Winograd 快速卷積相關研究綜述
2022-05-17 06:01:16黃立波
計算機與生活 2022年5期
童 敢,黃立波
國防科技大學 計算機學院,長沙410073
卷積神經網絡(convolutional neural network,CNN)在計算機視覺、自然語言處理等任務上應用廣泛。越來越多的研究嘗試加速CNN 的訓練和推理,使用快速卷積算子就是其中的重要方法。快速卷積算子包括快速傅里葉變換(fast Fourier transformation,FFT)卷積和Winograd 卷積,這類卷積通過把輸入特征映射和卷積核線性變換到相應的空間,將原來的運算轉換為對應位相乘,運算結果再經過逆線性變換即可得到原特征映射空間的輸出。
在“變換-運算-逆變換”的過程中,乘法運算的次數比直接卷積有可觀的減少,而代價則是加法運算次數的增加。在絕大多數現代處理器上,加法的執行效率遠高于乘法,因此可以使用快速卷積算子來提高模型執行效率。由于FFT 變換是映射到復數空間,Winograd 卷積運算過程中對內存的占用只需FFT卷積的一半,使其迅速成為最流行的快速卷積算子。
但是直接應用Winograd 卷積存在很多挑戰。首先,基本的Winograd 卷積適用范圍有限,僅可在單位步長、小卷積核的二維卷積上應用,在大卷積核上應用則會有數值不穩定的情況。其次,由于線性變換和逆線性變換的復雜性,快速卷積算子在特定平臺上的優化難以實現,比如利用并行性和數據局部性。此外,Winograd 卷積與以剪枝和量化為代表的網絡壓縮技術難以直接結合,因此不易在算力不足和有能耗限制的平臺上部署實現。針對這些問題,研究者做了大量的工作,但至今還未有公開的文章對相關工作進行系統性的總結。為給后續研究者提供參考,本文從算法拓展、算法優化、實現與應用三方面綜述Winograd 的發展,并對未來可能的研究方向做出展望。
1 Winograd 卷積原理
Winograd 于1980 年提出了有限脈沖響應(finite impulse response,FIR)濾波的最小濾波算法。最小濾波算法指出,由拍的FIR濾波器生成個輸出,即(,),需要的最少乘法數量((,))為+-1。以(2,3)為例,涉及到的乘法數量為((2,3))=2+3-1=4,從6 次降低到了4 次。
2015 年,Winograd 最小濾波算法初次被應用在CNN 中,利用減少的乘法次數提升卷積算子性能。如果用矩陣的形式表示Winograd 最小濾波算法,則可以得到:
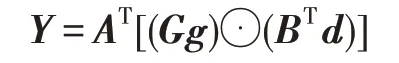
其中,為濾波器向量,為輸入數據向量,為輸出數據向量,表示濾波器變換矩陣,表示數據變換矩陣,⊙表示矩陣的對應位相乘(Hadamard積),表示輸出變換矩陣。通過嵌套一維最小濾波算法(,),可以得到二維的最小濾波算法(×,×):
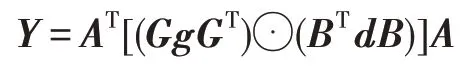
二維最小濾波算法所需乘法數為(+-1),而原始卷積算法需要乘法數為×××。對于(2×2,3×3)而言,乘法次數從36降低到了16,減少了55.6%。
