基于FT-MIR的三七粉末摻偽成分的定量檢測模型研究
2022-04-15 07:39:08何鳳蕓楊曉東周勝靈謝林李光林
西南大學學報(自然科學版) 2022年4期
何鳳蕓,楊曉東,周勝靈,謝林,李光林
西南大學 工程技術學院,重慶 400715
三七又稱田七、人參三七、金不換等,為五加科植物,主要產于云南、廣西、四川,是一種應用于臨床治療的中藥材[1].通過研究發現,三七不僅可以治療咯血、衄血、外傷性出血、腫痛等癥狀[2],對冠心病、心絞痛、糖尿病、血栓等疾病也具有良好療效[3].大量的科學研究表明,三七有效成分中不僅含有Rb1,Rd,Re,Rg1,Rg2,Rh1,R1,R2,R3,R4,R6,R7等人參皂苷,還包括77種揮發油、17種氨基酸、丹參堿、三七黃酮類和多糖等[4].三七的藥用加工方式分為精加工(提煉萃取物)和粗加工(研磨成粉末)兩類.為了盡可能降低成本和牟取最大化的利益,不法商人選擇將三七粉與幾種中藥材粉末混合,在醫藥市場上以相同甚至更低的價格出售,不僅擾亂了市場秩序,還損害了消費者的利益和健康.為解決摻假問題,找出能夠快速精確地鑒別三七粉末純度的方法是非常必要的[5].
中國傳統藥材的光譜鑒定主要使用特定波長的光照射或掃描樣品,獲取特定的圖譜數據.中藥材光譜鑒別主要包括紫外光譜、紅外光譜、熒光光譜、核磁共振和質譜等方法[6-7].傅利葉中紅外光譜技術(Fourier transform mid-infrared,FT-MIR)能檢測多組分因素,還具有掃描速度快、靈敏度高等優點,不需要與KBr等混合制樣,無需壓片,比近紅外掃描獲得的數據具有更高的完整度.由于FT-MIR具有檢測精度高、分辨率高、應用范圍廣以及不需要對樣品做預處理等優點,已廣泛應用于預防醫學、農業、生殖生物學等領域對樣品進行定量分析.
圖1為實驗流程,實驗使用標準正態變換(Standard normal variate,SNV)、基線校準(Baseline)等方法單獨或組合進行原始光譜數據降噪及平滑; 協同區間(Synergy interval,Si)、競爭自適應加權算法(Competitive adaptive reweighted sampling,CARS)、連續投影算法(Successive projection algorithm,SPA)等方法用于挑選建模使用的特征變量; 最后分別建立偏最小二乘回歸(Partial least squares regression,PLSR)模型及支持向量回歸(Support vector regression,SVR)模型,再比較建模效果.甘草、合歡樹皮以及向日葵花盤等藥材粉末具有與三七粉末相似的外觀和物理性質,僅憑肉眼幾乎無法分辨他們的差別,這些藥材的價格也遠比三七低廉,因此常用于配制三七偽品.實驗將20頭純三七粉末與甘草、合歡樹皮和向日葵花盤等藥材粉末分別按實驗設計的10個摻比混合,并采集所有樣品的FT-MIR光譜數據[8-9].

圖1 三七粉末及其混合物偽品成分定量檢測模型建立流程圖
1 材料和方法
1.1 實驗材料
實驗所用樣品包括采集于文山產區的20頭三七1 000 g,購買于中藥材市場的純甘草超細粉末、純向日葵花盤超細粉末、純合歡樹皮超細粉末各1 000 g.所有樣本收集完成后均放置于50 ℃恒溫環境中至質量保持恒定.使用研磨機將烘干后的三七樣品粉碎后過200目篩,純甘草超細粉末、純向日葵花盤超細粉末、純合歡樹皮超細粉末烘干后也分別過200目篩,用精天FA1004A萬分之一精度電子天平按表1的比例分別稱取甘草、合歡樹皮和向日葵花盤粉末與三七粉末放入瑪瑙研缽中,用缽杵研磨使粉末混合均勻,每種比例制備35份樣品,每個樣品總質量為1 g,用于光譜數據采集.建立基于FT-MIR的三七粉末摻偽成分的定量檢測模型,以實驗樣品摻偽成分的不同質量作為濃度變量,保持每一份實驗樣品總質量不變,以100%偽品藥物粉末含量為基準,每次以0.1 g為增量梯度摻入三七粉末,同時減少0.1 g的偽品.
