基于RoBerta-BiLstm-Attention模型的機(jī)器生成新聞檢測
2022-04-22 11:19:26徐宇,楊頻
現(xiàn)代計算機(jī) 2022年3期
徐 宇,楊 頻
(四川大學(xué)網(wǎng)絡(luò)空間安全學(xué)院,成都 610065)
0 引言
隨著深度學(xué)習(xí)技術(shù)的快速發(fā)展,NLP的研究取得了長足的進(jìn)步,GPT2、Ctrl、Bert和RoBerta等預(yù)訓(xùn)練語言模型得到了廣泛的應(yīng)用。在文本生成的研究中,逐步將預(yù)訓(xùn)練語言模型融入其中。現(xiàn)在預(yù)訓(xùn)練模型生成的文本已經(jīng)可以做到與人工撰寫的文本極其相似,甚至可以生成邏輯清晰的新聞報導(dǎo),這有利于新聞的快速生成和及時傳播。同時,惡意攻擊者也可能采用同樣的技術(shù)生成具有攻擊性的虛假新聞報道,以實(shí)現(xiàn)網(wǎng)絡(luò)輿情的控制。為了防止文本生成的預(yù)訓(xùn)練模型用于網(wǎng)絡(luò)媒體攻擊,機(jī)器生成新聞的檢測是必不可少的。
現(xiàn)在人工檢測機(jī)器生成新聞無論是從費(fèi)用還是時間來說都是十分昂貴。通過自動機(jī)器生成新聞的檢測,可以減少人工檢測的壓力同時也可以提高檢測機(jī)器生成新聞的效率和準(zhǔn)確率。
1 相關(guān)研究
文本生成語言模型和算法在近幾年的快速發(fā)展,基于GAN和VAE的算法不斷改進(jìn)用于文本生成,比如SeqGAN、LeakGAN,以及基于transformer的大型預(yù)訓(xùn)練語言模型已經(jīng)能夠生成效果很好的文本,甚至生成邏輯清晰的新聞報導(dǎo),比如Grover稱已經(jīng)能夠生成比人工虛假新聞更加可信的假新聞。
機(jī)器文本生成檢測模型已經(jīng)發(fā)展了很多年,早期研究人員主要針對的是無人工校對的機(jī)器翻譯文本以及使用同義詞或者混淆技術(shù)生成的文本。使用的方法都是基于傳統(tǒng)機(jī)器學(xué)習(xí),分析機(jī)器文本和自然文本之前不同的特征。比如詞頻計數(shù),通過機(jī)器文本與自然文本之間的詞分布進(jìn)行檢測;語言特征通過虛詞密度、語句長度等語言特征進(jìn)行檢測;短語分析通過短語沙拉現(xiàn)象對機(jī)器翻譯文本的檢測。
