目標檢測技術在互動視覺效果制作中的應用研究
——以北京冬奧會開幕式節目《雪花》為例
2022-04-19 02:34:14徐子凡
現代電影技術 2022年4期
關鍵詞:檢測
韓 柯 徐子凡
(北京電影學院聲音學院,北京 100088)
1 引言
在數字娛樂與展示行業,制作互動視覺效果的需求已經十分常見。借助一些傳感與捕捉技術將體驗者的行為轉換為控制視頻播放或圖形渲染的信號,視覺效果就能跟隨體驗者的位置或動作實時變化,創設出沉浸式的虛擬現實體驗。不過,在以演員為主體的舞臺表演中,演員的表演動作通常是預先設計好的,只要跟隨時間去表演,經過多次排練之后,就能呈現出數字影像與演員互動的效果,無需借助捕捉設備精準的獲取演員的動作或位置。
當藝術表演以概念的傳達為核心時,對互動視覺效果的制作與呈現手段會有新的需求。在北京冬奧會開幕式節目 《雪花》中,500名手拿和平鴿道具的孩子在超過1萬平米的LED 地磚屏上以自由嬉戲的形式進行表演,每個人腳下都有閃亮的雪花特效時刻“追隨”。為了準確傳遞孩子們心中的自由與浪漫,使用精準排練去解決小演員腳下的特效跟隨問題就不再是可選方案,而構建一個能夠實時測定演員位置的定位系統,并以此完成互動視覺效果的制作是更具可行性的方案。
2 演出領域的互動視覺效果制作概念
在視頻游戲行業,互動視覺效果的制作主要是以游戲圖形引擎為平臺的視效內容制作與交互規則開發。在這個成熟的工業體系中,智能手機、個人計算機以及游戲專用主機是互動效果的通用實現設備,游戲的體驗者以鼠標、鍵盤、觸屏或游戲手柄等方式控制渲染程序產生圖形數據,再通過手機或計算機的屏幕體驗視覺效果。因而,游戲領域的互動效果制作很少需要考慮互動效果實現系統的構建。
與視頻游戲行業不同,演出領域的互動視覺效果并沒有標準化的制作平臺。對于演出中的互動環節,一方面,表演者可以是既定的演員也可能是任意選出的觀眾,互動行為可以是表演者的位置、動作,也可能是其表情甚至著裝的顏色;另一方面,視覺效果的呈現可以通過數臺投影組合投射出的非規則畫面,也可能借助現場每一位觀眾的手機屏幕。因此,對于現場演出而言,互動視覺效果的制作者通常要根據項目需求去選擇合適的表演行為捕獲技術,并構建一個可由行為數據控制的視效處理系統,而視效內容制作與交互規則開發則應基于所建構視效系統的技術平臺。可以說,演出領域的互動視覺效果制作方案是一個同時包含內容制作與系統集成的完整解決方案,而北京冬奧會開幕式節目《雪花》的互動視覺效果制作正體現了上述概念。
3 《雪花》的表演形式與互動視覺效果需求
北京冬奧會開幕式節目 《雪花》的表演形式,以及互動視覺效果制作需求可概括如下。

圖1 《雪花》的演出效果
3.1 表演形式
660名兒童演員分為兩組,以露天體育場內平整鋪設的LED 地磚屏為舞臺進行表演。其中,500名舞蹈組演員手持發光道具在完整舞臺區域進行跑動、行走、轉圈、揮舞道具等動作,160 名合唱組演員邊歌唱邊行走,表演區域主要在舞臺中心區。
