破除隱私計算的迷思:治理科技的安全風險與規制邏輯
2022-05-26 03:58:02趙精武
華東政法大學學報 2022年3期
趙精武
一、問題的提出:治理科技的邏輯怪圈
在經歷了“數據資源型—數據驅動型—數據賦能型”〔1〕參見夏義堃:《數據管理視角下的數據經濟問題研究》,載《中國圖書館學報》2021 第6 期,第109 頁。三個數據經濟發展形態之后,現代社會對于數據的依賴性早已不是最初的“數據增值加工”,而是深化至“數據如何變革產業形態”。這種“產業數字化”的市場趨勢促使立法理念發生變化:從單一的數據安全轉變為在數據安全前提下充分利用數據。但信息技術的迭代優化卻又使得立法者所希冀的“安全與利用并行”的理想圖景一次次被打破。在現代化治理活動中,法律規制技術風險的線性監管邏輯無法真正回應和解決不斷涌現的新型信息技術難題。因此,治理科技作為兼具業務合規和風險控制的技術方案,毋庸置疑地成為市場主體和監管機構的另一種選擇,如區塊鏈技術在實現“鏈上數據不可篡改”安全功能的同時,也滿足了企業安全交易的需求;再如人臉技術在滿足身份真偽高效核驗的同時,也達成了企業縮減業務流程和優化用戶體驗的商業預期。這些治理科技的開發與應用可謂有效統合了市場主體商業利益、監管者治理目標和市場受眾群體基本權益等多方利益的訴求。
然而,治理科技真的能夠為現代社會提供“法律與技術共治”的良好圖景嗎?答案顯然是“不能”。因為在治理科技研發過程中暗含著一種容易被忽視的商業邏輯:“××科技”是為了達成某種商業目標而創設的合規型技術方案,即治理科技的最終目的并不是實現監管機構的監管要求,而是給數據商業化處理活動提供充分可信的“安全背書”。并且,在信息技術發展進程中,從未出現過“絕對安全”的技術方案。這些主客觀因素決定了治理科技同樣可能產生不可預見的安全風險。在區塊鏈中,鏈上數據難以篡改不等于不能篡改,并且去中心化的技術方案也構成了對中心化監管活動的實質性威脅;而在刷臉應用中,身份核驗確實保障了用戶賬號使用的安全性,但“處處刷臉”的應用模式卻也加重了用戶對刷臉必要性和人臉識別信息安全性的疑慮。
不難發現,在治理科技治理社會風險的進程中,也在產生新的反治理風險,而為了消除這種反治理風險,新的治理科技又被納入新一輪的治理活動中。為了打破“數據孤島”和提升數據利用效率,隱私計算技術成為治理科技的新生代代表。該項技術方案的基本邏輯是在挖掘、分析、整合數據的過程中維持原始數據的保密性和本地化等安全指標,達成“數據安全”和“數據利用”之間的利益平衡。但是,這項治理科技似乎同樣沒有擺脫“治理—反治理—再治理”的邏輯怪圈,非授權主體依然可以通過“多次嘗試輸入數據生成特定關系的結果”倒推原始數據。事實上,治理科技的邏輯怪圈絕不止步于此,在不改變現有規制范式的前提下,未來的治理科技依然會產生類似的問題。因此,治理科技反治理風險的規制難題主要表現為如何完成規制理論和規制范式的轉型。
二、治理科技規制范式的“失效”:以隱私計算技術為例
在區塊鏈技術、人臉識別、用戶畫像等信息技術相繼產生新興社會風險之后,現行立法也隨之對技術的應用方式、應用場景及技術的“黑箱”效應提出一系列規范要求。從實際結果來看,立法規制確實將技術風險維系在可控范圍內,卻也限制了數據流動的路徑與范圍。因此,包括聯邦學習、安全多方計算和可信計算等技術方案的隱私計算技術成為新一代治理科技,其目的是在滿足現有數據安全保護監管要求的前提下實現更大范圍的數據商業化處理,通過“數據可用不可見”的方式化解數據安全與數據利用之間越發激化的法益沖突。
然而,信息技術領域從未出現過絕對安全的技術方案,即便是解決數據流動安全性的隱私計算技術同樣存在不同程度的反治理風險,如根據算法模型倒推原始數據的數據泄露風險等。更重要的是,由于隱私計算技術本身以數據安全合規為前提,故而數據處理者得以憑借“已經采取充分必要的技術措施保障數據處理安全”之事由規避承擔數據安全保護的責任,以風險預防、數據脫敏、限制處理目的、責任歸屬為內容的既有規制方式難以繼續延伸出適用于治理“治理科技”(即隱私計算技術)的義務性規范。
(一)風險預防的機制失效
在數據商業化利用領域,我國現行立法活動的重心在于控制數據處理活動中潛在的安全風險,而控制風險的主要方式則是對不同數據處理流程設置不同的監管要求,如安全評估制度、算法備案制度等。總體而言,我國數據安全風險預防機制大體可分為三個層次。
第一層次是“知情同意”規則,即自然人作為數據權利主體,當然有權基于知曉數據處理活動的利益和風險來決定是否同意相應的數據處理活動。進一步而言,個體風險的治理問題首先是自然人在風險和收益之間的判斷問題,法律所要預防的僅僅是“自然人不知情”的安全風險。在該層面,只要數據處理者告知隱私計算技術的功能效果和實際風險水平,即可被視為實質履行了風險預防義務。
第二層次是數據處理者的安全保障義務,即無論數據權利主體是否主動表明“自擔風險”,數據處理者作為數據集合的持有者和處理者,有義務確保數據的安全性、保密性和準確性。隱私計算技術的創設目的之一就是滿足安全保障義務的基本要求,即數據處理活動以“數據本地化”為前提,數據處理者對外傳輸的僅僅是經過數據訓練的算法模型和計算結果,在內部操作流程、信息分類管理、加密技術措施、操作權限分級和安全應急預案等層面滿足《個人信息保護法》(以下簡稱《個保法》)第51條的要求。
第三層次是安全評估制度,即數據處理者在使用新興信息技術之前,應當就該技術對個人權益的影響和安全風險水平進行評估,其目的是要求數據處理者審慎采用新技術,只有在對新技術的安全風險抱有足夠清晰的認知時才可投入使用,安全評估制度的內在治理邏輯是預防數據處理者為了提升市場競爭力而在技術尚未足夠成熟之前徑直采用風險較高的新興技術。并且,該制度的另一功能也是為了解決監管機構在信息技術創新過程中所面臨的監管信息資源受限問題,通過量化的評估指標和定性的評估結果來確定具體的監管措施。隱私計算技術的安全風險并不是個人信息安全威脅,而是黑客攻擊、未經授權訪問等外部主體的不法行為。現行立法所確立的安全評估制度的評估重心是確保新興技術應用能夠保障數據安全和個人信息私密性,這明顯存在安全評估規制目標與技術風險規制需求錯位的問題。
由此可見,風險預防機制對治理科技反治理風險的規制方式主要以數據處理者未能合理選擇穩妥且安全的隱私計算技術方案為限,即未能履行第二層次的安全保障義務,無法直接對隱私計算的應用方式和應用場景作出限定。換言之,純粹服務于商業目的的技術應用所引發的安全風險均可通過風險預防機制予以調整,但由于治理科技本身以遵守數據安全技術標準和監管要求為前提,暗含“已經盡可能預防風險”的技術邏輯,故而風險預防機制的預防功能無法直接適用于治理科技引發的反治理風險。