但是近兩年大型語言模型日益強(qiáng)大,機(jī)器生成的文本越來越逼真,導(dǎo)致研究人員對于其檢測有了很多不同想法。Gehrmann很精確的找到了GPT2模型根據(jù)前面單詞預(yù)測下一個詞的特點(diǎn)。采用統(tǒng)計學(xué)的方法將文章中的每個單詞的topK概率進(jìn)行標(biāo)注統(tǒng)計來協(xié)助專業(yè)人員檢測機(jī)器生成新聞。但它的檢測準(zhǔn)確率可能會受到生成模型解碼策略和生成模型訓(xùn)練樣本來源的影響。這在Ippolito的實(shí)驗(yàn)中得到了很好的證明。當(dāng)檢測的自然文本與訓(xùn)練生成模型的文本來自同一分布時,Gehrmann提出的方法檢測準(zhǔn)確率就接近于隨機(jī)概率。Ippolito主要的方法是微調(diào)的Bert對生成文本進(jìn)行檢測,在通過核采樣生成的文本下實(shí)驗(yàn)準(zhǔn)確率從接近隨機(jī)的55%增加到大約81%。對于解碼策略的影響,Holtzman分析了人工撰寫文本和機(jī)器文本分布的差異,并指出傳統(tǒng)解碼方式的會出現(xiàn)不連貫和陷入重復(fù)循環(huán)。為了解決這個問題他們提出了核采樣(topP)的解碼方式。但是我們的實(shí)驗(yàn)結(jié)果中表明在長文本的生成過程中表達(dá)不連貫并沒有得到很好的解決。
目前一些研究人員認(rèn)為檢測機(jī)器生成文本最好的方法是文本生成模型自身,比如GROVER通過生成模型對自身生成的新聞進(jìn)行檢測并和微調(diào)的Bert-large模型進(jìn)行對比,得出了單向transformer模型精確度高于雙向trans?former模型精確度的結(jié)論。但是Solaiman等人認(rèn)為同等大小的雙向transformer模型比單向的transformer模型檢測的準(zhǔn)確率更高,并通過微調(diào)的RoBerta模型對不同解碼策略的生成文本進(jìn)行實(shí)驗(yàn),得出了不同的結(jié)論并發(fā)現(xiàn)核采樣(topP)的生成文本更難以檢測。
2 檢測模型
本文提出一種基于RoBerta-BiLstm-Attention的機(jī)器生成新聞的檢測模型,如圖1所示。
