基于卷積神經網絡的油井供液程度定量分析方法及應用
2022-05-24 00:34:36智勤功
油氣田地面工程 2022年5期
關鍵詞:模型
智勤功
中國石油化工股份有限公司勝利油田分公司石油工程技術研究院
目前,我國大部分油田都處在開發的中后期,油井供液不足現象越來越嚴重[1]。對于供液不足油井而言,充滿程度不足通常會引起空抽和液擊工況。這樣不僅對抽油設備造成損耗,而且會消耗很多的電能,顯著提高了油田的開發成本。
針對供液不足油井的變化情況,目前采用的方法有:①利用動液面監測判別油井供液不足的程度[2-3],但傳統的動液面監測無法做到實時監測,由于井下環境復雜,監測誤差也較大。②根據示功圖判斷油井供液不足的程度,但該方法缺乏有效的識別方法,無法進行自動化分析,主要依靠工作人員經驗來判斷油井供液不足的程度,缺乏穩定性和權威性。以往的特征提取比較依賴先驗知識,隨著深度學習的快速發展,卷積神經網絡(CNN)可以學習性地提取由訓練數據驅動的特征描述,使其更加有變通性和通用性。CNN被看作達成深度學習的關鍵手段,但早期的CNN 由于缺乏大數據支持且硬件性能不佳,無法處理復雜的問題。隨著大規模ImageDatabase 的孕育和硬件條件的發展,CNN 已成為研究的熱點并得到迅速發展。近年來,主要的CNN結構有AlexNet[4]、LeNet-5[5]和VGGNet[6]等。在實際運用中,隨著油田生產信息化的全面推進,目前已實現油井生產數據的采集監控,數據的實時傳輸上傳,視頻監控的全面覆蓋,大數據資源已初步形成[7-8]。CNN 已在圖像分類[9-10]、目標檢測、目標跟蹤、文本識別這些領域獲得了極大的成就。
因此,基于油田大數據資源的完備和CNN 良好的特征提取性能,本文提出一種基于卷積神經網絡的油井供液不足程度量化分析方法,同時使用Softmax 分類器構建識別模型,很好地解決了傳統分析方法的不足。經現場應用,此方法能夠滿足油田實際應用需求。
1 卷積神經網絡
隨著深度學習的快速發展,卷積神經網絡已在石油工程領域展示出其突出的優勢[11-12]。針對油井供液不足程度識別的問題,本文選用卷積神經網絡作為識別模型。
1.1 卷積神經網絡及基本原理
卷積神經網絡識別圖像的基本原理是[13-14]:首先輸入待識別的圖像,采用卷積操作對待識別圖像進行特征提取;然后采用Max-pooling 方法對圖像降維,接著經過多個卷積層與池化層,充分提取待識別圖像特征;最后在全連接層中將提取到的所有特征參數合并,完成對待識別圖像的辨別與分類。卷積操作是對待識別的示功圖圖像X進行計算并獲取其特征參數,用Hi表示卷積神經網絡第i層的特征參數(H0=X),即

式中:Wi為網絡模型第i層卷積核的權值向量;bi為網絡模型第i層卷積核的偏移向量;f(x)為激活函數。
將提取到的特征參數經過池化窗口(n×n)操作之后,原尺寸收縮為先前的(1/n)×(1/n)。
1998年,YANN LECUN提出了LeNet-5網絡模型,網絡結構為:第一、二層為卷積層,卷積層后各自連接池化層;第三層也是卷積層,后連接兩個全連接層。作為第一代經典卷積神經網絡模型,在油井供液不足示功圖程度識別研究中,其網絡結構、激活函數和卷積核尺寸等方面存在可以繼續提升的空間。
AlexNet 由KRIZHEVSKY 等人創建,它贏得了2012年的ImageNet競賽。該模型由8層組成,其優勢在圖像分類上表現卓越。
2014 年,牛津大學計算機視覺組的研究員一起研發出新的CNN 模型(VGGNet),同時贏得了ILSVRC 2014比賽分類項目的亞軍和定位項目的冠軍。VGGNet的模型結構[11]如圖1所示。

