在線協同研討知識建構行為的自動分析研究*
2022-05-20 01:48:00何皓怡劉清堂關雪敏覃偉華
現代教育技術 2022年5期
何皓怡 劉清堂 張 思 關雪敏 覃偉華
在線協同研討知識建構行為的自動分析研究*
何皓怡1劉清堂2張 思2關雪敏1覃偉華3[通訊作者]
(1.廣西民族師范學院 數理與電子信息工程學院,廣西崇左 532200;2.華中師范大學教育信息技術學院,湖北武漢 430079;3.廣西大學公共管理學院,廣西南寧 530004)
為實現對在線協同研討知識建構過程的動態(tài)跟蹤與分析,文章采用文本分類方法,設計了“在線協同研討知識建構行為自動分析實施流程”。以此流程為指導,文章以網絡研修社區(qū)中教師工作坊的協同研討活動為例開展實驗,主要內容包括創(chuàng)建“教師工作坊知識建構行為編碼表”、采集與整理交互文本數據、選擇和提取文本特征、對訓練集數據進行預處理、訓練和評價分類模型、對分析結果的應用情況進行描述和解讀。實驗結果表明,在線協同研討知識建構行為自動分析方法可為利益相關者深入理解協同知識建構過程并為此過程進行實時干預和調節(jié)提供支持。
在線協同研討;知識建構;文本分類;學習分析

在線協同研討是一種重要的協作學習活動。在在線協同研討的過程中,學習者通過分享、提問、協商等交互活動共同建構公共知識,同時實現個人知識的增長。當前,對在線協同研討過程中的知識建構行為進行分析,常基于相應的編碼系統,采用內容分析方法,以人工編碼的方式把學習活動過程中產生的交互文本數據映射為相應的知識建構行為類型再進行分析研究。但人工編碼方法主觀性較強且費時、費力,分析結果反饋滯后,不利于進行實時的教學監(jiān)測和干預。若能基于文本分類方法實現對文本數據的自動分析,將會極大地提高數據分析的效率,且在教學過程的實時監(jiān)控方面也將發(fā)揮極大的應用潛力。
一 相關研究
對協同研討過程中產生的交互文本進行內容分析,可推斷出文本中的潛在性內容(如元認知、認知行為等[1]),這些內容能為協同知識建構過程提供更有意義的解釋。隨著文本分類技術的快速發(fā)展,研究者開始將此技術應用于內容分析研究,以提高分析的效率。例如,McKlin[2]采用人工神經網絡的方法,基于描述協同知識建構過程的認知存在編碼方案,對學習社區(qū)中學生的討論文本進行分類;L?ms?等[3]基于學生的協作交互文本,采用詞嵌入和具有注意力機制的深度學習方法構建分類模型,自動編碼分析學生協作探究學習的過程;Neto等[4]基于學生在線討論文本,利用相關工具提取文本特征并結合部分與情境相關的自定義特征,采用隨機森林算法編碼分析協作交互文本的認知存在階段,取得了較高的準確率(Accuracy=67%),之后還基于實驗結果解釋、探討了相關特征對認知存在不同階段的預測作用。而在中文交互文本的自動編碼研究方面,甄園宜等[5]基于深度神經網絡算法,構建了面向在線協作學習交互文本的分類模型,取得了較高的準確率(Accuracy=77.42%),但此實驗采用的交互文本編碼方案還較難適用于協同知識建構過程的分析。
