基于Flink的實時數倉設計及DPI業務應用
2022-05-27 17:03:11吳小芳
計算機時代 2022年5期



摘? 要: 在大數據時代,數字化轉型是企業發展戰略的必然選擇,而實時數倉建設則是數字化轉型的重點。實時計算相對于傳統的批處理,能夠快速體現數據的價值,有著廣泛的實時業務場景需求。本文提出一種基于Flink的實時數倉設計,并在DPI業務場景得到實踐驗證,有效支撐了運營商對業務請求次數、流量、活躍用戶數、業務成功率等多維度指標需求,可為其他更廣泛的實時業務場景落地奠定堅實的基礎。
關鍵詞: 流式計算; Flink; 實時數倉; DPI
中圖分類號:TP311? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2022)05-56-04
Design of real-time data warehouse based on Flink and application of DPI service
Wu Xiaofang
Abstract: In the era of big data, digital transformation is the inevitable choice of enterprise development strategy, and construction of real-time data warehouse is the top priority of digital transformation. Compared with traditional batch processing, real-time computing can quickly reflect the value of data and has a wide range of real-time business scenarios. In this paper, a real-time data warehouse design based on Flink is proposed and verified in practice in DPI business scenarios. It effectively supports the operators' requirements for multi-dimensional indicators such as business request times, traffic, number of active users, and business success rate. It can lay a solid foundation for the implementation of other broader real-time business scenarios.
Key words: flow calculation; Flink; real time data warehouse; DPI
引言
當今世界,信息化、數字化、智能化成為鮮明的時代特征,數字經濟成為經濟高質量發展的重要支撐。5G時代的來臨,更為數字經濟發展提供了嶄新的動能,數字化轉型成為企業發展戰略的必然選擇。
根據IBM Marketing cloud的最新報告,“僅過去兩年就創建了當今世界90%的數據,每天創建2.5億億字節的數據,隨著新設備、傳感器、新技術的出現,數據增長率還會進一步加快”。運營商DPI(深度報文解析)包括LTE、DPI和家寬DPI,通過分光鏡像的數據是海量的,基于這些DPI數據,充分挖掘使用價值,可為網絡質量與市場業務提供指導作用。運營商信令數據在場景保障、網絡指標裂化、投訴處理、感知問題溯源、問題定位定界等方面起重要作用。針對全網或某些重點區域進行實時指標監控,可以先于投訴解決問題,提升用戶對網絡感知滿意度。
