基于Python的防災(zāi)減災(zāi)大數(shù)據(jù)可視化
2022-07-02 07:50:05蔡智仲曾小雨丘新龍宋仁敏
電腦知識與技術(shù) 2022年15期
關(guān)鍵詞:數(shù)據(jù)采集可視化
蔡智仲 曾小雨 丘新龍 宋仁敏

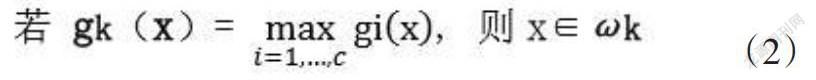

摘要:該文利用Python的網(wǎng)絡(luò)爬蟲技術(shù)所采集到的災(zāi)害數(shù)據(jù),通過災(zāi)害主題挖掘模型來達到將信息正確篩選和提取,并將其內(nèi)容可視化,最后推薦用戶,為用戶提供時效性、準(zhǔn)確性、多樣性的災(zāi)害可視化系統(tǒng)。
關(guān)鍵詞:數(shù)據(jù)采集;災(zāi)情分析;推薦;可視化
中圖分類號:TP311? ? ? 文獻標(biāo)識碼:A
文章編號:1009-3044(2022)15-0013-02
災(zāi)害給國家和人民帶來巨大損失,因此防災(zāi)減災(zāi)成為人們關(guān)注的重點,諸如對于災(zāi)情的發(fā)生,如何獲取相關(guān)數(shù)據(jù),通過大數(shù)據(jù)分析進行篩選正確的內(nèi)容,實現(xiàn)數(shù)據(jù)內(nèi)容的可視化,最終精準(zhǔn)效率進行防災(zāi)減災(zāi)推薦(如投放至相關(guān)部門與用戶手中)成為關(guān)注的熱點。目前最受關(guān)注的全球疫情數(shù)據(jù)來源之一——美國約翰斯·霍普金斯大學(xué)疫情可視化地圖,它的數(shù)據(jù)已經(jīng)成為國際公認(rèn)的最新數(shù)據(jù)權(quán)威來源,定期被世界各地的新聞機構(gòu)和政府機構(gòu)所采用,網(wǎng)站的每天的點擊量超過10億次。又如對于最近的溫嶺槽罐車爆炸事故,如能在最快時間讓政府相關(guān)部門和公眾了解事故,就有可能更大程度減少人民的傷亡等。通過Python的爬蟲技術(shù)采集數(shù)據(jù)后分析數(shù)據(jù),并且將數(shù)據(jù)進行可視化推薦給用戶,讓用戶能更加直觀了解形勢,成為本課題的研究價值和意義[1]。
1 問題分析
1.1 災(zāi)情數(shù)據(jù)采集
基于 python 的網(wǎng)絡(luò)爬蟲技術(shù),同時利用多種爬蟲技術(shù)進行數(shù)據(jù)采集,如:分布式網(wǎng)絡(luò)爬蟲,Scrapy爬蟲等,以完善數(shù)據(jù)樣本。災(zāi)情數(shù)據(jù)的收集儲存主 依托于大數(shù)據(jù)的存儲和檢索系統(tǒng),一種是 No-SQL,另一種大數(shù)據(jù)管理工具是 Hadoop,使用 Spark 進行操作[2]。
1.2 災(zāi)情數(shù)據(jù)分析
主要有兩個方面組成的,一是對災(zāi)害主題挖掘模型,有 LDA 模型和 TFIDF 模型等,其次是災(zāi)害主題分類算法,有樸素葉貝斯算法,KNN算法等。災(zāi)情內(nèi)容的分析利用了聚類分析、傾向性等方法。傾向性分析中從自然語言和機器學(xué)習(xí)的角度進行研究。聚類分析通過話題的檢測技術(shù)對話題進行組織和歸類[3]。
KNN算法:其核心思維是,如果特征空間中距離我們最近的k個樣本中大部分都屬于某個類別,那么這個樣本也屬于這個類別,并且具有該類別樣本的特征利用測量出來的不同特征值之間的距離進行分類這就是KNN算法。它的基本思路是:假設(shè)一個樣本在特征空間中高端k個最相似(也就是特征空間中最相近)的樣本中的大部分屬于某一個類別,則此樣本也屬于這個類別。K的大小通常是小于等于20的整數(shù)。KNN算法中,所選擇好的鄰居都是已經(jīng)正確分類的對象。這個方法在定類決策上僅僅依據(jù)最接近的一個或者幾個樣本的類別來決定待分樣本的類別屬性[4]。
K-近鄰法可以表示為:設(shè)有 N 個已知樣本分屬于 c 個類 ω i,i=1,…,c,考 查新樣本 x 在這些樣本中的前 k 個近鄰,設(shè)其中有 ki 個屬于 ω i 類,則 ω i 類的判別函數(shù)就是(公式1)
1.3 災(zāi)情數(shù)據(jù)內(nèi)容可視化(數(shù)圖共意的災(zāi)害新聞)
