融合字注釋的文本分類模型
2022-06-21 06:29:04楊先鳳趙家和李自強
計算機應用 2022年5期
楊先鳳,趙家和,李自強
(1.西南石油大學 計算機科學學院,成都 610500; 2.四川師范大學 影視與傳媒學院,成都 610066)(?通信作者電子郵箱565695835@qq.com)
融合字注釋的文本分類模型
楊先鳳1*,趙家和1,李自強2
(1.西南石油大學 計算機科學學院,成都 610500; 2.四川師范大學 影視與傳媒學院,成都 610066)(?通信作者電子郵箱565695835@qq.com)
針對傳統文本特征表示方法無法充分解決一詞多義的問題,構建了一種融合字注釋的文本分類模型。首先,借助現有中文字典,獲取文本由字上下文選取的字典注釋,并對其進行Transformer的雙向編碼器(BERT)編碼來生成注釋句向量;然后,將注釋句向量與字嵌入向量融合作為輸入層,并用來豐富輸入文本的特征信息;最后,通過雙向門控循環單元(BiGRU)學習文本的特征信息,并引入注意力機制突出關鍵特征向量。在公開數據集THUCNews和新浪微博情感分類數據集上進行的文本分類的實驗結果表明,融合BERT字注釋的文本分類模型相較未引入字注釋的文本分類模型在性能上有顯著提高,且在所有文本分類的實驗模型中,所提出的BERT字注釋_BiGRU_Attention模型有最高的精確率和召回率,能反映整體性能的F1-Score則分別高達98.16%和96.52%。
一詞多義;字注釋;基于Transformer的雙向編碼器;雙向門控循環單元;注意力機制;文本分類
0 引言
隨著中國互聯網行業的快速發展,根據第43次《中國互聯網發展趨勢報告》[1],截至2020年12月,中國互聯網用戶已達9.89億,互聯網普及率達70.4%。人們在網絡上隨時隨地獲取自己熱愛領域的優質文本信息,已經超越傳統紙質閱讀成為了新的閱讀熱潮。用戶日常面臨海量的文本信息,對文本信息進行文本分類能夠使得網絡運營商推送用戶感興趣的某些文本信息,同時提高用戶的閱讀體驗。如何對用戶感興趣的文本信息進行更加精準的分類,成為了當前自然語言處理(Natural Language Processing, NLP)領域下文本分類技術面臨的熱點問題。
文獻[2]中提出了基于卷積神經網絡(Convolutional Neural Network, CNN)的文本分類,句子的表示采用預訓練好的詞向量(Word Embedding)矩陣,利用多個不同的CNN卷積核提取輸入文本的不同特征,進一步證明了優化詞向量和特征提取能力可以提高文本分類準確度。文獻[3]中提出了一種基于多通道CNN模型,通過引入多通道分布式詞表示,獲取更多特征信息來改善文本分類效果。然而,CNN在處理文本時存在無法考慮語言結構的問題,忽略了詞語之間的依存關系。文獻[4]中提出了一種基于循環神經網絡(Recurrent Neural Network, RNN)的多任務學習的文本分類模型,利用RNN具有“記憶”功能來捕獲序列之間的依賴關系。文獻[5]中引入了雙向RNN(Bidirectional RNN, BiRNN)進行手寫文本分類,BiRNN將序列的正向信息和逆向信息結合訓練網絡。文獻[6]中利用長短期記憶(Long Short?Term Memory, LSTM)網絡進行短文分類,避免了傳統循環神經網絡的梯度爆炸、梯度消失和長期依賴等問題;但是LSTM模型參數過多,模型較復雜。文獻[7]中提出了門控循環單元(Gated Recurrent Unit, GRU)網絡對LSTM進行部分修改,模型更簡單,在保證擁有LSTM功能的同時提升了訓練效率。
