改進BYOL 的非小細胞肺癌表皮生長因子受體基因突變預測
2022-06-01 14:53:10楊嘉楠王忠昊王昊霖耿國華
光學精密工程 2022年9期
楊嘉楠,王忠昊,王昊霖,耿國華,曹 欣*
(1.西北大學 信息科學與技術學院,陜西 西安 710127;2.西北大學 文化遺產數字化國家地方聯合工程研究中心,陜西 西安 710127)
1 引言
肺癌是對人類健康和生命威脅最大的惡性腫瘤之一,我國的肺癌發病率和死亡率都居于第一[1-2]。根據病理類型肺癌可分為非小細胞肺癌(Non-small Cell Lung Cancer,NSCLC)和小細胞肺癌(Small Cell Lung Cancer,SCLC),其中非小細胞肺癌約占肺癌總發病率的80%~85%[3]。近年來,基于非小細胞肺癌驅動基因的靶向藥物不斷出現,其療效可靠、副作用輕微,已成為最受關注的治療方法之一。在驅動基因中,表皮生長因子受體(Epidermal Growth Factor Receptor,EGFR)是目前突變率最高的靶基因,也是非小細胞肺癌患者應用最廣泛的靶基因之一[4-5]。大量研究表明,只有對EGFR 突變敏感的人才能受益于靶向藥物EGFR 酪氨酸激酶抑制劑(Epidermal Growth Factor Receptor Tyrosine Kinase Inhibitor,EGFR-TKI)[6]。因 此,EGFR 基因檢測的突變狀態已成為臨床應用靶向藥物的先決條件[7],突變檢測的結果尤其重要。
18F-氟-2-脫氧葡萄糖(18F-fluoro-2-deoxyglucose,18F-FDG)[8]PET/CT 顯像是目前在醫院臨床上最常用的分子成像方式,它是一種結合細胞糖代謝和組織形態學的雙模態影像學檢查方法,廣泛應用于惡性腫瘤、心血管和神經系統等領域[9]。中國原發性肺癌診療規范明確指出,18FFDG PET/CT 是肺癌診斷,臨床分期與再分期、療效判定和預后預測的最優手段[10]。18F-FDG PET/CT 顯像技術,可以更為精準地診斷臨床患者EGFR 基因是否發生突變,輔助指導臨床靶向藥物的應用[11]。
對于非小細胞肺癌EGFR 基因突變預測,近年來的研究主要圍繞著影像組學和機器學習展開。影像組學是近年來醫學中的熱點領域,它將癌癥成像特征與基因表達相關聯。影像組學具有反映病變生物學行為的多個定量特征,可對病變的基因表型和突變情況進行預測[12]。Zhang 等[13]利用定量影像組學標志物和臨床變量預測非小細胞肺癌EGFR 的突變狀態,對180例非小細胞肺癌患者提取反映腫瘤異質性和表型的485 個定量特征,利用基于多變量Logistic模型預測EGFR 的突變狀態。結果發現,影像組學特征具有預測非小細胞肺癌EGFR 突變狀態的潛能,且影像特征預測非小細胞肺癌是否存在EGFR 突變的價值顯著優于單獨使用臨床變量模型。