綜上可知,現有研究多為對英文文本的自動編碼分析,而如何針對中文文本進行知識建構行為的自動編碼分析還有待進一步研究。另外,當前人工智能系統中存在的“黑箱”、數據偏見、算法偏見等問題,使得可解釋AI日益受到關注[6]。因此,將智能技術融入在線協同研討情境中,實現知識建構行為的自動分析,還要綜合考慮教育領域的應用需求、協同知識建構的過程特征、可用的數據資源、AI算法的適用性等問題,在此基礎上設計適切的分析方法,構建一個可解釋、可信任的教育AI系統。
二 在線協同研討知識建構行為自動分析實施流程的設計
綜合前人的相關研究成果和本研究團隊的相關教學實踐,本研究設計了在線協同研討知識建構行為自動分析實施流程,如圖1所示。

圖1 在線協同研討知識建構行為自動分析實施流程
①編碼系統的選擇與構建。編碼系統用于確定分析單元的歸屬類型,而實現自動編碼分析,需要綜合考慮分析目標與實際的應用需求,將人工智能技術與教育教學理論有機融合,創(chuàng)建一個適應于具體教學情境的編碼方案,在有效反映分析目標特征的同時,又能為計算機實現自動分類提供更為友好的信息,從而達到較好的應用效果。
②數據的采集和整理。本環(huán)節(jié)可采用網絡爬蟲方法采集網絡平臺上的文本數據,并存入相應的數據庫中;之后,可通過數據清洗對“臟數據”進行有效的檢測和修復,以提升數據質量,為后續(xù)的數據處理和分析做好準備。
③特征選擇和提取。本環(huán)節(jié)需著重考慮在線協同研討具有的多主題、跨學科特點,以及協同知識建構過程具有的階段性和交互性特點。因此,文本特征的選擇和提取可考慮從文本數據中獲取語義、語法特征與研討情境特征等——這些特征與研討內容無關,既具有較好的跨情境性,也能為文本分類提供較好的區(qū)分性信息。
④數據預處理。本環(huán)節(jié)需著重解決數據集的類別樣本不平衡問題。為避免因訓練集樣本不平衡而產生分類誤差,需要對數據進行相應處理,以實現數據集中各類別樣本的平衡。
⑤分類模型選擇與評價。分類模型的選擇,應考慮特定領域的風險和需求、可用的數據資源和現有的領域知識、機器學習模型的適用性是否滿足待處理計算任務的要求等因素。結合教育領域對可解釋AI的需求[7],本環(huán)節(jié)應優(yōu)先選擇標準的可解釋模型。分類模型的訓練需要經過反復調試與比較,以提升其計算性能和精度。分類模型的檢驗與評價,可從分類準確率(Accuracy)、與人工分析的一致性和跨情境性等方面來進行。
⑥結果的應用及解釋。本環(huán)節(jié)重在應用分析結果解釋特征變量與知識建構行為類別的關系,增強使用者對模型的信任度并深化其對協同知識建構過程的認知,讓使用者能夠理解、信任和有效管理整個過程。另外,自動分析方法提升了分析的效率,可與相關工具軟件結合,及時、可視化地呈現教學的過程或狀態(tài)等,從而為協同知識建構過程的干預和調節(jié)提供支持。
需說明的是,當在線協同研討知識建構行為自動分析進行到第六個環(huán)節(jié)時,應根據具體的應用效果,于必要時返回到之前的環(huán)節(jié)并對相關環(huán)節(jié)進行優(yōu)化與調整,以滿足實際的應用需求。