文獻[8]中提出了詞的分布式表示,通過一種較低維度的稠密向量表示,將詞信息分布式地表示在稠密向量的不同維度上,具備一定的語義表示能力。文獻[9]中提出了Word2Vector詞向量訓練工具,為了學習更具意義的詞向量,包括了CBOW(Continuous Bag-of-Words)和Skip-Gram兩種不同訓練模型。CBOW模型思想通過前后單詞預測當前單詞,而Skip-Gram思想是通過當前單詞預測其前后單詞。Word2Vector訓練出的詞向量是唯一不變的,無法解決一詞多義的問題。文獻[10]中提出了Doc2Vector模型,目的是為了保存句子上下文信息,解決詞序和語義問題,可將任意長度句子表示為固定長度的句向量。文獻[11]中提出了ELMo(Embeddings from Language Models),基于動態詞向量的思想,通過語言模型得到詞的單一表示后根據上下文語境不同再調整詞向量,從而使在不同語境下的詞向量表示不同。文獻[12]中提出了基于多層Transformer[13]的雙向編碼器(Bidirectional Encoder Representations from Transformers, BERT),通過大量語料訓練,考慮詞語在不同上下文的表達應該不同,形成融合位置信息和上下文信息的動態詞向量,并可通過訓練好的BERT模型獲取指定句子的句向量,該句向量能夠較充分地表示句子意思。
上述方法對文本分類作出的貢獻主要在優化詞向量和特征提取部分,但是在這兩部分還存在更多的提升空間需要去研究。為了更加準確地進行文本分類,需要設計出更加完善的文本表示方法以及充分的特征提取網絡。針對以上問題,本文提出了一種融合BERT字注釋的文本分類模型。在文本表示部分,由于字典和詞典中往往包含這一個字或詞的各種注釋信息,這些注釋能夠非常準確地描述這個字詞,BERT可以將注釋信息轉換為句向量,將注釋句向量和字嵌入向量拼接作為該字基于上下文的文本表示,解決一詞多義問題。在特征提取部分,使用雙向GRU(Bidirectional GRU, BiGRU)網絡提取文本雙向特征,在BiGRU網絡后引入注意力(Attention)機制[14],計算注意力概率分布,獲得具有重要性分布的特征表示,增強特征提取能力。
1 相關工作
1.1 文本分類
文本分類是自然語言處理的一個重要分支,目的是將給定文本歸類為預設定的類別。文本分類應用廣泛,包含新聞分類、情感識別和垃圾郵件過濾等。隨著大數據和人工智能時代的到來,文本分類的研究由傳統的基于規則匹配方法轉向機器學習特別是深度學習方法。傳統的機器學習算法如K近鄰(K-Nearest Neighbor, KNN)[15]、支持向量機(Support Vector Machine, SVM)[16]和樸素貝葉斯(Naive Bayesian, NB)[17]等在進行文本分類時通常存在無法學習較深的文本語義、準確率較低和數據稀疏等問題。