作為舞臺的LED 地磚屏尺寸約155米×76米。節目表演時段在日落后,使用常規舞臺燈光進行照明。
3.2 互動視覺效果
大量雪花狀圖形單元以組為單位持續生成并消失,每組效果在每個演員腳下區域實時生成后,快速向四周擴散,擴散半徑約1米,持續3到5秒后消失。擴散過程中帶有顏色與形態的改變,呈現出雪花沿演員行動軌跡散落的效果。
4 《雪花》的互動視覺效果制作思路
演出領域的互動視覺效果并沒有標準制作方案,在進行軟件層面的視效內容制作與交互規則編寫之前,首先要確定互動效果的實現平臺。
依據系統功能,可以把 《雪花》的互動視效實現平臺分為演員定位系統、圖形渲染系統、視效顯示系統三個部分,見圖2。

圖2 《雪花》的互動視效實現平臺結構
作為一個兼顧現場與直播效果的表演,《雪花》的視覺效果呈現基于國家體育場內已經鋪設的大規模LED 地磚屏,這是一個支持標準視頻信號輸入的顯示系統,也是視效顯示系統的主體。另一方面,在指定位置實時產生特定圖形是當今計算機實時渲染引擎的常規功能,盡管 《雪花》的視覺效果需要實時生成形狀、顏色等屬性動態變化的大量圖形單元,并且渲染系統輸出至顯示系統的信號需達到接近14K 的超高分辨率,不過在多機同步渲染與輸出機制下,圖形渲染系統的功能需求基于主流的實時渲染技術即可實現。
演員定位系統是《雪花》互動視效實現平臺的設計重點。《雪花》的舞臺區域超過1萬平米,500名演員從舞臺南、北兩側上場后,他們的表演幾乎涉及整個舞臺區域。互動娛樂領域常見的定位設備無法直接滿足本節目的技術需求,因而需要整合相關技術研發面向本次大型演出的演員定位系統,這也是本文的主要研究內容。
5 演員定位系統的功能需求分析
演員定位系統的主要功能是測定演員在表演區域的位置。《雪花》的演員僅在平整的LED 地磚屏上表演,且互動效果也僅在LED 地磚屏上顯示,因此,實現演員在LED 平面上的二維定位即可滿足需求。
從測量設備的類型上劃分,互動娛樂領域的二維定位技術主要有基于紅外或壓力傳感器、基于電磁波收發設備、基于激光雷達、基于相機的幾類方案,而根據《雪花》的演出環境與功能需求,一些技術并不適用。首先,在進行 《雪花》的互動視效制作時,LED 地磚屏已經搭建完成,無法改為LED內嵌紅外或壓力傳感器的方案,且該方案的成本也較高。其次,諸如GPS、UWB (UltraWideBand,超寬帶)等基于電磁波的定位技術因需要演員穿戴設備而不優先考慮,并且這些技術在本節目的表演區域很難實現每秒15次以上的連續測定,較差的定位實時性將會影響節目效果呈現。再者,由于表演人數較多,使用二維激光雷達 (業內稱為LiDAR)掃描表演區域的方案無法較好的解決演員之間的相互遮擋問題,并且工業激光雷達的探測距離有限,針對超過1萬平米的表演區域并沒有理想的安裝位置。