機器學習算法能夠在沒有明確指令的情況下執行特定任務,它依賴于模式和推理。這些算法被饋送數據并且能夠創建復雜的數學模型。雖然線性回歸等基本學習模型能夠對線性關系進行建模,但更高級的機器學習模型,例如邏輯回歸、支持向量機(Support Vector Machine,SVM)和隨機森林具有更高的模型容量,以及非線性建模的潛力[14-16]。深度學習是機器學習的一個子集,它使用多個表示層從原始輸入中逐步提取更高級別的特征[17]。對于非小細胞肺癌的預測,機器學習和深度學習可以結合使用:深度學習用于提取CT/PET 掃描特征[18],而機器學習用于建立各種特征之間的關系。Wang 等[19]使用卷積神經網絡VGG-16 模型,以96 例肺癌患者的CT 圖像作為網絡輸入,預測非小細胞肺癌EGFR 的突變狀態,取得了不錯的效果。然而,這種方法需要依賴大量專家手工標注的患者圖像數據,耗費大量的資源。在專家手工標注的患者圖像數據數量不充足的情況下,網絡訓練出的模型會因樣本重復率太高而過擬合。
為了解決專家手工標注的患者圖像數據不足的問題,人們將視線轉向了無監督神經網絡。無監督神經網絡不需要大量專家手工標注的患者圖像數據,就能區分患者病歷的陰性、陽性。Francisco 等[20]提出了一種無監督遷移學習方法,先在一個胸部CT 圖像數據集進行卷積自編碼器的預訓練,然后為訓練出的卷積自編碼器增加分類器,在另一個包含EGFR 突變狀態信息的肺癌患者CT 圖像數據集進行任務訓練。這種方法的優勢在于不需要大量專家手工標注的患者圖像數據,然而其預測結果準確率卻不如有監督訓練方法。
隨著深度學習領域的高速發展,PIRL[21],CPC[22],SimCLR[23],MoCo[24],SwAV[25]、SimSiam[26]和BYOL[27]等自監督對比學習方法脫穎而出。與傳統的分類方法不同,對比學習并不去學習一張圖片歸屬于哪個類別,取而代之的是去學習各個圖片實例之間的相似點與不相似點,通過縮小相似圖像間的距離,增加不相似圖像間的距離,在向量空間上完成圖像樣本的聚類,構建成向量字典。通過對比學習訓練出的模型不需要大量已標注數據,就能有效地提取圖像特征[28],得到接近有監督方法的預測準確度。
本文提出了一種基于改進BYOL 的非小細胞肺癌EGFR 基因突變預測方法。對患者肺部病灶區CT 和PET 雙模態圖像進行優化處理,在通道維度上將它們連接并作為網絡模型的輸入。同時,修改了BYOL 網絡投影層中非線性多層感知器(Multilayer Perceptron,MLP)的層數,提升了網絡預測準確率。通過調整任務階段頂層分類器,使模型的預測準確率進一步提升。
