基于改進YOLO V4 的橋梁纜索表面損傷識別方法
2022-05-24 11:44:18鄒易清蘇建功夏曉華李玉強蔣立軍韋耀淋
電子設計工程 2022年10期
鄒易清,蘇建功,夏曉華,李玉強,蔣立軍,韋耀淋
(1.柳州歐維姆機械股份有限公司,廣西 柳州 545006;2.長安大學道路施工技術與裝備教育部重點實驗室,陜西 西安 710064)
橋梁中的纜索是關鍵受力構件,在懸索橋、拱形橋和斜拉橋等大跨度橋梁建設中應用廣泛。一旦纜索表面出現損傷,在纜索拉應力及長期風吹日曬的作用下,損傷日趨嚴重,致使雨水滲入纜索內部,引發纜索內部鋼絲銹蝕和銹斷,嚴重威脅橋梁安全。因此,及時、準確的纜索表面損傷識別,對有效預防橋梁事故的發生具有重要意義[1]。
當前,國內外對橋梁纜索表面損傷的識別主要通過人工檢測[2]完成,檢測過程存在一定的主觀性且效率低。激光掃描法[3]能實現自動檢測,但成本高,難以推廣應用;文獻[4-5]利用機器視覺技術進行檢測,然而當圖像存在色差等問題時檢測結果不佳。隨著計算機視覺與深度學習的發展,深度卷積神經網絡在諸如板裂紋[6]、橋梁與路面病害[7-8]等表面缺陷[9]檢測中體現出巨大的優越性。文獻[10]利用Faster R-CNN 卷積神經網絡實現了纜索表面損傷類型及區域的識別,但目前這方面的文獻較少,基于深度學習的纜索表面損傷識別方法仍需進一步研究。
鑒于YOLO V4(You Only Look Once V4) 模型[11]在目標識別中具有良好的性能,文中在其基礎上開展橋梁纜索表面損傷自動識別與定位研究。為提升網絡的特征提取能力,在YOLO V4 模型結構中嵌入注意力機制模塊,從而提高纜索表面損傷的識別精度,實驗驗證了該方法的有效性。
1 橋梁纜索表面識別方法
基于深度學習的目標檢測模型能對圖像中的物體進行快速準確的識別和定位,相較于Mask RCNN[12]、Faster R-CNN[13]等兩階段(two-stage)目標檢測模型,YOLO V4 作為典型的單階段(one-stage)目標檢測模型,經過單次檢測即可直接得到目標的類別概率和位置坐標值,具有良好的檢測速度和精度。文中提出的橋梁纜索表面損傷識別方法基于改進的YOLO V4 目標檢測模型,其流程如圖1 所示,主要包括4 個步驟。