綜合上述分析,《雪花》的演員定位系統可以使用一種基于相機的定位方案,定位系統連續測定并輸出演員站立點的位置坐標,位置的測量頻率與測定精度應不影響節目效果的呈現。
6 演員定位系統的設計思路
6.1 基于相機的定位技術分析
基于相機的定位技術在互動娛樂領域已有較長的應用歷史,其定位原理主要是依據被測目標在相機拍攝圖像中的位置來推算目標在實際空間中的位置。相機設備本身并不包含探測與定位機制,它僅輸出反映畫面光學特征的圖像。基于相機拍攝的圖像或視頻數據進行目標定位需要借助相機標定機制確定圖像與實際空間的坐標對應關系,之后借助圖像處理算法確定目標 (像素)在完整圖像中的位置坐標,從而推算出目標在實際空間中的坐標。
6.1.1 相機標定
工程測量與計算機視覺領域的相機標定是一個求解相機特定參數的過程,這組特定參數可用于計算相機所拍攝空間中的某一點與圖像中某一點的對應關系。
相機標定的技術方案通常根據實際需求來選擇。使用常規數字相機實現目標在平面上的二維定位時,常用的方式是在被探測平面上放置或顯示明顯的標志物,這些標志物在平面上的二維坐標是已知的,當相機拍攝到標志物時,即可確定標志物所在像素與實際平面二維坐標之間的關系。常規數字相機輸出的單幀圖像是一個以像素為單位的二維矩陣,并且可認為像素的排列與間距是規則的,但相機的成像光軸與被探測平面并不一定絕對垂直,并且相機鏡頭的成像也會有一定程度的畸變,因此從理論上講,實現精確定位需要通過標志物測定出圖像中所有像素與空間坐標點的對應關系。不過根據定位的精度需求,可以認為像素與空間坐標在一定范圍內存在可計算的對應關系,因此對多個坐標已知的標志物進行逐個測定,建立相機模型及參數,經過推算即可得到圖像中任意像素所對應的實際二維坐標。

圖3 相機標定的概念
6.1.2 區分目標圖像
在大部分基于相機的定位方案中,確定目標位置需要將目標(的圖像)從完整的單幀圖像中區分出來。一些常見的目標圖像區分方案如下。
(1)基于紅外光強度區分目標圖像
借助紅外相機直接區分目標的方案在互動娛樂領域較為常見。紅外相機拍攝的畫面主要反映物體的紅外輻射強度,如果被探測區域中的目標發出明顯強于其他物體的紅外光,則可利用紅外光的強度對比來實現目標與背景的分離。
(2)基于深度信息區分目標圖像
深度相機泛指帶有深度測量系統的一類視頻相機,這類相機能依靠深度測量系統得到所拍攝圖像中各區域與相機之間的距離值。如果目標與相機的距離相比畫面中其它元素到相機的距離有所不同,則可以借助深度信息將畫面中的目標對象區分出來。目前常見的深度測量系統基于紅外光散斑來推算深度值,這類技術受環境光影響較大,深度的有效測量距離通常在十幾米以內,因而采用這類技術的Kinect、RealSense等相機主要用于小范圍的室內娛樂系統。另一方面,使用激光雷達輔助相機獲取深度數據也是一個技術方案,不過這類系統目前成本較高,并且分辨率有限。
(3)基于目標檢測算法區分目標圖像