(二)數據脫敏的目的失效
從國內外數據安全立法實踐來看,立法者普遍認同數據脫敏技術是兼顧數據安全和數據利用的有效技術方案。如在個人信息保護領域,GDРR 第32 條和我國《個保法》第11 條、第73 條均有提及匿名化、加密處理、去標識化等數據脫敏技術措施。數據脫敏的目的在于消除和降低原始數據泄露的實際風險,同時經過脫敏后的數據將能夠充分滿足數據商業處理的目的。數據脫敏的制度目的在于盡可能消除數據背后的關聯性、逆向復原性及可識別要素,但隱私計算技術本身就是以數據脫敏為技術前提的,并且其采取的脫敏技術方案更為直接徹底。例如在差分隱私模式下,隱私計算技術可以在數據處理結果中添加噪聲,使攻擊者無法根據輸出差異回推原始數據,從而保護用戶隱私;再如在同態加密模式下,隱私計算可以實現傳輸海量數據集合的加密密文而不上傳原始數據的技術目標,數據處理的直接對象僅是加密密文,僅有原始數據的持有人才可以對加密數據處理結果進行解密。治理科技的“治理”屬性意味著該類技術的研發邏輯以契合數據安全技術標準為前提,數據脫敏這一傳統規制范式顯然已經無法實現最初的規范目的,因為“脫敏”之要求已經成為治理科技研發的核心技術要求之一。
(三)目的正當的約束失效
技術安全風險既包括內生性風險,也包括外部應用風險。內生性風險主要指向技術方案自身的不完備性可能導致的安全事件,在立法層面多以安全評估制度、安全保障義務等義務性規范予以規制;外部應用風險主要指向技術應用方式不合理可能導致的安全事件,例如個人信息過度收集、超目的處理等,這也是現階段監管機構在治理數據安全風險中所面臨的主要問題。在數據治理領域,數據安全級別與數據安全流動范圍成反比,即數據流動越少,數據也就越安全。因此,《網絡安全法》《數據安全法》《個保法》均有貫徹“控制數據流動范圍”的基本立場。當然,這并不等同于“限制數據流動”,而是強調盡可能控制數據在合理范圍內流動,其中“合理范圍”的認定標準即是數據處理目的的正當性和必要性。為了增強市場競爭力和搶占商業資源,企業普遍希望收集的數據越多越好,這種數據收集活動只會增加個人信息泄露的安全風險,且企業超范圍收集個人信息的間接結果還表現為企業過度分析自然人的行為方式和生活習慣,個人隱私泄露的風險同樣增加。因此,目的正當性原則成為數據安全立法的基本原則,在實踐中表現為外部技術審查。所謂“外部”,通常是指同數據處理者無利益關聯、具備特定技術或法律知識的第三方。例如,算法審計及構建于其上的問責制度,就備受學界推崇,〔2〕例如,有學者指出,通過外部審核“拷問”人工智能,或可暴露埋藏其中的歧視風險。參見李成:《人工智能歧視的法律治理》,載《中國法學》2021 年第2 期,第144 頁; [德]托馬斯·維施邁爾:《人工智能系統的規制》,馬可譯、趙精武校,載《法治社會》2021 年第5 期,第120 頁。另有學者呼吁,“建立統一的個人信息保護機構,實現數據生命周期中不同階段的動態平衡”。參見許可:《健康碼的法律之維》,載《探索與爭鳴》2020 年第9 期,第130 頁。在聯邦學習中可比照適用。英國《政府數據倫理框架》還提出了“同行社區”的概念,將來自技術共同體的持續評價視為保障算法目標正義的核心手段,但對如何實施語焉不詳。
目的正當性原則發揮約束效用的前提是數據處理活動單純以營利為目標,如果不對處理目的進行內部自我約束和外部技術審查,則極易產生過度收集和濫用數據的風險事件。然而,隱私計算技術的底層邏輯是“合規處理數據”,數據處理者在采用安全多方計算、聯邦學習、可信執行環境等具體技術方案時,并不會直接對外傳輸或共享原始數據,其處理目的的內在順位表現為“先是以加密、本地化等方式保障數據安全,其次才是數據商業價值的開發”。因為數據處理目的正當性和必要性已經以“代碼即法律”的方式嵌入隱私技術的底層代碼,依托隱私計算的數據處理活動會將處理目的是否正當、安全且必要作為預設條件。因此,面對以“治理安全風險”為內容的治理科技,目的正當性早已被融入其應用方式中,無法對事中、事后的反治理風險發揮目的矯正和處理方式約束的功能。
(四)技術透明的問責失效
法律責任在所有具有規范性意義的制度安排中居于核心地位,既是違反特定義務必須承擔的法律后果,也是救濟相關權利損害的必要措施,更是保護正當權益的直接手段。〔3〕參見程嘯:《民法典編纂視野下的個人信息保護》,載《中國法學》2019 年第4 期,第26 頁。適用于信息技術應用風險的責任攤派機制,目的在于解決事后風險責任的可追溯性、合理配置與具體分擔等問題。以服務鏈條為基礎,主導方責任、參與方責任、技術方責任和監管責任共同構成技術風險責任歸屬體系的主構架。但是,由于技術手段眾多、數據處理方式迥異,歸責制度的設計還有待斟酌,法院在應對零星出現的問題時只能比照《電子商務法》第5 條規定的“產品和服務質量責任”,對鏈條上的所有數據處理者適用嚴格責任原則,這樣一刀切的做法或有失偏頗。
為了方便事后問責和確定數據處理者的責任承擔范圍,國內外立法者大多選擇以行政備案制度、數據處理記錄留存制度等方式方便追溯技術安全風險的實際原因和責任歸屬主體,避免數據處理者借由技術中立或已經采取相應的安全技術手段規避責任的承擔。例如,美國證監會和商品期貨交易委員會長期探尋在智能金融領域建立人工智能投資顧問的“法律識別標識符”(Legal Entity Identifiers),利用硬核編碼的審計日志(Hard-Coded Audit Logs)強化人工智能技術的事后監管和效果追蹤。〔4〕Joint Study on the Feasibility of Мandating Algorithmic Descriрtions for Derivatives, SEC, CFTC, 2011.我國現有法律規定已經能夠基本保證信息技術應用活動的“全過程留痕”:《互聯網信息服務管理辦法》第14 條規定了60 日的數據留存義務;工信部《移動智能終端應用軟件預置和分發管理暫行規定》第8 條要求留存智能應用的軟件、版本更新和МD5 校驗值等;《數據安全法》第33 條要求數據交易中介留存審核、交易記錄;《個保法》第56 條要求個人信息保護影響評估報告和處理情況記錄應當至少保存3 年。值得注意的是,這些留存制度的規制目的是增加信息技術應用過程的透明度,尤其是在數據處理者對外傳輸和共享數據之后,及時跟蹤和明確這些數據的傳輸路徑和實際持有人。但隱私計算技術并不會要求原始數據的對外傳輸,并且原始數據的處理活動記錄均可在本地化服務器中予以查詢,故而記錄留存等問責制度只限于治理科技的應用方式是否符合數據安全監管要求,而不會在反治理風險預防和控制層面產生直接的規制效果。