RoBerta相對于Bert做了一些調(diào)整。將Bert的靜態(tài)masking調(diào)整為動態(tài)masking,直到每一次將訓(xùn)練樣本輸入到模型時,才進(jìn)行隨機(jī)的掩碼。將Bert的wordpiece分詞算法調(diào)整為BPE算法,從相鄰子詞中選取頻數(shù)最高的兩個子詞合并。使用更多的數(shù)據(jù)和更大的批次訓(xùn)練,可以更好的提高詞嵌入的質(zhì)量,有利于我們提取出高質(zhì)量的語義信息。我們將輸入樣本前后都加入了[cls]和[seq]兩個特殊的標(biāo)志,如圖1所示。
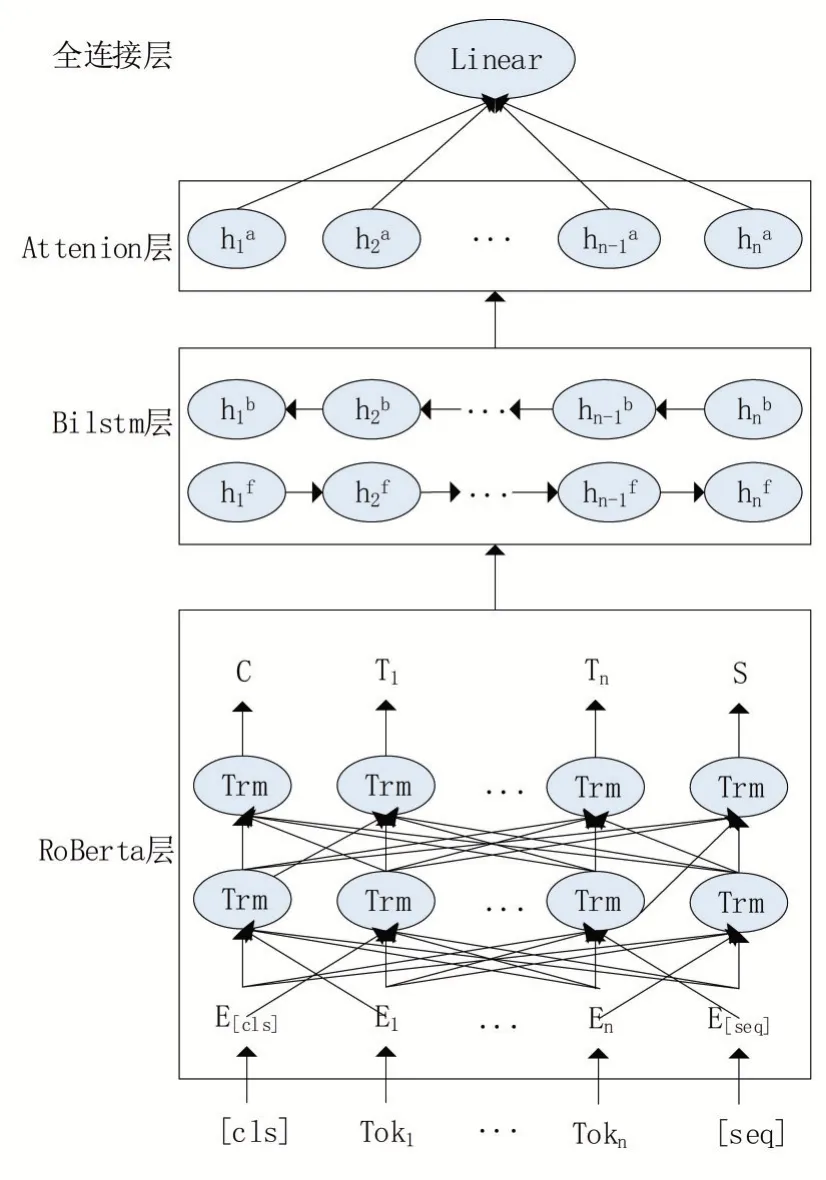
圖1 RoBerta-BiLstm-Attention模型結(jié)構(gòu)
BiLstm層中包含了一個前向Lstm和一個后向的Lstm,分別用于學(xué)習(xí)RoBerta詞嵌入后的上下文信息。Lstm通過遺忘門、記憶門和輸入門計算隱藏信息。在時刻,遺忘門和記憶門計算公式如下:
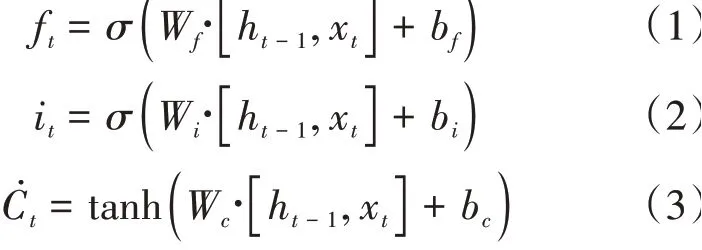
h是前一時刻的隱藏狀態(tài),x是當(dāng)前時刻輸入的詞嵌入信息,輸入是遺忘門的值f,記憶門的值是i,臨時結(jié)點(diǎn)狀態(tài)值?。再計算當(dāng)前時刻結(jié)點(diǎn)狀態(tài)信息。計算公式如下:
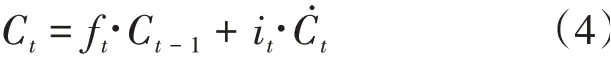
其中f是遺忘門,i是記憶門,?是臨時結(jié)點(diǎn)狀態(tài),C是上一時刻的結(jié)點(diǎn)狀態(tài)信息。最后計算當(dāng)前時刻的隱藏信息,計算公式如下:
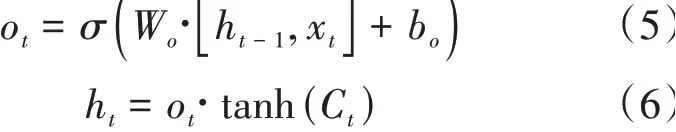

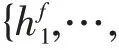
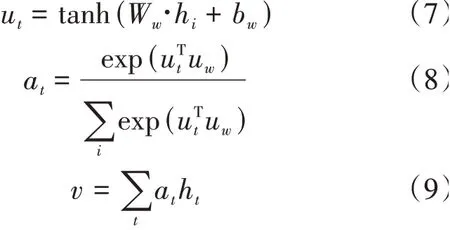
3 實(shí)驗(yàn)及分析
3.1 數(shù)據(jù)集
由于缺乏公開可用的機(jī)器生成新聞數(shù)據(jù)集,我們爬取了CNN、ROUTER和BBC的200M的新聞數(shù)據(jù)集對GPT2-large預(yù)訓(xùn)練模型進(jìn)行了微調(diào)來生成新聞數(shù)據(jù)集FakeNews。生成模型中我們分別采用了topK=40結(jié)合topP=0.96以及topP=0.96解碼方式生成新聞,生成新聞中各選取了32000條。為了讓生成新聞與真實(shí)新聞滿足同一分布,我們按照1∶1的比例在訓(xùn)練GPT2-large的語料中選取了真實(shí)新聞文本。本文使用了3∶1∶1的比例劃分訓(xùn)練集、驗(yàn)證集和測試集,如表1所示。
