用于信息檢索的句子級深度關聯匹配模型
2022-06-29 12:36:12郝文寧靳大尉
計算機技術與發展 2022年6期
田 媛,郝文寧,陳 剛,靳大尉,鄒 傲
(陸軍工程大學 指揮控制工程學院,江蘇 南京 210001)
0 引 言

深度神經網絡,作為一種表示學習方法,已經被廣泛應用于NLP任務[3-4],并取得顯著成果,鑒于此,研究者嘗試將其應用于IR中,現有的神經信息檢索模型可大致分為兩類:語義匹配模型和關聯匹配模型。語義匹配模型主要關注文本的表示,通過深度神經網絡將查詢和待檢索文檔映射到低維的向量空間,然后利用這種向量表示計算它們的相似度;關聯匹配模型主要關注文本之間的交互,對查詢和待檢索文檔之間的局部交互進行建模,使用深度神經網絡學習層次交互信息以得到全局的相似度得分。現有的用于IR的深度關聯匹配模型通常以詞為單位進行局部相關度匹配,沒有考慮詞之間的順序及語義信息,無法解決一詞多義的問題。該文提出的關聯匹配模型使用語義相對完整的句子作為單位實現查詢與待檢索文檔之間的局部交互,首先計算查詢中每個句子與待檢索文檔中各個句子的相似度得分,并將這些得分映射到固定數量的桶中,桶按相似度等級劃分,從而獲取固定長度的匹配直方圖;然后使用一個前饋神經網絡學習局部交互的層次信息獲取每個查詢句與整個文檔的相似度得分;最后使用一個門控網絡計算每個查詢句的權重并聚合得到最終整個查詢與文檔的相似度得分。
主要貢獻如下:
(1)將句子級檢索與深度關聯匹配模型相結合,以語義相對完整的句子為單位進行查詢與待檢索文檔之間的局部匹配,充分考慮了詞的上下文信息。
(2)查詢Q的全部局部匹配直方圖輸入到神經網絡之前將其重新排列,解決模型因對位置信息過度擬合,即可能在經常用0填充的句子處學習到較低的權重帶來的整體檢索性能下降的問題。
(3)使用交叉熵損失替換鏈損失,并通過實驗驗證,使用交叉熵損失可以提高模型的檢索性能。
1 相關研究
IR中的核心問題就是計算文檔與給定查詢之間的相關性,也就是文本匹配的問題。傳統BM25是一個專門用于計算查詢和候選文檔之間相似度的評分標準,文獻[5]指出,其搜索功能在實踐中往往會過度懲罰有用的長文檔,Na等人[6-7]將其改進成vnBM25,有效地緩解了文章長度的冗余影響。Kusner等人[8]提出了詞移距離的概念(WMD),從轉換成本上度量文本之間的相似度。鑒于深度神經網絡良好的表示學習能力,近年來研究者已經提出了很多深度匹配模型用于IR,旨在基于自由文本直接對查詢和文檔之間的交互進行建模[9],這些模型大致分為兩類,語義匹配模型和關聯匹配模型。如圖1(a)所示,語義匹配模型中的深度網絡是為查詢和待檢索文檔學習一個好的表示,然后直接使用匹配函數去計算二者之間的相似度,例如在DSSM[10]中,深度網絡使用的是一個前饋神經網絡,匹配函數則是余弦相似度函數;在C-DSSM[11-12]中,使用卷積神經網絡學習查詢和文檔的向量表示,然后使用余弦相似度函數計算二者之間的相似度得分。