在計算機視覺領域,目標檢測是一種在數字化圖片或視頻中檢測特定物體的技術,而人工智能概念的興起讓目標檢測技術更加關注如何在常規圖像(而不是帶有紅外強度或深度信息的圖像)中檢測某一類語義對象,比如人、貓或者車。簡單的說,目標檢測技術可以讓計算機像人一樣把圖像中的各類對象“圈”出來,實現了從完整圖像中區分出某類目標圖像的需求。
6.2 計算機視覺領域的目標檢測
計算機視覺的廣義研究目標在于令計算機程序能夠“理解”數字化的圖像內容,而這個 “理解”可分為多個不同的層次。最初級的層次是判斷圖像中出現了哪些類別的物體,這里的類別通常是泛化的語義對象,例如人、狗、羊等,因此也被稱為“分類 (Classification)”。更高層次的 “理解”則是在“分類”的基礎上,檢測出圖像里的每個物體,獲得其類別與位置,也就是令計算機看懂圖像中“在哪里,有什么”,這一處理在計算機視覺領域被稱為目標檢測 (Object Detection)。目標檢測又為其它更高級的算法提供了基礎,例如將目標從背景中精確分割,或是對特定目標進行追蹤等。
一般來說,目標檢測的實現主要基于對圖像視覺特征的提取,例如形狀、紋理、顏色等,再依據這些特征對物體進行識別。在傳統的圖像算法中,用于識別的視覺特征往往是預先設計的一般性特征,例如方向梯度直方圖 (Histogram of Oriented Gradients,HOG)算法。這類算法僅需要少量計算資源就能夠實現檢測,但是由于使用了固定的特征以及比較簡單的分類算法,能夠實現的檢測精度與類別都比較有限。

圖4 計算機視覺的研究目標

圖5 使用卷積神經網絡進行目標檢測[1]
為計算機視覺領域帶來跨時代變化的是近年來迅速發展的卷積神經網絡 (Convolutional Neural Network,簡寫為CNN)算法。不同于傳統算法,卷積神經網絡利用多層卷積核 (Convolution Kernel)函數對圖像特征進行提取,通過改變卷積核的大小、權重,可以實現各種不同視覺特征的提取,并形成多個特征圖 (Feature Map)。特征圖的特征可以繼續被卷積核提取,直到分析出對應于各種不同目標圖像的高級特征,利用這些高級特征進行檢測,能夠實現遠超傳統算法的檢測準確度。
使用卷積神經網絡實現高精度目標檢測的關鍵在于確定各個卷積層中的卷積核參數,而這要依賴對卷積神經網絡進行的大規模訓練。卷積神經網絡的訓練是借助大量經過標注的圖片來進行的。這里的標注是指以人工方式將圖片中的目標對象標記出來(比如用邊界框分割出目標對象)。使用標注過的圖片數據去訓練網絡,即能逐漸調整出理想的卷積核參數,最終讓神經網絡能夠把目標從未經標注的圖片中區分出來。卷積神經網絡通常需要用大量的已標注圖片去訓練才能達到理想的檢測準確度,不過業內已經有開放下載的訓練集 (已經標注好的圖片數據),并且對于一些常見對象(比如人、車)的檢測,可以通過下載權重文件直接得到一個訓練好的網絡模型。當然,如果需要針對特定目標提高檢測的準確度,就需要專門標注帶有特定目標的圖片,并對神經網絡進行訓練。
