基于卷積神經網絡的生物醫學實體標準化研究
2022-05-31 02:28:28趙蘭枝史欣沅
科技創新與應用 2022年15期
趙蘭枝,史欣沅
(1.河套學院 數學與計算機系,內蒙古 巴彥淖爾015000;2.中國科學院大學,北京101408)
在科學報告和公共出版物中,同一概念往往具有不同的表達方式。實體標準化,或者稱為實體鏈接,就是要將不同的表達形式對應到相同的標準實體上。在生物醫學領域,每年要出版數十萬的文章。所以,自動的高效率信息檢索和知識處理是非常重要的。自然語言處理領域的幾大基本問題之一就是實體標準化。實體標準化要完成從模糊表達或者多樣化表達到標準表達的任務。
人們為了完成實體標準化的任務做了許多的嘗試。由于生物醫學領域概念的多樣性,生物醫學的實體標準化始終是研究中的前沿領域,許多致力于完成實體標準化的文章紛紛發表。然而僅僅依靠形式上的相似來判定鏈接關系是不恰當的。要想準確地完成實體標準化,必須要從實體所蘊含的內在含義出發來思考問題。由于深度學習的崛起,人們期望機器能夠自己學習到不同實體之間的鏈接關系,即使用機器學習的方法來完成實體標準化。
近些年來,以機器學習為代表的人工智能領域迅速崛起并且成為當代學術界和工業界的熱點話題。現在,人工智能技術遍布我們的生活。從手機語音助手、商品推薦系統、人臉識別系統到自動駕駛技術,這些都或多或少地使用了人工智能技術。特別是近些年,隨著數據的爆炸式增長、機器計算能力的增強、機器學習算法的成熟以及其廣闊的應用前景,越來越多的人開始關注“深度學習”這個全新的研究領域,深度學習也以其強大的能力被運用于各個研究領域。詞嵌入技術的出現使得自然語言轉變為特征向量產生可能,也使得深度學習開始被運用于自然語言處理領域。然而深度學習需要大量的標注數據作為訓練集。當可供訓練的語料庫較小時,通過深度學習完成實體標準化就成為了挑戰。
本文從研究實體的語義含義出發,通過使用預先訓練好的詞向量所包含的語義信息來完成從通俗文本表達到標準實體的任務。通過整合完美匹配和淺層卷積神經網絡的方法,本文模型能夠在可訓練樣本較少的情況下達到非常好的性能表現。
1 基于廣域表的縮寫檢測模型處理實體類型產生數據集的原理
通過將預先標注好的文件整合并處理后生成廣域表,借由廣域表完成縮寫檢測和找到本文處理的實體類型產生數據集。首先將數據集經過完美匹配模塊進行部分匹配和剪枝,然后將目前還未被匹配的實體送入卷積神經網絡模型進行實體標準化產生特征向量并與標準向量進行對比,通過投票器獲得最終結果。
本文采用的輸入數據是經過預先標注好的文本數據。預標注文本是由人工標注的文本,并為每個實體標記了類型。預標注文件分為兩類,一類標注文件標記了每篇文章中出現的實體并為其編號,同時指明了該實體的其他具體信息;另一類標注文件標記了每篇文章中出現的標準實體并為其編號以及對應的字典ID等具體信息。例如對于一篇如圖1所示的語段,其對應標注文件如圖2和圖3所示。

圖1 原始文本數據

圖2 預標注文件一(截圖)

圖3 預標注文件二(截圖)
由《Abbreviation definition identification based on automatic precision estimates》一文提出的縮寫檢測模型(以下簡稱Ab3P模型)是一種準確率極高的,能將生物醫學領域的縮寫詞轉變成完整形式的模型。在各種各樣的出版物中,縮寫形式在通俗文本中是普遍存在的。例如CNS表示中樞神經系統(central nervous system,CNS),這樣的用法經常出現在有關神經學科的研究文獻中。顯然,這樣的縮寫形式也應該鏈接到相應的實體上去。由于縮寫詞大部分來源于詞組,縮寫詞通常沒有預先訓練好的詞向量,并且會對模型的訓練產生干擾。本文通過Ab3P模型[1]來將通俗文本中的縮寫形式轉換其對應的標準詞組。Ab3P是一個專門為生物醫學概念開發的縮寫檢測工具,其準確率高達96.5%。Ab3P縮寫檢測模塊如圖4所示。

