基于Python的LSTM模型對(duì)流感預(yù)測(cè)的研究*
2022-05-28 04:18:12翟夢(mèng)夢(mèng)王旭春全帝臣李美晨陳利民仇麗霞
中國(guó)衛(wèi)生統(tǒng)計(jì) 2022年2期
關(guān)鍵詞:模型
翟夢(mèng)夢(mèng) 王旭春 任 浩 全帝臣 李美晨 陳利民 仇麗霞△
【提 要】 目的 探討基于keras的LSTM模型和SARIMA模型預(yù)測(cè)我國(guó)北方省份流感樣病例數(shù)的可行性,為流感防控工作提供合理的預(yù)測(cè)方法。方法 利用國(guó)家流感中心2013-2019年北方省份的周流感監(jiān)測(cè)數(shù)據(jù)構(gòu)建LSTM模型和SARIMA模型,并進(jìn)行預(yù)測(cè)。采用平均絕對(duì)誤差(MAE)、均方根誤差(RMSE)評(píng)價(jià)兩種模型的預(yù)測(cè)效果。結(jié)果 LSTM、SARIMA模型的MAE值分別為304.19、352.74,RMSE值分別為398.71、521.07;相比之下,LSTM模型的預(yù)測(cè)性能優(yōu)于SARIMA,較SARIMA模型預(yù)測(cè)性能分別提高了13.76%、23.5%。結(jié)論 基于Keras的LSTM模型的預(yù)測(cè)效果較好,優(yōu)于SARIMA模型,可為流感預(yù)測(cè)提供科學(xué)依據(jù)。
流行性感冒簡(jiǎn)稱流感,流行期間會(huì)造成學(xué)生缺課、人員缺勤、勞動(dòng)力嚴(yán)重喪失,嚴(yán)重影響人群的健康狀況[1];流行高峰期間,發(fā)病和就診人數(shù)急劇增加,門診和住院負(fù)擔(dān)也會(huì)隨之加重[2-3],阻礙了社會(huì)經(jīng)濟(jì)的有序發(fā)展。近年來我國(guó)流感發(fā)病數(shù)呈上升趨勢(shì),因此,準(zhǔn)確、合理的預(yù)測(cè)模型對(duì)政府的決策和有效防控有著重要的指導(dǎo)意義。
流感監(jiān)測(cè)數(shù)據(jù)具有時(shí)間序列特征,自回歸移動(dòng)平均(autoregressive integrated moving average,ARIMA)模型作為傳統(tǒng)時(shí)間序列預(yù)測(cè)的代表,能夠分析數(shù)據(jù)的長(zhǎng)期趨勢(shì)、周期性變化和隨機(jī)擾動(dòng),是疾病預(yù)測(cè)中最常用的一種方法[4]。當(dāng)時(shí)間序列數(shù)據(jù)存在季節(jié)性或周期性波動(dòng)時(shí),常構(gòu)建季節(jié)性自回歸移動(dòng)平均(seasonal autoregressive integrated moving average,SARIMA)模型[5],但在實(shí)際應(yīng)用中,往往需要通過差分等方法將不平穩(wěn)序列變?yōu)槠椒€(wěn)序列,這會(huì)造成信息浪費(fèi)且隨著預(yù)測(cè)時(shí)間的延長(zhǎng),精確度隨之降低[6]。