根據二維矩陣形式,可以自然地將Winograd卷積分為四個分離的階段:輸入變換(input transformation,ITrans)、卷積核變換(kernel transformation,KTrans)、對應位相乘(element-wise matrix multiplication,EWMM)和輸出變換(output transformation,OTrans),如圖1所示。
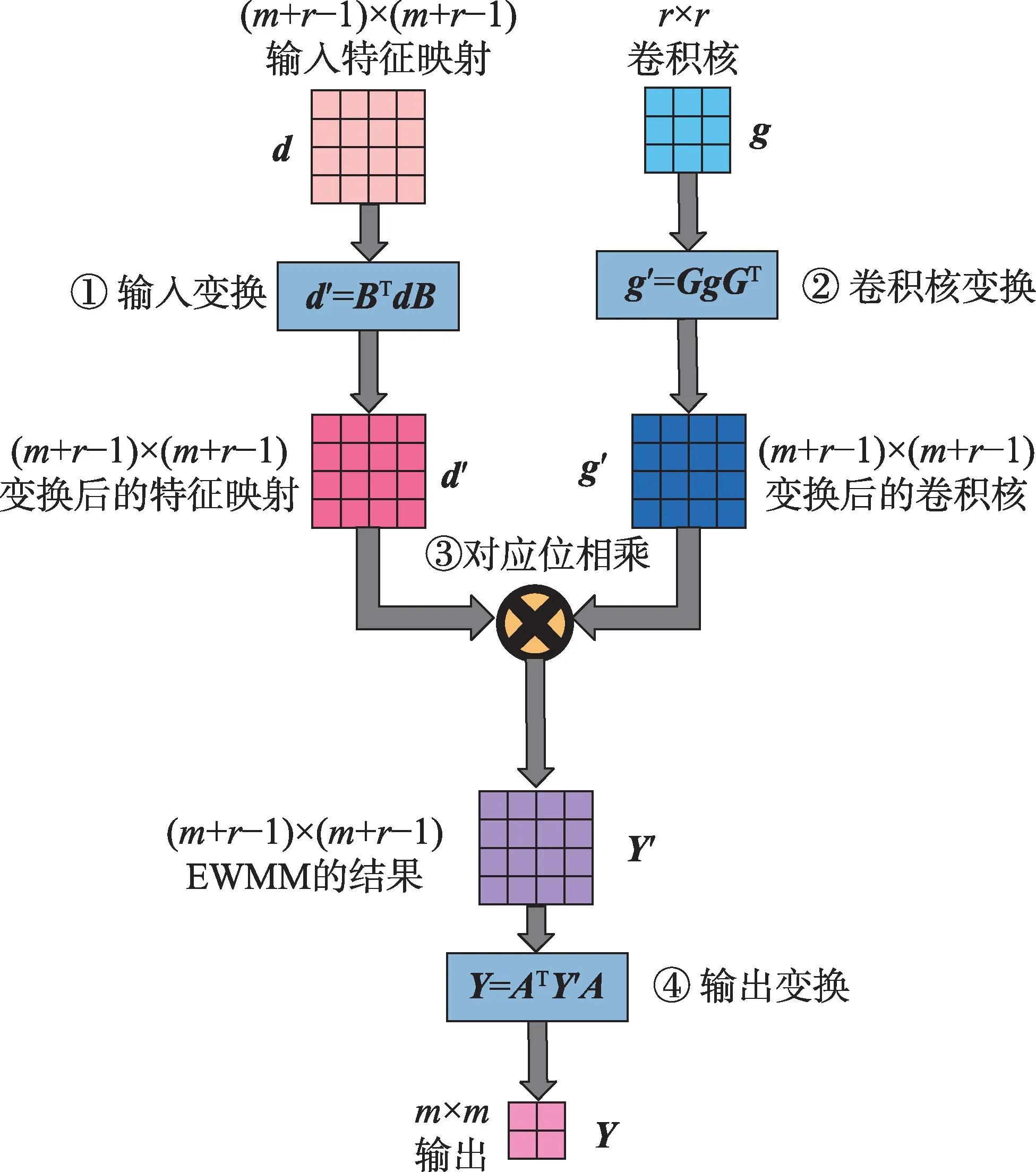
圖1 Winograd 卷積的四個階段Fig.1 Four stages of Winograd convolution
對于二維卷積算子,需要先將卷積輸入劃分為相互重疊的(+-1)×(+-1)的切片,切片之間有-1 的重疊部分。實驗表明,(2×2,3×3)在多個卷積上的實現性能超過了NVIDIAcuDNN,而且使用的內存大小遠低于FFT 卷積。
2 Winograd 卷積的一般化和拓展
2.1 Winograd 卷積的一般化
基本的Winograd 卷積僅支持=3 和=2 的二維卷積算子,且切片大小不超過6,無法滿足現代CNN 中豐富的卷積算子類型,需要對其進行一般化。Winograd 卷積的一般化主要分為四個方向,分別是支持任意維度、支持任意切片大小、支持任意常規卷積、支持特殊卷積。
三維卷積是三維CNN 的主要組件,常用于處理空間相關的信息。通過對一維Winograd 卷積進行嵌套,可以得到其二維形式,重復進行嵌套則可以得到任意維度的Winograd 卷積。Budden 等給出了維Winograd 卷積的一般形式,并將二維Winograd 卷積視為特殊情況在CPU 上實現,但并未實現三維的情況。其他研究者使用了同樣的嵌套方法,并針對特定平臺完成了三維Winograd 卷積的實現。由于不同維度上算法的實現有統一性,Shen 等提出了二維、三維統一的現場可編程邏輯門陣列(field programmable gate array,FPGA)模板實現。Deng 等提出了可變分解方法,支持三維卷積的同時也支持了非單位步長的卷積。
更大的切片大小會減少切片之間的重疊部分,但同時也會帶來更大的數值誤差,因此在對精度要求不太嚴格的場合會直接使用更大的切片尺寸以提升性能。大尺寸的卷積核也在卷積網絡模型中經常出現,通常為了保持Winograd 卷積的精度,這里卷積也會被替換為小尺寸的卷積。Lu 等在FPGA 上評估了大尺寸切片分別在=3 和=5 下的精度情況,實驗表明小的切片尺寸在=3 時可以保持模型的高精度。Huang 等也完成了類似的工作。Mazaheri等則基于符號編程構建了支持不同硬件后端的實現,同時也支持不同尺寸的切片。
此類直接實現的方法會在大尺寸切片和大尺寸卷積核上顯著損失精度,因此將這類卷積分解為更小的卷積成為了研究者常用的方法。Yang 等使用分解方法統一了常規卷積、depth-wise 卷積以及分組卷積,而大切片尺寸、大卷積核卷積和非單位步長卷積也都可以通過分解方法轉換為基本的Winograd 卷積。常用的分解單元實現包括(2×2,3×3)、(2×3,3×3)、(3×2,3×3)、(3×3,3×3)等。Liu 等同樣基于分解方法,在FPGA 上實現了使用相同資源支持任意卷積核大小的Winograd 卷積。利用大卷積核上計算的對稱性,Sabir 等使用近似計算技術支持了=5 大小的卷積核。
