基于PCA-MIC-LSTM的碟形湖溶解氧含量預測模型研究
2022-07-01 13:31:14遲殿委,黃琪,劉麗貞,方朝陽
人民長江 2022年6期
遲 殿 委,黃 琪,劉 麗 貞,方 朝 陽
(1.煙臺理工學院 人工智能學院,山東 煙臺 264005; 2.江西師范大學 鄱陽湖濕地與流域研究教育部重點實驗室,江西 南昌 330022; 3.江西省科學院,江西 南昌 330096)
0 引 言
水質(zhì)預測是對水質(zhì)進行評價、管理和保護的一項基礎工作。隨著互聯(lián)網(wǎng)、物聯(lián)網(wǎng)、智能傳感器等技術的發(fā)展及其在水質(zhì)監(jiān)測中的應用,可實現(xiàn)實時快速監(jiān)測水體指標,并以此為基礎數(shù)據(jù),來準確預測湖泊水質(zhì)變化趨勢,這對于構建水質(zhì)環(huán)境預警機制具有重要意義[1]。湖泊水環(huán)境是一個易受氣候變化、流域生態(tài)變化和人類活動影響的不確定系統(tǒng)。通過對水質(zhì)指標特征進行分析并建立預測模型,可以促進對水環(huán)境內(nèi)在機理的理解,這對于湖泊水質(zhì)管理和保護、水污染防治具有重要意義。湖泊水質(zhì)變化具有漸變性、非線性和不確定性等特點[2],從宏觀上又表現(xiàn)出季節(jié)性、周期性等特點,這使得傳統(tǒng)機理和經(jīng)典數(shù)學理論模型難以模擬其過程。
近年來,隨著水質(zhì)數(shù)據(jù)的在線監(jiān)測獲取能力和計算能力的發(fā)展,數(shù)據(jù)驅(qū)動模型在水質(zhì)預測中受到了廣泛的關注。水體溶解氧能夠調(diào)節(jié)生物多樣性[3],影響營養(yǎng)鹽生物地球化學特征[4-5]、溫室氣體排放[6]和飲用水水質(zhì)[7],并能指示水體污染狀況[8],因此,溶解氧是評價湖泊生態(tài)系統(tǒng)健康的重要指標[9]。然而,受氣候變化和人類活動的影響,溫帶區(qū)域的湖泊溶解氧普遍呈現(xiàn)下降趨勢[9],已嚴重威脅到湖泊生態(tài)系統(tǒng)服務功能。因此,長期監(jiān)測并能很好預測湖泊水體溶解氧(DO)的濃度,對水質(zhì)監(jiān)控管理具有重要的作用。
目前,國內(nèi)外學者針對湖泊、河流和池塘等地表水體DO濃度預測方法,已經(jīng)開展了大量的研究[10-18]。由于水體的區(qū)域性和類型的差異性,各學者選用的模型方法都各不相同,主要包括支持向量機、多元自適應樣條回歸法、神經(jīng)網(wǎng)絡法(長短時記憶網(wǎng)絡Long Short Term Memory Network,LSTM;廣義回歸神經(jīng)網(wǎng)絡法和后向傳播神經(jīng)網(wǎng)絡)、多項式混沌法等方法。