
基于大數據的煤礦違規行為分析識別系統研究
2022-05-23 02:03:56張洪亮
煤礦安全 2022年5期
關鍵詞:煤礦
張洪亮
(1.中煤科工集團沈陽研究院有限公司,遼寧 撫順 113122;2.煤礦安全技術國家重點實驗室,遼寧 撫順 113122)
在大數據技術流行的今天,我國也加快了對大數據相關技術應用的進程,大數據技術與行業進行了深度融合,同時也推動了各行業的產業智能化升級。2019 年10 月底,國家煤礦安全監察局印發煤安監辦[2019]42 號《國家煤礦安全監察局關于加快推進煤礦安全風險預警系統建設的指導意見》[1-2],要求“建設覆蓋國家、省、煤礦企業多個層面的安全生產風險監測預警系統,打通從企業向上至煤礦安全監管部門、省級煤監機構、國家煤礦安監局系統的數據采集、傳輸、共享渠道。”。同時應對煤礦安全生產形勢依然嚴峻,如何利用信息化手段提高煤礦安全執法,降低煤礦安全生產事故,保障煤礦安全生產是急需解決的問題。因此,急需研究建設煤礦安監執法相關數據分析平臺,對煤礦企業的相關違規行為進行識別、報警,并及時消除安全隱患。基于先進信息化技術,不斷推進信息化建設,滿足煤礦企業自身的安全管理要求,提高煤礦企業的安全生產管理水平,避免重特大安全事故發生,保障企業安全生產的總體目標。
1 系統關鍵技術
大數據技術是一系列復雜技術的總稱,基礎的技術包含數據采集、數據倉庫、數據存儲、數據挖掘、機器學習、多線程、可視化等。其主要核心關鍵技術包括Hadoop 大數據技術和Hive 數據倉庫技術。大數據技術架構如圖1。
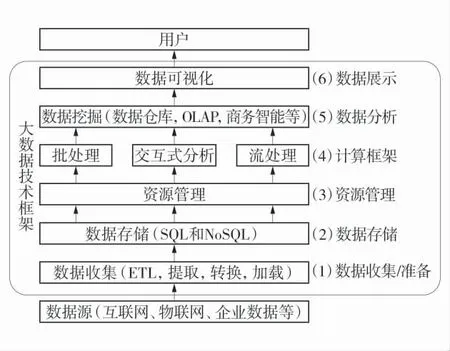
圖1 大數據技術架構Fig.1 Big data technology architecture
1)Hadoop 技術。Hadoop 技術框架是一個依托于Apache 基金會的分布式系統基礎架構。Hadoop 適合應用于大數據存儲和大數據分析的應用,是以一種可靠、高效、可伸縮的方式進行處理的。還可以構建于公共社區服務器,這樣大大降低了用戶的使用、開發成本。用戶可以方便地在Hadoop 公共社區服務器上設計、開發、運行和處理海量數據的應用程序。Hadoop 還支持Java 語言編寫的技術框架,能夠完美地運行在Linux 操作系統上。同時,Hadoop 也支持其他編程語言。Hadoop 最核心的技術架構是HDFS和MapReduce。HDFS 為海量數據提供分布式存儲,MapReduce 為海量數據提供了分布式計算能力。
2)Hive 數據倉庫技術。Hive 是基于Hadoop 的一個數據倉庫工具,用來進行海量數據的提取、轉化和加載,即ETL 操作。Hive 數據倉庫相關工具能夠將結構化的、有序的數據文件轉化為關系型數據庫中的數據表,并能夠進行SQL 語句查詢,能將SQL語句轉變成MapReduce 任務來執行。Hive 的優勢是使用成本低,可通過類似關系型數據庫的SQL 語句實現快速MapReduce 計算,使對MapReduce 使用變得更簡單,不必開發復雜的MapReduce 模塊程序。
2 系統設計
2.1 煤礦常見違規操作行為