圖4 Ab3P縮寫檢測模塊
通過應用Ab3P縮寫檢測模型可以生成每篇文章對應的縮寫詞對照表。縮寫詞對照文件包含實體的縮寫形式和其對應的完整形式等信息。一個縮寫詞對照文件如圖5所示。

圖5 縮寫詞對照(文件截圖)
對于神經網絡所需要使用的輸入數據,需要將通俗文本中的實體對應到相應的標準實體上。首先需要通過由Ab3P模型生成的縮寫詞對照表將縮寫形式用完整形式替換,再將所有數據合并到一張廣域表中以供模型之后使用。廣域表的部分數據如圖6所示。

圖6 廣域表部分數據(截圖)
輸入文件給出了標準詞典,標準詞典包含實體ID和標準實體名稱2部分數據。部分標準詞典數據如圖7所示。

圖7 標準詞典部分數據(截圖)
對于帶有連字符的實體,需要用空白字符取代連字符來保證模型的正確運行。同時,大小寫的不同也可能會對詞向量的生成產生影響。如果某個詞無法在詞向量模型中找到匹配項,則需要將其全部轉為小寫形式再進行匹配。對于一個標準實體來說,使用預先訓練好的Word2Vec模型,將實體中的每個詞轉變成相對應的大小為(1,200)詞向量。每個詞對應的詞向量為xi=[x1,x2,...,xk],其中k=200。然后對這n個詞向量做簡單平均處理得到該實體對應的詞向量y=[y1,y2,...yk],其中k=200。
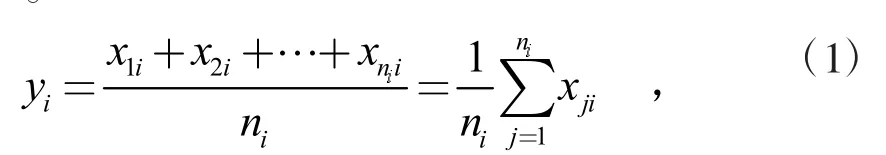
其中,xji表示第i個詞向量的第j個分量,ni表示詞向量的個數。
由于大小為(1,200)的詞向量處理起來開銷很大,并且包含許多次要信息,所以需要對詞向量進行降維處理。本文使用主成分分析法對詞向量進行降維,主要成分占比例不小于95%。經過主成分分析法降維的向量大小為(1,139),大大提升了模型的效率。假設實體E的標準向量為z,則z=PCA(y,ncomponent=0.95)$,其中y表示實體E的大小為(1,200)的詞向量。最后將所有標準向量與標準詞典表合并得到標準向量表。生成標準向量如圖8所示。

圖8 生成標準向量
首先要將訓練數據分割為訓練集和驗證集,本文選擇從訓練數據中隨機選擇17%作為驗證集數據。由于訓練數據中包含許多未對齊實體(這些都是與本文所研究目標無關的實體),第一步要從廣域表中去掉這些實體項。
同時本文的研究對象為phenotype和habitat,所以需要剔除其他類型的實體。然后將剩余的通俗實體通過詞向量模型轉化成大小為(8,200)的嵌入矩陣。由于98.8%的實體都是由不超過8個詞組成的,所以設置嵌入矩陣的行數為8。如果實體的詞向量個數不足8個,則需要用零向量填充至8個。若實體的詞向量個數超過8個,則需要進行分組。每8個一組,組內進行簡單平均處理。若最終結果不足8個,則進行0填充。經過這樣的處理,每個通俗實體都是有大小為(8,200)的嵌入矩陣描述。令Xi表示第i個輸入的實體,xij表示第i個實體Xi第j個單詞的k維詞向量,本文中k=200。定義詞嵌入矩陣xi如下:
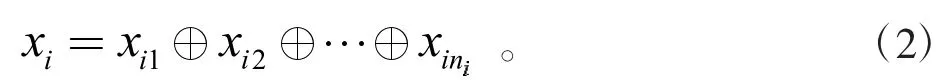
2 利用完美匹配模塊提升模型的精度和提高卷積神經網絡的訓練效率
值得注意的是,自由文本中的某些實體能夠通過基于規則的處理與標準實體完成形態上的匹配。這些實體經過形態上的比較即可快速地找到對應標準實體,而不需要被送入神經網絡模型來完成鏈接。并且根據我們的詞向量生成方式,形態上完全相同的實體之間,其特征向量一般也應該是相同的。由于完美匹配模塊的貢獻,本文的神經網絡模型能夠更高效地利用數據,收斂速度也會加快。完美匹配的規則如下:
(1)用空白符替代連字符;
(2)移除除去字母和空白符之外的所有字符;
(3)采用大小寫不敏感匹配模式。
完美匹配模塊如圖9所示。

