面向鐵路旅客服務應用的語音識別模型研究
2022-05-09 05:11:54王心雨
鐵路計算機應用 2022年4期
王心雨,景 輝
(1.中國鐵道科學研究院 研究生部,北京 100081;2.中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
人類主要依靠語言進行交流溝通,但在使用計算機時卻離不開雙手,通常使用鍵盤輸入計算機命令,或根據計算機提示進行點擊操作。隨著語音搜索服務及智能音箱產品的日漸成熟,與語音識別技術相關的智能車載、智能家居、智能客服等應用陸續走進大眾生活,促使人們使用計算機的操作方式發生轉變。例如在身份識別的應用方面,與指紋識別、虹膜識別等生物識別技術相比,語音識別技術無需記憶密碼,身份驗證過程更為快捷,一條簡短的語音指令即可代替以往的復雜操作,用戶易于接受,便于推廣應用。
在深度學習技術興起之前,語音識別技術主要采用隱馬爾可夫模型[1](HMM,Hidden Markov Model)和高斯混合模型[2]( GMM,Gaussian Mixed Model);其中,HMM 用于描述音頻信號的動態特性,GMM用于描述HMM每個狀態的靜態特性。這個時期因受技術所限,語音識別率提升緩慢,語音識別技術的發展一度停滯不前。隨著深度神經網絡[3](DNN,Deep Neural Network)的興起,語音識別技術框架逐漸由GMM-HMM轉變為DNN-HMM,以DNN模型替代GMM模型,無需假設語音數據的分布,即可獲得語音時序結構信息,使得狀態分類概率得以改善,語音識別準確率顯著提升。特別是在端到端(E2E,End-to-End)機器學習策略出現后,語音識別技術開始進入百花齊放時代,涌現出多種復雜的訓練網絡。其中,較為常用的E2E機器學習模型有:連接時序分類(CTC,Connectionist Temporal Classification)模型[4]、遞歸神經網絡傳感器 ( RNN-T,Recurrent Neural Network Transducer)模型[5]、LAS(Listen Attend and Spell)模型[6],T-T(Transformer-Transducer)模型[7]。與傳統語音識別模型不同,CTC模型不需要在訓練數據前對語音與標簽進行對齊處理,節省了訓練開銷, 但是CTC模型沒有考慮上下文之間的關系,生成的文本質量較差。RNN-T 模型是在CTC模型的基礎上加以改進,能夠支持流式語音識別,具有語言模型建模能力,主要用于輔助文本的生成, 解決了CTC模型生成文本質量差的問題。LAS模型利用注意力(Attention)機制實現有效的對齊,因其考慮了上下文信息,在準確度上會略高于其它模型,但正是因為它需要上下文信息,因而無法支持流式語音識別,且準確度會受到輸入語音長度的影響。T-T 模型是對RNN-T的改進,它將RNN-T中長短時記憶[8](LSTM, Long Short Term Memory)編碼器替換為Transformer[9]編碼器,Transformer是一種非循環的注意力機制,可以讓網絡執行并行計算,能夠支持流式語音識別。