基于卷積神經網絡的目標檢測算法并不唯一。一些檢測精度較高的算法(例如FastR-CNN 算法)在完成分類任務后需要通過第二個獨立階段進行位置探測,因而相對耗時,而YOLO、SSD 等算法則采用僅通過一個階段的網絡運算同時完成分類和檢測任務的策略,以犧牲一定檢測精度為代價,做到了檢測效率的有效提升。
6.3 使用目標檢測算法實現演員定位
基于相機的定位方案通常需要目標被清晰拍攝,《雪花》的演員人數多且表演區域廣,因此在高處架設相機能夠盡量避免畫面中出現演員相互遮擋的情況,但這也意味著相機與演員之間的距離較遠,加之國家體育場的結構與演出安全要求,可選的相機架設位置與舞臺中心的距離在100米以上,這超出了常規深度相機的作用范圍,也無法較好地使用主動式紅外探測。另一方面,需要定位的500名演員在表演時穿著一致,人形輪廓清晰,舞臺的燈光環境與互動視覺內容也會在排練過程中確定下來,上述條件為使用目標檢測算法實現演員圖像的識別與定位提供了可行性。
目標檢測算法的檢測速度將直接決定演員定位系統的處理時間,單幀圖像處理時間較長不僅會降低定位系統的測量頻率,也會增加互動視效實現平臺的系統延遲。較低的測量頻率會影響互動視效的流暢度,而較大的系統延遲則會導致演員快速移動時出現視覺效果明顯滯后于演員站立位置的現象,讓實時互動的概念無法成立。因此,在保證一定識別精度的條件下,演員定位系統應優先選擇檢測速度較快的算法,盡可能縮減系統延遲。
綜合上述分析,《雪花》的演員定位系統設計思路如下:使用多臺相機組成拍攝視角覆蓋完整表演區域的采集系統,對表演過程進行連續的圖像采集,再借助計算機視覺領域的目標檢測算法得到每個演員在單幀圖像中的位置,最后基于相機標定的結果,推算出演員在實際表演區域中的位置。使用檢測速度較快的目標檢測算法確保單幀定位處理能在合理時間內完成,使用算法連續處理相機輸出的單幀圖像序列,即能對演員進行連續定位,滿足演員定位系統的功能需求。
7 基于目標檢測的互動視覺效果制作方案在《雪花》中的應用情況
基于目標檢測的演員定位系統與圖形渲染系統、視效顯示系統構成了《雪花》的互動視效實現平臺,加上面向該平臺開發的互動視效程序,形成了完整的互動視覺效果制作方案,見圖6,這里對演員定位系統的系統構成做簡要說明。
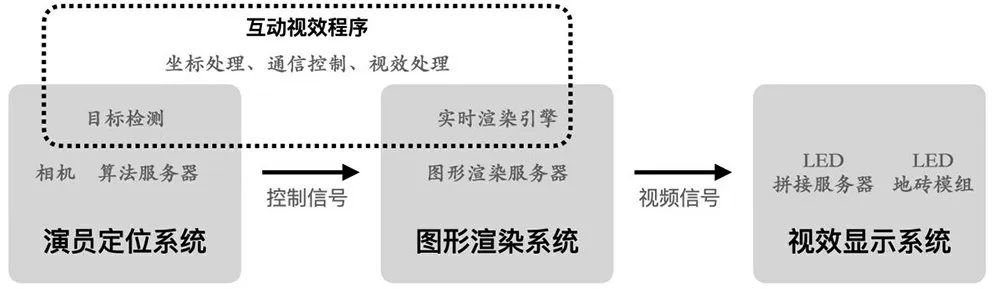
圖6 《雪花》的互動視效制作方案
7.1 《雪花》的演員定位系統構成
《雪花》的演員定位系統可以分為圖像采集設備、定位算法服務器以及目標定位程序、坐標處理程序幾個主要單元。下文對其中關鍵技術指標進行說明。
7.1.1 圖像采集設備與定位算法服務器