近年來,隨著計(jì)算機(jī)硬件和算法的提升,深度神經(jīng)網(wǎng)絡(luò)(deep neural network,DNN)的計(jì)算得以實(shí)現(xiàn),與傳統(tǒng)時(shí)間序列方法相比,不需要對(duì)原始時(shí)序數(shù)據(jù)進(jìn)行平穩(wěn)性處理,也能獲取數(shù)據(jù)的波動(dòng)性及規(guī)律性特征[7],其中,循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)的預(yù)測(cè)性能較好,但當(dāng)時(shí)間序列較長(zhǎng)時(shí),RNN會(huì)出現(xiàn)梯度消失及長(zhǎng)期記憶能力不足的問題[8-9]。1997年,Jürgen Schmidhuber等人提出了長(zhǎng)短期記憶神經(jīng)網(wǎng)絡(luò)(long-short term memory,LSTM),可以很好地解決上述問題,更適合處理長(zhǎng)時(shí)間序列數(shù)據(jù)[10]。目前,LSTM已被應(yīng)用于股票預(yù)測(cè)[11]、銷售預(yù)測(cè)[12]等領(lǐng)域,但在流感預(yù)測(cè)方面少見報(bào)道,本研究利用2013-2019年國(guó)家流感中心報(bào)告的北方省份流感樣病例建立基于keras平臺(tái)的LSTM模型,研究其對(duì)流感的預(yù)測(cè)性能,并與SARIMA模型進(jìn)行比較,為我國(guó)傳染病預(yù)測(cè)提供科學(xué)依據(jù)。
資料與方法
1.資料來源
本研究使用的數(shù)據(jù)來源于國(guó)家流感中心(http://www.chinaivdc.cn/cnic/)。國(guó)內(nèi)的流感調(diào)查研究發(fā)現(xiàn),我國(guó)南方與北方流感流行情況存在差異,由于北方的流感樣病例報(bào)告數(shù)較南方省份有更為明顯的季節(jié)特征,更適合建立SARIMA模型,因此,整理了北方省份2013-2019年共364周的流感監(jiān)測(cè)周報(bào)數(shù)據(jù)進(jìn)行分析和建模。
2.研究方法
(1)SARIMA模型
預(yù)處理過程包括:①平穩(wěn)性檢驗(yàn):根據(jù)單位根檢驗(yàn)(augmented dickey-fuller test,ADF)及自相關(guān)函數(shù)圖判斷序列平穩(wěn)性。②白噪聲檢驗(yàn)(Box-Ljung檢驗(yàn)):對(duì)平穩(wěn)序列進(jìn)行白噪聲檢驗(yàn),若序列為白噪聲序列則分析結(jié)束,若為非白噪聲序列則進(jìn)行建立SARIMA模型。