近年來,我國鐵路運輸能力和服務水平持續提升,鐵路憑借其便捷性、舒適性和安全性,成為民眾出行首選的交通方式。目前,語音識別技術在鐵路領域主要應用于面向旅客的鐵路互聯網售票系統(簡稱:12306)智能客服,在站車交互、移動檢票、列車補票等業務中尚未廣泛應用。研究面向鐵路旅客服務應用的語音識別模型時,首先要選用合適的語音識別模型進行優化改進,使其達到較高的識別準確率,并針對特定的應用場景構造特定的鐵路領域訓練數據集,將其用于語音識別模型的訓練,以增強模型的鐵路領域特征;此外,目前的鐵路旅客服務涉及鐵路出行條例、旅客常問問題等眾多文本信息,為此,在語音識別模型的基礎上結合特定的文本處理機制,將進一步有效地提高具體應用的語音識別準確率。
本文研究提出一種改進的語音識別模型,借助RNN-T模型對于語音識別處理的優勢,用Conformer[10]結構替換RNN-T中的RNN結構,Conformer結構是以卷積增強的Transformer模型,Transformer能夠有效提取長序列依賴關系,而卷積擅長提取局部特征,Conformer結構可將兩者結合起來,以增強語音識別的效果;另外,在卷積模塊上加入注意力機制,發揮注意力機制參數少、速度快的優勢,且基于注意力機制的每一步計算不依賴于上一步的計算結果,可解決RNN不能并行計算的問題,還能從較長的文本信息中捕獲重要特征,解決長文本信息被弱化的問題。結合旅客常問問題查詢設備和車站智能服務機器人2個應用場景中的旅客服務功能,利用改進的語音識別模型完成定制化開發,使旅客可通過語音交互方式簡單、快捷、高效地獲取所需服務。
1 相關的網絡模型
1.1 CTC模型和RNN-T模型
CTC模型是一種可以把語音轉化文本的語音識別模型,只需要提供輸入的音頻序列和對應的輸出文本序列,就可以對CTC模型進行訓練,解決了傳統語音識別模型訓練時需要標簽對齊的問題。經CTC解碼后,每一幀都能生成對應的字詞,不需要進行后續的處理,因而CTC模型能夠很好地支持流式語音識別。
如圖1所示,CTC模型完成語音識別的音頻數據處理流程為:(1)將音頻數據均分成若干段,每段都匹配一個音節,生成預測序列,此處引入空白符用于分割音節(即圖1中表示為灰色框),空白符不對應任何輸入,后續會從輸出中將其刪除;(2)合并重復的音節,并去除空白符;(3)輸出對應的文本序列。
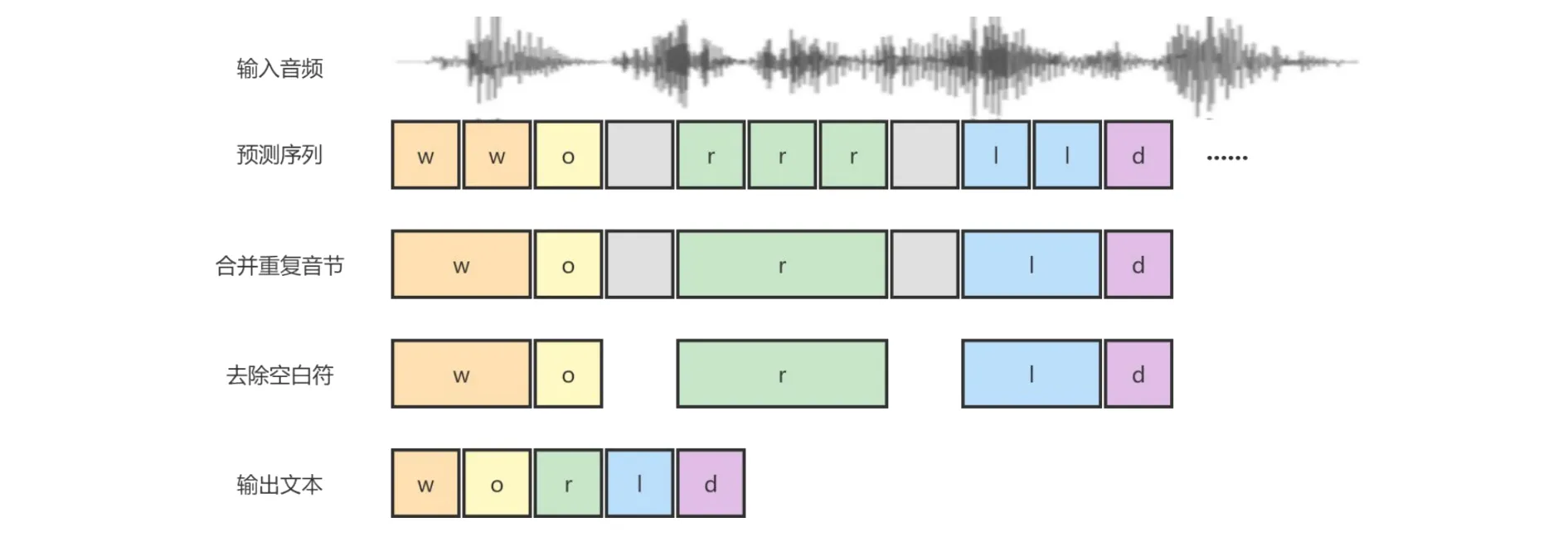
