地理標志農產品質量安全風險評估及預警研究
2022-06-28 02:55:48胡晨鈺
軟件導刊 2022年6期
張 彪,胡晨鈺,李 晶
(昆明理工大學管理與經濟學院,云南昆明 650500)
0 引言
中國作為一個農業大國,農業是國民經濟的根本,而“三農問題”一直是我國國民經濟發展所面臨的重要挑戰。2021 年是“十四五”開局之年,《2020 年農產品質量安全工作要點》中明確指出各企業要提升監管能力,完善質量監管體系,防范質量安全隱患,穩步提升農產品質量安全水平,做好農產品質量安全工作對于實施鄉村振興戰略具有特殊且重要的意義[1]。與一般的農產品相比,地理標志農產品在其原產地獨特的氣候和特殊的土壤條件等自然生態環境以及長期沉淀的歷史人文因素影響下,形成了自己獨特的品質和特征。然而,近些年來頻頻爆出地理標志農產品質量安全事故,如贛南臍橙染色事件、五常大米香精事件、金華火腿敵敵畏事件等讓人瞠目結舌[2]。這些事故足以表明當前我國在地理標志農產品質量安全方面存在著明顯問題,嚴重破壞了地理標志農產品的品牌效益與市場信譽,阻礙了農業的規模化與產業化發展。云南省作為地理標志農產品大省,截至2021 年,擁有地理標志農產品86 個[3]。因此,對地理標志農產品的質量安全風險進行評估與預警,對于降低農產品質量安全風險,保證品牌影響力具有重要意義。
很多學者在農產品質量安全相關理論與實踐方面進行了大量探索,尤其是在地理標志農產品品牌建設、農產品質量安全風險因素研究、農產品質量安全風險評估等方面取得了豐碩成果。學者們大多基于不同視角,采用不同方法展開研究。在農產品質量安全風險評估方法方面,可分為單一風險因子評估和多指標綜合評價[4]。在單一風險因子評估中,影響農產品質量安全的主要來源是化學性污染和生物性污染。齊艷麗等[5]對玉米及其秸稈中殘留的戊唑醇和吡唑醚菌酯進行風險評估,并針對玉米生產中農藥的安全使用提出建議;何祥祥等[6]通過評估草莓的革蘭氏陰性細菌、霉菌等微生物污染情況,為控制草莓微生物數量和開發殺菌抑菌技術提供了參考。但由于單一風險因子的評估因子較為單一且多用于化學、生物等自然科學領域,因此社會學科相關研究大多使用多指標綜合評價法。多指標綜合評價常用方法有:模糊評價法、Logistic 回歸模型、人工神經網絡法等。祁南南[7]建立了靜態模糊綜合評價模型來評估水果質量安全風險,雖能夠有效判斷水果的風險等級,但計算復雜,指標權重的確立缺乏依據;張東玲等[8]提出基于Logistic 回歸方程模型的農產品質量風險評估方法,并對風險進行了判別,但其可輸入的指標數量過少,很難擬合出數據的真實分布;陳婷婷[9]基于BP 神經網絡建立肉制品冷鏈物流質量風險評估模型,并對風險等級進行分類,但算法的學習速度較慢,且訓練精度較低。因此,本文擬采用的評估模型為RF-DBN 模型,主要原因有:①RF 因具有強大的特征抽取和表達能力,被廣泛用于高維、海量數據的降維處理,去除冗余特征,防止過擬合現象出現;②DBN 模型前期采用無監督學習,最后一層采用反向傳播神經網絡自頂向下有監督地微調整個模型,減少前向無監督學習的整體誤差,使網絡結構達到最優。通過樣本數據的輸入,不斷學習并改進網絡模型權值,能夠減少人為主觀性對結果造成的影響。