基于深度學習的文本分類方法能夠通過神經網絡去提取更多的文本特征,進行自動分類。這類方法通常分為兩個主要步驟:一是將輸入文本表示為合適的向量矩陣;二是選擇合適的神經網絡,如采用CNN、RNN來提取文本特征信息完成文本分類。本文選用BiGRU結合Attention機制來提取文本特征信息。
1.2 BERT模型
文本表示是自然語言處理中的基礎工作,將詞表示成固定長度的稠密向量稱為詞向量,又叫詞嵌入(Word Embedding)。詞向量大幅度提升了神經網絡處理文本數據的能力。文本表示的好壞直接影響到下游網絡進行文本分類的效果。本文使用BERT模型對字典注釋信息編碼,獲取句級別的注釋向量。

圖1 BERT模型結構Fig. 1 Structure of BERT model
Transformer是一個Encoder-Decoder結構,由多個編碼器和多個解碼器堆疊構成。BERT模型中只采用了Transformer的Encoder部分,其結構如圖2所示。編碼器由多頭自注意力機制(Multi-Head Self-Attention)、殘差網絡和前饋網絡組成,可將輸入信息轉化成特征向量。
1.3 GRU網絡
GRU是對LSTM的一種效果很好的變體,GRU將LSTM的忘記門和輸入門合成了一個單一的更新門,同樣還混合了細胞狀態和隱藏狀態以及其他一些改動,它比LSTM結構更簡單,參數更少,收斂性更好,而且很好地解決了RNN中的長依賴問題。GRU由更新門和重置門構成,具體結構如圖3所示。

圖2 Transformer Encoder結構Fig. 2 Structure of Transformer Encoder

圖3 GRU結構Fig. 3 GRU structure
重置門用來控制前一狀態有多少信息被寫入到當前的候選集上,重置門越小,前一狀態的信息被寫入得越少。更新門用來控制前一時刻的狀態信息引入到當前狀態的程度,更新門的值越大,前一時刻的狀態信息被引入得越多。GRU模型的更新方式如式(1)~(4)所示:
1.4 Attention機制
Attention機制使網絡模型對少量重要信息重點關注學習,關注學習表現為權重系數的計算,權重越大表示對應的特征信息重要程度越大。Attention機制被廣泛應用于機器翻譯、語音識別、詞性標注等領域,且表現較優。
2 網絡模型
本文提出了一種融合BERT字注釋、雙向GRU和注意力機制的文本分類模型,其模型結構如圖4所示。
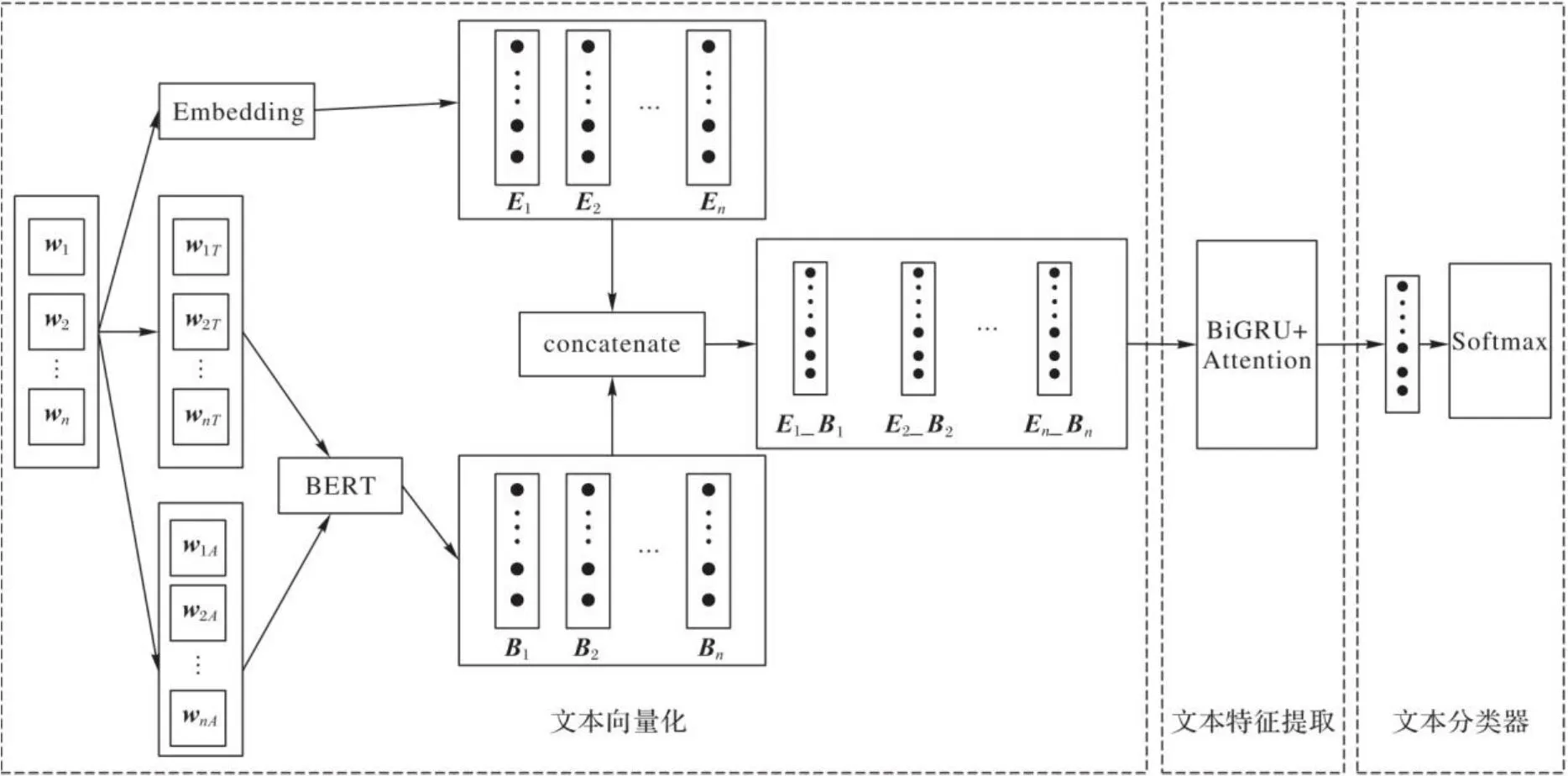
圖4 本文模型結構Fig. 4 Proposed model structure
本文模型由文本向量化、文本特征提取和文本分類器三部分組成。文本向量化的目的是將輸入文本轉為向量矩陣,向量矩陣由字嵌入和BERT對字注釋編碼拼接所得。文本特征提取部分采取BiGRU網絡提取文本篇章語義信息,Attention機制對BiGRU輸出特征計算序列的重要性分布,輸出包含注意力概率分布的文本特征表示。文本分類器部分采用Dropout方法[18]防止過擬合,通過Softmax分類器得出文本不同類別概率,達到了預測文本類別的效果。
2.1 文本向量化