圖1 CTC模型處理流程
CTC模型的缺點是忽略了音頻序列間的前后依賴關系,即認為當前幀yu與 前序各幀yi(i<u)沒有任何聯系。由于語音信號是連續的,不僅各個音素、音節以及詞之間沒有明顯邊界,各個發音單位還會受到上下文的影響。因此,對語音信號進行建模時,需要考慮音頻序列間前后依賴關系,否則會對模型的識別準確率產生不良影響。
為解決這個問題,RNN-T模型對CTC模型進行了改進,在CTC模型的編碼器(Encoder)基礎上,加入了RNN結構,它將前面輸出的幀作為預測網絡(Prediction Network)的輸入,再將輸出的隱藏向量pu與由Encoder生成的聲音特征序列henc輸入到聯合網絡(Joint Network)中,經聯合網絡處理后得到輸出值zi, 再將zi傳遞到Softmax層,最終得到對應類的概率P(y?i|x1,···,xti,y0,···,yui-1),其結構如圖2所示。
RNN-T模型的特點是,可將預測網絡輸出的文本特征和語音信號的聲學特征較好地融合在一起,同時對兩者進行聯合優化,從而獲得較好的識別準確率。
1.2 Conformer模型
Conformer Encoder整體結構如圖3所示,每個Conformer 塊類似于一個三明治結構,前后用到2個Feed Forward Network(FFN)模塊,每個FFN模塊的輸出只取原輸出的一半。文獻[10]通過實驗驗證表明,與只取單個FFN結構的全部輸出相比,各取2個FFN結構的一半輸出,可使模型整體上表出更為優異的性能。
Conformer Encoder的計算公式為
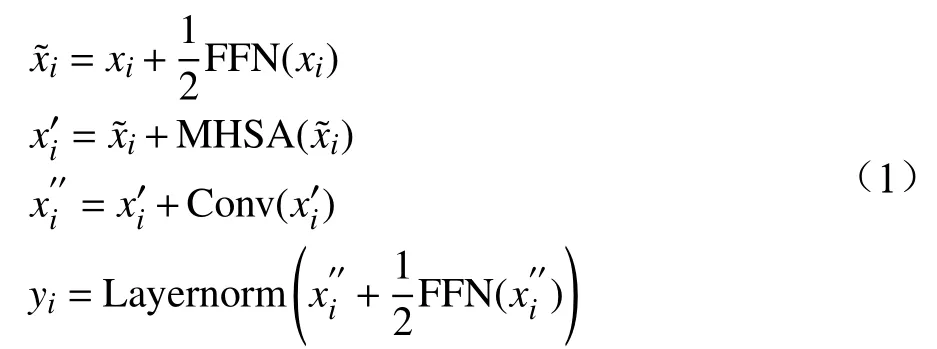
其中, F FN(x)、 M HSA(x)、 C onv(x)分別為FeedForward模塊、Multi-Head Self Attention模塊、Convolution模塊的計算結果,yi為這3個模塊經Layernorm規范化處理后的輸出結果。
2 語音識別模型改進
2.1 注意力機制
考慮到鐵路旅客服務應用場景,存在眾多長句表述的情況,且需要考慮上下文之間的聯系。Conformer結構中的卷積模塊在訓練中忽略了長句中的局部特征,且音頻信息本身也存在難以獲取局部與整體之間關聯性的缺陷,為此需要對卷積模塊做出改進。
原先的Conformer模型中的卷積模塊使用prenorm殘差、point-wise卷積和線性門單元(GLU,Gated Linear Unit)。為了解決難以將長語音序列合理表示為對應特征向量的問題,在Conformer模型的卷積模塊中增加一條基于Attention機制的計算路徑,將原先卷積模塊的計算結果與Attention模塊的計算結果相乘,作為最終卷積模塊的結果,如圖4所示。