圖1 VGGNet神經網絡結構Fig.1 VGGNet neural network structure
VGGNet 模型分為6 種不同的網絡架構,每個結構有5個卷積組,每個卷積組使用一個3×3的卷積核,后面跟著一個2×2 最大的池化層,接著是三個全連接層,最終結合Softmax 分類器構建網絡模型。
VGGNet 網絡模型與LeNet-5 網絡模型對比:首先在VGGNet 模型中采用了局部響應歸一化機制,局部響應歸一化機制可以在模型中對局部神經元創建權重參數,使得網絡模型在對圖像識別的過程中,更加具有針對性和目的性;然后卷積層中采用RELU激活函數取代了Tanh和Sigmoid[15-16],使識別準確率大大提升;接著池化層中采用Max-pooling方法代替了Avg-pooling 方法,從而避免了在特征提取的過程中出現圖像模糊的情況;最后在全連接層中增加了dropout 層,有效防止了過擬合現象的產生。
VGGNet 網絡模型與AlexNet 網絡模型對比:VGGNet模型是對AlexNet模型的進一步優化,網絡層數更深;VGGNet 使用的卷積核為3×3,而非AlexNet的11×11或5×5,準確率更高。
但其相對龐大的網絡結構在圖像識別的過程中花費了大量時間。
1.2 改良的VGGNet網絡模型
針對診斷油井供液不足程度的問題,選用了改良后的VGGNet 結構,它不僅可以滿足識別準確率的要求,還可以減少識別時間。改良后的VGGNet結構主要有以下優點:
(1)改良后的VGGNet 模型輸出層由1 000 個神經元變為10個神經元輸出。
(2)改良后的VGGNet 網絡模型由4 層卷積、4 層池化和3 層全連接構成,減少了訓練時間,提高了收斂速度。
輸入的目標圖像大小為100×200,改良后的VGGNet網絡參數如表1所示。

表1 改良后的VGGNet網絡參數Tab.1 Prameters of improved VGGNet network
2 油井供液不足程度示功圖識別
2.1 示功圖程度識別方法流程
基于CNN 的油井供液不足程度示功圖的識別方法(圖2)如下:將訓練樣本集放入CNN網絡模型中進行訓練;將待識別的驗證樣本集放入已訓練好的CNN模型中進行驗證。

圖2 基于CNN的油井供液不足程度示功圖識別方法流程Fig.2 Identification method flow of indicator diagram of liquid supply deficiency degree based on CNN
2.2 示功圖圖像預處理
基于CNN 的油井供液不足程度示功圖識別原理為:以識別圖像像素點代替識別圖像,完成圖像的分割。對于分割后的圖像先以部分圖像為單位提取特征值,再將局部小特征進行匯總,最終完成整個圖像識別過程。因此,在圖像中出現的所有多余信息都將影響卷積神經網絡的訓練效果,考慮到繪制出的示功圖還包含橫坐標(位移)、縱坐標(載荷)以及坐標線等冗余信息,需要先對示功圖進行預處理[17-18]。預處理的質量決定了樣本集的水平,以及網絡的訓練效果,具體步驟如下:
(1)實驗數據。本實驗采集了某油田現場n余口井的有桿泵懸點載荷、位移等數據,通過對數據質量的篩選和清洗,繪制成統一的標準化示功圖圖像:圖像的大小為100×200 像素,DPI 為50 像素/英寸,曲線線寬為2.5 mm;接著對示功圖進行分類和篩選,從而建立油井供液不足示功圖樣本集(圖3)。

圖3 實驗中用到的油井供液不足示功圖Fig.3 Indicator diagram of insufficient liquid supply for oil wells used in the experiment
(2)像素歸一化。輸入的原始示功圖的像素位于0 到255 之間,像素的不同會干擾神經網絡的學習能力,無形中制造了誤差。因此,根據示功圖像素的最大值及最小值,本文采用了最大、最小值歸一化方法,其公式如下:

式中:xi為像素點值,像素的最大和最小值分別是max(x)和min(x)。
通過常規的歸一化方法處理圖像,將像素回歸至0 到1 之間,不改變圖像特征,排除了井間差異,使得所需信息更加突出,隱匿噪聲信息,節省了訓練時間。
2.3 用于示功圖的CNN模型結構
本文基于傳統的VGGNet 模型,提出了一種改良的VGGNet 模型,用于識別油井供液不足程度。首先構建了油井供液不足程度示功圖數據集,然后將Max-pooling為采樣方法、RELU為激活函數,建立了4 層卷積層、4 層池化層和3 層全連接層的網絡模型,采用反向傳播算法優化其網絡模型。訓練好的網絡模型不僅能夠滿足油井供液不足程度識別準確率要求,又能大大減少識別時間。改進的VGGNet模型結構如圖4所示。