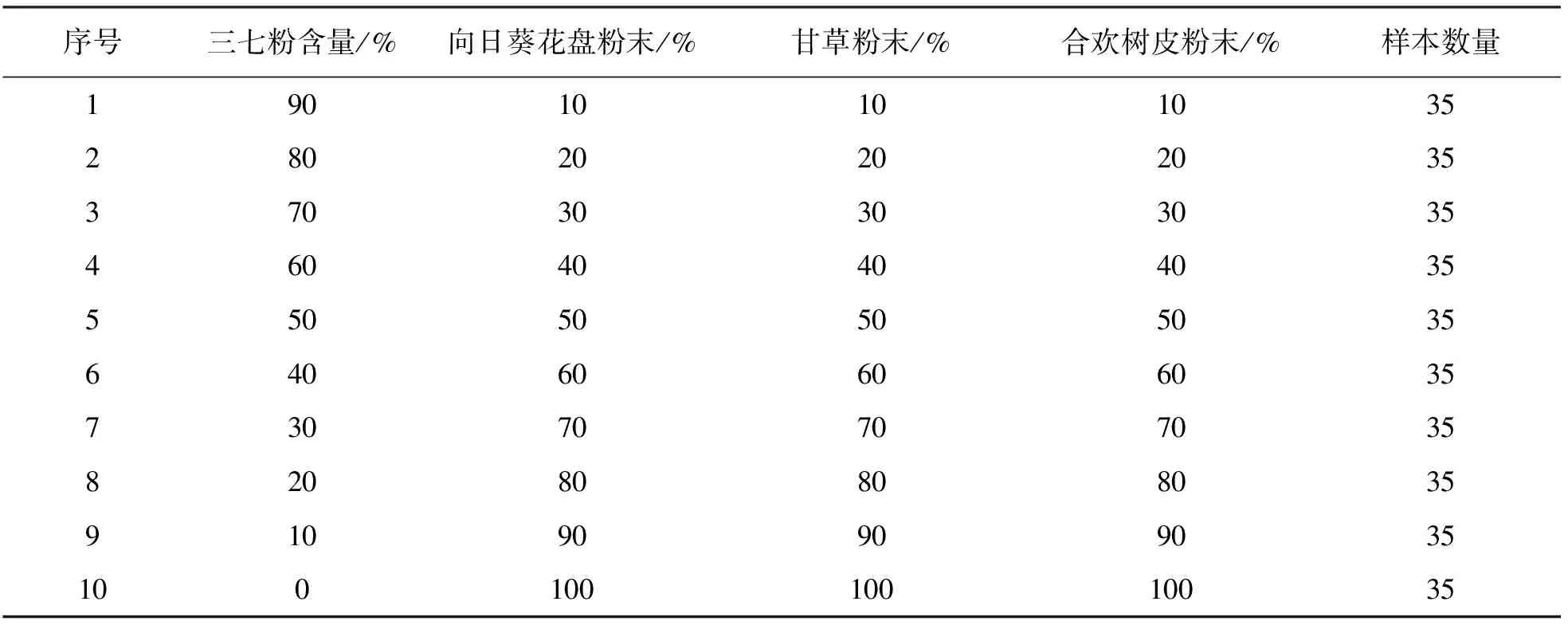
表1 三七粉末分別與向日葵花盤粉末、甘草粉末、合歡樹皮粉末混合的比例

圖2 三七及其偽品混合物的FT-MIR光譜
1.2 FT-MIR光譜數據采集
光譜數據采集使用的設備為傅里葉變換紅外光譜儀(Thermo Fisher Scientific 5225 Verona Rd.Madison,WI 53711),光譜采集設備配套軟件為OMNIC,初始化設置如下:分辨率設置4 cm-1; 設置自動大氣背景扣除; 每間隔30 min重新采集一次背景信息; 掃描次數為32次,最終掃描結果取平均光譜.如圖2所示,單個樣品通過實驗最終得到一條FT-MIR光譜.模型建立使用Random Sampling算法劃分數據集,訓練集與預測集劃分比例為3∶1,訓練集共787條光譜數據,預測集共262條光譜數據.光譜數據分析處理使用的軟件包括MATLAB2018a,The Unscrambler X10.4,OriginPro 8等.