文本向量化是將文本轉化為向量形式表示,所表示的向量可以體現文本的特征信息,本文提出了將字嵌入和注釋向量拼接作為文本向量化方式。
2.1.1 字嵌入
2.1.2 注釋向量
BERT模型對輸入文本編碼可以得到兩部分向量:一部分是字符級別的向量,即輸入文本的每個字符對應的向量表示;另一部分是句向量,即BERT模型輸出的最左邊[CLS]符號的向量,BERT模型認為[CLS]向量可以代表整個句子的語義。BERT的輸出如圖5所示。
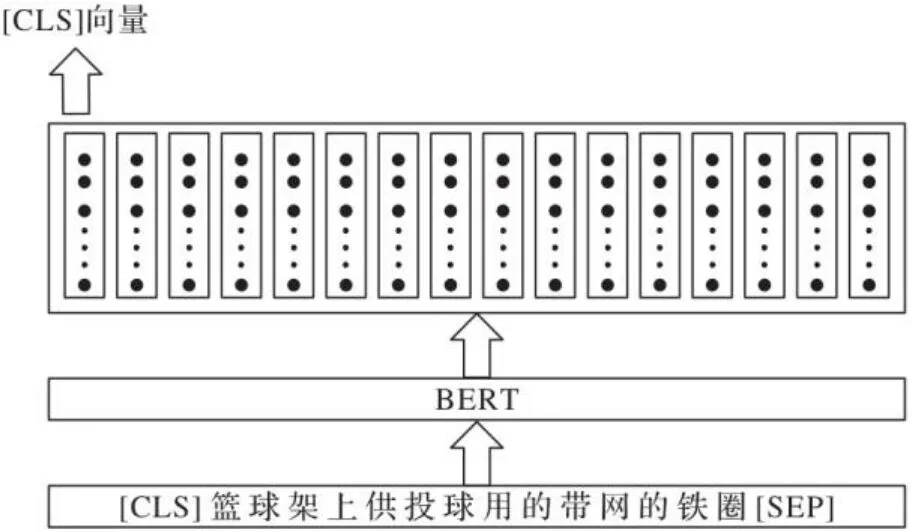
圖5 BERT模型的輸出Fig. 5 Output of BERT model
注釋是對一個字所表達含義的解釋,一個字或詞在不同語境下具有不同的意思。本文選擇通過BERT模型對語料庫所有字注釋信息進行編碼,獲得句子級別的向量(句向量)。一個字有多條注釋,一條注釋對應一個句向量。為了對輸入語句中每個字選擇出符合語境的注釋句向量,還需要通過BERT對每個字結合上下文編碼后得到語境句向量,注釋句向量的選擇方法通過余弦相似度(Cosine Similarity)計算不同注釋句向量與語境句向量的相似度,相似度最高的注釋向量即為當前字對應的注釋信息。
假設輸入句子中第i個字有k條注釋,BERT對k條注釋進行句向量編碼得到k*m的矩陣A,BERT對的上下文進行句向量編碼得到1*m的向量t,則在當前語境下對應的注釋是t和A的k條向量計算余弦相似度的最大值。
2.1.3 融合注釋向量
在訓練過程中,本文模型的字嵌入矩陣和其他模型參數會進行更新,以達到最佳分類效果。
2.2 文本特征提取
本文使用BiGRU網絡提取文本向量化后的特征信息,并引入注意力機制計算特征向量的注意力概率分布。
循環神經網絡是具有記憶功能的網絡,可以發現樣本之間的序列關系,是處理序列樣本的首選模型。BiGRU是雙向門控循環單元,由于單向GRU只能依據之前時刻的時序信息來預測下一時刻的輸出,在語言類任務中,下一時刻的輸出由之前狀態和未來狀態共同預測得到顯得尤為重要。而BiGRU增加反向時序信息傳遞,對于每一時刻,輸入會同時提供給兩個方向相反的GRU,輸出由這兩個單向GRU共同決定。BiGRU相較單向GRU能夠學習到雙向長期依賴關系,提取特征更豐富,且實驗結果表明BiGRU的表現優于單向GRU。BiGRU的結構如圖6所示。
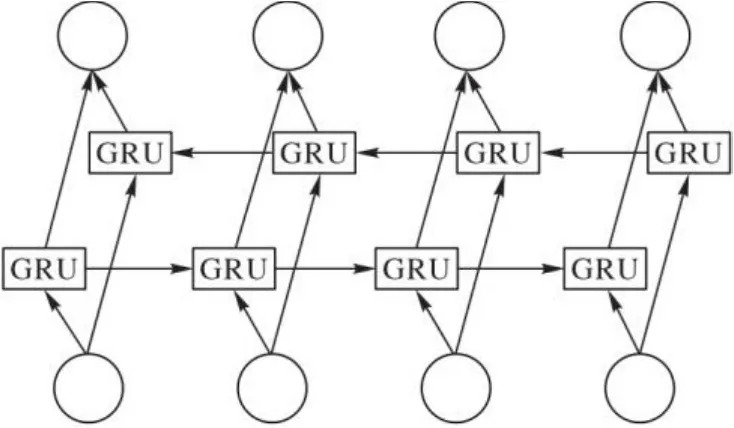
圖6 BiGRU結構Fig. 6 BiGRU structure
本文在BiGRU模塊之后引入注意力機制,可以生成含有注意力概率分布的文本語義特征表示,突出重要特征信息對文本分類結果的影響,改善模型分類效果。注意力機制中文本特征向量的計算過程如式(8)~(10)所示:
2.3 文本分類器
本文引入Dropout方法防止過擬合,采用Softmax回歸模型對Dropout后文本特征進行多分類。預測文本類別的計算如式(11)~(12)所示:
通過全連接網絡將特征向量映射到N維向量上,其中N為類別個數,并對其通過Softmax計算得到在每個類別上的概率值,是概率值最高的類。
2.4 文本分類算法
本文提出了融合字注釋模型分類算法,具體步驟如下:
算法1 融合字注釋模型分類算法。
