加高工程大型水庫移民規劃管理信息系統設計
2022-05-19 12:55:42周海,張星
水利科技與經濟 2022年5期
周 海,張 星
(貴州省水利水電勘測設計研究院有限公司,貴陽 550002)
0 引 言
移民規劃管理工作是一項系統性極強,且操作十分復雜的工作,需要考慮的影響因素較多,因此工作順利開展的難度較大[1]。對于國家經濟發展來講,必須按照規劃在某些區域進行水利工程新建,這樣才能保證該區域的可持續發展。因此,對目標區域的居民進行移民規劃是一直都要面對的問題,當然對于當地的居民來說,即使非自愿但也是不得不進行的工作。對于水庫移民規劃安置是個較困難的工作,需要各層協調溝通,多方面努力才能保證移民的順利開展[2]。上世紀80年代開始,國家開始重視水庫移民規劃安置問題,并且在該領域投入大量的人力和物力用來推動該項工作的開展[3]。從目前實際情況來看,隨著水力資源的不斷開發與利用,水庫移民人員逐年增多,與社會同期發展,帶來了很多不可避免的矛盾。因此,本文設計一套適用于加高工程大型水庫移民規劃管理信息系統,用來彌補水利工程移民研究不足的現狀。
王茂洋等[4]提出了一種基于云計算技術的征地移民信息化管理平臺,用來解決現階段對于水利工程和征地帶來的移民工作中存在的各種問題。首先利用云計算技術構建征地移民信息化管理動態系統,針對移民工作各階段的實際要求,采集居民基本信息并對其進行動態跟蹤管理,利用該系統可以查詢移民后期的人員流動現狀以及生產生活情況,并與初始未移民生活現狀進行對比,實現征地移民工作的智能化和高效化管理,經過實踐證明了該方法的實用性,并已在多個大中小型水庫中使用,但是無法滿足功能設計要求。