包括空洞卷積和轉置卷積在內的特殊卷積常用于圖像分割、超分辨率等領域。空洞卷積的Winograd形式被提出用于支持擴張為2 和4 的情況,原理是擴張輸入變換矩陣的規模。Shi 等通過預定義的分解和交織操作將轉置卷積轉換為多個基本卷積,從而實現了對轉置卷積的支持。
總結Winograd 卷積一般化研究工作相關文獻如表1 所示。通過結合嵌套方法和分解方法,理論上可以實現CNN 中所有卷積的Winograd 卷積形式。
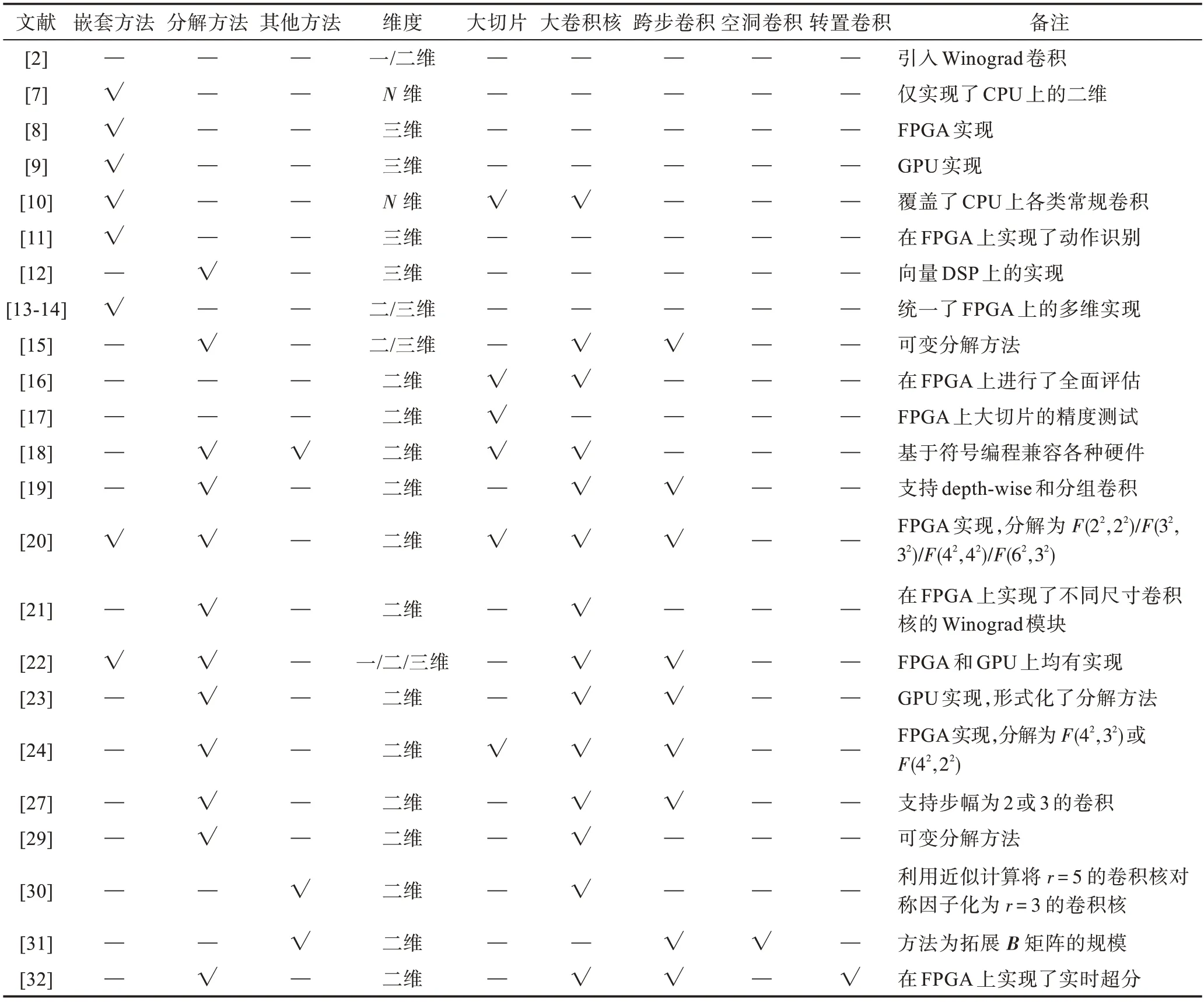
表1 Winograd 卷積的一般化Table 1 Generalization of Winograd convolution
2.2 Winograd 卷積的拓展
除了一般化到各類卷積,還有一些研究嘗試拓展Winograd 卷積本身的線性變換。Winograd 算法族首先將輸入的切片和卷積核線性變換到Winograd域,執行Hadamard 積之后再逆變換回特征映射域。對于指定的卷積核和切片尺寸,線性變換矩陣、、是給定的。卷積可以表示為多項式乘法,將卷積核和輸入向量的元素分別映射到多項式()和()的系數,則輸出向量(和的卷積)的元素等于多項式()=()()的系數。Winograd 卷積算法族基于多項式上的中國剩余定理(Chinese remainder theorem,CRT)對不可約且互質的多項式同余系統內的多項式取余即可得到卷積輸出,對同余方程組進行求解即根據多項式的系數得到線性變換矩陣的具體解。因此,對Winograd 卷積的拓展可以從兩個角度入手:一是使用不同的變換,將運算映射到不同的域;二是采用不同的變換矩陣生成多項式。
Barabasz 等將Winograd卷積算法中使用的卷積多項式拓展為高階多項式,實驗表明使用二階多項式會顯著降低誤差,但同時也會增加乘法次數,因此需要在乘法次數和浮點數精度之間做權衡。Ju等提出的雙線性多項式與此方法原理相同,保持了大卷積核上的數值穩定性。而Meng 等將多項式乘法拓展到復數域,利用共軛復數乘法的對稱性可以進一步減少乘法數量。Liu等提出將余數系統(residual number system,RNS)引入到Winograd 卷積,通過取余的操作實現Winograd 卷積的量化操作,進一步支持更大的輸入切片尺寸而不會引入顯著誤差。Xu等創新地引入了費馬數變換(Fermat number transformation,FNT),使用這種變換一方面可以確保中間運算結果均為無符號數,另一方面還將所有的計算都簡化為移位和加法操作,有利于在FPGA等設備上實現。
根據最小濾波算法的描述,Winograd 卷積已經達到了最少的乘法運算次數。FFT 卷積由于使用了傅里葉變換,在乘法次數和內存占用上遠高于Winograd 卷積,但保持了很好的精度。探索不同的變換可能會引入更多的乘法次數,但若能保持模型精度也是可選的實現技術。而生成多項式的選擇則是在不增加乘法次數的前提下減少了精度損失,且無需修改算法,因此在應用上更具有現實意義。
2.3 其他