圖9 完美匹配模塊
采用卷積神經網絡的靈感來源于KIM[2]和LIMIMSOPATHAM與COLLIER[3]等人。由于卷積核相當于特征提取器,使用卷積神經網絡可以提取詞向量中內在的本質特征。不同的卷積核可以提取的不同的特征,通過增加卷積核的個數可以增加提取的特征數目。一般來說直接提取的特征過于細致,所以需要使用池化來提升來進一步捕捉泛化特征和降低維度來提高收斂速度。使用全連接層可以學習到不同特征之間的相互聯系。所以卷積神經網絡往往會在網絡尾端加入全連接層。
本文的卷積神經網絡模塊由1個一維卷積層、1個池化層和2個全連接層構成。神經網絡的輸入為大小為(8,200)的嵌入矩陣,輸出為一個大小為(1,139)的特征向量。輸出的特征向量將與所有標準向量進行比較,選擇在特征空間中余弦距離最小的向量作為該實體對應的標準向量的得分。選擇得分最高的標準向量最為該實體對應的標準向量。卷積神經網絡結構如圖10所示。

圖10 卷積神經網絡結構
為了減少過擬合,本文采用3個CNN模型同時訓練的集成方法。3個CNN模型具有相同的結構,但是他們的初始權重卻是各自隨機初始化,并且具有不同的卷積核大小,不同大小的卷積核和可以抽取不同細粒度的特征。為了增強本文模型的泛化能力,CNN模型所使用的數據是經過隨機bootstrap取樣的[4]。并且本文采用5-折交叉驗證的方法使用袋外數據來驗證。3個CNN模型產生的特征向量將被送入一個多數投票器中。如果沒有結果以多數優勢勝出,則投票器會選取一個驗證過程中準確率最高的模型產生的結果。結合集成機制的網絡模型如圖11所示。

圖11 結合集成機制的網絡模型
整個模型的輸入數據分為2種:預注釋通俗文本實體和標注實體。
標準實體通過詞向量模型轉變成(n,200)的向量模型,再經過簡單平均和PCA降維處理后變成大小(1,139)的標準向量。
預注釋文本中的實體首先經過Ab3P模塊將縮寫詞還原到完整形式,然后通過詞向量模型成為(8,200)的嵌入矩陣。嵌入矩陣被送入3個結構相同的CNN模型中,得到大小為(1,139)的特征向量。將特征向量與標準向量做比對,選取余弦相似度最高的標準向量送入投票器。投票器選擇得分最高的標準向量作為結果。數據流動方向如圖12所示。

圖12 數據流動方向
3 實驗結果及分析
本文所使用的生物醫學語料庫和預先注釋的實體集由BioNLP-OS2019 task Bacteria Biotope提供。該任務中包含了2種實體類型:phenotype和habitat。實體phenotype描述了微生物的特性;實體habitat描述了可以觀察到微生物的物理環境。同時該任務還提供了包含了3 602個相關標準概念的標準詞典。在提供的原始詞典中,每個實體被分配了一個唯一的ID,同時提供了該實體的層級信息。在本文中,每個標準實體的層級信息被省略。Ab3P縮寫詞探測器由任務組織者們另外提供。預先編譯好的詞向量模型也需要單獨下載。本文所使用的實驗環境為windows 10專業版20H2。本文使用基于Tensorflow和Keras的深度學習框架設計模型和算法,使用python語言進行編程。
本文的神經網絡模型使用隨機梯度下降算法作為優化方法,使用余弦相似度作為損失函數。在整個訓練數據中,隨機選擇20%作為驗證集數據。同時使用提前停止法來決定訓練輪數。設置學習率為0.01,batch size為2,三個模型的卷積核大小分別為4、5和6,卷積核數目為5 000,超參數的設置由網格搜索法決定。
本文所介紹的模型具有良好的性能。表1展示了本文模型各個組件的準確率。通過分析表1可以看出,我們的完美匹配模塊起到了相當的作用。在測試集中,CNN模塊的準確率只有0.66,而整體的模型準確度卻達到了0.71,這說明完美匹配模塊對整體模型準確度的貢獻相當可觀。

