滿足差分隱私的一種頻繁序列挖掘算法
2022-05-30 04:33:18李玉偉
計算機技術與發展 2022年5期
李玉偉,楊 庚,2
(1.南京郵電大學 計算機學院、軟件學院、網絡空間安全學院,江蘇 南京 210023;2.江蘇省大數據安全與智能處理重點實驗室,江蘇 南京 210023)
0 引 言
頻繁模式挖掘在數據處理方面具有重要意義,頻繁模式挖掘最早由Agrawal等人[1]提出,在他們的研究中,頻繁模式被定義為頻繁項集,其目的是在事務數據庫中挖掘出消費者的購買習慣,通過分析消費者已經購買的商品中不同物品之間的聯系,觀察者可以制定出更優的市場策略。頻繁模式挖掘算法目前在網絡信息安全、金融預測、地震監測和營銷策略等領域均得到了廣泛應用。頻繁模式算法的范圍隨著研究的不斷深入也已經從最初的頻繁項集挖掘,擴展至挖掘更復雜的模式,比如頻繁子圖挖掘[2]、頻繁序列挖掘[3]等等。
頻繁序列挖掘算法的目的就是在以序列形式儲存的數據集中挖掘出頻繁的序列事務。對于序列而言,某一序列中可以多次出現相同項,這是其與項集的差別。因此序列的長度就能突破字符種類上限的限制,序列的種類也會隨序列的大小增加呈指數級增長。序列模式和序列數據,如軌跡或DNA序列,在許多應用中被廣泛使用。例如,從主要道路收集的交通數據可用于確定出行最多的地區和預測交通擁堵。然而頻繁序列模式的內容和支持度的計數都會導致用戶信息的安全得不到保障[4]。為了解決該問題,Dwork等人[5]在2006年提出了差分隱私模型。該模型在挖掘過程和發布數據中對支持度添加擾動噪音,為數據隱私提供了強有力的、可證明的保障。差分隱私保護模型的隱私保護手段是可量化并且嚴格的,其隱私保護強度與入侵者持有的信息無關。由于該模型在挖掘過程中對數據進行噪音擾動,可以達到在原數據集中改變序列記錄并不會導致挖掘結果出現較大波動的目的。
目前已經有了一些具有差分隱私保護的序列挖掘算法,但這些挖掘算法大多是缺乏交互性的非漸進式的算法。在選擇了數據集和確定了最小閾值之后,用戶啟動算法(比如PrefixSpan算法),在算法停止之前,中間的過程中不會得到任何回應。這樣的延遲對于數據挖掘的生產力有很大的影響,因此將操作者對于挖掘信息的即時判斷處理加入到整體的挖掘過程中十分有必要。Sacha等人提出的Prosecco算法[6]就是一種漸進式的、滿足交互性的頻繁序列挖掘算法。但此算法同樣存在隱私泄露的問題。該文在Prosecco算法的基礎上,采用差分隱私保護技術對其進行安全性保障,設計了一種滿足差分隱私保護的序列挖掘算法ProSVT。主要貢獻如下:
(1)針對交互式、漸進式的序列挖掘算法添加差分隱私保護機制。ProSVT周期性地返回給用戶高度近似的頻繁序列結果。這種漸進式的過程體現在根據用戶定義的對數據集分塊(blocks)的基礎下逐漸分析挖掘的過程。
(2)運用并改善了添加噪音的機制,即雙層拉普拉斯噪音稀疏向量算法。稀疏向量法[7]是滿足差分隱私保護的一種添加拉普拉斯噪音的方法,該文將其運用于挖掘頻繁序列的算法中,并且在添加閾值噪音的位置做了改變,使添加噪音后算法挖掘結果更精確和穩定。
1 相關工作
