配電網電力設備缺陷文本智能辨識運維綜述
2022-05-09 03:01:40張磐鄭悅李海龍劉航旭李國棟葛磊蛟
電力建設 2022年5期
張磐, 鄭悅,李海龍,劉航旭,李國棟,葛磊蛟
(1.國網天津市電力公司電力科學研究院, 天津市 300384;2.國網天津市電力公司,天津市 300010;3.國網天津市電力公司濱海供電分公司,天津市 300450;4.天津大學電氣自動化與信息工程學院,天津市 300072)
0 引 言
智能配電網電力設備具有種類繁雜、數量多、運維難等特點[1],隨著電力系統的不斷發展以及智能電網建設的深化推進,電網企業數據庫中存儲的電力數據隨著智能電網的運維呈現爆發式增長[2]。這些數據通常以非機構化數據如圖像、文本等形式存儲[3],蘊含大量關于電網設備運行狀態的信息[4]。通過對電力設備缺陷文本的深度挖掘,能夠實現電網運行狀態的實時監測、故障定位及設備維修,為電網的可靠運行提供指導[5]。
近年來,電力數據挖掘雖然已成為研究熱點,但真正得到挖掘并利用的數據卻很少[6],如何深度挖掘電力設備缺陷文本內部信息,是電力設備精細化管理未來發展面臨的主要問題。我國在電力設備缺陷文本挖掘方面的成果較少,面臨巨大挑戰。首先,電力設備相關信息以文本形式表示,往往含義模糊、計算機難以辨別;其次,電力領域具有專業性,無法直接應用其他領域的文本挖掘方法;最后,隨著智能電網的高速發展,電力設備相關文本會變得更加復雜,當前電力設備缺陷文本挖掘技術將不再適用。
本文基于現有研究成果,對該領域的發展方向以及主要方法進行分析,并指出面臨的關鍵難題。首先,面向電力設備缺陷文本挖掘從4個方面進行剖析:1) 電力設備缺陷文本錯誤識別與質量提升;2) 電力設備缺陷嚴重等級自動分類;3) 電力設備缺陷細節提取;4) 電力設備健康狀態自動評價。其次,結合相關文獻中的算例結果,對不同方法實現的效果進行分析。最后,分析電力設備缺陷文本挖掘技術未來發展方向,以期為該領域的進一步研究提供參考與借鑒。
1 電力設備缺陷文本深度挖掘技術
電力設備缺陷文本深度挖掘技術包含缺陷文本錯誤識別與質量提升、缺陷嚴重等級自動分類、缺陷細節提取和健康狀態自動評價4個方面,如圖1所示。
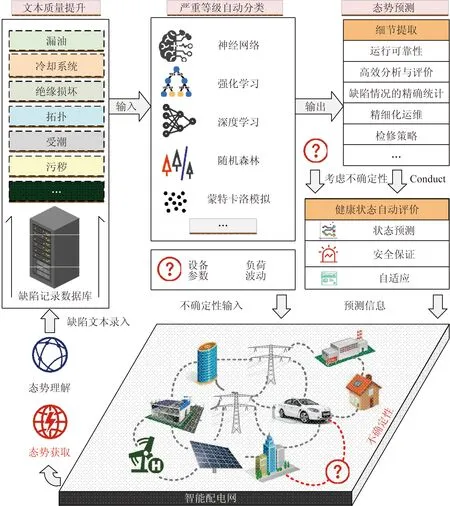
圖1 電力設備缺陷文本深度挖掘技術示意圖Fig.1 Schematic diagram of text deep mining technology for power equipment defects
首先對缺陷文本進行錯誤識別與質量提升,剔除文本記錄錯誤、混雜等數據,得到高質量的缺陷文本數據;進而對設備缺陷嚴重等級進行自動分類,并提取缺陷細節,進行電力設備的全面態勢獲取;最后進行健康狀態自動評價,實現電力設備未來態勢的預測。
2 缺陷文本錯誤識別與質量提升
