MySQL索引改進的B+樹的研究
2022-05-30 10:48:04林榮杭劉小英
電腦知識與技術 2022年16期
關鍵詞:數據庫
林榮杭 劉小英

摘要:MySQL數據庫采用了B+樹作為索引的數據結構,傳統的B+樹的葉子節點是一個單向的指針,這使得在范圍搜索數據時,只能單方面查找一個方向的數據,極大地增加了數據查找的時間。為了增加MySQL數據庫中索引的搜索效率,提出一種改進的B+樹,通過對B+樹的葉子節點增加一個雙向的指針,提出雙向查找數據的B+樹算法,通過與原生B+樹的搜索進行對比發現,改進的B+樹在范圍搜索方面可以極大地減少搜索時間和I/O次數。
關鍵詞:數據庫;B+樹;數據結構;MySQL
中圖分類號:TP301? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)16-0012-02
數據庫作為目前最有效地管理數據的方式被廣泛應用于各類應用系統中[1-2]。在大量的數據庫選型中,MySQL數據庫因為自身開源,輕便,速度快的優勢成了最為頻繁使用的數據庫之一[3-5]。在MySQL數據庫的底層,為了方便對數據的查找、插入、刪除、修改以及維護,MySQL數據庫在眾多的數據結構中選擇了B+樹這一數據結構來實現索引、實現底層的數據信息管理。B+樹是多路查找樹B樹的一個變種[6],同時B+樹的樹結構是多路搜索的平衡樹,數據僅存儲在葉子節點中,非葉子結點引導搜索,同時為了有效檢索所有的葉子頁面,葉子節點間通過指針相互鏈接[7]。本文在研究了傳統B+樹搜索的原理后,對B+樹的葉子結點進行了優化,有效地提高了搜索效率。
1 傳統B+樹
1.1 B+樹的特征
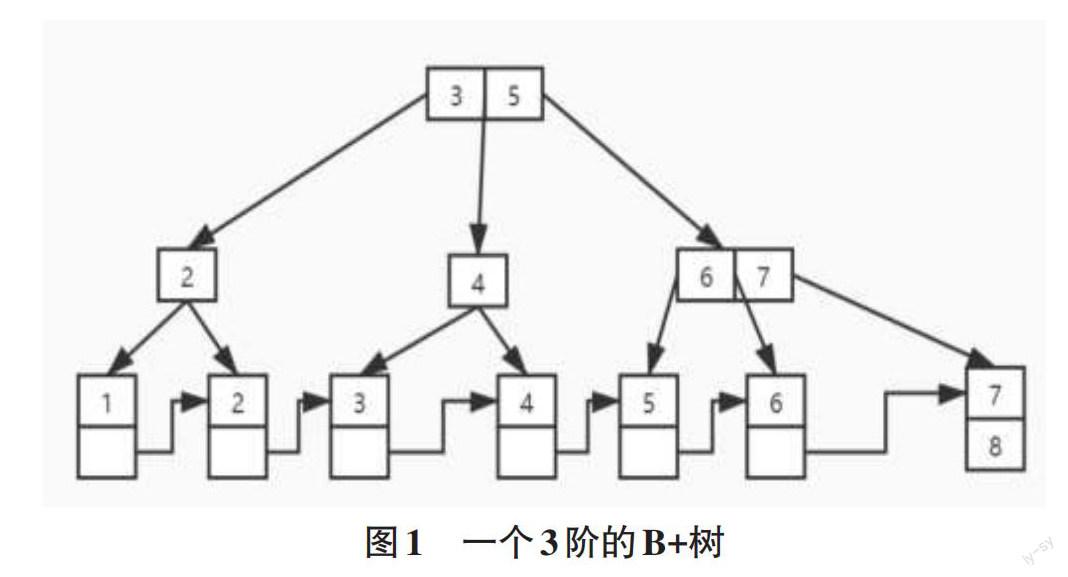
B+ tree 是一種多叉樹,每個節點可以擁有大量子節點,同一個樹中允許不同的節點可以擁有不同數量的子節點[8]。一棵B+ tree由一個根節點、若干個內部節點和若干個葉節點組成。B+樹中數據以鍵值對(Key - value)的形式存儲在樹中,非葉子節點只存儲鍵(Key),而在葉子節點中存儲鍵和值(Key - value)。通過觀察圖1,一個3階的B+樹,可以發現B+樹一個節點可以存放多個值。一顆階為P的B+樹,它的Root(根)節點至少應該有兩個子節點,同時Root節點最多只能擁有P個孩子節點。同時這個B+樹的每個非葉子節點最多也只有P個孩子節點,最少應該存在兩個節點,這個特性和Root節點一樣。而每個葉子節點中最多存在P-1個元素,最少存在?P/2?個元素。
1.2 B+樹對數據的操作