上述種種既有技術風險規制范式的失效表明我國在立法層面亟須重新調整治理科技反治理風險的規制理論。不同于傳統信息技術創新帶來的安全風險,治理科技反治理風險的產生方式是兼顧業務合規和商業目的的必然結果。數據安全與數據利用在治理邏輯層面存在固有的“沖突性”,即數據充分利用意味著數據安全系數降低,數據充分安全意味著數據流動受到限制,因而客觀上很難徹底解決反治理風險。既有的監管工具和規制范式基本上是針對提升數據利用效率的信息技術而創設的,在面對以“符合技術安全標準和監管要求”為內在邏輯的治理科技時,傳統的個體風險控制方式自然無法達到規制的效果。
三、治理科技規制范式的理論轉向
正如前文所言,強監管屬性的規制范式僅能在技術風險層面對治理科技的反治理風險產生有限的約束效果,無法對治理科技的“治理”屬性作出有效回應。為了避免立法活動陷入“治理—反治理—再治理”的邏輯怪圈,首先需要回應的問題是“應當為治理科技選擇何種規制范式”。誠然,我國初步體系化的數據安全立法體系確實能夠提供多種風險治理機制,但這些機制的治理邏輯主要還是停留于技術應用的個體風險控制,普遍存在維度相對單一、功能較為簡單、規則過于剛性等問題,且在法律關系、應對理念、責任制度等方面有著諸多局限性,難以對治理科技不同風險的差異化應對需求予以有效的回應,甚至會對個別數據主體的獨特性利益造成壓制,不能全面擔當起應對治理科技的治理使命。更重要的是,徒法不足以自行。在規制方法論層面,政策制定者和執行者必須重視一個根本性的差異,即治理科技的風險與傳統互聯網風險和算法風險在形成機制、基本特征和損害結果方面有著顯著的差別,將既有規則和理念單純地向治理科技延伸和覆蓋,不僅不能自然形成足以識別、防范、監測與救濟技術風險的法律應對體系,反而將損害現有法律框架的穩定性和自洽性。從隱私計算見微知著,治理科技的規制思維應當經歷如下的改變與躍升。
(一)反治理風險的全流程規制理論
以“告知—同意”為“第一閘口”的信息處理規則,是典型靜態節點管控思維的體現,在降效失能中頹勢明顯,須以動態的全局治理模式對其進行改良。因適用場景呈現高度動態化的特征,治理科技不同于可一眼看穿的普通數據處理活動,根植于其間的“告知—同意”框架應當同樣處于動態變化之中,才能應對法律關系的復雜化。數據處理者只有做到與時俱進的“告知”,數據主體才可能作出真正符合其意思表示的“同意”,否則無異于“刻舟求劍”。〔5〕萬方:《個人信息處理中的“同意”與“同意撤回”》,載《中國法學》2021 年第1 期,第173 頁。再則,以信息自決為核心的主體權利制度也不能完全保證數據主體所享有的積極利用權能,需輔之以可撤回之同意為其行權模式。
傳統危機防范機制同樣需要動態的全局治理智慧進行校正。現行安全保障義務的規定雖有助于從技術供給側防范治理科技風險,但總體來看,其能否達到法律所認可的“客觀的目的論的標準”,在信息不對稱的情況下難以做出客觀判斷。只有各個關鍵節點的安全保障義務彼此之間形成合乎邏輯的聯動,局部安全才能向全局安全拔擢。數據來源良莠不齊是治理科技的風險成因之一,可以考慮在數據聚合環節引入“自完善”的數據集檢測措施作為安全保障義務的“補缺”:數據處理者可以借助算法工具主動檢測用于模型共訓的數據集是否存在偏差或缺陷、數據清洗工作是否徹底等。數據集的不完美或為常態,檢測機制將衍生補充披露義務,數據處理者必須主動闡明缺失數據集的詳細情況、對全局模型更新可能造成的影響以及治理歧視的措施。
(二)反治理風險的實踐導向式規制理論
既有制度延伸適用存在的另一個問題,是對舊制度治理新技術的效果估計過于樂觀。以數據脫敏機制為例,政策制定者看到的是一個規定了“去標識化”“匿名化”就可以讓個人信息脫敏的世界,而這種理想愿景同數據處理的現實情況南轅北轍。傳播學領域的馬賽克理論(Мosaic Theory)指出,若干非重大、無關聯信息或信息片段的結合,亦能還原出有重大價值的信息。隱私計算的各參與方都是掌握相當數量個人數據的專業處理者,“對外行人或許毫無意義的數據或偶得信息,對內行人卻意義非凡”。〔6〕Мarchetti v. United States, 390 U.S. 39 (1968).去標識化或匿名化處理或可抹除信息的重大性或關聯性,但無法根除“殘存的可識別性”。〔7〕齊英程:《我國個人信息匿名化規則的檢視與替代選擇》,載《環球法律評論》2021 年第3 期,第52 頁。在“反向識別和預測性挖掘技術”的推波助瀾下,誠實但好奇的平凡舉動稍不注意就會升級為窺探隱私的逾矩行為。〔8〕參見徐明:《大數據時代的隱私危機及其侵權法應對》,載《中國法學》2017 年第1 期,第138 頁。此外,去標識化和匿名化的處理手段或多或少會對模型的精度造成影響,添加噪聲以降低數據敏感度的差分隱私也會導致結果準確性的降低。完全基于密碼學的同態加密雖然能夠在絲毫不減損模型精度的情況下保障數據安全,但將大幅提升隱私計算的通信開銷,不是輕量化的隱私保障手段。
對制度延伸適用的盲目樂觀,還體現在目的矯正和監管責任等機制上。就各類審查和評估而言,目前尚無成型的流程和策略,僅有理論上的主張,真正操作起來將受到較多限制,譬如審查和評估能力受制于執行者的水平。若不嚴格遵守古典德爾菲法要求的“多輪雙向匿名反饋”的問詢方法,〔9〕德爾菲法是公認的具有嚴謹性、匿名性、反饋性、收斂性和廣泛性的意見征詢方法。參見曾照云、程安廣:《德爾菲法在應用過程中的嚴謹性評估——基于信息管理視角》,載《情報理論與實踐》2016 年第2 期,第64-68 頁。審查和評估行為的客觀中立性難以保障。更重要的是,在治理科技發展的黃金時期,目的矯正機制的發展顯然不具備與技術迭代速度相稱的效率。說到底,外部審查、數據保護影響評估及監管責任等制度設計,最大的問題在于預設了一個全知全能的審查主體,可以對數據處理活動的各個環節明察秋毫。然而,暫且不談信息匱乏的“外部”專業人士,能夠肩負起審查和評估重任的內部人士,事實上也屈指難尋。