煤礦違規行為存在于企業生產、經營的方方面面,但與安全息息相關的違規操作行為還是存在于安全生產的過程之中,主要有變換傳感器接入位置、遮擋傳感器探頭、篡改上傳數值、人為下調傳感器安裝位置、中斷傳感器數據、無計劃刪除測點、傳感器假標校等違規行為。
1)傳感器接入位置信息違規場景。井下實際檢測傳感器已安裝,但是不接信號或在中心站軟件不定義,使其數據不傳到中心站,用別的地方的傳感器信號代替此位置傳感器的信號,迷惑檢查人員或上級人員。如將傳感器放置于甲烷氣體體積分數比較低的進風巷內,導致監測的數據遠遠低于實際值。
2)傳感器傳感頭被遮擋違規場景。將傳感器的傳感頭部分使用塑料口袋等進行捆扎,讓外界中的環境氣體無法進入傳感器的感應室內,導致傳感器無法對環境中的甲烷等氣體進行檢測,即使瓦斯氣體超限,傳感器也無法進行監測,或者檢測到的甲烷氣體體積分數值嚴重偏低。
3)傳感器數值上傳違規場景。當傳感器的氣體體積分數值將要超限或已超限時,在數據上傳服務器前將原始數據進行修改來防止系統發出報警。數據會存在突增點、突減點和窄幅震蕩的異常,且在突增異常點、突降異常點之后會伴隨出現數據窄幅震蕩異常,即數據整體表現比較平穩,但變化頻率較快。
4)下調傳感器安裝位置違規場景。相關安全規程要求,甲烷傳感器應垂直懸掛,距頂板(頂梁、屋頂)不得大于300 mm,距巷道側壁(墻壁)不得小于200 mm。瓦斯的密度比空氣小,所以瓦斯易在巷道上部積聚。人為下調傳感器安裝位置或者修改傳感器量程,將導致甲烷傳感器測量值與實際瓦斯體積分數值相比整體縮倍偏低。
5)傳感器中斷違規場景。地面或井下人員在發現傳感器有上升超限趨勢后,對該分站主通訊進行中斷或將傳感器拔掉、或將傳感器設置為不巡檢狀態、或者出現異常情況后中止上傳,使超限后的數據無法正常傳輸到地面中心站,待瓦斯體積分數值恢復正常后恢復通訊。
6)無計劃刪除測點異常場景。地面監控人員將已經出現的超限(或預計將會出現超限)測點刪除,致使數據上傳中斷。
7)傳感器標校周期違規場景,傳感器需按標校周期定期標校,并按標校氣樣標校。礦井標校不規范行為有:在上傳的數據中,將傳感器的正常狀態修改為標校,導致傳感器標校狀態持續時間過長;未按標校周期對傳感器進行標校;1 次標校持續時長過短。
2.2 大數據分析模型抽象
通過分析煤礦違規操作行為的各種場景,找出每種違規行為內在的數據發展變化規律。抽象出每種違規行為的算法分析模型。研究煤礦傳感器接入位置信息、傳感器探頭被遮擋、傳感器數值不正常、人為下調傳感器安裝位置、傳感器中斷、無計劃刪除測點、傳感器標校周期等違規操作場景的異常數據特征,分析數據的變化趨勢,構建數據分析模型。
例如:當工作面在采煤時,由于開采導致大量瓦斯涌出,上隅角傳感器T0、工作面傳感器T1、回風巷傳感器T2的瓦斯體積分數值均比較高;在非采煤時,瓦斯不再涌出,傳感器T1、傳感器T2的瓦斯體積分數值會在快速下降之后保持比較低的水平,而傳感器T0則由于上隅角容易積聚瓦斯,瓦斯體積分數值呈緩慢下降的趨勢。因此在整個生產過程中,傳感器T1、傳感器T2的瓦斯數據呈一致變化趨勢,傳感器T0則與之不同。
利用上述各傳感器的數據變化特征,從數據變化幅度是否劇烈、數值同時上升/下降的占比、1 d 內數值變化頻率方面,對傳感器T0、傳感器T1、傳感器T2連續計算多天的數據,如果每天的數據都異常,則認為該傳感器的位置異常,以此判斷傳感器T0、傳感器T1、傳感器T2的安裝位置是否正確,或以此來判斷是否存在違規操作行為。每種違規場景都抽象出相應的判斷算法,為大數據分析識別模塊的開發做準備。