基于對表演區域與演出環境的調研數據,圖像采集設備由國家體育場六層觀眾席最高處架設的4臺1.1英寸傳感器工業相機 (含專業鏡頭)組成。每臺相機負責場地約1/4區域,以4K 分辨率、60幀/秒的參數運行。為了避免場內低溫對相機性能造成影響,相機覆蓋了專用保暖套,見圖7。

圖7 相機架設位置
定位算法服務器包含5臺獨立的機架式服務器,其中4臺執行目標定位程序,另1臺執行坐標處理程序。定位算法服務器使用雙至強32核心處理器,鎖頻2.6GHz時執行目標檢測算法的單幀處理時間在30ms以內,從相機拍攝到定位處理完成的平均耗時為60ms,可達到預期效果。

圖8 定位算法服務器
演員定位系統選擇的工業相機支持以SPF+光纜接口的萬兆以太網直接發送視頻數據。4臺相機與執行目標定位程序的4臺服務器通過光口以太網交換機組成網絡。在服務器端,Linux系統配合相機廠商提供的SDK 可以直接獲取RGB 格式的無壓縮圖像數據。
演出系統的可靠性極為重要。《雪花》的演員定位系統采用了雙系統備份方案,兩套系統使用完全一致的“4相機+5服務器”硬件配置,各自獨立運行,持續發送定位數據。而后端的圖形渲染系統能夠同時接收來自兩套定位系統的數據,并根據設置實時切換或者混合使用兩套系統的定位數據,實現了演員定位系統的熱備份。
7.1.2 目標定位程序
目標定位程序基于卷積神經網絡中檢測速度較高的YOLO 算法進行目標檢測。借助節目排練時采集的圖片數據對神經網絡進行訓練后,圖像中的演員會以邊界框(Bounding Box)的形式被框選出來,將邊界框底邊的幾何中心點作為演員站立位置的參考點,再結合預先輸入程序的相機標定參數,即可得出演員在實際舞臺平面的位置坐標。
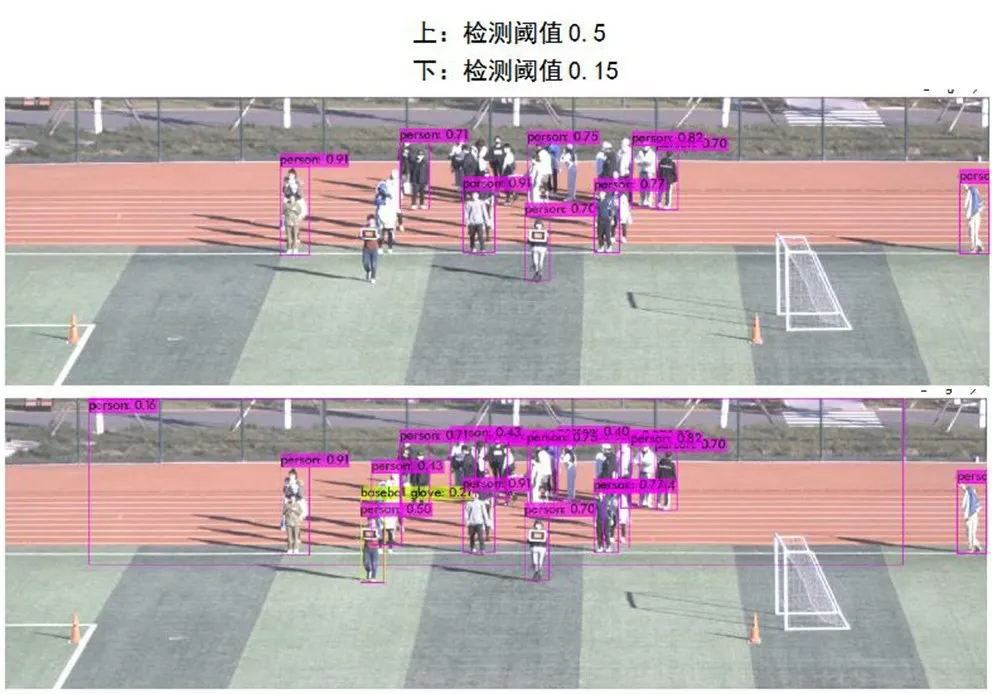
圖9 使用YOLO 進行的定位測試
YOLO 算法實現快速檢測的核心機制在于預先將輸入圖像用二維網格劃分成若干個格子,每個格子根據卷積網絡提取的特征直接進行物體的類別與位置預測,一次性完成分類和檢測任務。使用YOLO 算法有以下參數可以根據被檢測目標的特點進行調整。
(1)YOLO 的網格分辨率。YOLO 算法會對圖像進行網格劃分,通過提高網格的分辨率,可以提升對較小目標的檢測效果,但這種操作會增加運算耗能,影響檢測速度。
(2)每個格子內負責進行位置預測的錨框(Anchor Box)數量以及大小。該參數可以根據訓練時的數據集進行設定,從而使算法更好地適應特定的檢測目標。
(3)檢測閾值。其代表算法在對預測結果有多高把握時即認為該預測有效。通過降低閾值,可以令算法輸出更多的預測框,在有大量對象需要檢測時可以提升檢測率,但也會增加誤檢可能性。
7.1.3 坐標處理程序
目標定位程序的輸出結果是每位演員站立位置的平面坐標,由于完整表演區域被分為四個區域獨立檢測 (如圖10),且區域之間有交疊部分,因此開發了坐標處理程序用以匯總來自四個目標定位程序的坐標值,并過濾掉因區域交疊產生的冗余坐標。此外為了優化互動視覺效果,程序使用濾波算法對坐標連續變化的軌跡進行了平滑處理,并設計了一些輔助性的參數,從而構成完整的定位數據。
