超大型三維場景分布式渲染系統體系結構與技術研究
2022-06-21 04:19:20李昆昆于春雨盧石磊李文博
科技創新與應用 2022年17期
郭 陽,李昆昆,于春雨,盧石磊,李文博,劉 甜
(青島理工大學 復雜網絡與可視化研究所,山東 青島 266520)
分布式渲染是將分布式計算和實時渲染結合,實現大體量模型的繪制與渲染,利用多GPU累積能力協同處理渲染任務,實現單PC機無法達到的快速繪制與渲染效果。實時渲染流程中最為關鍵的階段是幾何處理和光柵化。STEVEN和MICHAEL等[1]人針對三維模型實時繪制和渲染提出Sort分類策略,將分布式渲染分為了Sort-first、Sort-middle和Sort-last三種方式,Sort-first將圖元數據在幾何處理之前進行歸屬判斷,Sort-middle將圖元數據在幾何處理和光柵化之間進行歸屬判斷,Sort-last由于以無序狀態通過了幾何處理和光柵化,因此不再需要歸屬判斷,直接在顯示系統上進行圖像合成。
分布式渲染的實現取決于多渲染節點的系統構建,系統體系結構的設計將直接影響渲染效率[2]。本文設計一種新的體系結構實現超大型三維場景的Sortfirst和Sort-last分布式渲染。
1 傳統主從體系結構
傳統的分布式渲染系統體系結構為主從(Master-Slave)結構,其結構模型較為簡單,整個執行過程中任務量最大的繪制與渲染由從節點完成,并且根據任務量的需求大小或者用戶要求決定從節點的數量,實現系統的擴展性。主從結構的劣勢在于主節點職責過多,極易影響系統渲染效率;模型的計算渲染和圖像合成為串行關系,在從節點計算渲染時,主節點處于空閑狀態。
孫昭等[3]基于主從結構實現了一種按場景內容分布的渲染系統,Master節點負責系統的管理和用戶的交互結果顯示,Slave節點負責子場景的渲染,該方式提升了場景渲染的整體時間。彭敏峰[4]提出將多任務并行圖形繪制系統節點分為三類:負責幾何運算的應用節點、執行OpenGL指令的服務節點和負責與用戶交互的控制節點,該結構實現了多節點的并行計算和繪制,繪制結果可以多個屏幕顯示。湯敏[5]將分布式渲染的體系結構改進為Master-Slave-Collector,在主從結構中加入了Collector節點,通過添加任務池和結果池的方法實現系統的負載均衡。路石[6]在基于高性能并行可視化服務器上實現了多個系統內部節點,擴充了系統中的節點角色,使系統邏輯更加清晰,但容易造成多個節點之間數據的往復傳輸,從而增加由于網絡傳輸所帶來的時間消耗。
2 服務節點+主渲染節點+從渲染節點結構
2.1 系統節點角色
基于主從結構,為減少主節點的任務壓力,并且在從節點渲染時,主節點不處于空閑狀態,增加第三類系統角色,該角色承載主節點中的部分任務模塊,減輕主節點任務量。系統角色為:服務節點、主渲染節點和從渲染節點。服務節點任務包含:系統環境部署、任務計算;主渲染節點任務包含:主渲染循環維護、用戶交互和事件處理(根據渲染需求,判斷系統是否進行圖像合成);從渲染節點任務包含:被動渲染執行。
