Q;否則回到Step4,繼續求解。
合并代價閾值參數p 為時間序列幅值的比例,確定幅值A 前需對異常值進行剔除。
2.2 單元區段劃分算法修正
采用自底向上算法對滬寧城際鐵路100 個基本單元區段某次檢測的TQI 數據進行分割, 經計算,參數p 設置為0.15。
數據序列初始分割如圖2(a)所示,可以看出,在所有的分割點中,有部分TQI 的極大值被當作了分割點,這意味著狀態最差的地段被分割在了兩個連續的單元區段中,而分割的目的是把狀態較差的區段(即TQI 較大的區段)單獨劃分出來,而上述算法明顯不能很好地解決這個問題,有必要對上述算法進行修正。

圖2 數據序列的分割點Fig.2 Segmentation points of data sequence
首先,如圖2(b)所示,將極大值點用紅色虛線表示。可以看到,對于大部分區段來講,直接刪除極大值點沒有問題, 但是對于點68、72 和點91、93 這種連續極大值點(圖中標出點)來說,直接將其從分段點中刪除是不妥的,這樣無法控制分段區間的合并代價。
如圖2(c)所示,在連續兩個極大值中間尋找最小值,用藍線表示,作為兩極大值的分段點,可以保證極大值兩側的合并代價是不大于預定閾值的。
最終得到修正后該序列的分割點,如圖2(d)所示。
2.3 單元區段自動劃分流程
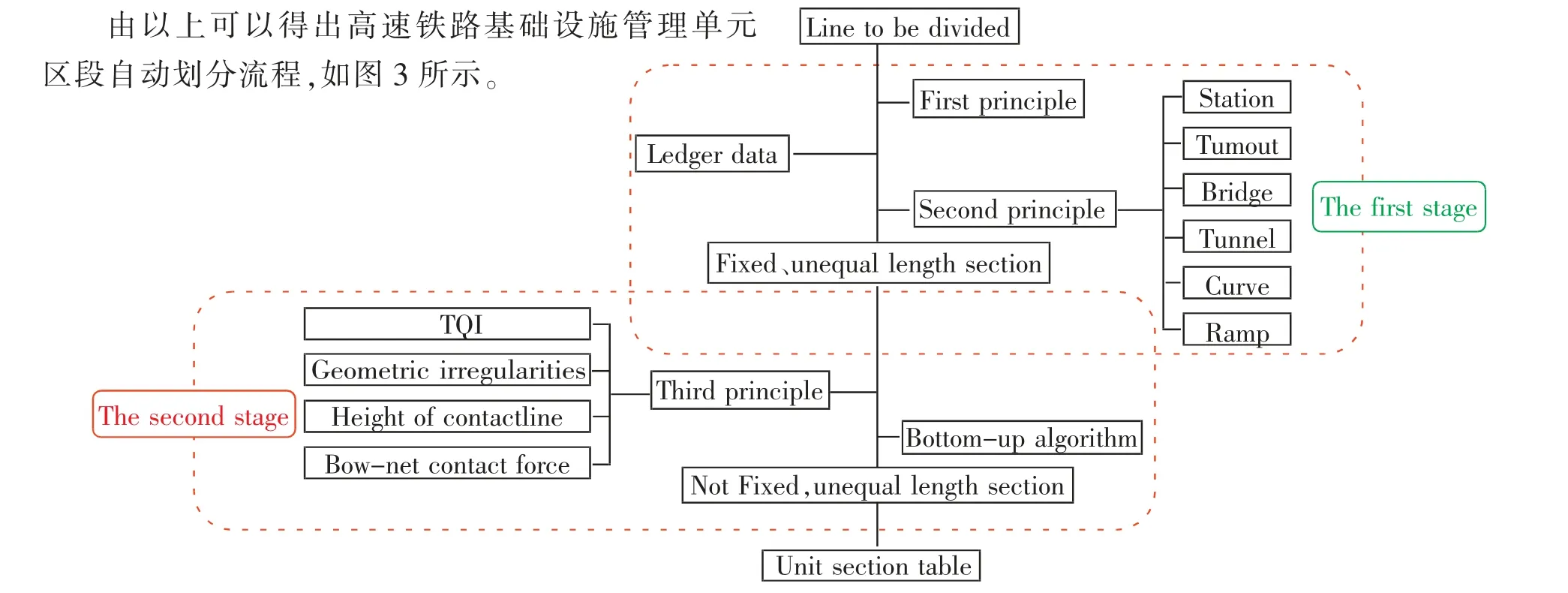
圖3 單元區段劃分流程Fig.3 Flow of unit section division
對于待劃分線路,結合臺賬數據,依照第一原則和第二原則對線路進行第一階段的固定單元區段劃分。 為進一步掌握狀態較差的地段,在劃分單元區段時,依照第三原則的TQI、接觸線高度等考慮因素對線路進行第二階段的動態單元區段的劃分,根據需要,可選擇上述檢測數據的一種或幾種對線路進行動態劃分,以滬寧城際鐵路的TQI 檢測數據為例對其進行動態單元區段劃分。