其中,支持向量回歸法和循環(huán)神經(jīng)網(wǎng)絡法應用于DO濃度預測較為廣泛。有學者發(fā)現(xiàn),支持向量機比后向傳播神經(jīng)網(wǎng)絡、廣義回歸神經(jīng)網(wǎng)絡、多元自適應樣條回歸法以及M5模型樹等更能預測水體的DO濃度[11-12,16]。羅學科等[17]提出了基于差分自回歸移動平均與支持向量回歸組合模型,主要通過SVR模型來補償其中的非線性變化,將巢湖水域2004~2015年間的pH和溶解氧監(jiān)測數(shù)據(jù)作為試驗樣本進行模型訓練和預測,取得了較高的預測精度;Li等[14]基于最大信息系數(shù)(MIC)的特征選取與支持向量回歸法(SVR)分析結合,很好地預測了珠江潮汐河流網(wǎng)水體中的DO濃度,其確定系數(shù)大于0.90,并發(fā)現(xiàn)與MIC法相結合能顯著降低誤差率和提高擬合度。Antanasijevi等[10]通過比較不同人工神經(jīng)網(wǎng)絡法,預測了塞爾維亞北部的多瑙河中溶解氧的濃度,并得出循環(huán)神經(jīng)網(wǎng)絡(RNN)要優(yōu)于廣義回歸神經(jīng)網(wǎng)絡和后向傳播神經(jīng)網(wǎng)絡的結論。由于溶解氧在線監(jiān)測數(shù)據(jù)具有時間序列特征,因此使用深度學習中的RNN法能處理好時間序列問題。然而在處理長時間序列問題時,容易造成梯度消失或爆炸[19]。LSTM[20-21]是RNN算法的一個變種,具有選擇記憶的特點,其神經(jīng)元受控于輸入門、輸出門、遺忘門3個門控,克服了傳統(tǒng)RNN梯度消失的問題,可以更加精細地預測時間序列變量。進一步地,有很多學者嘗試將LSTM模型進一步優(yōu)化,比如結合主成分分析(PCA)法[22]、粒子群優(yōu)化算法[23]、添加自適應白噪聲的完備集成經(jīng)驗模態(tài)分解法和人工蜂群算法[24]、K-相似度法[25]、小波變換法[26-27]等處理方式,可以顯著提高預測效果。
鄱陽湖是中國第一大淡水湖,其承接流域來水又與長江直接相通,水位變化具有季節(jié)性變化規(guī)律,孕育了面積巨大的淡水湖泊濕地,分布著數(shù)量眾多的碟形湖,特殊的地貌特征和水文等特征,使得碟形湖在鄱陽湖濕地及流域生態(tài)系統(tǒng)扮演著愈加重要的角色[28]。碟形湖在夏秋季高水位時與鄱陽湖主湖相連,在冬春季枯水時形成獨立的小湖泊,獨特的環(huán)境使得水體溶解氧受環(huán)境影響的因素更為復雜,表現(xiàn)為不確定性和不穩(wěn)定性。溶解氧是直接指示自然水體生態(tài)系統(tǒng)健康水平的重要指標,而已有研究多關注于養(yǎng)殖水體DO[22-23,29-32],受限于維護工作繁瑣等因素的影響,野外部署高頻、自動的水質(zhì)監(jiān)測設備較少,研究不夠深入,尤其是對于復雜多變的碟形湖天然水體中DO濃度變化方面的研究則相對更少。此外,由于監(jiān)測數(shù)據(jù)具有長時間序列、不穩(wěn)定和非線性特征,且容易受到設備、天氣等因素影響,存在一定的噪音數(shù)據(jù),影響了模型的訓練速度和性能,模型輸入?yún)?shù)的復雜性也容易使建立的預測模型出現(xiàn)過擬合。