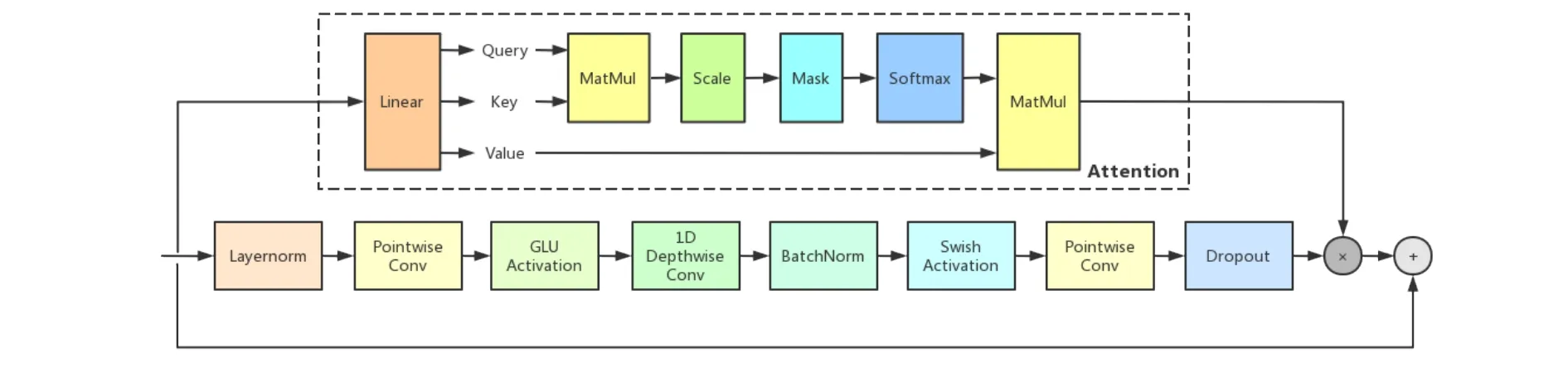
圖4 Conformer的卷積模塊結構
Attention機制能夠較好地捕獲全局和局部間的聯系,在一定程度上彌補了卷積神經網絡對局部與整體之間關聯性的忽略。改進后的卷積模塊的計算公式為
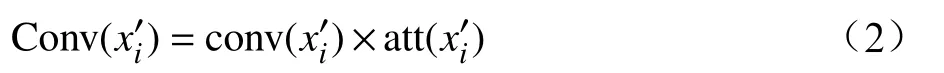
其中, c onv(x)、 a tt(x)分別為卷積模塊、Attention模塊的計算結果, C onv(x)為兩個模塊相乘的結果。
Attention處理過程為:(1)對輸入進行線性變換,得到 Query、Key、Value(分別記為 Q、K、V);(2)將Q與K進行點積運算,得到輸入詞之間的依賴關系;(3)進行尺度變換、掩碼和softmax操作,最終生成Attention矩陣:
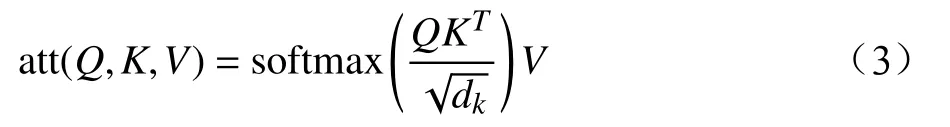
其中, dk為Q和K向量的維度,除以該參數是為了防止Q與K的點積運算結果過大。
由公式(1)~(3)可得,改進后的Conformer結構的計算公式為
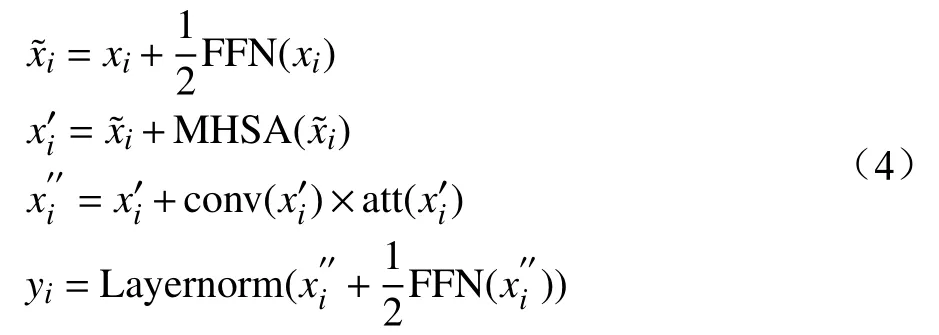
2.2 Conformer-Transducer模型結構
Conformer-Transducer(C-T)模型是對 RNN-T模型的改進,用Conformer Encoder結構替代RNN-T模型中的RNN Encoder結構,并且延用2.1節中提出的在卷積模塊中引入注意力機制的Conformer Encoder結構,預測網絡結構選用雙層LSTM,其模型結構如圖5所示。
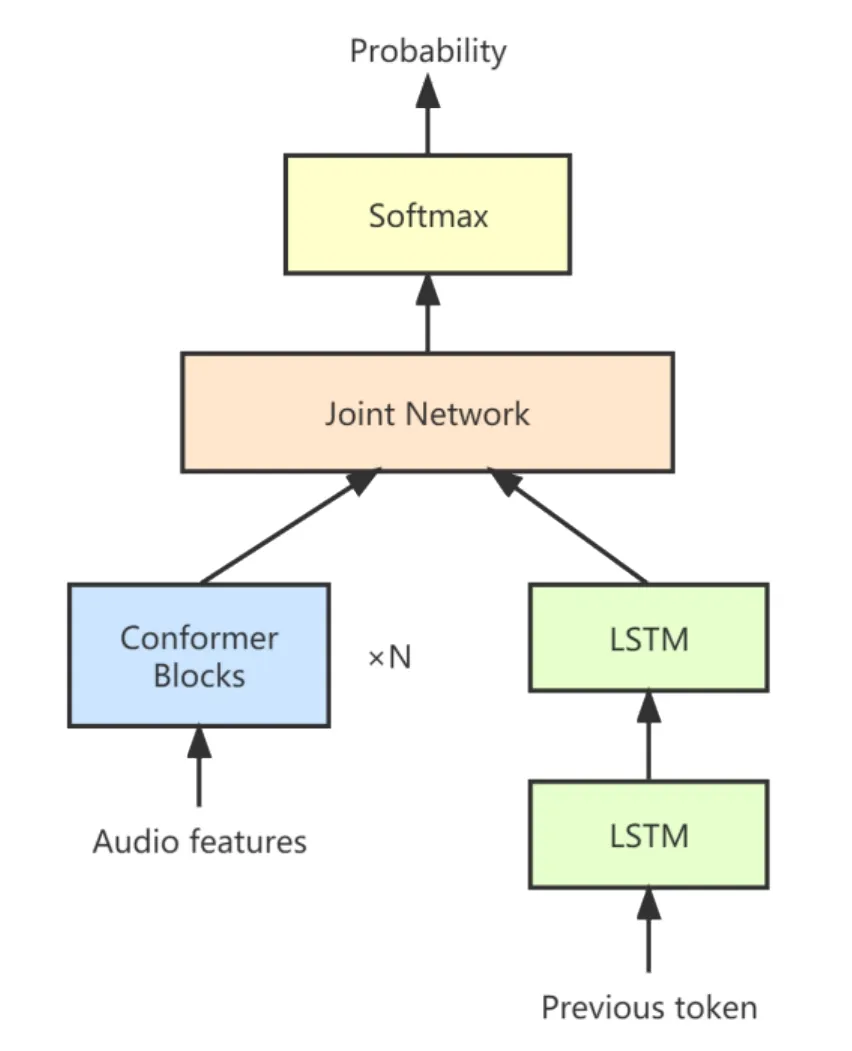
圖5 Conformer-Transducer模型結構
LSTM是對序列數據進行操作,適用于對時間序列中間隔和延遲相對較長事件的處理。在堆疊式LSTM結構中,上層的LSTM為下層的LSTM提供的是序列輸出,而不是單個值輸出。因此,該模型能夠更復雜地處理時間序列數據,以不同的比例捕獲信息。選擇雙層LSTM作為預測網絡可增加神經網絡的深度,提高訓練效率,并獲得更高的識別準確率。
3 改進模型語音識別效果分析
3.1 數據集與評估指標
為加強語音識別模型的領域特征,數據集的數據一部分來源于12306人工客服對話音頻資料,對旅客與客服間對話音頻進行清洗和拆分,去除音頻中無人聲的部分音頻,提取的有效語音音頻時長約為540 h;另有一部分數據是組織專人錄制的鐵路出行條例及旅客常問問題的問答對話,錄制的有效語音音頻時長約為200 h。數據集內含約32萬對語音-文本數據對,按照7:3的比例,將數據集分成訓練集和測試集;其中,訓練集用于對語音識別模型的訓練,測試集用于對模型進行測評。實驗數據集的統計信息如表1所示。