SARIMA模型表達(dá)式為:(p,d,q)(P,D,Q)S。p,q為自回歸和移動(dòng)平均階數(shù),d為差分次數(shù),P、Q為季節(jié)自回歸和移動(dòng)平均階數(shù),D為季節(jié)差分次數(shù)。其構(gòu)建過程主要包括:①根據(jù)調(diào)整后序列的自相關(guān)圖與偏相關(guān)圖,選擇可能的p、q、Q和P值進(jìn)行擬合。②運(yùn)用極大似然估計(jì)法估計(jì)模型參數(shù)。③模型檢驗(yàn):最終通過最小信息量準(zhǔn)則(the Akaike′s information criterion,AIC)和施瓦斯貝葉斯準(zhǔn)則(Schwars′s bayesian criterion,SBC)最小原則選擇最優(yōu)模型。④利用所選的最優(yōu)模型進(jìn)行預(yù)測(cè)。
(2)LSTM模型
LSTM模型于1997年被Sepp Hochreiter和 Jurgen Schmidhuber提出,后被Alex Graves、Haim Sak和Wojciech Zaremba等人逐步改進(jìn)并予以應(yīng)用[10],是一種特殊的RNN網(wǎng)絡(luò)類型。LSTM模型中引入了獨(dú)特的記憶單元結(jié)構(gòu),使其可以在學(xué)習(xí)時(shí)間序列長(zhǎng)期依賴性的同時(shí)克服RNN的梯度消失問題,使網(wǎng)絡(luò)能夠更加有效地利用長(zhǎng)時(shí)間序列信息,同時(shí),LSTM模型對(duì)時(shí)間序列無平穩(wěn)性要求,可以直接對(duì)序列進(jìn)行訓(xùn)練,減少了人為因素的干預(yù),使得模型具有較強(qiáng)的客觀性,因此,本研究選擇該模型進(jìn)行分析與預(yù)測(cè)。
由于LSTM模型是RNN的一種改進(jìn)模型,其模型基本結(jié)構(gòu)與RNN相同。RNN結(jié)構(gòu)如圖1所示,LSTM模型僅與RNN的隱含層模塊(單元結(jié)構(gòu)A)不同。
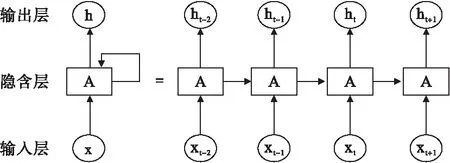
圖1 RNN結(jié)構(gòu)
LSTM模型是將RNN的隱含層模塊(單元結(jié)構(gòu)A)重新設(shè)置為L(zhǎng)STM單元結(jié)構(gòu),其內(nèi)部結(jié)構(gòu)如圖2所示。圖2中的A分別代表一個(gè)LSTM單元。
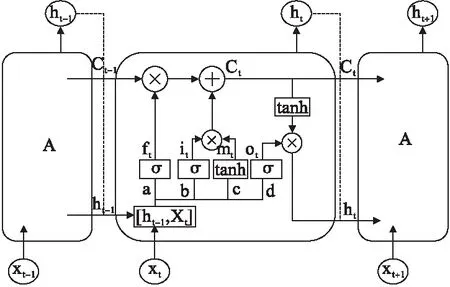
圖2 LSTM網(wǎng)絡(luò)單元結(jié)構(gòu)
LSTM模型中的單元結(jié)構(gòu)A(LSTM單元)又稱記憶單元,由輸入門、遺忘門和輸出門組成,其中,a表示遺忘門,決定傳來的信息是否要丟棄;b表示輸入門,與c共同更新當(dāng)前時(shí)刻的單元狀態(tài),具體是通過將it和mt相乘更新當(dāng)前時(shí)刻的單元狀態(tài)Ct,并將其傳遞到下一個(gè)記憶單元;d表示輸出門,決定當(dāng)前時(shí)刻輸出的值,由ot和經(jīng)tanh函數(shù)處理的Ct共同決定。模型通過這三種門控結(jié)構(gòu)控制信息在記憶單元和神經(jīng)網(wǎng)絡(luò)中的流動(dòng)[13]。ft、it、ot分別代表三個(gè)門結(jié)構(gòu)狀態(tài),mt代表單元輸入狀態(tài),ht-1代表t-1時(shí)刻的輸出、xt代表t時(shí)刻的輸入。具體計(jì)算公式如下[14]:
ft=σ(Wfhht-1+Wfxxt+bf)
it=σ(Wihht-1+Wixxt+bi)
mt=tanh(Wmhht-1+Wmxxt+bm)
Ct=ftCt-1+immt
ot=σ(Wohht-1+Woxxt+bo)
ht=ottanh(Ct)
式中,W表示連接兩層的權(quán)重矩陣,σ表示sigmoid激活函數(shù),b是對(duì)應(yīng)的偏置項(xiàng)。
LSTM模型構(gòu)建過程:①將原始數(shù)據(jù)進(jìn)行預(yù)處理,包括數(shù)據(jù)歸一化及數(shù)據(jù)重構(gòu);②轉(zhuǎn)換為3D數(shù)據(jù):將預(yù)處理過的數(shù)據(jù)轉(zhuǎn)換為適合LSTM要求的3D數(shù)據(jù);③基于Python的深度學(xué)習(xí)框架Tensorflow下的keras平臺(tái)來建立LSTM模型,使用訓(xùn)練集數(shù)據(jù)對(duì)模型進(jìn)行訓(xùn)練;④使用訓(xùn)練后的模型在測(cè)試集上進(jìn)行;⑤預(yù)測(cè)數(shù)據(jù)反歸一化。
數(shù)據(jù)歸一化:為了提高模型的訓(xùn)練速度和預(yù)測(cè)精度[15],本文使用min-max normalization方法對(duì)原始數(shù)據(jù)進(jìn)行歸一化處理。
式中:X*為數(shù)據(jù)歸一化后的值;X為原始數(shù)據(jù),Xmax和Xmin分別為其最大值和最小值。
數(shù)據(jù)重構(gòu):由于流感數(shù)據(jù)為一維時(shí)間序列,而LSTM模型的數(shù)據(jù)樣本要有輸入X和對(duì)應(yīng)的輸出Y,因此,本文通過滑窗法進(jìn)行數(shù)據(jù)重構(gòu)。
滑窗法是使用過去時(shí)間點(diǎn)觀測(cè)值來預(yù)測(cè)下一時(shí)間點(diǎn)預(yù)測(cè)值的方法,具體重構(gòu)過程如圖3所示,即假設(shè)原始時(shí)間序列為具有m個(gè)時(shí)間點(diǎn)的觀測(cè)值序列,將t時(shí)刻之前的k個(gè)時(shí)間點(diǎn)的觀測(cè)值作為輸入Xt,t時(shí)刻的觀測(cè)值作為輸出Yt。以此類推,將原始時(shí)間序列重構(gòu)為有輸入和輸出的數(shù)據(jù)集。圖3中將k設(shè)置為6(即使用t時(shí)刻前6個(gè)時(shí)間點(diǎn)的觀測(cè)值作為輸入),此時(shí)Xt為[[3],[4],[5],[6],[7],[8]],是一個(gè)2D張量,t時(shí)刻的Yt為[[9]],同樣是2D張量。Xt+1為[[4],[5],[6],[7],[8],[9]],對(duì)應(yīng)的Yt+1為[[10]]。以此類推,則重構(gòu)后的數(shù)據(jù)集包含m-k個(gè)樣本點(diǎn)。其中,1,2,3,4…8,9,10…m分別代表各時(shí)間點(diǎn)觀測(cè)值歸一化后的數(shù)值。