綜上所述,本文提出了基于PCA降噪處理、MIC的特征選取與LSTM模型相結合的方法,來預測鄱陽湖南磯濕地保護區(qū)碟形湖湖泊水體溶解氧含量。首先,數(shù)據(jù)預處理階段采用PCA對數(shù)據(jù)進行降噪處理;然后利用MIC來計算各特征與分類標簽之間的關聯(lián)程度,并選擇相關度高的部分特征作為最終的訓練特征;最后用LSTM進行訓練建模。本文模型通過清洗降噪實現(xiàn)了樣本數(shù)據(jù)的可靠性,通過特征提取簡化了預測模型,不僅提高了模型的訓練速度和準確度,而且有效地防止了過擬合,提高了模型的泛化能力,可為鄱陽湖及其流域水質(zhì)監(jiān)測管理和維護提供科學決策的依據(jù)。
1 數(shù)據(jù)處理和方法
1.1 數(shù)據(jù)集來源和介紹
本文所采用的數(shù)據(jù)集,來自江西師范大學與鄱陽湖南磯濕地國家級自然保護區(qū)共建的鄱陽湖南磯自然保護區(qū)野外綜合試驗站中戰(zhàn)備湖的實時在線監(jiān)測數(shù)據(jù)。鄱陽湖南磯濕地國家級自然保護區(qū)所處的贛江口與鄱陽湖交匯的河口三角洲濕地,是典型的內(nèi)陸河口濕地,處于東亞-澳大利亞水鳥遷飛線路之中,位于鄱陽湖南部,在全球具有代表性,2020年2月3日被國家林業(yè)和草原局根據(jù)《濕地公約》指定為國際重要濕地。戰(zhàn)備湖位于保護區(qū)西南部,受流域水文交互作用影響,夏秋豐水期(星子站水位超過17.00 m時)成為鄱陽湖水域一部分,冬春枯水期(星子站水位低于14.00 m時),四周圍灘完全出露,水域與鄱陽湖大湖面分割,形成典型淺碟形子湖泊,面積約 2.7 km2。2016年11月在戰(zhàn)備湖內(nèi)投放和運行了一個浮體,搭載了水質(zhì)、小型氣候站等自動監(jiān)測設備[33]。監(jiān)測指標包括大氣溫度、風向、風速、大氣壓強、相對濕度、水溫、pH、電導率、氧化還原電位和溶解氧等10個指標。本文數(shù)據(jù)集的監(jiān)測時間范圍為2017年4~11月(共8個月),每隔2 min采集一次數(shù)據(jù),共采集到7 803條數(shù)據(jù)。數(shù)據(jù)集信息如表1所列。由表1可以看出:碟形湖的溶解氧存在極大的不穩(wěn)定性,其極差值可達13.06 mg/L,高于已報道的深水湖泊及淺水湖泊的極差值[34-35]。這意味著需要特定的模型來針對獨特的碟形湖,以預測湖口溶解氧的含量。
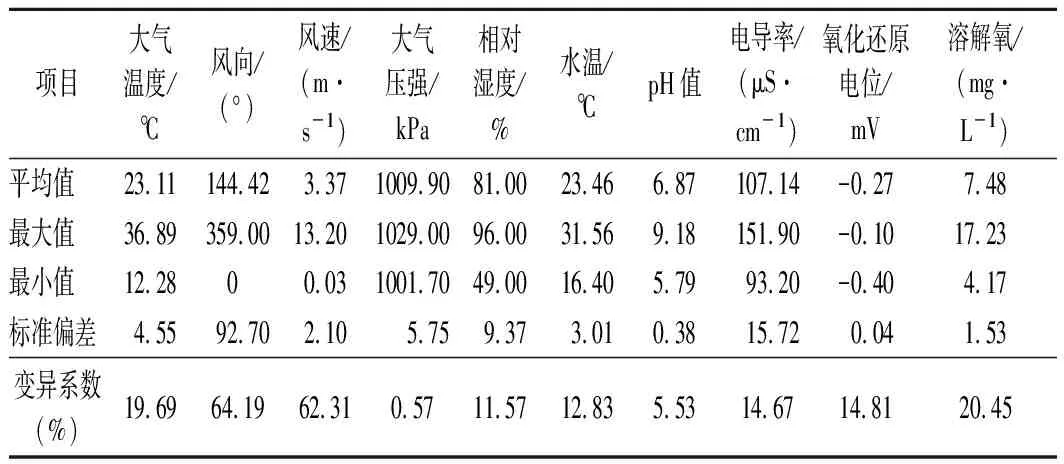