(a)語義匹配模型 (b)關聯匹配模型
然而,Guo等人[13]指出,IR中所要求的匹配與NLP任務中所要求的匹配是不同的,若在創建文本表示之后再進行交互,可能造成精確匹配信息的丟失。關聯匹配更適用于檢索任務,如圖1(b)所示,首先建立查詢中詞與待檢索文檔中詞之間的局部交互,然后使用深度神經網絡學習層次匹配模式以獲取全局相似度得分,例如ARC-II[14]和MatchPyramid[15]模型使用詞向量之間的相似度得分作為兩個文本的局部交互,然后使用分層的卷積神經網絡來進行深度匹配;DRMM模型首先計算查詢-文檔對詞之間的相似度得分,并將其映射成固定長度的直方圖,然后將相似度直方圖送入一個前饋神經網絡以獲取最終的得分;K-NRM[16]模型使用核池化來代替DRMM中的相似度直方圖,有效解決了生成直方圖時桶邊界的問題。
近年來已經有學者提出句子級的檢索方法,但是這些方法僅使用無監督學習將查詢句與文檔句之間的相似度得分簡單整合以獲取最終得分。文獻[17]中提出三種整合方法:第一個是將文檔中每個句子的相似度得分進行累加以獲得整個文檔的相似度得分;第二個是將文檔中全部句子相似度得分的平均值作為整個文檔的相似度得分;第三個是取文檔中句子相似度得分的最大值作為文檔的相似度得分。李宇等人[18]提出了相關片段比率的概念,取文檔中句子相似度得分的最大值與相關片段比率的乘積作為整個文檔的相似度得分。文中模型將句子級檢索與深度神經網絡相結合,使用深度神經網絡學習查詢句子與待檢索文檔句子之間的層次匹配信息,從而獲得整個查詢-文檔對的相似度得分。
2 句子級深度關聯匹配模型
該文提出了一個句子級深度關聯匹配模型(sentence level deep relevance matching model,SDRMM),具體來說,在句子級別的關聯匹配上使用了一個深度神經網絡結構,學習查詢句與文檔句的層次匹配信息以獲取最終的查詢-文檔對得分。如圖2所示。

圖2 句子級深度關聯匹配模型
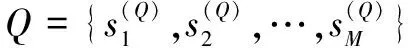
2.1 句子級關聯匹配

(1)
為獲取固定長度的匹配直方圖,該文對查詢句與文檔句之間的相似度得分按等級分組,每一組看做一個桶,統計落入各個桶中的文檔句個數,然后取其對數作為最終的局部匹配信息,考慮到較多桶中可能只有一個文檔句子,直接取對數后值為0,會影響模型的訓練效果,先對桶中的文檔句子數進行加一操作再取其對數。例如,將相似度范圍[-1,1]劃分為4個等級{[-1,-0.5),[-0.5,0),[0,0.5),[0.5,1]},查詢中的其中一個句子與待檢索文檔對應的局部交互得分為(0.2,-0.1,0.6,0.7,0.8,0.9),那么該查詢句所對應的固定長度的匹配信號就為[0,log2,log2,log3]。
2.2 深度關聯匹配
深度關聯匹配模型的輸入即為上述查詢中各個句子與待檢索文檔之間的局部交互信息,首先使用前饋神經網絡從不同水平的局部交互中學習層次匹配信息,針對每個查詢句得到一個與待檢索文檔的相似度得分,前饋網絡中隱藏層的輸出如式(2)所示:

i=1,2,…,M;l=1,2,…,L
(2)


(3)
(4)
由于在保證深度關聯匹配模型輸入的固定長度時使用了零填充方法,在訓練時,模型可能會在經常填充零的位置錯誤學習到較低的權重,也就是說,門控網絡在學習權重時,可能會對不同位置的局部匹配信號區別對待。為了避免這種問題,首先將零填充后的每個查詢的全部局部關聯匹配直方圖重新排列,然后再將其送入模型進行訓練,實驗結果表明該做法能夠提高整體的檢索性能。
2.3 模型訓練
在已有的一些神經信息檢索模型中,例如DRMM、PACRR[22]等,通常使用成對的排序損失最大間隔損失來訓練模型,而在文中的句子級深度關聯匹配模型訓練時,使用一個交叉熵損失來替換最大間隔損失,對比實驗表明,交叉熵損失可以提高模型的檢索性能。損失函數定義為:
L(Q,D+,D-,Θ)=
(5)
其中,Q為一條查詢,D+表示與查詢相關的文檔,D-表示與查詢不相關的文檔,Score(Q,D)表示查詢與文檔的相似度得分,Θ表示前饋神經網絡和門控網絡中的全部參數。
3 實 驗
使用Med數據集對提出的句子級深度關聯匹配模型進行評估,該數據集來自Glasgow大學收錄的IR標準文本測試集,其中包含1 033篇文檔,30條查詢,詳細情況如表1所示。對Med數據集進行預處理,去除標簽等無用信息,參照標準停用詞表刪去停用詞并提取詞干,實驗中使用五折交叉驗證以減少過度學習,將全部查詢劃分為5部分,每次取4/5的查詢作為訓練集,剩下的作為驗證集。此外,還在Med數據集上對提出的模型和一些基準信息檢索模型進行比較,使用MAP、檢索出的Top-10個文檔的歸一化折現累積增益nDCG@10和Top-10個文檔的準確率P@10作為評估指標。