國內外學者在地理標志農產品品牌建設及發展相關理論與實踐方面取得了豐碩成果,但在地理標志農產品質量安全風險評估及預警方面的研究仍存在很大的提升空間,如構建系統性的質量安全風險指標,而非采用單一性評價指標等。鑒于此,本文以云南普洱茶為例,運用全面質量管理中“人、機、料、法、環”5 要素,建立地理標志農產品質量安全風險指標評估體系,再運用隨機森林模型對指標體系進行降維,最終構建云南省地理標志農產品質量安全風險評估及預警的RF 和DBN 模型,并進行實證研究。
1 地理標志農產品質量安全風險評價指標體系構建
1.1 評價依據及分析
全面質量管理是指一種以產品質量為核心,全員參與以實現對產品進行有效質量控制和質量改進的管理體系,其中“人、機、料、法、環”是全面質量管理理論中影響產品質量的主要因素。因此,本文擬從供應鏈角度出發,結合上述5 個因素對地理標志農產品在種植、加工、物流和銷售4個階段的質量安全風險因素進行分析,具體如下:
(1)種植階段質量安全風險。與一般農產品相比,地理標志農產品獨特的品質和特征大多來源于原產地特有的氣候與特殊的土壤條件。在種植階段,“人”的因素可分為種植人員的種植經驗和種植技能培訓水平,若種植人員缺乏種植知識及相關技能,則可能導致其在設備操作、病蟲害防治等對專業性要求較高的操作中出現問題,影響地理標志農產品質量安全;“機”的因素可分為農產品種植機械化水平和農產品質量檢測設備水平,種植機械化設備的缺乏將直接導致地理標志農產品生產效率低下,產量較低,質量水平參差不齊;“料”的因素主要包括地理標志農產品種苗選擇及農藥、化肥使用情況,不同品質的種苗會生長成不同質量的農產品,若濫用農藥和化肥,將會在農產品內部殘留有害物質,影響其質量安全;“法”的因素主要包括病蟲害防治方法和地理標志農產品采摘方法,不同方法也會導致不同的質量問題;“環”的因素包括地理標志農產品生長環境和灌溉水質,地理標志農產品的生長對種植環境和水質要求較高,這些都會對產品造成安全隱患。
(2)加工階段質量安全風險。對地理標志農產品采摘之后進行初加工,可增加其附加值,提升產品在市場上的競爭力和價格水平。在加工階段,“人”的因素主要包括工作人員從業資質和知識技能培訓水平,地理標志農產品獨特的加工工藝也是其具有特殊品質的原因之一,因此工作人員需要具有專業的加工知識和技能;“機”的因素主要包括加工機器自動化程度和加工成品檢測設備情況,在加工過程中,機器的自動化水平會直接影響產品的標準化,若使用劣質的加工設備和質量檢測設備,會導致加工工藝不完善,質量不合格;“料”的因素主要包括原材料新鮮程度和食品添加劑情況,在加工中使用變質的原材料或大量防腐劑和食品添加劑會影響農產品質量安全;“法”的因素主要包括地理標志農產品獨特的加工工藝和溫濕度控制技術;“環”的因素主要包括加工場所環境和倉庫環境,地理標志農產品對溫度、濕度的敏感度較高,過濕或溫度過高極易導致其發霉變質。此外,倉庫不衛生也會增加其質量安全隱患。