表1 樣本數(shù)據(jù)信息Tab.1 Samples information
1.2 數(shù)據(jù)預處理
數(shù)據(jù)預處理包括2個部分的工作:樣本特征數(shù)據(jù)歸一化和基于PCA的數(shù)據(jù)降噪處理。
(1) 數(shù)據(jù)歸一化處理。由于所選取的水質(zhì)特征指標范圍較大,數(shù)據(jù)樣本由10個不同指標特征變量組成,這些特征變量有不同的量綱,而且差異較大,為了消除水質(zhì)各特征單位和尺度差異的影響,以對每個特征同等看待,需要對特征進行歸一化,就是將每個特征調(diào)整到一個特定的范圍。這里選用最大值最小值歸一化方法,將所有特征值轉換到區(qū)間[0,1]中,以減少數(shù)據(jù)的波動性和復雜性。最大值最小值歸一化公式如式(1)所示:
(1)
(2) 基于PCA的數(shù)據(jù)降噪處理。考慮監(jiān)測采集周期較長,在水中放置太久容易被污染物附著以及天氣的變化,都會造成采集數(shù)據(jù)存在一定偏差,而且特征之間存在冗余。因此,首先對樣本數(shù)據(jù)進行PCA降維降噪處理[36]。本文在保留樣本中有效信息的前提下,通過將樣本數(shù)據(jù)集先降維,然后再升到原來的維度,達到減少噪聲的效果。因為設備采集的數(shù)據(jù)噪聲數(shù)據(jù)比例不大,這里設置PCA算法保留樣本中98%的有效信息。PCA算法的主要步驟如下[37-38]:
步驟1,首先對樣本數(shù)據(jù)矩陣y(nxm)={y1,y2,…,ym}進行中心化處理,得到中心化的矩陣y′。
步驟2,對y′的協(xié)方差矩陣分解特征值。
步驟3,將前t個最大特征值對應的特征向量經(jīng)過標準化之后組成特征矩陣W={W1,W2,…,Wt}。
步驟4。最終降維后的數(shù)據(jù)為ynew=WTy′。
PCA的作用除了降維,也能夠?qū)颖緮?shù)據(jù)進行噪聲過濾。因為主成分中任何一個成分的變化影響都遠大于噪聲的影響,各成分相對不受影響,可以使用主成分來重構帶噪聲的原始樣本數(shù)據(jù)。主要思路是在保留原數(shù)據(jù)集主要信息的前提下,將數(shù)據(jù)集降維,然后將低維數(shù)據(jù)升為高維數(shù)據(jù),即還原到原始數(shù)據(jù)集的維度,其升維步驟描述如下:
步驟1,首先取包含t個最大特征值的矩陣W的轉置矩陣WT。
步驟2,然后用降維后的矩陣ynew與WT相乘,將降維后的矩陣升高到原來的維度,結果矩陣記為yr。
步驟3,求矩陣每一列的均值,得到n維向量V。
步驟4,將矩陣yr與均值向量V相加反構出原始維度的數(shù)據(jù)矩陣。
1.3 特征變量的篩選