在目前的隱私保護模型方法中,k-匿名模型[8]已經得到了廣泛的研究并應用于各領域,而后續研究表明,信息入侵者持有的信息量在很大程度上會影響模型的安全性,而且k-匿名模型的隱私保護水平并未得到有效且嚴格的證明。針對這些問題,Dwork提出的差分隱私保護模型(2006)可以抵擋各類對數據信息的攻擊,并且同時可以設定隱私參數來決定其隱私保護水平。Dwork證明了在背景知識存在的情況下,絕對隱私保護是不可能的,由此產生了基于不可區分性的差分隱私概念。差分隱私要求任何計算對單個記錄的更改不敏感,也就是說,針對任意一條記錄,數據庫包含或者不包含該條記錄不影響最后計算的結果。因此,這意味著掌握某條記錄的攻擊者不能根據對數據庫的操作得到關于該條記錄的任何有價值信息。實現該模型的噪音機制一般分為兩種情況,如果數據為非數值型采用指數機制,反之則采用拉普拉斯機制。
該領域的研究現狀在文獻[9]中已經得到了非常詳盡的介紹。滿足差分隱私保護的頻繁模式挖掘的研究,最早從頻繁項集挖掘相關算法開始。文獻[4]定義了一個新的效用概念top-k用來量化頻繁項集挖掘算法的輸出精度,即返回數據集中前k個最頻繁的項集作為輸出結果,該算法將模式長度大于lmax的事務截斷,然后添加Laplace噪音對支持度進行擾動以達到安全性,但當參數k和lmax較大時,算法不能保證其挖掘性能。文獻[10]提出的PrivBasis算法利用了一種稱為θ-基的新概念,θ-基集具有頻率大于θ的項集是某個基集的子集的性質,該算法采用的top-k頻繁項集挖掘可以看作是通過降維的方式來處理高維數據。文獻[11]中提出的DP-topkP算法通過后置處理噪音支持度的方式使結果滿足一致性約束,同時也增強了其可用性。由于較長的數據事務會使數據集的敏感度提高,文獻[12]提出了一種截斷長事務的方法,并且將截斷引發的錯誤與噪音引發的錯誤進行權衡,該top-k算法在k不是很小的情況下能獲得較好可用性的挖掘結果。和頻繁項集挖掘相比,頻繁序列挖掘存在高維和序列性的特點,因此這些算法尚不能應用于挖掘頻繁序列。
文獻[13]提出的基于混合粒度前綴樹結果算法首次實現了發布軌跡數據(頻繁序列挖掘)中的差分隱私保護。該算法在構建前綴樹的過程中使用Laplace噪音對數據進行擾動,使其發布的數據結果滿足差分隱私保護,但是算法存在前綴樹高度增長導致發布數據的效用大大降低的問題。文獻[14]采用變長n-gram來提取序列數據庫的基本信息,利用了前綴搜索樹結果和一組基于馬爾可夫假設的新技術來降低噪音量,使算法在挖掘的過程中滿足差分隱私保護。該算法在短序列為主的數據集下有較好的表現,當存在較多高維數據時挖掘結果的可用性得不到保證。PT-Sample算法[15]利用數據的統計特性來構造一個基于模型的前綴樹,用于挖掘前綴和子串模式的候選集,但是該算法并不適用于挖掘非字符類型的數據。文獻[16]提出的DPFSM算法,設計了一種打分函數來區分不同候選序列的優先權,然后通過閾值修正策略來減少截斷誤差與傳播錯誤,但尚未考慮到隱私預算的分配問題。以上算法都各自有其適用的方向并且都還存在一些問題,因此如何通過設計一種算法使頻繁序列挖掘的結果可用性與差分隱私保護的安全性達到較好的平衡是現在研究的重點和難點。
2 理論基礎
2.1 差分隱私
差分隱私是通過在挖掘過程中或者輸出結果中添加噪音對數據進行擾動來保證數據的安全性,使得在數據集中改變一條記錄(移除或者添加一條記錄)之后,任何查詢的輸出結果都不會改變。差分隱私的定義如下:
定義1:對于相鄰數據庫D1和D2(D1和D2之間只相差一條記錄),給定算法A,算法A可能輸出的結果集合為S,若算法A在數據庫D1中輸出S的概率與算法A在數據庫D2中輸出S的概率的比值小于常數值eε,稱算法A滿足ε-差分隱私保護, 即:
Pr[A(D1)∈S]≤eε×Pr[A(D2)∈S]
(1)
隱私預算參數ε可以衡量算法的隱私保護強度,ε值越小表示安全性(隱私強度)越高,但是同時也會使數據的可用性降低。
實現差分隱私保護主要依靠對數據的支持度添加噪音的機制,主要包括Laplace機制和指數機制,前者針對實數型數據,后者針對字符型數據。噪音量的大小取決于隱私參數和全局敏感度,隱私參數是用戶自己設定的,敏感度是數據集在算法下的屬性,函數的敏感度為數據庫中改變一條事務之后函數輸出結果的最大改變量,其數學的定義如下:
定義2:對于任意一個函數f,D→Rd,函數f的敏感度Δf定義為:
(2)
其中,f的查詢維度為d,R為f映射的實數空間。
該文的數據集為實數型數據,因此采用Laplace機制。為了使算法滿足差分隱私保護,Laplace機制在算法輸出結果中加入服從Laplace分布的隨機噪音。Laplace機制的定義如下:
定理1:對于敏感度為Δf的函數f,算法
A(D)=f(D)+Lap(λ)
(3)
滿足ε-差分隱私保護,其中Lap(λ)是服從λ=Δf/ε的Laplace分布,Laplace分布的概率密度函數為:
Pr[x|λ]=(1/2λ)e-|x|/λ
(4)
參數λ是根據隱私參數ε和函數敏感度Δf共同決定的。
由于處理的問題有時比較復雜,單個差分隱私保護算法不能解決問題,通常需要將用戶在算法中指定的隱私參數進行合理分配并采用多個滿足差分隱私保護的安全性算法。
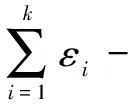
定理3(并行性質):假設A1,A2,…,Ak為k個滿足差分隱私保護的算法,其中,每個算法Ai依次滿足εi-差分隱私保護(1≤i≤k)。那么,當算法A1,A2,…,Ak分別作用于數據庫D1,D2,…,Dk(所有數據庫均不相交)時,這些算法構成的組合算法A滿足max{εi}-差分隱私保護。
由差分隱私保護算法的串行性質和并行性質可以推出如下結論:當存在多個滿足差分隱私保護的算法A1,A2,…,Ak,對于其構成的組合算法A的隱私預算總和,根據需要處理的數據庫彼此是否相交有不同的結果,前者為所有算法的隱私預算之和,后者為所有算法中隱私預算的最大值。
2.2 頻繁序列挖掘
多條序列記錄構成了頻繁序列挖掘的數據集,每一條用戶序列記錄都可能包含該用戶的涉及隱私安全的信息。在頻繁序列挖掘中,對于某一條序列,其在數據集中出現的次數被定義為該序列的支持度,支持度與數據集中所有序列記錄的數量的比值被定義為該序列的頻率。類似地,閾值也分別被定義為絕對閾值和相對閾值,對應于支持度和頻率。如果某一序列的支持度大于絕對閾值或者其頻率大于相對閾值,就可以將該序列加入所要輸出的頻繁序列集合之中。如果未經特殊說明,文章中的閾值一般指絕對閾值。
已知I={i1,i2,…,in}為序列數據集中項的集合(即字母表)。在頻繁序列挖掘中,字母表中任意項的一個非空集組合就構成了一條用戶序列,例如S=a1a2…a|s|表示長度為|S|的序列(a1,a2,…,a|s|∈I)。對于一條序列S,如果|S|=k,稱S為一個長度為k的序列(即一個k-序列)。頻繁序列挖掘的目的是要發現序列數據庫中的所有頻繁子序列,并且計算每個頻繁序列的支持度。
3 ProSVT算法
本節詳細描述所提出的用于挖掘頻繁序列的ProSVT(Prosecco-SVT)算法。
3.1 概 述