表1 數據集統計信息
在語音識別任務上,采用字錯誤率(CER,Character Error Rate)作為語音識別模型的準確率評價指標,數值越低,表示效果越好;CER計算公式為
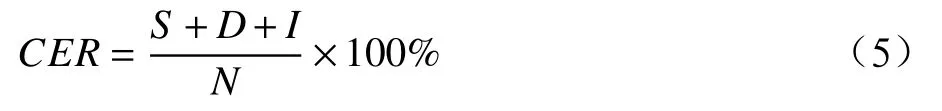
其中,S表示替換的字符數目;D表示刪除的字符數目;I表示插入的字符數目;N表示參考序列中字符總數。
3.2 實驗環境配置
實驗環境配置如表2所示。
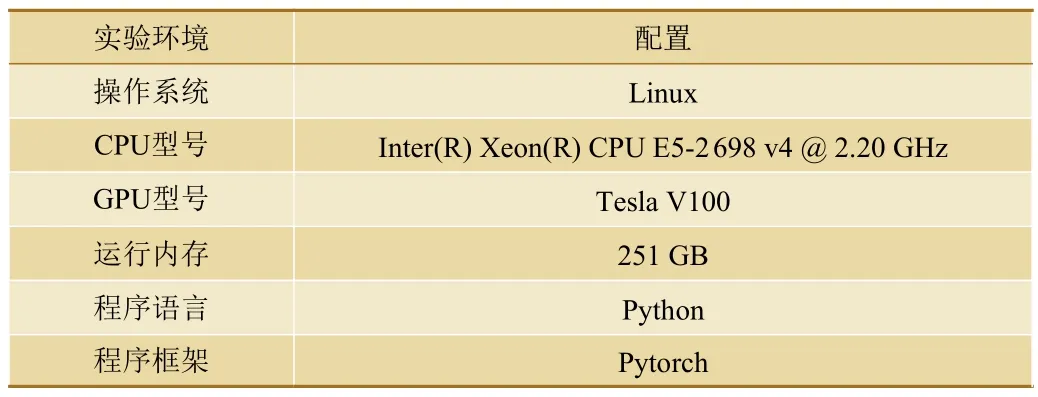
表2 實驗環境配置
3.3 語音識別模型參數設置
由于參數規模對模型準確率會產生一定的影響,考慮了2種參數規模的Conformer模型(Conformer small 和Conformer big),其具體參數設置如表3所示。

表3 2種語音識別模型的參數規模設置
輸入幀使用了大小為 8 的上下文窗口,可生成 640維特征向量,將其作為傳感器編碼器的輸入,幀移位設置為 30 ms;所有模型的卷積核大小都設置為5;預測網絡選用2 個隱藏節點為720的 LSTM 層。2個模型分別在訓練迭代12個epoch 和15個epoch后結果趨于穩定,模型訓練耗時約2~3天時間。
3.4 訓練細節
(1)數據處理:實驗中音頻統一使用16 KHz的采樣率,若存在不符合16 KHz采樣率的音頻,則對其進行采樣率轉化;音頻特征為80維log-mel FBank。
(2)預訓練:采用wav2vec對Conformer編碼器網絡進行預訓練,預訓練的掩碼起點以0.06的概率隨機選擇,掩碼步長設置為10。使用Adam優化器和Transformer學習率策略調節學習率,峰值學習率為2e-3,預熱步長設置為25。Comformer small模型和Comformer big模型均使用Adam優化器和指數移動平均進行訓練。
(3)模型訓練:與預訓練相同,所有模型都使用Adam優化器和指數移動平均進行訓練,根據下游任務調整batch大小、學習率和預熱步長。使用標準的自適應SpecAugment策略,頻率掩碼F設置為27,時間掩碼的最大時間掩碼比Ps設置為0.05,使用2個頻率掩碼和10個時間掩碼對輸入進行增強。
3.5 結果分析
以RNN-T模型作為基線模型,對T-T模型和改進前后的C-T模型進行對比測試,不同模型的測評結果如表4所示。

表4 RNN-T基線模型、T-T模型和改進前后的C-T模型的測評結果
結果表明:
(1)參數規模會對模型準確率產生一定影響。從測評結果可以看出,相對于C-T (Conv) small模型,C-T (Conv) big模型的字錯誤率降低0.09%;C-T(Conv+Attention) big模型較于C-T (Conv+Attention)small模型,在字錯誤率上降低0.07%。2組實驗均表明,參數規模的擴大,在一定程度上能提高模型識別準確率,提升模型的性能。