三 實驗與結果討論
本研究按照在線協同研討知識建構行為自動分析實施流程,以網絡研修社區(qū)中教師工作坊的協同研討活動為例開展實驗,旨在基于教師在線協同研討過程中產生的交互文本,來探討對知識建構行為進行自動分析的實現過程。
1 編碼系統的選擇與構建
本研究在選擇與構建編碼系統時,著重考慮了以下三個方面的問題:
(1)網絡研修協同研討活動的相關特點
在網絡研修協同研討活動中,教師研討的話題多為其在教學實踐過程中關注的問題。教師通過在線協作,推動問題的解決;同時,教師在吸納彼此思想的基礎上共同構建一種新的理解,這種理解對教學實踐可能具有重要的參考價值。此外,教師在此過程中進行自我反思,不斷發(fā)展其實踐性知識,進一步提升了個人的專業(yè)知識和能力。因此,應將教師的教學反思和共同體新知識的構建作為網絡研修協同研討活動的關注重點。
(2)對IAM的認識
交互分析模型(Interaction Analysis Model,IAM)是一個可靠而友好的模型[8],它將協同知識建構的過程劃分為分享觀點、認知沖突、意義協商、檢驗修正、達成應用等五個階段。在應用過程中,IAM可通過分析低階、高階心智功能行為的出現頻率,來評價小組的交互能力和質量。而要促進協作過程中高階心智功能行為的出現,階段1(分享觀點)和階段2(認知沖突)帖子的出現是關鍵。在階段1中,經過分享、比較、澄清所達成的共同理解有利于協作意義的生成和學習[9]。在階段2中,參與者認知的不協調、觀點間的不一致可以促進交互的深度[10]。
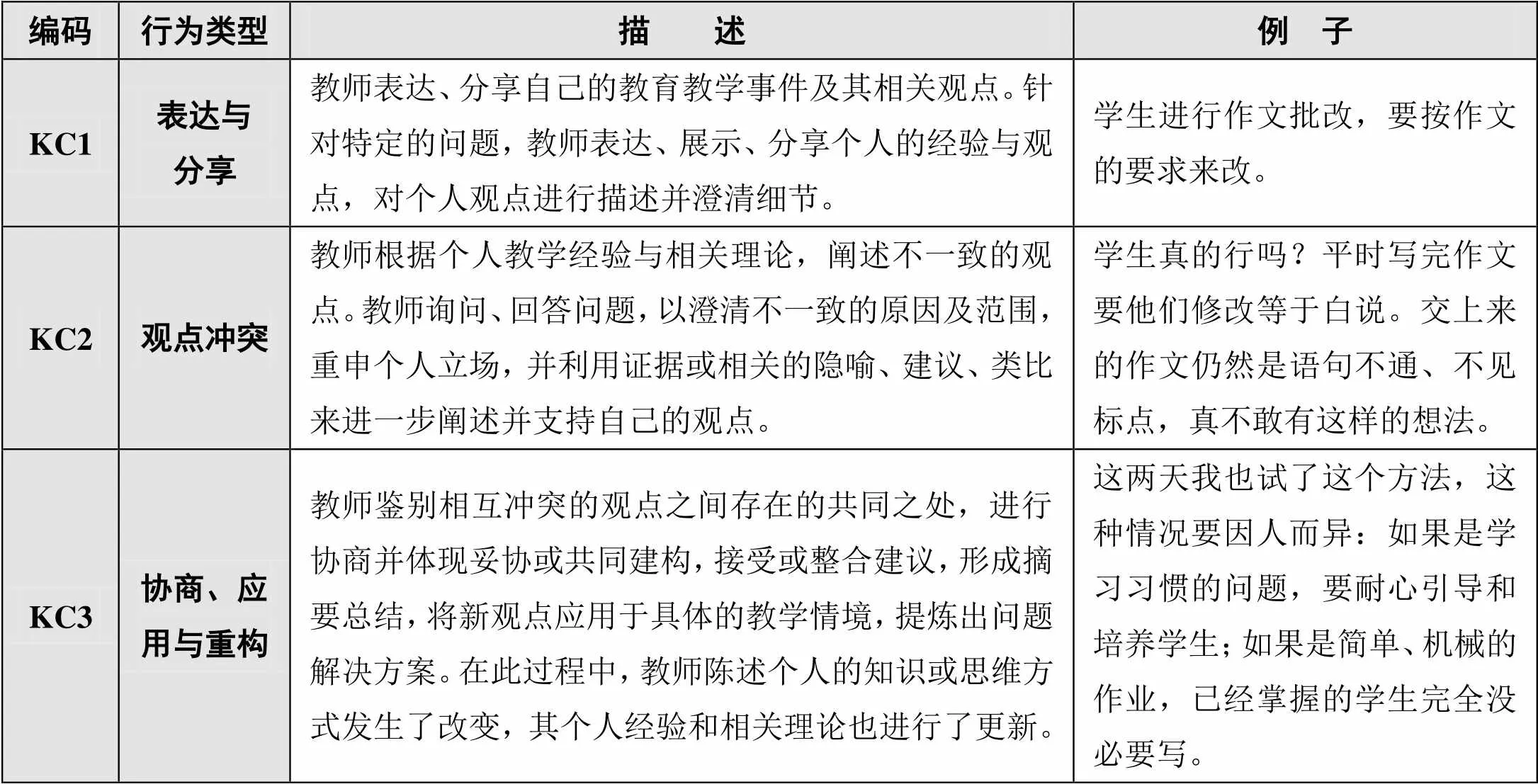
表1 教師工作坊知識建構行為編碼表
(3)人工智能技術的相關特征
目前,人工智能技術還屬于弱人工智能,其應用僅適用于規(guī)則十分明確的、定義十分清晰的任務[11]。因此,在編碼方案中對類別的劃分和描述應具有良好的區(qū)分性,如此才有利于機器算法提取各類別樣本的相關文本特征,從而提升文本分類模型的準確率。另外,訓練集類別樣本分布的平衡性也是影響文本分類模型準確率的重要因素。
考慮到上述問題,結合分析目標和實際的應用需求,本研究邀請10名相關專家參與構建“教師工作坊知識建構行為編碼表”的訪談,并結合訪談反饋進行綜合分析。參考IAM,指導者在協同研討過程中應重點監(jiān)控階段1和階段2帖子的出現情況,以促進學習者高階心智功能行為的出現,并據此對交互過程及其質量進行分析、評價,由此得到最終的編碼表,如表1所示。
2 數據的采集和整理
本研究采集了網絡研修社區(qū)中A小學語文教師工作坊中的評論數據作為訓練集。該教師工作坊中有1名坊主、2名輔導教師和92名學員,其網絡研修活動持續(xù)了3個多月。具體的活動分三個階段實施:①案例研習階段,教師通過觀摩教學案例,確定此次活動的研討主題為“學生參與作文批改,效果是不是更好些?”②實踐探究階段,教師在線下驗證相關觀點和方法、在線上分享實踐的體會與疑惑,大家共同協商推動問題的解決。③總結反思階段,教師反思自己的教學實踐,分享研修心得。本研究采集了此次網絡研修活動中的過程數據,得到1773條文本評論;同時,還采集了D小學數學教師工作坊中的評論數據作為測試集,研討主題為“怎樣對待不完成作業(yè)的學生?”,得到651條文本評論。之后,按照“教師工作坊知識建構行為編碼表”,以消息為分析單元,對上述訓練集和測試集進行編碼,得到數據分布情況,如表2所示。