袁維華等[5]為了驗證地鐵運營資產管理系統的實用性,以北京地鐵為例,基于BIM技術構建,構建北京地鐵信息數據庫,并利用空間管理,對地鐵的設備和維修進行管理,實現系統的智能化管理,利用該系統結合BIM+FM管理模式,實現地鐵安全管理的多平臺融合管理,利用該系統與物聯網技術結合,對地鐵運營資源管理都具有重要的實用價值。
基于以上研究背景,本文從硬件和軟件兩方面,設計水庫移民規劃管理信息系統,從而滿足設計要求。
1 大型水庫移民規劃管理信息系統硬件設計
1.1 設計大型水庫移民規劃管理信息系統總體架構
大型水庫移民規劃管理信息系統的總體架構主要采用Arc SDE開發框架的架構,主要采用服務器模式[6],數據庫主要采用SQL Server服務器,利用ASP.NET-WEB對水庫移民規劃管理信息系統進行開發,實現系統的總體功能。其總體架構圖見圖1。
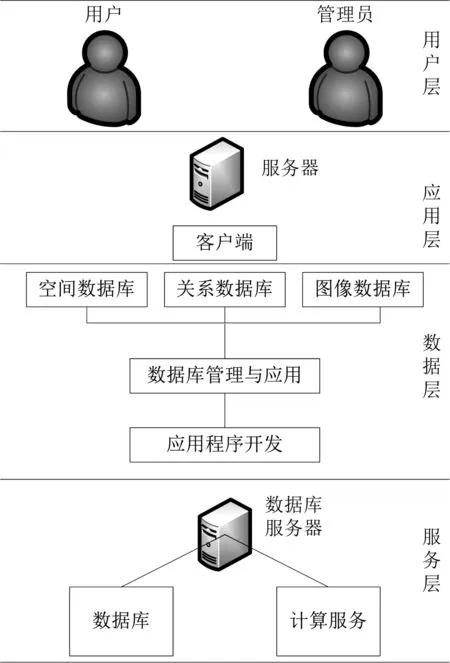
圖1 大型水庫移民規劃管理信息系統總體架構
大型水庫移民規劃管理信息系統總體架構主要分為4個層次,分別是用戶層、數據采集層、應用層和信息服務層[7]。其中,應用層是整個系統架構的核心部分,主要用于服務普通用戶和系統管理員,應用層是實現整體系統軟件運行的終端;數據采集層主要是在用戶層和應用層中間,用戶互聯網數據的采集與分析;信息服務層是整個系統架構中的重要層面,主要負責提供水庫移民規劃管理信息的服務,包括基本網絡服務功能和數據服務功能,以及水庫規劃管理信息管理功能。
1.2 設計水庫移民戶錄入服務器
