基于seq2seq模型的標簽推薦方法
2022-05-30 11:49:10郜山權劉宣彤
吉林大學學報(理學版) 2022年2期
劉 磊, 王 昊, 孫 凱, 郜山權, 劉宣彤
(1. 吉林大學 計算機科學與技術學院, 長春 130012; 2. 外交學院 英語系, 北京 100037)
Node包管理器NPM是node.js默認的, 用JavaScript編寫的軟件包管理系統. 開源開發人員可基于NPM平臺共享或者借用軟件包. 為幫助開發人員更高效地搜索到所需的軟件包, NPM提供了一種標簽搜索機制, 根據具體的標簽推薦相關的軟件包. 因此, NPM平臺通常要求開發人員在發布或更新軟件包時為其分配標簽. 目前, 主流的標簽推薦方法都是利用物體的文本特征實現標簽推薦[1-2], 如EncTagRec++[3]和FastTagRec[4]等. 這些文本特征主要包括Readme文檔或描述文本. 但在NPM軟件包的標簽推薦場景下, 包的Readme文檔主要用于介紹包的使用說明和安裝說明等, 這種類型的文本信息對標簽推薦的作用較小, 且包的描述信息過短, 表達的信息不充足. 本文統計了58 753個軟件包的描述信息, 統計結果表明, 76.7%的包描述文本不超過10個單詞. 因此, 這些傳統的利用Readme文檔或描述文本的標簽方法在NPM軟件包標簽推薦場景下性能較差. 為解決傳統方法在NPM軟件包標簽推薦場景下的局限性, 本文從包的代碼角度出發推薦標簽. 與Readme文本以及描述文本相比, 包的代碼信息能更直觀和具體地描述包的行為. 此外, 文獻[5]對比了傳統標簽推薦方法和深度學習標簽推薦方法在相同標簽工作下的性能, 實驗結果表明, 選擇合適的深度學習方法可能會獲得更有效的結果. 因此, 本文從包的代碼角度出發, 利用深度學習模型為NPM軟件包推薦標簽. 首先, 通過程序分析技術構建出NPM軟件包的函數調用圖, 利用圖遍歷算法遍歷該函數調用圖, 從而將軟件包轉化為一組具有語義信息的函數調用序列; 其次, 利用seq2seq模型將函數體字符序列映射為函數名稱序列[6], 通過訓練seq2seq模型將包含語義信息的軟件包函數調用序列映射到軟件包的標簽序列上, 從而完成標簽的推薦工作.
1 研究方法
本文采用加入了注意力機制[1]的seq2seq模型完成NPM軟件包的標簽推薦工作. Seq2seq模型[2]是一種將輸入序列映射到輸出序列的深度學習模型, 廣泛應用于機器翻譯領域[7-8]. 該模型通常會引入注意力機制提高模型性能. 在本文提出的標簽推薦方法中, 首先利用ECMAScript開發工具解析NPM軟件包的源代碼, 構建出軟件包的函數調用圖, 通過圖的深度優先遍歷得到一組能反映軟件包功能語義信息的函數調用關系序列, 并用該序列作為seq2seq模型的輸入; 其次, 再訓練seq2seq模型, 該模型以軟件包的標簽序列作為輸出. 模型訓練結束后, 對于一個新的軟件包, 訓練好的seq2seq模型會將該包的函數調用序列映射到一組預測的標簽序列上, 預測序列中的標簽將會作為推薦標簽推薦給該軟件包. 圖1為本文方法的整體流程.