2 基本原理
2.1 材 料
從醫院處獲得了近幾年來非小細胞肺癌EGFR 基因突變檢測的患者CT 圖像與PET 圖像。為了制作非小細胞肺癌EGFR 基因突變數據集,需要對原始圖像進行預處理。使用專家勾畫MASK 文件對CT 原圖與PET 原圖進行勾畫操作,只保存患者病灶區部分的CT,PET 圖像。然后,計算出PET 數據對應的SUV 值作為新的PET 數據。
在計算時本文使用基于DICOM 標簽的計算規則[29]:
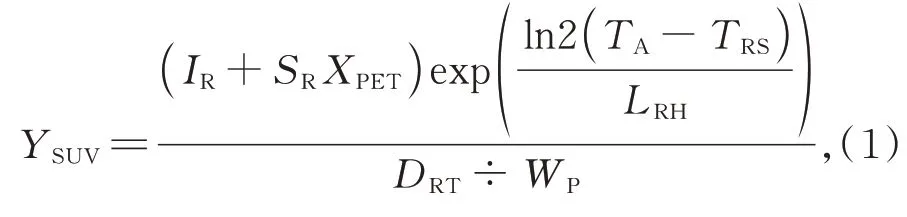
其中:XPET為PET 數據讀取的一個三維矩陣,YSUV為SUV 計算后新PET 數據的三維矩陣,變量DRT為放射性核素總劑量,WP為患者體重,IR為重定標截距,SR為重標斜率,TA為采集時間,TRS為放射性藥物起始時間,LRH為放射性核元素的半衰期(秒)。
對CT 圖像數據使用中值濾波法去除噪聲,以優化CT 圖像數據。將處理后的CT-PET 圖像按4∶1 劃分為訓練集和測試,用于網絡的訓練與測試。
2.2 方 法
2.2.1 網絡結構
網絡的整體流程如圖1 所示。從非小細胞肺癌EGFR 基因突變數據集中讀取患者病灶區的CT-PET 圖像對作為網絡的輸入x~D,其中D表示非小細胞肺癌EGFR 基因突變數據集,x是從D中均勻采樣得到的CT-PET 圖像對。通過t和t'兩種不同的圖像增強操作組得到x的兩個不同的視圖v和v'。fθ和fφ表示兩個網絡結構相同但是網絡權重參數不同的卷積自編碼器。將x的兩個不同的視圖v和v'分別經過fθ和fφ兩個卷積自編碼器正向傳播得到yθ和y'φ。gθ和gφ表示兩組網絡結構相同但是網絡權重參數不同的投影層非線性多層感知器。然后,yθ和y'φ分別經過gθ和gφ兩組 非線性多 層感知 器得到zθ和z'φ。對z'φ進行停止梯度傳播得到sg(z'φ),而zθ則經過預測層qθ傳播得到qθ(zθ)。最后,使用sg(z'φ)和qθ(zθ)進行損失計算,反向傳播更新online 網絡權重參數并依照online 網絡權重參數調整target 網絡權重參數。
網絡中卷積自編碼器采用ResNet-50 網絡框架[30],去除了網絡頂端的全連接層分類器。投影層使用3 層非線性多層感知器,通過3 個以ReLU激活函數和批量歸一化操作隔開的全連接層,將卷積自編碼器提取的特征降維,對網絡輸出的特征向量做L2 正則化操作,將投影特征向量的長度進行歸一化后投影在投影空間,即投影在一個長度為1 的單位超球面上。預測層和投影層結構類似,將提取的特征向量映射到單位超球面上,同時使online 網絡和target 網絡不一致,此時任何圖片經過網絡投影后,在投影空間里面所有圖像的映射都不會坍塌到同一個點,避免產生模型坍塌現象,學習不到有用的信息。損失函數使用均方差(Mean Squared Error,MSE)損失函數,即:
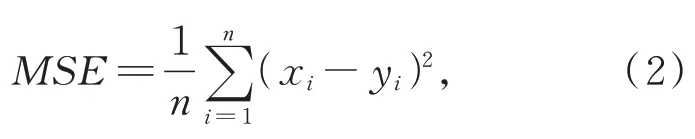
其中:x和y表示兩個特征矩陣,i為其下標,n為矩陣元素總數。通過最小化online 網絡和target網絡映射在單位超球面上的距離來優化online 網絡權重參數。
通過損失函數計算梯度并反向傳播,更新online 網絡的各層權重參數,見式(3):
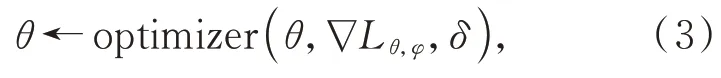
其中:θ是online網絡權重參數,δ是學習率,optimizer 是梯度優化器,?L是損失值的梯度。target 網絡由于梯度停止操作,無法通過梯度反向傳播更新網絡權重參數。取而代之,target 網絡的權重參數會隨著online 網絡的權重參數改變,見式(4):
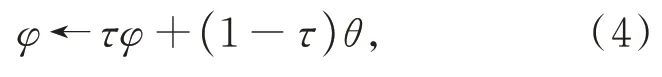
其中:φ是target 網絡的權重參數,τ是超參數,介于0~1 之間,這里取τ=0.99。
2.2.2 損失函數原理
BYOL 網絡通過對輸入圖像使用兩種不同的隨機圖像增強操作,產生2 張不同的視圖,將兩張視圖輸入網絡兩個不同的分支,最終將特征向量映射在單位超球面上。BYOL 網絡認為同一張圖片的兩種不同的視圖應該互為正例,它們的特征向量映射在單位超球面上時應該盡量地靠近對方。因此,BYOL 網絡的損失函數目標是最小化同一張圖片兩個不同視圖特征向量映射在單位超球面上的距離。BYOL 的損失函數如下:

L1是余弦相似度的變形,它的最小值相當于兩個特征向量余弦相似度的最大值,也就是說隨著損失函數的縮小,兩個視圖的特征向量在單位超球面上的映射之間的距離會越來越近。由于online 和target 兩個網絡分支不對稱,所以BYOL網絡會交換兩個圖像增強后的視圖,使其沿另一個分支路進行前向傳播,計算損失值L2。
所以BYOL 網絡的最終損失函數如下:
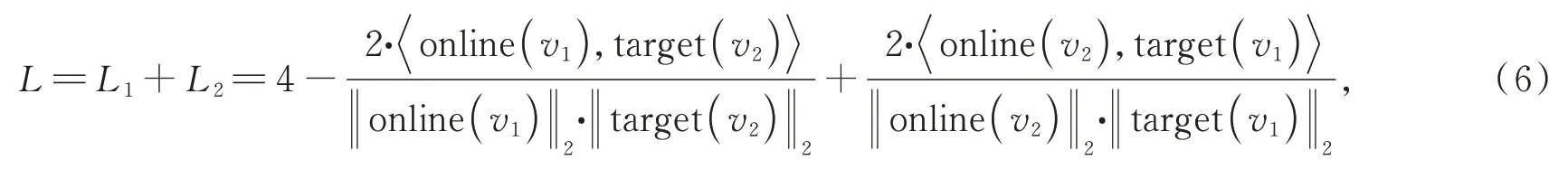
其中:online(v1),online(v2)分別為視圖1、視圖2在online 網絡的輸出特征向量,target(v1),target(v2)分別為視圖1、視圖2 在target 網絡的輸出特征向量。
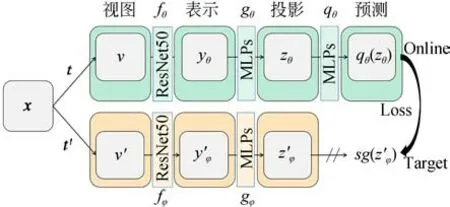
圖1 網絡結構框架Fig.1 Network structure frame
2.2.3 雙模態通道維度連接
