融合雙流殘差網絡和注意力機制的群體行為識別方法
2022-05-30 10:48:04黃少年全琪賀子琴胡俊杰
電腦知識與技術 2022年30期
黃少年 全琪 賀子琴 胡俊杰

摘要:文章為實現復雜場景下群體行為的自動分析與識別,方便城市安全管理,建立融合雙流3D殘差網絡和時空注意力機制的群體行為識別模型。首先,提取群體場景的靜態可視特征及動態光流特征作為模型輸入,構建融合時空注意力的雙流3D殘差網絡提取群體場景的深度特征,通過對深度可視特征及運動特征的多次融合實現群體行為識別。然后,基于真實群體視頻數據集CUHK開展實驗,驗證模型的合理性,并對比分析該模型與多種已有模型的行為識別結果。結果表明: 融合雙流3D殘差網絡和時空注意力機制的群體行為識別模型具有可靠的群體行為識別能力,與其他深度神經網絡模型相比,該模型具有更高的準確率和更優的混淆矩陣。
關鍵詞:群體行為識別;殘差神經網絡;注意力機制
中圖分類號:TP18? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)30-0001-03
開放科學(資源服務)標識碼(OSID):
隨著我國城市化進程的快速發展,群體聚集的情況頻繁在各種公共場所中出現。群體高度聚集的公共場所很可能出現因群體擁擠引發的踩踏事件。因此,自動分析、識別群體行為,理解復雜環境下的群體運動動態,對于避免群體災難性事件發生、提高城市公共安全管理能力具有重要意義。
隨著深度學習模型在圖像分類、視頻分析等領域的成功應用,其在群體場景深度特征表示方面也取得了顯著進步。Shao等[1]首次基于VGG-16深度網絡結構構造時空切片卷積神經網絡,提取群體場景在時間維度和空間維度上的深度特征表示。鑒于視頻序列中存在大量的時空信息,Simonyan等[2]首次提出雙流卷積神經網絡完成人體行為識別。袁亞軍等[3]采用CNN模型學習群體靜態行為特征及動態行為特征,并綜合兩種深度特征完成行為分析。以上研究表明,雙流深度神經網絡能有效提取群體場景的時空深度特征表示,但上述研究中針對群體行為識別的模型較少,且識別準確率有待進一步提高。因此,為進一步增強深度神經網絡對復雜群體場景的特征表示能力,提高群體行為識別的準確率,筆者擬構建融合雙流3D殘差網絡和時空注意力機制的群體行為識別模型,實現群體行為識別,以期為城市公共安全群體管理提供新的途徑。
1 模型架構
筆者提出了一種融合雙流3D殘差網絡和時空注意力機制的群體行為識別模型,模型主要包括數據預處理、深度特征提取、特征融合及群體行為識別四個模塊。
1.1 數據預處理
數據預處理包括空間域預處理和時間域預處理兩部分。空間域預處理指從群體視頻流中提取連續圖像序列作為空間域殘差網絡的輸入。為減少時間消耗和計算復雜度,從每個群體視頻的隨機位置提取的連續32幀圖像,并將其裁剪為[224×224]的幀序列。時間域預處理則指從圖像序列中提取對應的連續光流序列作為時間域殘差網絡的輸入。光流是研究圖像動態特征的常用方法,采用TV-L1(Total Variation-L1 Optical Flow)[4]光流估計模型提取群體序列的光流圖,該算法適合相鄰圖像幀間位移變化較小的運動特征提取。
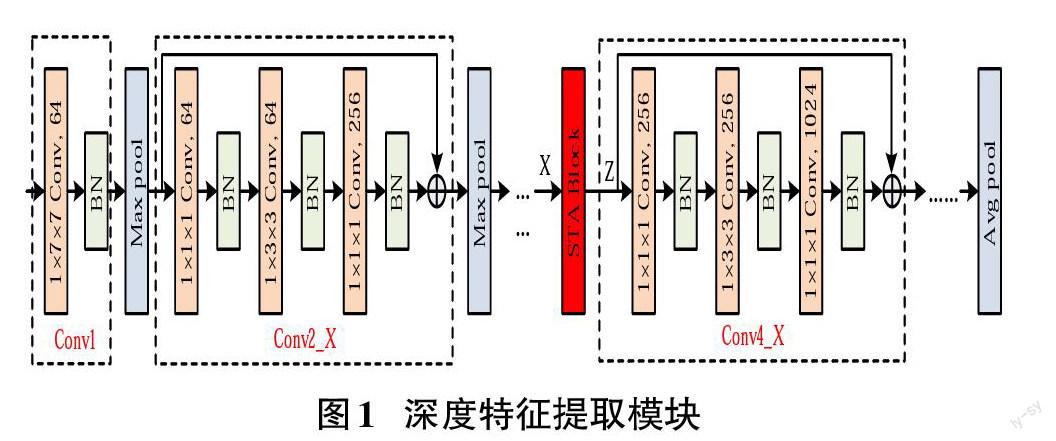
1.2 深度特征提取模塊