表2 對訓練集、測試集進行編碼后的數據分布情況
3 特征選擇和提取
教師工作坊中研討的主題多樣,這就對文本分類模型的泛化能力和情境遷移能力提出了要求。另外,還需考慮文本特征對目標類型的可解釋性,以加深對知識建構行為的認識和理解。基于此,本研究擬選擇和提取交互文本的語言探索與詞計數(Linguistic Inquiry and Word Count,LIWC)特征和研討情境特征作為分類算法的輸入變量。
(1)LIWC特征
LIWC特征是指使用LIWC工具來抽取的交互文本的語言心理特征。本研究通過“文心”(TextMind)中文心理分析系統[12],從上述訓練集和測試集中獲取到102個中文語言心理特征。
(2)研討情境特征
研討情境特征可理解為一個帖子在整個討論線程情境中的位置特征,主要包含——
①帖子深度:取一個整數值,代表帖子在整個討論線程中的時間順序位置。
②回復帖類型:取一個布爾值,標識該帖是對主題帖的回復還是對其他帖的回復。若是對主題帖的回復,則取值為0;若是對其他帖的回復,則取值為1。
③回復數:取一個整數值,代表一個帖子所獲得的回復消息數。
④回復帖與主帖的相似度:是指回復帖內容與所回復的主帖內容經計算取得的余弦相似度值。通過本特征可以判斷,回復帖在多大程度上建構在主帖的信息之上。
⑤嚴格時間順序帖與上一帖的相似度:將每個帖子放置在一條時間線上,然后嚴格按照其創(chuàng)建時間進行排序,而不考慮其引用及其與其他帖子的關系,如圖2所示。排序完成后,計算帖子與其上一帖的余弦相似度值。通過本特征可以判斷,帖子在多大程度上建構在上一帖的信息之上。
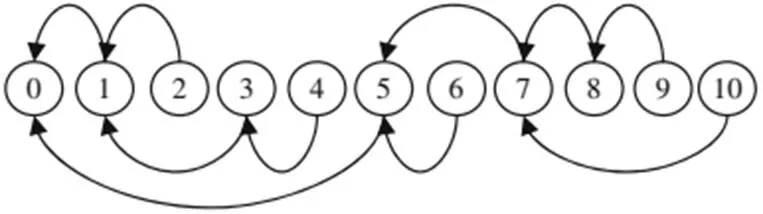
圖2 按嚴格的時間順序進行排序的帖子
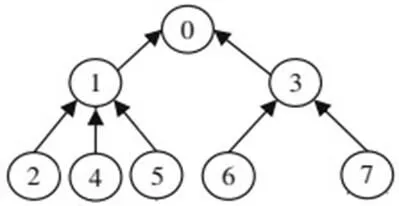
圖3 按語義時間順序進行排序的帖子
⑥語義時間順序帖與上一帖的相似度:語義時間順序跟蹤共享思想的討論,靠討論線程將相關帖子組織起來,再依據時間順序對相同層級的帖子進行排序。如圖3所示,2、4、5號帖在同一討論線程內處于同一回復層級(都是對1號帖的回復),在此可按創(chuàng)建時間對這三個帖子進行排序。帖子的語義時間順序,反映了子話題隨著時間推移的發(fā)展情況。排序完成后,計算該序列內帖子與其上一帖的余弦相似度值。
4 數據預處理
由于訓練集中三種類型的樣本在數量上存在較大差異,為避免因訓練集樣本不平衡而產生的分類誤差,需要對數據進行預處理。本研究中的訓練集帖子總數為1773條,平均分布在各行為類型中的帖子數量應有591條。為此,本研究采用SMOTE算法[13],過采樣分別增加KC2、KC3的樣本數452條、203條;欠采樣則減少KC1的樣本數655條,以實現各行為類型最終帖子數量的平衡,如表3所示。