水庫移民錄入服務器主要完成水庫移民管理的數據庫構建工作,實現對水庫移民各項指標的管理功能。為了對數據庫進行優化處理,利用EAServer進行鏈接緩存[8],避免組件分別操作造成資源的浪費。
根據構建水庫移民戶錄入服務器所需的功能,給出相應的組件結構圖見圖2。
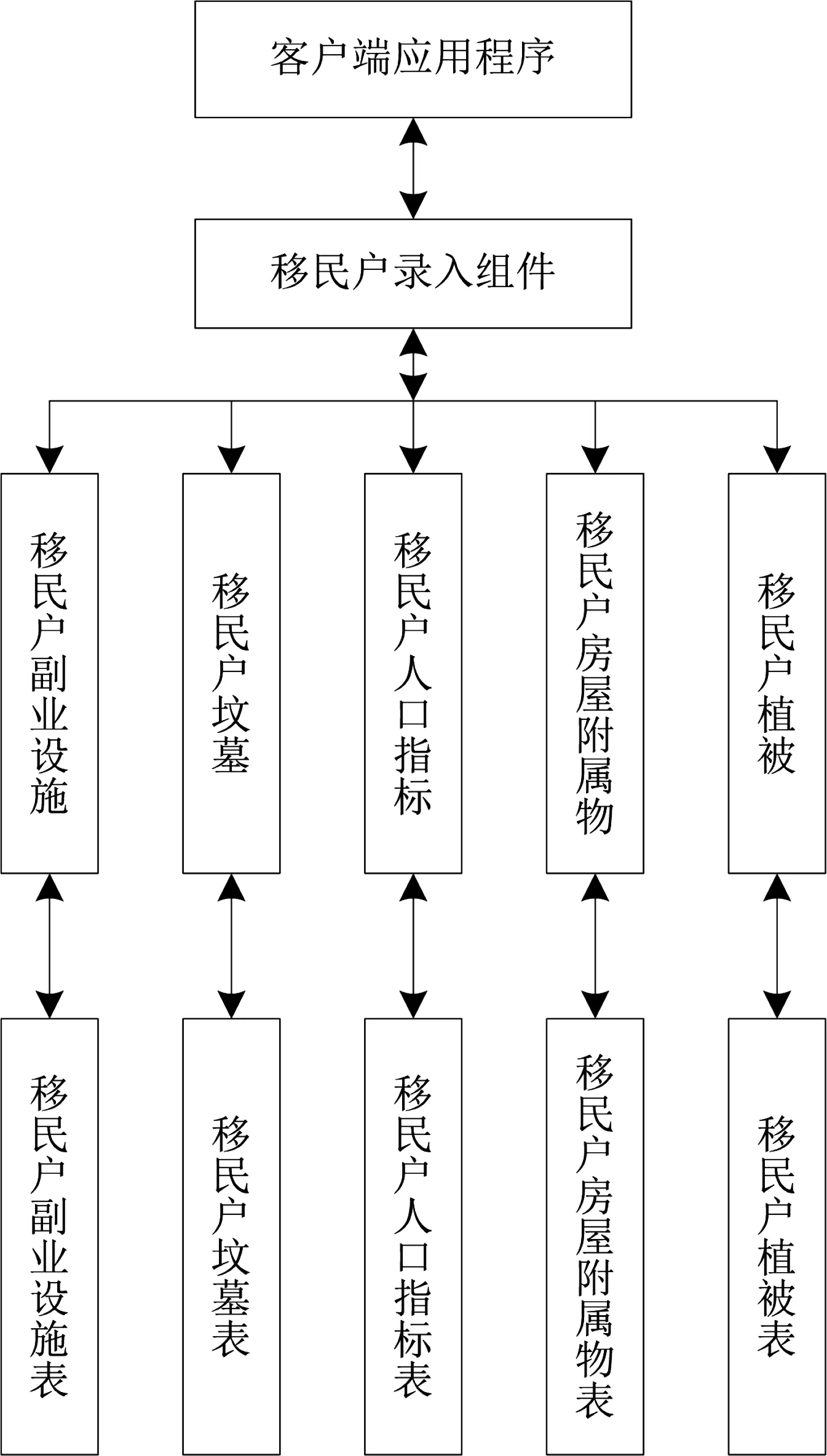
圖2 水庫移民戶錄入服務器組件結構圖
水庫移民戶錄入服務器的組件執行流程如下:
Step1:獲取移民戶信息;
Step2:獲取移民戶的家庭成員信息,以及對應的固定資產和房屋樹木信息;
Step3:根據實際的移民戶的信息,錄入到水庫移民服務器中;
Step4:根據錄入系統的組件結構,獲取相應的移民戶信息并添加到表信息中,通過對移民戶信息的更新實現對實時信息的監控;
Step5:根據需要的組件信息,調用相對應的居民對象,并根據居民現有的信息狀態,通過客戶端引用的方式進行傳遞,通過Retrieve方式實現對遠程數據對象信息的操控;
Step6:調用居民規劃管理信息,完成對應的事務管理,根據組件時間,在操作過程中撤銷數據的居民信息錄入[9],斷開服務器再重新連接。
綜上所述,完成水庫移民戶錄入服務器流程的設計,結合居民實際的規劃管理信息,減少共享帶來的資源消耗,增強錄入服務器的整體性能。
2 大型水庫移民規劃管理信息系統軟件設計
2.1 構建大型水庫影響范圍分析模型