基于Prosecco算法,設計了一種具有隱私保護功能的序列挖掘算法,Prosecco算法首先將數據集分成數量為b的子集塊,b為用戶指定的參數。在挖掘過程中,當分析完第i個子集塊后,算法輸出一個滿足αi-近似的中間結果。中間結果在不斷更新,用戶可以根據當前結果的價值來決定是否繼續挖掘,因此整個挖掘過程中得到的數據具有交互性質。
一種挖掘頻繁序列的流算法采用了一種用戶相關的降低閾值(ξ<θ)的方法,并且在所有的子集塊中都使用相同的降低后的閾值,這種策略不足以保證中間結果的有效性,因為在某些塊中有的序列支持度低于ξ,于是就會被忽略,導致結果不準確,從而誤導用戶。Prosecco為了避免這種隱患,使用了塊相關的降低閾值的方法。這個過程是根據統計學中的相關定理確定了每個子集塊的特定參數,結合用戶先前設定的錯誤概率,共同決定誤差參數,即閾值下降的幅度。隨著挖掘過程的繼續,該幅度越來越小,最終收斂于0,閾值也收斂于標準閾值,算法輸出精確挖掘結果。
在挖掘頻繁序列的部分使用雙噪音(改善過的SVT)來為候選序列添加拉普拉斯噪音,即在序列支持度和閾值上同時添加噪音并控制噪音大小。此前的SVT法是在每個查詢序列上添加不同的隨機噪音,而在閾值上添加統一的一個噪音,這種做法存在弊端,如果閾值噪音過大就會導致整體比較結果,因此將統一的閾值噪音改為在每一次對查詢序列操作時在閾值上添加的不同隨機噪音,在比較噪音支持度和噪音閾值時,剔除未能達到噪音閾值的候選序列,反之就將其加入頻繁序列集合中。
3.2 算法描述
首先來詳細描述提出的ProSVT算法(如Algorithm1所示),其輸入參數有數據集D,子集塊數量b,閾值θ,錯誤概率δ,敏感度Δ,隱私預算ε,算法的輸出為最終的頻繁序列集合。
ProSVT算法將數據集D分割成β個子集塊B1,B2,…,Bβ,其中β=|D|/b,在同一時間只處理一個子集塊。根據統計學的Vapnik-Chervonenkis(VC) dimension及相關公式計算出的誤差參數α,然后由該誤差參數α得到降低后的閾值ξ,將參數ξ作為新的閾值進行頻繁序列挖掘,獲得第一個子集塊的輸出結果。接著依次對后面的子集塊進行操作,不斷更新輸出序列集,得到最終結果F并輸出。
Algorithm 1:ProSVT
Input:datasetD,block sizeb,minimum frequency thresholdθ,failure probabilityδ,sensitivity Δ,privacy budgetε
Output:a setF
1β←|D|/b
3ξ←θ-α/2
4Q←pretreatment(B1)
5F←doubleNoise-getFS(B1,Q,Δ,ξ,ε)
6 returnIntermeiateResult (F,α)
7 for eachi←2,…,β-1 do
9ξ←θ-α/2
10Q←pretreatment(Bi)
11F←upadteRunningSet (F,doubleNoise-getFS(Bi,Q,Δ,ξ,ε))
12 returnIntermediateResult(F,α)
13F←upadteRunningSet(F,Bβ,ξ)
14 returnF
Algorithm2是改善過后的SVT法,即doubleNoise-getFS算法。該算法的輸入為子集塊B,查詢隊列Q,敏感度Δ,下調閾值ξ,隱私參數ε,輸出為查詢結果。