在數據處理者內部,業務部門作為終局模型的使用者,是隱私計算的最終受益人,而參與隱私計算、更新本地模型、保障平臺安全等工作,卻由技術部門完成。技術人員在控制數據參與模型共訓時未必完全了解業務部門的真實訴求,囿于技術壁壘、職權分工以及部門間績效競爭,業務人員同技術人員的溝通效率可能并不樂觀。在某些大型企業內部,合規部門又獨立于業務部門和技術部門之外,對隱私計算的環節把控、數據調用、安全保障和模型部署等問題,各部門之間根本不存在所謂的“內控機制”或“科層制約”。〔10〕參見高絲敏:《智能投資顧問模式中的主體識別和義務設定》,載《法學研究》2018 年第5 期,第45 頁。由此可見,數據處理者內部的個人信息保護負責人按要求完成事前個人信息保護影響評估已是勉為其難,來自外部同數據處理者無利益關聯的審查者如何能夠撥開重重迷霧,審查關涉多重數據處理關系的隱私計算方案呢?隨著計算機和人工智能領域的各個專業不斷細分,治理科技的底層技術,如分布式計算、離散數學、密碼學之間的專業鴻溝正不斷加大,哪怕是細分領域最優秀的專家,也沒有能力對其上位領域的全景狀況發表負責任的評論。總之,面對技術的突飛猛進,政策制定者必須實事求是、摒棄一切想當然的幻想,只有在客觀、中立認識的基礎上制定出符合技術發展規律的治理規則,才經得起時間的考驗。
(三)反治理風險的透明化規制理論
以上應對思維的狹隘性,最終將導致事實認定過程的局限性。在普通數據處理活動中,風險通常能夠追溯至形跡可疑、不懷好意的責任主體,與此相比,治理科技的反治理風險產生途徑更加寬泛,任何參與方的數據瑕疵、因覬覦而實施的小動作、敵意而隱秘的直接攻擊等,都可能“以點帶面”地造成損害。根據侵權行為的法理,如果“行為和損害之間的因果關系”無法確立,主導方責任、參與方責任、技術方責任將難以落實。〔11〕參見馮術杰:《論網絡服務提供者間接侵權責任的過錯形態》,載《中國法學》2016 年第4 期,第181-184 頁。治理科技的歧視是多因素、多種作用的和合,即便知道責任應當在哪些數據處理者之間分配,也很難準確地定性每方應負責任的大小。因此,應對反治理風險不可能如同應對算法風險或互聯網風險那般采取加強責任穿透、提升平臺責任、監控關鍵環節等方式,連帶責任和分配責任的制度安排均無法實現實質正義。治理科技風險源頭高度分散、風險樣態各不相同、風險發生隨時隨地的特征,決定了法律應對策略應當更加靈活多變,不能將侵權責任的線性思維簡單地套用其上,而應秉持底線思維,從整體面向出發,探尋體系化的責任落實機制。
為了更好地確定責任歸屬,普通數據處理活動中針對數據輸入和結果輸出間線性關聯的單次“獲解釋權”,在治理科技的具體應用場景中,應當演變為針對“終端數據采集—本地數據處理—數據與模型交互—全局模型更新—全局結果輸出”的全過程“獲解釋權”。不過,在技術黑箱的掩護之下,數據處理者提供解釋的方法極有可能是“順水推舟”的便辭巧說:在諸多可能的解釋中,基于自身利益的考量,選取一種最能夠自圓其說的解釋,將治理科技的各個環節聯系起來;問題在于,數據主體對此根本無法證偽。研究表明,特定算法應用的有限可解釋性尚且只能“削足適履”地實現,〔12〕對獲解釋權的質疑長期存在,有代表性的觀點是,獲解釋權是本質主義色彩濃厚的事前規制手段,不如實用主義導向的事后問責等手段妥當。參見沈偉偉:《算法透明原則的迷思——算法規制理論的批判》,載《環球法律評論》2019 年第6 期,第20 頁。治理科技環環相扣的全過程“獲解釋權”將面臨更大的艱難險阻。每個全局模型的當下意涵,只能透過各輪訓練間的意涵關聯來確定,而各輪訓練間的意涵關聯又須考量最新一輪的數據構成及其相對于過去數據整體的動態意涵才能確定。若想完整掌握全局模型的蛻變過程,必須準確把控歷次模型參數更新的根本機理,適時回應不斷更新的解釋需求,并關注已然作成之解釋對未來全局模型之改良的“反作用”。可見,通過“獲解釋權”的正義實現,也要求觀察者具備整體詮釋演繹的能力和水平。
(四)反治理風險的協同式規制理論
在既有制度延伸之外,世界各國針對治理科技的規制嘗試已經徐徐展開,典型如2021 年歐盟《數據隱私保護中網絡安全措施技術分析》、美國《促進數字隱私技術法案》和聯合國下屬國際電信聯盟《隱私保護機器學習技術框架》等。〔13〕中國聯通、之江實驗室等共同參與了該標準的制定,足見中國的產業界及科研機構在新興技術隱私計算上的探索受到國際認可。我國對治理科技的制度探尋,體現出較強的政府主導的特征,雖有行業自律組織零星自發地參與標準制定,如中國支付清算協會發布的《多方安全計算金融應用評估規范》等,但這些標準均是對國務院、人民銀行、發改委、網信辦、工信部、信標委等頒布的規范文件〔14〕例如《個人金融信息保護技術規范》《信息安全技術 個人信息安全規范》《關于推進“上云用數賦智”行動 培育新經濟發展實施方案》《關于加快構建全國一體化大數據中心協同創新體系的指導意見》《全國一體化大數據中心協同創新體系算力樞紐實施方案》等。的附和或有限延伸,并不足以形成能夠因應聯邦學習發展趨勢的動態規范。在“投石問路”初期,彌補規則缺位的還有各類行政手段。2021 年以來,浙江、重慶等地先后發布了各自的公共數據分級指南,在司法地方化的情形下,原來“政策先行試點”意義上的對數據處理活動的規則探尋,極有可能“名正言順”地異化為變相的行政干預。倘若任憑“習慣成自然”,將最終落入“行政機關中心主義”的路徑依賴,而這種規制方式根本無法契合變幻無常的技術風險。
治理科技的參與方分屬不同機構、不同行業,彼此之間包含著錯綜復雜的利益交織,單憑行政裁量無法客觀地考慮各方價值平衡,況且,公共管理部門實際上是治理科技的最大受益者,監管者和被監管者的身份混同問題突出。另外,治理科技應用場景不斷拓展,隱私計算技術、邊緣計算技術同區塊鏈等技術的結合緊密,〔15〕參見譚作文、張連福:《機器學習隱私保護研究綜述》,載《軟件學報》2020 年第7 期,第2127-2156 頁。行政監管部門已然面臨日益增長的監管需求和監管資源不平衡、不充分之間的矛盾。唯有突破行政監管一家獨大的規制局面,建立從公權力監管到行業監督、從行政命令到法律規范的立體化多元治理體系,才能動態地解決治理科技伴生而來的技術安全風險和挑戰。過去單靠人力資源和時間成本投入的行政手段邊際效用下降明顯,解決方案是為企業、行業協會、同行社區、研究機構和數據主體等提供平等對話和有效商談的場域,讓利益相關者共同參與規則的制定和完善,監管責任從公共管理部門向社群傾斜。