步驟2 對輸入中每個字通過固定滑動窗口獲取充分體現每個字漢語意思部分的上下文,并對其進行BERT編碼獲得句向量,通過新華字典,對輸入每個字的注釋信息BERT編碼獲得句向量,求與矩陣中余弦相似度最高的句向量作為該字的注釋信息。
步驟3 輸入每個字的字向量和BERT注釋向量拼接得到E_B,將其作為文本向量化結果。
步驟4 將E_B輸入BiGRU網絡,再接Attention網絡,提取帶注意力值的特征向量。
步驟5 將步驟4得到的特征向量經Dropout后輸入Softmax分類器進行分類訓練,輸出文本分類模型。
3 實驗與結果分析
3.1 實驗數據集
本文選擇在以下兩個數據集上做對比實驗。
數據集1是由清華自然語言處理實驗室提供的THUCNews新聞文本分類的數據集。THUCNews是根據新浪新聞RSS訂閱頻道2005—2011年間的歷史數據篩選過濾生成。從THUCNews中抽取了80 000條新聞數據,數據類別為體育、財經、房產、家居、教育、科技、時尚、時政、游戲、娛樂,各8 000條,訓練集、測試集和驗證集的樣本數比例為6∶1∶1,其中,訓練集總樣本數為60 000條,測試集和驗證集的總樣本數均為10 000條。
數據集2是新浪微博情感分類數據集,從中隨機抽取正負樣本數各6 000條。將這12 000條數據作為實驗數據集,數據類別分為正向情感和反向情感兩類,各6 000條,訓練集、測試集和驗證集的樣本數比例為4∶1∶1。
3.2 評估指標
本文對所有實驗模型的分類性能評價指標選擇采用精確率(Precision)、召回率(Recall)和F1分數(F1-Score)。
精確率的計算如式(14)所示:
召回率的計算如式(15)所示:
F1分數綜合了精確率和召回率,是反映整體的指標,F1分數越高說明實驗方法越有效。F1分數的計算如式(16)所示:
其中:TP(True Positive)表示真正例;FP(False Positive)表示假正例;FN(False Negative)表示假負例;TN(True Negative)表示正負例。
3.3 實驗設置
為了驗證將注釋信息融入文本向量化階段的有效性和BERT字注釋_BiGRU_Attention模型在擁有更優的特征提取能力后的分類效果更好,本文選擇了在THUCNews數據集上使用多個目前在中文文本分類任務上應用廣泛且效果較好的網絡結構以及引入BERT字注釋網絡結構作為baseline模型進行對比實驗。用于對比的模型包括:TextCNN、LSTM、BiGRU、Word2Vec_TextCNN、Word2Vec_LSTM、Word2Vec_BiGRU、BERT字注釋_TextCNN、BERT字注釋_LSTM、BERT字注釋_BiGRU。
根據BERT字注釋_BiGRU_Attention對兩個數據集分類的F1分數和模型損失值對模型參數進行調整,主要是Embedding維度和BiGRU節點數,經多次實驗后模型參數設置如表1所示。
3.4 結果分析
在數據集1上進行對比的實驗結果如表2所示,可以看出使用了BERT字注釋的網絡結構的F1分數均高于字嵌入網絡結構和Word2Vec網絡結構。由此可知,在文本表示階段引入BERT字注釋后,同一個字在不同語境下文本向量化結果不同,相較于Word2Vec和字嵌入形成的靜態字向量,對語義消歧有一定的幫助,BERT字注釋和字嵌入拼接豐富了文本特征信息,增加的BERT字注釋特征信息對后續網絡進行文本分類產生積極影響。