doubleNoise-getFS算法中,先將給定的隱私參數ε分為ε1(分配給支持度的隱私預算)和ε2(分配給支持度的隱私預算),然后分別計算出支持度噪音和閾值噪音,接著對于查詢隊列Q中每個查詢序列的支持度和閾值添加噪音,保留噪音支持度大于噪音閾值的序列,并將其加入挖掘算法的中間結果。
Algorithm 2:doubleNoise-getFS
Input:subsetB,query queueQ,sensitivity Δ,lower frequencyξ,privacy budgetε
Output:query answera1,a2,…,a setF
1ε1=ε2=ε/2
3 for each queryqi∈Qdo
4 ifqi(B)+ρ1≥ξ+ρ2then
5 Outputai=qi(B) andF.add(ai), count+1
6 else
7 Outputai=⊥
3.3 隱私性證明
定理4:ProSVT算法滿足ε1+ε2-差分隱私。
證明:由于在ProSVT整體算法中,doubleNoise-getFS算法中加入了支持度噪音和閾值噪音,因此需要證明加噪過程滿足差分隱私保護。對于任意的輸出a={丅,丄}l,只要證得:
(5)
首先考慮第一種情況:

fi(B,z)=Pr[qi(B)+ρ2<ξ+z]≤
Pr[qi(B')+ρ2<ξ+z]=
fi(B',z)
(6)
gi(B,z)=Pr[qi(B)+ρ2≥ξ+z]≤
Pr[qi(B')+ρ2+Δ≥ξ+z]≤
eε2Pr[qi(B')+ρ2≥ξ+z]=
eε2gi(B',z)
(7)
又因為|I┬|≤c,所以,

eε2Pr[A(B')=a]<
eε1+ε2Pr[A(B')=a]
(8)
然后考慮第二種情況:
?iqi(B)≤qi(B'),記qi(B)≥qi(B')-Δ,所以有:
fi(B,z-Δ)=Pr[qi(B)+ρ2<ξ+z-Δ]≤
Pr[qi(B')-Δ+ρ2<ξ+z-Δ]=
fi(B',z)
(9)
考慮到約束條件qi(B)≤qi(B'),所以有:
gi(B,z-Δ)=Pr[qi(B)+ρ2≥ξ+z-Δ]≤
Pr[qi(B')+ρ2≥ξ+z-Δ]≤
eε2Pr[qi(B')+ρ2≥ξ+z]=
eε2gi(B',z)
(10)
再將積分變量z轉換為z-Δ,可得:


eε1+ε2Pr[A(B')=a]
(11)
因此,該算法滿足ε1+ε2-差分隱私。
4 實驗及分析
本節對提出的ProSVT算法進行實驗仿真,并從精確率、召回率和F-score等方面對ProSVT算法進行性能分析。
4.1 實驗設置
實驗環境為Intel? CoreTMi7-9750H CPU@2.60 GHz,16 GB內存,Windows10 64位操作系統,實驗用Java語言實現具體的ProSVT算法。
4.1.1 數據集
實驗基于兩個公開可獲得的真實序列數據集(見表1)。
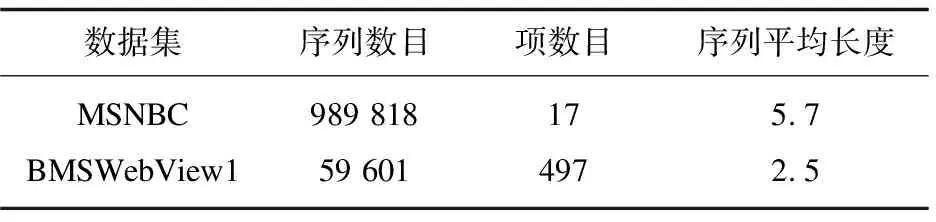
表1 真實數據集參數
MSNBC數據集為1999年9月28日msnbc.com網站按照時間順序記錄下的用戶訪問,數據集中的每個序列對應于該用戶在24小時內的頁面瀏覽點擊,該數據集共有989 818條序列記錄,點擊項為17項,對應了17個頁面類別,序列平均長度為5.7。BMSWebView1數據集用于KDD CUP 2000,它包含來自電子商務的clickstream數據,序列量為59 601,共包含497個不同的項,序列平均長度為2.5。