2.2 系統工作流程
本文設計的系統體系結構工作流程如下:渲染任務執行時由服務節點的環境資源部署開始,系統中的其他節點都會接收到來自服務節點的部署方案,此時實現所有節點角色的劃分。服務節點開始部署渲染任務,首先根據渲染節點數量分配任務量到其他節點中,各渲染節點接受命令加載場景并開始渲染。渲染節點的工作大致相同,經過清除、繪制、交換等,最后進行顯示。在此期間,主節點還會接收新的事件命令,并提交到服務節點,此時服務節點一并計算,進行新的任務劃分,開始下一幀的渲染循環。
2.3 并行機制
在渲染中引入并行機制,在不改變單幀串行關系的情況下,使得多幀的渲染實現并行處理,以此實現多節點的分布式任務處理,減少單節點的渲染計算量,還可以實現流水線加速效果。
當采用并行機制執行任務時,假設全部在理想情況下,任務分配、渲染執行、數據傳輸和圖像合成時間相等,忽略其他操作的時間,則理論上N幀的加速比可達到4N/(N+3)。在實際執行過程中,模型繪制與渲染和圖像合成的時間會遠遠大于圖像數據傳輸的時間,因此無法達到理想效果。并且當流水線內部包含的模塊操作越多時,其渲染執行和圖像合成的時間差越大,當從節點渲染第k幀時,此時的圖像合成顯示的是k-2幀,因此在負責圖像合成的主渲染節點中需進行緩存處理。
2.4 子任務劃分
在Sort-first渲染方式中,子任務根據屏幕2D圖像的物理位置進行劃分,因此子任務劃分可通過基于視錐體的圖元分割實現,通過視錐體計算可以得出裁剪掉外部圖元[7],還可以得到投影到二維屏幕上的矩陣。
首先選擇三維坐標系,采用OpenGL右手坐標系,X軸向前,Y軸向上,Z軸向右。以2個子視錐體為例,進行坐標和透視投影矩陣計算。視錐體切分如圖1所示。
通過設置視錐體的fovy、Width、Height、zNear、zFar參數可以得出視錐體中的l、r、t、b、n和這幾f個變量值,再推導出視錐體透視投影矩陣。得到透視投影矩陣之后,便可以根據用戶自定義屬性切分視錐體,得到若干個子視錐體和它們各自的透視投影矩陣。
在切分視錐體為2個子視錐體時,變換相應的變量便可獲得子視錐體的投影矩陣,例如當r=0時,即可得到左二分之一子視錐體;當l=0時,可得到右二分之一的子視錐體,當得到二分之一子視錐體后,重復上面的過程,可得到三分之一或四分之一視錐體,當賦值為0時為均分。
在分配渲染任務時,需根據模型變換和新事件處理對子任務不斷進行劃分,需進行負載均衡處理,通過在視錐體內部建立包圍盒的方式判斷子視錐體內部頂點的數量是否趨于平衡,若某個子視錐體存在的頂點過多,則重新分配,使子視錐體內部的頂點數量盡量保持一致,使渲染節點的任務量基本一致,渲染時間保持平衡。
3 實驗測試
實驗采用5臺PC機組成分布式渲染系統,其中服務節點和主渲染節點各1臺,從渲染節點3臺,因此可進行四分模型的渲染劃分。
3.1 模型用例