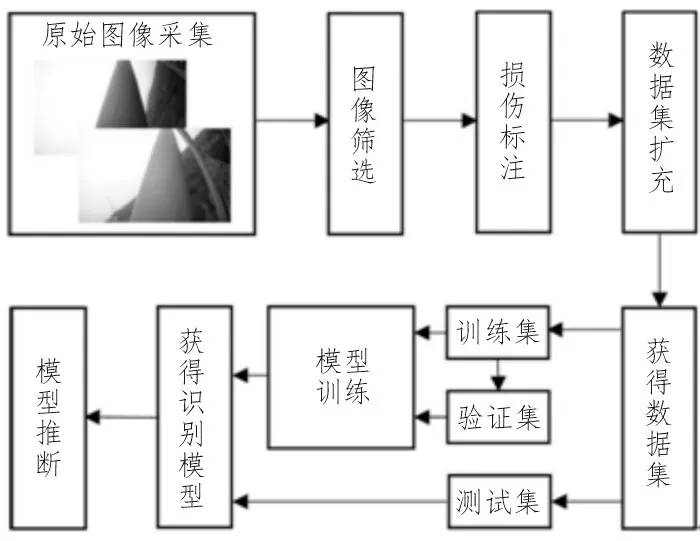
圖1 橋梁纜索表面損傷識別方法流程圖
1)原始圖像采集:通過纜索爬行機器人拍攝橋梁纜索表面圖像。
2)數據集制作:包括圖像篩選、損傷標注、數據集擴充及獲得數據集。篩選圖像,通過數據增強方法擴充樣本數量。
3)模型訓練:改進YOLO V4 模型,調整模型參數,使用數據集進行模型訓練,獲得識別模型。
4)模型推斷:利用識別模型作出預測,輸出識別結果。
2 數據集制作
橋梁纜索圖像的采集地點為江西省某大橋,使用纜索爬行機器人完成圖像采集,挑選纜索表面出現損傷的圖像共201 張,圖像分辨率為1 920×1 080像素。
對深度學習而言,準備的數據越充足、越全面,訓練得到的深度學習網絡模型識別效果越好。當數據量不足時,可采用數據增強的方法擴充數據集。數據增強不僅可以增加訓練的數據量,提高模型的泛化能力,也能通過增加噪聲數據,提升模型的魯棒性。通過旋轉、鏡像、亮度改變、添加高斯噪聲等單一方法或多種方法結合的物理變換對圖像進行數據增強[14-15],最后獲得2 995 張圖像作為數據集,并使用圖形圖像注釋工具LabelImg 對每張圖像中的橋梁纜索表面損傷進行標注。隨機選取數據集中的90%(2 695 張)作為訓練集,10%(300 張)作為測試集,在訓練集中任意選取10%(270 張)作為驗證集。
3 改進YOLO V4模型
YOLO V4 目標檢測模型在YOLO V3 目標檢測模型的基礎上,對主干特征提取網絡(Backbone network)、加強特征提取的頸部網絡(Neck network)和預測輸出的頭部網絡(Head network)進行改進。在主干特征提取網絡中,利用CSPNet 結構(Cross Stage Partical Network)構造了CSPDarknet53,可以在降低計算量的情況下保持甚至提高網絡的性能。此外,CSPNet 結構中引入了Mish 激活函數,Mish 激活函數是光滑函數,具備較好的泛化能力,對結果也有優化作用。