1.3 數據預處理和異常值剔除
原始光譜數據中常存在一些與待測樣品性質無關的噪聲信息,這些干擾信息會直接造成光譜數據的基線漂移.因此,有必要采用預處理方法消除噪聲,將儀器或環境的干擾而隨機引起的噪聲信息最小化,提高樣品光譜的信噪比.SNV和Baseline等方法[10-11]可有效地校正紅外光譜數據,消除顆粒大小和分布不均勻對數據的影響,實驗分別應用這兩種光譜預處理方法及其組合方法對原始數據進行預處理后建立回歸模型.
異常值是指樣本中的個別值[12],其數值明顯偏離所屬樣本的其余觀測值,不屬于同一總體,因此需要通過數據預處理及特征變量挑選減少它對實驗結果的干擾.實驗通過計算F值(F-residuals)和T值(Hotelling’s T2)并將此結果作為評判變量是否為異常值的標準.F值的大小即為樣本和模型之間的差值,而T值則是表征模型對樣本描述效果的評估.當F值和T值的計算結果超出置信區間[13]的5%,那么這個樣本就可被視為異常值.實驗中剔除了一條異常光譜,總計使用1 049條樣品光譜,每條光譜含7 468個變量.
1.4 偏最小二乘回歸原理及支持向量回歸建模
PLSR是一種基于因子分析的多元校正方法,廣泛應用于定量分析,集成了主成分分析、典型相關分析、線性回歸分析的優點[14]; SVR[15]是在研究二分類問題的基礎上提出的,旨在使所有樣本點離超平面的總偏差最小.實驗中全光譜數據、特征波段和特征變量被分別用于建立各自的PLSR和SVR模型,評價變量選擇方法主要通過比較基于不同方法建立的模型效果,依據均方根誤差(RMSE)和決定系數(R2)進行評估.

圖3 三七、甘草、向日葵花盤、合歡樹皮粉末光譜
2 結果與分析
2.1 FT-MIR特征
實驗中使用FT-MIR數據,因此采集了波長范圍400~4 000 nm的反射譜,用于后續數據分析和建模.全光譜可分為4個寬區域:X—H延伸區(2 500~4 000 nm)、三鍵區(2 000~2 500 nm)、雙鍵區(1 500~2 000 nm)和指紋區(400~1 500 nm).圖3為純三七粉、純向日葵盤粉、純甘草粉、純合歡皮粉的FT-MIR光譜,所有藥材粉末的光譜特征都呈現出相似的趨勢,有明顯吸收峰的波長約1 008.84 nm和3 285.43 nm,這可能與C—H—O鍵和O—H鍵的對稱振動有關.當樣品受到紅外輻射時,會產生反射、吸收等作用,所以物質濃度差的變化可以直接反映在能量變化上.
2.2 建模的特征變量選取方法
2.2.1 協同區間算法(Si)
Si可以結合多個高精度的局部區間來最小化模型中的變量數量[17].對于每個區間組合,以RMSE作為模型精確度的評價標準,選取RMSE最小的獨立子區間建立PLSR模型進行預測.校正集RMSE為0.014 4,預測集RMSE為0.015 1,全光譜劃分為20個子區間,此時經Si選擇出的特征波段為第14,15,16,17,18個子區間,波長范圍為759.815 9~1 658 nm,其中共含有1 864個變量.Si-PLSR方法選擇的特征變量數與原光譜數據的全部變量數相比已大幅減少,但樣本總量與壓縮后的變量綜合后,對于建模而言仍然是非常龐大的運算量,因此有必要對樣品光譜的特征變量數進一步壓縮.
