車牌識別系統的關鍵技術分析
2022-06-21 11:27:48李宏偉羅自航張賀磊
物聯網技術 2022年6期
關鍵詞:檢測
李宏偉,羅自航,張賀磊
(1.漯河職業技術學院,河南 漯河 462000;2.鄭州工業技師學院,河南 鄭州 450007;3.鄭州航空工業管理學院,河南 鄭州 450046)
0 引 言
近些年,隨著國家經濟和科技的飛速發展,人們的生活也隨之發生了巨大的變化。據有關部門統計,截至2020年6月,國內汽車保有量2.7億輛。如此龐大的數字給交通管理部門的運行管理帶來了很大的壓力。智能交通系統(ITS)自被提出以來,利用人工智能領域的數字圖像處理技術和圖像處理算法對汽車車牌進行自動識別,不斷提升智能交通系統的運行效率,具有非常重要的理論價值和現實應用意義。車牌識別技術屬于該領域的問題分支,車牌識別系統在人們的周圍有著廣泛的應用場景,例如:公共設施停車場管理、小區門禁系統、公司學校單位門禁等。
1 車牌識別的關鍵步驟
通過對我國車牌圖像進行收集分析,車牌上的字符有著如下特點:車牌的第一個字符通常為漢字,一般是該車所在地省份或者直轄市的簡稱;車牌的第二個字符通常是一個大寫字母,代表該車所在地所處省份的某一個地級市;第三個字符到第七個字符,一般情況下為字母或者數字的組合。對于車牌的顏色而言,不同的背景色往往代表著不同的含義,車牌背景為黃色一般代表大車,車牌背景顏色為藍色一般代表小車,車牌背景為黑色一般代表外資企業或者大使館使用的專用車輛,軍用車牌一般以白色為背景,字體顏色為紅色。
本文研究討論的車牌針對的對象是民用一般車輛,其背景顏色為藍色,字符顏色為白色。利用數字圖像進行車牌識別的流程如圖1所示。
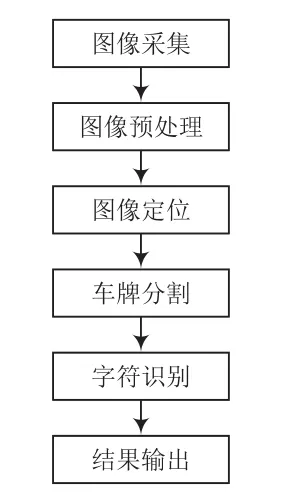
圖1 車牌識別流程
2 車牌識別過程的關鍵技術介紹
2.1 圖像采集模塊
該模塊的硬件部分主要包含高性能攝像機、高性能PC機、圖像采集卡和照明設備等。很多地方的停車場車牌管理系統主要由車輛傳感探測器、高性能計算機、高性能攝像機和視頻采集卡等組成。硬件設備的作用在于對車輛靠近、通過、停留及離開進行輔助判斷。
2.2 圖像預處理模塊
圖像采集模塊在采集圖像的過程中不可避免地會受到實際拍照環境的影響,例如光線的強弱、車牌的干凈程度、天氣等因素,都會對最后形成的圖像質感造成一定的影響。通過圖像預處理,提高圖像的有效性,使圖像中的有用信息更加容易檢測,顯著降低圖像中的噪聲干擾。處理主要包括以下幾個方面:
(1)圖像的灰度化處理。在計算機系統中,比較常用的顏色空間有RGB、YUV、CMY、HSI,不同的色彩空間只是同一種物理量的不同表示。圖像的灰度化主要是將采集的彩色圖像變成灰度圖像,減少數字圖像處理的數據量。攝像頭采集的圖像通常是RGB顏色空間下的圖像,R代表紅色,G代表綠色,B代表藍色。可以得到下式:
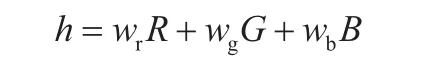
式中:代表最后計算產生的灰度值;、、代表不同的權重。
(2)圖像的增強處理。圖像增強的主要作用是有效提升圖像的質量與辨識度,使圖像的后續處理變得更加容易。空域增強與頻域增強是經常使用的增強技術。直接對圖像中任意像素的灰度值進行計算處理,這時圖像中的明暗對比度也會隨之變化,該方法稱為空域增強技術。空域增強技術經常使用的方法包括灰度變換增強、直方圖增強與空域濾波等。頻域增強技術先對需要處理的圖像進行傅里葉變換,將圖像從空間域變換為頻率域,之后在頻率域中對圖像進行計算處理,處理結束后再通過傅里葉反變換將圖像從頻域轉換到空間域。低通濾波、高通濾波和同態濾波是頻率域增強技術中常用的3種方法。
(3)圖像的邊緣檢測處理。邊緣檢測的原理:根據圖像的差異性進行檢測,從而有效檢測出所需圖像中的有效區域。常見的邊緣檢測算法比較多,檢測效果相對比較好。微分算子、Canny算子與LOG算子是常用的邊緣檢測算法。
2.3 車牌定位模塊
車牌定位模塊主要利用高性能計算機上的軟件算法實現,該部分主要利用數字圖像處理技術進行車牌位置的定位識別。其可直接把圖像分割成目標圖像和背景圖像,去除背景中的干擾。通常情況下,把目標圖像設置為1,背景圖像設置為0,從而得到處理后的圖像。車牌定位識別的過程涉及形態學等學科。常用的形態學處理圖像的方法主要有膨脹處理、腐蝕處理、開運算處理與閉運算處理。車牌定位模塊流程如圖2所示。
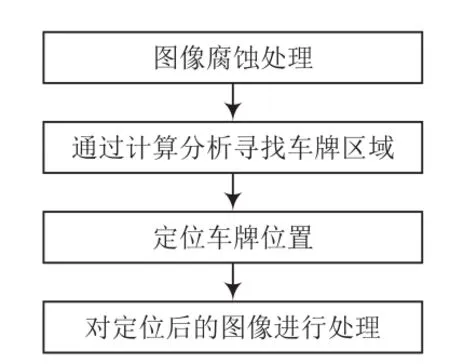
圖2 車牌定位模塊流程
2.4 字符分割模塊
車牌圖像的分割分為兩部分:首先在采集的圖像中檢測獲取僅含有車牌的圖像區域;其次是對只包含車牌的數字圖像進行處理,得到車牌中的單個字符;接下來對得到的每個字符進行識別分析。在字符分割模塊過程中,常采用基于投影信息、邊緣信息和輪廓信息提取字符的分割方法。本文采用垂直投影法進行圖像分割,其流程如圖3所示。