Liu[31-32]、Zeng[33]、Wang[34]和Yin 等[35]的研究結果表明,CT 和PET 圖像對患者EGFR 等相關基因突變、生物靶向治療療效的預測及動態評估具有一定價值。從CT 和PET 圖像中提取出來的圖像紋理特征可以用來預測非小細胞肺癌患者EGFR 的突變情況。這里將非小細胞肺癌患者肺部病灶區的CT 和PET 圖像在通道維度上連接疊加作為網絡的輸入,將112×112×1 尺寸的圖像矩陣在通道維度上連接,得到一個112×112×2 尺寸的新圖像矩陣,作為網絡的輸入,見圖2。
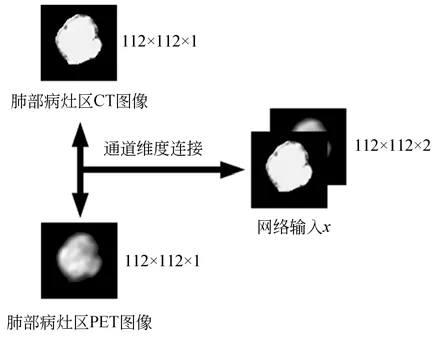
圖2 CT,PET 圖像的通道連接Fig.2 Channel connection of CT and PET images
2.2.4 圖像增強
BYOL 網絡通過對同一張圖片采用兩種不同的圖像增強,產生兩種視圖,然后將兩種視圖分別輸入網絡的兩個不同分支得到輸出計算的損失值。由于這兩個視圖是由同一張圖片變換而成,因此它們應該屬于同一個實例,經過網絡提取的特征向量映射在單位超球面上時,視圖之間的距離應盡可能地小。然而,如果兩個視圖過于相似,會出現模型坍塌現象,影響網絡訓練結果。因此,對比學習需要采用一種圖像增強方式,使得同一張圖片經過圖像增強變換出來的兩個視圖在保持原實例特征的前提下盡量不相似。
本文從基礎圖像增強方法庫中挑選出幾種適合單通道灰度圖像的圖像增強方法(高斯模糊、水平翻轉、垂直翻轉、銳化和縮放后隨機裁剪),如圖3 所示。從這幾種隨機增強庫中每次隨機選出不定數量且參數隨機的圖像進行組合。通過隨機挑選得到的兩個增強操作組會產生兩個在保持原圖像實例特征的前提下,盡可能不相似的視圖。

圖3 圖像增強結果Fig.3 Image augmentation results
2.2.5 網絡實現
本文提出的方法分為預訓練和任務網絡訓練兩部分。在預訓練階段,將無標簽數據集輸入網絡,經過200 個Epochs 的迭代不斷優化網絡權重參數,使網絡學會將輸入的樣本進行分類,對比學習網絡會縮小相似樣本間的距離,擴大不相似樣本間的距離,最終所有輸入的數據樣本被聚為兩類:陰性和陽性。在任務網絡訓練階段,將少量含標簽的數據集(僅使用20%標注數據)輸入網絡,并在網絡頂部增加分類器,經過100 個Epochs 的迭代優化,得到最終訓練好的模型。任務網絡訓練階段因為有專家標注的陰性、陽性標簽,可以為預訓練階段的模型分出來的兩個類型確定陰性、陽性。具體實驗參數如表1 所示,預訓練網絡和訓練任務網絡都使用Adam 梯度優化器,經過調試將學習率設置為0.000 3,訓練時的Batch Size 設置為35。預訓練網絡和訓練任務網絡的Epoch 分別為200 和100。在訓練階段與測試階段將112×112×1 大小的PET 與CT 圖像融合,形成雙通道112×112×2 的矩陣并輸入網絡進行訓練及測試,詳細參數見表1。如圖4 所示,Loss 曲線經過多個Epochs 的迭代最終達到收斂。