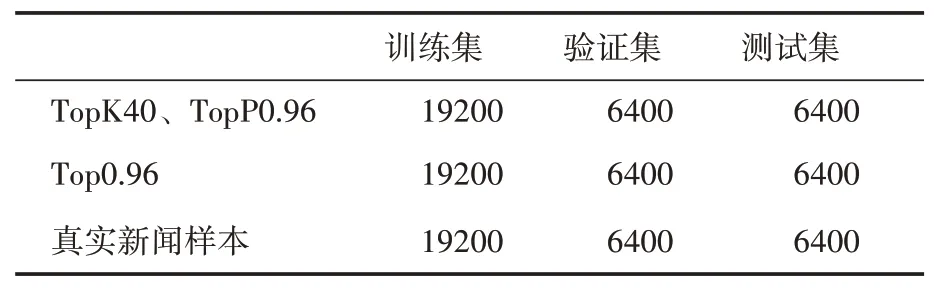
表1 機(jī)器生成新聞數(shù)據(jù)集的劃分
3.2 對比實(shí)驗(yàn)
我們使用的主要方法是RoBerta-BiLstm-Attention,并在兩個不同解碼方式生成的數(shù)據(jù)集上進(jìn)行了測試。每一篇新聞的最大長度是510,我們將RoBerta-BiLstm-Attention與其他一些基線分類模型進(jìn)行了對比。
RoBerta-BiLstm將RoBerta獲取新聞的詞向量結(jié)果,同時輸入到Bilstm網(wǎng)絡(luò)中,最后的結(jié)果獲取前向最后結(jié)點(diǎn)和反向第一個結(jié)點(diǎn)的隱藏狀態(tài)拼接值,輸入線性層得到最后的預(yù)測結(jié)果。
Fine-tuned RoBerta將RoBerta-base模型進(jìn)行了微調(diào),模型同樣被訓(xùn)練了10個epoch,batchsize設(shè)置為32。
Bert-BiLstm-attention將roberta模型換成了bert進(jìn)行了實(shí)驗(yàn)測試,參數(shù)設(shè)置和RoBerta-Bilstm-attention模型完全一致。
BiLstm將新聞數(shù)據(jù)集使用scapy進(jìn)行分詞詞嵌入(維度300),訓(xùn)練了一個基于BiLstm的二分類模型。
對比實(shí)驗(yàn)還做了常用分類算法FastText、TextCnn和TextRnn。
3.3 實(shí)驗(yàn)分析
本文以廣泛使用的準(zhǔn)確率(Accuracy,)、召回率(Recall,)和1值(F-score)作為評價標(biāo)準(zhǔn)。準(zhǔn)確率是正確預(yù)測的新聞數(shù)量與所有新聞數(shù)量的比值;召回率是機(jī)器生成新聞中被預(yù)測為機(jī)器生成新聞的比例;1值是指精確率和召回率的調(diào)和平均數(shù)。