(3)物流階段質量安全風險。地理標志農產品在物流階段產生質量安全風險主要來源于運輸過程中的存儲問題和其包裝產生的安全隱患。“人”的因素主要為工作人員缺乏存儲經驗造成的質量安全隱患;“機”的因素主要為質量檢測設備情況,由于地理標志農產品具有保質期短、易變質的特點,若無法及時清理破損、變質的農產品,會威脅其質量安全;“料”的因素主要包括地理標志農產品最終銷售成品質量和農產品外部包裝材質質量;“法”的因素主要包括包裝技術和溫濕度控制技術,因包裝不當導致微生物含量超標等會造成安全隱患;“環”的因素主要包括倉庫存儲環境和運輸環境,嚴格監控物流階段的環境衛生情況可大幅降低農產品質量安全風險[4]。
(4)銷售階段質量安全風險。地理標志農產品不同于一般農產品具有流動銷售的特點,因此無法輕易辨別其質量,但與一般農產品類似,地理標志農產品具有易變質、難儲存的特點。因此,在銷售階段,“人”的因素主要為工作人員存儲經驗;“機”的因素為質量檢測設備情況,如果商品質量檢驗水平不高,難以剔除出已變質、損耗的產品,則會造成質量安全風險;“料”的因素主要為商品質量水平,需要從商品的源頭控制其質量安全風險;“法”的因素主要包括產品冷藏保鮮技術及商品標識與可追溯管理水平;“環”的因素主要包括倉庫存儲環境和銷售場所環境,需要從產品存儲到銷售環節都保證其質量安全。
為更清晰地描述“人、機、料、法、環”5 要素與種植、加工、物流、銷售4 階段之間的關系,系統化地繪制質量安全風險體系魚骨圖如圖1所示。

Fig.1 Quality and safety risk analysis fish bone map圖1 質量安全風險分析魚骨圖
1.2 質量安全風險評估指標收集
目前,關于農產品質量安全風險評估指標構建的研究成果豐富,本文的主要研究對象是地理標志農產品,其本身就屬于農產品范疇,因此在指標構建上可參考農產品質量安全相關文獻來確定。運用文獻收集法對農產品質量安全評估體系指標進行初步的收集與選取,查找國內外關于農產品質量安全評估體系的相關文獻,最后選取了10篇文獻資料,具體如表1所示。
1.3 質量安全風險評估指標體系構建
首先,采用文獻收集法對質量安全風險因素進行收集與歸納,建立質量安全風險評估體系;其次,運用專家打分法,邀請7 名質量風險管理領域的專家,對質量安全風險評估體系進行論證與篩選;最終,確定地理標志農產品質量安全風險評估體系,其中包含4 個二級指標,34 個三級指標,具體如表2所示。
2 地理標志農產品質量安全風險評估模型構建
2.1 隨機森林模型
2.1.1 模型簡介
隨機森林(Random Forests,RF)通常又稱為組合決策樹,其是通過集成學習思想將多個決策樹集成的一種算法,因其具有強大的特征抽取與表達能力,被廣泛用于高維、海量數據的降維處理。隨機森林的基本原理是從初始訓練集M 中隨機且有放回地抽取m 個訓練樣本,抽取出的每個訓練樣本便是一棵決策樹(弱分類器),m 個樣本便組成了隨機森林。

Table 1 Information on indicators of agricultural product quality and safety evaluation system表1 農產品質量安全評價體系指標資料