表3 訓練集數據預處理
5 分類模型選擇與評價
(1)模型選擇
建立分類模型時,本研究選用隨機森林(Random Forest)算法,它是以決策樹為基本分類器的一種集成學習方法,在文本分類領域應用廣泛。該算法是一種白盒算法,可度量特征的重要性[14];此算法中,平均精度下降(Mean Decrease Accuracy,MDA)利用置換袋外數據(Out-Of-Bag,OOB)計算變量的重要性,MDA值越大,說明變量越重要。實驗中使用R語言的randomForest包來運行隨機森林算法,并結合importance()函數來度量并輸出變量的重要性值。
(2)模型訓練與評價
在應用隨機森林算法構建分類模型的過程中,有兩個待確定的重要參數:決策樹數量ntree和隨機分割變量數mtry,它們都對模型的分類精準度有一定的影響。參考Geurts等[15]的研究成果,本研究將ntree值設為1000。而對于mtry值,本研究通過逐一比較其不同取值,選取OOB誤差值最小時的mtry值作為最佳取值。據此,本研究選取了17個不同的mtry值(即1、3、5、7、9、11、13、15、21、32、43、54、65、76、87、95、108)用于實驗計算,結果如圖4所示。圖4顯示,在訓練集中最佳模型所獲得的準確率是0.887、Kappa值為0.830,此時mtry值為9。一般認為,如果Kappa值>0.75,則編碼結果間具有極好的一致性[16]。綜上可知,當ntree參數取值1000、mtry參數取值為9時,訓練得出的隨機森林模型自動分類結果的信度較高。
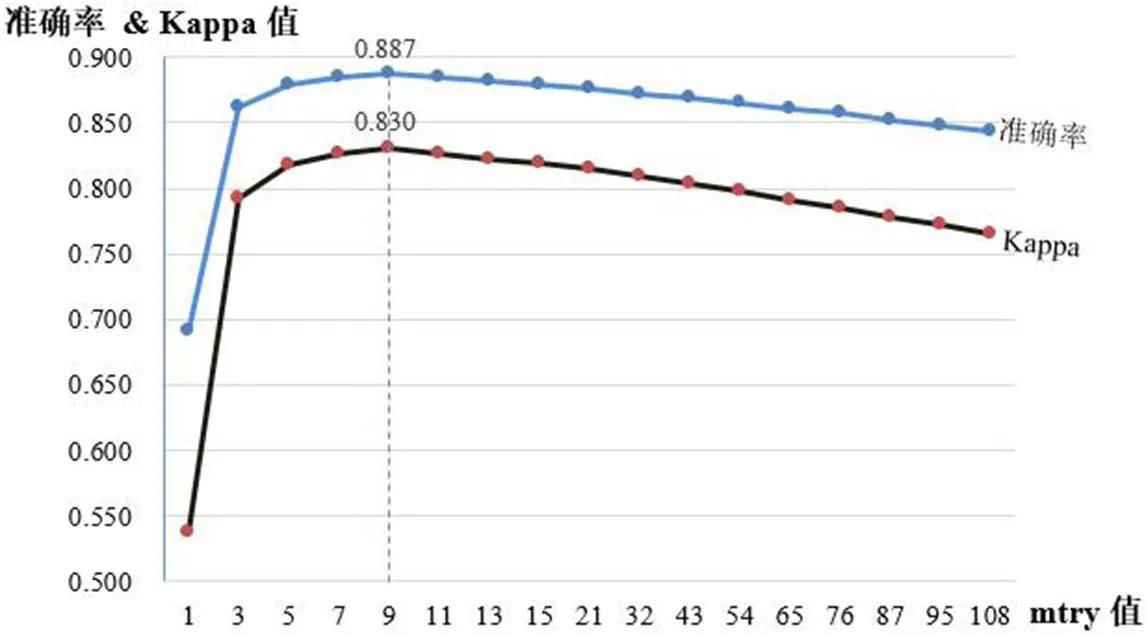
圖4 隨機森林mtry值選擇的實驗計算結果
此外,本研究還應用跨情境的測試數據集來評估訓練得出的分類模型的泛化能力。該模型在測試集上的分類準確率為0.756、Kappa值為0.502。一般認為,如果Kappa值處于0.40~0.75之間,則編碼結果間具有良好的一致性[17]。由此可以推斷,該模型能較好地適用于跨情境分類。
6 結果的應用及解釋
(1)特征重要性分析
依據隨機森林算法中MDA值的大小,本研究排列出影響知識建構行為分類的重要特征變量,得到MDA值排在前3位的LIWC特征,如表4所示。
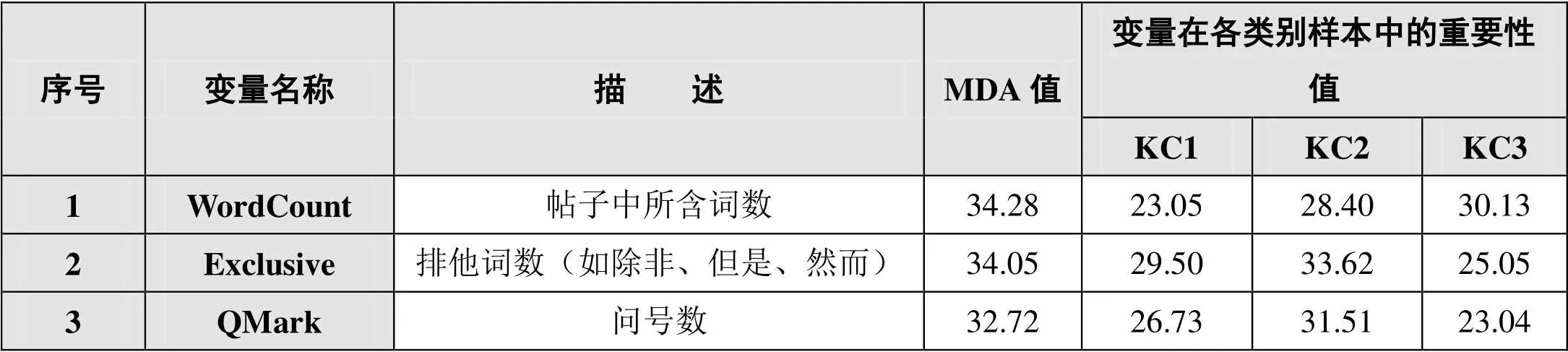
表4 MDA值排在前3位的LIWC特征
①帖子中所含詞數(WordCount)特征:與KC3(協商、應用與重構)行為緊密相關。Joksimovic等[18]的研究表明,該特征體現出了帖子語言結構的復雜性,可推斷出認知探究和認知加工的增長。②排他詞數(Exclusive)特征:與KC2(觀點沖突)行為緊密相關。通過在訓練語料中查看相關帖子,可以發(fā)現排他詞的使用能反映說話者嘗試發(fā)表具有區(qū)分性的觀點,或者表明說話者發(fā)表了不一致的觀點。③問號數(QMark)特征:與KC2(觀點沖突)行為緊密相關。問號多出現在問句當中,結合訓練語料的分析可以發(fā)現:問號的出現,體現了該帖子是針對相關觀點提出質疑或提出問題。以上分析結果能為協同知識建構活動的角色腳本設計提供參考[19],有利于相關角色或參與者準確表達各自觀點,進而促進在線協作學習的有效性。