Winograd 卷積還被用于和Strassen 算法結合。Strassen 算法是一種減少矩陣運算次數的算法。雖然有研究指出Strassen 算法減少的運算遠小于Winograd 算法,但該工作將在Strassen 算法中使用的卷積替換為Winograd 卷積,結合了兩者帶來的運算減少實現了更進一步的優化。Winograd 卷積也被應用在加法神經網絡上,用加法代替乘法,保持了相當的性能且降低了功耗。
3 Winograd 卷積的優化
3.1 剪枝和利用稀疏性
剪枝是CNN 優化中常用的有效技術。剪枝主要用于對CNN 中卷積算子的權值進行修剪,對輸出影響很小的權值會被置零。剪枝后的卷積核成為稀疏張量,這帶來了兩點好處:一是按照特定的壓縮格式存儲稀疏的卷積核張量權值可以減少內存使用;二是稀疏張量中大量元素為0,因此可以減少卷積的計算量。對于卷積層和全連接層的卷積可以將參數減少90%以上。但在Winograd 卷積上直接應用剪枝是有困難的,因為稀疏的卷積核在變換到Winograd 域后又會變回稠密矩陣,這違背了剪枝的初衷。
Liu 等首 先提出 在Winograd 卷積和FFT 卷積上應用剪枝,在卷積核變換之后引入剪枝以得到稀疏的Winograd 域卷積核。他們在后續的研究中又將線性整流單元(rectified linear unit,ReLU)置于輸入變換之后,結合稀疏的卷積核進一步提升了稀疏性,如圖2 所示,Wang 等也使用了相同的剪枝方法。Li等提出在本地學習剪枝系數,減少了剪枝帶來的精度損失。Lu 等和Shi 等也分別在卷積核變換后引入了剪枝。Yu 等指出,添加ReLU 的方法改變了網絡結構,重訓練的代價也大,因此他們提出在輸入變換前進行結構化剪枝傳遞稀疏性,同時對卷積核進行剪枝。為了兼顧速度和準確性,Zheng 等在Liu等工作的基礎上,提出了動態學習批量的大小。
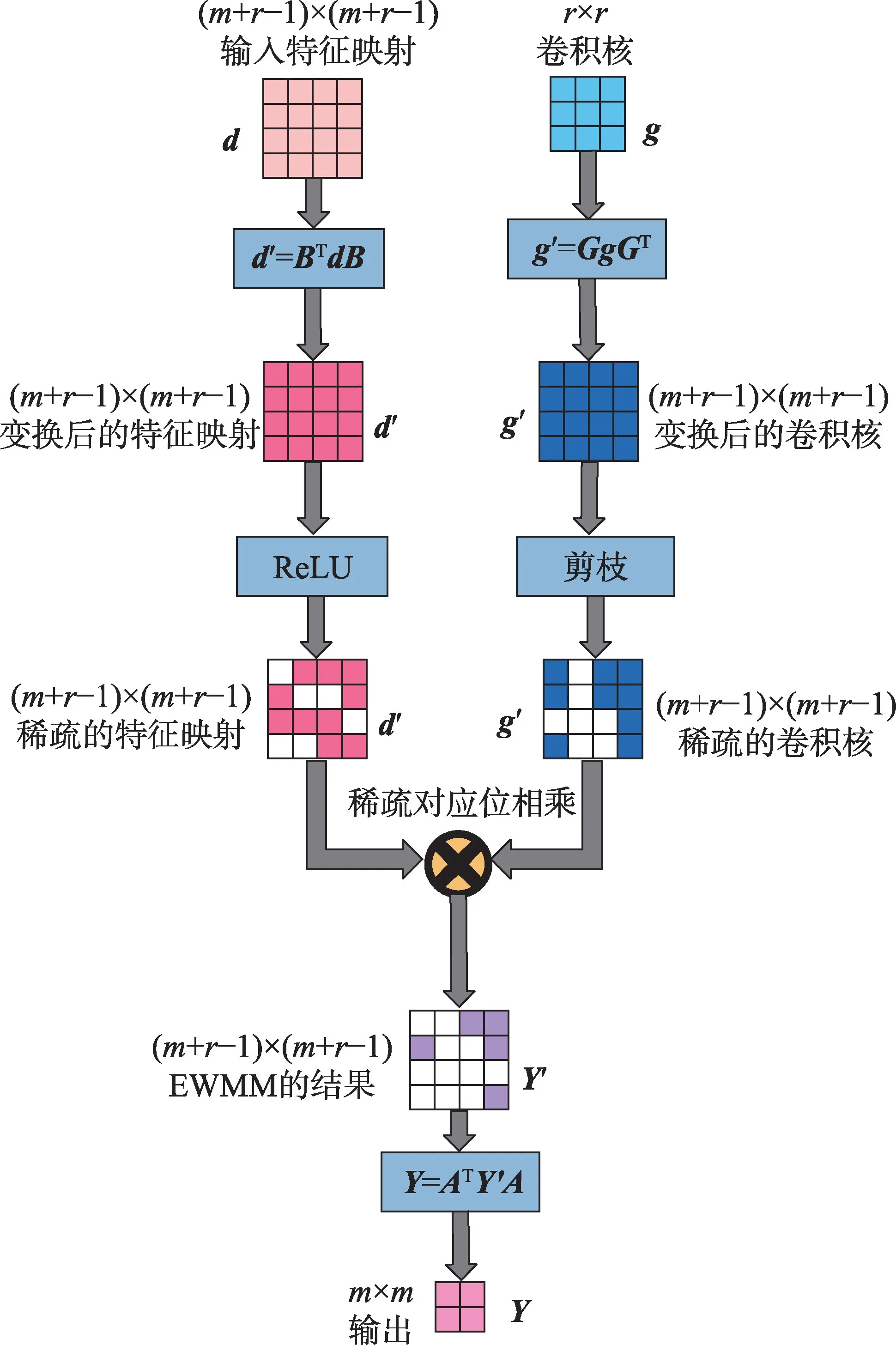
圖2 在Winograd 卷積中應用ReLU 以實現剪枝Fig.2 Pruning by applying ReLU in Winograd convolution
在對稀疏性的利用上,包括計算優化和模型壓縮兩方面。Park 等提出Zero-Skip 技術,軟硬件上分別實現在EWMM 階段計算時跳過零權值,是經典的計算優化方法。Choi 等首次提出了利用Winograd 卷積剪枝的模型壓縮方法,區別于Liu 等工作,他們使用池化代替了ReLU。Yang 等提出了一種規則的剪枝模式,以優化模型的壓縮,Wang 等則是提出了一種新的編碼方式來確保壓縮與解壓縮。
Winograd 卷積的剪枝技術主要相關工作的總結與分析如表2 所示。
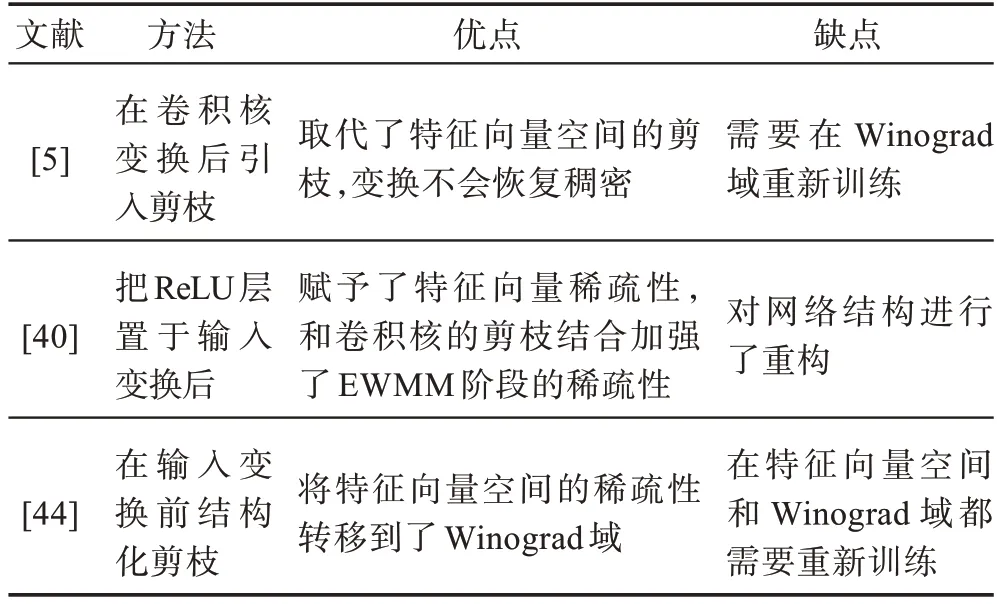
表2 Winograd 卷積中的剪枝Table 2 Pruning in Winograd convolution
3.2 低精度與量化
Winograd 卷積也可以與量化結合,犧牲精度以換取更小的模型和更快的運算速度。Zhuge 等首先使用了8 位定點數的Winograd 卷積,但與16 位定點數相比誤差顯著。Zhang 等使用的精度與他們一致,但引入了細粒度調度,因此在性能上有顯著提升。Meng 等在變換后的卷積核上應用量化,使用精度縮放技術量化到INT8 精度上。Liu 等在把Winograd 卷積拓展到余數系統的同時也使得可以將卷積量化到INT8 精度。Ye 等實現了12 位的混合卷積FPGA 實現,還有一些研究也使用了8 位的量化精度。Han 等還進一步探索了ARMCPU 上的2~8位量化精度。Li等直接在Winograd域插入線性量化,對2~8 位的量化精度進行了全面評估。他們的實驗表明,8 位以下的量化精度會帶來不可忽視的模型精度下降。