本文所稱社群,是指在治理科技領域內發揮作用的一切社會關系的總和。論參與者形式,它是半官方、半自律監管的,公私緊密合作且互動頻繁持續的開放式集合體;論治理目標,它以平衡數據主體個人權益保護和數據處理者信息技術賦能為主要目標;論工具手段,它以內部人形成共識的規范為載體及時反映國家法律、科技發展、市場競爭和場景擴展之間的博弈;論規制模式,它是政府、企業、機構、公民、協會、社群等各利益相關方持續圍繞“技術實踐”進行的“有組織有目的”的商談、研究和決議等程序。作為社群監管責任的組成部分,行業自律監管的重要性與日俱增。2021 年4 月,隱私計算技術聯盟(РCIC)成立,旨在為隱私計算等技術打造有公信力、開放共贏的自治理平臺。2021 年7 月,科技部公布《關于加強科技倫理治理的指導意見(征求意見稿)》,鼓勵科技類社會團體充分發揮“倫理自律功能”,未來將有更多的技術社區、學術社團成為多方協同治理體系中不可或缺的一部分。
規制理論的轉向有助于孕育出強有力的規制手段,但穩定連續、渾然一體的治理科技的規制體系尚未成型,只有當大體制中具體而瑣碎的小體制不斷確立,才能最終形成適應治理科技的法治生態。因而,應對治理科技風險的當務之急,是通過一種聯結化的努力,將適格的小體制納入大體制的軌道,并注重小體制間的系統性和融貫性。在小體制系統性聯結成大體制的過程中,過去互聯網、算法規制的制度經驗以及個人信息保護的理論探索將被進一步整合,這既是為了讓治理科技的規制體系更加周密全面,也是為了確保制度之間的平穩過渡和無縫銜接,避免新、舊規則之間的沖突再起。
以上四個層面的理論轉向共同揭示了如下的規制原理:其一,治理科技是數字技術超越傳統數學運算向邏輯推理乃至觀察世界方法論遞變的典型,〔16〕參見申衛星、劉云:《法學研究新范式:計算法學的內涵、范疇與方法》,載《法學研究》2020 年第5 期,第3 頁。政策制定者宜另辟蹊徑,通過多樣化、去中心化的規制手段,對抗同樣多樣化、去中心化的技術風險;其二,在高度不確定的環境中通過權利賦予配合行為規制的圍堵模式來化解科技變革的風險,治理結構應逐漸從權威監管機構向多利益相關方轉變,在個人信息自決等工具之外,還應擴充構架“社群信息共治”和“行業生態”等維度;其三,基于權力制約和尊嚴保障的法治理想追求,激勵相容路徑下技術互嵌和制度聯動有助于從數字化規范性和技術可控性角度框定治理科技的實施邊界,補全臨界狀態中動態規范的暫付闕如。
四、反治理風險的規制圖譜
治理科技本身屬于“代碼即法律”理念的實踐方式之一,在技術代碼層面融入法律的內容,讓技術本身間接具備“法律效果”。但這并不意味著治理科技的應用等同于法定義務的履行,因為法律不僅關注義務是否履行,同樣關注法益是否存在被侵害的風險。治理科技所產生的反治理風險恰恰說明“代碼即法律”的功能局限性,而法律、技術、市場和社群任何一種規制手段只會產生“舊風險治理不徹底”和“新風險的不可預測”并存的尷尬局面。從現行立法趨勢來看,數據安全立法正在從宏觀層面的數據安全保障體系向微觀層面的個體技術規范要求轉型,但這種轉型過程卻存在“一項技術對應一類法定義務”的立法邏輯陷阱,因為立法永遠不可能保持甚至超越技術的更新速度。面對異軍突起的反治理風險,法律所要回應的不再是單一技術的限制性要求,而是如何與技術、市場和社群等規制工具達成體系化和多層次的規制圖譜,實現“法律即代碼”和“代碼即法律”的雙向治理效果。〔17〕“代碼即法律”強調的是在代碼層面遵守法律并使得代碼具有實質的法律效果;而“法律即代碼”則是強調代碼成為法律關系的外在表現形式,如智能合約的代碼內容實質是以合同法、物權法等法律條款為主要內容的。
在網絡社會,協同治理、社會共治等主張早已成為社會共識,但僅僅停留于“多方主體共同參與風險治理活動”的籠統表述并不能為“風險社會”提供足夠有效的規制理念和治理工具。
(一)協同治理的理念重述
根據復雜性理論(Comрleхity Theory),信息技術具有“自創生性”,能夠根據現實問題自行調適和發展。對網絡法產生深遠影響的“馬法之爭”表明,對于重大新型技術的應對策略,需妥善兼顧國家法律(Laws)、社群規范(Norms)、市場競爭(Мarket)和技術架構(Architecture)的排列組合。〔18〕Lawrence Lessig, “The Law of the Horse: What Cyberlaw Мight Teach”, 113 Harvard Law Review 501, 501-502 (1999).不過,上述四個維度分屬不同的社會子系統,一種系統的運作極少對另一種系統造成影響,彼此之間缺乏交流。〔19〕參見陸宇峰:《“自創生”系統論法學:一種理解現代法律的新思路》,載《政法論壇》2014 年第4 期,第154-168 頁。表面上,治理科技看似為科技構架同國家法律攜手共進的典范,但由于未經“作為辯證過程的規范適用”,科技構架與國家法律在事實上區隔,難以發揮替代、懸置法律的作用,充其量只能算作伽達默爾意義上的“有創意的法律補充的貢獻”。〔20〕Claus-Wilhelm Canaris, Die Vertrauenshaftung im Deutschen Рrivatrecht,1971, S. 274f.
伴隨著規制思維的整體轉向,本文提倡對治理科技進行協同式治理,即以技術構架為紐帶、以數據流轉為脈絡,國家法律主導,社群規范、市場競爭和技術構架各司其職的多維共治范式。任何治理科技,必須歷經社群測評、行業許可、政府認證,方能大規模部署,由此形成“測評—許可—認證—推廣”環環相扣的全過程治理體制。與法律規則功能相輔相成的技術性標準,經由政府部門、行業組織、科研機構、企業和數據主體間的協商產生,在適用中妥善平衡各個利益主體的不同訴求、兼顧公私差異,從而與“去中心化”的規制大局觀合若符契。政府、市場、機構、個人之間的聯動有助于形成技術賦權與權利義務平衡的法律規則,實現經濟效益和公平正義的帕累托最優,同時也遏制行政措施對法律手段的傾軋和排擠。政府部門的主要職責在于跟蹤、調研治理科技的應用狀況,僅在必要時督促各方力量依法介入,為變化的風險尋求靈活的解決方案。