在大型水庫的建設中,通過構建大型水庫影響范圍分析模型,分析水庫建設過程中的影響范圍,其主要包括土地征收的影響、水庫建設區的影響以及水庫建設后的影響。一般來講,大型水庫建設地區的影響可以通過水庫建設過程的影響范圍得到。在水庫的建設中,存在一個大型水庫的死水位區,其中永久淹沒的地區屬于死水位區,而最高水位區不會受水庫的風浪等影響。一般對大型水庫產生影響的是風浪爬高和岸堤的坡度[10],其影響范圍的經驗公式為:
(1)
其中:hf為大型水庫的風浪高度;h為大型水庫加高工程的高度;β為水庫的坡度;vs為水庫內的水流速;d為波浪的流程;λ為影響范圍系數。
假設水庫的防洪水位為MWL,水庫水位最高點的最大流速為Wv,則可以得到加高工程水庫淹沒的最高方程式L,滿足下式:
L=MWL+3.2λ*0.020 8(Wv)5/4*d1/3*tanβ
(2)
根據式(1)和式(2)可以看出,當求出L后,就可以結合空間分析理論[11],對大型水庫影響范圍的加高工程區域進行定位,根據拓撲分析模型,得到大型水庫影響范圍分析模型。其模型的具體功能技術流程見圖3。
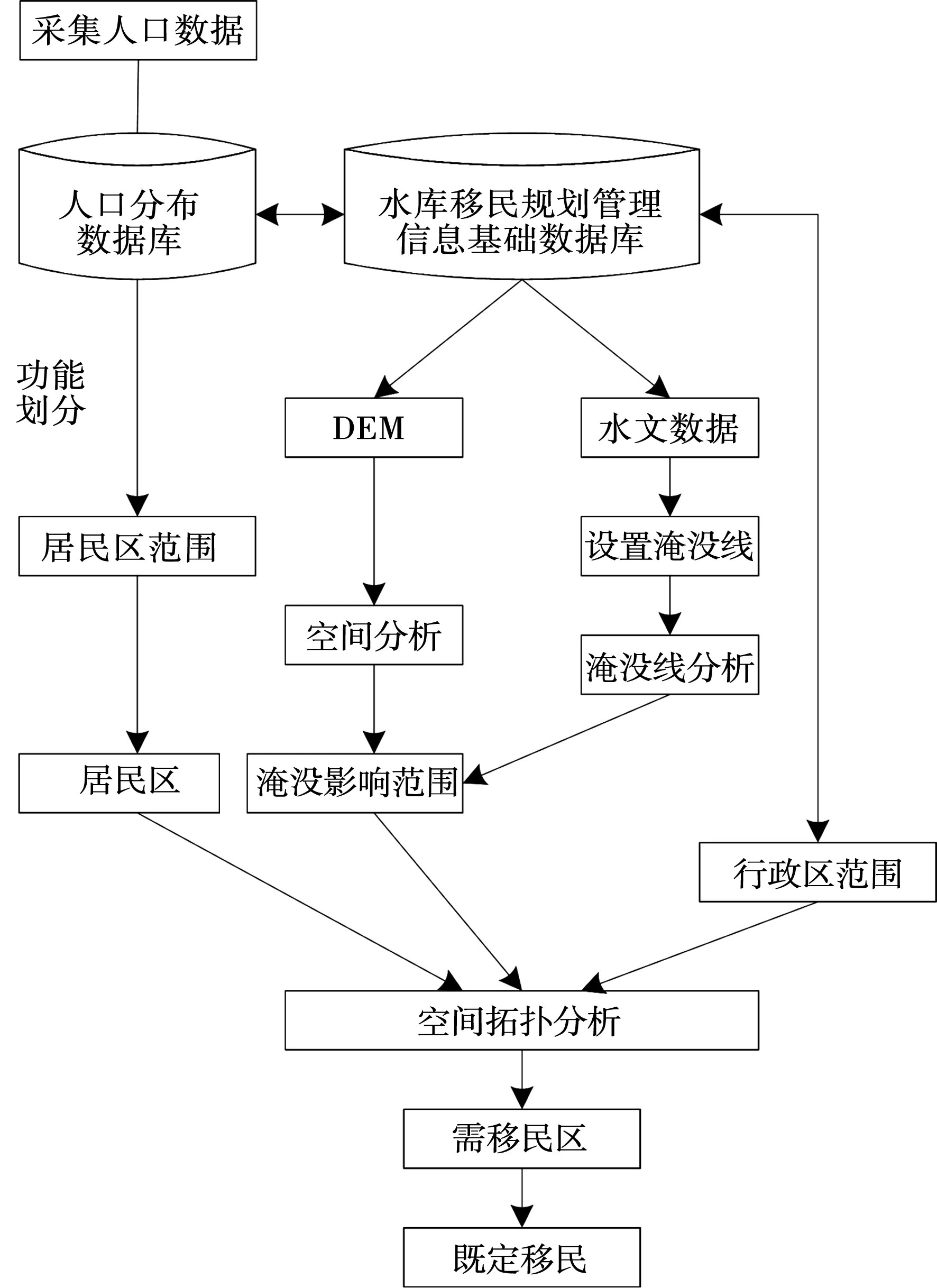
圖3 大型水庫影響范圍分析模型結構
根據以上計算,完成了大型水庫影響范圍分析模型的構建。
2.2 設計水庫移民安置規劃程序
在設計水庫移民安置規劃程序之前,首先要對當地需要移民的人員進行基礎調查,確定從事農業生產的人數,以及從事二、三產業的轉移人員,在安置的過程中,將人員的規劃放在首要位置[12],通過對從事農業和二、三生產失業移民數據的采集,完成其產業安置規劃。移民的首要問題就是建房生存,對安置區的環境和容量進行分析,合理安排移民戶的耕地面積和建房的土地面積,從而確定安置區需要開發的住房面積和耕地面積,完成對移民的生活安置。