隨著電力設備的日常運維,電力設備缺陷文本在電力設備文本系統中大量累積[7],但由于電力設備數量龐大,缺陷種類復雜,現有的規范[8]無法實現全面總結;此外,由于缺陷文本的人為記錄特征,時常會出現由于記錄人員經驗不足導致的文本殘缺甚至錯誤等現象[9],造成了缺陷文本挖掘的復雜性。因此,錯誤識別與質量提升是電力設備缺陷文本挖掘的關鍵技術之一。首先對電力設備缺陷文本進行錯誤識別,找到因錄入不規范、語病等原因導致的文本錯誤,進而針對識別結果對其進行矯正,實現質量提升。
2.1 缺陷文本錯誤識別
通過對電力設備缺陷文本的挖掘,識別電力設備缺陷文本的錯誤,從而更加完整地記錄電力設備相關缺陷,為電力設備缺陷文本的質量提升奠定基礎。我國對于文本錯誤識別的研究開始于20世紀90年代,起步較晚,對于電力設備缺陷文本領域的錯誤識別相關研究較少。文獻[10]面向卷宗文本錯誤識別構建了查錯模塊,對錄入的文本進行搜索,找出語病、錯別字等文本錯誤并記錄位置。文中為了充分考慮語料庫不能完全涵蓋自然語言的局限性,將語料庫中的詞與識別文本進行比對,找出未登錄的疑似語病的詞字。進而將疑似錯誤與上下文的詞串結合,利用Kenlm模塊計算置信度值判斷正誤。然而針對電力設備缺陷記錄領域,文獻[10]所提方法并不適用。
現有針對電力設備缺陷文本的研究主要聚焦于電網公司中質量欠佳的歷史缺陷文本,主要結合電力設備缺陷文本分類規范,研究電網中各設備的缺陷矯正方法,以改善設備缺陷。對于新錄入信息管理系統中的缺陷文本,采用文本質量評價方法對其存在的問題進行分析,通過缺陷文本質量評價方法,對修正前后的缺陷文本記錄數據進行打分,根據評分結果得到缺陷文本錯誤識別結果。
為對大規模文本信息進行深度分析,可借助知識圖譜(knowledge graph,KG)顯示知識之間相關聯系的能力[11],構建電力設備缺陷文本知識圖譜實現檢索、查錯等功能。知識圖譜是一種新型的圖型數據庫,它通過“結點-關系-結點”的基本三元結構表示知識之間的關系[12]。知識圖譜技術的發展有賴于人工智能的普及,它可以通過可視化的方式顯示人工智能的決策過程。在知識圖譜的分類中,縱向知識圖譜指的是某一特定領域的知識圖譜。電力知識圖譜作為一種典型的縱向知識圖譜,已在電力工業的數據分析與決策環節得到了應用。使用結構化數據形式的電力設備缺陷文本構造知識圖譜,便可實現輔助錄入系統所需要的數據檢索與可視化功能[13]。針對電力設備缺陷文本錯誤識別,文獻[14]采用基于知識圖譜的缺陷文本錯誤識別方法,提出了一種基于圖搜索的缺陷記錄檢索過程,通過深度優先搜索算法實現對知識圖譜中完整樹的搜索,從而構成完整的缺陷記錄,大大簡化了工作人員分析文本的過程。該文獻最后以電網公司變壓器缺陷文本為例,將所提方法與基于機器學習的模型進行對比,結合相關評價標準例如精確率、召回率等,證明了所提方法在提升缺陷文本錯誤識別效果方面的有效性和優越性。