本文選取500米口徑球面射電望遠鏡(FAST)模型作為測試用例,課題組已完成FAST模型的建模工作[8-11],如圖2所示。
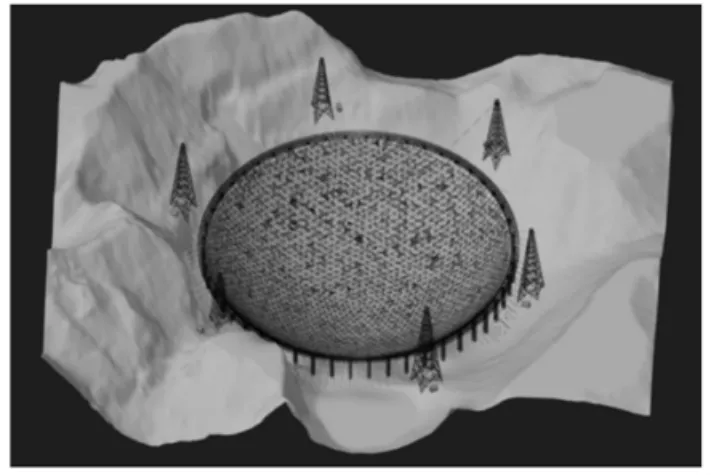
圖2 FAST模型
FAST各部件模型在經過整合并且添加上其他體量較小的模型之后,整體模型體量已超過千萬級,見表1。

表1 FAST整體模型體量
3.2 測試結果
實驗測試中采取兩種方式驗證本文設計的系統體系結構,一是Sort-first渲染及最終圖像不在主渲染節點合成的方式,該方式使用2.4節設計的劃分策略完成2D圖像分割;二是Sort-last渲染及最終圖像在主渲染節點合成的方式,該方式直接將模型數據范圍進行劃分,各渲染節點占據等比例的模型數據。
3.2.1 Sort-first圖像不合成方式
根據子任務劃分方式,進行視錐體的切分,將視錐體分為若干個不同的子視錐體,所有子視錐體渲染任務部署到不同的渲染節點中執行渲染操作。如圖3所示,主渲染節點和3個從渲染節點各占1/4的模型渲染任務,并通過視口的位置變換實現顯示拼接。
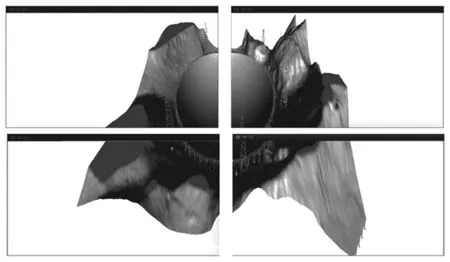
圖3 四分FAST模型圖像不合成
3.2.2 Sort-last圖像合成方式
在該渲染方式中,沒有進行基于視錐體的劃分,按照模型比例大小實現任務的分配,例如在四分模型中,將模型數據大小等分為4份,4個渲染節點各占1/4,并且由于Sort-last渲染實現的是模型的部分區域,無法進行顯示拼接,因此在主渲染節點進行圖像合成,在渲染窗口中直接輸出整體模型圖案,如圖4所示。

圖4 四分FAST模型圖像合成
3.3 結果分析
在渲染節點數量分別是1~4的情況下,采集執行1 000次渲染循環耗用的時間,其中包含圖像不合成和圖像合成兩種情況,如圖5所示。
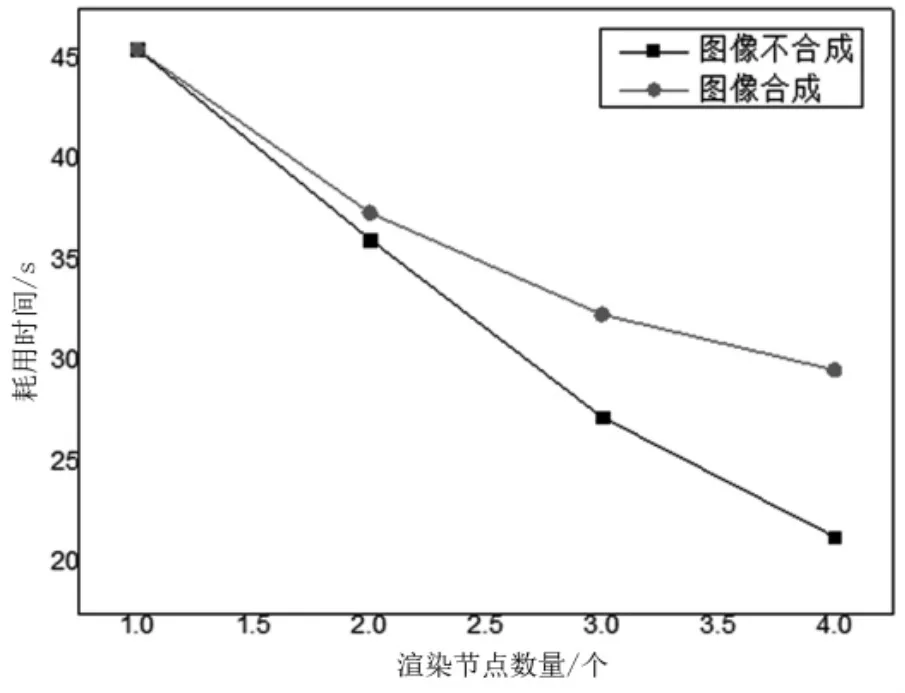
圖5 渲染耗時對比
當增加渲染節點時,1 000幀的渲染耗時持續減少,繪制和渲染流暢度逐漸提升。當增加到4個渲染節點時,其渲染幀率也從22 fps分別增加到了47 fps和33 fps,能夠滿足實時渲染要求,驗證了本文設計的分布式渲染系統體系結構的有效性。
在圖像的合成中,由于增加了圖像數據的傳輸和合成,因此在渲染耗時上,高于不合成的方式,并且在渲染節點逐漸增加的情況下,網絡傳輸和合成耗時逐漸增多。
4 結束語
本文提出一種基于服務節點+主渲染節點+從渲染節點的分布式渲染系統體系結構,將任務執行過程中與渲染工作無關的模塊分離到服務節點中,使其承擔系統管理工作,與渲染相關的模塊任務全部分配給渲染節點,并盡量使主節點與從節點的任務量趨于一致。以中國天眼FAST三維模型作為測試用例,測試結果表明,在保證實時渲染流暢度的前提下,本系統能夠有效減少三維模型的整體渲染時間,提高渲染效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