B+樹對數據的操作主要包括查找、插入和刪除。對數據進行插入和刪除的時候,B+樹會判斷每個節點的子節點是否滿足最多存在P-1個元素,最少存在?P/2?個元素的規則,不滿足則實現上溢或者下溢操作,調整樹的平衡,在自我平衡后B+樹每個葉子節點到Root節點的深度也是一樣的。在進行數據插入操作時,B+樹會對插入數據進行排序,實現自身數據結構的有序性。在對數據進行有序排序后,B+樹在葉子節點會利用一個單向鏈表形式的數據結構將葉子節點的所有節點有序的串聯在一起。在進行查找操作時,B+樹會通過非葉子節點來逐個定位到一個需要查找的范圍,然后在這個范圍的葉子節點進行搜索,搜索的方式則是通過葉子節點的單向鏈表來查找數據。
2 改進的B+樹
2.1改進思路
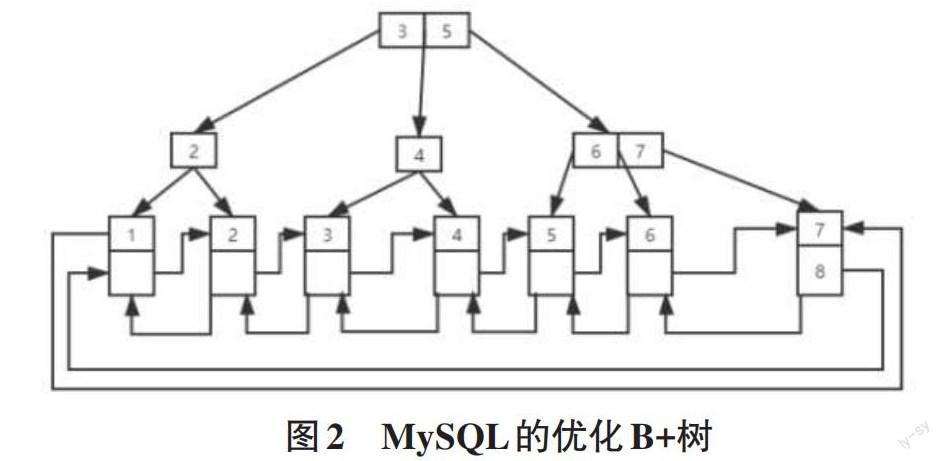
通過觀察B+樹的查找方式不難發現,B+樹在查找一個數據時首先定位某個非葉節點是否存在該數據,不存在則在一個范圍內的葉子節點中通過單向鏈表查找,但是當葉子節點過多時就會發生鏈表長度過長,此時采用單向鏈表查找模式就會出現極大的時間浪費,同時也不利于MySQL數據庫對數據的精確范圍查找,因為單向鏈表只有一個方向,無法滿足在使用MySQL數據庫時出現的雙向查找,所以需要讓B+樹的葉子節點不只是單向的鏈接,而是可以雙向循環的鏈接,讓數據查找時可以隨意沿著某個方向去查找,如圖2所示。
2.2改進后的B+樹算法
MySQL數據庫在進行數據操作時常會使用范圍的查找,例如使用select * from * where x(字段) 以下是改進后的B+樹搜索算法 輸入:第一個滿足小于搜索值(Key)的位置 輸出:獲取到所有滿足小于搜索值(Key)的值 List if(this.number <=0)? //判斷當前葉子節點是否存在值 return null; Integer left = 0;? ?//葉子節點內部是個數組 Integer right = this.number; Integer i = 0; while(true) { if(key.compareTo(i) <= 0) { //獲取所有小于Key的值 list.add(this.values[i++]); }else {? //表示已經遍歷完當前葉子節點中所有小于Key的值 if(this.prev.title.equals("end")){ break; //判斷指針是否已經移動到最右邊的葉子節點 } this.key = prev.key; //將當前的key數組指向葉子節點左邊的葉子節點的key數組 this.values = prev.values;//同上操作,讓values數組指向左邊的values數組 } } return list;} 在改進了B+樹的搜索算法后,B+樹的搜索小于某個值的流程為: 1)調用搜索算法先定位到第一個小于或等于搜索值的臨界值; 2)對臨界值的葉子節點進行遍歷,因為是數組,其遍歷的時間復雜度為O(1); 3)遇到第一個大于搜索值的數據時,將Key和Values數組移動到前一個葉子節點中; 4)遍歷前一個葉子節點數據; 5)遍歷完后檢查前一個葉子節點是否為右邊最后一個節點,如果是則結束遍歷操作,并返回值,不是繼續移動指針并遍歷。 