基于加高工程大型水庫對周圍的影響,獲取其影響范圍,并通過空間拓撲分析[13],獲取當前安置移民區的實際狀況,獲取當前移民影響的農耕面積和總人口數,即:
(3)
Mx=Mi+Mj
(4)
其中:Mn為移民戶中從事農業的人口數量;Nz為水庫淹沒影響的農用耕地數目;Nzq為影響區未被淹沒的農用耕地數據;Mz為移民區設計中的務農人數;p為人口的增長率;Mj為二、三產業的安置人口數;Mx為待安置的人口數量。
獲取水庫移民的各個產業的安置人口數目,分析水庫移民安置區的農地面積和建筑面積[14],根據實際情況進行合理規劃。水庫移民安置規劃程序的步驟如下:
首先,對需要安置的水庫移民數據進行采集,通過數據庫架構中的SQL Server數據庫,調用需要安置的水庫移民的人口數量以及從事產業的具體情況,對應人口的耕地面積和人口的增長率以及需要安置的建房面積和耕地面積。其次,對備選的水庫移民安置地進行數據調用,包括安置地的可耕種土地面積、可建房面積,并對其進行合理的規劃。再次,對水庫移民安置地的環境進行分析,分析出安置土地的可遷入人口數量和可耕地面積[15],然后對水庫移民的人口數與所需耕地面積進行對應匹配處理。最后,對水庫移民安置程序進行優化配置,將遷入的水庫移民分配到相應的安置區,并進行優化配置,最終得到水庫移民規劃管理信息的遷移圖和安置信息圖,為水庫移民的決策者提供決策參考信息。
3 系統測試分析
3.1 策略分析
在測試本文中水庫移民規劃管理信息系統時,為了達到系統的設計要求,滿足移民過程的管理需要,測試過程分為功能測試和性能測試兩部分。