上述圖搜索算法對于錯誤識別具有良好的效果,但是容易因為臨近搜索而陷入死循環。樹搜索算法在搜索問題復雜度不高的情況下可以在不明顯犧牲搜索靈活度的前提下解決陷入死循環的問題。因此樹搜索算法也可以用于解決缺陷文本錯誤識別的難題。文獻[15]為提高缺陷分類等級的準確度,對缺陷文本中的錯誤識別進行了研究。首先輸入歷史記錄的設備缺陷文本,并根據國家電網有限公司給出的缺陷分類標準構建了樹路徑匹配框架。進而按照樹路徑匹配算法找到對應的最相似路徑,從而識別到文本錯誤并給出錯誤程度。這種基于樹搜索的識別模式與圖搜索類似,但是區別在于前者允許經過重復的節點而后者不允許。
由于關系提取的準確性將直接影響知識圖譜[14]和樹結構的準確性和完整性,且現有的知識圖譜與樹結構的表示主要是依賴電網公司的分類標準,隨著設備的多樣化以及運行場景的復雜化,缺陷文本的錯誤可能會被誤識別[15]。如果使用更多的語法解析等自然語言處理技術提取更多的語義特征,缺陷文本的錯誤識別效果可進一步提高。這也是未來缺陷文本錯誤識別研究的一個可能方向。
2.2 缺陷文本質量評價與提升
缺陷文本的質量會影響深度挖掘的效果,因此高質量的缺陷文本庫是對其深度挖掘的基礎。設備缺陷文本很大一部分由人工錄入,存在錄入不規范、語病等問題,對缺陷文本進行錯誤識別后需要對其進行質量評價和提升。
機器學習與自然語言處理技術可以實現缺陷文本質量的智能評價與提升[16]。文獻[17]將文本錯誤的糾正問題看作輸入數據的規范化翻譯過程,改變了傳統的文本錯誤識別-質量提升的二階段策略,運用帶注意力機制的序列到序列學習模型對常規中文文本進行了錯誤糾正。這種文本提升方法需要大量的帶標簽數據對深度學習模型進行訓練,對于電力設備缺陷文本專業領域的適用性不足,目前對電力設備缺陷文本質量提升方面的研究較少。文獻[18]提出了一種缺陷文本質量評價和提升方法,以電網中不同設備產生的25 000多條歷史缺陷文本為例,通過缺陷文本質量評價方法,對修正前后的缺陷文本記錄數據進行打分,根據打分評價結果,準確識別新錄入文本存在的問題并給出修改建議,完成新錄入缺陷文本質量的提升,從而驗證了所提方法在同時實現歷史缺陷文本與新錄入文本質量評價與提升方面的有效性。
電力設備缺陷文本質量提升過程主要有以下幾個步驟:首先,以電網公司缺陷文本為樣本,分析獲知電網公司缺陷文本存在的問題,如格式殘缺、語義模糊、冗雜等問題;然后,針對這些問題,提出缺陷文本質量評價指標,并以此構建相關評分體系對缺陷文本進行評價;基于文本質量評價結果,聚焦于電網公司中質量欠佳的歷史缺陷文本,采用潛在多元Beta分布等方法,結合電力設備缺陷文本分類規范,對文本內容予以矯正;最后,針對新錄入信息管理系統中的缺陷文本,采用上述文本質量評價方法對其存在的問題進行分析,從而給出修正建議。
然而,目前的缺陷文本質量評價方法存在很強的主觀性[18],隨著缺陷文本數據量的增加可能出現評價與實際質量偏差過大的情況影響質量提升效果。因此,基于客觀評價結果建立缺陷文本質量量化模型是未來缺陷文本質量提升的重要方向。