4.1.2 測試對象
測試主要集中在三個算法:(a)ProSVT:此算法是該文提出的差分隱私保護下的頻繁序列挖掘算法;(b)Prefix:這是文獻[13]中提出的一種構造前綴樹挖掘頻繁序列的差分隱私保護算法;(c)N-gram:此算法是利用可變長度的n-gram模型來挖掘頻繁序列的差分隱私保護算法[14]。
4.1.3 指 標
在實驗中測試的衡量標準為Precision、Recall和F-score。其中Precision為挖掘的精確率,Recall為挖掘的召回率,F-score為兩者的綜合評價指標。設Up是由具有隱私保護的算法挖掘得到的頻繁項集,Uc是真實的頻繁項集,具體定義如下:
(12)
4.2 實驗結果
本節首先針對最低閾值θ和隱私預算ε對ProSVT算法進行測試,然后將ProSVT與Prefix、N-gram進行對比,并分析實驗得出的結果。由于敏感度和序列長度成正比,因此在本實驗中用平均序列長度來表征敏感度。
4.2.1 不同閾值
這里測試了ProSVT算法在隱私預算固定時,改變閾值對其挖掘性能造成的影響。圖1和圖2分別是在MSNBC和BMSWebView1數據集下的測試結果。實驗結果表明,隨著閾值的提升,挖掘結果的精確率、召回率都有明顯的增加,從而使F-score也得到提升。因為閾值提高后,算法挖掘的候選頻繁序列數目減少,出現誤差的可能減少,由此提高了挖掘性能。用戶在挖掘頻繁序列時,不宜將閾值設置得過低,否則會大大降低挖掘結果的可用性。

圖1 MSNBC:不同θ下的挖掘性能

圖2 BMSWebView1:不同θ下的挖掘性能
4.2.2 不同隱私預算
這里測試了ProSVT算法在最低閾值固定時,改變隱私預算對其挖掘性能造成的影響。圖3和圖4分別是在MSNBC和BMSWebView1數據集下的測試結果。可以看出隨著隱私預算的提升,挖掘結果的精確率、召回率都有明顯的增加,從而使F-score也得到提升。當隱私預算增加時,所添加的拉普拉斯噪音隨之降低,因此理論上會使挖掘結果更加精確。
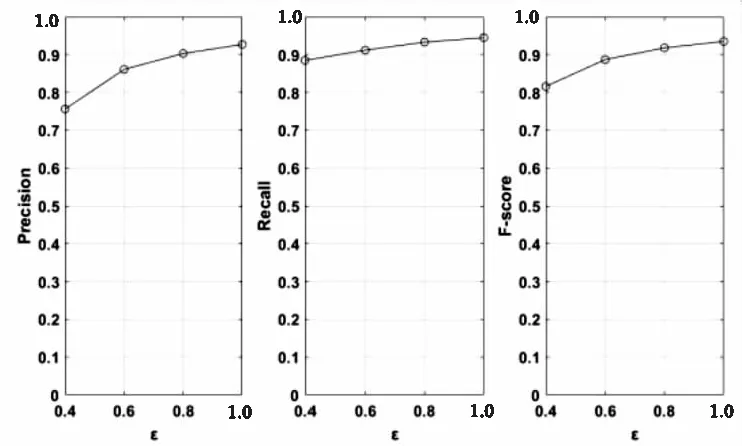
圖3 MSNBC:不同ε下的挖掘性能
4.2.3 ProSVT與其他算法
這里測試當固定閾值,改變隱私預算時在兩個數據集中ProSVT、Prefix以及N-gram算法的F-socre指標變化,如圖5和圖6所示。對于MSNBC數據集,ProSVT在低隱私預算時表現較差,當隱私預算大于0.4后,其挖掘性能較Prefix和N-gram更優秀;對于BMSWebView1數據集,ProSVT在各種大小的隱私預算情況下的挖掘性能表現都要優于Prefix和N-gram。

圖5 MSNBC:三種算法的挖掘性能對比

圖6 BMSWebView1:三種算法的挖掘性能對比
5 結束語
提出了一種滿足差分隱私保護的頻繁序列挖掘算法ProSVT。此算法是在Prosecco算法的基礎上加入了改善過后的雙拉普拉斯噪音方法以保證挖掘期間的差分隱私機制,以其漸進式、交互性的特點給挖掘者更便捷、有效的挖掘頻繁序列的體驗。在真實數據集下的相關實驗表明了最低閾值和隱私預算的分配對于挖掘性能的影響,在和其他算法對比的過程中,ProSVT也有比較出色的表現。在隱私預算的分配中,對于支持度噪音和閾值噪音的隱私預算分配采用均分的方法,進一步的研究中可以針對隱私預算分配方法作深入的探討。