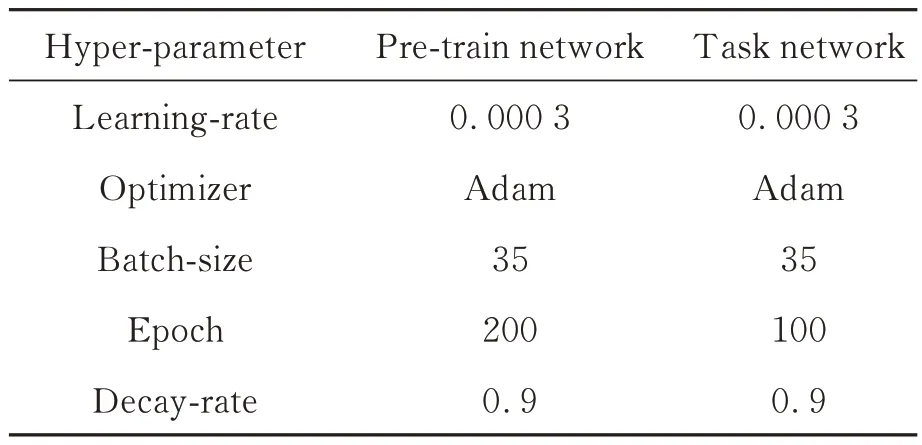
表1 網絡訓練超參數Tab. 1 Network training hyper-parameters
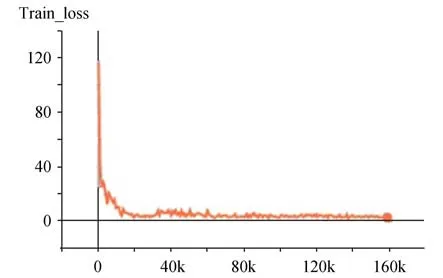
圖4 訓練Loss 曲線Fig.4 Training loss curve
2.2.6 評價指標
使用專家的手動標注作為基本事實,本文使用ROC曲線(Receiver Operating Characteristic Curve)以及曲線下面積(Area Under the Curve,AUC)對網絡進行定量評估[36-37]。
ROC 曲線是基于混淆矩陣得出的。一個二分類模型的閾值可能設定為高或低,每種閾值的設定會得出不同的真正例率(TPR)和假正例率(FPR),將同一模型每個閾值的(FPR,TPR)坐標都繪制在ROC 空間里,就成為特定模型的ROC 曲線。ROC 曲線橫坐標為假正例率,縱坐標為真正例率。使用ROC 曲線作為模型分類性能的評判標準有兩個優點:(1)ROC 曲線簡單、直觀,通過圖示可觀察分析學習器的準確性,并可用肉眼做出判斷;ROC 曲線將真正例率和假正例率以圖示方法結合在一起,可準確反映某種模型真正例率和假正例率的關系,是檢測準確性的綜合代表;(2)ROC 曲線不固定閾值,允許中間狀態的存在,利于使用者結合專業知識權衡漏診與誤診的影響,選擇一個更加合適的閾值作為診斷參考值。
AUC 就是ROC 曲線的下面積。在比較不同的分類模型時,AUC 值越大的分類器,分類準確率越高。
3 實驗和結果分析
3.1 對比實驗
實驗使用由醫院提供的180 余名患者肺部CT 和PET 成像,對每個患者的CT 和PET圖像進行勾畫操作,只保存患者肺部病灶區。將CT和PET 圖像成對保存,制成肺部非小細胞肺癌EGFR 數據集。實驗環境統一使用NVIDIA Ge-Force TITAN V顯卡,Python 版本為3.7,CUDA 版本為10.2,所用 框架為Pytorch 1.10.1 版本。使用本文提出的網絡獲得基于非小細胞肺癌EGFR 基因突變數據集上的預測結果,并與目前廣泛應用的醫學圖像影學以及主流有監督卷積神經網絡VGG-16,ResNet-50,Inception v3 及無監督遷移學習CAE 方法進行對比。實驗結果如表2 所示。
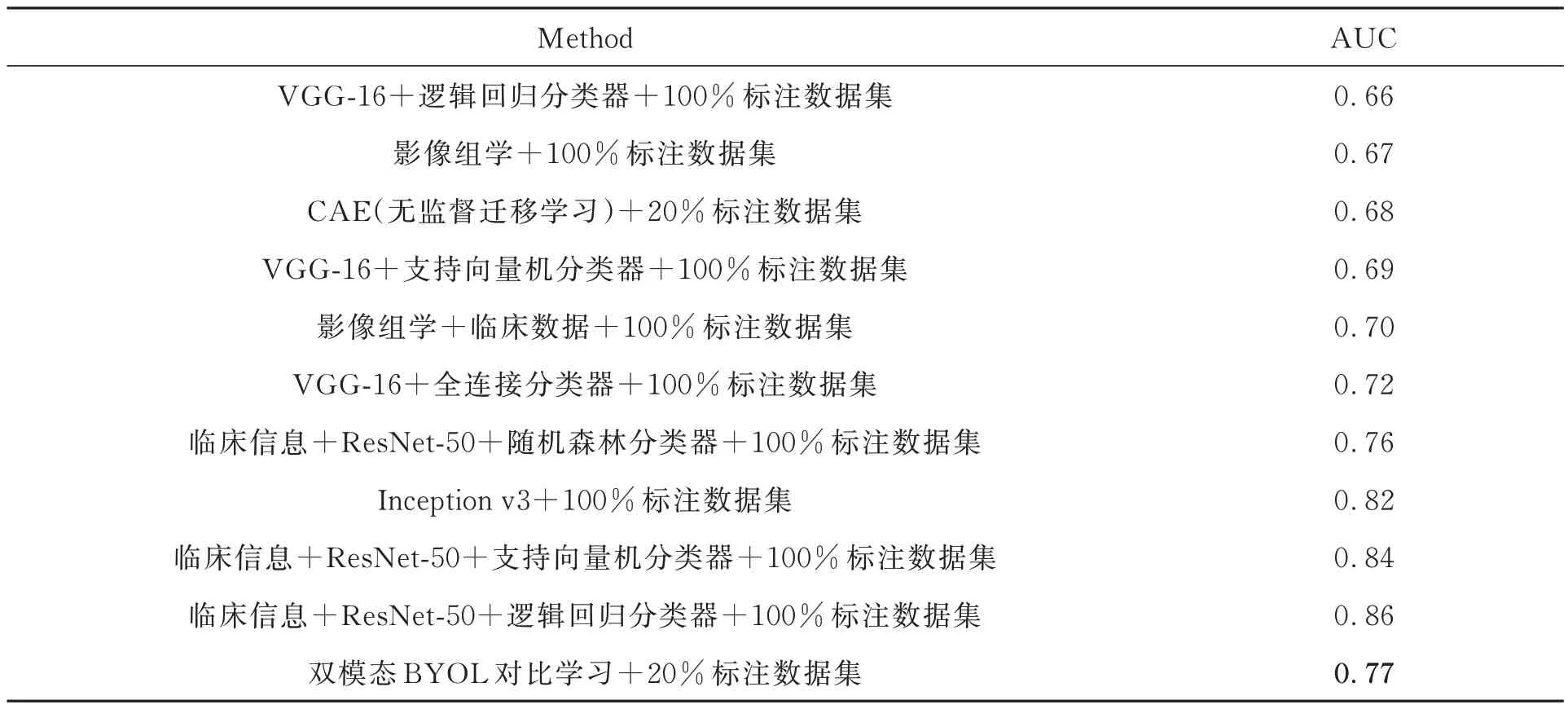
表2 不同方法非小細胞肺癌EGFR 基因突變的預測AUCTab. 2 Predicting AUC for EGFR gene mutation in non-small cell lung cancer by different methods