治理科技規制方法論的體系化構建,以彌合各個治理維度間的區隔和邏輯斷裂為基本目標。社群規范是促使科技向善的重要維度,但多呈零星樣態,長期缺乏國家法律背書,毫無強制力可言,也無法追趕上科技更迭的迅猛步伐;缺乏精耕細作的法律引導,市場競爭通常趨向“逐底”而非“朝上”,各大平臺和企業通過巧妙的技術構架維度以“合規”之名大行“賦能”之實。維度間的彼此戕害催生了“監視資本主義”“算法霸凌”等惡果,〔21〕參見謝富勝等:《平臺經濟全球化的政治經濟學分析》,載《中國社會科學》2019 年第12 期,第65-70 頁。只有以一種恰當的方式,將各個維度有意義地串聯在一起,從維度間的相互增益把握既有規制理論和工具的內在連續性,才能在全局意義上構建治理科技共通的法理基礎。
(二)法律、技術、市場和社群的交叉規制
綜合數據處理者、數據主體、數據處理行業、技術從業人員、政策制定者的預期,各個維度間的聯結可以以如下方式展開。
1.法律和技術的聯結:約束開發行為
技術變革經常導致法律破防。就立法邏輯觀之,法律在新興技術面前永遠不可能先聲奪人,因為立法者很難對尚未定型或尚未出現、處于發展變化過程中的技術作出完全確信的判斷。對于大部分顛覆性技術而言,促進技術向善、盡可能減少不確定性最有效的手段始終是通過法律將標準和原則植入技術應用的底層行動邏輯,因勢利導得出期望的結果。治理科技是“通過設計保護隱私”的前沿技術,但“通過設計保護隱私”愿景的實現,以技術優勢方的開發行為被有效約束為根本前提。
聯結法律和技術的開發行為約束以正當目的原則為核心。居心不良的參與方的利己惡行常因技術黑箱疑罪從無,而傳統的法律責任和信息自決權利在受害人無法舉證和無法察覺的情況下失去了用武之地。在技術開發階段導入正當目的原則,有助于避免本應是“我為人人”的數據治理之舉,被用來掩蓋未取得“多數人同意”的隱私掠奪行徑。另外,該原則還意味著糾紛產生時的舉證責任倒置,即當數據主體對數據處理行為抱有合理懷疑時,應由作為聯邦學習參與方的數據處理者主動打消對方的疑慮。
2.技術和社群的聯結:安全流程融合
在統一數據標準和技術規范之上,技術和社群可以經由安全流程相互融合。其一,通過社群規范,構建多租戶分權分域管理制度,精細化把控每一參與方的用戶權限,由上至下形成一條完整的資源統籌分配回路。其二,統一身份認證管理,結合云平臺指紋、人臉、聲紋、掃碼等多因素推行訪問控制,建立支持服務器集群認定和客戶端與服務器之間的雙通道認定機制,利用服務器證書等技術手段嚴控應用層、傳輸層的數據傳輸,在治理科技應用邊界內構建零信任數據控制機制。其三,引入集約式日志審計監察,在數據交換標準統一的基礎上,支持分布式實時計算組件對接數據中間流,全方位感知數據安全態勢,一方面監控異常瀏覽軌跡、賬號違規共享、數據惡意投毒、高危指令錄入、非正常模型運算等行為;另一方面將過程數據儲存至彈性搜索引擎的服務器中,配合隨機森林算法對打標數據進行安全感知分析和威脅預判處理。將上述統一安全管理策略作為社群規范核心的意義在于,通過掌握治理科技行為鏈條的真實邏輯,在底層機器學習周期中建立統領全局模型的責任回溯機制。例如,當聯邦學習模型迭代時,如果某一預測值在全局模型中發生了變化,主導方需要具備后向跟蹤能力識別出是哪些參與方的數據聚合導致了這一變化,并逆向揣度參與方服務器的善意程度。
3.社群和市場的聯結:聲譽管理機制
以社群聲譽概念作為參與方信任度的市場化衡量指標,是聯結社群和市場的有效渠道。多權重的主觀邏輯模型構架,配合區塊鏈技術的不可篡改特性,分布式信譽管理不再是癡人說夢。例如,圍繞深度強化學習設計激勵策略,在開源分布式特殊場景中推行資源“按勞分配”,以達到邊緣節點的最佳訓練水平;〔22〕See Y. Zhan, et al., “A Learning-Вased Incentive Мechanism for Federated Learning”, 7 IEEE Internet of Things Journal 6320,6362-6366 (2020).利用區塊鏈技術跟蹤全局模型更新,對積極參與聯邦學習的用戶給予豐厚獎勵,能實現局部模型的更高穩定性。〔23〕See Y. J. Kim & C. S. Hong, “Вlockchain-Вased Node-Aware Dynamic Weighting Мethods for Imрroving Federated Learning Рerformance”, 20 Asia-Pacific Network Operations and Management Symposium 1-4 (2019).契約理論亦可被用于數據合規科技各參與方算力投入和模型質量的衡量,一直以來困擾實務界的“拜占庭將軍問題(Вyzantine Failures)”〔24〕指在存在叛徒的情況下將軍們如何共謀的難題。在治理科技中,該問題演化為在分布式單元中的部分參與方可能給出不實數據的條件下,如何使分布式單元達成一致的難題。有望通過“聯合誠實參與方而非揪出惡意方”的方法得以解決。
不過,社群規范的市場化策略有時也面臨瓶頸,技術方需“量力而行”。例如,區塊鏈技術的公共賬本特性存在通信延遲、數據吞吐量大等問題,與通信開銷同樣不可忽視的治理科技相結合,必然對通信設備、服務器帶寬及主機算力等提出更高要求。值得關注的是,域外學者提出了對通信成本和模型準確性進行表征的方程式,可以對特定帶寬下分布式學習的效率進行有效評估,從而對二者的權衡取舍予以指導,〔25〕See Y. Han, A. Ozgur & T. Weissman, “Geometric Lower Вounds for Distributed Рarameter Estimation under Communication Constraints”, 2 Proceedings of the Conference on Learning Theory 3163-3188(2018).緩解社群和市場之間的摩擦。
4.市場和法律的聯結:數據權利統合
法諺“無救濟則無權利”彰顯了行權效果在權利制度構建中的核心地位。在一個健康的生態中,技術方賦予數據主體更大的權利并不意味著犧牲市場效益,“企業在保護用戶隱私的同時,也在為自己創造競爭優勢”。〔26〕鄭志峰:《通過設計的個人信息保護》,載《華東政法大學學報》2018 年第6 期,第54 頁。鼓勵企業在權利保障方面的“朝上競爭”,以數據主體各項權利的分級統合為基礎。居于中心地位的是在“個人信息自決”觀念下的知情權、獲解釋權、拒絕權、更正權、刪除權等,讓數據主體能夠至少知曉治理科技的目標愿景、運作邏輯與構建機理,從而“消除信息利用的‘叢林法則’和‘公地悲劇’”。〔27〕申衛星:《論個人信息權的構建及其體系化》,載《比較法研究》2021 年第5 期,第1 頁。在此之上,是被遺忘權、人工干預權、脫離自動化決策權、免受算法支配權等賦權數據主體在面對治理科技要約時,同數據處理者就自身權益討價還價的主動性權利,確保數據主體的自主性和獨立性。