依據隨機森林算法中MDA值的大小,本研究得到排在前3位的研討情境特征如表5所示。
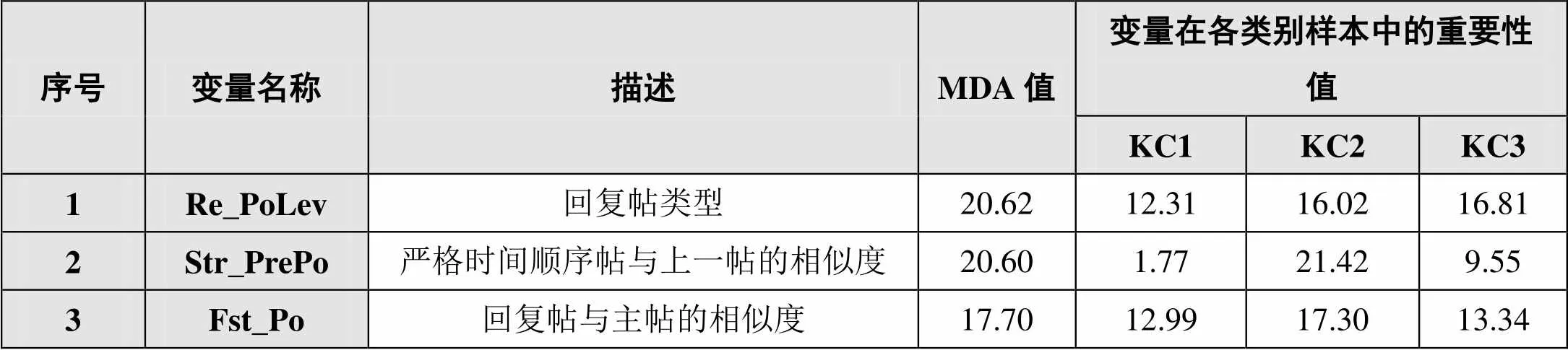
表5 MDA值排在前3位的研討情境特征
①回復帖類型(Re_PoLev)特征:與KC3(協商、應用與重構)、KC2(觀點沖突)行為有較高的相關度。查看訓練語料可以發(fā)現,回復帖若是對非主題帖的回復,則該帖大概率屬于KC2、KC3類別;若是對主題帖的回復,則該帖很有可能屬于KC1類別。由此可以推斷,教師在進行協同研討知識建構的過程中能基于研討主題分享觀點,能針對他人的觀點提出不一致意見或進行協商建構新知識。②嚴格時間順序帖與上一帖的相似度(Str_PrePo)特征:與KC2(觀點沖突)行為緊密相關。查看訓練語料可以發(fā)現,當本特征值較小時,該帖屬于KC2類別的可能性較大;而當本特征值較大時,該帖屬于KC1、KC3類別的可能性較大。由此可以推斷,教師常引用按嚴格時間順序的上一帖的相關內容,來分享觀點或協商建構知識。③回復帖與主帖的相似度(Fst_Po)特征:與KC2(觀點沖突)行為緊密相關。查看訓練語料可以發(fā)現,當本特征值較大時,該帖屬于KC2類別的可能性較大。由此可以推斷,教師常通過直接回復他人帖子并引用該帖子中的相關內容來發(fā)表不一致的觀點,體現出教師在發(fā)表不一致觀點時有較強的針對性。引用異議帖子中的相關內容并直接回復,這種謹慎而有針對性地發(fā)表不一致觀點的方式,有利于學習共同體中良好協作氛圍的營造,進而促進知識的意義建構。通過以上分析可知,研討情境特征在知識建構行為分類中具有一定的重要性,因此對帖子進行編碼分析時,結合上下文情境是非常有必要的,這有利于提升編碼的信度和效度。
(2)知識建構行為的序列分析
基于自動編碼獲得的結果,利益相關者可以便捷地使用滯后序列分析法(Lag Sequential Analysis,LSA),對交互行為序列及模式進行分析,進一步探究學習者認知水平與互動行為之間的關系,為研修過程的干預和調節(jié)提供支持。本研究利用滯后序列分析軟件GESQ 5.1,計算出交互行為類型的調整殘差值(Z-Score)。一般來說,如果Z-Score值>1.96(<0.05),則表示從起始行為到目的行為之間的轉換具有顯著意義[20]。

圖5 網絡研修各階段的知識建構行為轉換情況