2.3 數據的清洗與轉換
以煤礦安全監測聯網數據為基礎,通過大數據的手段對可能出現的違規操作行為場景進行分析。首先通過對集團聯網平臺原始數據文件進行實時記錄留存,類似飛機黑匣子的功能,實時記錄所有監控系統運行原始數據,作為以上違規操行行為分析的數據來源。實現與基于大數據的煤礦違規行為分析識別系統的數據對接。
該過程將使用Hive 工具對海量數據進行數據提取、轉換與加載[3-4],即ETL 操作。Hive 定義了簡單的類似SQL 的查詢語言,即HiveSql。論其本質,Hive其實針對SQL 語句進行翻譯、解釋,它能夠將用戶輸入的HiveSql 語句轉換成MapReduce 作業,并在Hadoop 集群上運行。一般情況下,數據倉庫分為ODS、DW 2 部分。通常的做法是從業務系統到ODS做數據清洗,將臟數據和不完整數據處理掉,再從ODS 到DW 的過程中做數據轉換,進行不同業務規則數據的計算和整合。數據ETL 處理過程如圖2。

圖2 數據ETL 處理過程Fig.2 Data ETL processing process
2.3.1 數據清洗
數據清洗的目的是處理掉那些不滿足計算統計要求的各類數據,主要包括殘缺的數據、錯誤的數據和冗余的數據3 大類。
1)殘缺的數據。即信息不完整,存在局部數據缺失的數據,如監測值、采集時間等。需要將這一類數據過濾出來,處理掉。
2)錯誤的數據。產生原因是業務系統不夠健全,比如超量程數據、日期格式不正確、日期越界等。
3)冗余的數據。數據時間相同、值相同的數據記錄,需將重復的數據的記錄去除,只保留1 條。
數據清洗是一個不斷持續的過程,不可能在短時間內完成,而是隨著數據的采集,不斷地發現問題,處理問題。對于清洗之后的數據,可寫入文本文件或數據庫,以做日志存儲備份,也可以作為將來驗證、改進數據來源的依據。
2.3.2 數據轉換
數據轉換主要是對數據格式、數據密度、業務規則不一致的數據進行一些格式轉換、密度調節、規則轉換的處理。
1)數據格式轉換。數據格式不一致的數據轉換主要是一個格式統一的過程,將不同業務系統的相同類型的數據按照規定的統一格式進行轉換處理,本系統只抽取煤礦安全監控系統的聯網數據,不存在不一致數據的轉換。
2)數據密度轉換。安全監控聯網系統數據一般存儲非常詳細的數據,而數據倉庫中的數據是用來做分析、統計的,不需要非常詳細的數據,所以,需將安全監控聯網系統數據按照數據倉庫設定的密度進行聚合。
3)業務規則不同的數據類型轉換。這個類型的轉換有時不是簡單的加減操作就能完成,需要在ETL 操作中將各業務規則數據進行計算,然后存儲在數據倉庫中,最后為MapReduce 階段的計算、分析做準備。本系統數據來源、業務規則單一,不需要進行業務規則的數據類型轉換。
2.4 分析識別模塊
基于hadoop 的MapReduce 進行分布式運算程序的開發[5-8],實現海量數據的分析、統計。MapReduce 編程模型只能包含1 個Map 階段和1 個Reduce 階段。第1 個階段的MapTask 并發實例,完全并行運行,互不相干;第2 個階段的ReduceTask 并發實例互不相干,但是他們的數據依賴于上一個階段的所有MapTask 并發實例的輸出。MapReduce 關系圖如圖3。