本文通過使用改進的BYOL 網絡進行自監督訓練,使用無標簽圖像,即未通過專家標注的圖像數據,迭代200 個Epochs 訓練出一個ResNet-50 預訓練模型,再使用少量有標簽圖像(20%的已標注數據)迭代100 個Epochs 微調預訓練的網絡模型,得到任務網絡模型。圖4 為網絡訓練時的損失下降曲線。在不需要大量標記數據的情況下獲得了77% AUC,比傳統的影像組學(67% AUC)的預測效果更好,還高于使用普通卷積神經網絡的有監督方法,和目前比較主流的無監督遷移學習方法(68% AUC)。雖然本文提出的方法AUC 低于融入患者臨床信息的ResNet-50 網絡,但是該方法是自監督訓練,不需要大量的人工標注數據集,也不需要患者的大量臨床信息特征,具有更大的發展潛力。其優勢總結如下:(1)該方法預測得到的AUC 高于傳統影像組學及卷積神經網絡的AUC;(2)使用自監督學習,不需要大量人工標記數據,不需要患者的臨床信息,更加便捷、節省成本;(3)使用對比學習方法,讓相似的病灶區樣本間距離縮短,不相似的病灶區樣本間距離增大,學習到樣本間的相似性,更好地進行分類預測。
3.2 消融實驗
為了進一步探究網絡結構對本文提出的基于雙模態的改進BYOL 對比學習網絡的影響,本文通過一系列消融實驗,分別探究了頂層分類器、投影層非線性MLP 層數和雙模態數據集的影響。
3.2.1 頂層分類器對性能的影響
本文在任務模型的輸出部分分別使用了全連接層、支持向量機和隨機森林3 種分類器,實驗結果見圖5。其中,全連接分類器的分類預測由全連接神經網絡實現,以ReLU 函數為激活函數,最后使用交叉熵損失函數進行損失計算;支持向量機分類器基于1 024 維輸入向量的線性核函數的SVM 模型進行分類;隨機森林分類器基于輸入1 024 維特征向量,使用隨機森林和L1 正則化進行分類。3 種分類器分別得到了77%AUC,75% AUC,74% AUC。從表3 可以看出,使用全連接分類器取得的實驗結果略優于其他兩種方法。
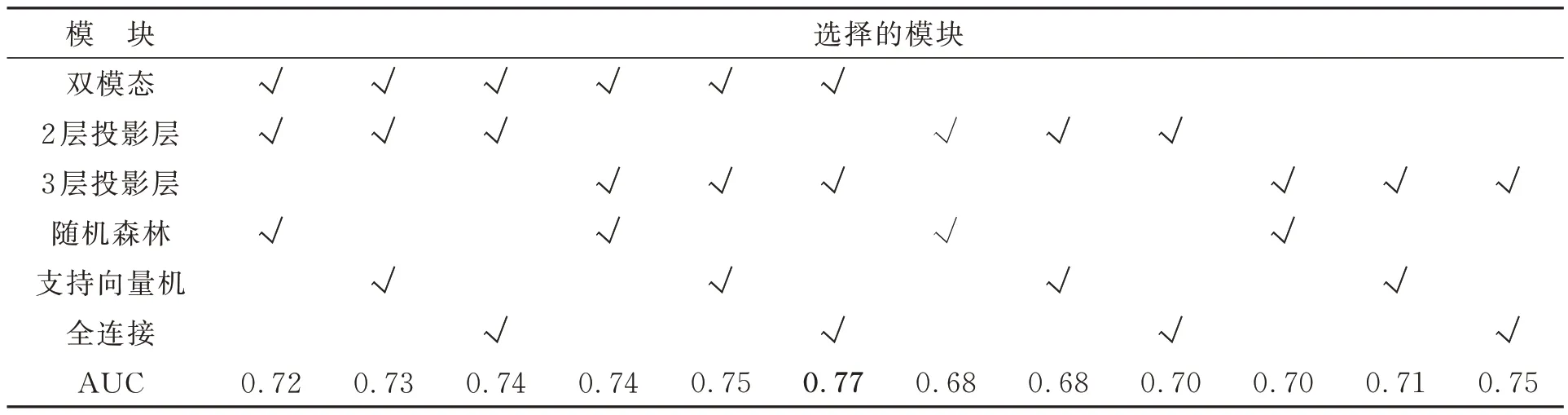
表3 消融實驗結果Tab. 3 Ablation experiment results
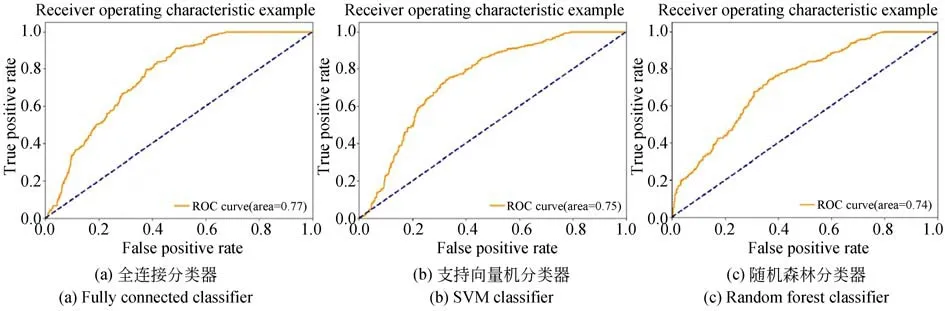
圖5 三種分類器預測AUCFig.5 AUC of three classifiers
3.2.2 投影層非線性MLP 層數對性能的影響