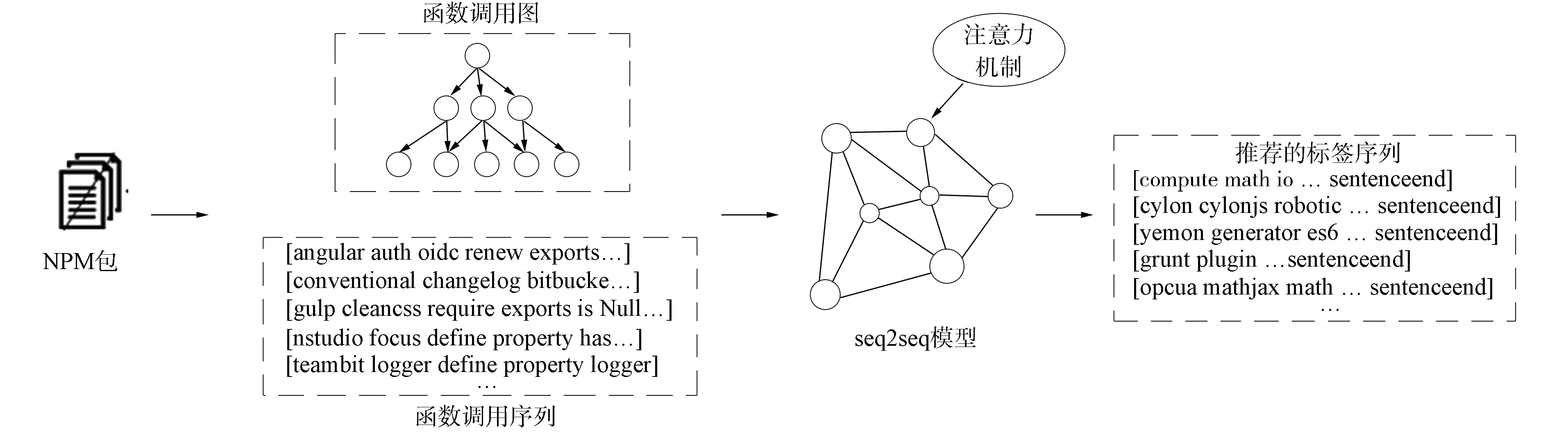
圖1 本文方法流程Fig.1 Flow chart of proposed method
1.1 數據處理
數據處理部分為標簽推薦模型準備訓練數據, 該部分主要完成以下兩項任務: 1) 將NPM軟件包表示成函數調用序列的形式; 2) 抽取軟件包的標簽序列信息. 對于任意一個NPM軟件包p, 經過數據處理后都會對應一組序列對(s,t):p→(s,t), 其中s是p對應的函數調用關系序列,t表示p擁有的標簽序列.
1.1.1 函數調用序列
為將NPM軟件包表示成序列的形式, 本文選擇構建包的函數調用圖, 遍歷該調用圖, 從而得到包的函數調用序列, 并用該序列作為包的表示. 由于函數調用圖能反映包的函數調用關系, 具有軟件包功能相關的語義信息, 因此用函數調用序列表示一個NPM軟件包合理.
在構建函數調用圖的過程中, 利用程序靜態分析技術解析NPM軟件包的源代碼, 這些代碼是基于JavaScript(JS)語言實現的. ECMAScript開發工具可以幫助解析JS代碼, 其中Esprima為JS代碼生成對應的抽象語法樹, Estravese用于遍歷語法樹并定位到函數相關的節點抽取出函數名稱. 由于一個NPM包由多個文件模塊組成, Madge工具用于幫助分析模塊之間的依賴關系決定模塊分析的順序, 因此在整個分析過程中, 利用information-matching的方法構建NPM軟件包的函數調用圖. 最后通過圖的深度優先遍歷, NPM軟件包最終被表示成函數調用序列的形式.
利用Estraverse工具遍歷抽象語法樹時, 首先需定位語法樹中函數相關的節點才能抽取對應的函數名稱. 函數相關的節點主要是函數聲明和函數調用, 而在JS語言中函數聲明和函數調用的格式有很多種, 其在語法樹中的表現形式也不同. 因此, 為能準確定位到函數相關節點抽取出的函數名稱, 本文參考了JS函數的基礎語法和Esprima官方文檔, 針對不同語法格式的函數聲明和函數調用制定相應的抽取規則定位語法樹中函數相關的節點, 從而抽取出函數名稱及相對應的文件模塊信息.
1.1.2 包標簽序列
軟件包標簽序列的獲取相對容易, CommonJS規范規定NPM軟件包的根目錄下必須默認存在一個配置文件package.json, 該配置文件包含了軟件包的基本信息, 其中包括標簽信息. 因此, 只需要找到根目錄下的配置文件, 分析配置文件的keywords屬性即可獲取軟件包的標簽序列.