圖4 卷積神經網絡結構Fig.4 Convolutional neural network structure
2.4 分類識別
Softmax 分類器在卷積神經網絡領域中已取得了良好的應用效果,并作為一種泛化能力強的通用學習算法廣泛應用于多類圖像識別領域。本文選取Softmax 分類器對示功圖圖像進行訓練和驗證,檢驗示功圖圖像特征提取的效果。
3 實驗
3.1 實驗環境
本次實驗基于64位的Win10系統,CPU為Intel(R)Core(TM)i7-10750K,CPU 的主頻為2.59 GHz,內存為16 GB。基于Keras 深度學習框架和GPU[19],利用Anaconda 下基于Python 語言的pycharm 進行代碼編制[20]。
3.2 實驗步驟
步驟1:通過油田生產現場采集到的載荷、位移數據,繪制成示功圖。對于不符合油井供液不足示功圖的圖像進行清洗工作,將得到的8 000 張示功圖分為10個供液不足等級。
步驟2:打亂樣本集,將樣本集按8∶2比例劃分訓練集和驗證集。根據油井供液不足示功圖特點,創建卷積神經網絡結構,利用訓練集對神經網絡結構訓練和優化。
步驟3:利用反向傳播算法優化卷積神經網絡權值參數,獲取合適的識別準確率,并保存訓練好的模型。
步驟4:用保存好的模型對驗證集示功圖圖像進行識別。
步驟5:若識別錯誤,則修正錯誤的識別結果;將修正過的示功圖放入對應分類樣本集,再次訓練卷積神經網絡,通過強化學習,不斷更新卷積神經網絡模型參數。
3.3 實驗結果
在訓練過程中設定批處理尺寸為200,迭代次數為200,學習率為0.000 1。訓練集包含6 400 張圖像,驗證集包含1 600 張圖像。訓練集和驗證集的準確率如圖5所示。

圖5 訓練集和驗證集準確率Fig.5 Training set and validation set accuracy
3.4 結果分析
本次實驗采用GPU 訓練CNN 網絡模型。訓練時間在有GPU 訓練情況下需要8 min 左右,而無GPU訓練情況下需要56 min。
從圖5可以看出,開始階段訓練準確率呈上升趨勢,經過一段時間后,準確率均保持在98%以上。由此可知,本次實驗訓練集網絡模型是比較成功的。接著利用驗證集對訓練好的模型進行驗證,驗證集的準確率基本都在98%以上,能夠滿足實際的功能需求。
3.5 對比實驗
為了驗證CNN 識別油井供液不足程度示功圖的性能[21],本文還測驗了其他方法對示功圖圖像的識別效果,包括不同的網絡結構和迭代次數訓練下所識別的油井供液不足程度示功圖的準確率。
3.5.1 迭代次數對比
本次實驗選取迭代次數為100、200和300,每次迭代示功圖圖像200張。若迭代次數太少,將造成驗證準確率較低;若迭代次數太多,不僅不能提高正確識別率,而且將增加訓練時間;因此,選取迭代次數為200時,可以使模型能充分學習圖像特征并收斂(表2)。

表2 不同卷積層神經網絡層數對比Tab.2 Comparison of numbers of neural network layers of different convolutional layers
3.5.2 網絡結構對比
在深度學習中,隨著網絡層數增加,CNN模型學習能力將更強,但層數過多,將會導致網絡模型出現過擬合現象;隨著網絡層數減少又會出現CNN模型欠擬合現象。因此,在選擇卷積層數時,本文采用一層一層增加直到識別率不會隨著層數增加而發生顯著變化的方法來確定最佳層數。第一層使用了16個尺為3×3的卷積核,池化層使用2×2的池化核;第二層使用32 個尺寸為3×3 的卷積核,池化層使用2×2 的池化核;第三層使用64 個尺寸為3×3 的卷積核,池化層使用2×2 的池化核;第四層使用64 個尺寸為3×3 的卷積核;第五層使用128個尺寸為3×3的卷積核。
不同卷積層神經網絡層數對比結果如表3 所示。當層數增加,準確率也慢慢增加,然后保持不變或下降。為此,CNN 網絡結構選擇4 層最合適,收斂耗時短,準確率也更高。