Table 2 Quality and safety risk assessment system表2 質量安全風險評估體系
2.1.2 模型構建
本文采用隨機森林模型對指標體系進行降維,對各個指標特征的重要性進行評估,計算隨機森林中每棵決策樹上的特征作了多少貢獻,依據特征重要性剔除相應比例的特征,選擇最優特征并對指標重要性進行排序,最終篩選出對結果影響較大的指標實現數據降維。本文采用隨機森林模型對影響地理標志農產品質量的安全風險因素重要性進行排序,篩選掉對地理標志農產品質量安全影響較小的指標因素。RF 結構如圖2所示。
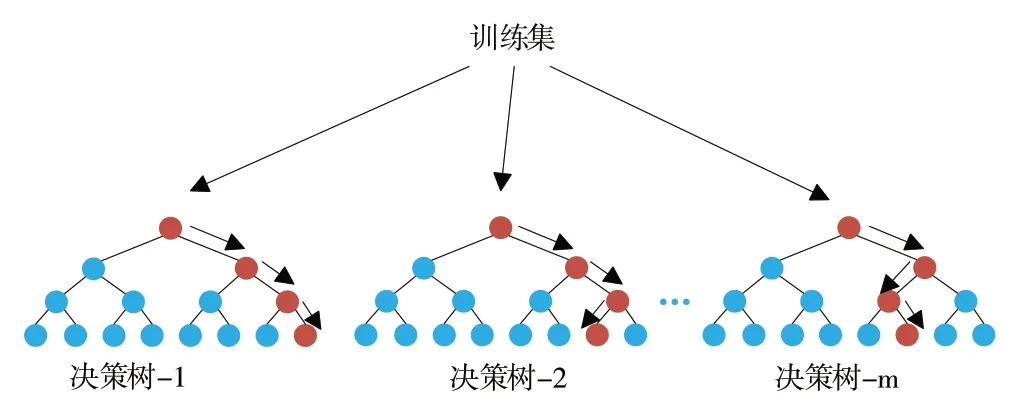
Fig.2 RF structure圖2 RF結構
2.2 深度置信網絡模型
2.2.1 模型簡介
深度置信網絡(Deep Belief Networks,DBN)是2006 年由“深度學習之父”Hinton 提出的深度學習模型,其是一個將概率統計學與機器學習及神經網絡相融合的概率生成模型。深度置信網絡是由若干個受限玻爾茲曼機(Re?stricted Boltzmann Machines,RBM)元件堆疊而成,通過不斷從底層特征中提取出抽象的高層特征后進行分類,具有良好的學習能力。單層RBM 是包含一層可視層v 和一層隱藏層h 的無向圖模型,且層內的單元之間不存在連接。RBM 結構如圖3所示。
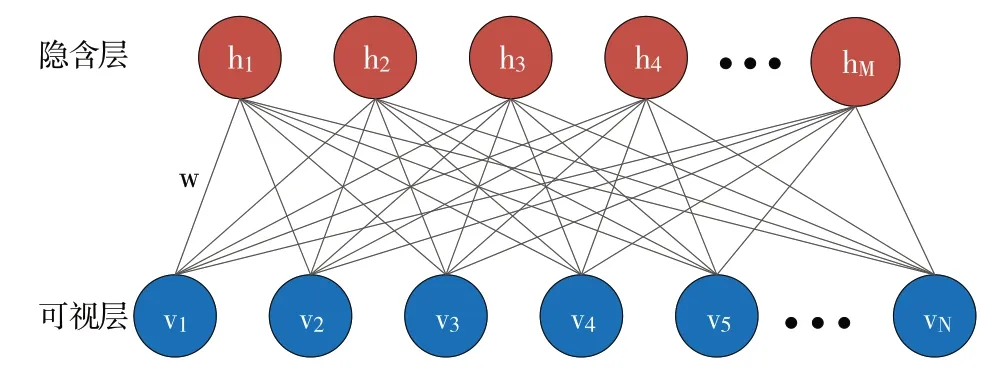
Fig.3 RBM structure圖3 RBM結構
首先,在RBM 訓練過程中,利用對比散度(Contrastive Divergence,CD)算法進行參數更新,使得訓練樣本的概率達到最大。每一層RBM 經過多次迭代訓練均得到初始化權值參數,形成無監督的DBN 網絡。然后,采用BP 算法將最后一層RBM 的輸出值作為輸入值,自頂向下有監督地微調整個模型,減少前向無監督學習的整體誤差,達到最優網絡結構。最后,將得到的特征矩陣輸入softmax 分類器中,利用隨機梯度下降(Stochastic Gradient Descent,SGD)算法對損失函數進行優化,最終達到分類的目的。
2.2.2 模型構建
本文將收集的數據集按照8∶2 的比例劃分為訓練集和測試集,利用訓練集訓練RBM 模型,確定模型初始權值,將最后一層RBM 的輸出值當作BP 神經網絡的輸入層,對模型進行有監督的調優。softmax 分類器在微調后對地理標志農產品的質量安全風險進行判別分類,并輸出風險等級。之后利用測試樣本集檢驗DBN 模型分類效果,并將此模型用于地理標志農產品質量安全風險分類與識別。DBN 模型結構如圖4所示。

Fig.4 DBN structure圖4 DBN結構
3 實證分析
3.1 數據收集
普洱茶作為云南省的地理標志農產品,在省內被普遍種植,尤其位于瀾滄江中下游地區的普洱市茶區、西雙版納茶區、臨滄茶區三大茶區更是貢獻了90%以上的普洱茶原料。本文為驗證模型,將選取300 個普洱茶企業,對其普洱茶質量安全風險等級進行評價。將其風險評價等級分為5 級,最低風險為1 級,最高風險為5 級。然后邀請7位質量安全風險評估專家,根據企業相關情況采用問卷形式對指標體系進行打分,分數范圍為0~10。分數越接近10,代表該指標的情況越優異,所對應的風險越低,如表3所示。最后根據得到的數據構建風險矩陣表。