目前現已有大數據基礎設施建設,批處理采用基于Spark計算引擎分布式集群,流處理采用基于Storm組件分布式集群。但隨著技術的迭代更新,各種處理組件層出不窮,在集群搭建組件選擇時,需遵循數據處理高效性、集群穩定性、投資合理性三方面原則基礎上,因地制宜,嘗試新的技術選型,進而提高性能,降低資源投入。
基于上述問題,本文提出了一種基于Flink的實時數倉設計,應用于運營商DPI數據業務中,在性能、吞吐量等方面效果明顯提升,有效地減少了集群中服務器節點數量,節約了硬件資源。
1 Flink概述
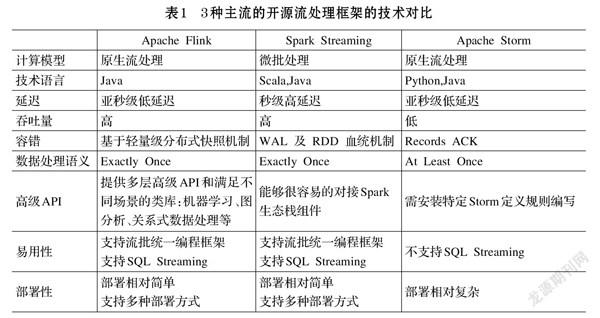
Apache Flink[1,2]是一個面向分布式數據流處理和批量數據處理的開源計算框架,它可以在同一個Flink運行時(Flink Runtime)支持分布式流處理和批處理兩種類型功能應用[3],極大提高了迭代算法的性能。Flink開源項目是近兩年大數據處理領域冉冉升起的一顆新星,但在國內許多大型互聯網企業的工程實踐中均有應用,如阿里、美團、京東等。本文對三種主流開源流處理的技術做對比,具體如表1所示。
從編程語言角度而言,Spark編程語言主要是Java和Scala。而Flink主要是Java,編程語言更加成熟,代碼通用度更高,修改代碼更容易。
從時延和吞吐量角度而言,Flink是純粹的流式設計,通過使用顯示迭代程序[4],極大提高了算法性能。Flink吞吐量約為Storm的3~5倍,Flink在滿吞吐時延遲約為Storm的一半。Flink在時延和吞吐量方面的性能表現較好,特別適用于對超大規模數據流在線實時計算的要求。
從與現有生態體系結合角度而言,Flink與超大型計算和存儲HBase的結合比Spark和Storm更有優勢,同時接口也更友好。
綜合比較之下,Flink是一個設計良好的框架,它不但功能強大,而且性能出色,同時兼顧低延遲、高吞吐和高性能,所以這是本文采用Flink技術的主要原因。
2 架構設計
2.1 整體架構設計
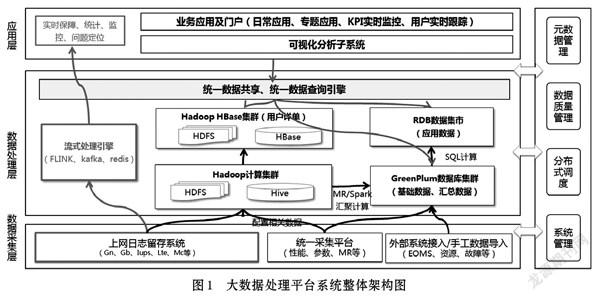
本項目采用架構分層、功能模塊化的總體設計思路。模塊間采用標準接口,便于升級替換,整體架構分為三層,具體如圖1所示。
⑴ 數據采集層:支持多源異構數據源的數據采集。包括:上網日志留存系統、統一采集平臺等。
⑵ 數據處理層:對接數據采集層源數據,實現數據的多樣化處理。包括:流式處理、批處理等。對外提供統一的數據共享、數據查詢引擎。
⑶ 應用層:依托數據處理層提供的統一數據共享、數據查詢引擎,服務多場景引用。包括:可視化分析子系統、業務應用及門戶、實時場景。
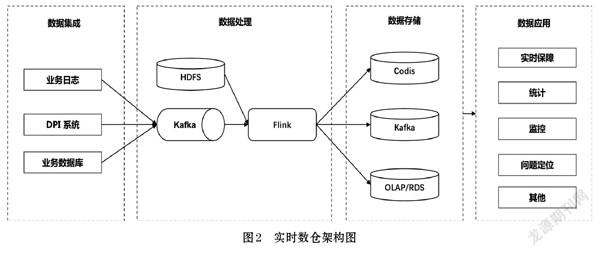
2.2 實時數倉架構設計
在圖1所示的大數據處理平臺系統整體架構基礎上,針對實時鏈路進一步細化,其遵循架構分層原則,將數據處理層拆分為二層:數據處理和數據存儲,旨在強調Apache Flink的技術核心角色,其完成上游ODS原始數據和DIM公共維表數據的攝取,對接下游DWS實時指標的存儲,圖2為實時數倉架構設計圖。
3 DPI業務實現
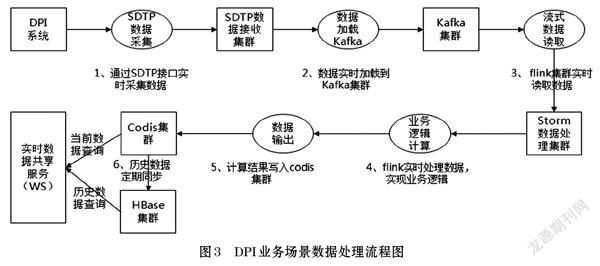
圖3所示為DPI業務場景數據處理流程,技術選型SDTP+Kafka+Flink+Codis,包括以下六個步驟。
Step1:通過SDTP接口實時采集數據,DPI系統產生的信令數據經過分光、回填地市、號碼、打時間戳等數據預處理動作,輸出XDR數據到SDTP數據接收集群。