功能測試是對系統應用過程中的各項功能進行測試,采用服務請求-結果反饋的方式,測試移民規劃管理信息的傳輸量、系統反饋的準確率和響應速度,從而衡量系統功能的健壯性。
性能測試是當多名不同的用戶同時登錄系統時,系統中各項事務的響應時間和吞吐量情況,從而衡量系統性能的優越性。
3.2 設置測試參數
基于3.1中的策略分析,為保證大型水庫移民規劃管理信息系統能夠安全穩定運行,設置參數見表1。
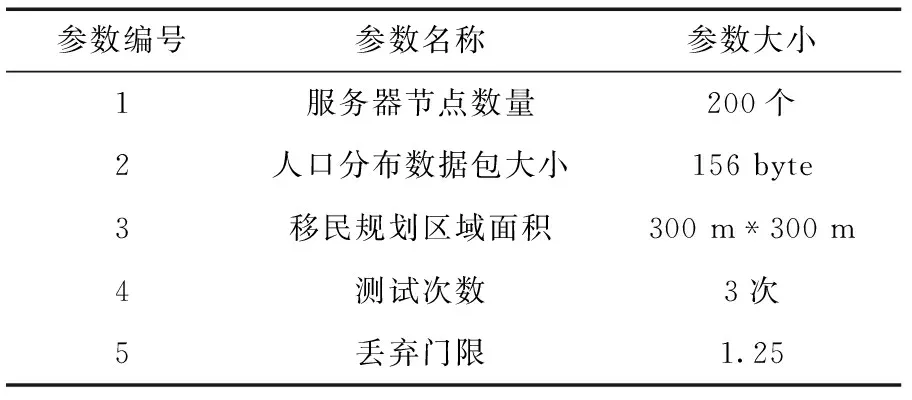
表1 參數設置情況
3.3 設置測試環境
根據系統測試中各項參數的設置情況,設置測試環境見表2。
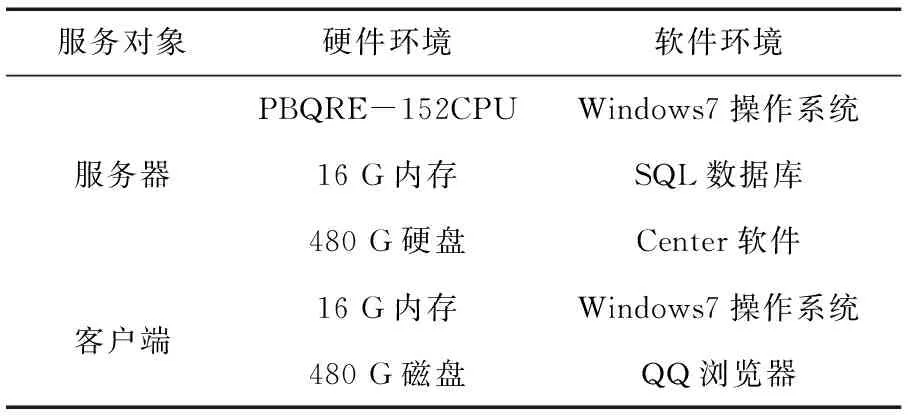
表2 測試環境
3.4 功能測試
規劃管理功能測試中,在系統中隨機選取200名用戶,對移民區域進行規劃管理,分析系統的數據傳輸量、響應情況。規劃管理功能測試狀況見表3。
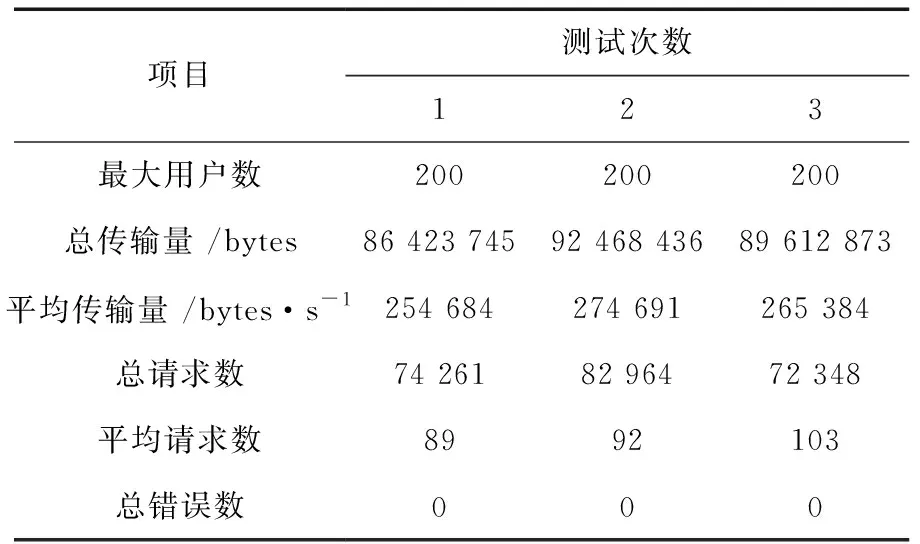
表3 規劃管理功能測試狀況
系統的響應情況見圖4。
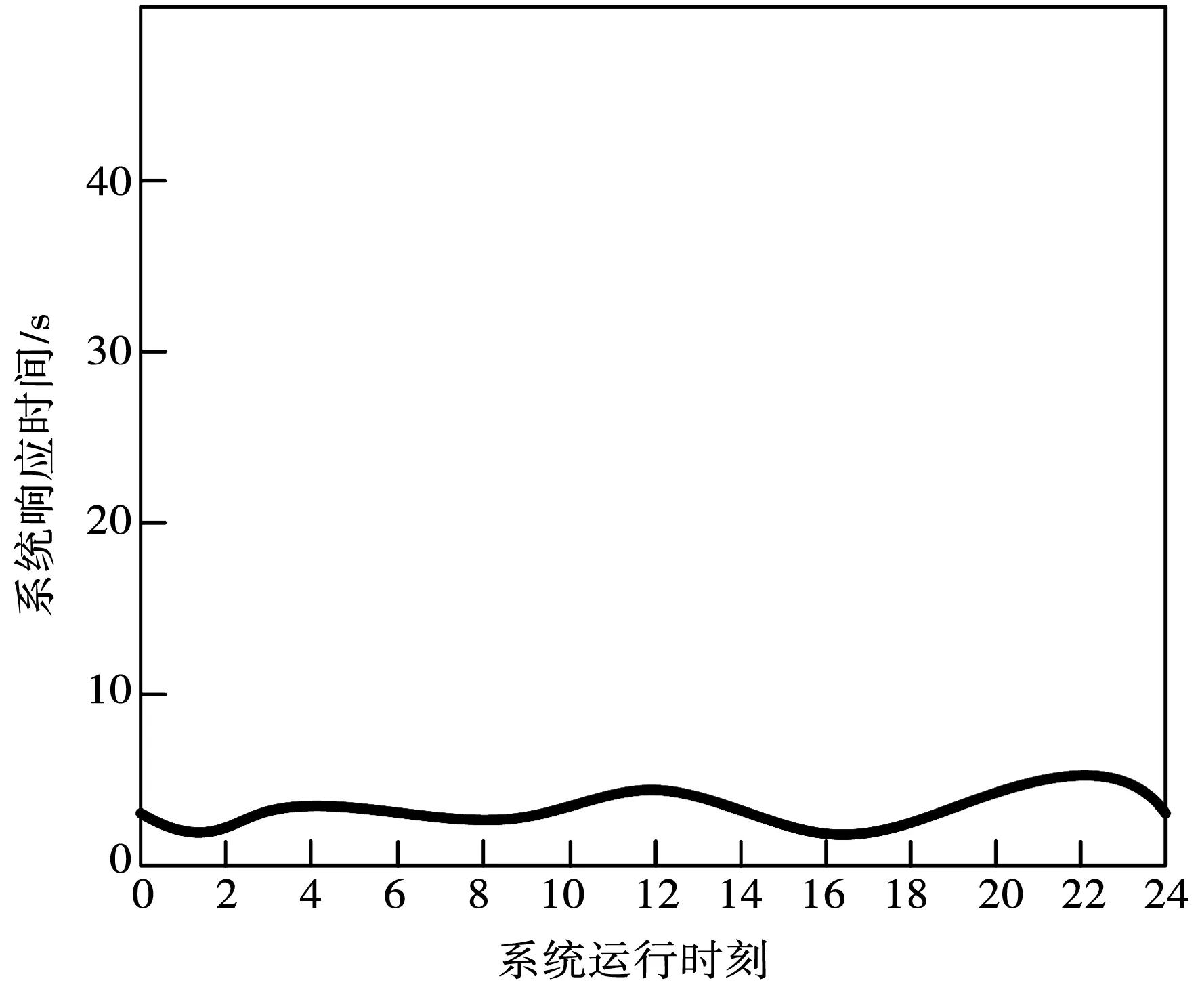
圖4 規劃管理功能測試的耗時情況
經過上述功能測試,當多名用戶同時登錄水庫移民規劃管理信息系統時,移民規劃管理功能的反應速度比較快,回應用戶請求的錯誤率為0%,能夠滿足移民規劃管理信息系統的設計要求。
3.5 性能測試
為了測試水庫移民規劃管理信息系統的性能,模擬50名用戶同時登錄系統時,操作各項事務的響應時間情況,測試結果見表4。