對于低精度和量化帶來的精度損失,Fernandez等提出通過學習訓練減少INT8 精度Winograd 卷積的誤差,與剪枝技術中的重訓練原理相同。而Ahmad 等提出對精度損失建模,為特征映射和卷積核使用不同的量化級別。Barabasz用勒讓德基多項式取代Winograd 變換中的規范基多項式,提出基于基變技術的9 位量化精度Winograd 卷積,維持了數值穩定性。Sabir 等在特征映射切片上應用量化,應用粒子群優化技術找到量化的閾值以保持精度。可以根據他們的工作,總結緩解量化帶來的精度損失的方法如表3 所示。

表3 緩解量化Winograd 卷積精度損失的方法Table 3 Methods to alleviate accuracy loss of quantization in Winograd convolution
3.3 數值穩定性
Winograd 卷積在初期只應用在3×3 的卷積核和小的輸入切片上,原因在于Winograd 卷積計算中內在的數值不穩定性。在更大的卷積核或輸入切片上,Winograd 變換的多項式系數呈指數增長,這種不平衡會反映在變換矩陣的元素上,造成很大的相對誤差。Vincent 等指出這種數值不穩定性的來源是變換中大尺寸的范德蒙德矩陣,提出精心挑選出最小指數增長的值相應的多項式,同時對變換矩陣進行縮放以緩解數值不穩定性。
Barabasz 團隊從數學的角度在Winograd 卷積數值穩定性的維持上做了大量工作。他們首先提出使用超線性多項式來構造Winograd 變換矩陣,在運算次數和計算精度之間進行平衡,Ju 等提出的雙線性方法與他們的想法一致;之后他們又提出基變技術,通過額外引入一個正則化變換矩陣,在實現了量化的同時保持了數值穩定性;他們進一步的研究表明,線性變換過程中浮點數乘加的運算順序會影響到結果的準確性,這同樣是由于變換矩陣中元素的指數級不平衡導致的,通過霍夫曼編碼運算順序就可以減少這種誤差,從而允許更大的切片尺寸和卷積核尺寸。
在前文提到的工作中,也有很多研究嘗試優化Winograd 卷積的數值穩定性,總結相關工作的主要思路有四點:
(1)將卷積拆分為小切片或小卷積核的Winograd 卷積,如分解方法;
(2)對Winograd 變換作出修改映射到精度更高的空間,如使用超線性多項式;
(3)選擇變換矩陣生成多項式中相對誤差更小的,如使用變換矩陣最大最小元素比值最小的;
(4)更改計算中乘累加的順序,優先累加乘積更小的結果。
其中分解方法已經大量使用于研究中,而選擇變換矩陣的方法由于無需修改Winograd 卷積算法本身也具備直接應用的可行性。而超線性變換會突破現有Winograd 卷積實現的架構,在數學上論證該方法優越性之前距離實際應用還有一定的距離。
4 Winograd 卷積的實現、優化與應用
4.1 實現