3 缺陷文本缺陷嚴重等級自動分類
在電力系統巡檢過程中,往往會累積大量缺陷文本,這些缺陷文本中記錄著大量關于設備缺陷嚴重等級的相關信息,對設備缺陷等級的分類至關重要。通過分類設備缺陷嚴重等級,工作人員可以更好地實現對電力系統中缺陷設備的管理。然而傳統的設備缺陷嚴重等級分類方法往往需要人工完成,其分類效率低下;且針對模糊性較強的亞健康缺陷,往往會出現由于巡檢人員經驗不足而分類不精確的情況,對電力設備運行狀態的評估產生不利影響。
隨著人工智能及模式識別的深度開發,多種機器學習模型與電力設備缺陷嚴重等級分類相結合[19],既能夠提高電力設備缺陷嚴重等級分類的效率[20],又能夠避免因信息模糊造成的分類精確率降低。文獻[21]針對缺陷文本分類,首先通過one-hot詞袋模型對缺陷文本進行預處理,實現了向量空間的構建及缺陷嚴重等級的分類與量化;接著采用K最近鄰算法對電力設備缺陷記錄數據完成類別辨識。仿真部分以斷路器缺陷文本為例,對缺陷文本進行重新分類,與初始結果進行對比可得,該方法準確率更高,驗證了所提方法的可行性。
機器學習與智能識別的應用,使得分類效率大大提高。但這類分類方法往往需要依靠特征函數,從而導致特征項模糊甚至丟失[22];此外,傳統機器學習分類方法的泛化能力以及數據挖掘能力有限,從而大大限制了缺陷文本的分類效果。
為解決上述問題,基于卷積神經網絡(convolutional neural network,CNN)的電力設備缺陷文本挖掘算法被提出,通過卷積運算實現特征壓縮降維、減小運算量[23]。文獻[19]通過與多種傳統機器學習分類模型對比得出:基于CNN的缺陷文本分類模型在耗費一定時間的前提下,顯著降低了缺陷文本分類的錯誤率;此外,與以往的機器學習分類法相比,基于CNN的缺陷文本分類模型分類時間較短,提高了分類效率。但是該方法僅對文本進行了一次串行淺層特征提取,不能很好地挖掘長文本深層語義信息。針對CNN無法對長序列信息建模的問題,應用循環卷積神經網絡(recurrent convolutional neural network,RCNN)是解決該問題的可行思路。RCNN是基于循環神經網絡(recurrent neural network,RNN)的改進算法,克服了傳統RNN長期依賴、梯度爆炸的問題[24]。文獻[25]以變壓器為研究對象,運用RCNN模型完成對缺陷文本的自動分類。仿真部分基于變壓器運維文本,將RCNN方法分別與傳統文本分類模型、RNN以及CNN方法進行對比。與傳統中文文本分類方法相比,RCNN同時實現了特征提取與分類評估,可直接面向底層進行語義分析,分類性能提升了3.49%~21.0%;相比于CNN、RNN,RCNN 模型網絡框架更加優秀,可更好地融合上下文信息并最大可能保留關鍵語義。