通過表2還可以看出,使用了BiGRU網絡結構的F1分數相較TextCNN和LSTM網絡結構分別提高了1.16個百分點和3.62個百分點。在融入BERT字注釋,豐富輸入特征后,BiGRU的優勢更能體現出來,BERT字注釋_BiGRU的F1分數相較BERT字注釋_TextCNN提高了2.48個百分點,表明BiGRU網絡通過提取雙向時序特征信息,有效學習到了長文本中的長期依賴關系,使分類效果得到顯著提升。與BERT字注釋_BiGRU網絡相比,本文提出的引入Attention機制后的BERT字注釋_BiGRU_Attention網絡,通過Attention機制對BiGRU提取的不同特征信息進行權重分配,在增強特征提取能力的同時進一步提高了文本分類的F1分數,其F1分數達到了98.16%。

表1 模型參數Tab. 1 Model parameters

表2 數據集1上各模型的指標對比Tab. 2 Indicator comparison of different models on dataset 1
在數據集2上進行對比實驗的結果如表3所示,融入字注釋信息的模型在短文本的情感分類任務上是可行的,融入字注釋信息對TextCNN網絡的性能提升相對較多。BERT字注釋_BiGRU_Attention仍然可以取得最高的F1分數,達到了96.52%,但是在短文本情感分類數據集上,模型性能提升效果并不是很好。
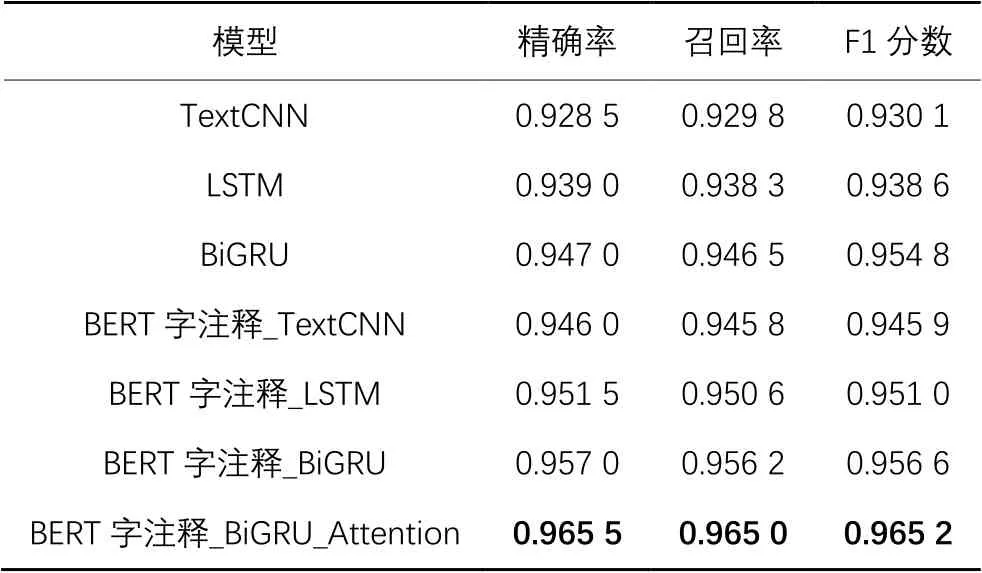
表3 數據集2上各模型指標對比Tab. 3 Indicator comparison of different models on dataset 2
由表3還可以看出,在面對序列數據時,循環網絡能夠展現出自己的優勢,配合Attention機制后F1分數有所提高。
綜上,將字典信息融合進文本表示是可行的,BERT對字注釋編碼后拼接字嵌入作為文本表示,特征提取采用BiGRU_Attention的網絡結構能夠在文本分類任務上取得較優的表現。
4 結語
本文借助中文字典,提出了通過BERT預訓練模型對字典中注釋信息編碼,并將符合語境的注釋編碼和字嵌入拼接作為文本表示,豐富了文本特征信息,對語義消歧有一定的幫助。實驗結果表明,融合字注釋模型在新聞文本分類和情感分類任務上相較傳統網絡LSTM和TextCNN的分類效果有顯著提升,同時融合BERT字注釋的BiGRU_Attention網絡面對時序數據時,特征提取能力表現較優,相應的分類效果也更好。下一步將針對精確分詞后優化文本表示,整合字典注釋和詞典注釋,以及注釋如何更好地融合模型發揮更強大的作用,進一步優化神經網絡結構,使之在面對自然語言處理領域的任務時性能更優。
[1] 中國互聯網信息中心.第47次《中國互聯網發展狀況統計報告》[R/OL].[2021-02-03].http://cnnic.cn/hlwfzyj/hlwxzbg/hlwtjbg/202102/P020210203334633480104.pdf.(China Internet Network Information Center. The 47th China Statistical Report on Internet Development [R/OL]. [2021-02-03]. http://cnnic.cn/hlwfzyj/hlwxzbg/hlwtjbg/202102/P020210203334633480104.pdf.)
[2] KIM Y. Convolutional neural networks for sentence classification [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL,2014: 1746-1751.
[3] HASHIDA S, TAMURA K, SAKAI T. Classifying tweets using convolutional neural networks with multi-channel distributed representation [J]. IAENG International Journal of Computer Science, 2019, 46(1): 68-75.
[4] LIU P F, QIU X P, HUANG X J. Recurrent neural network for text classification with multi-task learning [C]// Proceedings of the 2016 25th International Joint Conference on Artificial Intelligence. California: IJCAI Organization, 2016: 2873-2879.
[5] PHAN T van, NAKAGAWA M. Text/non-text classification in online handwritten documents with recurrent neural networks [C]// Proceedings of the 2014 14th International Conference on Frontiers in Handwriting Recognition. Piscataway: IEEE, 2014: 23-28.
[6] NOWAK J, TASPINAR A, SCHERER R. LSTM recurrent neural networks for short text and sentiment classification [C]// Proceedings of the 2017 International Conference on Artificial Intelligence and Soft Computing, LNCS 10246. Cham: Springer, 2017: 553-562.
[7] CHO K, VAN MERRI?NBOER B , GU?L?EHRE ?, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: ACL, 2014: 1724-1734.