Table 3 Risk rating table表3 風險等級表
通過多輪匿名方式征詢質量安全風險評估專家意見,不斷反饋、調整并綜合多數專家的主觀經驗和判斷,統計、處理、分析專家意見,對選取的300 家普洱茶企業的34 個普洱茶質量安全風險指標等級進行客觀、合理估算,最終得到300 份普洱茶質量安全風險指標體系調查數據。將收集得到的專家打分數據進行歸一化處理,得到最終影響云南普洱茶質量安全風險的指標體系數據。
3.2 基于RF的指標降維
將RF 模型導入影響云南普洱茶質量安全風險的指標體系數據,借助Python 軟件得到34個影響因素的重要性分布,如圖5所示。
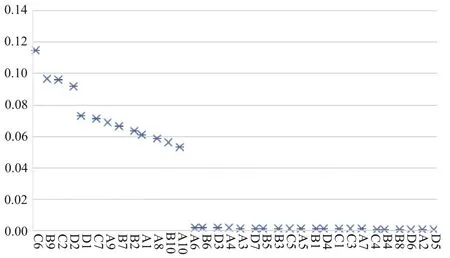
Fig.5 Indicator importance distribution map圖5 指標重要性分布圖
為更直觀地觀察數據,將各個指標的重要性數據匯總成表格,如表4 所示。通過對表4 中的指標重要性進行分析,可得出:①重要性指數最高的指標。最重要的因素是倉庫存儲環境情況,重要性指數為0.11。茶葉需嚴格控制存儲的溫度、濕度以保證其口感、色澤等,因此物流期間的倉庫存儲環境對于保證茶葉質量至關重要;②重要性指數達到0.09~0.1 區間的指標。在此區間的指標包括加工場所環境、物流階段成品質量檢測設備和銷售階段商品質量檢測設備情況。普洱茶的加工工序較為繁瑣,對加工環境要求較為嚴苛,因此對加工場所環境的嚴格把控會提高普洱茶加工質量。物流過程中的頻繁裝卸會給茶葉帶來一定損傷,采用良好的茶葉質檢設備可規避質量風險,而銷售階段作為供應鏈的最后一環,采用良好的茶葉質檢設備更顯得尤為重要;③重要性指數達到0.07~0.8 區間的指標。在此區間的指標包括銷售管理人員存儲經驗和農產品加工工藝。若銷售管理人員對茶葉的存儲經驗不足,將會導致普洱茶變質,不同的加工工藝也會大幅影響茶葉的風味和口感,從而影響其質量;④重要性指數在0.06~0.07區間的指標。在此區間的指標包括工作人員種植經驗、運輸環境、生長環境及加工人員知識技能培訓情況。種植階段工作人員的種植經驗和茶葉生長環境將直接影響到茶葉原材料質量,良好的運輸環境可減少因碰撞或溫濕度變化帶來的茶葉破碎或變質。普洱茶的加工工藝特殊,因此需要對加工人員進行技能培訓,才能保證生產出符合質量的茶葉;⑤重要性指數在0.05~0.06 之間的指標。在此區間的指標為農產品采摘方式、倉庫存儲環境及食品添加劑超標情況。茶葉采摘方式分為機器和人工兩種,人工采摘的茶葉質量較高,而加工階段的倉庫存儲情況則確保從原葉、半成品到成品不會因存儲不當而變質。若食品添加劑過量,將會對人體造成嚴重影響,也必須重視。

Table 4 Indicator importance table表4 指標重要性表