災(zāi)害風(fēng)險的視覺化是一個從語言與話語的結(jié)合到視覺修辭的反應(yīng)的連續(xù)過程。一方面,將RST理論用于災(zāi)害新聞的數(shù)據(jù)分析,在視覺修辭下將數(shù)據(jù)修辭和視覺描繪形象化。另一方面,使用可視化工具來將模型進行數(shù)據(jù)的轉(zhuǎn)換。例如,一個稱為可視化的視覺診斷系統(tǒng)被用來可視化分類器的敏感性和特異性之間的權(quán)衡。在這組工具中,我們使用黃色磚塊的rocauc類來可視化分類器的敏感性和特異性之間的權(quán)衡[5]。
1.4 信息個性化智能投遞
實現(xiàn)精準(zhǔn)的個性化服務(wù),先是建立用戶模型,對用戶畫像進行改進,利用現(xiàn)有推薦算法作為召回操作并添加召回方法,利用優(yōu)化算法和特征提取方法對模型進行優(yōu)化,再利用機器學(xué)習(xí)算法的邏輯回歸模型估算點擊率,最后使用用戶繪圖,將圖像與召回數(shù)據(jù)相結(jié)合,采用模型進行預(yù)判。使用開源工具將用戶模型加載到引擎中,并對信息進行優(yōu)化,使結(jié)果更加方便用戶,如圖1所示。
2實施方案
2.1網(wǎng)絡(luò)數(shù)據(jù)采集
首先需要通過爬蟲的技術(shù)在公開的網(wǎng)站上進行爬蟲例如:騰訊新聞網(wǎng)、丁香園等,通過對網(wǎng)站發(fā)出請求,會得到一系列的數(shù)據(jù),當(dāng)中的數(shù)據(jù)有很多是對接下來的操作是沒有用的,因此需要進行一定的篩選,保留下所需要的內(nèi)容[6]。
2.1.1 數(shù)據(jù)存儲
對于數(shù)據(jù)的存儲,我們采用的是MYSQL數(shù)據(jù)庫。在存儲之前,將數(shù)據(jù)進行分類,分為歷史數(shù)據(jù)以及詳細(xì)數(shù)據(jù)兩個大項,在兩個表中會有例如在本次的災(zāi)害中的傷亡情況、人口失蹤情況等的數(shù)據(jù)項,通過每次的數(shù)據(jù)更新我們能夠?qū)崟r采到當(dāng)天的我們采集到當(dāng)天的數(shù)據(jù),并且存放在了數(shù)據(jù)庫中[7]。
2.1.2 數(shù)據(jù)分析利用
通過對數(shù)據(jù)的存儲后,不難發(fā)現(xiàn)在這些數(shù)據(jù)中都是有可以規(guī)劃的,通過對這幾項的數(shù)據(jù)進行內(nèi)容規(guī)劃,能夠?qū)⑦@些數(shù)據(jù)進行可視化的利用。例如將各類數(shù)據(jù)的增長情況通過曲線圖、餅狀圖、折線圖等等來顯示[8]。
2.2 數(shù)據(jù)可視化
2.2.1數(shù)據(jù)可視化的概述
數(shù)據(jù)可視化即利用計算機圖形學(xué)和圖像處理等技術(shù),將數(shù)據(jù)庫中的每一個數(shù)據(jù)項作為圖元素表示,將數(shù)據(jù)的各個屬性以多維數(shù)據(jù)的形式表示,從而將數(shù)據(jù)以形象化的視圖展現(xiàn)出來轉(zhuǎn)換為我們能夠一目了然的可視化的線條變化趨勢和圖像,清晰有效傳達信息,讓人們直觀獲取數(shù)據(jù),了解數(shù)據(jù),給人們提供一個直觀的、便捷的、交互的可視化環(huán)境,大幅度地提高人們對數(shù)據(jù)的感知和理解[9]。
2.2.2數(shù)據(jù)可視化工具
現(xiàn)今有許許多多的數(shù)據(jù)可視化工具,例如:Google Chart、Sigma、ECharts、Vega等,這些工具大體都可以分為三類,一類是面向用戶的可視化系統(tǒng),一類是面向開發(fā)者的可視化庫。
本文使用的是ECharts的數(shù)據(jù)可視化工具,ECharts是國內(nèi)一款優(yōu)良的可視化圖表控件,由Baidu前端數(shù)據(jù)可視化團隊研發(fā),它與大多數(shù)瀏覽器兼容,而且依賴于底部的輕量級的Canvas類庫,供給形象,生動,可互動,可高度個性化定制的可視化的數(shù)據(jù)圖表[10]。8039FACF-0513-41CA-B3B3-E2FAF4178601
2.2.3 數(shù)據(jù)展現(xiàn)和分析
通過數(shù)據(jù)可視化工具ECharts對Python爬取過來的數(shù)據(jù)進行展現(xiàn)和分析,本文利用ECharts繪制了中國地圖和折線圖進行數(shù)據(jù)的展現(xiàn)。
獲取全國地圖數(shù)據(jù)的主要代碼如下:
def get_c2_data():
sql = "select province,sum(confirm) from details " \
"where update_time=(select update_time from details " \
"order by update_time desc limit 1) " \
"group by province"
res = query(sql)
return res
通過觀察全國地圖分布顏色,當(dāng)全國各地范圍內(nèi)出現(xiàn)災(zāi)情時,顏色越深則說明該地區(qū)發(fā)生的情況越不樂觀;通過全國累計趨勢圖能夠反映每天災(zāi)情傷亡情況,能夠清晰地看出災(zāi)情的走向,給人更加直觀的感受;通過全國新增趨勢圖可以直觀發(fā)現(xiàn)在該次的災(zāi)情中每天帶來的人員傷亡情況,側(cè)面也能夠反映出災(zāi)情的嚴(yán)重程度。
當(dāng)以上步驟完成后,我們會利用web工具將上面的內(nèi)容進行整合,利用HTML和CSS技術(shù)呈現(xiàn)給用戶。
3 結(jié)語
最后通過對數(shù)據(jù)的內(nèi)容爬取以及數(shù)據(jù)的分析最終得出的呈現(xiàn)是有參考價值但是不能完全表現(xiàn)出每時每刻的變化。通過對這些數(shù)據(jù)的每次更新和我們可以實時發(fā)現(xiàn)在國內(nèi)外不同時刻發(fā)生的各種大小事情,能夠讓信息更加便捷到達每個用戶的手中,每一個人都能夠知道當(dāng)前的形勢。通過對這些數(shù)據(jù)的分析、可視化,能夠讓人們的生活更加的便捷。此外,在數(shù)據(jù)分析研究這類數(shù)據(jù)能夠提取出各個地區(qū)的情況,能夠快速掌握各個地區(qū)的災(zāi)情程度,了解其狀況,以便各個地區(qū)做出合理、有效的措施以便減少人員傷亡以及財產(chǎn)損失。
參考文獻:
[1] 張偉.5G可視化數(shù)據(jù)新聞帶來融媒體傳播革命[J].中國傳媒科技,2019(12):52-53.
[2] 楊凱.基于Hadoop平臺的個性化新聞推薦系統(tǒng)的設(shè)計與實現(xiàn)[D].北京:北京交通大學(xué),2019.
[3] 楊林.基于標(biāo)記模板的分布式網(wǎng)絡(luò)爬蟲系統(tǒng)的設(shè)計與實現(xiàn)[D].武漢:華中科技大學(xué),2019.
[4] 劉麗群,劉麗華.情感與主題建模:自然災(zāi)害輿情研究社會計算模型新探[J].現(xiàn)代傳播(中國傳媒大學(xué)學(xué)報),2018,40(7):39-45.
[5] 杜臻.基于特征提取和異常分類的網(wǎng)絡(luò)流量異常檢測方法[D].南京:南京郵電大學(xué),2019.
[6] 韓雪華,王卷樂,卜坤,等.基于Web文本的災(zāi)害事件信息獲取進展[J].地球信息科學(xué)學(xué)報,2018,20(8):1037-1046.
[7] 于韜,李偉,代麗偉.基于Python的新浪新聞爬蟲系統(tǒng)的設(shè)計與實現(xiàn)[J].電子技術(shù)與軟件工程,2018(9):188,242.
[8] 田江.基于Python的新聞個性化推薦系統(tǒng)優(yōu)化與實現(xiàn)[D].景德鎮(zhèn):景德鎮(zhèn)陶瓷大學(xué),2018.
[9] 高巍,孫盼盼,李大舟.基于Python爬蟲的電影數(shù)據(jù)可視化分析[J].沈陽化工大學(xué)學(xué)報,2020.
[10] 王子毅,張春海.基于ECharts的數(shù)據(jù)可視化分析組件設(shè)計實現(xiàn)[J].微型機與應(yīng)用,2016,35(14):46-48,51.
【通聯(lián)編輯:光文玲】8039FACF-0513-41CA-B3B3-E2FAF4178601
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
農(nóng)業(yè)與技術(shù)(2016年15期)2016-11-09 17:43:03
科技視界(2016年18期)2016-11-03 22:51:40
中國科技博覽(2016年22期)2016-11-01 16:58:26
軟件工程(2016年8期)2016-10-25 15:54:18