Chen T 等[23]和Chen X L 等[26]發現,通過增加投影層非線性MLP 的層數可以有效提高對比學習網絡模型的分類準確率。而原始BYOL網絡的投影層只有2 層非線性MLP,因此實驗投影層分別使用2 層非線性MLP 和3 層非線性MLP 訓練出的模型進行分類。結果顯示,3 層非線性MLP 訓練出的模型得到了77% AUC,高于2 層非線性MLP 訓練出的模型(74%AUC)。由此表明,通過增加投影層非線性MLP 的層數可以有效地提高對比學習網絡模型的分類準確率。
3.2.3 雙模態對性能的影響
已有研究表明[31-37],CT 和PET 圖像在預測非小細胞肺癌EGFR 突變中具有一定的參考價值。本文將患者病灶區的CT 圖像和PET 圖像信息融合起來作為網絡的輸入。實驗分別使用患者病灶區CT 圖像和PET 圖像的融合信息與只使用CT 圖像信息作為網絡輸入訓練網絡,最終分別得到了77% AUC 和75% AUC。從實驗結果可以看出,同時使用患者病灶區的CT 圖像和PET 圖像兩個模態時可以得到更好的效果。
4 結論
本文基于改進BYOL 的自監督非小細胞肺癌EGFR 基因突變預測方法,以BYOL 自監督對比網絡為基礎對其網絡結構進行改進,加深了非線性MLP 的層數,同時融合了CT 和PET 兩個模態的圖像數據,指導網絡提取更有效的圖像特征,提高預測準確度。本文所提的網絡結構與方法最終得到了77% AUC,相對于傳統的影像組學方法的分類結果提高了7% AUC,相對于有監督VGG-16 網絡的分類結果提高了5% AUC。在不需要大量專家手工標注數據集及大量患者臨床數據的情況下(僅使用20%標注數據),該方法僅比融合了患者大量臨床信息等數據的有監督網絡低9% AUC,能夠有效地指導醫師無創且自動地根據患者的CT,PET 圖像判斷是否發生非小細胞肺癌EGFR 基因突變,從而幫助患者進行EGFR 靶向治療,展示了其輔助臨床決策的潛力。
醫學圖像并不像普通圖像那樣包含大量場景,所以高級語義特征(如病灶區的形狀、輪廓)以及低級語義特征(如病灶區的邊緣、紋理)都很重要。后續的研究中,會繼續關注跟隨對比學習圖像分類方面的最新進展,探究AUC 更高的醫學圖像分類方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫苑(2023年2期)2023-03-15 09:03:04
中國臨床醫學影像雜志(2022年2期)2022-05-25 13:24:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
癌變·畸變·突變(2016年3期)2016-02-27 06:15:34
核科學與工程(2015年4期)2015-09-26 11:59:03
醫學研究雜志(2015年12期)2015-06-10 06:57:46
鄭州大學學報(醫學版)(2015年1期)2015-02-27 14:50:26