3 實驗分析 3.1實驗對比 為了驗證改進后的B+樹在MySQL中搜索效率的提升,本文選擇Java為編程語言,在Eclipse上分別對改進前后的B+樹進行了構建,并通過兩者的I/O次數和查找用時來探討改進后的B+樹在數據查找方面的優勢。在實驗中采取了控制變量法用于提高實驗的可信性,實驗中的B+樹為512階,并且搜索5條數據(搜索結果只有5條數據,格式為大于x和小于y),得到結果如表1、表2所示。 3.2實驗數據分析 由表1可以得出,隨著數據量的增加,雖然搜索的數據一直都只有5條數據,但是由于搜索的5條數據是雙向的,而初始的B+樹當中葉子節點是一個單向鏈表,無法滿足對數據的雙向搜索,所以會產生更多的I/O次數,當數據達到105級別時會出現I/O次數驟升的情況。改進后的B+樹,因為葉子節點是雙向循環的,所以每次搜索的I/O次數都十分平均,沒有出現驟升的情況。由表2可以得出,原B+樹在數據量為105由于I/O次數的增加,其搜索時間也突然增加,但是改進后的B+樹并不會出現這種現象,這也增加了搜索的穩定性,不會出現突然間的時間增大。在數據逐漸增大的過程中MySQL使用改進后的B+樹時所帶來的時間消耗并不會出現突然性的增加,而是一個平緩的過程,這證明了在將B+樹改進后,B+樹的搜索優化效果較好。 4 結論 通過分析原生B+樹的基本特點,提出了一種MySQL索引改進的B+樹,通過將B+樹葉子節點的單向鏈表變為雙向鏈表來提升B+樹在對范圍數據進行查找的效率。改進后的B+樹在對范圍數據進行查找時帶來了極高的效率,無論是從I/O次數還是時間消耗上來看都得到了極大的提升,這些提升對于數據存儲量極大的MySQL數據庫而言有現實意義。 參考文獻: [1] 侯金彪.一種基于Jsp和MySQL的外賣系統的設計與實現[J].安順學院學報,2021,23(3):129-136. [2] 朱寶善,陳光浦,李鵬程,等.基于B/S模式和MySQL的人力資源管理系統設計[J].現代電子技術,2021,44(14):65-69. [3] 宋永鵬.基于MySQL的數據庫查詢性能優化[J].電子設計工程,2021,29(12):43-47. [4] 豆利.基于MySQL的查詢優化技術[J].電腦知識與技術,2021,17(15):35-36. [5] 石怡.基于MySQL數據庫的查詢性能優化研究[J].四川職業技術學院學報,2021,31(1):164-168. [6] 王瀾.內存數據庫中B+樹和CSB+樹的性能比較[J].通訊世界,2015(12):277. [7] 施恩,顧大權,馮徑,等.B+樹索引機制的研究及優化[J].計算機應用研究,2017,34(6):1766-1769. [8] 時亞南.B+樹算法的Java實現方法研究[J].計算機技術與發展,2015,25(1):111-114. 【通聯編輯:王力】
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
