基于PSO優化的葉節點加權隨機森林算法
2022-04-24 09:15:22胡明祺張森昶
現代計算機 2022年4期
胡明祺,張森昶
(鄭州大學網絡空間安全學院,鄭州 450000)
0 引言
隨機森林(random forest)由加利福尼亞大學的Leo Breiman提出,后來經過YL Pavlov的改善, 提高了隨機森林算法的基本性能,并在研究和工業等各領域得到廣泛應用。傳統隨機森林算法的隨機性來自于兩個隨機化過程:一是從原始數據集中隨機生成若干訓練集,二是用來分支的最優特征屬性是從隨機生成的部分特征屬性中選擇的,最終其輸出結果為一個包含分類能力各不相同的決策樹的集合。由于傳統的隨機森林算法隨機程度高且對每棵決策樹的分類能力不做評估,因此極易出現同一集合中同時存在權重相同的、分類能力較強和較弱的決策樹分類器,使隨機森林的整體性能下降。這也導致傳統隨機森林算法準確度不高,易出現過擬合現象。
目前,對隨機森林中的決策樹加權以區分不同決策樹的投票性能成為提高隨機森林算法分類精度的一個研究方向。本文提出了一種基于PSO 優化的葉節點加權隨機森林算法,通過bagging 算法進行抽樣和特征選擇,并在每棵樹的葉節點上進行加權,從而賦予每個葉節點不同的投票權重,提高分類的精確度。此外,我們引入粒子群算法(PSO)對權重向量進行優化,使加權不再由人工設置,提高算法的科學性與合理性,在整體上改善了算法的性能。
1 相關工作
近年來,大量學者從各個方面對傳統隨機森林算法進行了許多優化。林楓等提出了用果蠅算法進行優化的隨機森林算法, 解決了傳統參數選擇方法存在主觀干擾性的問題, 該算法有利于較大數據集的提取,但無法作用于較小數據集且未對隨機森林算法的重要問題,即投票問題,進行優化。莊巧蕙對隨機森林算法的泛化能力進行提升,使其能夠參與實際應用,但是僅僅提高泛化能力會在某些情況下降低隨機森林算法的準確性。楊彪使用基于誤判率比較的二次訓練的方法對決策樹的葉結點進行加權,提高了隨機森林算法的性能,但在權重優化方面仍有提升的空間。
2 粒子群算法
自適應優化算法可以根據當前數據的處理特征,自動調整模型參數或處理辦法,以達到增強模型分類性能的目的。粒子群算法是一種性能較好的自適應優化算法。本文采用粒子群算法對隨機森林進行葉節點權重優化,使權重向量更加科學合理。
粒子群優化算法可以處理連續優化問題和組合優化問題。在傳統粒子群算法中,模型會初始化一群隨機解,將這些潛在的解稱作粒子,這些粒子通過跟蹤兩個極值來更新自己。


此時,每個粒子的優劣性可以由目標函數來得到,將第個粒子的“飛翔”速度記為
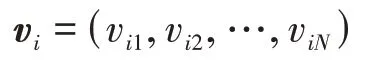
將第個粒子的個體極值記為
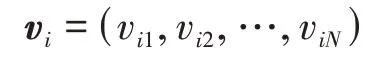
第個粒子的全局極值記為
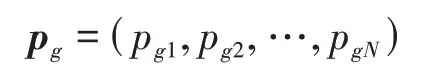
更新每個粒子為
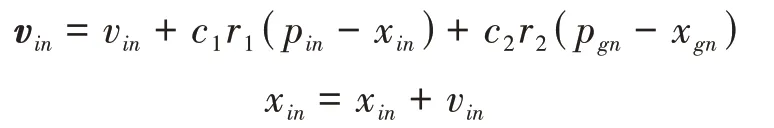
其中= 1,2,…,,= 1,2,…,;和為非負的常數;和是介于[ 0,1] 之間的隨機數。v∈[ -,];是常數。以上操作迭代進行直至滿足迭代終止條件。
3 加權的隨機森林算法
3.1 隨機森林算法
隨機森林是一個以若干決策樹為其基分類器的組合分類器,傳統的隨機森林算法主要由三步組成:①采用bootstrap抽樣的方法從原始數據集中隨機生成若干訓練集。②用各訓練集分別訓練決策樹,并不進行剪枝,其用來分支的最優特征屬性是從隨機生成的部分特征屬性中選擇的。③各個決策樹分類器的集合構成一片隨機森林,此隨機森林的模型輸出為:
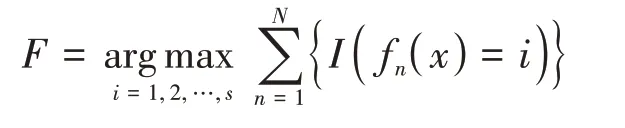
其中為測試集,為類別數,為隨機森林模型的規模,f()表示第棵決策樹的分類結果,(?)是一個判斷函數,當基分類器的輸出結果滿足條件時為1,不滿足時為0。
對于隨機森林中決策樹的生成算法,我們選擇CART決策樹算法,此算法遞歸地在每個內部節點處進行基于基尼指數的特征分割,最終生成一棵二叉樹。CART決策樹對特征值的選取及特征取值的數目有很好的適應性,因此被廣泛使用。
3.2 基于PSO優化的葉加權隨機森林算法
作為一種分類器的組合方法,隨機森林算法在訓練數據集選取和特征值選取時的隨機化可以有效避免決策樹易于過擬合的缺點,增強模型的泛化能力。但實際上,正是由于決策樹生成算法的兩個隨機化過程,各個決策樹甚至同一決策樹的每個葉節點的分類精度都有較大的差異。在傳統隨機森林模型中,每棵決策樹的投票權重都是相等的,這就導致一些性能較差的決策樹或葉節點的投票會影響整個隨機森林分類器的最終分類結果。因此,本文提出基于PSO 優化的葉加權隨機森林算法,對隨機森林中每棵決策樹的每片葉節點加以不同權值,并使用PSO 算法進行自適應優化,進而達到提高隨機森林分類器整體性能的目的。
此外,針對隨機森林分類器在某些噪聲較大的分類或回歸問題上會出現過擬合的問題,我們通過bagging 算法對特征集和訓練集進行特征選取,以此來訓練分類器,并提升算法在特征選取方面的準確性。在特征選取之后,我們為每個子葉隨機分配初始可信度,構成可信度向量,并使用PSO 算法對可信度向量進行優化,直至其性能達到預先設置的完成閾值。最后,我們記錄葉節點可信度向量,并將其作用于測試中最終得到的葉節點,以此來對子葉加權,最終采取投票法得出隨機森林的結果。
算法步驟如下:


其中為測試集,為類別數,為隨機森林模型的規模,f()表示第棵決策樹的分類結果,(?)是一個判斷函數,當基分類器的輸出結果滿足條件時為1,不滿足時為0。
4 實驗結果與分析
為了檢驗此算法的性能,我們使用標準UCI測試數據集對算法進行測試。選擇的數據集詳細信息如表1所示。

表1 數據集
為了測試算法的可靠性,我們在每一個數據集中加入30%的隨機噪聲,隨后用上述數據集對隨機森林算法和加權隨機森林算法分別進行了十折交叉驗證,以達到對比效果。測試結果如表2所示。

表2 分類精度
可以看出,相較于原本的隨機森林算法,PSO 優化的加權隨機森林算法在各數據集上的分類精度都有明顯的提升。通過對比可以發現,PSO 優化的加權隨機森林算法對于大數據集的適應性更好,性能提升度可達19.1%。
此外,為了測試PSO 優化過程對本算法分類精度的影響,我們嘗試改變PSO 算法的種群數量和最深迭代次數兩個參數,并進行了多次對比實驗,測試選用的數據集為Bank Marketing數據集。在Python 環境下測試的輸出結果如圖1所示。
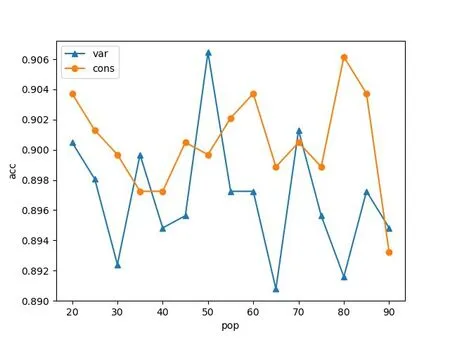
圖1 Python環境下測試的輸出結果
其中,var 表示最深迭代次數iter=60+2×pop 的情況;cons 表示iter=150 的情況。從實驗結果可以看出,pop 和iter 對PSO 性能并無明顯影響,PSO 優化的加權隨機森林算法有較好的適應性和穩定性。
5 結語
本文提出了一種基于PSO 優化的葉加權隨機森林算法。這種算法針對決策樹生成算法的兩個隨機化過程,對隨機森林中每棵決策樹的每片葉節點加以不同的權值,使各個葉節點的投票權重與其分類精度達到平衡。利用PSO 算法全局搜索能力強、收斂速度快的優勢,我們對葉節點權值進行優化,以此提高分類性能較強的葉節點的投票權重,降低分類性能較弱的葉節點的投票權重,有效避免決策樹易于過擬合的缺點,增強模型的泛化能力,進而達到提高隨機森林分類器整體性能的效果。
理論分析和實驗結果表明,基于PSO 優化的葉加權隨機森林算法是可行的。與傳統的隨機森林算法相比,該算法在分類精度及模型穩定性上都有明顯提升,且對于大數據集的適應性更好,性能可比傳統的隨機森林算法提升19.1%,有一定的研究和應用價值。
目前,本文算法在提高模型適應性方面還存在改進的空間,在降低算法時間復雜度方面仍需作進一步的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