Step2:數據實時加載到Kafka集群,通過SDTP接口實時接收XDR數據,完成解析等預處理動作后實時加載到Kafka集群。
Step3:Flink集群實時讀取XDR數據。
Step4:Flink實時處理數據,實現業務邏輯,完成各類型實時指標的計算。
Step5:計算結果實時寫入Codis集群。
Step6:歷史數據定時同步,提供統一的實時數據共享服務(包括:OpenAPI,WS)對外提供數據服務,包括實時數據查詢、歷史數據查詢等。
3.1 數據采集
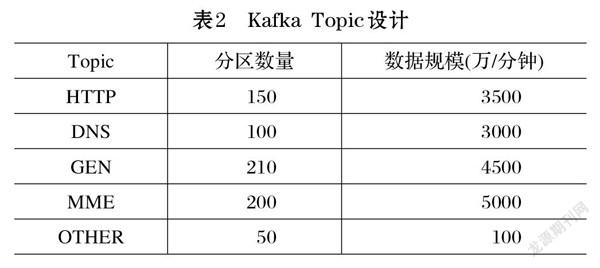
通過SDTP接口實時采集DPI系統數據并輸出到Kafka集群時,根據業務屬性和數據規模, 對Kafka Topic進行了細化設計,具體見表2所示。
3.2 數據處理
信令實時指標定義,時間維度包括1分鐘、5分鐘。空間維度從小到大包括小區、場景/地市、省等。指標包括:業務請求次數(COUNT)、流量(SUM)、活躍用戶數、業務成功率等。文中表3給出了實時指標定義示例。
根據不同的指標定義,對應不同的Flink作業。
⑴ 基礎指標作業。可分三層,第一層數據接入,第二層完成最細粒度維度所有小區的指標計算,是最核心邏輯。第三層高維度指標聚合,通過第二層中間節點,下游輸入數據規模由無限降為有限,最多為小區數*業務細類數,與源數據量無關。
⑵ 用戶數指標作業。因為用戶數指標的特殊性,其只能對接全量XDR源數據,獨立計算所有維度。
3.3 數據存儲
本文采用的技術選型Codis集群,根據業務類別和實時指標規模,設計多維度鍵值指標存儲模式,具體詳細指標如表4所示。
3.4 應用效果
根據設計的方案,通過實施部署91臺物理機,支撐處理數據量100T/天,數據條數3735億條/天。
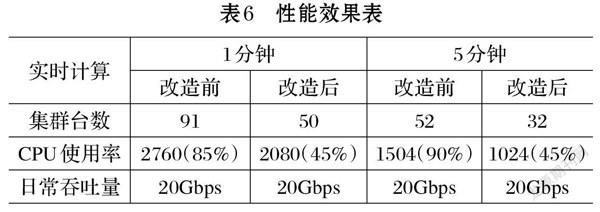
經過測試應用,1分鐘粒度時延由9分鐘縮短為2分鐘,5分鐘粒度由9分鐘縮短為6分鐘,時延效果如表5所示。在硬件方面,節省了物理機,減少了硬件投資,降低了CPU使用率,具體性能效果如表6所示。
4 結束語
本文通過分析傳統實時數倉組件Spark Streaming和Apache Storm的處理效率低、吞吐率低等問題,基于Flink組件,設計了高效的實時數倉架構,并且結合運營商DPI數據業務場景,實現了技術選型為SDTP+Kafka+Flink+Codis的系統開發上線,在減少大量硬件投入的情況下,滿足了運營商對于業務請求次數、流量、活躍用戶數、業務成功率等多維度指標需求,達到了降本增效的目的。
參考文獻(References):
[1] Alexandrov A, Bergmann R, Ewen S, et al.The
Stratosphere platform for big data analytics[J].Vldb Journal,2014,23(6):939-964
[2] Apache Flink[EB/OL].[2019-09-01].https://flink.apache.
org/.
[3] 宋靈城.Flink和Spark Streaming流式計算模型比較分析[J].
通信技術,2020,53(1):59-62
[4] 代明竹,高嵩峰.基于Hadoop、Spark及Flink大規模數據
分析的性能評價[J].中國電子科學研究院學報,2018,13(2):149-155
收稿日期:2021-10-25
*基金項目:江西省教育科學規劃項目“教育大數據背景下在線學習資源個性化智能推薦研究”(21QN012)
作者簡介:吳小芳(1990-),女,江西九江人,碩士,工程師,主要研究方向:信息技術,數據挖掘。