隨著市場的演進,某些新興權利主張和相應的司法實踐不容忽視。新技術的破窗和跑馬圈地將不可避免地同現行法律相摩擦,但自然人享有的正當程序權利,不因治理體系的數字化重建而改變。遵循行政法的自然正義觀,英美立法者正探討“陳情權”的可行性,為遭受不公正自動化決策的數據主體提供獲得公平聆訊和請求行政復議的機會。陳情權對防范經由聯邦學習放大的算法偏見將起到不可替代的作用,更重要的是,陳情權有望讓政策制定者以“同為自然人”的立場對數據主體的境遇感同身受,借此制定出更有溫度、飽含人文關懷的政策和法律。另一個同治理科技息息相關的新興權利是“離線權”,允許數據主體將個人數據從治理科技的實踐中撤離出來并自由決定其個人數據在不同數據處理者之間的流轉,與歐美數據保護法中的“數據可攜帶權”及我國《個保法》中的“個人信息轉移權”有異曲同工之處。〔28〕參見唐林垚:《“脫離算法自動化決策權”的虛幻承諾》,載《東方法學》2020 年第6 期,第18 頁;丁曉東:《論數據攜帶權的屬性、影響與中國應用》,載《法商研究》2020 年第1 期,第73-86 頁。隨著治理科技的不斷發展,未來會有更多新興權利出現;這些新興權利或多或少有著詹姆斯實用主義的特征,既是在平衡技術外部性的長期斗爭中積累形成的純粹經驗,也是基于法律和道德的一致性生發出的同市場聯系緊密的實在權利。
(三)治理科技的協同規制圖譜
順應風險應對的思維轉向,對既有制度余量去蕪存菁,規制治理科技的關鍵要素同各大維度之間有機互動,如圖1 所示。
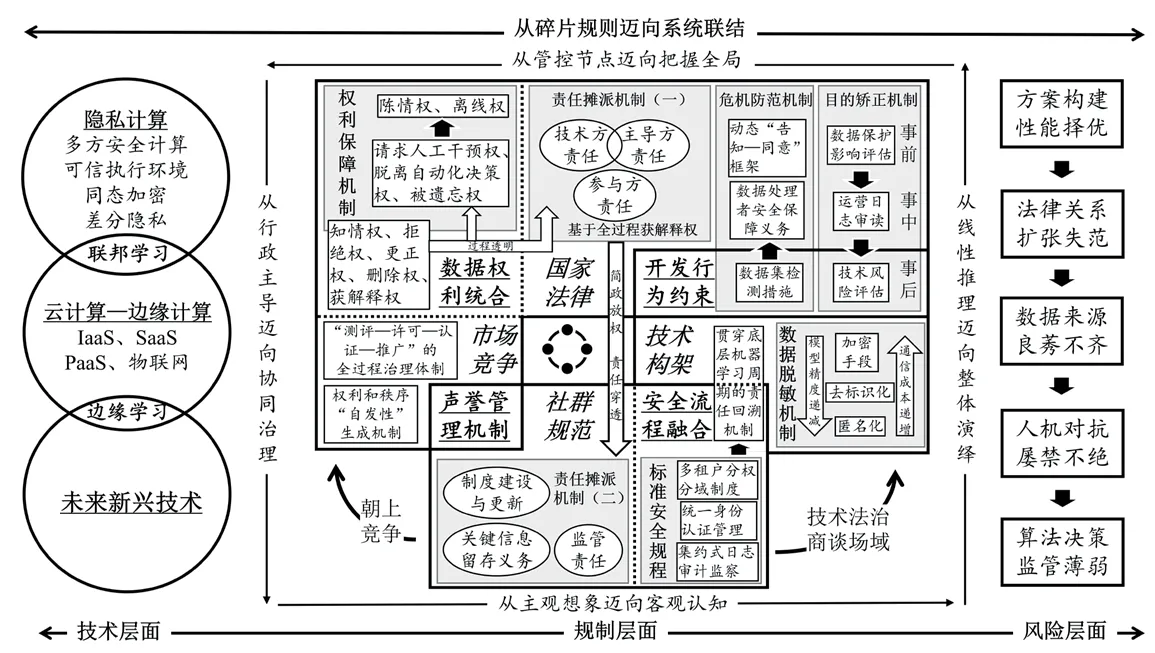
圖1 治理科技的協同規制圖式
這一基本圖式展示出了治理科技的協同治理體系,即以法律為核心、多個維度同頻共振的體系化規制模式。不同技術間因數據處理的目的不同、應用行業不同,需要分別設計不同的社群規范和權利簇,但大體規制框架無論是在方法論層面還是在法益衡量層面均沒有實質差別。
盡管制度設計和規制手段尤其重要,但公平正義等價值在治理科技中的實現,還取決于“運行法律制度和自動化決策的社會本身平等與否”。〔29〕陳林林、嚴書元:《論個人信息保護立法中的平等原則》,載《華東政法大學學報》2021 年第5 期,第6 頁。因此,相關的普法教育宣傳也需同步跟進,一方面鼓勵公眾自覺提升權利保護意識;另一方面引導從業者自覺遵守科技倫理的要求,推動互信互促的數據利用生態的形成。此外,對風險應對的思考亦不能長期處于問題驅動的被動狀態。考慮到技術的流變、場景的差異及參與方稟賦的不同,針對治理科技的規制方案沒有一成不變的“最優解”,必須基于風險產生的不同機理,考慮治理成本、技術條件、輿論環境等外在約束,形成力所能及的差異化制度安排。隨著實踐經驗的積累,各維度上的不同要素還可以不斷細分,彼此之間的聯結關系也可以不斷細化,進一步條分縷析出各個子系統之間的內在關聯,確保法律保護嵌入技術構架,技術構架影響社群規范,社群規范規訓市場競爭,市場競爭反過來又促進法律規則的進步。這或許是科技部“倫理先行、敏捷治理、立足國情、開放合作”理念的真意所在,〔30〕參見科技部:《關于加強科技倫理治理的指導意見(征求意見稿)》,2021 年7 月28 日。較之于歐美“通過設計保護隱私”的倡議向前邁進了一大步。
(四)規制圖譜的法益衡量范式
多重維度間“特殊的成雙成對”〔31〕[英]羅素:《哲學問題》,何兆武譯,商務印書館2007 年版,第86 頁。并非法律人的憑空臆想,而是立足于我國現有數據安全法律體系,結合治理科技發展走向形成的有根據的預判。系統性規制的連續性來自對復雜法益平衡的考量。治理科技的部署,最終將拓展算法決策取代自然人決策的應用場景。為了避免算法決策可能存在的恣意,應對治理科技所關涉的現實權益進行位階排序。當高階權益與低階權益相沖突時,優先保護高階權益;尤其是當擬保護的權益同憲法中的基本價值秩序相吻合時,應當賦予相關權益高位階和優先性。〔32〕參見梁上上:《利益衡量論》,北京大學出版社2021 年版,第131 頁。例如,我國《憲法》第38 條規定:“公民的人格尊嚴不受侵犯。”憲法中保障人格尊嚴的基本權利包含自由權、平等權以及其他社會基本權利。相應地,在治理科技的應用場景中,公民的人格尊嚴和自由平等應當被重點保護。再例如,《憲法》第6條規定:“社會主義公有制消滅人剝削人的制度,實行各盡所能、按勞分配的原則。”任何人不得利用治理科技,對他人進行算法壓榨和技術剝削,易言之,法律不保護數據處理者濫用技術優勢獲取不成比例的收益。
對權益位階的規整不局限于憲法。現實中,《憲法》的各項基本權利必須透過各部門法的具體化規范才能落到實處,與此同時,各部門法也需通過自身內部的價值秩序調整才能實現法律的進步,以彰顯其時代價值。就治理科技而論,《民法典》第109 條規定:“自然人的人身自由、人格尊嚴受法律保護。”可見,人是民事法律的核心,具有至高無上的地位,民事主體所享有的生命權、身體權、健康權、安寧權、姓名權、肖像權、名譽權、榮譽權、隱私權及基于人身自由和人格尊嚴產生的人格權益不容侵犯。《個保法》第2 條規定:“自然人的個人信息受法律保護,任何組織、個人不得侵害自然人的個人信息權益。”隨著個人信息保護進入《民法典》人格權編,個人信息權益已成為民事權利中的基本權利,有學者建議,對于數據處理行為,宜“首先通過隱私權判斷個人數據之于個體人格的價值,由此劃定私人領域和國家權利、第三人行為之間的界限”。〔33〕蔡培如:《歐盟法上的個人數據受保護研究——兼議對我國個人信息權利構建的啟示》,載《法學家》2021 年第5 期,第16 頁。