1.2 模型構建
收集NPM軟件包對應的序列對信息后, 標簽推薦模型的輸入和輸出可以確定. 訓練時, 模型以軟件包的函數調用序列作為輸入, 軟件包的標簽序列作為輸出. 訓練完成后, 對于一個新的軟件包的函數調用序列, 模型可以預測一組標簽序列, 將該標簽序列作為軟件包的推薦標簽. 本文方法使用seq2seq模型進行標簽推薦, 該模型基于編碼器和解碼器構建, 編碼器和解碼器均為循環神經網絡、 長短期神經網絡(LSTM)或門控循環單元(GRU). 本文選擇計算能力消耗相對少的GRU循環神經網絡. 為優化模型性能, 在seq2seq模型中加入了注意力機制. 注意力機制的優勢在于該機制能為模型解碼器端計算動態的注意力向量進行標簽預測, 這種注意力向量能極大地保留輸入序列的信息, 從而使模型的推薦結果更準確合理. 而不采用注意力機制的seq2seq模型只能基于一個固定的上下文向量進行標簽預測. 這種沒有注意力機制的模型通常存在兩個局限性: 1) 當輸入序列過長時, 固定的上下文向量很難包含整個序列的信息, 而是偏向于表達序列末尾的信息; 2) 使用固定的上下文向量無法幫助模型明確輸入序列和輸出序列之間的對應關系, 使輸入序列中的所有詞匯對預測結果的貢獻相同. 這兩種局限性都會影響模型的預測結果, 因此本文引入注意力機制優化標簽推薦模型. 圖2為標簽推薦模型的基本結構.
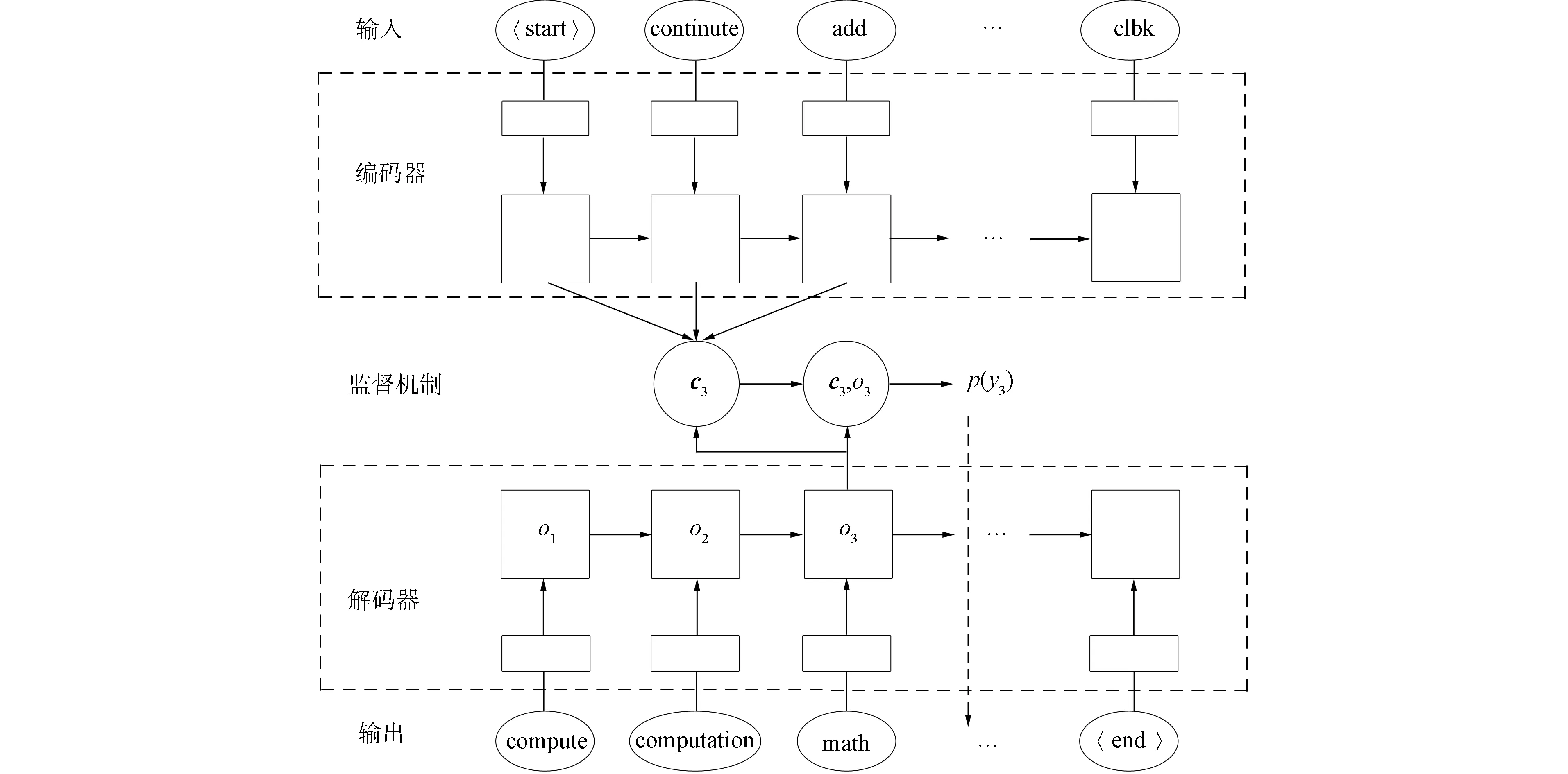
圖2 標簽推薦模型結構Fig.2 Architecture of tag recommendation model
對于一個包p的函數調用序列s, 編碼器首先通過嵌入層將s轉換成向量的表示形式, 編碼器端的循環神經網絡利用該向量計算出不同時期的隱藏狀態h.解碼器端在預測標簽時, 會根據已預測的標簽以及注意力向量計算當前預測標簽yi的概率p,p的計算公式為
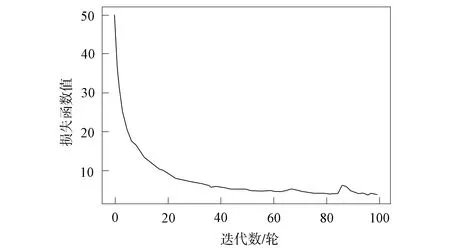