表3 不同卷積層神經網絡層數對比Tab.3 Comparison of numbers of neural network layers of different convolutional layers
4 現場應用
以某管理區塊為例,該區塊具有常溫、高壓、低孔、特低滲透油藏的特點。對于該區塊某口油井,通過訓練后的卷積神經網絡模型,對采集的示功圖進行識別分析,實現了此油井供液程度定量化評估。油井供液不足示功圖數據的采集頻率為每30 min 一次,本文選取6 h 跨度的示功圖圖像樣本進行評估。
從圖6,圖7 可以看出,通過基于卷積神經網絡的油井供液程度智能識別方法,可以準確地反映出隨時間不斷變化的油井供液程度。結果表明,該油井供液能力較差,亟需對油井生產參數進行調控。

圖6 示功圖圖像樣本Fig.6 Sample of indicator diagram image

圖7 基于示功圖的油井供液程度量化評估Fig.7 Quantitative assessment of oil well fluid supply degree based on indicator diagram
通過基于深度學習的油井供液不足程度量化分析方法監測油井供液情況,根據油井供液情況進行遠程動態調頻生產,供液能力較差時減低生產參數,供液能力變好后調高生產參數,保障油井供液的穩定性和泵筒的高充滿系數。2020 年6—8 月,在該管理區塊3口油井上進行了生產參數自適應調控試驗,均取得了較好的效果。
從表4可以看出,平均沖速下降0.55 min-1,日產液量增加1.28 m3,日產油量增加0.91 m3,節電58 kWh/d,節約電費59.16元/d。
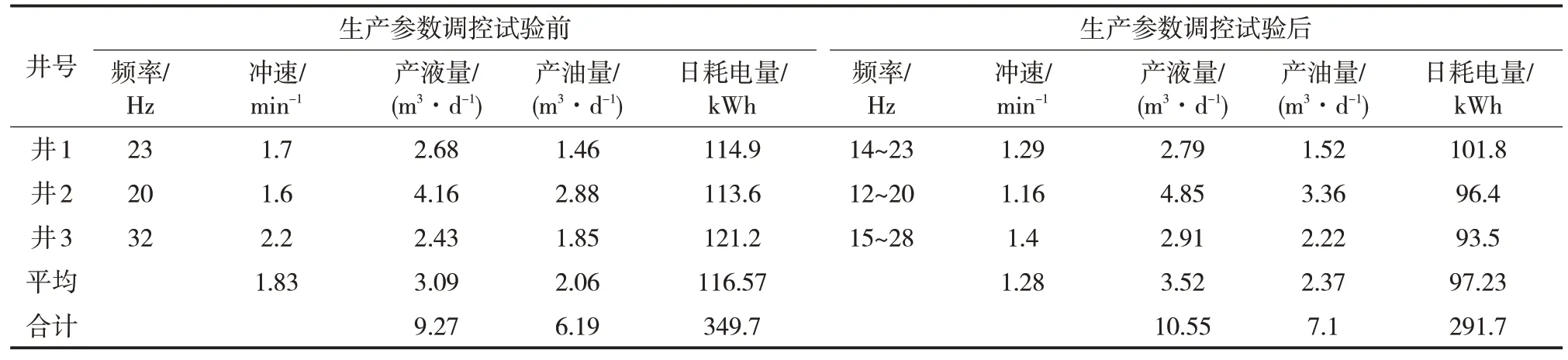
表4 生產參數調控試驗前后對比Tab.4 Comparison before and after the production parameter control test
5 結論
針對油井供液不足程度分析,建立了一套示功圖樣本集,設計了包含4層卷積層、4層池化層和3層全連接層的卷積神經網絡模型,準確率達98.58%,訓練完成的卷積神經網絡模型能夠高效準確識別供液不足程度。礦場應用進一步表明,采用所建立的油井供液不足程度量化分析方法監測油井供液情況并進行遠程動態調頻生產,能夠實現抽油機沖速與油井供液程度的合理匹配,有效減少了電能浪費。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