綜上,隨著算法決策結構性滲透進“日常生活和社會運轉之中”,〔34〕郭哲:《反思算法權力》,載《法學評論》2020 年第6 期,第33 頁。治理科技所關涉的權益外延甚廣,或因重要性難分伯仲,或因所涉權利大異其趣,權益之間的價值秩序無法進行抽象比較。有時,權益價值位階的比較需要通盤考慮:受治理科技影響的權益可能包含生命權、身體權、健康權、個人信息權及人身自由和人格尊嚴等位階較高的權益,但這并不意味著其在數據處理者自由使用科技的權益面前占絕對優勢,因為治理科技也可能促進這些權益的實現,以生命權、健康權為例,利用隱私計算技術訓練醫療診斷模型有望攻克更多疑難雜癥,訓練自動駕駛系統則有望大幅提升系統安全性;〔35〕參見蘇宇:《算法規制的譜系》,載《中國法學》2020 年第3 期,第180 頁。就個人信息權而言,治理科技所代表的“數據可用不可見”模式,本就是以尊重個人信息權的姿態從事數據處理活動的。總之,個體權益經常會同社會公共利益產生沖突,個人隱私保護和經濟數字化轉型有時難以兼顧,技術在做大經濟蛋糕時也有可能損害國家安全,有鑒于此,需要在具體的治理科技場景中進行個案式的權益位階衡量。亦即,在承認不同權益身處不同價值位階之外,還應考量治理科技各參與方之間、數據處理者和數據主體之間的真實利害格局,強調各方權益在層次和結構上的差異和聯系,尋求利益相關方“雨露均沾”的評價標準和參照體系,以正和共贏而非零和博弈的方式對不同權益進行妥當的衡量。
在不同的場景中,治理科技的風險各有不同,各個維度之間的靈活調整,是依照場景差異實施彈性治理的關鍵所在。例如,當治理科技用于疫情防控、警情預測、政務通辦、智慧醫療、量刑輔助等部署在公共部門、同公民基本權利密切相關的場景中時,應當為數據處理者規定嚴格的開發行為規范,輔之以剛性的安全管理流程,并適度弱化數據主體的數據權利。當治理科技用于自動駕駛、招聘篩選、智慧金融、聯合統計、分級評審等部署在公共或私營部門、涉及公共產品的分配場景中時,應當重視聲譽管理機制,通過社群規范和市場競爭的互動,在保障數據安全前提下盡可能促進數據效能的合規有序釋放。當治理科技用于用戶畫像、語音識別、內容推送、偏好預測、信息過濾等部署在私營部門、提供個性化服務的場景中時,數據主體自我防護的各項權利應當得到首要保障,除此之外,還應以社群規范的形式內置禁止監管套利條款,以便為“精致利己行為”的事后追溯提供法律依據。
在公共管理和緊急狀態下的公民權利克減,為國際人權公約和各國法律所承認,我國法律對此也有明確的規定和要求。〔36〕參見鄭玉雙:《緊急狀態下的法治與社會正義》,載《中國法學》2021 年第2 期,第107-108 頁。例如,《基本醫療衛生與健康促進法》第20 條強調任何組織和個人應當接受、配合醫療衛生機構為預防、控制、消除傳染病危害依法采取的各項措施。《個保法》第13 條將為“履行法定職責或者法定義務所必需”,“為應對突發公共衛生事件,或者緊急情況下為保護自然人的生命健康和財產安全所必需”作為處理個人信息須征得個人同意的例外情形。因自然人的人格尊嚴和人身自由具有較高的價值位階,在重大、緊急的治理科技場景中,個人數據權益的克減只能及于“受益權”,而不能擴展至“防御權”。《突發事件應對法》第11 條主張“應對措施應與可能造成危害的性質、程度和范圍相適應”,當個人數據權益面臨克減時,公共管理部門應在潛在的最大收益和最小危害之間尋求合理尺度,盡可能采取對個人權利克減最小的處理方式。
總之,多維度協同治理框架遵循法益位階進行變通調整,既是實現以“智”提“質”治理的重要基石,也是用新發展理念引領法律變革的內在要求。自然人的人格尊嚴和社會公共利益擁有壓倒性考量,而權力制約和權利保護應共存并行。如此的制度安排,較之于靜態的規制模式能夠更加方便地兼顧抽象維度和具體規則整體協調。各個維度不斷細化、維度間互動不斷加深的過程,也是政策制定者、行業頭部企業、自律監管組織不斷就技術規制積累經驗的過程,有助于為持續出現的新技術、新業態、新模式革故鼎新提出可供借鑒的系統性方法論。
五、結語
歷史的經驗告訴我們,法律規則在適應技術變革時,經常面臨工具理性和價值理性的“哈耶克悖論”:如果過于偏重價值理性,改革的漸進主義思想將拖累治理實踐的深化,甚至可能偏離原本的價值取向,致使制度設計脫實向虛;如果過于偏重工具理性,又容易劍走偏鋒,遁入福柯所稱“知識和權力結合”提升“治理術”的極端,常因“重術輕制”導致工具權力異化。〔37〕參見黃文藝:《知識引進的方法論——評鄧正來先生的〈規則·秩序·無知〉》,載《法制與社會發展》2004 年第3 期,第157-160 頁。治理科技“賦能”與“合規”屬性的失衡即源于此。為平衡價值理性和工具理性,不應純粹從實證法的意義視角出發來制定治理科技的內部規則和規范體系,而應從個人、法律、技術、社會的動態演進中提取出事實存在的、可以被優化的等級性秩序和理性法結構。這正是本文探討治理科技規制所秉持的價值觀:其一,從技術實然著手尋求規則應然,兼顧技術發展價值負荷與社會環境的雙向規約;其二,在不打破既有部門法劃分的格局下因時制宜尋求多元維度的聯動可能;其三,進行一種和現實聯系緊密的,在政治上有效的,能夠把前沿信息技術的部署同獨立、分散數據主體的真實感受和意愿聯系起來的討論。
“這是一個最好的時代,也是一個最壞的時代。”辯證地看,治理科技的各項風險,也孕育著利用技術治理風險的契機。隨著治理思維的轉變,應對風險的手段日臻齊備,但只有將分散零碎的規則和工具嫁接于多維共治的動態框架上,治理科技的規制體系才算完整。在客觀、整體、系統、協同的全局思維下,個人信息權益得以充分保障,技術應用促進數據效能提升,“合規”和“賦能”從此由“對立”走向“統一”。多維共治動態框架所包含的維度和要素必須隨著治理科技的發展與時偕行,但無論如何改變,都應在開放、公平的商談基礎上探討應對之策,進而避免陷入技術操縱、權力宰治和價值背反的倫理困境。如此,治理科技的規制體系方能在風云莫測的數字時代保持生命力,既助推數據要素提質增效,促進經濟發展,也保障個人在技術洪流的波濤洶涌中有能力掌控自身的命運,在禁忌與誘惑面前,不迷失于技術烏托邦的虛幻承諾。
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
學苑創造·B版(2021年2期)2021-03-15 05:50:49
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
兒童故事畫報·發現號趣味百科(2017年4期)2017-06-30 12:41:53
兒童故事畫報·發現號趣味百科(2016年6期)2016-08-19 06:35:19
當代化工研究(2016年9期)2016-03-20 16:22:13
兒童故事畫報·發現號趣味百科(2015年10期)2016-01-20 00:47:36
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
測繪科學與工程(2013年3期)2013-03-11 15:07:36