(2)Attention機制對卷積模塊具有一定的修正作用。相對于無Attention機制的C-T small模型,加入Attention機制的C-T small模型的字錯誤率降低0.26%;相對于無Attention機制的C-T big模型,加入Attention機制的C-T big模型的字錯誤率降低0.24%,識別準確率達到92.09%。2組實驗均表明,Attention機制在一定程度上能對卷積模塊的解碼結果進行修正,從而提高模型的識別準確率。
4 融入面向鐵路旅客服務應用的文本處理機制
在鐵路旅客服務中,客服人員與旅客進行語言交互,形成音頻信息。而鐵路旅客服務中語言交互內容往往對應著特定的文本信息,如鐵路出行條例匯編、旅客常問問題庫等。為此,可考慮利用領域特征文本信息來輔助語音識別,在語音識別模型中加入文本處理機制。針對特定的鐵路旅客服務語音識別應用,除了對語音識別模型進行改進和基于領域特征數據集訓練外,進一步結合以下2種文本處理機制進行定制化處理。
(1)語言模型:語言模型的作用是通過計算一句話的概率來判斷該語句的語序是否通順,分為統計語言模型和神經網絡語言模型2種類型。統計語言模型是通過計數的方式對概率進行求解,而神經網絡語言模型是通過神經網絡進行建模求解,但兩者都是基于模型對輸入文本進行概率預估。最常用的統計語言模型是n-gram語言模型,該模型認為當前詞與前面的n-1個詞有關,但該模型沒有充分考慮詞與詞之間的關系,容易導致數據稀疏;為了解決數據稀疏的問題,研究人員提出了神經網絡語言模型,常用于構建語言模型的神經網絡有:循環神經網絡、長短時記憶網絡、Transformer等。語言模型與語音識別模型的融合方式是,利用鐵路相關語料對語言模型進行訓練,再在語音識別模型的解碼階段,將語言模型進行插值融合。
(2)熱詞賦權:在語音識別模型中,對于常用詞匯的識別效果較好,但對于特有的人名、地名或者特定領域的專有詞匯來說,可能存在識別準確率不高的情況。對于這些專有詞匯,可以建立語音識別任務專用的熱詞詞典,并設置熱詞賦權模塊,以顯著提升專有詞匯的識別準確率。在語音識別模型的解碼階段,除了利用語言模型進行插值融合外,還可以利用熱詞賦權模塊對解碼結果進行修正。
5 鐵路旅客服務語音識別應用實例
5.1 旅客常問問題查詢設備
鐵路12306官方網站按照車票、購票、進站乘車等不同階段,對旅客常問問題進行分類。旅客可根據查詢需求,通過索引或使用搜索框來尋找解答,這種查詢操作方式較為耗時,更適合在電腦上進行操作。目前,12306 App尚未提供旅客查詢旅客常問問題的搜索框,旅客撥打12306人工客服往往需要排隊等候較長時間,才能獲得客服人員的問題解答。