在頸部網絡中,使用了SPP(Spatial Pyramid Pooling)結構和PANet(Path Aggregation Network)結構。在對CSPDarknet53 網絡輸出的最后一個特征層完成3 次卷積操作后,利用SPP 結構中4 個不同尺度的最大池化層進行處理,可以極大地增加感受野,分離出最顯著的上下文特征,且幾乎不會降低網絡的處理速度。PANet 結構的使用能夠準確地保留空間信息,有助于正確定位像素點,形成mask。
在深度卷積神經網絡處理圖像時,使網絡自適應地注意重要、有用的目標信息,可以提高最終模型的識別準確率。SENet[16](Squeeze-and-Excitation Networks)是一種通道卷積注意力機制模塊,通過學習的方式自動獲取每個特征通道的重要程度,以此來提升有用的特征并抑制無效特征,進而加快特征處理的速度。SENet模塊結構如圖2 所示。
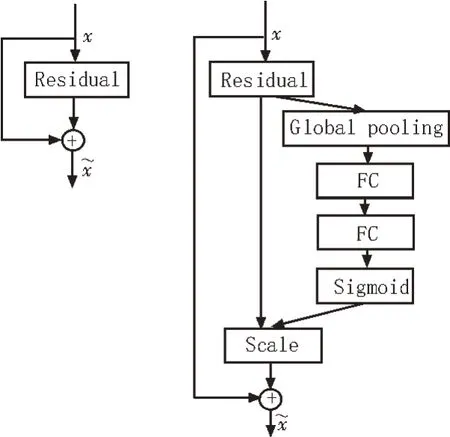
圖2 SENet模塊結構
SENet 模塊首先對輸入進來的特征層進行全局平均池化(Global pooling),然后利用兩個全連接層(FC)先降低特征層維度而后升高至原來維度,最后經過Sigmoid 激活函數處理后便獲得了輸入特征層各個通道的權值,通過將權值與原輸入特征層相乘的方式對每個特征層進行加權,以此處理不同重要程度的特征層[18-19]。
SENet 模塊并不是一個完整的網絡,可以靈活嵌入到分類或目標檢測網絡中。如圖3 所示,將SENet模塊嵌入到YOLO V4 模型主干特征提取網絡層的3 個有效特征層中,同時在PANet 結構中將兩個上采樣后的結果添加到SENet 模塊,增強網絡的特征提取能力。圖3 中Conv 表示卷積(Convolution),BN 表示批量正則化(Batch Norm),Concat 表示特征融合(Concatenation),UpSam 表示上采樣(UpSampling),DownSam 表示下采樣(DownSampling)。
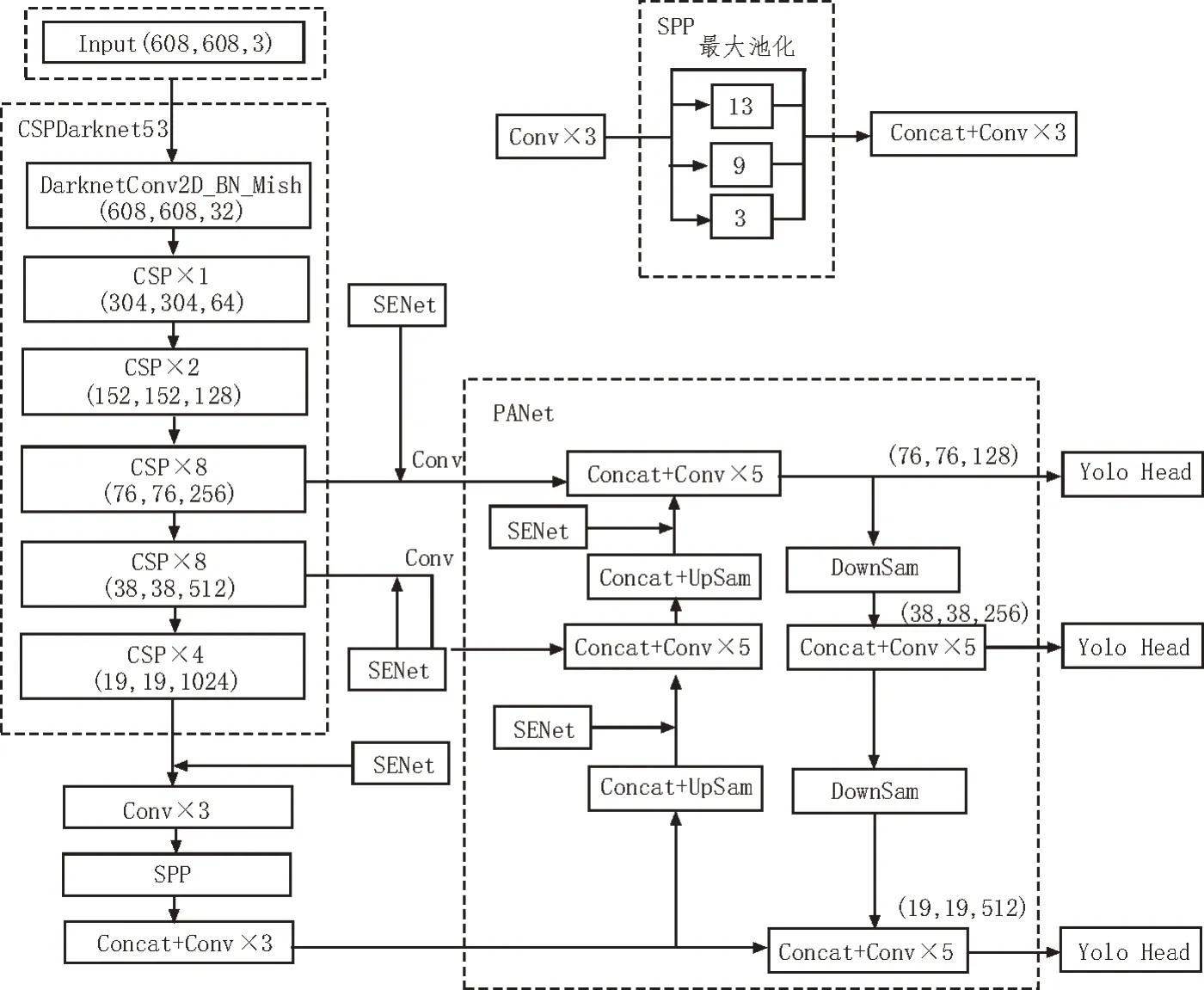
圖3 嵌入SENet模塊的YOLO V4模型結構
4 模型的訓練與測試