Winograd 卷積帶來的高性能使得研究者們迅速將其部署到各類平臺,除了CPU、GPU 等,還包括對效率和功耗有嚴格要求的FPGA 平臺、移動端和邊緣計算設備。對實現了Winograd 卷積的實現進行統計,得到特定平臺上的研究占比如圖3 所示。
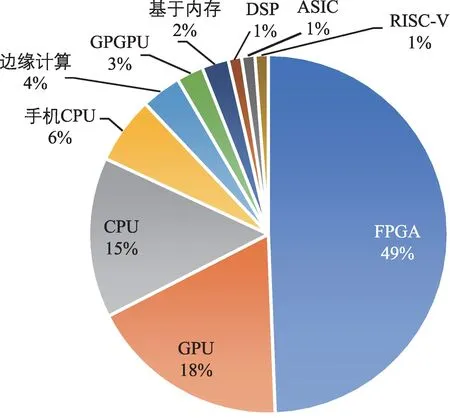
圖3 Winograd 卷積實現的平臺分布情況Fig.3 Platform distribution of Winograd convolution implementation
從圖中可以看到,在FPGA 上的Winograd 卷積實現幾乎達到了總數的一半。這個具有統治地位的比值一方面說明Winograd 卷積在硬編碼的FPGA 平臺上更容易實現并發揮優勢,另一方面也說明越來越多的人工智能應用在向低功耗的平臺上部署。與之類似的是移動端和邊緣計算上的實現,在這類平臺上計算資源十分有限,對功耗的要求也更高,因此Winograd 卷積帶來的乘法數量減少是有重大收益的。CPU 端和GPU 端具備很強的算力,通常用于神經網絡的訓練,因此相關工作也集中在對訓練速度的優化上。而也有部分供應商仍在使用云服務器上的CPU 和GPU 為用戶提供人工智能服務,因此相關研究也具備一定的市場。GPGPU-Sim 作為模擬GPU 的軟件平臺,可以模擬對GPU 硬件的修改,在GPGPU-Sim 上的研究可以為SIMT 體系結構的設計提供方向。
對于上述傳統平臺,部分研究實現了相應的深度學習框架,在其中集成了Winograd 卷積以提升模型執行效率。Perkins實現的Cltorch 是基于OpenCL實現的硬件無關的后端平臺。Xiao 等實現了一個Caffe 模型到FPGA 映射的工具,基于動態規劃選擇是否應用Winograd 卷積。Dicecco 等設計了CPUFPGA 異構平臺上的開源后端框架,但僅支持單位步長的Winograd 卷積。Demidovskij 等還實現了面向Intel 硬件的、支持Winograd 卷積的軟件棧,面向包括CPU、集顯、神經計算棒等生成高效負載。
值得注意的是,除了上述傳統平臺,還有一些研究嘗試將Winograd 卷積部署在其他非傳統平臺上。比如基于內存的計算平臺,Lin 等在ReRAM 上實現了Winograd卷積,基于切片提高了數據重用,而Ghaffar等則基于DRAM 架構實現了8-bit 的量化卷積。隨機計算和近似計算也用于實現Winograd 卷積。Chen 等實現了向量DSP(domain specific processor)上的三維Winograd 卷積。而第五代精簡指令集計算機(reduced instruction set computer-V,RISC-V)指令集作為新流行的開源指令集,同樣吸引了部分研究者在相關平臺上部署人工智能應用。Wang 等通過拓展一條(2×2,3×3)的卷積指令并新增計算模塊,在一個開源RISC-V框架上實現了Winograd 卷積。
4.2 優化
性能是部署在特定平臺上必須要考慮的事情,對于不同的平臺,研究者們采用的優化方法也大相徑庭,現分平臺總結相關優化技術如下。