文獻[26]采用基于雙向長短期記憶網絡(bi-long short term memory, BiLSTM)的分類模型實現對缺陷文本缺陷嚴重等級高效自動分類。選取經過人工分類的某電網公司2010—2015年的529個故障文本中的900條句子作為輸入數據,輸出為設備故障嚴重等級。仿真部分通過分類準確率、召回率以及F1值3個指標對BiLSTM方法與LSTM及CNN方法進行比較,驗證了BiLSTM方法的優越性。文獻[27]在BiLSTM的基礎上引入了注意力機制,提出了基于注意力機制的雙向長短期記憶神經網絡(BiLSTM based on attention mechanism, BiLSTM-Attention)缺陷文本分類方法。相比于傳統文本分類模型、BiLSTM模型以及CNN模型,BiLSTM-Attention模型在電力設備缺陷文本分類中具有更好的分類性能,提高了對含有混淆信息長文本的特征提取能力和分類能力。關于電力設備缺陷文本缺陷嚴重等級自動分類的方法如圖2和表1所示。
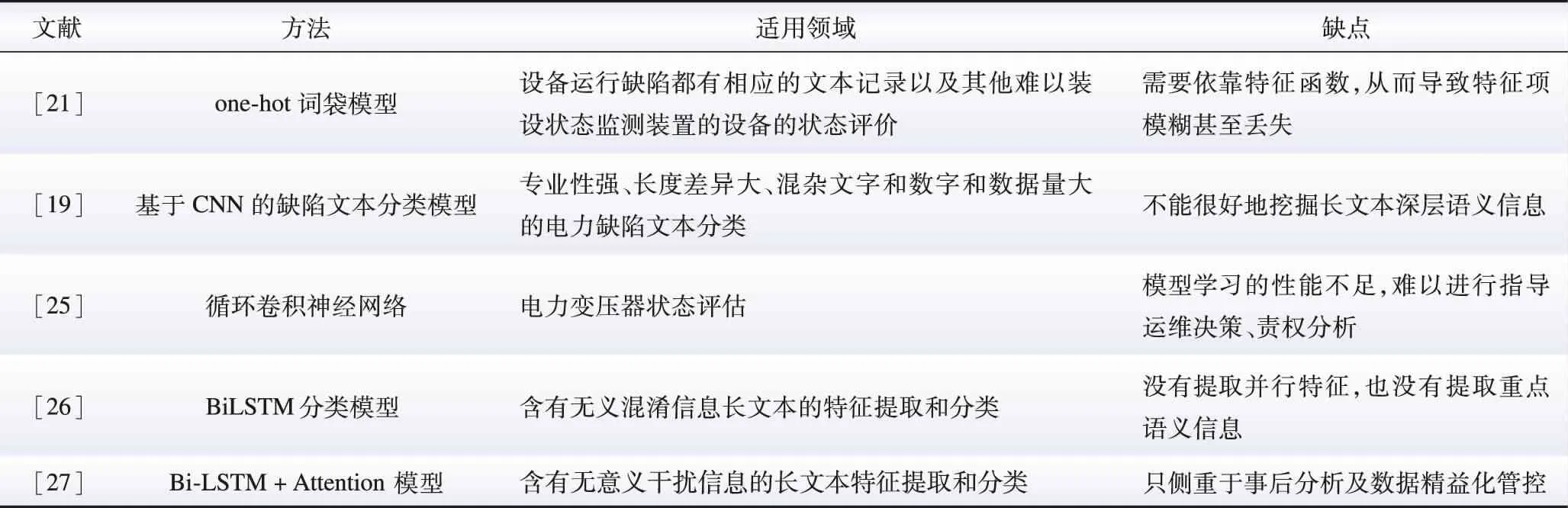
表1 現有缺陷文本缺陷嚴重等級自動分類方法特點對比Table 1 Comparison of characteristics of existing automatic classification methods for defect severity level of defect text
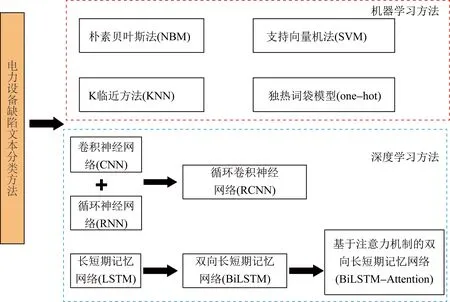
圖2 缺陷文本缺陷嚴重等級自動分類方法Fig.2 Automatic classification method for defect severity level in defect text
4 缺陷文本缺陷細節提取
電力公司在電力設備的日常運營巡檢中,通常以非結構化數據形式將電力設備的異常和維護等信息錄入管理系統,數據形式以文本形式為主。這些信息中存在著大量的設備相關運行狀態信息,同時還表征了其他同類設備的運行可靠性信息[28]。然而通過對大量缺陷文本信息的研究能夠發現,同一設備多個零件的缺陷情況經常存在于一條缺陷文本信息中,過度且復雜的描述導致信息記錄錯亂無序。通過對缺陷記錄中缺陷細節的提取,可以實現缺陷情況的精確統計、高效分析與有效評價。因此,缺陷文本中缺陷細節的提取是確保電力系統安全運行的關鍵環節[29]。自然語言處理(nature language processing, NLP)技術是一門融合語言學、計算機科學、數學于一體的科學,可以實現人與計算機之間用自然語言進行有效通信,在一定程度實現人機交互。為此,基于NLP領域中的多種方法被廣泛應用到中文電力設備缺陷文本細節提取中。目前電力設備缺陷文本細節提取按自然語言不同主要可分為英文電力設備缺陷文本細節提取和中文電力設備缺陷文本細節提取2個方向。