3 單元區段劃分實例
按照提出的單元區段自動劃分方法,對滬寧城際鐵路上行線進行基礎設施管理單元區段劃分。
3.1 第一階段劃分
結合臺賬數據,按照第一原則和第二原則進行第一階段的固定單元區段劃分,得到滬寧城際鐵路上行線DK0+000~DK300+400 里程范圍內線路共劃分了692 個單元區段。 對于劃分的692 個單元區段,根據第二原則中的車站、道岔、橋梁、隧道、曲線、坡道6 種屬性進行自動分類統計,可以掌握線路基本結構情況,如圖4 所示。 圖4 中無屬性表示單元區段中沒有車站、道岔、橋梁、隧道、曲線、坡道中任何一種結構,單屬性表示單元區段中有其中一種結構,依此列推。 滬寧城際高速鐵路上行線所有單元區段中,具有2 個屬性的區段數最多,將近占130 km,具有3 個屬性的區段數次之,超過90 km,只具有一個屬性的區段數排在第三位,超過60 km,具有4 個或5 個屬性的區段數最少;從對應的里程分布來看,基本上和區段數分布一致。
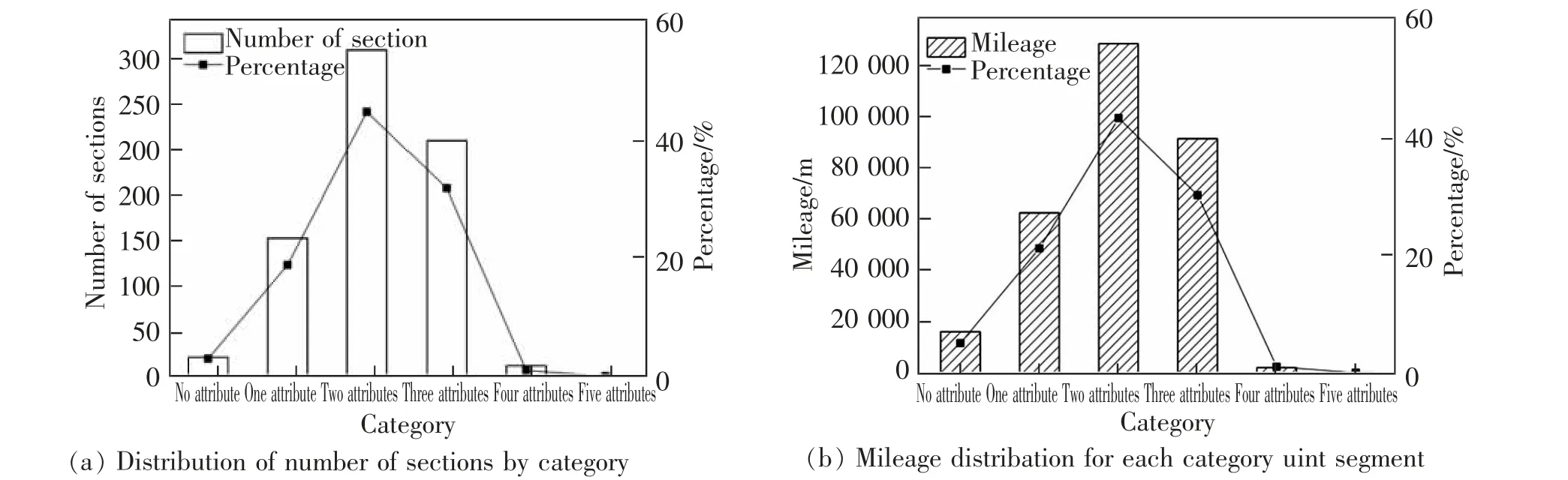
圖4 線路基本結構情況Fig.4 Basic situation of the line structure
3.2 第二階段劃分
首先對算法參數進行確定。由單元區段動態劃分算法可知,除了一個單維的時間序列T,還需要輸入預定的合并代價閾值參數p, 該參數直接關系到了區段劃分的長度,為了確定合適的參數p,利用滬寧城際鐵路某個自然月的TQI 檢測數據,以不同長度的線路應用不同的參數p 進行區段劃分,如圖5 所示。
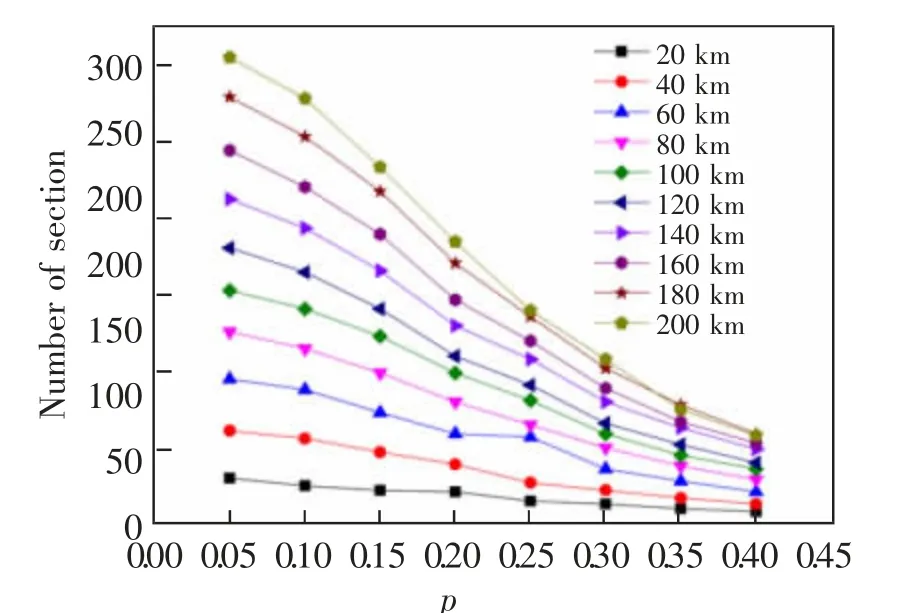
圖5 不同參數p 下分段數Fig.5 The number of segments under different parameters p