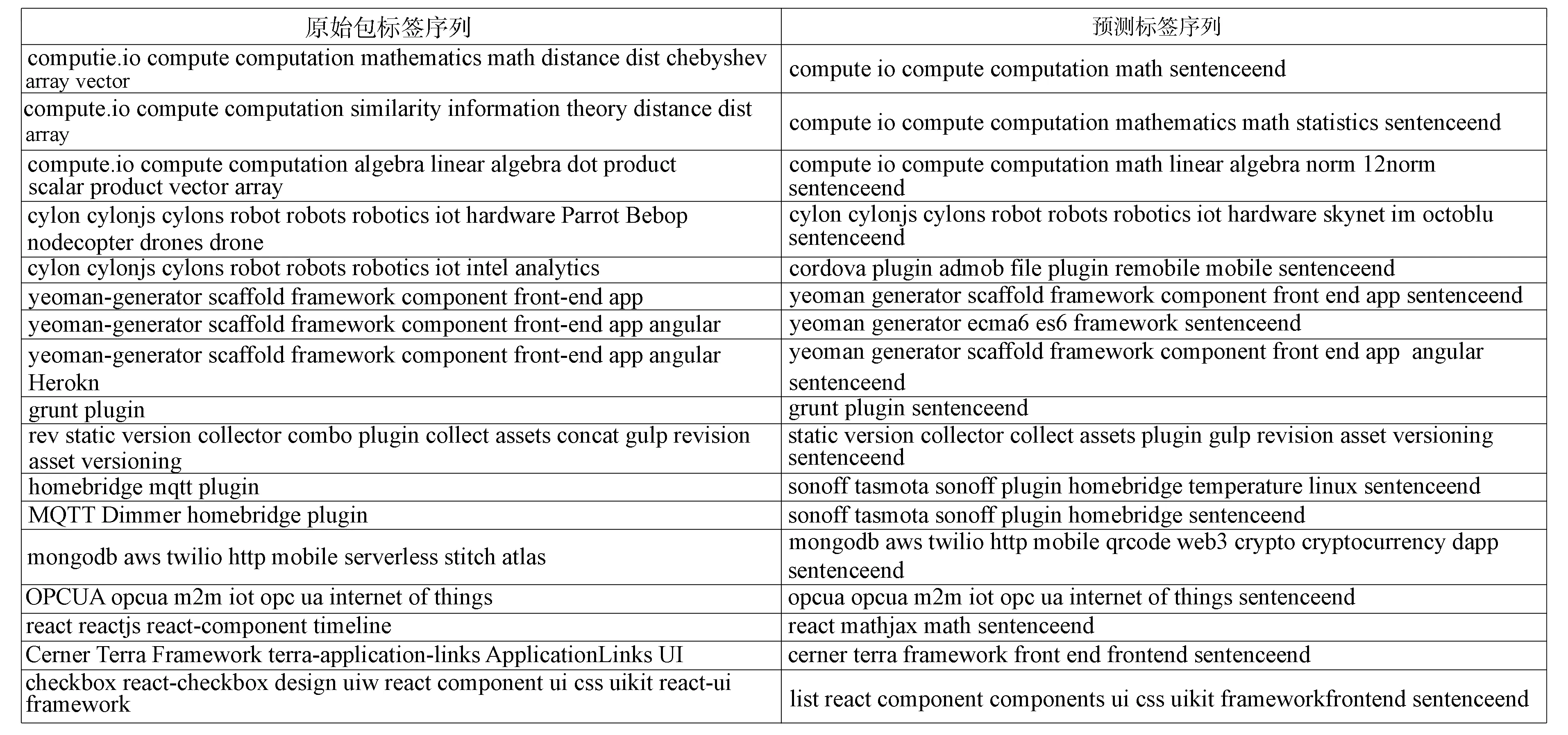
p(yi|y 其中:x為輸入序列的向量表示;y為已預測標簽的向量表示;oi為當前解碼器的狀態;ci為當前狀態下的注意力向量, 注意力向量ci是由注意力函數根據隱藏狀態hi和解碼器狀態oi計算得到的.在Softmax計算結果中最大概率值對應的標簽為當前模型的預測標簽yi. 在數據收集過程中, 首先通過爬蟲程序在NPM平臺上收集到3 833個NPM軟件包的基本信息, 利用命令行安裝指令將這3 833個包安裝到本地計算機. 經過數據處理后, 最終得到3 833條有效的函數調用序列信息和標簽序列信息對, 這些序列對將用于標簽推薦模型的訓練和測試. 本文按照傳統的二八劃分將數據集劃分為不相交訓練集和測試集. 圖3 損失函數曲線Fig.3 Loss function curve 為使模型表現更優, 收斂更快, 本文結合已有的實現方法設置seq2seq模型的參數: 學習率為0.006, 嵌入層維度為64, 隱藏層神經元為1 024, 最大序列長度為100, 損失函數采用稀疏分類交叉熵. 常用的注意力機制主要有additive機制和dot-production機制兩種, 本文采用后者. 圖3為訓練過程中損失函數值的變化曲線. 由圖3可見, 在迭代到約40輪時模型已經趨于收斂了, 整個100輪迭代過程約需耗時70 min. 參考文獻[9], 本文定義兩種指標R1和R2評估模型.對于指標R1, 只要預測標簽序列與原始標簽序列之間交集不為空, 即模型至少預測對一個標簽即認為預測結果有效, 統計有效結果在測試集中的比例, 該比例作為R1指標下的準確率.其公式定義為 其中:Tp為測試集合;TSO函數返回包p原始標簽序列;TSP函數返回包p預測標簽序列; 函數J判斷序列是否有交集, 有交集則返回1, 反之返回0.本文模型在R1評價指標下的準確率為82.6%. 