文獻[30]以紐約市電力系統相關信息作為參考,提出了一種基于機器學習的海量缺陷歷史數據挖掘方法,電力公司通過該模型可以確定維護和維修工作的優先級,例如:1)對饋線故障維修的優先等級;2)對電纜、接頭、終端以及變壓器等故障維修的優先等級。該方法為電網公司提供了電力設備故障預測以及預防性維修的依據,從而實現對電網更好的維護。國外的缺陷文本細節提取研究主要聚焦于英文文本,然而與之相比,中文文本在構詞、詞性等方面存在著較大差異,因此英文文本挖掘的相關算法研究在中文文本中是不適用的。文獻[31]提出一種基于語義框架的電力設備缺陷文本缺陷細節提取方法,為電力設備缺陷的進一步記錄、管理奠定了基礎。首先,建立本體字典庫;接著通過對電力設備缺陷記錄數據的總結分析,結合其固有特點實現了電力語義框架與語義槽的建立;采用槽填充并構建語義框架,構建流程如圖3所示。通過對大量變壓器缺陷文本的處理,驗證了該方法能夠精確提取電力設備缺陷文本中的缺陷信息,因此也能夠應用于電力設備缺陷統計與分類中。文獻[32]結合依存句法分析技術對電力設備缺陷文本信息的精確辨識方法進行了改進。首先,基于依存句法分析技術,構建了電力設備缺陷文本與電力設備標準文本的依存句法樹,依存句法樹生成流程如圖4所示。接著運用依存句法的樹匹配算法實現了電力設備缺陷細節數據的準確分析與分類。最后以主變壓器為研究對象,通過分析其歷史缺陷文本記錄,證明了該方法的優越性和實用性,相比于其他方法,該方法的計算速度與精確度更具有優越性。

圖3 構建語義框架流程Fig.3 Semantic for framework construction
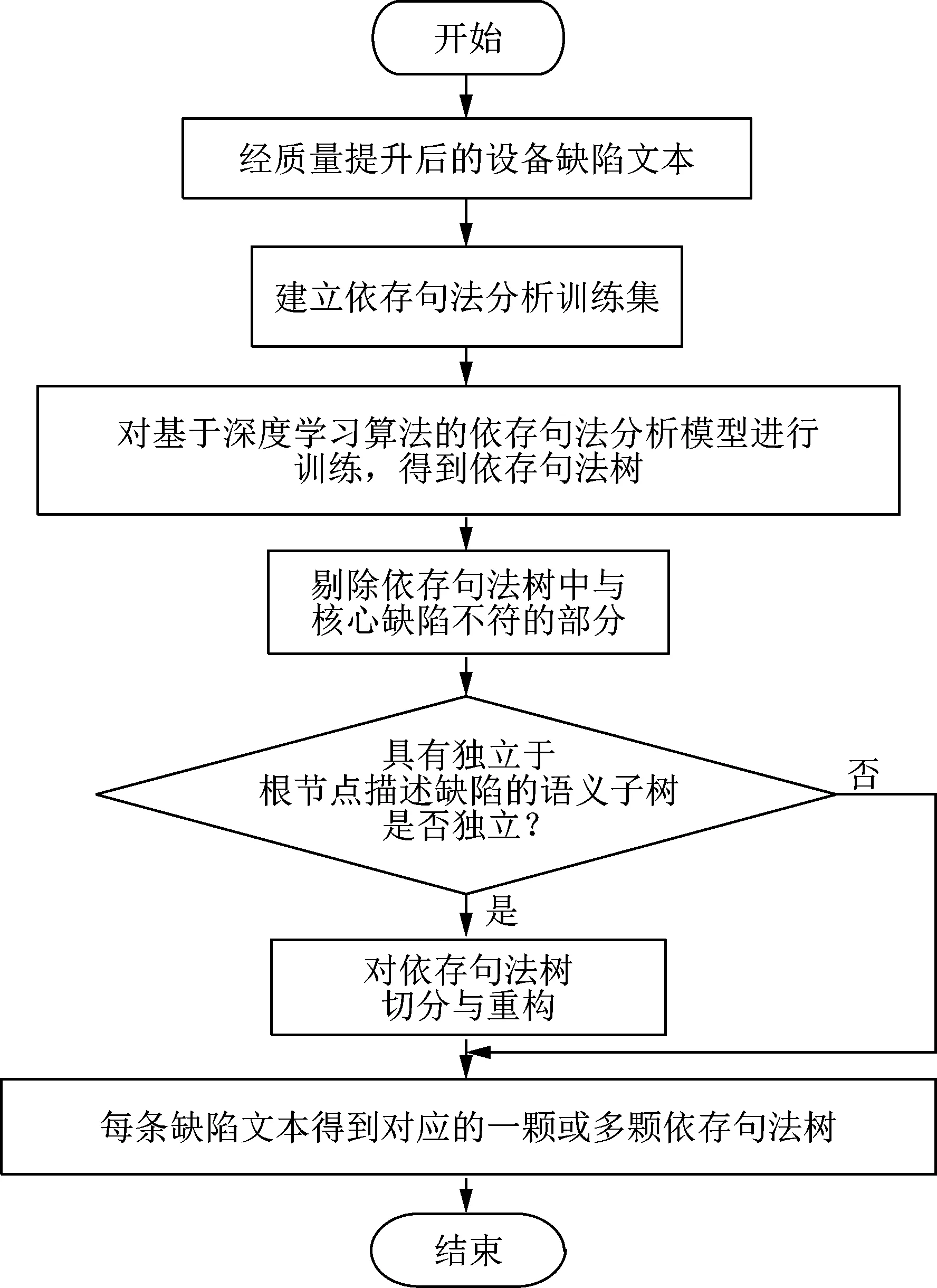
圖4 電力設備文本依存句法樹生成流程Fig.4 Flowchart of constructing dependency syntax tree based on equipment defect text
5 缺陷文本健康狀態自動評價
在電力設備日常運行巡檢中,產生的缺陷文本除了包含電力設備當前的缺陷情況外,還蘊藏著豐富的電力設備健康狀態歷史記錄,通過對健康狀態的歷史記錄進行分析,能夠更好地評價設備運行狀態,從而實現對電力設備未來態勢的預測。
當前健康狀態主要評價方法如下所述:1) 基于評價導則與專家系統的方法,這種方法成本高、耗時長,當面對大量設備健康狀態評價時,難以滿足需求[33];2) 基于人工智能技術構建神經網絡等模型的方法,這種方法是目前的主流方法,能夠實現大量設備健康狀態的評價[34-37]。