Heinecke 等將即時(just-in-time,JIT)編譯優化技術用于加速x86 CPU 架構上直接卷積和Winograd卷積在小卷積核上的實現,在編譯過程中提前計算卷積核調用時的地址偏移量。Ragate依賴編譯器的自動向量化,可將計算階段轉換為批量矩陣乘法(batched general matrix multiplication,BGEMM),利用CPU 的高級向量擴展(advanced vector extensions,AVX)指令集實現性能提升。Jia 等提出了CPU 上的自定義數據布局,同樣利用CPU 上的向量化指令實現高效訪存。在數據重用方面,Gelashvili 等利用CPU 的L3 Cache 駐留卷積核實現了對卷積核的重用,但無法支持通道數過大的卷積,而Wu 等利用Winograd 卷積中的相似性也可以實現CPU 上的深度數據重用。
在GPU 上同樣可以將Winograd 卷積的計算階段轉換為批量矩陣乘法,然后調用高效的矩陣乘法實現。Lan 等和Wang 等分別在GPU 上實現了三維Winograd 卷積,但前者的計算階段直接調用了cuBLAS 中的矩陣乘法實現,后者則是手動編寫了特定的實現。Hong 等在大規模GPU 集群上利用Winograd 卷積的數據并行性和切片內并行性實現了多維并行訓練。Jia 等利用MegaKernel 技術將Winograd 卷積的四個階段融合,同時利用精心設計的任務映射算法可在GPU 上達成顯著的性能提升。另外,Yan 等將源代碼和匯編(source and assembly,SASS)級別的匯編器優化用于優化Winograd 卷積,通過合并全局訪存并使共享訪存無沖突,利用緩存設計流水線,提高計算強度,還利用常規寄存器填補了謂詞寄存器不足的缺陷。
與CPU和GPU不同的是,FPGA上沒有高效的神經網絡計算庫可供直接調用,但可定制的特性給予了FPGA 上進行優化更多可能性。Cariow 等首先研究了Winograd 卷積硬件實現的最小需求,并在FPGA 上實現了Winograd 卷積的基本模塊。在數據重用方面,Aydonat 等利用流緩沖區暫存所有的中間特征映射實現了高能耗比的FPGA 實現,而Lu等設計了線緩存結構來暫存特征映射并重用不同切片的數據,并在后續工作中針對稀疏的情況進行了優化。
由于FPGA 可定制化的特性,對計算資源的充分利用是優化的重點。一些研究統一了二維和三維的Winograd,構建了FPGA 上的統一模板。另一些研究聚焦于統一Winograd 卷積和矩陣乘的實現,以最大化模塊的可重用性。對硬件實現方案進行系統評估才能最大化資源利用率并提升計算效率。Ahmad 等和Liu 等還對FPGA 上實現Winograd 卷積進行了全面的設計空間探索。此外,還有其他工作也在FPGA 上實現了Winograd 卷積并對設計空間進行了探索,他們還在設計高效數據布局等方面進行了大量研究。
各個平臺上的優化雖然方法各異,但相互有共同之處。例如,CPU 和GPU 均為多級內存層級體系結構,因此均可利用各級緩存駐留數據實現數據重用。三個平臺上的優化方法總結比較如表4 所示。
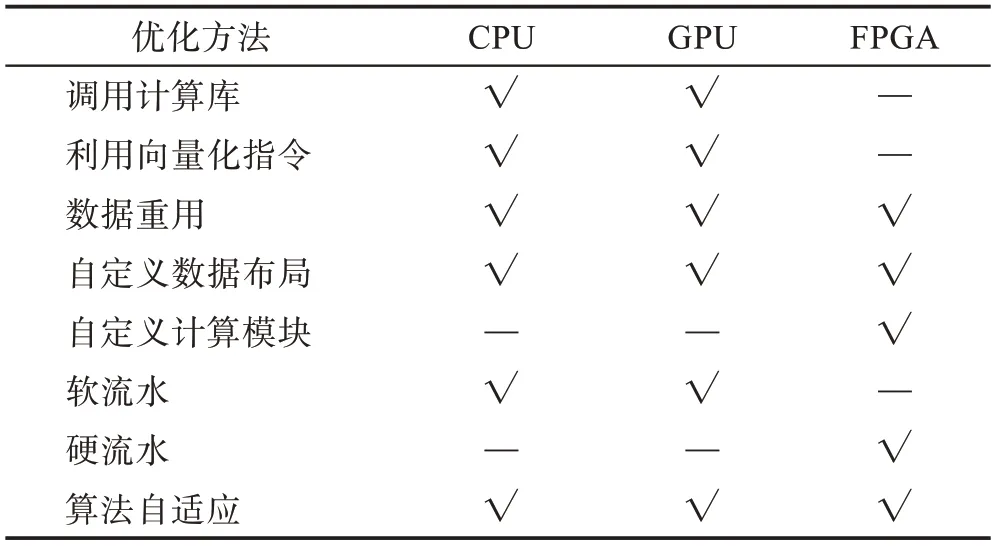
表4 不同平臺上的性能優化方法Table 4 Performance optimization methods on different platforms
4.3 應用