[8] HINTON G E. Learning distributed representations of concepts [M]// MORRIS R G M. Parallel Distributed Processing: Implications for Psychology and Neurobiology. Oxford: Clarendon Press, 1989: 46-61.
[9] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL]. [2021-02-21]. https://arxiv.org/pdf/1301.3781.pdf.
[10] LE Q, MIKOLOV T. Distributed representations of sentences and documents [C]// Proceedings of the 2014 31st International Conference on Machine Learning. New York: JMLR.org, 2014: 1188-1196.
[11] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg: ACL, 2018:2227-2237.
[12] DEVLIN J, CHANG M W, LEE K, et al. BERT:pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg: ACL, 2019:4171-4186.
[13] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 2017 31st International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2017: 6000-6010.
[14] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Proceedings of the 2014 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014:3104-3112.
[15] BILAL M, ISRAR H, SHAHID M, et al. Sentiment classification of Roman-Urdu opinions using Na?ve Bayesian, decision tree and KNN classification techniques [J]. Journal of King Saud University — Computer and Information Sciences, 2016, 28(3): 330-344.
[16] SUN A X, LIM E P, LIU Y. On strategies for imbalanced text classification using SVM: a comparative study [J]. Decision Support Systems, 2009, 48(1): 191-201.
[17] JIANG L X, LI C Q, WANG S S, et al. Deep feature weighting for naive Bayes and its application to text classification [J]. Engineering Applications of Artificial Intelligence, 2016, 52:26-39.
[18] HINTON G E, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors [EB/OL]. [2021-02-21]. https://arxiv.org/pdf/1207. 0580.pdf.
Text classification model combining word annotations
YANG Xianfeng1*, ZHAO Jiahe1, LI Ziqiang2
(1.School of Computer Science,Southwest Petroleum University,Chengdu Sichuan610500,China;2.College of Movie and Media,Sichuan Normal University,Chengdu Sichuan610066,China)
The traditional text feature representation method cannot fully solve the polysemy problem of word. In order to solve the problem, a new text classification model combining word annotations was proposed. Firstly, by using the existing Chinese dictionary, the dictionary annotations of the text selected by the word context were obtained, and the Bidirectional Encoder Representations from Transformers (BERT) encoding was performed on them to generate the annotated sentence vectors. Then, the annotated sentence vectors were integrated with the word embedding vectors as the input layer to enrich the characteristic information of the input text. Finally, the Bidirectional Gated Recurrent Unit (BiGRU) was used to learn the characteristic information of the input text, and the attention mechanism was introduced to highlight the key feature vectors. Experimental results of text classification on public THUCNews dataset and Sina weibo sentiment classification dataset show that, the text classification models combining BERT word annotations have significantly improved performance compared to the text classification models without combining word annotations, the proposed BERT word annotation _BiGRU_Attention model has the highest precision and recall in all the experimental models for text classification, and has the F1-Score of reflecting the overall performance up to 98.16% and 96.52% respectively.
polysemy; word annotation; Bidirectional Encoder Representations from Transformers (BERT); Bidirectional Gated Recurrent Unit (BiGRU); attention mechanism; text classification
TP183;TP391.1
A
1001-9081(2022)05-1317-07
10.11772/j.issn.1001-9081.2021030489
2021?03?31;
2021?07?08;
2021?07?21。
國家自然科學基金資助項目(61802321);四川省科技廳重點研發計劃項目(2020YFN0019)。
楊先鳳(1974—),女,四川南部人,教授,碩士,主要研究方向:計算機圖像處理、智慧教育; 趙家和(1997—),男,陜西渭南人,碩士研究生,主要研究方向:自然語言處理; 李自強(1970—),四川青神人,教授,博士,CCF會員,主要研究方向:機器學習、智慧教育。
This work is partially supported by National Natural Science Foundation of China (61802321), Key Research and Development Program of Science and Technology Department of Sichuan Province (2020YFN0019).
YANG Xianfeng, born in 1974, M. S., professor. Her research interests include computer image processing, wisdom education.
ZHAO Jiahe, born in 1997, M. S. candidate. His research interests include natural language processing.
LI Ziqiang, born in 1970, Ph. D., professor. His research interests include machine learning, wisdom education.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