文獻[34]提出了一種比率型斷路器全壽命周期運行狀況評價模型。首先,根據斷路器缺陷等級,結合文本挖掘技術和相關評價規范[35]得到缺陷等級評價結果,將評價結果量化為健康狀態指數;接著運用比率型狀態信息融合模型得到單位健康周期健康狀態指數,將其與之前得到的健康狀態指數結合,得到了全壽命周期數據流,從而得到斷路器全壽命周期運行狀況評價模型。文獻[36]表明,結合全壽命狀態評價模型,可從電力設備缺陷文本中的語句結構和語義對電力設備缺陷文本進行深層次挖掘,通過對比缺陷文本與電力設備缺陷評價規范,給出當時情景下的電力設備健康評價結果,從而極大改善了電力設備健康狀態評估的客觀性與準確性。文獻[37]以電力系統故障的告警信號為研究對象,提出了一種電力調度故障自動判斷模型。首先,結合隱馬爾可夫模型及向量空間模型對調度故障信息進行預處理;接著基于對故障信息文本的辨識結果,實現對故障情況的精確診斷,并通過k-means聚類法獲取高概率故障為運維人員提供運維檢修依據。
現有的基于缺陷詞庫的電力設備健康狀態評估方法[30],普遍存在以下缺陷:由于樣本較少,經過模型訓練所得到的結果往往并不精確,難以覆蓋所有缺陷,缺陷文本錄入不規范也會限制電力設備健康狀態評估方法的準確性。因此,通過對電力設備缺陷文本深度挖掘來提高缺陷類型評估準確性的方法[36]存在固有局限性,需要先對缺陷文本進行質量提升。此外,基于機器學習的健康狀態評估方法的核心是實際需要故障類型對訓練的故障樣本具有高度依賴性,對于故障樣本未包含的故障類型,難以進行精準識別,通過生成對抗網絡來生成原本故障樣本未包含的數據是一種數據增強的有效手段。此外,深度學習等機器學習算法需要大量的有標簽數據作為數據支撐,當訓練數據匱乏時,訓練出的模型極易出現過擬合的現象,這種現象在小規模數據集上尤為明顯。未來,通過人工智能技術提高訓練樣本集完備性以加強故障類型識別精度值得深入研究。
6 電力設備缺陷文本信息挖掘前景展望
目前電力設備缺陷文本挖掘領域仍然處于初級階段,對文本挖掘技術有待進一步研究。本文基于目前的研究成果,對電力設備缺陷文本挖掘技術進行了總結,其未來關鍵技術發展前景展望如下:
1) 高質量電力本體詞典的構建。電力本體詞典是電力設備缺陷文本挖掘技術的基礎[36],其質量決定了電力設備缺陷文本挖掘的效果。受制于電力領域方向眾多、詞匯復雜等因素,構建高質量電力本體詞典困難,如何通過相關方法構建高質量電力本體詞典,是今后研究的關鍵問題。目前電力本體詞典的構建主要針對非結構化的文本數據,如果能與結構化的多源數據進行融合,結合專家系統對電力本體詞典進行實時在線擴充,將會極大消除電力設備缺陷文本挖掘對于未知缺陷的特征文本提取困難的現狀。
2) 知識圖譜在電力設備缺陷文本信息提取中的深層次應用。當前電力知識圖譜的研究不夠深入,在其內部架構設計方面有待進一步研究[38]。文獻[39]所提出的電力知識圖譜主要采用三元組的形式進行表示,難以表示更加復雜的電力設備缺陷文本信息。因此,如何進一步開發知識圖譜,使其能夠更加詳細地表達復雜信息,是電力知識圖譜在電力設備缺陷文本挖掘中的重要研究方向;此外,電力知識圖譜構建過程中,如何更加準確地獲取大量有效知識以及如何更好對知識進行有效融合,是電力知識圖譜應用的另一關鍵問題。知識圖譜具有良好的解釋性,而基于深度學習的特征提取方法具有精準度高解釋性差的特點,因此可以將二者結合,構建基于深度學習的新型知識圖譜,將深度學習的輸出結果轉化為知識圖譜可以理解的三元組進行推理,在保證缺陷文本提取合理性的基礎上提高提取精度與效率。