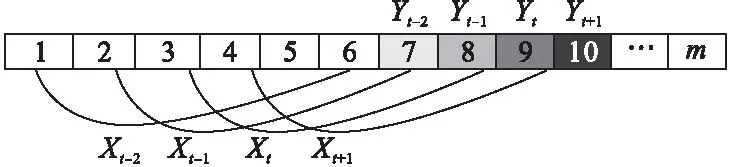
圖3 滑窗法數(shù)據(jù)重構(gòu)示意圖
數(shù)據(jù)轉(zhuǎn)換:由于LSTM模型要求輸入數(shù)據(jù)的格式為(samples,time_steps,input_dim)的3D張量(3D數(shù)據(jù))。其中,samples代表樣本量,time_steps代表時(shí)間步長(zhǎng),input_dim代表每個(gè)時(shí)間步的數(shù)據(jù)維度。經(jīng)數(shù)據(jù)重構(gòu)后(圖3),得到的輸入樣本Xt-2、Xt-1、Xt、Xt+1、Xt+2…Xm-6均為2D張量,將重構(gòu)后的輸入樣本按順序組合在一起時(shí)就轉(zhuǎn)換成了LSTM所要求的3D張量。由于時(shí)間步長(zhǎng)不同,重構(gòu)后的樣本量也不相同,當(dāng)時(shí)間步長(zhǎng)為k時(shí),樣本量為m-k,且流感序列為一維數(shù)據(jù),因此,LSTM模型的輸入數(shù)據(jù)格式為(m-k,k,1)。
(3)模型效果評(píng)價(jià)
采用平均絕對(duì)誤差(mean absolute error,MAE)、均方根誤差(root mean squared absolute error,RMSE)指標(biāo)來評(píng)價(jià)模型的預(yù)測(cè)性能。
(1)
(2)
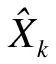
3.統(tǒng)計(jì)分析
采用SAS 9.2軟件建立SARIMA模型,采用python 3.7.1進(jìn)行單位根檢驗(yàn)、白噪聲檢驗(yàn)、自相關(guān)圖和偏自相關(guān)圖;采用Pycharm的keras軟件包實(shí)現(xiàn)LSTM模型。
結(jié) 果
1.流感樣病例時(shí)間分布
2013-2019年我國(guó)北方省份流感流行概況如圖4、5所示。可見流感樣病例每年呈增長(zhǎng)趨勢(shì),且每年的冬春交替時(shí)期是流感發(fā)病的高峰期。
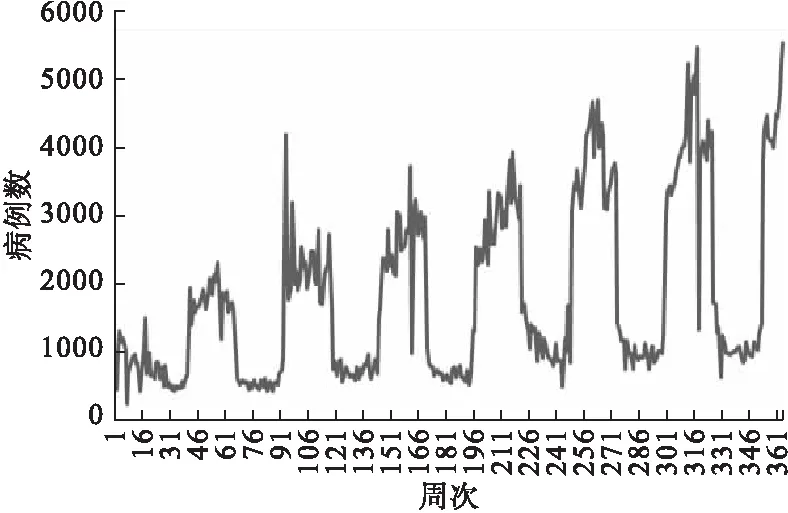
圖4 2013-2019年北方省份流感樣病例時(shí)序圖
2.SARIMA模型
由圖4、圖5可知該序列呈每年遞增的趨勢(shì)和明顯的季節(jié)性特征,原始序列為不平穩(wěn)序列(圖6)。將2013-2019年共364周數(shù)據(jù)的前4/5設(shè)置為訓(xùn)練集,后1/5設(shè)置為測(cè)試集。進(jìn)行1階差分及52步差分,差分后序列平穩(wěn)且不能視為白噪聲(表1),季節(jié)性周期為52周(即S=52),初步選定SARIMA(p,1,q)(P,1,Q)52模型。
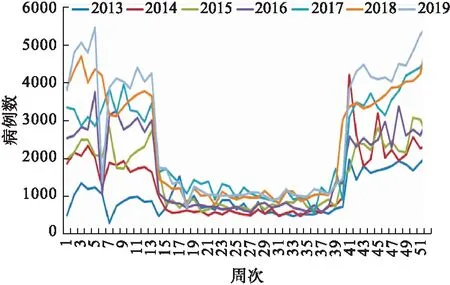
圖5 北方省份年度流感樣病例數(shù)
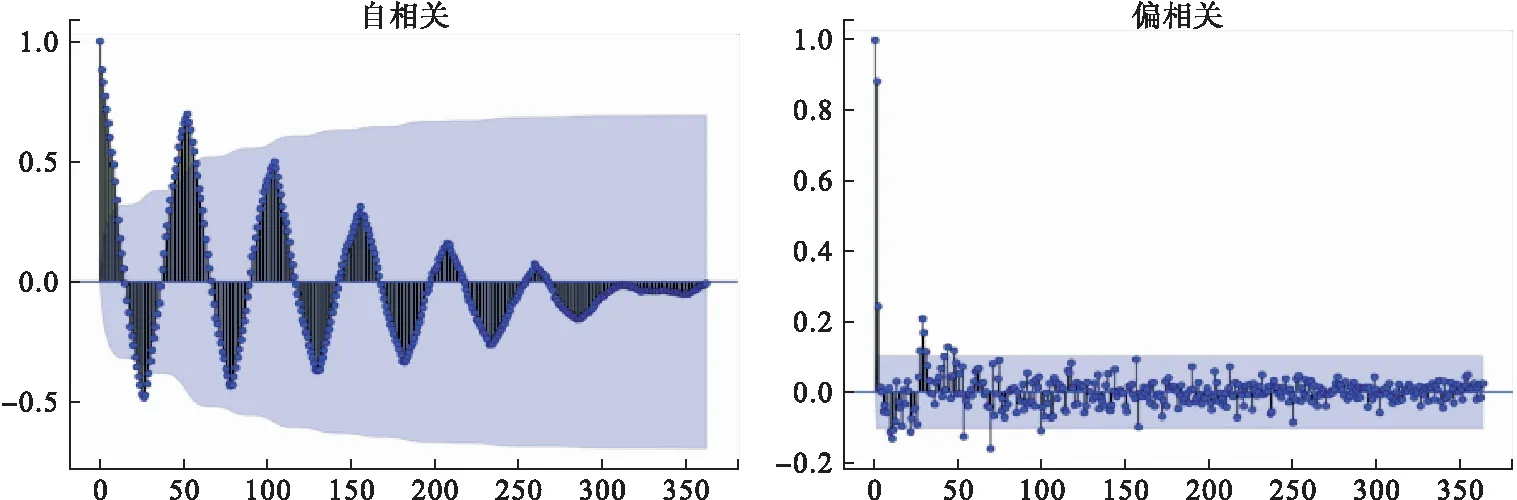
圖6 原始序列自相關(guān)與偏相關(guān)圖

表1 差分后序列平穩(wěn)性及白噪聲檢驗(yàn)