圖3 垂直投影法進行圖像分割流程
2.5 字符識別模塊
識別算法的理論基礎是模式識別,主要有以下幾種方法。
2.5.1 基于特征的字符識別方法
在對車牌拍照的過程中,往往容易受采集環境的影響,如車牌圖像的潔凈度、車牌字符是否有破損及變形等都會對車牌的采集結果造成影響。通過采集得到一個原始圖像,然后進行統計、分析、計算等處理。由此可以看出,統計識別過于依賴采集過程中的原始圖像完整性,采用這種方法得到較高的準確率比較困難,因此車牌識別很少采用這種方法。
2.5.2 基于神經網絡的字符識別
在模式識別過程中,利用神經網絡處理一些實際分類模型問題有著不俗的表現,它具備較強的自適應性與較強的學習能力,對于復雜、推理不清晰的問題模型適合采用這種方法。
2.5.3 基于模板匹配的字符識別
利用模板匹配算法進行字符識別相對比較簡單,計算量較小,運行效率較高。本文采用這種算法進行字符識別,步驟如下:
(1)使需要識別的測試樣本與訓練測試樣本的大小保持一致;
(2)將需要測試對象與訓練樣本庫中的對象進行對比分析;
(3)獲得相似度最高的字符識別結果。
3 實驗結果
利用MATLAB 2016a運行本文算法。采用50張不同場景、不同地區、不同型號的車牌圖片進行驗證,發現能夠正確識別的圖片有41張,識別正確率達82%,證明文中算法可以實現較為準確的車牌識別。車牌識別過程圖片如圖4~圖9所示。

圖4 原始圖片

圖5 Radon傾斜校正
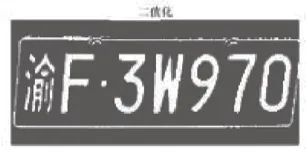
圖6 二值化處理

圖7 字符分割投影統計

圖8 字符分割

圖9 識別結果
4 結 語
從仿真實驗結果中可以看出,文中算法的識別正確率為82%,可以較為準確地識別汽車車牌,具有一定的理論學習和實際運用參考價值。但文中的算法在準確率方面會受車牌遮擋、光照強度、相機與車牌距離、車牌傾斜等因素的影響,在今后的學習研究中需針對這些影響因素不斷改進算法。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