傳統殘差網絡采用2D卷積提取深度特征,鑒于3D卷積在時空特征提取上的優越性,構建基于時空注意力機制的3D殘差網絡提取群體視頻的深度特征表示。該模塊基于殘差網絡ResNet50進行設計,其原理圖如圖1所示。對于輸入的RGB圖像序列和光流圖序列,首先用卷積核為1×7×7的卷積層提取淺層特征,然后依次經過Conv2_x、Conv3_x、Conv4_x 以及Conv5_x四個殘差塊,每個殘差塊均包含一個1×3×3和兩個1×1×1大小的卷積核。為避免隨著網絡深度增加而帶來的梯度消失問題,在每一個三維卷積層后增加BN層進行批量歸一化,以加快訓練網絡收斂的速度。
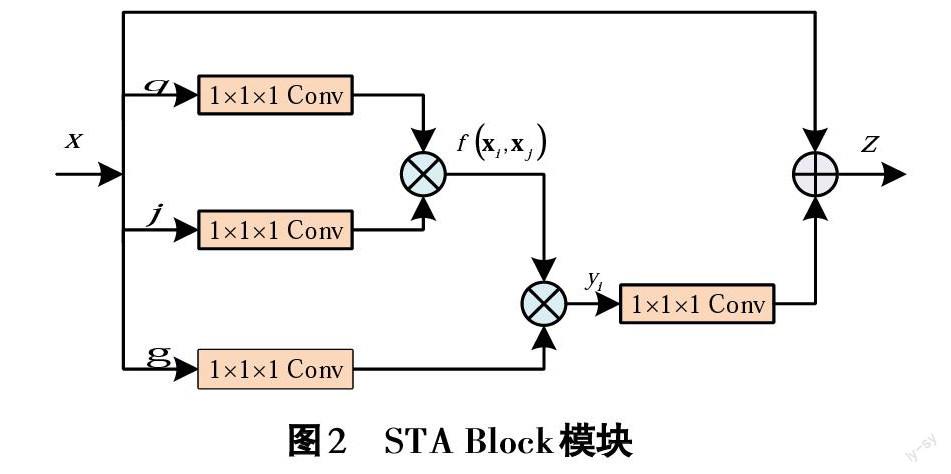
為進一步提取群體深度特征的遠距離依賴性,設計時空注意力模塊(Spatio-Temporal Attention Block, STA Block),在不改變三維殘差網絡原有結構的基礎上,將該模塊插入Conv4_x殘差塊前面。基于非局部注意力機制的基本原理[5],時空注意力模塊(STA Block)采用嵌入式高斯函數作為相似性度量函數,采用線性函數作為響應函數,即:
[fxi,xj=e(Wθxi)T(Wφxj)]? ? ? ? ? ? ? ? ? ? ? ? ? (1)
[g(xj)=Wgxj]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (2)
其中,[Wθ], [Wφ],[Wg]為待學習的權重參數。通過公式(3)計算可得到[yi]的非局部時空注意力值,將該值與原始輸入特征[x]進行殘差鏈接,即可得到時空注意力增強的特征[z]. 即:
[zi=wzyi+xi]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(3)
其中,[wz]為待學習的權重參數,[+]表示殘差連接。STA Block模塊的結構圖如圖2所示, 圖中?表示矩陣乘法。
1.3 深度特征融合與識別
為進一步提升群體行為識別的準確率,采用[3D]卷積融合和[3D]池化融合方式構建深度特征融合模塊。其中3D卷積融合的形式化表示為:
[ycat=concatzv, zm]? ? ? ? ? ? ? ? ? ? ? ? (4)
[y=ycat*f+b]? ? ? ? ? ? ? ? ? ? ? ? ? (5)
上式中,[zv, zm]分別為深度可視特征圖及運動特征圖,[zv, zm∈RT×H×W×D],其中[T]為特征圖的時域尺寸,[H]和[W]分別表示特征圖的寬度和高度,[D]表示特征圖的通道數;[ycat]為[zv]和[zm]的直接連接且[ycat∈RT×H×W×2D]; [*]為3D卷積操作;[f]為[1×1×1]的卷積核;[b]為偏置常數。將卷積結果[y]輸入過濾器大小為1×2×2的3D最大池化,形成3D卷積融合。
1.4 模型參數
模型的空間域殘差網絡和時間域殘差神經網絡具有相同的網絡結構,分別對視頻的RGB幀序列以及光流序列進行深度特征提取,時空注意力模塊(STA Block)被嵌入在Conv4_x殘差塊前,輔助提取具有遠距離依賴性的群體時空特征。由于二維卷積不能很好地捕獲視頻序列間的時序關系,三維卷積不僅能捕獲局部空間信息,還能捕獲全局時間信息。因此,文中模型的卷積和池化操作均為三維卷積以及三維池化。模型詳細的參數設置如表1所示。
2 實驗與分析
2.1 數據集與數據預處理
實驗中所有的群體行為視頻均來自CUHK群體數據集,該數據集包含來自215種群體場景下的474個視頻。該數據集的群體場景均在不同的監控環境下獲取,包括機場、商場、街道等眾多城市公共場所,其包括的所有群體行為被分為八類,具體類別如表2所示。