2.2.2 競爭自適應加權算法(CARS)
與Si相比,CARS[18]是一種變量選擇方法,因此覆蓋面更廣.CARS算法對于同樣的數據集單次運行的結果會有些差異,即挑選出的變量及其數量略有不同,在此基礎上建立的定量模型也會得出略微不同的評價結果.為得到盡可能精確的實驗結果,數據經過120次CARS算法計算,綜合計算結果選取RMSE值最小的變量選擇結果為后續建模使用的理想數據.圖4即為運行120次CARS算法后采用的最優結果,表示隨采樣次數增加,算法選擇的特征變量在數量上會逐漸縮減; 圖4(b)中曲線表示的是RMSE隨采樣次數的增加而改變的趨勢,可以看出采樣次數小于20次時,預測集RMSE穩定小于0.05,對應圖4(a)特征變量數較多,而當采樣次數大于20后,預測集RMSE明顯增大,對應圖4(a)顯示變量總數趨于極小值,說明迭代過多后選擇的特征變量過少,導致PLSR模型欠擬合; 圖4(c)回歸系數,展示了每次迭代各變量的回歸系數值會隨采樣次數增加而波動的情況,每條曲線都代表著一個變量的回歸系數,迭代結束后回歸系數不為0的變量被CARS選中.
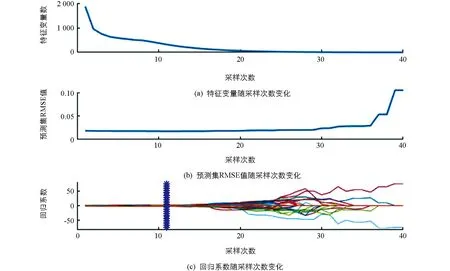
圖4 CARS算法特征變量選擇結果
從圖4可以看到,隨著CARS算法迭代次數在1~15區間時,特征變量數會急劇減少,預測集RMSE值則處于較低水平,回歸系數此時同樣沒有明顯變化; 當迭代次數處于15~30區間內,特征變量數量已降至最低,預測集RMSE在此階段無明顯變化,回歸系數開始劇烈波動; 當迭代次數處于30~40區間內,預測集RMSE值急劇上升,這表明隨著特征變量的減少,模型會欠擬合,大量回歸系數經歷振蕩后波動幅值減小,逐漸收斂于零,也存在少量回歸系數波動幅值持續增大.總體來看,當CARS迭代11次時,預測集RMSE的值最小,回歸系數也處于穩定水平,對應圖4(a)中選出的特征變量總數為321.

圖5 SPA算法特征變量篩選結果
2.2.3 連續投影算法(SPA)
SPA是前向特征變量選擇方法[19],變量選擇的最終結果是最小共線性的變量組合,利用向量的投影分析,將波長投影到其他波長上,投影向量的大小決定其是否能夠作為待選波長.實驗在經過Si和CARS選擇后每條樣品光譜留存了321個變量,使用SPA算法可以在保持建模性能良好的前提下最大限度地減少變量數.算法迭代最佳結果校正集RMSE值為0.0210,預測集評價指標RMSE值為0.0286,這表明變量選擇結果是合理的.圖5為SPA算法特征變量篩選結果,此時樣品光譜的變量總數壓縮到了17個,分別為1 560.13,1 347.999,1 150.813,1 132.492,1 106.458,1 040.89,1 009.552,985.446 5,945.430 9,889.505 4,862.506 8,845.150 6,839.365 2,804.652 8,799.831 5,786.332 3,759.815 9.
2.3 PLSR與SVR模型比較
表2總結了不同變量選擇方法的建模結果.通過采用Si和CARS及SPA得到的光譜變量建立PLSR和SVR模型,并利用模型結果評價變量選擇的效果.所有模型的決定系數均在0.97以上,表明所建立的模型具有較好的預測效果,也表明中紅外光譜技術適用于三七粉末成分定量檢測.由表2的實驗結果對比可知,SVR模型在各個變量選擇方法基礎上的性能表現均優于PLSR模型.三七粉末PLSR模型預測性能最優的是Si-CARS-PLSR模型,校正集RMSE值為0.024 4,R2值為0.992 8; 預測集RMSE為0.024 7,R2值為0.992 7.PLSR模型的校正集與預測集的RMSE均小于0.046,決定系數最小值為0.975 1.三七粉末SVR模型預測性能最優的是CARS-SVR模型,校正集RMSE值為0.019 9,R2值為0.9955; 預測集RMSE為0.020 5,R2值為0.994 1.SVR模型的校正集與預測集的RMSE均小于0.024 0,R2最小值為0.983 3.在PLSR模型中,與其他變量選擇方法相比,CARS可以選擇回歸系數絕對值較大的波長點去除權重較小的波長點,通過交互驗證選擇RMSE值最小的子集,可以有效地求出變量的最優組合.在SVR模型中,CARS變量選擇方法對于三七粉末成分表現了最好的預測結果,顯著減少了模型的光譜變量數,同時提高了模型的效率和準確性.