3) 電力設備缺陷文本細節提取方法的深度開發[40]。當前電力設備缺陷文本細節提取方法仍較為簡單,可以通過篩選進一步完善。如利用神經網絡的分類功能對不同數據進行篩選,有效降低非強關聯數據對提取結果的影響,改善細節提取原始數據集的質量。
4)多源數據融合在電力設備缺陷文本挖掘方法中的應用。當前依靠缺陷文本挖掘與自動診斷技術的應用對電力設備健康狀態自動評價的方法只是基于歷史缺陷記錄數據對設備當前運行態勢進行評價,如何將設備運行實時監測數據與健康狀態評價模型相結合,實現電力設備健康狀態完整評價,仍需要進一步研究。例如針對多源數據融合接入進行綜合分析處理,實時融合機器人等站端各類智能裝備在線數據和離線監測數據等信息;進而依托設備健康狀態評價算法模型進行設備運行狀態評估;最后結合專家系統中的知識庫、規則庫實現智能預警,并與智能裝備調度平臺進行聯動控制,實現一體化、全方位的數字化和智能化設備健康狀態評估。
7 結 論
本文主要從技術角度探討了電力設備缺陷文本錯誤識別與質量提升、嚴重等級自動分類、缺陷細節提取、健康狀態自動評價等關鍵技術。本文研究的內容,是基于該領域已有科研成果所作的總結和展望,以期對電力設備缺陷文本挖掘技術的進一步發展及應用提供一些思路和借鑒。然而配電網作為輸電端與負荷端連接的關鍵系統,具有設備復雜、傳感器種類多樣、新舊程度不一等特點。在應用層面,由于運行環境惡劣、電磁干擾,許多設備狀態監測裝置現場應用性能不穩定,監測裝置本身存在故障率、誤報率高及數據可信度存疑等問題,電力設備缺陷文本智能辨識技術在配電設備智能高效運維的實際工程應用面臨嚴峻挑戰。通過建立基于人工智能的電力設備缺陷文本分類模型,對現場巡視人員錄入的缺陷文本數據進行等級分類并給出相關分類依據可有效提升電力設備運維效率。此外,電力設備缺陷文本挖掘技術的發展仍然需要相當長的過程,在當前研究的基礎上,應融合多種方法實現電力設備缺陷文本挖掘,以期實現更加智能的效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
江蘇安全生產(2020年7期)2020-09-04 09:34:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代工業經濟和信息化(2016年22期)2016-08-23 11:55:50
電測與儀表(2016年18期)2016-04-11 11:29:34
小學教學參考(2015年20期)2016-01-15 08:44:38