實驗在臺式計算機上完成,利用Tensorflow 以及Keras 框架來改進YOLO V4 模型。實驗環境如表1所示。

表1 實驗環境
為減少模型的訓練時間以及使模型更好地收斂,采用遷移學習的方法訓練模型。在模型訓練過 程中,先凍結主干特征提取網絡層,將更多的資源用
4.1 實驗環境與網絡訓練
于訓練后半部分網絡,訓練一定代數后,解凍主干特征提取網絡層,并采用預訓練好的COCO 分類網絡模型的參數作為主干特征提取網絡層的初始權重值,繼續對全部網絡進行訓練,直至得到最終的模型,利用這種訓練方式可有效保證權值。
設置合適的訓練參數是提升識別模型性能的重要手段。訓練圖像尺寸設為800×800 像素,在使用預訓練參數時,設置模型的迭代次數(Epoch)為50次,批處理的數據集樣本數量(Batch size)為8,基礎學習率(Base learning rate)為0.001;不使用預訓練參數時,設置模型的迭代次數為70 次,批處理的數據集樣本數量為2,基礎學習率為0.000 1,總迭代次數為120次。學習率采用余弦退火策略進行調節,每5輪重置基礎學習率,基礎學習率最小值設置為0.000 01。在訓練集上每完成一個Epoch,保存一次權值參數,模型訓練結束后共得到120 個模型權值參數,以此評價訓練模型的性能。訓練集損失值曲線如圖4所示。
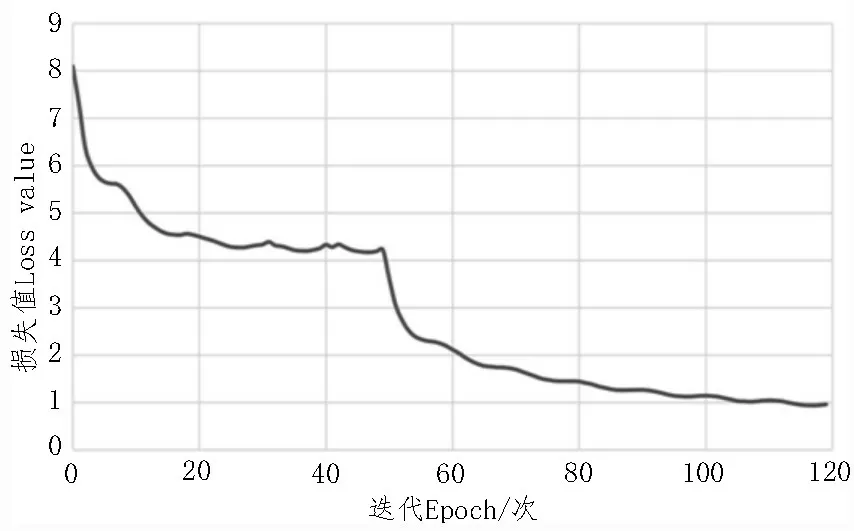
圖4 損失值隨迭代次數變化曲線
訓練模型時,選用Adam 梯度優化器,其超參數beta_1 設置為0.9,beta_2 設置為0.999,利用Keras 框架中的提前終止法(Early stopping)來防止過擬合,在每一個Epoch 結束時,計算模型在驗證集上的損失值,若損失值不再下降,則停止訓練。
在前50 代訓練中,訓練集損失值雖有一定震蕩,但整體呈現持續下降趨勢;第50 代訓練時,由于解凍訓練致使訓練集損失值突然下降,在后續的訓練過程中,損失值緩慢變小直至幾乎不發生變化,模型收斂。
4.2 模型測試結果與分析