本實驗中A小學語文教師工作坊中開展的網絡研修活動經歷了三個階段,各階段的知識建構行為轉換情況如圖5所示。此次網絡研修活動始于案例研習階段,教師通過觀摩案例對相關教學問題進行探討,并討論解決問題的理論和方法;當有教師提出不一致的觀點和意見時,他們會反復探討、辯解與協商(KC2→KC2,KC3→KC3)。在實踐探究階段,教師在線下開展實踐、線上提出疑惑并分享觀點,教師就分享的教學事件及其相關觀點進行探討、詢問或辯解(KC1→KC2);通過觀點的“碰撞”,教師提出協商、接受或整合建議,在具體教學情境中修正、提煉問題解決方案等(KC2→KC3,KC3→KC3);在交互過程中,教師的知識建構水平逐步提升(KC1→KC2→KC3)。而在總結反思階段,教師對整個研修活動進行總結,積極分享自己的研修心得,交流、反思、總結自己的教學實踐和研修收獲(KC1→KC1,KC3→KC3)。
四 結語
為了實現對在線協同研討知識建構過程的動態(tài)跟蹤與分析,本研究首先設計了“在線協同研討知識建構行為自動分析實施流程”;然后,基于此流程實現了對網絡研修社區(qū)中教師工作坊協同研討過程知識建構行為的自動編碼分析,并將分類模型應用于跨情境的測試數據集中,取得了較好的分類效果(分類準確率為0.756、Kappa值為0.502);最后,對實驗結果的應用情況進行了探討。本研究發(fā)現,交互文本的語言心理特征和研討情境特征在知識建構行為的不同類別樣本中具有不同的表現形式,這可為利益相關者深入理解協同知識建構過程并對此過程進行實時干預和調節(jié)提供支持。后續(xù)研究將增大在線協同研討知識建構行為自動分析方法的應用范圍,進一步對分類模型的泛化能力進行驗證,以提升其應用價值。
[1]Henri F. Computer conferencing and content analysis[A]. Collaborative Learning Through Computer Conferencing[C]. Berlin: Springer, 1992:117-136.
[2]McKlin T. Analyzing cognitive presence in online courses using an ANN[D]. Atlanta: Georgia State University, 2004:40-80.
[3]L?ms? J, Uribe P, Jiménez A, et al. Deep networks for collaboration analytics: Promoting automatic analysis of face-to-face interaction in the context of inquiry-based learning[J]. Journal of Learning Analytics, 2021,(8):113-125.
[4]Neto V, Rolim V, Pinheiro A, et al. Automatic content analysis of online discussions for cognitive presence: A study of the generalizability across educational contexts[J]. IEEE Transactions on Learning Technologies, 2021,(3): 299-312.