實(shí)驗(yàn)結(jié)果如表2和表3所示。與傳統(tǒng)的深度學(xué)習(xí)算法相比,RoBerta-BiLstm-Attention在解碼策略是核采樣(top)時準(zhǔn)確率、1值和召回率都提高了13%以上。同時傳統(tǒng)的深度學(xué)習(xí)算法受識別序列的長度影響很明顯,當(dāng)解碼策略是核采樣(topP)時且長度減少到125時,檢測的準(zhǔn)確率和1值不到80%,但是RoBerta-BiLstm-attention準(zhǔn)確率和1值都在95%左右。
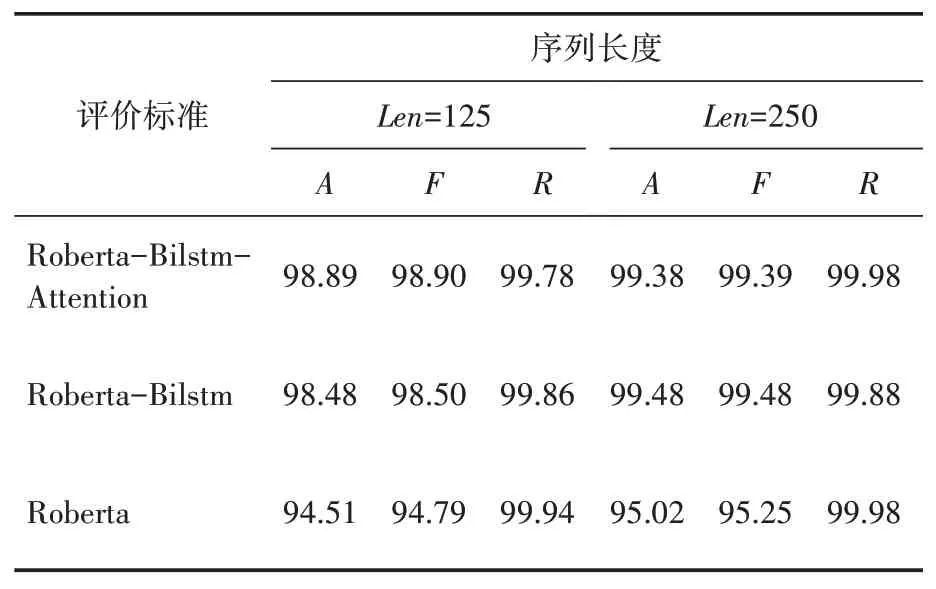
表2 top K生成新聞實(shí)驗(yàn)結(jié)果(A是準(zhǔn)確率、F是F1值、R是召回率)/(%)
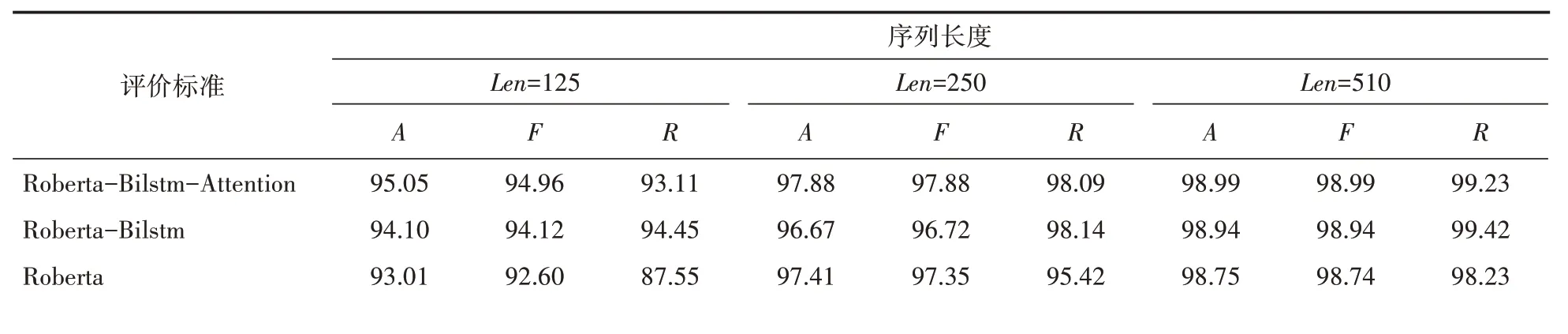
表3 核采樣生成新聞實(shí)驗(yàn)結(jié)果(A是準(zhǔn)確率、F是F1值、R是召回率)/(%)
與同類型深度學(xué)習(xí)模型相比,在序列長度為510和250時,我們發(fā)現(xiàn)RoBerta-BiLstm-Attention框架的提升不明顯,在topK生成的樣本下存在輕微劣勢。于是我們對于機(jī)器生成新聞進(jìn)行了人工分析,發(fā)現(xiàn)GPT2-large在生成序列過長的新聞時,會出現(xiàn)一些很明顯的特征。比如前后文主題性出現(xiàn)偏差、有重復(fù)的語句以及一些比較明顯的語法錯誤。這些錯誤很容被捕捉,所以模型的提升不會很明顯。如圖2所示。

圖2 語句重復(fù)和前后語義偏差
在序列長度為125時,GPT2-large生成新聞的錯誤更加難以捕捉,所以檢測的準(zhǔn)確率、1值等會出現(xiàn)下降趨勢。但是Roberta-Blistm-Attention相比于目前最強(qiáng)大的Roberta,在top生成的樣本下1值和準(zhǔn)確率都提升了近2%,召回率提升了5.56%。在top生成的樣本下1值和準(zhǔn)確率都提升了4%以上。如圖3所示。

圖3 機(jī)器生成新聞的檢測準(zhǔn)確率(%)