采用SSD[17]模型、Faster R-CNN 模型、原始YOLO V4 模型和在頸部網絡融入注意力機制的YOLO V4模型對測試集圖像進行識別,識別效果如圖5 所示,圖中白色矩形框為模型檢測出的表面損傷,橢圓形框和平行四邊形框為漏檢的表面損傷,虛線矩形框為誤檢的表面損傷,黑色矩形框為局部放大區域。由圖5 可知,SSD 模型對橋梁纜索表面損傷的檢測效果較差,易出現漏檢的情況(圖中橢圓形框)。在圖5(a)、5(b)中,Faster R-CNN 模型雖能正確識別出損傷,但存在誤檢問題(圖中虛線矩形框)。在圖5(b)中,YOLO V4 模型對小目標存在漏檢問題(圖中橢圓形框)。在圖5(c)中,YOLO V4 模型對其中的一處損傷識別正確但僅識別出某一小部分,圖中平行四邊形框中的損傷未能識別出來。融入注意力機制的YOLO V4 模型則能準確識別出橋梁纜索表面損傷,具有較高的識別準確率和良好的泛化能力。
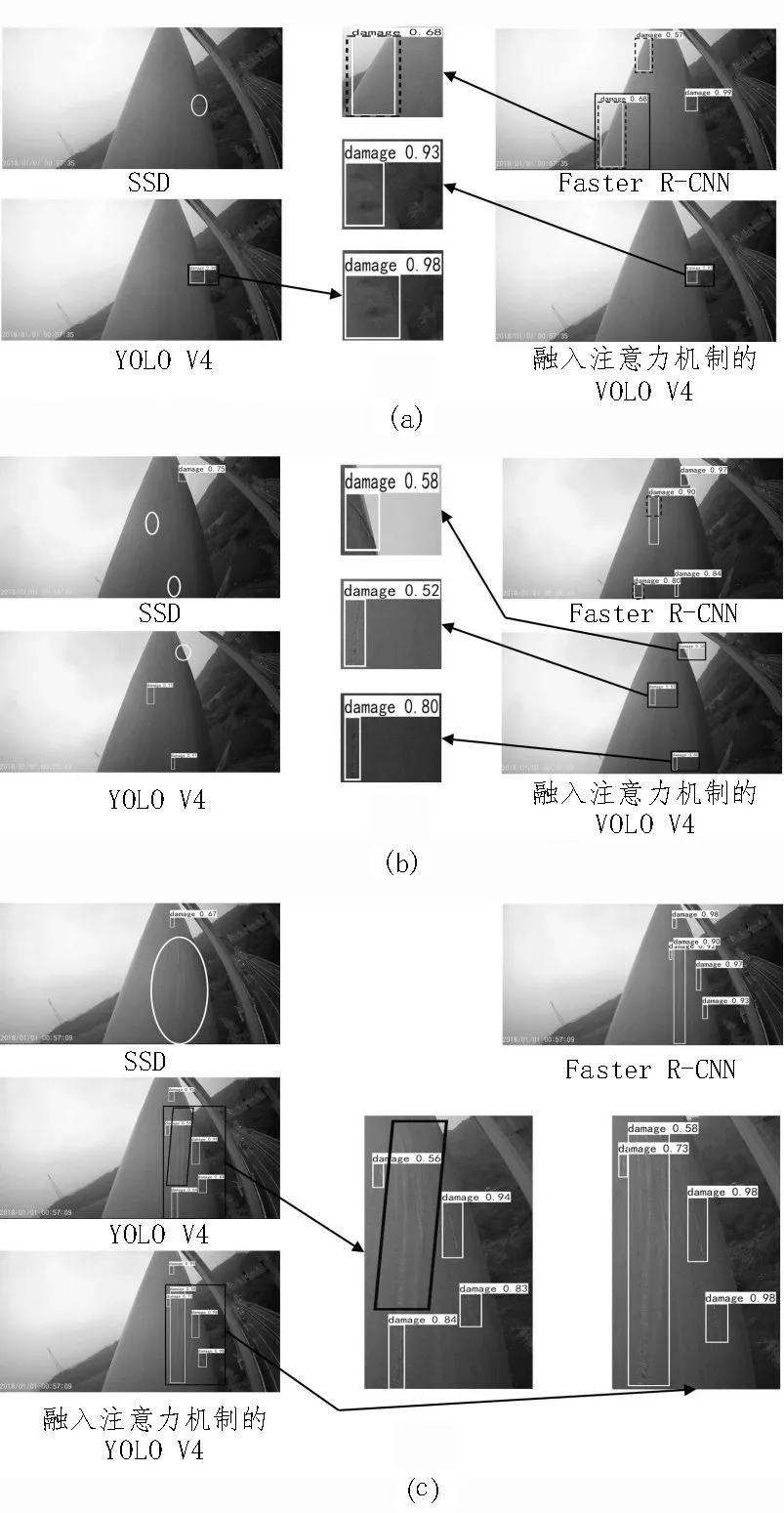
圖5 不同模型的識別結果對比圖
為客觀評價訓練所得模型對纜索表面損傷的識別效果,通過計算預測圖像的平均精度和平均檢測時間來評價訓練后的模型,其中,平均精度是以召回率(R)為橫坐標、精確率(P)為縱坐標建立的PR 曲線的線下面積,平均檢測時間為檢測一張圖像所需的平均時間,平均精度的計算公式為:

式中,r為積分變量,P(r)為P-R 曲線函數表達式。利用SSD 模型、Faster R-CNN 模型、原始YOLO V4 模型和融入注意力機制的YOLO V4 模型對纜索表面損傷進行識別的客觀評價結果如表2 所示。為保證實驗結果的公平性,每個模型的訓練圖像尺寸均為800×800像素,迭代次數一致。原始YOLO V4模型和融入注意力機制的YOLO V4 模型使用上節給出的超參數,并分別對SSD 和Faster R-CNN 模型設置合適的超參數,在相同的實驗環境下采用相同的訓練方式進行訓練,如遷移學習、優化器等。
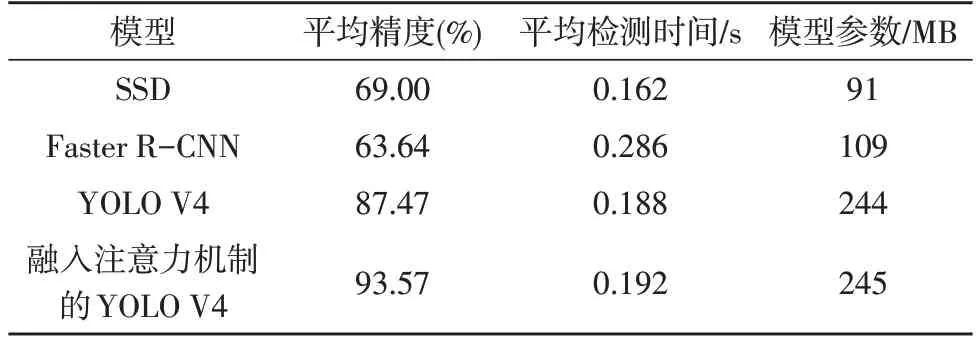
表2 不同模型對橋梁纜索表面損傷的識別結果