表1 Med數據集信息
3.1 基準模型
使用一些現存的基準模型如BM25、DRMM、無監督句子級檢索模型以及筆者之前提出的無監督句子級關聯匹配模型與該文的句子級深度關聯匹配模型進行比較,本節將對這些基準模型進行簡要介紹。
BM25:該模型代表了一種經典的概率檢索模型[23],它通過詞項頻率和文檔長度歸一化來改善檢索結果。
無監督句子級檢索模型:左家莉等人提出一種結合句子級別檢索的文檔檢索模型,首先計算待檢索文檔中每個句子與查詢的相似度得分,然后通過對這些相似度得分的簡單加和、求平均或取最大值來獲取整個文檔與查詢的相似度得分,這里分別將三種不同的整合方法表示為SRIR1、SRIR2和SRIR3;李宇等人提出一種文檔檢索中的片段化機制,通過設定合適閾值從文檔中篩選出高度相關片段并計算相關片段比率,然后將相關片段中的最高相似度得分與相關片段比率的乘積作為整個文檔與查詢的相似度得分,這里將該模型記為TSM_BM25;筆者在之前的工作中也提出了一種無監督句子級檢索模型,先使用預訓練的Sentence-Bert模型獲取查詢與待檢索文檔中各個句子的向量表示,使用余弦距離計算句子之間的相似度得分,然后再使用現有的整合方法獲取整個文檔的得分,模型記作MI-IR。
DRMM:該模型是一種關注文本交互的深度匹配模型,首先通過計算查詢中的詞與待檢索文檔中的詞之間的相似度獲取局部關聯匹配直方圖,然后通過前饋神經網絡學習出分層的關聯匹配從而獲取最終查詢-文檔對的相似度得分。
3.2 實驗設置
該文的句子級深度關聯匹配模型是由三層前饋神經網絡和一層門控網絡構成的,在前饋神經網絡中,一層輸入層接收局部關聯匹配信號,設有30個節點,兩個隱藏層分別包含5個節點和1個節點,獲取每個查詢句與文檔的相似度得分;門控網絡設有1個節點,獲取最終查詢-文檔對的相似度得分。在訓練時,使用Adam優化器,batch-size設為20,學習率設為0.01,epoch設為3,門控網絡中參數向量的維度設為768,與句向量的維度保持一致。對基準模型DRMM,使用CBOW模型獲取300維的詞向量用于計算查詢中的詞與待檢索文檔中的詞之間的局部關聯。
3.3 實驗結果及分析
本節展現不同的基準模型以及該文的句子級深度關聯匹配模型在Med數據集上的實驗結果,如表2所示。