通過對表4 的進一步分析,可得出重要性指數超過0.05 的指標共有13 個,分別為:倉庫存儲環境情況(C6)、加工場所環境情況(B9)、成品質量檢測設備(C2)、商品質量檢測設備(D2)、銷售管理人員存儲經驗(D1)、農產品加工工藝(B7)、工作人員種植經驗(A1)、運輸環境情況(C7)、生長環境情況(A9)、人員知識技能培訓(B2)、農產品采摘方式(A8)、倉庫存儲環境情況(B10)、食品添加劑超標情況(B6)。由于其余21 個指標的重要性指數不足0.01,與上述13 個指標相比重要性較低,因此選取這13 個指標對本文分類模型進行訓練,探尋各影響因素與普洱茶質量安全風險等級之間的關系。降維后得到質量安全風險評估體系,如表5所示。
3.3 基于DBN的風險評估分析
在以上運用RF 降維之后選取的樣本中,將其中80%的樣本數據用于訓練,剩余20%用于測試,并匯總出相應等級的訓練集和測試集數量,如表6所示。

Table 5 Quality and safety risk assessment system after dimension re?duction表5 降維后的質量安全風險評估體系
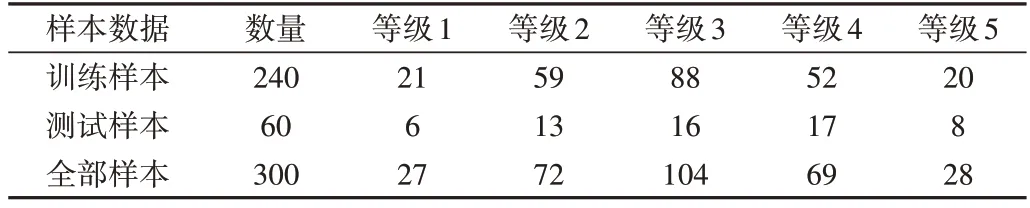
Table 6 Sample distribution表6 樣本分布情況
根據3.2 中降維后的指標體系,可確定模型的輸入層有13 個神經元,輸出層有5 個神經元,即等級1、等級2、等級3、等級4和等級5。本文根據得到的樣本數據對DBN 模型參數不斷進行調整優化,分別選用兩個RBM 模型進行堆疊,其隱含層中的神經元個數依次為50、35 個,并設RBM 前向學習率為0.01。根據訓練樣本測試不同迭代次數對DBN 模型精度的影響,不同迭代次數的DBN 精度如圖6所示。
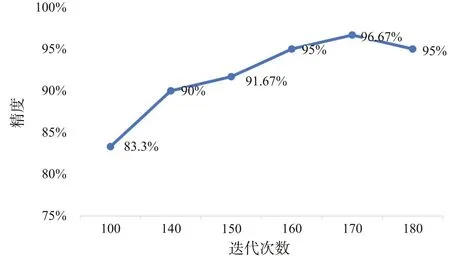
Fig.6 DBN accuracy for different iterations圖6 不同迭代次數的DBN精度
由圖6 可以得出,在迭代次數小于170 次時,模型精度隨著迭代次數的增加而增加。當迭代次數為170 次時,精度達到最高為96.67%;當迭代次數為180 次時,模型處于過擬合狀態,所以精度略有下降,且增加了迭代時間。因此,本文選擇迭代次數為170次。
接下來將全部數據輸入上述調整好的DBN 模型中,DBN 模型預測結果如圖7 所示。由圖7 可知,在普洱茶的質量安全風險分類中,實際分類結果與模型分類預測結果相差不大。
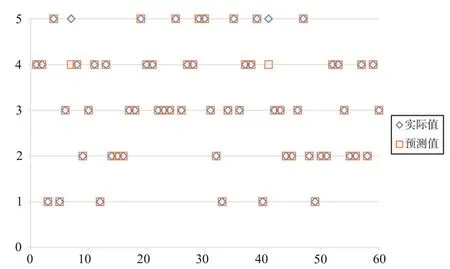
Fig.7 DBN model prediction results圖7 DBN模型預測結果
分類預測匯總結果如表7 所示。由表7 可知,從等級1到等級3,分類精度高達100%,而分類錯誤主要出現在等級4 和等級5 中,有兩組等級4 的樣本被錯分為等級5。該結果說明DBN 風險評估模型對普洱茶的質量安全風險有較強的分類預測能力。
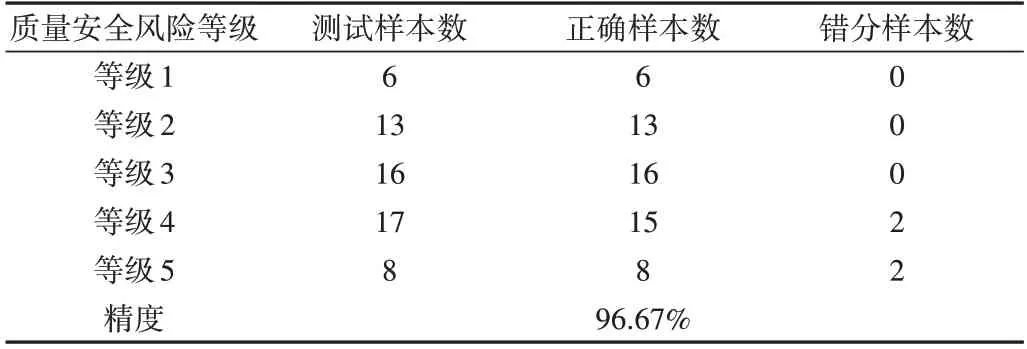
Table 7 Categorical predictions summary results表7 分類預測匯總結果
3.4 模型對比分析