[5]甄園宜,鄭蘭琴.基于深度神經網絡的在線協作學習交互文本分類方法[J].現代遠程教育研究,2020,(3):104-112.
[6][7]王萍,田小勇,孫僑羽.可解釋教育人工智能研究:系統框架、應用價值與案例分析[J].遠程教育雜志,2021,(6):20-29.
[8]Gunawardena C N, Anderson T. Analysis of a global online debate and the development of an interaction analysis model for examining social construction of knowledge in computer conferencing[J]. Journal of Educational Computing Research, 1997,(4):397-431.
[9]Dama C I, Ludvigsen S. Learning through interaction and the co-construction of knowledge objects in teacher education[J]. Learning, Culture and Social Interaction, 2016,(11):1-18.
[10]Kanuka H, Anderson T. Online social interchange, discord, and knowledge construction[J]. Journal of Distance Education, 1998,(1):57-74.
[11]鄭勤華,熊潞穎,胡丹妮.任重道遠:人工智能教育應用的困境與突破[J].開放教育研究,2019,(4):10-17.
[12]Gao R, Hao B, Li H, et al. Developing simplified Chinese psychological linguistic analysis dictionary for microblog[A]. International Conference on Brain & Health Informatics (BHI’13)[C]. Tokyo: Springer, 2013:359-368.
[13]Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002,(16):321-357.
[14]Louppe G, Wehenkel L, Sutera A, et al. Understanding variable importances in forests of randomized trees[A]. Advances in Neural Information Processing Systems 26 (NIPS 2013)[C]. Cambridge: The MIT Press, 2013:1-9.
[15]Geurts P, Ernst D, Wehenkel L. Extremely randomized trees[J]. Machine Learning, 2006,(1):3-42.
[16][17]Wever B D, Schellens T, Valcke M, et al. Content analysis schemes to analyze transcripts of online asynchronous discussion groups: A review[J]. Computers & Education, 2006,(1):6-28.
[18]Joksimovic S, Gasevic D, Kovanovic V, et al. Psychological characteristics in cognitive presence of communities of inquiry: A linguistic analysis of online discussions[J]. The Internet and Higher Education, 2014,22:1-10.
[19]Radkowitsch A, Vogel F, Fischer F. Good for learning, bad for motivation? A meta-analysis on the effects of computer- supported collaboration scripts[J]. International Journal of Computer-Supported Collaborative Learning, 2020,15:5-47.
[20]楊現民,王懷波,李冀紅.滯后序列分析法在學習行為分析中的應用[J].中國電化教育,2016,(2):17-23、32.
Research on Automatic Analysis of Knowledge Construction Behaviors in Online Collaborative Discussion
HE Hao-yi1LIU Qing-tang2ZHANG Si2GUAN Xue-min1QIN Wei-hua3[Corresponding Author]
In order to realize the dynamic tracking and analysis of the knowledge construction process of online collaborative discussion, this paper used the text classification method to design the “implementation process of automatic analysis of knowledge construction behavior of online collaborative discussion”. Guided by this process, this paper took the collaborative discussion activities of teachers’ workshops in the e-learning community as an example to carry out the experiment, and the main contents include creating a “teacher workshop knowledge construction behavior coding scheme”, collecting and sorting interactive text data, selecting and extracting text features, preprocessing training set data, training and evaluating classification model, and describing and explaining the application situation of analysis results. The results showed that the automatic analysis method of knowledge construction behavior in an online collaborative discussion can provide support for stakeholders to deeply understand the collaborative knowledge construction process and to intervene and adjust the process in real time.
online collaborative discussion; knowledge construction; text classification; learning analysis
G40-057
A
1009—8097(2022)05—0093—09
10.3969/j.issn.1009-8097.2022.05.011
基金項目:本文受國家自然科學基金項目“面向大規(guī)模在線教育的學習者協作會話能力評估模型及干預機制研究”(項目編號:62077016)、廣西高等教育本科教學改革工程一般A類項目“基于創(chuàng)新實踐能力培養(yǎng)的SPOC翻轉課堂混合型教學模式研究——以管理溝通課程為例”(項目編號:2018JGA115)、廣西民族師范學院2021年校級科研項目“混合學習過程的多模態(tài)分析及歸因研究”(項目編號:2021BS006)資助。
何皓怡,高級工程師,博士,研究方向為學習分析,郵箱為he_haoyi@163.com。
2021年8月31日
編輯:小米
猜你喜歡
阿來研究(2021年1期)2021-07-31 07:38:26
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
新世紀智能(高一語文)(2020年9期)2021-01-04 00:42:46
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
幼兒教育·父母孩子版(2016年12期)2017-05-24 13:11:53