表1 模型各部分性能
由表2可知,通過與其他模型的比較,ABCNN[5]只有0.22的準確率,而本文模型卻具有0.71的準確率,顯示了本文模型的巨大優勢。由于ABCNN模型比較復雜,在數據集比較充分時發揮出非常高的性能。但是在數據集較少時,ABCNN模型的訓練不足,無法發揮很好的性能。得益于淺層卷積網絡的簡單結構,本文模型在數據集較少時能夠較快收斂并且達到非常高的精度。基準模型[6]的準確率為0.69,由于基準模型只有一個全連接層,無法從數量眾多的特征中學習到各個特征和標準向量之間的關系。本文使用2個全連接層來捕捉特征和標準向量之間的對應關系,使得模型準確率上升到0.71。

表2 各模型性能比較
本文采用3個CNN模型同時訓練的方法來提升模型準確率。整合模型的準確率略優于單個模型,所以整合模型確實起到了提升模型準確度的作用,但是整合模型訓練比較費時。本文所使用的卷積核數目為5 000,改變卷積核的數目會導致CNN模型準確度的變化。圖13給出了使用不同卷積核時CNN模塊的準確度。

圖13 卷積核數目對準確率的影響
當卷積核過少時,CNN模型對特征的提取不足,導致模型在訓練集和測試集的精確度都比較低;當卷積核過多時,模型提取的特征太多太強,導致模型泛化能力變差,即使在訓練集上精確度較高,但在測試集上的精確度卻下降。同時,卷積核增多,訓練時間也會呈現增加趨勢。
雖然本文模型的性能表現比較不錯,但是仍然存在許多不足。首先,在使用詞向量模型構建標準實體的詞向量時,標準實體中的每個詞只是進行簡單的加權平均。事實上,一個實體的詞語中有的包含更多的語義信息,有的攜帶較少的語義信息。一種合理的方式是考慮為實體中的每個單詞分配不同的權重,以使得生成的標準詞向量更能表示其語義特征。或者使用其他的詞嵌入模型,直接將實體轉化成對應的詞向量。
其次,CNN模塊存在問題。通過分析CNN模塊的準確率,CNN模塊在訓練集的準確率較高,但在測試集的準確率卻相對較低。這說明CNN模塊的泛化能力有待提升。
4 結束語
本文介紹了一個基于卷積神經網絡的整合模型用來將自由文本中的生物醫學實體標準化到其對應的標準實體上。使用Ab3P縮寫詞檢測模塊完成對輸入文本中縮寫詞的處理。通過利用預先訓練好的詞嵌入模型將自然語言轉變成機器可以處理的詞向量。利用完美匹配模塊來提升模型的精度和提高卷積神經網絡的訓練效率。3個具有不同大小卷積核的CNN模型同時訓練提高了模型對詞向量的特征抽取能力。淺層神經網絡結構與完美匹配模塊的結合使模型在訓練數據較少時達到了相當的準確率。與相關模型的對比也展示出本文模型的效率。但本文模型依然存在一些問題,想要達到更高的準確率需要更加深入的研究。
模型性能的進一步提升有可能通過將更多的語義信息納入模型而實現,例如上下文環境信息,實體的層次信息等。由于缺乏語境信息而導致標準化過程中產生偏差,這種偏差不僅影響卷積神經網絡模塊的性能,而且會影響完美匹配的性能。對于同一個文本中實體,標準詞典可能具有多個候選實體可以與之對應。但是由于缺乏語境信息,本文模型只能將其對應到一個固定的標準實體上。盡管已經有人在研究如何在實體標準化時保留更多的語義信息,但是想要完成完美的實體標準化還有很長的路要走。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
家庭影院技術(2018年4期)2018-05-09 07:07:52
光學精密工程(2016年6期)2016-11-07 09:07:19
專用汽車(2016年4期)2016-03-01 04:13:43
質量與標準化(2015年9期)2015-12-31 11:41:40