類別1表現的是密集群體以不同的形態無規律地向四周行走;類別2和類別3表現的是群體中的絕大部分朝著同一方向行走;類別2的群體是以有組織的形態有序行走,群體中的個體行走方向相對穩定;類別3的群體以無組織的形態行走,群體中的個體隨時都可能改變方向,極有可能發生擁堵情況;類別4~8表現的是公共交通和群體管理場所群體流的變化情況,類別4是不同方向的群體流合并,例如火車站進站口的群體流場景;類別5是群體分散成多個流,例如火車站出站口的群體流場景;類別6是群體與反方向群體交叉行走,例如斑馬線上群體流場景;類別7與類別8表現的是自動扶梯上人流情況,類別7比類別8場景更加復雜,包含了自動扶梯周圍的人流情況。
選取每個視頻中隨機位置的連續32幀圖像作為訓練數據,并將原圖像大小調整為[224×224]。為獲得更好的分類精度,對提取的RGB圖像數據和光流數據均進行標準化處理。
2.2 模型訓練
實驗采用PyTorch1.9.0+CUDA11框架在Ubuntu18.04.5LTS操作系統下使用雙GPU(型號為:Nvidia3090)完成并行加速訓練。模型中雙流網絡的輸入設置為連續的32幀RGB數據和連續的32幀光流數據。下面從數據清洗與預處理、訓練、測試三個階段說明文中實驗的具體設置。
1)數據清洗與預處理階段。首先對原始視頻進行分類,其中80%用于訓練集,20%用于測試集,將小于32幀的小視頻清除掉,然后采用TV-L1算法提取視頻的光流序列。考慮到視頻間分辨率的不一致性,將提取的RGB幀和光流圖大小調整為[256×320],并采用隨機裁剪與水平翻轉的方式進行數據增強。
2)訓練階段。將預處理階段的RGB幀和光流圖裁剪為[224×224],為了加快網絡的收斂速度,裁剪后的RGB幀和光流圖統一歸一化到[-1,1]。經多次實驗發現,BN層對整個網絡至關重要,在實驗中產生過梯度爆炸、過擬合等一系列問題,在加入BN層后都有所緩解。因此,在訓練過程中,每個3D卷積后都會加入一層BN層進行批量歸一化。訓練中采用小批量隨機梯度下降算法優化網絡參數,批大小為6,動量為0.9,權重衰減系數為5e-4。雙流網絡中兩個分支的初始學習率都為0.001,學習率改變策略為當訓練損失在6個epoch內沒有降低時,將學習率降為原來的1/2。
3)測試階段。采用預留的20%的數據作為測試集,用來測試網絡的擬合能力,對于每幀圖像同樣采取隨機裁剪的方式進行數據增強。采用top-1識別準確率作為評價標準,最后判斷所有樣本的8類概率作為分類的結果。
2.3 實驗結果分析
為驗證模型的合理性,基于CUHK數據集開展多次實驗,驗證模型中各個模塊對群體行為識別結果的影響;并通過與已有方法的對比分析,驗證模型的有效性。
通過以上實驗分析,模型最終在Conv4_x殘差塊前插入STA Block模塊,且采用連接融合的方式進行融合。為了獲取更好的實驗效果,本次實驗事先基于UCF101數據集對網絡進行預訓練。預訓練能使網絡更好地學習到通用特征,使模型具有更好的泛化效果。
基于相同的實驗數據集,文中方法與其他方法識別結果的對比如表6所示。從表6可知:文中方法的識別結果要優于其他方法,與其他方法最好的結果(文獻[7])相比,文中方法的準確率提高了1.1%。而文獻[7]的數據預處理方式更為復雜:除了提取光流圖外,該方法還使用背景減除法對RGB圖像序列進行了預處理。此外,該方法的輸入僅為連續的10幀圖像,而文中方法輸入為連續的32幀,顯然文中模型更具備捕獲遠距離依賴性的能力。綜上所述,構建的融合雙流3D殘差網絡與時空注意力的群體行為識別模型可有效地完成群體行為識別。
3 結論
1)針對群體行為識別任務,提出了一種融合時空注意力機制的雙流殘差網絡結構。采用UCF101數據集進行預訓練,將得到的參數初始化至整個網絡,并使用CUHK群體數據集對權重參數進行微調,該模型對8種群體行為的分類識別具有更高的準確率。