本文基于MIC法對多個特征變量進一步篩選。該方法于 2011年由Reshef等[39]提出,是用于檢測變量之間非線性相關程度的最新方法。MIC使用最大歸一化互信息來度量特征與目標類別的關聯(lián)程度,并將信息論和概率的概念應用于連續(xù)型數(shù)據(jù)。MIC以2個特征變量間的聯(lián)合概率密度來衡量其相關程度[40],該值能夠度量隨機變量之間的線性關系和非線性關系,從而可以深度挖掘變量之間的內(nèi)在關系。MIC不僅可以用于標記特征取值離散的情況,也可以用于標記取值是連續(xù)的情況。
如果2個變量之間存在關聯(lián),它們對應的數(shù)據(jù)點的集合分布在二維空間中;如果使用m乘以n的網(wǎng)格劃分數(shù)據(jù)空間,總能找到一種能夠?qū)?個變量的散點圖進行網(wǎng)格劃分的辦法,變量x與y的MIC定義如下:
(2)
式中:I(X;Y)為X與Y的互信息,nx與ny分別為在網(wǎng)格劃分過程中變量X與變量Y被劃分的段數(shù)。
本文湖泊水體和相關氣象數(shù)據(jù)樣本特征變量與溶解氧之間并不一定呈線性關系,而且所有指標特征的取值均為定量的、連續(xù)的,故采用MIC法來計算溶解氧與各特征之間的相關度,將最終選取關聯(lián)程度高的特征作為LSTM預測模型的輸入特征。設溶解氧特征為預測目標Y,分別將各特征設為X。MIC計算主要步驟如下:
(1) 給定i,j,X,Y構成的散點圖進行i列j行網(wǎng)格化,并求出最大的互信息值;
(2) 對最大的互信息值進行歸一化處理;
(3) 選擇不同尺度下互信息的最大值作為MIC值。
1.4 LSTM模型
LSTM模型是將隱藏層替換成LSTM細胞單元,使其具有長期記憶的能力。LSTM的關鍵是細胞狀態(tài),它穿過整個隱藏網(wǎng)絡,LSTM通過門結構控制細胞狀態(tài)添加或者刪除信息,門結構是一種選擇性讓信息通過的方法,是為了保證LSTM 網(wǎng)絡記憶較長時間周期的上下文信息,解決了普通RNN模型中的梯度消失問題。LSTM模型使用Adam算法[41]進行優(yōu)化,通過設置學習率進行權重更新,最后使用測試集來測試模型的性能。LSTM門控模塊結構如圖1所示。

圖1 LSTM門控模塊結構Fig.1 Gating module structure of LSTM model
1.5 PCA-MIC-LSTM模型
為了提高預測速度和精度,結合以上算法,本文提出了基于PCA-MIC-LSTM的碟形湖水體溶解氧預測模型,即基于鄱陽湖碟形湖戰(zhàn)備湖的在線監(jiān)測數(shù)據(jù)(7 803條)。首先,將所有特征數(shù)據(jù)取值均被歸一無量綱化和PCA降噪處理;然后,基于MIC最大信息系數(shù)的特征選取;最終,選用MIC相關系數(shù)不小于0.30[14]的指標特征用于溶解氧的預測,即作為LSTM模型的輸入。算法相關設置如下:LSTM時間步長設置為3,隱層單元數(shù)設置為32,批量大小設置為100,學習率為0.001,迭代次數(shù)設置為50。針對采集的數(shù)據(jù)樣本,將前67%的數(shù)據(jù)用于訓練數(shù)據(jù),其余33%的樣本數(shù)據(jù)作為模型驗證數(shù)據(jù)用于預測。具體預測流程如圖2所示。