為了驗(yàn)證Attention機(jī)制對機(jī)器生成新聞檢測性能的提升.我們對比了未引入Attention層的RoBerta-BiLstm模型和引入了Attention層的RoBerta-BiLstm-Attention模型的檢測效果。在加入了Attention機(jī)制、解碼策略為topP和序列長度為125時,模型的準(zhǔn)確率和1值分別提升了0.95%、0.84%。在序列長度為250時,模型的準(zhǔn)確率和1值分別提升了1.21%,1.16%。實(shí)驗(yàn)結(jié)果表明,引入了attention后模型的檢測性能都得到了提升。
為了驗(yàn)證RoBerta對于識別機(jī)器生成新聞性能的提升,對比了使用同等規(guī)模大小的Bert的識別效果。如圖4所示,無論序列長度為多少,在樣本采樣方式為topP時,加入Roberta層后,模型的準(zhǔn)確率、召回率和1值都提升了5%左右。實(shí)驗(yàn)結(jié)果表明,引入Roberta模型后能夠識別出更多的機(jī)器生成新聞。
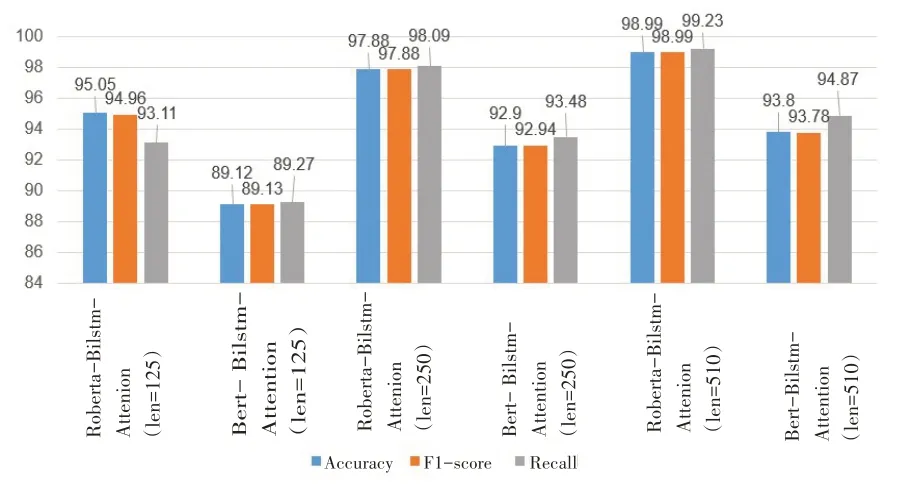
圖4 RoBerta-BiLstm-Attention和Bert-BiLstm-Attention數(shù)據(jù)對比(top P)
4 結(jié)語
本文針對目前可能存在濫用的機(jī)器生成新聞,提出了一種Roberta-BiLstm-attention模型,用于自動檢測機(jī)器生成新聞。區(qū)別于傳統(tǒng)的深度學(xué)習(xí)檢測方法,我們使用了Facebook最新的模型RoBerta做詞嵌入,能夠有效的消除歧義,提高詞嵌入的表達(dá)質(zhì)量。相比于同等類型的Bert,RoBerta的使用讓模型的各個指標(biāo)都得到了很高的提升。同時引入了BiLstm捕獲文本的前后向語義表達(dá)和注意力機(jī)制選擇性捕獲序列的關(guān)鍵信息,以提升機(jī)器生成新聞的檢測效果。實(shí)驗(yàn)結(jié)果表明目前大型語言模型生成文檔級文本時,仍然存在著很多不盡人意的表現(xiàn),這對于大規(guī)模濫用來說是一個很好的現(xiàn)象。但是對于NLP的文本生成的發(fā)展來說,仍然是一個難以解決的難題。同時我們提出的模型各個指標(biāo)都比目前的方法更高,但是模型的結(jié)構(gòu)也是越來越復(fù)雜。在未來的研究工作中,我們將進(jìn)一步簡化模型結(jié)構(gòu),提高模型的檢測質(zhì)量。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