根據(jù)文獻(xiàn)顯示,參數(shù)超過2階的情況極為少見,且通過差分后序列的自相關(guān)和偏相關(guān)圖(圖7)確定可能的p、q、P和Q值,確定5個(gè)備選模型(表2),根據(jù)AIC,SBC最小原則選擇最優(yōu)模型,最終確定模型為SARIMA(0,1,1)(0,1,1)52。該模型的殘差白噪聲檢驗(yàn)結(jié)果為χ2=17.124,P=0.378,表明其殘差序列為白噪聲。

表2 備選模型參數(shù)估計(jì)及參數(shù)檢驗(yàn)
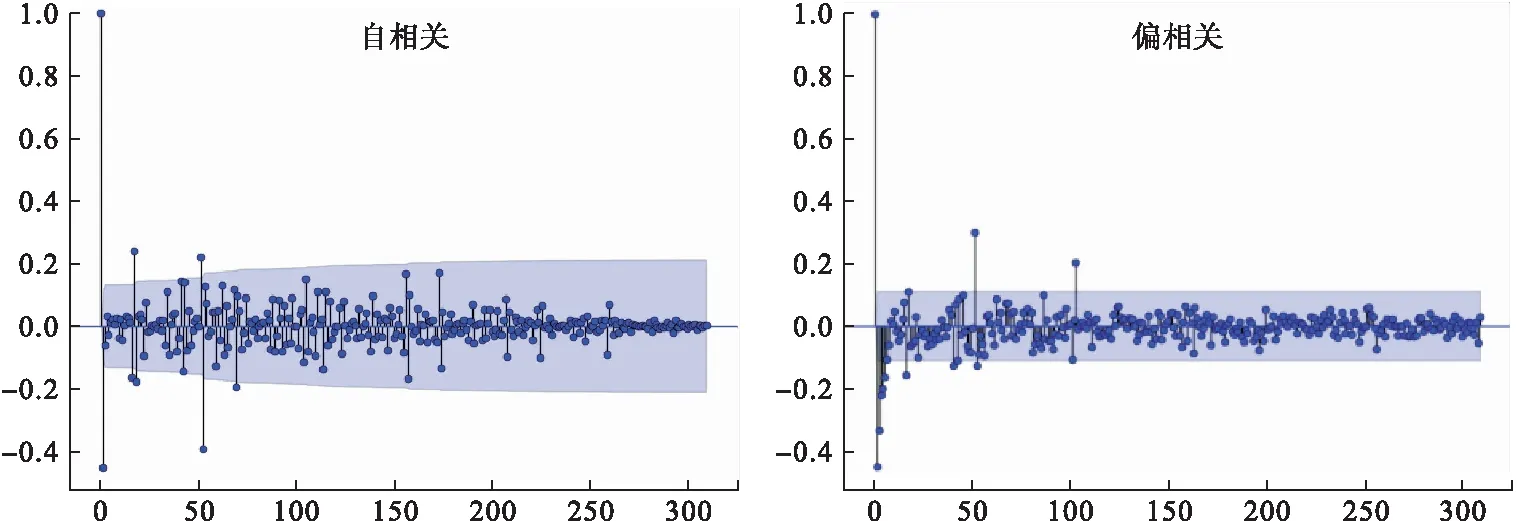
圖7 差分后序列自相關(guān)與偏相關(guān)圖
從QQ圖看出殘差服從正態(tài)分布,殘差序列為白噪聲,再次表明所構(gòu)建的模型是有效的。利用SARIMA(0,1,1)(0,1,1)52模型預(yù)測(cè)我國(guó)北方省份2019年1月-12月的流感樣病例數(shù),結(jié)果如圖9所示。
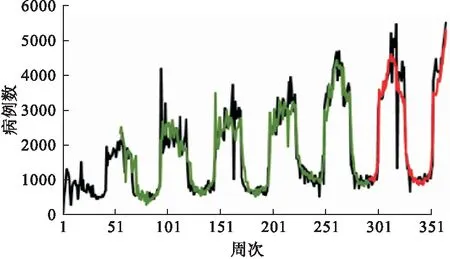
圖9 SARIMA(0,1,1)(0,1,1)52模型預(yù)測(cè)圖
3.基于keras平臺(tái)的LSTM模型
由于LSTM模型對(duì)時(shí)間序列無平穩(wěn)性要求,可以直接建立模型。同樣地將前4/5(291)的流感數(shù)據(jù)設(shè)置為訓(xùn)練集,后1/5(73)設(shè)置為測(cè)試集,建立LSTM模型。
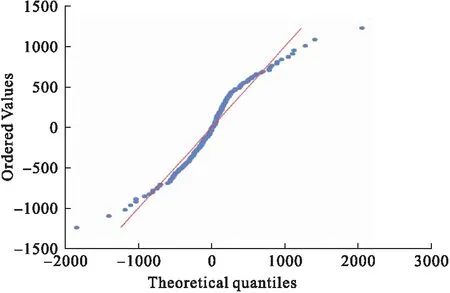
圖8 SARIMA模型殘差QQ圖
本文的隱藏層設(shè)置為單隱層,節(jié)點(diǎn)數(shù)設(shè)置為4,輸出層設(shè)置為1,采用Adam算法優(yōu)化參數(shù),其他為默認(rèn)參數(shù)。由于時(shí)間步長(zhǎng)會(huì)影響待預(yù)測(cè)樣本的長(zhǎng)度,原始數(shù)據(jù)經(jīng)歸一化及數(shù)據(jù)重構(gòu)后將其轉(zhuǎn)換為L(zhǎng)STM模型輸入要求的3D數(shù)據(jù)格式,經(jīng)數(shù)據(jù)轉(zhuǎn)化可知:其數(shù)據(jù)格式為(m-k,k,1),其中,m為原始時(shí)間序列的樣本數(shù),k為時(shí)間步長(zhǎng)。經(jīng)過數(shù)據(jù)重構(gòu),時(shí)間步為1的LSTM模型訓(xùn)練集和測(cè)試集樣本數(shù)為290和72,時(shí)間步為52的LSTM模型樣本數(shù)為239和21。不同時(shí)間步長(zhǎng)下的輸入數(shù)據(jù)格式如表3所示。

表3 不同時(shí)間步長(zhǎng)下的輸入數(shù)據(jù)格式