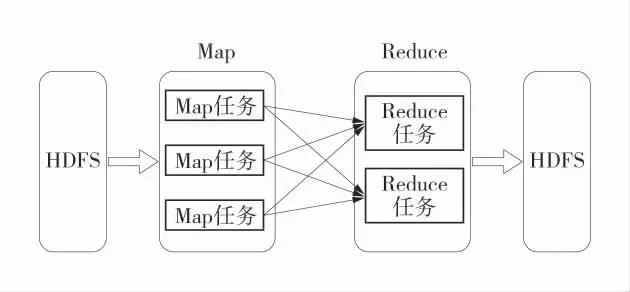
圖3 MapReduce 關系圖Fig.3 MapReduce diagram
1)Map 任務開發。首先基于JAVA 技術定義1個數據讀取類MonitorDataReadMapper,并實現Mapper 接口map 方法,用于逐行讀取清洗轉換好的倉庫里的海量安全監測聯網數據。

2)Reduce 任務開發。類似與Map 開發,首先定義1 個JAVA 類MonitorDataReduce,并實現Reduce接口的reduce 方法,對Map 階段處理之后的數據根據抽象出來的算法模型進行統計分析,找出各種違規場景風險點,并進行統計結果的輸出持久化,供可視化展示。

3 分布式運行設計與計算
首先,準備3 臺客戶機,在每臺客戶機上安裝JDK1.8,并配置環境變量。再安裝Hadoop,并配置相應的環境變量,最后配置集群[9-10]。啟動集群上的每個數據節點,保證整個集群的正常運行。集群節點關系圖如圖4。
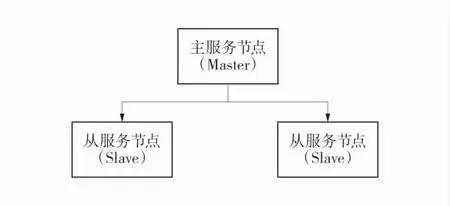
圖4 集群節點關系圖Fig.4 Cluster node diagram
將2 開發好的MapReduce 程序放在集群里運行。前提需開發1 個驅動類MonitorDataDriver。public class MonitorDataDriver{

最后通過Maven 生成JAR 包,并拷貝該JAR 包到Hadoop 集群。執行[syccri@hadoop102 software]$hadoop jar MonitorData.jar com.syccri.monitordaaa.MonitorDataDriver 命令,最終生成想要的分析統計,計算結果。
4 結 語
通過對大數據技術、算法模型、倉庫技術、分布式技術的研究,建立大數據開發、分析環境。通過對變換傳感器接入位置、遮擋傳感器探頭、篡改上傳數值、人為下調傳感器安裝位置、中斷傳感器數據、無計劃刪除測點、傳感器假標校等違規操作行為所產生異常數據的內在規律性進行分析,建立大數據數學分析模型,開發大數據分析模塊加以分析、識別,是行之有效的技術手段,能夠助力安監部門監察煤礦企業違規、違法操作行為,現場精準取證,消除安全隱患。
猜你喜歡
經濟技術協作信息(2018年22期)2019-01-19 03:00:22
工業設計(2016年4期)2016-05-04 04:00:23
現代企業(2015年8期)2015-02-28 18:55:34
現代企業(2015年6期)2015-02-28 18:51:50
河南科技(2014年11期)2014-02-27 14:17:24
河南科技(2014年11期)2014-02-27 14:09:47
河南科技(2014年10期)2014-02-27 14:09:19
河南科技(2014年5期)2014-02-27 14:08:27
河南科技(2014年8期)2014-02-27 14:08:07
河南科技(2014年8期)2014-02-27 14:07:44