由圖5 可以看出,隨著參數p 的增大,不同長度線路劃分出來的區段數越來越少。 參數p 越小,下降趨勢越明顯。 當參數p 小于0.2,即融合閾值小于幅值的0.2 的時候, 參數p 的變化對線路劃分有著較大的影響;當參數p 大于0.3,即融合閾值大于幅值0.3 的時候, 參數p 的變化對線路劃分影響稍小。 且線路越長,下降趨勢越明顯。 當參數p 小于0.2 時,線路越長,參數p 的變化對線路劃分影響越大;當參數p 大于0.3 時,線路長度的改變隨參數p的變化對線路劃分的影響稍小。
為方便對線路進行養護維修管理以及把握線路整體狀態,在對線路進行分析時不希望線路根據TQI 劃分的區段全部太長或者太短, 若劃分區段全部太長,即參數p 越大,則無法識別線路狀態較差地區;若劃分區段全部太短,即參數p 越小,則無法重點突出線路狀態較差的地區。 為此,計算不同線路長度及不同參數p 下劃分出區段的平均長度,如圖6 所示。 所有不同長度線路劃分出區段的平均區段長度隨參數p 的變化趨勢均在參數p 取0.2 到
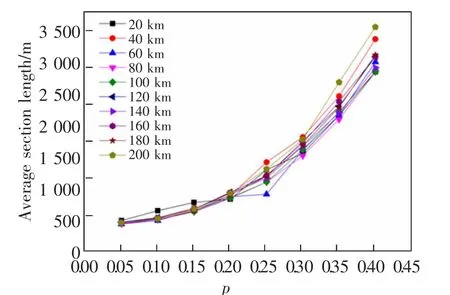
圖6 不同參數p 下區段平均長度Fig.6 Section average length under different parameters p
0.3 之間發生明顯變化。
當參數p 小于0.2 時,除20 km 線路外,其余不同長度線路隨著參數p 的增大, 變化趨勢基本一致,且平均區段長度在1 200 m 以下; 當參數p 大于0.3時,不同長度線路隨著參數p 的增大,變化趨勢基本一致, 且平均區段長度即將超過區段劃分第一原則規定的2 000 m 的上限。 當參數p 在0.2 和0.3 之間時,是大部分線路變化趨勢的拐點,同時也是不同長度各線路變化區別最大的區間,尤其當參數p 取0.25時,平均區段長度浮動范圍為1 071 m 至1 538 m。