當(dāng)模型的時(shí)間步設(shè)置為1時(shí)(即將前1周數(shù)據(jù)作為輸入,后1周數(shù)據(jù)作為輸出),結(jié)果見圖10。從圖中可以看出,在數(shù)據(jù)不做差分等處理的前提下,LSTM模型抓住了數(shù)據(jù)線性增長(zhǎng)和波動(dòng)率逐漸增加的兩大趨勢(shì),這是經(jīng)典的時(shí)間序列分析模型不容易做到的;但由于原始數(shù)據(jù)存在周期性的結(jié)構(gòu)特點(diǎn),將時(shí)間步設(shè)置為52(即將前52周數(shù)據(jù)作為輸入,后1周數(shù)據(jù)作為輸出)進(jìn)行預(yù)測(cè),結(jié)果見圖11。并與時(shí)間步為1的模型進(jìn)行比較。
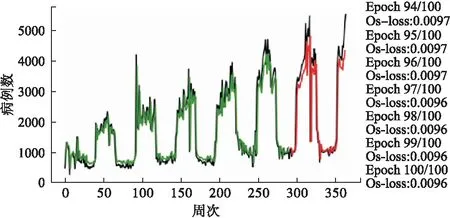
圖10 LSTM(1)模型預(yù)測(cè)圖及100次預(yù)測(cè)丟失率圖
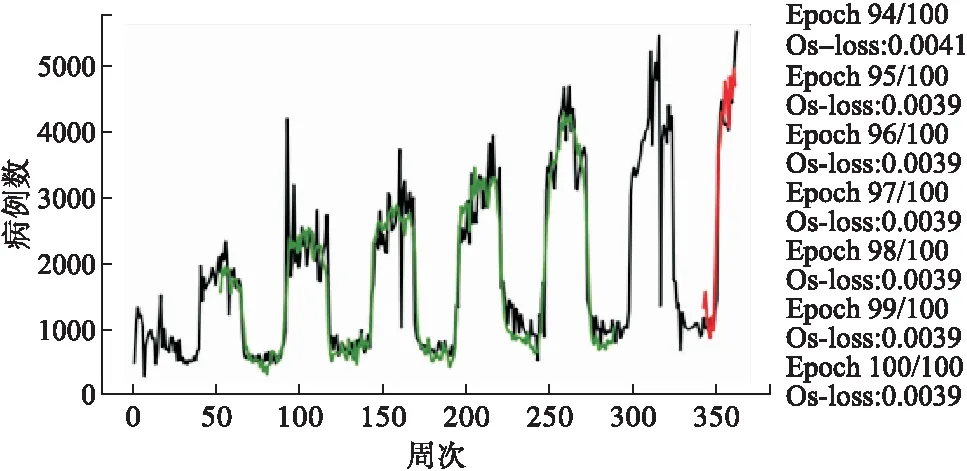
圖11 LSTM(52)模型預(yù)測(cè)圖及100次預(yù)測(cè)丟失率圖
時(shí)間步為1的LSTM模型預(yù)測(cè)丟失率穩(wěn)定在0.0096,高于時(shí)間步為52的LSTM模型預(yù)測(cè)丟失率穩(wěn)定在0.0039,其中,丟失率(loss)代表訓(xùn)練集樣本的預(yù)測(cè)值與真實(shí)值的差異程度,用于評(píng)價(jià)LSTM模型的訓(xùn)練效果。通過比較兩模型的丟失率,表明所構(gòu)建的時(shí)間步為52的LSTM模型較好。
4.模型對(duì)比分析
運(yùn)用SARIMA模型和LSTM模型對(duì)北方省份2019年1-12月流感樣病例數(shù)進(jìn)行預(yù)測(cè),結(jié)果顯示:SARIMA模型、LSTM(1)、LSTM(52)模型對(duì)于流感的預(yù)測(cè)趨勢(shì)與真實(shí)流感樣病例數(shù)趨勢(shì)基本一致,說明SARIMA、LSTM模型都能較好預(yù)測(cè)流感發(fā)病趨勢(shì)。SARIMA模型預(yù)測(cè)效果居中,其MAE、RMSE分別為352.74、521.07;LSTM(1)預(yù)測(cè)效果最差,其MAE、RMSE分別為448.79、784.09,較SARIMA模型分別增加96.05、263.02,預(yù)測(cè)性能分別降低了27.23%、50.50%;LSTM(52)預(yù)測(cè)效果最好,其MAE、RMSE分別為304.19、398.71,較SARIMA模型分別減少48.55、122.36,預(yù)測(cè)性能分別提高了13.76%、23.50%;表明對(duì)于具有周期性特征的時(shí)間序列而言,考慮周期特征的LSTM模型在流感預(yù)測(cè)性能最好(表4)。
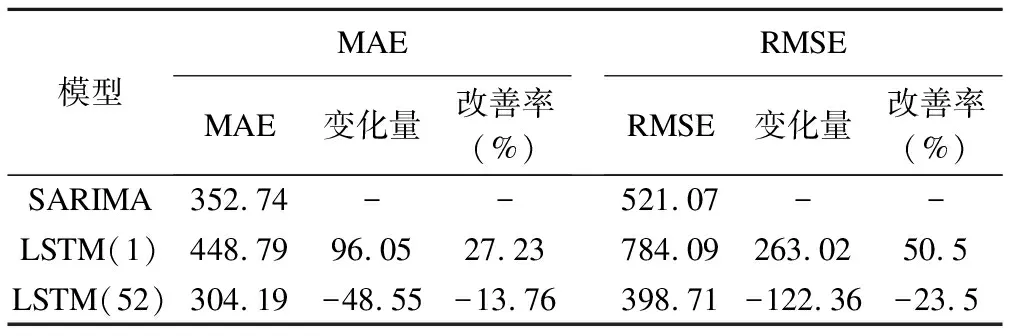
表4 三種模型預(yù)測(cè)性能對(duì)比
討 論