為此,設計了一款基于語音識別技術的旅客常問問題查詢設備,直接通過語音交互來完成旅客遇到的大多數問題解答,旅客無需手動輸入查詢條件,也不需要撥打客服電話咨詢,極大地縮短旅客咨詢問題的時間。鐵路旅客常問問題查詢設備的語音數據處理流程如圖6所示。
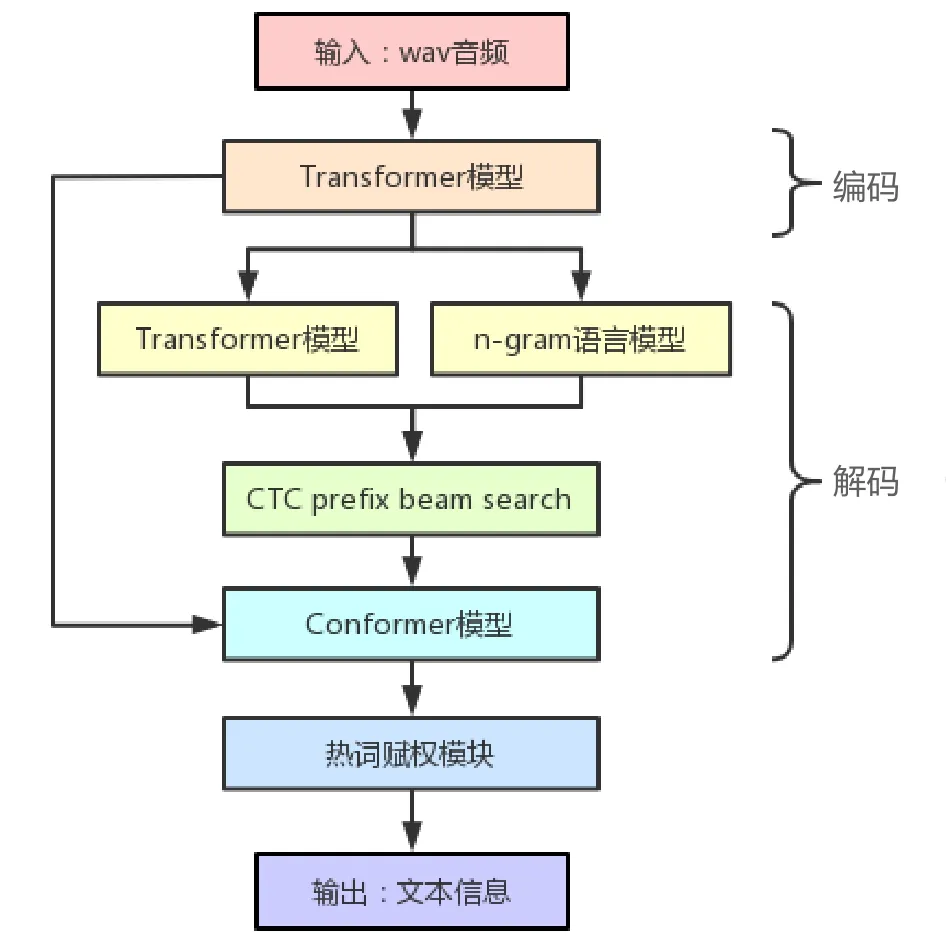
圖6 鐵路旅客常問問題查詢設備的語音數據處理流程
該設備結合流式與非流式2種語音識別模型。其中,流式語音識別模型能夠在處理音頻流的過程中實時返回識別結果,適用于要求查詢設備實時返回查詢結果的應用場景。相對流式語音識別模型,非流式語音識別模型的識別結果更為準確,可用于修正流式模型的識別結果。
在音頻編碼處理階段,將Transformer模型與Conformer模型相結合,充分結合兩種模型的優點,保證長短句子的有效編碼。在音頻解碼處理階段,增加基于Transformer和n-gram的2種語言模型,利用鐵路相關語料對語言模型進行訓練。為提高音頻解碼的召回率,增加了CTC prefix beam search的解碼過程,該解碼算法可篩選出N條最佳解碼路徑。在完成音頻解碼處理后,增加了熱詞賦權模塊,設置旅客常用問題熱詞詞典,根據這N條最佳解碼路徑中包含熱詞的情況進行賦權加分,最終選定得分最高的那一條最佳解碼路徑作為識別結果。
通過搜集和整理旅客常問問題,在實驗室環境對語音查詢功能進行模擬測試,準確率達約為92%。
5.2 車站智能服務機器人
隨著人工智能(AI,Artificial Intelligence)技術的逐漸成熟及智能機器人的應用普及,鐵路車站新型智能機器人正朝著“AI+智能出行”方向發展。新型智能機器人的使用改變了傳統車站只能靠人工服務和標識引導的方式開展車站旅客服務工作,使鐵路旅客出行更加便捷、高效。目前,已有部分鐵路車站引入智能機器人為旅客提供向導服務,同時還能提供車次、公共交通線路、天氣、酒店等信息查詢服務。目前,這些查詢服務還需要旅客手動操作,還沒有有效地結合語音識別技術。
為此,研發了“零操作”車站智能服務機器人,可通過語音交互方式為鐵路旅客提供更為全面的人性化服務,車站智能服務機器人與鐵路旅客的交互過程如圖7所示。
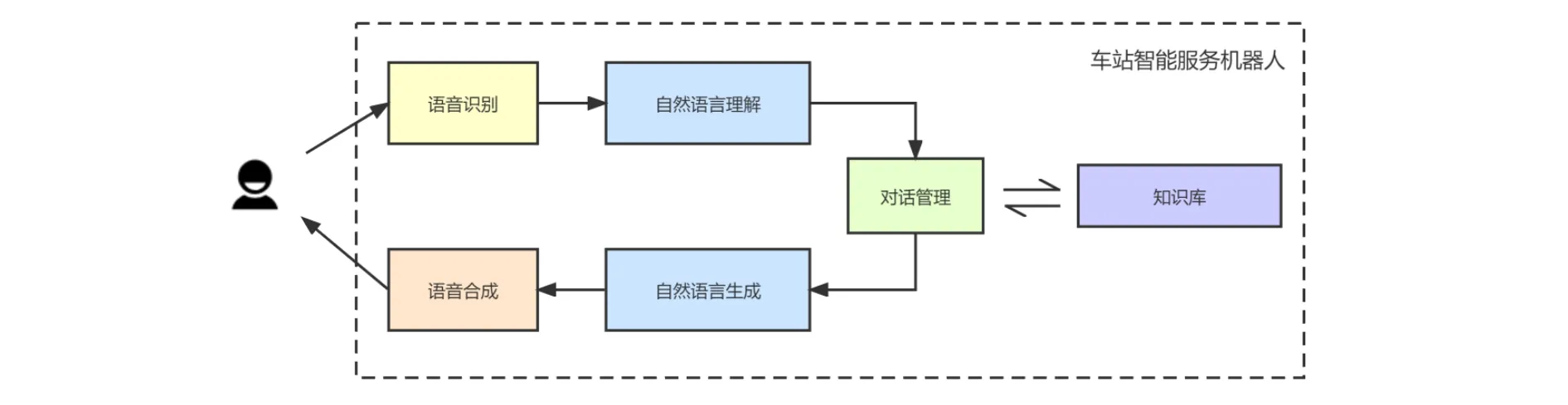
圖7 車站智能服務機器人與鐵路旅客的交互過程
車站智能服務機器人與鐵路旅客的交互過程為:(1)機器人首先進行語音識別,將語音信號轉化為文本;(2)通過自然語言理解技術對文本進行語義理解,將其映射為旅客對話行為;(3)對話管理模塊根據旅客對話行為,結合旅客常問問題知識庫內容,選擇機器人需要執行的系統行為;(4)通過自然語音生成技術,生成需要反饋給旅客的自然語言;(5)機器人將合成的問題解答語音反饋給用戶。