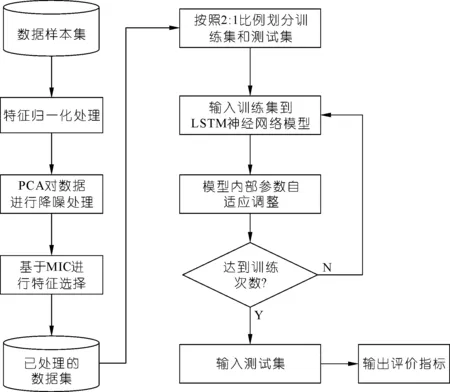
圖2 PCA-MIC-LSTM模型流程Fig.2 Flowchart of PCA-MIC-LSTM model
1.6 模型評價
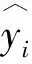
(3)
為了驗證預測模型的精確度和擬合效果,采用了MAPE和R2作為評價指標。MAPE即平均絕對比例誤差,反映了所有樣本的誤差絕對值占實際值的比例,該指標越接近0,得到的模型越準確,其計算公式如式(4)所示:
(4)
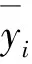
(5)
2 結果與討論
2.1 特征變量的選擇
基于最大信息系數(shù)(MIC),計算出溶解氧與各特征值的相關度,如表2所列。
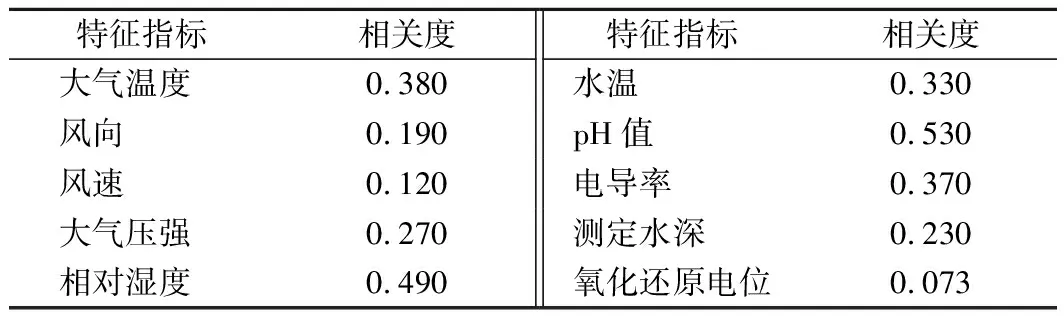
表2 基于MIC算法的各特征值與溶解氧的相關度Tab.2 Correlation between each eigenvalue and dissolved oxygen concentrations based on MIC algorithm
由表2可以看出:pH和相對濕度與溶解氧相關度較高,分別是0.53和0.49,對溶解氧的預測影響較大。而氧化還原電位與溶解氧相關度很低,這與該特征本身取值變動不大有關,從表1中看到其標準差為0.04,特征取值基本不變化,對預測模型的影響可以忽略。為了進一步簡化LSTM模型的運算量,提高其泛化能力和訓練速度,將MIC相關系數(shù)閾值設置為0.3[14],將與溶解氧相關程度較小的特征變量(即MIC<0.3)去掉,最終用于模型訓練的特征變量精簡為大氣溫度、相對濕度、pH、電導率。
2.2 模型比較
為了驗證本文提出模型的有效性,將本文提出的基于PCA降噪處理、MIC特征選取與LSTM結合的方法,與SVR、傳統(tǒng)LSTM等預測模型做對比實驗。SVR算法選擇RBF函數(shù)作為核函數(shù),懲罰系數(shù)C是通過設定一個數(shù)值范圍尋優(yōu)得到,本文采用C=7000。各預測模型結果如表3所列。
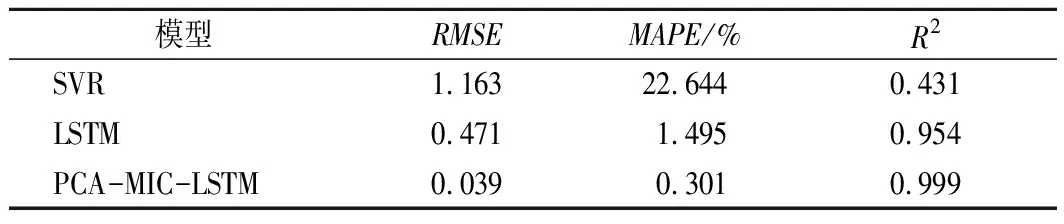
表3 與其他模型溶解氧預測結果的比較Tab.3 Comparison results with other models for predicting DO concentrations