由于流感病毒極易發(fā)生變異,造成大流行[16],加重衛(wèi)生服務(wù)負(fù)擔(dān)。因此,及時(shí)了解流感流行趨勢(shì)、早期發(fā)現(xiàn)疫情是預(yù)防控制的關(guān)鍵。SARIMA模型著重分析流感樣病例數(shù)隨時(shí)間的變化規(guī)律,可以將其他未知的影響因素綜合于時(shí)間序列中,最終通過分析流感樣病例數(shù)之間的自相關(guān)性和依存關(guān)系來進(jìn)行預(yù)測(cè),SARIMA模型要求序列為平穩(wěn)的非白噪聲序列,對(duì)于非平穩(wěn)的時(shí)間序列,需要對(duì)序列進(jìn)行差分達(dá)到平穩(wěn)后進(jìn)行分析,而LSTM模型則可以直接對(duì)時(shí)間序列進(jìn)行訓(xùn)練并預(yù)測(cè),相比于傳統(tǒng)的統(tǒng)計(jì)學(xué)分析模型更具優(yōu)勢(shì)[17],因此本文建立SARIMA模型和LSTM模型,并根據(jù)時(shí)間周期性特征對(duì)LSTM模型進(jìn)行調(diào)參,采用MAE和RMSE兩個(gè)指標(biāo)來比較兩模型在預(yù)測(cè)流感樣病例數(shù)的準(zhǔn)確性。
結(jié)果顯示,3個(gè)模型對(duì)我國(guó)北方省份流感的預(yù)測(cè)趨勢(shì)與真實(shí)流感病例數(shù)趨勢(shì)基本一致,但相比較來說,LSTM(52),即考慮時(shí)間周期性,模型的預(yù)測(cè)效果最好,優(yōu)于SARIMA模型和LSTM(1)模型。可能是由于LSTM(1)模型只用前1周的流感發(fā)病人數(shù)預(yù)測(cè)下一周,沒有考慮流感發(fā)病的周期性,而LSTM(52)模型克服了平移錯(cuò)位的現(xiàn)象,提高了預(yù)測(cè)精度,這也與李琳等[8]利用LSTM模型分析新疆地區(qū)慢性阻塞性肺病的月門診量變化趨勢(shì)研究結(jié)果相一致。因此,與傳統(tǒng)的時(shí)間序列預(yù)測(cè)模型SARIMA相比,本文建立的基于keras平臺(tái)的LSTM模型可以對(duì)未來一段時(shí)間我國(guó)流感樣病例數(shù)進(jìn)行預(yù)測(cè),為流感有效防控及相關(guān)部門進(jìn)行資源優(yōu)化配置提供一定的參考。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
 中國(guó)衛(wèi)生統(tǒng)計(jì)2022年2期
中國(guó)衛(wèi)生統(tǒng)計(jì)2022年2期
- 中國(guó)衛(wèi)生統(tǒng)計(jì)的其它文章
- 單個(gè)發(fā)生率為0或1的meta分析及軟件實(shí)現(xiàn)
- 國(guó)內(nèi)高等醫(yī)學(xué)院校開展醫(yī)學(xué)科學(xué)研究設(shè)計(jì)課程現(xiàn)狀分析*
- 醫(yī)學(xué)統(tǒng)計(jì)學(xué)課程優(yōu)化及BOPPPS教改實(shí)踐初探*
- 多重填補(bǔ)技術(shù)在醫(yī)學(xué)研究缺失值處理中的應(yīng)用及發(fā)展*
- 重癥轉(zhuǎn)出患者家屬預(yù)防誤吸知信行現(xiàn)狀及影響因素分析
- 應(yīng)用累積比數(shù)回歸模型分析乳腺癌患者術(shù)后生活質(zhì)量影響因素*