Winograd 卷積提出的初衷是為了實現高性能卷積,但由于其內在的數值不穩定性,初期僅有小卷積核 上應 用Winograd 卷積。CPU 上和GPU 上均有對FFT 和Winograd 的性能進行的比較,他們的結論是一致的,即FFT 在大尺寸卷積核的卷積上性能更好,而Winograd 卷積適用于小尺寸卷積。而Zlateski等指出,隨著CPU 的內存帶寬越來越大,Winograd 卷積的性能優勢也會減少。不過隨著拓展和優化的進一步深入,Winograd 卷積也成為了最適合小尺寸卷積核的快速卷積實現,在各神經網絡計算庫和深度學習編譯框架上均有實現。
Winograd 卷積旨在加速卷積以提高CNN 模型的執行效率,對實時性有要求的場景都可以嘗試使用。Zhuge 等利用混合卷積實現了人臉識別系統。Lou 等基于三維Winograd 卷積實現了用于動作識別的加速器。Shi 等和Yen 等分別將其用于實時超分辨率,但在上采樣上有區別,前者使用的是轉置卷積的Winograd 實現,而后者使用shuffle 層代替了轉置卷積。Yao 等還實現了穿戴設備上的語音識別加速器,應用了一維的8 bit 整數Winograd 卷積網絡。Winograd 卷積的應用不止于此,未來還可以有更多對實時性有要求的人工智能應用Winograd卷積實現,尤其是在移動端、物聯網和邊緣計算設備上。
5 總結與展望
Winograd 卷積是當前應用最廣泛的快速卷積算子。從引入到CNN 至今,其使用范圍隨著研究的深入逐漸覆蓋了現代CNN 中的各類卷積,與剪枝、量化等技術的結合也走向成熟。在各種平臺深度學習框架和神經網絡庫中均已集成Winograd 卷積,可以為各類硬件平臺生成高效的工作負載。
這里對未來的研究方向給出幾點展望。在算法本身的優化方面,數學方法仍然是突破Winograd 卷積局限性的根本方法,由于其內在的最小乘法次數屬性,有望在未來的研究中基本取代現有的基于一般矩陣乘的卷積。現已有從數學角度解決數值穩定性的方法,但由于引入了新的計算機制或額外的步驟,在各平臺上還沒有高效的實現,對硬件友好優化方法的研究可能會是后續研究的重點方向。在實現與應用方面,FPGA 平臺上可以輕松為Winograd 卷積定制軟硬件協同的實現,但現有FPGA 實現對數值穩定性的關注太少。FPGA 實現具備很高的靈活性,可參照相關優化方法率先部署更快更精確的Winograd卷積。由于Winograd 卷積數據流的內在復雜性,在CPU、GPU 這類通用計算平臺上,如何利用好算力和內存層級還有待進一步研究。比如Winograd 四個階段現大多實現為四個分離的計算核,CPU 上已經有研究嘗試利用L3Cache 進行融合。但GPU 上嘗試的融合屬于任務調度層面的融合,利用高速緩存的融合還未有相關研究。GPU 等設備近年都引入了類似TensorCore的高性能運算單元,但Winograd 卷積相關研究均未利用這類部件,因此對新硬件特性的利用也可以成為另一個突破口。此外,在非常規平臺的實現明顯滯后于理論,比如基于內存的計算平臺、開源RISC-V框架上的實現還局限于小卷積核,下一步可以嘗試在這類平臺上實現更一般化的Winograd卷積。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