從表3中的數(shù)據(jù)可以看出:傳統(tǒng)的LSTM算法比SVR算法具有更好的預測精度,確定系數(shù)R2由0.431顯著提高至0.954。其均方根誤差RMSE減少了0.692,即DO濃度的預測精度平均提高了59.5%,MAPE由22.644%下降至1.495%,說明LSTM算法的預測精度和擬合效果明顯好于SVR模型。因為樣本數(shù)據(jù)具有時序性,某樣本的溶解氧濃度與該樣本時間前后樣本有較大關聯(lián),SVR算法無法在模型預測時保留之前樣本的信息,而LSTM算法非常適合對時序數(shù)據(jù)的建模。LSTM改變網(wǎng)絡內(nèi)部結構,通過細胞狀態(tài)中的信息遺忘和記憶新信息來影響后續(xù)時刻信息的傳遞[42],可以有效發(fā)掘序列間的非線性關系,從而得到的預測精度更高的模型。
基于PCA-MIC-LSTM的組合方法與傳統(tǒng)的LSTM算法相比,確定系數(shù)R2進一步提高,擬合系數(shù)高達0.999。其均方根誤差減少了0.432,即DO的預測精度比傳統(tǒng)LSTM平均提高了91.72%。這就表明:本文提出的方法在湖泊DO預測精度方面具有非常明顯的提高,經(jīng)PCA和MIC法處理后,MAPE有大幅度降低,由1.495%進一步降低至0.301%,說明本文提出的方法無論是精度還是擬合效果都是相對最優(yōu)的。
從總體樣本中選取33%的數(shù)據(jù)作為測試樣本數(shù)據(jù)集,然后根據(jù)測試樣本數(shù)據(jù)的預測值與真實值進行曲線繪圖。其中,橫坐標表示測試樣本點的序號,縱坐標表示DO濃度值,傳統(tǒng)的LSTM模型預測值與真實值的比較曲線圖和散點圖分別如圖3(a)和圖3(b)所示。
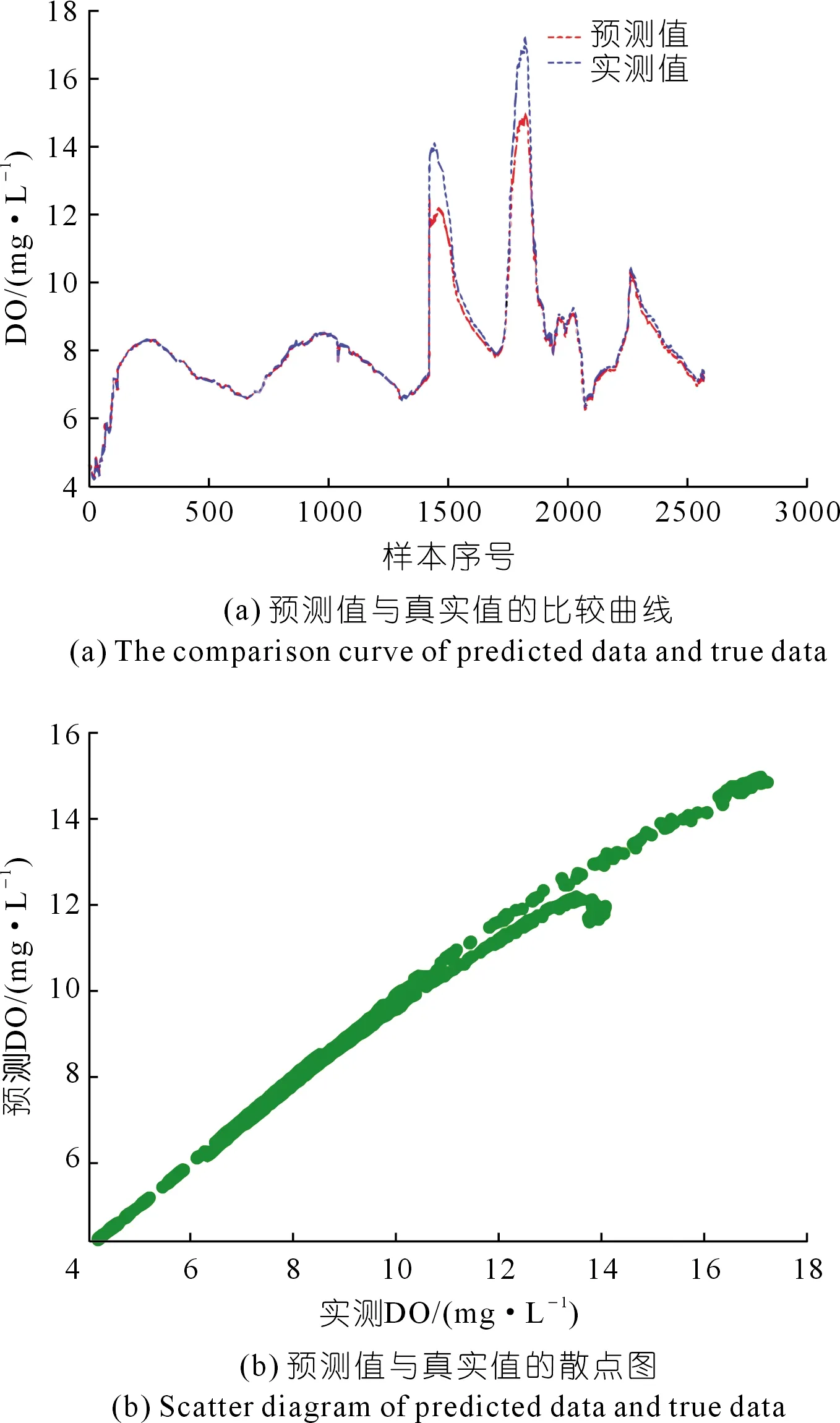
圖3 傳統(tǒng)LSTM溶解氧預測結果Fig.3 Dissolved oxygen prediction results by traditional LSTM
采用PCA-MIC-LSTM模型所得的預測值與真實值,其擬合曲線圖和散點圖如圖4所示。
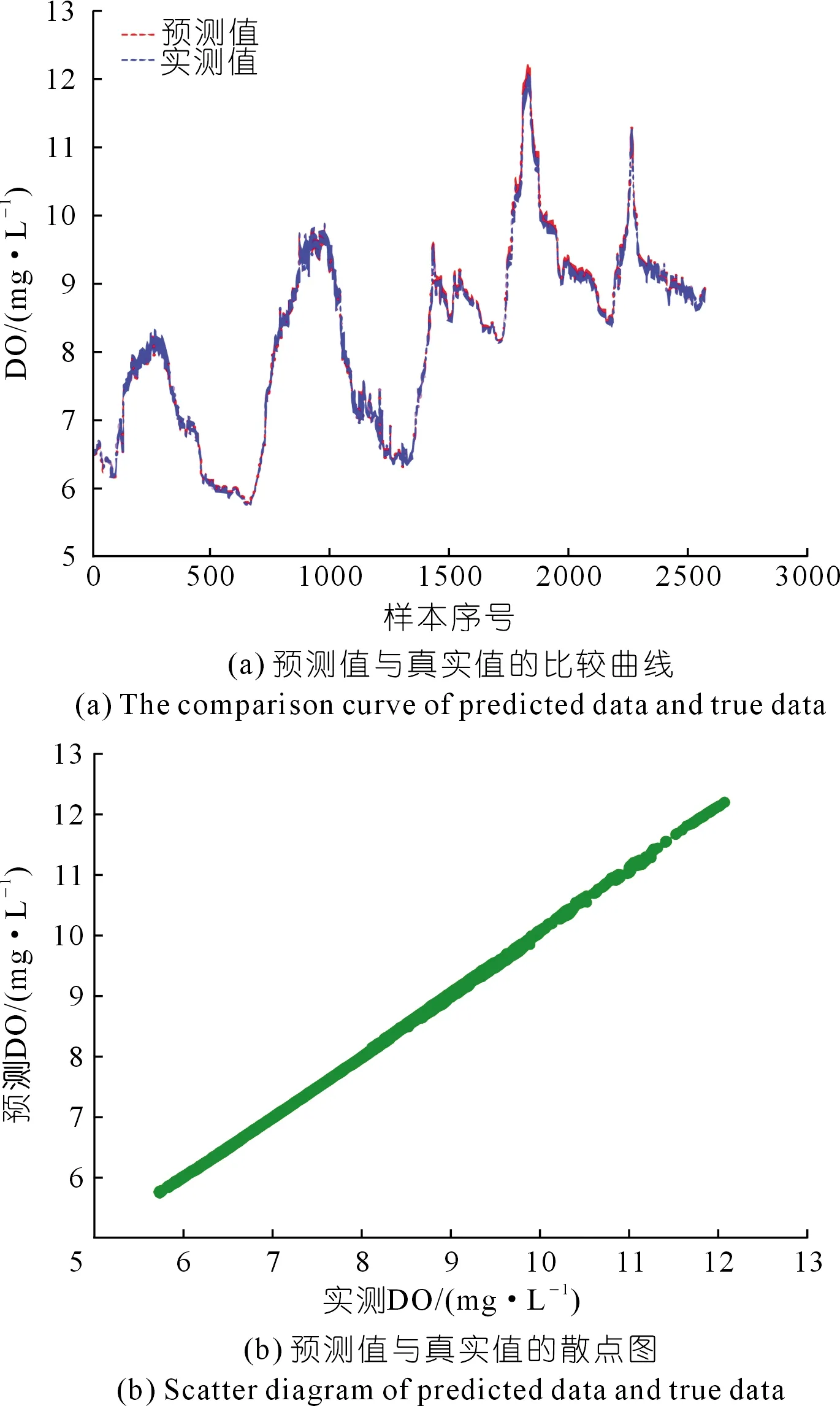
圖4 PCA-MIC-LSTM溶解氧預測結果Fig.4 Dissolved oxygen prediction results by PCA-MIC-LSTM model
通過對圖3和圖4進行對比可以看出:PCA-MIC-LSTM預測結果的擬合精度相對于沒有進行降噪處理及特征選取的傳統(tǒng)LSTM模型來說,有了很大的提高,擬合效果更佳。
綜上所述,本文提出的PCA-MIC-LSTM模型能有效避免數(shù)據(jù)樣本中噪聲的影響,獲得較為理想的預測精度。同時,基于MIC,選擇與溶解氧相關度較高的特征作為LSTM模型的輸入,降低了模型的運算復雜度,取得了理想的擬合效果。
2.3 PCA降噪和MIC特征選取對模型預測的影響對比