本文提出的語音識別模型主要用于實現車站智能服務機器人的語音識別功能模塊,與通用的語音識別模型相比,為車站智能服務機器人定制開發的語音識別模型在識別鐵路專有名詞方面效果甚佳。這個語音識別模型的訓練集選用鐵路客服對話語料,且設置有鐵路專用字典,收錄了車站名、城市名、車次信息等鐵路相關行業術語,以及行程所遇到問題的關鍵詞,可顯著地提高車站智能服務機器人內置的語音識別算法的適用性。車站智能服務機器人在與乘客的交互過程中,能更加準確地識別出旅客所提出的問題,例如“檢票口怎么走”、“如何做人臉核驗”、“怎么取報銷憑證”之類的常見問題,從而給出符合旅客所問問題的解答。
除了為鐵路旅客提供所在車站、車站所在城市等出行相關資訊外,車站智能服務機器人還可提供火車線路查詢、車次時間、票價政策、乘車須知、失物招領、引導窗口、業務辦理等客服信息,能夠替代車站客服人員完成大量的旅客服務工作。
6 結束語
本文基于RNN-T模型進行語音識別模型研究,用 Conformer結 構 代 替 了 RNN Encoder, 并 對Conformer結構的卷積模塊進行了改進,并在其中加入注意力機制,彌補了卷積網絡訓練的缺點,可有效提高語音識別模型的識別準確率。考慮到鐵路旅客服務通常都對應著特定文本信息,在語音識別模型的基礎上融合了語言模型與熱詞賦權2種文本處理機制,使其在鐵路專有名詞的識別上優于通用的語音識別算法。同時,基于改進后的語音識別模型,完成了旅客常問問題查詢設備與車站智能服務機器人中語音識別應用的開發。語音識別應用有助于提高鐵路旅客服務水平,改善鐵路旅客出行體驗,還能更為有效地替代鐵路工作人員完成更多旅客服務,促進鐵路旅客服務工作實現減員增效。
在實際場景中,鐵路旅客使用鐵路旅客服務語音識別應用時,很難保證所處環境相對安靜,各種復雜的聲學環境會對語音識別的效果造成不良影響。此外,在日常生活中,人們說話往往也較為隨意,語言習慣不一,如帶有明顯地方口音、經常重復、停頓或插入,不會嚴格遵循語法要求。對于基于標準語音訓練的語音識別模型而言,要做到準確識別這類缺乏足夠規范性的語音是相當困難的。因此,如何逐步提升鐵路旅客服務語音識別技術的魯棒性將是下一階段的研究重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
云南畫報(2021年12期)2021-03-08 00:50:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
鐵道通信信號(2018年7期)2018-08-29 01:17:04
商周刊(2017年9期)2017-08-22 02:57:56
光學精密工程(2016年6期)2016-11-07 09:07:19