反向傳播神經網絡(BP)具有很強的非線性映射能力,是應用最為廣泛的神經網絡,而支持向量機(SVM)是一種被廣泛應用于數據分類問題的監督學習算法。因此,為進一步驗證DBN 模型的可靠性,本文選取傳統機器學習算法中的BP 神經網絡和SVM 分類器分別對普洱茶質量安全風險等級進行分類測試,并對測試結果進行對比。BP 神經網絡選取3 層神經網絡結構,分別為輸入層、隱含層和輸出層。其中,輸入層和輸出層的神經元數量與DBN 模型一致,分別為13 和5,且迭代次數為4 000 次,激活函數為Sig?moid 函數。在SVM 分類器中,設置內核函數為RBF,懲罰系數為1,分類策略選擇“ovr(one versus rest)”,即一對多分類。3種模型分類結果比較如表8所示。

Table 8 Comparison of classification results of three models表8 3種模型分類結果比較
由表8可知,在測試樣本相同的情況下,可以得出:
(1)DBN 模型在普洱茶質量安全風險分類的60 個測試樣本中,可正確分類出58 個樣本,評估精度較高,可達96.67%,明顯優于BP 神經網絡和SVM 分類器。該結果表明,DBN 模型可有效實現對地理標志農產品質量安全的風險評估,且相較于BP 神經網絡和SVM 分類器,該模型在質量安全風險等級評估與分類中具有一定優越性。
(2)BP 神經網絡模型在60 個測試樣本中,可正確分類出54 個樣本,評估精度一般,僅為90%。BP 神經網絡只有輸入層、隱含層和輸出層3 層網絡結構,對于復雜函數關系的學習與訓練能力明顯低于深度神經網絡DBN,所以其對普洱茶質量安全風險等級的評估結果一般。
(3)SVM 分類器在60 個測試樣本中,僅正確分類出46個樣本,評估精度較低,僅為85%。原因在于其最初設計為解決二值分類問題,因此在處理多分類問題時,只能間接構造合適的多分類器,無法直接解決多分類問題,所以評估結果不理想。
4 結論與建議
近年來頻頻爆出地理標志農產品質量安全事故,嚴重破壞了地理標志農產品的品牌效益與市場信譽,阻礙了農業規模化、產業化發展。本文充分利用深度學習在海量、高維數據中優秀的特征學習與提取能力,將RF 和DBN 模型引入地理標志農產品質量安全風險評估。通過實證分析,相對于傳統方式,該模型具有較高的評估準確率。該研究結果為我國地理標志農產品質量評估方法的應用提供了參考。但本文研究中也存在一些不足:①由于數據獲取和標量化的限制,本文只選取了部分影響地理標志農產品質量安全的因素,實際上仍存在大量未被提及的因素有待繼續研究;②本文采用專家打分法獲取調查數據,具有一定程度上的主觀性。
后續可從以下兩方面進行深入研究:①基于深度學習的地理標志農產品質量安全風險評估方法優化。RF 和DBN 只是眾多機器學習算法的一個,還可進一步探索概率神經網絡、無監督學習等方法;②多種風險評估方法的有機融合。任何單一的風險評估方法都有自身的優勢和局限,可通過組合評價方法充分發揮各方法的優點,取長補短,從而提高風險評估的準確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