為了進一步分析PCA降噪處理和MIC特征選擇對預測精度的影響,本文將兩者作了對比分析,即將未進行數(shù)據(jù)降噪處理和特征提取的傳統(tǒng)LSTM方法記為LSTM;將只進行PCA降噪處理后的樣本使用LSTM模型進行訓練,標記為PCA-LSTM;將只基于MIC法進行特征提取后使用LSTM模型預測標記為MIC-LSTM;對數(shù)據(jù)進行PCA降噪處理和MIC特征提取后再進行LSTM模型預測,記為PCA-MIC-LSTM。模型預測結果具體如表4所列。
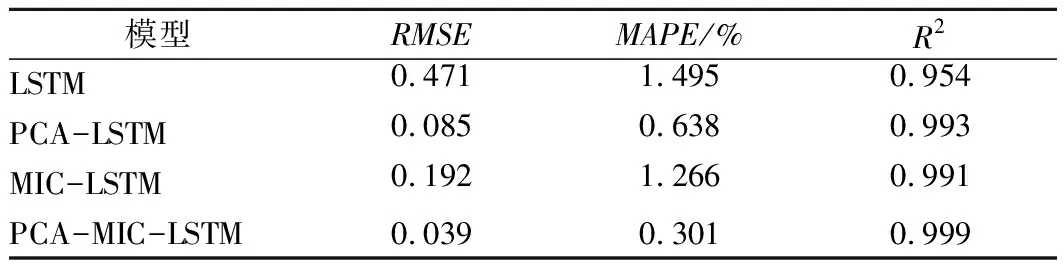
表4 PCA和MIC對LSTM模型的影響Tab.4 Effects of PCA and MIC on LSTM model
從評價指標可以看出:MIC-LSTM預測模型相比LSTM模型降低了59.24%,PCA-LSTM模型相比LSTM模型降低了81.95%。可以看出,針對數(shù)據(jù)進行前處理,顯著提高了溶解氧的預測穩(wěn)定性和準確性。其中,將數(shù)據(jù)進行PCA降噪處理對訓練結果影響更大。這表明樣本數(shù)據(jù)中存在一定的噪聲,會對預測模型的準確率產(chǎn)生一定的影響,采用PCA提取特征主成分,由于噪聲與提取目標本身不相關,從而達到降噪效果,提高了預測模型的準確率和擬合效果。為了更好地改進預測模型,今后可以考慮為采集數(shù)據(jù)的設備配備專門的清洗裝備,以保證數(shù)據(jù)從根源上減少噪聲和冗余等。PCA-MIC-LSTM模型,即本文提出的模型,無論是從穩(wěn)定性、精度和擬合效果方面預測效果都是相對最優(yōu)的,是預測碟形湖水體DO濃度的有效方法。
3 結 論
本文針對碟形湖水體溶解氧的影響因子較多且復雜的情況,結合其時序性和非線性的特點,提出了PCA-MIC-LSTM預測碟形湖泊水體溶解氧濃度的模型。基于戰(zhàn)備湖氣象和物化因子數(shù)據(jù)集來預測DO濃度,通過與SVR和LSTM模型對比,本文提出的PCA-MIC-LSTM模型顯著提高了DO濃度的預測精度。其中,PCA降噪及MIC特征提取處理能夠顯著提高模型的穩(wěn)定性和準確性,有助于開展和完善該類湖泊水體的水質(zhì)監(jiān)控和保護工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環(huán)境(2023年5期)2023-06-30 01:20:01
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
當代水產(chǎn)(2019年1期)2019-05-16 02:42:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
河南科技(2014年23期)2014-02-27 14:19:15