表2 Med數據集測試評估
可以看出,幾個無監督的句子級檢索模型均比傳統的文檔級概率檢索模型BM25在性能上有所提升,這表明一些相似度計算方法可能會受到文本長度的影響。在這些無監督句子級檢索模型中,SRIR模型與TSM_BM25模型的檢索性能相差不大,表明在Med數據集上對用BM25公式計算出來的文檔句的相似度得分使用不同的無監督整合方法差別不大,而筆者之前提出的MI-IR模型,相對于其他幾種無監督句子級檢索模型在準確率和nDCG上均有一定的提升,說明Sentence-Bert模型確實能更好地捕獲句子的語義信息,從而提升文檔檢索的性能。神經檢索模型DRMM相較于傳統的BM25檢索模型在MAP、P@10以及nDCG@10上分別有8.1%、11.9%和6.9%的提升,且優于幾種無監督的句子級檢索模型,比MI-IR模型在MAP上有7.3%的提升,這也表明了關注文本之間交互的深度神經網絡檢索方法能夠提升文檔檢索的性能。
在這些檢索模型中,該文的句子級深度關聯匹配模型(SDRMM)明顯表現更好,其相較于傳統檢索模型BM25在MAP、P@10以及nDCG@10上分別有18.6%、19.3%和15.4%的提升;較無監督句子級檢索模型中表現最好的MI-IR模型分別有17.7%、11.3%和8.9%的提升;較深度關聯匹配模型DRMM分別有9.6%、6.6%和7.9%的提升。證實了以語義相對完整的句子為單位的查詢-文檔對之間的局部關聯匹配要比以詞為單位的局部關聯匹配表現好,能夠捕獲文本之間更加精確的匹配信息。
3.4 消融實驗
通過消融實驗對SDRMM做進一步分析,以驗證打亂查詢中局部匹配直方圖輸入順序以及使用交叉熵損失的有效性。實驗中仍然使用Med數據集,SDRMMsequence表示查詢匹配直方圖順序未打亂且使用交叉熵損失的SDRMM;SDRMMhinge表示查詢匹配直方圖順序打亂且使用鏈損失的SDRMM;SDRMMhinge×sequence表示既未將查詢匹配直方圖順序打亂又未使用交叉熵損失的SDRMM,實驗結果如圖3所示。

圖3 消融實驗評估
從圖中數據可以看出,在同樣使用了交叉熵損失的情況下,打亂查詢句的順序比不打亂查詢句的順序在P@10和nDCG@10上均有近1%的提升;在同樣打亂查詢句的順序的情況下,使用交叉熵損失比使用鏈損失在P@10和nDCG@10上分別有近3%和近2%的提升,在MAP上有0.3%的提升;不打亂查詢句順序且使用鏈損失的模型效果最差,在MAP指標上低于SDRMM 0.8%,在P@10和nDCG@10上分別低于SDRMM近4%和近3%。總的來說,選擇的最優的SDRMM相比于SDRMMsequence、SDRMMhinge以及SDRMMhinge×sequence在Top-K個檢索文檔的MAP、準確率和nDCG上均有一定的提升,證實提出的打亂查詢中句子的輸入順序以及使用交叉熵損失對于提升文檔檢索的性能的有效性。
4 結束語
提出了一種新的關注文本之間交互的神經信息檢索模型,通過獲取查詢與待檢索文檔之間更深層的匹配信息來提高檢索的性能。現存的一些深度關聯匹配模型通常是以詞為單位計算查詢與文檔之間的局部交互信息,但這往往忽略了詞之間的順序和語義信息。使用語義相對完整的句子為單位,在已有的無監督句子級檢索的基礎上,使用深度神經網絡學習查詢句與待檢索文檔句之間的層次交互信息從而得到整個查詢-文檔對的相似度得分。為了進一步提升文檔檢索的性能,使用交叉熵損失來替代現有一些模型中常用的鏈損失,此外,為了減小模型訓練時對不同位置查詢句區別對待的影響,在輸入查詢中的句子時,將其順序打亂。在Med數據集上的實驗結果表明,該文的句子級深度關聯匹配模型比一些傳統的信息檢索模型以及先進的檢索模型表現好。
當前在計算查詢句與待檢索文檔句之間的相似度得分時,只簡單使用了余弦相似度函數,在下一步的工作中,將對句子之間的相似度計算方法進行改進,考慮結合文檔中句子的位置信息,因為句子的位置也會影響其重要程度;還可以將多種相似度算法相結合,以綜合不同算法的優勢。還希望能在更多的數據集上訓練該句子級深度關聯匹配模型,以進一步查看模型在不同數據集上的表現。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代陜西(2021年17期)2021-11-06 03:21:36
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