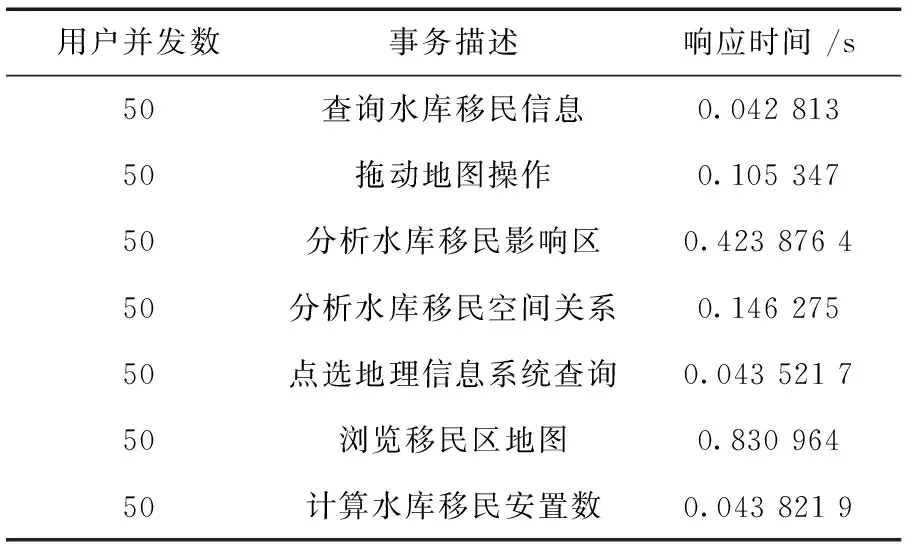
表4 各項事務的響應時間情況
表4的結果顯示,當50名用戶同時登錄系統時,系統的多用戶響應時間比較低,平均響應時間在1秒以內,可以滿足移民規劃管理信息系統的預期設計要求。
水庫移民規劃管理信息系統在一天內的吞吐量情況見圖5。
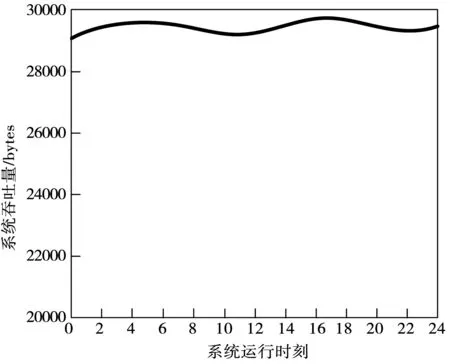
圖5 系統吞吐量測試結果
從圖5的結果可知,水庫移民規劃管理信息系統在運行過程中,系統吞吐量為29 356 bytes。按照系統的網路占用率來看,水庫移民規劃管理信息系統還沒有全部被占滿。
4 結 語
本文提出了加高工程大型水庫移民規劃管理信息系統設計,經測試發現,該系統的功能和性能均可滿足設計要求。但是本文的研究還存在很多不足,在今后的研究中,希望可以針對水庫移民研究內容和理論的零散性展開系統性研究,以彌補文中系統的不足。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
領導決策信息(2018年50期)2018-02-22 06:17:16
家庭影院技術(2017年9期)2017-09-26 03:41:45
商周刊(2017年5期)2017-08-22 03:35:26
中華手工(2017年2期)2017-06-06 23:00:31
中國衛生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
中外會展(2014年4期)2014-11-27 07:46:46