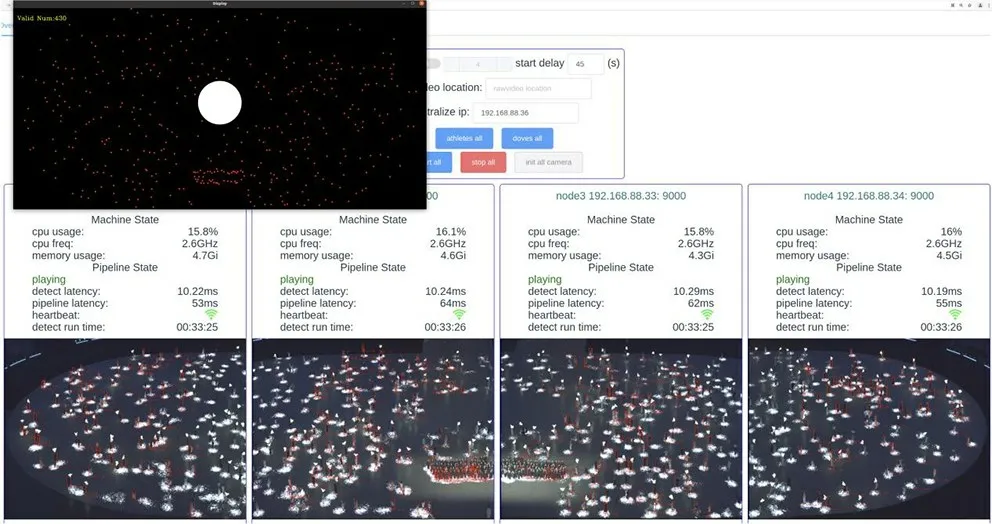
圖10 定位處理程序監控界面
坐標處理程序以UDP 數據包形式發送完整表演區域的演員定位數據至后端的圖形渲染系統。依據前期對目標定位程序單幀處理時間的測試結果,定位處理程序的數據包發送頻率定為30次/秒,采用定長數據包方案。
7.1.4 相機標定操作
表演區域平整鋪設的LED 地磚屏具有非常有利于的標定條件。實際操作中,在LED 地磚屏上顯示一個棋盤狀黑白相間的網格圖,并設置每個方格為同等的邊長(圖11)。通過實地測量獲得LED 所顯示每個方格邊長的物理尺寸后,選擇LED 地磚屏的一點作為坐標原點,可以構建出基于LED 地磚屏的平面坐標系,由于地磚屏上每個方格的長度是已知的,因此格與格的每個交界點都可以作為標定操作的標志點。在整個表演區域等間距選擇80個標志點進行標定時,經過實際測量驗證,演員定位的誤差不超過15cm,能夠滿足呈現效果需求。

圖11 表演區域的標定操作
7.2 《雪花》的互動視覺效果實現情況
《雪花》的互動視覺效果制作方案在節目排練過程中進行了多次測試與調整,包括相機的分布、相機分辨率、曝光參數、對卷積神經網絡的訓練、目標檢測算法的檢測閾值測定、單幀畫面平均處理時間測定,以及互動視效程序中通信控制機制、視效觸發與渲染機制的調整,最終在開幕式前的彩排和開幕式正式演出中實現了預期目標,為全世界觀眾呈現了精彩的互動視覺特效。
在前期測試中,YOLO 目標檢測算法的漏檢一直是定位系統的主要問題。盡管項目使用最接近正式演出環境的排練數據對神經網絡進行了 “訓練”,但因節目轉播效果需要,現場燈光無法達到目標檢測的理想條件,演員著裝后無法較好的和背景進行區分,在檢測閾值降低到一定程度時,依然會出現演員漏檢的情況。此外,YOLO 算法對小尺寸目標的識別效果較差,當目標較密集的聚集在一起時,發生漏檢的幾率會明顯增加。因此在表演過程中,當幾名小演員站立位置過近、相互遮擋或者和平鴿道具擋住演員頭部時,演員定位系統都會大概率出現定位丟失現象。不過,上述情況針對單個演員而言并不會持續頻繁出現,因此在對互動視覺效果的觸發機制與渲染算法調整后,漏檢問題已經不會影響到互動效果的觀賞體驗。
8 總結
計算機視覺領域的目標檢測算法為互動視覺效果制作中的演員定位問題提供了新的解決方案。基于目標檢測的定位系統無需演員穿戴設備,使用單臺高性能服務器配合常規相機即能實現定位,而使用高分辨率、高幀率的專業相機時,其定位精度與速度能夠滿足大型演出的實時互動視效需求。相信隨著計算機視覺領域人臉識別、骨骼追蹤、三維姿態預測等技術的持續發展,演出領域的互動視覺效果將迎來全新的制作方式。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