當參數取0.2~0.3 時,既能夠保證線路按照TQI劃分得到的區段長度不至于太長,使得絕大部分區段都能夠處于區段劃分第一原則規定的2 000 m 上限之下,重點突出線路狀態較差地區;也能夠保證區段長度不至于太短,使得區段長度在1 000 m 上下波動,有效識別線路狀態較差地區;同時線路劃分出的區段平均長度對參數p 取0.25 時最為敏感,也就是說,此時能夠更加有效多樣地按照線路狀態劃分線路,故推薦p 取0.25。
對滬寧城際鐵路上行線進行第二階段的動態單元區段劃分, 得到滬寧城際鐵路上行線DK0+000~DK300+400 里程范圍內線路共劃分了172 個單元區段,按照第一原則、第二原則和第三原則對其進行第二階段的動態劃分后,共劃分了777 個單元區段,相較于第一階段的固定單元區段劃分,多劃分出85 個單元區段。 以此法進行區段劃分,可以重點掌握狀態較差區段,并大大提高了劃分效率與準確性。
4 結論
本文提出的高速鐵路基礎設施管理單元區段的自動劃分方法,對掌握線路基本結構情況,把握基礎設施狀態變化規律, 快速定位狀態較差地段,針對性制定養護維修計劃,提高養護維修效率和質量具有基礎性作用。
1) 針對人工劃分單元區段效率低,易出錯的問題,提出了單元區段自動劃分第一原則、第二原和第三原則,并且利用Matlab 編程實現了單元區段的自動劃分, 將其分為第一階段的固定單元區段劃分,用來掌握線路基本結構情況。
2) 第二階段采用改進的自底向上算法進行動態單元區段劃分, 用來重點掌握狀態較差區段,大大提高了劃分效率與準確性。
3) 以滬寧城際高速鐵路上行線為例進行第一階段的固定單元區段劃分,掌握了滬寧城際高速鐵路線路的基本結構情況;并根據TQI 檢測數據進行了第二階段的動態單元區段劃分。