3 討論
光譜技術已經較為廣泛應用于三七質量檢測方面,Nie P C等[20]將三七粉末摻入苦參粉和玉米粉,使用可見光光譜和近紅外光譜分別建立了PLS模型和最小二乘—支持向量機(LS-SVM)模型.實驗結果表明,近紅外光譜技術適用于三七粉末的定量檢測,然而針對不同批次的檢測樣品,使用近紅外數據建立的判別模型泛化能力有待提升.Chen H等[21]使用了苦參粉、玉米粉分別依照不同比例摻入純三七粉末中,采集近紅外光譜數據,在此基礎上建立CARS-PLSR模型進行定量分析,實驗結果表明,基于特征變量建立的PLSR模型效果優于基于全光譜變量建立的PLSR模型.三七粉幾乎不溶于水,而玉米粉加入水中溶液會變渾濁,因此可通過觀察粉末加水后的溶液清澈程度進行判斷.目前,適用于光譜數據的定量分析模型多種多樣,如人工神經網絡(Artificial neural network,ANN)、多元線性回歸(Multivariable linear regression,MLR)、極限學習機(Extreme learning machine,ELM)、BP神經網絡[22]、PLSR和SVR等,使用的PLSR和SVR模型具有穩定性好、適用范圍廣等優點.三七及其偽品的光譜數據特征選擇過程是:首先將原始光譜劃分為20個子區間,使用Si選出特征波段,使用CARS從特征波段中選擇初始特征變量,使用SPA選出最終特征變量,使定量模型盡可能精簡.
每條原始光譜往往包含幾千個變量,其中大多數都是不表示研究對象特征的冗余信息,使用原始光譜建模會降低模型預測效果,選用的特征變量選擇可以較好地保留原始數據中潛在的語義信息,減少建模運算量.三七及其偽品的光譜數據特征變量選擇過程即首先將原始光譜劃分為20個子區間,使用Si選出特征波段,再結合CARS從中選擇特征變量,最后利用SPA將特征變量數壓縮至盡可能小.實驗完成了快速識別以及三七粉末及其偽品混合物的定量檢測,包括數據預處理、特征波段提取、特征變量選擇以及定量模型評估等,SNV和Baseline等方法單獨或組合用于原始光譜數據降噪及平滑; Si,CARS,SPA等用于挑選建模使用的特征變量; 最后分別建立PLSR及SVR模型.
4 結論
實驗結果表明,FT-MIR是定量檢測三七粉末摻入偽品的有效方法.實驗采用Si,CARS和SPA 3種變量選擇方法來提高模型的穩定性和預測精度,其中基于CARS方法挑選的特征變量訓練的SVR和PLSR模型對三七粉成分檢測都有較好的預測效果.對比兩種建模結果可知,SVR在使用相同變量時建模精度優于PLSR,實驗中建立的所有三七粉末及其混合物偽品成分定量檢測模型準確率最高的是CARS-SVR模型,評估參數校正集R2值為0.995 5,校正集RMSE值為0.019 9; 預測集R2值為0.995 2,預測集RMSE值為0.020 5,該模型的建立基于254個特征變量,數據量仍有進一步壓縮的空間.CARS-SPA-PLSR/SVR模型使用了數量最少的特征變量,與原始光譜的建模結果比對,即使是變量數從7 468減至12個,其建模效果仍優于全光譜.原始光譜數據在經過特征變量選擇后,不僅可提升建模精度,還能優化建模速度,為實際生產應用提供了可行穩固的方案.SNV-Baseline作為數據預處理方法有效消除了原始光譜數據中的噪聲信息,使用變量選擇方法CARS方法可以極大地壓縮特征變量數目,優化建模效果.實驗表明,CARS-SPA-SVR模型具有實際應用潛力,對今后的三七粉末質量分級、檢測和篩選具有重要意義.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