對于指標R2, 只有當預測序列和原始標簽序列重合, 即只有當模型預測對所有的標簽才能認定當前預測結果有效, 統計有效結果在測試集中的比例, 該比例作為R2指標下的準確率.其公式定義為 其中: 函數F判斷序列是否重合, 重合則返回1, 反之返回0; 其他參數含義與R1相同.本文模型在R2評價指標下的準確率為33.7%.由于R2指標要求模型完全預測標簽, 所以該準確率也合理. 圖4為部分軟件包原始標簽序列與預測標簽序列的對比結果. 由圖4可見, 本文模型的確能為軟件包推薦合理的標簽, 驗證了本文方法的有效性. 盡管本文方法能為NPM軟件包推薦合理的標簽, 但由實驗結果可見, 這種推薦方法存在一定的缺陷, 如在預測標簽序列中會出現重復的標簽, 這與實際情況不符. 出現這種情況的原因是模型在預測當前標簽時只計算了輸出序列中每個標簽的概率值, 輸出最大概率值對應的標簽, 而未考慮該標簽是否已經出現在輸出序列中了. 圖4 原始標簽序列與預測標簽序列對比結果Fig.4 Comparison results of original tag sequences and predicted tag sequences 綜上所述, 針對NPM平臺上存在大量的軟件包沒有標簽或標記不完善的問題, 本文提出了一種基于seq2seq模型的標簽推薦方法. 該方法從NPM軟件包的源代碼出發, 利用靜態程序分析技術構建出軟件包的函數調用圖, 通過圖遍歷算法將其轉換成一組語義信息的函數調用序列. 訓練好的seq2seq模型將軟件包的函數調用序列映射到一組預測的標簽序列上, 從而完成軟件包的標簽推薦工作. 實驗結果表明, 本文方法能為NPM軟件包推薦合理的標簽, 準確率可達82.6%.2 實驗驗證
2.1 數據收集
2.2 模型訓練
2.3 評價指標與實驗結果
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