從表2 中可以發現,融入注意力機制的YOLO V4 模型相較于原始的YOLO V4 模型,纜索表面損傷識別的平均精度高出6.10%,平均檢測時間僅增加了0.004 s;與SSD 模型相比,雖然平均檢測時間有所增加(增加了0.030 s),但平均精度高出24.57%,識別效果顯著提升;與Faster R-CNN 模型相比,在平均檢測時間減少(減少了0.094 s)的同時,平均精度高出29.93%,表明改進的YOLO V4 模型在纜索表面損傷識別中明顯優于現有文獻使用的Faster R-CNN模型。因此,在頸部網絡部分嵌入注意力機制的YOLO V4 模型能有效提升橋梁纜索表面損傷的識別精度,其識別精度明顯高于SSD 模型和Faster R-CNN模型。雖然改進的YOLO V4 模型在平均檢測時間上略高于原始YOLO V4 模型和SSD 模型,但其0.192 s的單幅圖像平均檢測時間仍可保證在纜索表面損傷識別過程中具有較好的實時性。上述平均精度和平均檢測時間的實驗驗證了文中方法的有效性。
5 結論
識別橋梁纜索表面損傷是修復纜索損傷的前提,能有效預防橋梁纜索向嚴重病害發展,對提高橋梁的經濟性和安全性具有重要意義。為實現準確、快速的橋梁纜索表面損傷識別,文中將注意力機制嵌入YOLO V4 目標檢測模型中,提出了基于改進YOLO V4 模型的橋梁纜索表面損傷圖像識別方法。
融入注意力機制的YOLO V4 模型能有效識別橋梁纜索表面損傷,平均精度為93.57%,相較于SSD模型、Faster R-CNN 模型和原始YOLO V4 模型,平均精度高出24.57%、29.93%和6.10%,其0.192 s 的單幅圖像平均檢測時間能保證在纜索表面損傷識別過程中具有較好的實時性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
電子制作(2019年15期)2019-08-27 01:12:00
湖南教育·A版(2019年4期)2019-05-10 03:31:44
小學生學習指導(低年級)(2019年4期)2019-04-22 03:28:24
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
山東工業技術(2016年15期)2016-12-01 05:31:04
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
