文本分類中TF-IDF算法的改進研究
2022-07-04 02:54:40吳宗卓
計算技術與自動化 2022年2期
吳宗卓
關鍵詞:文本分類;特征選擇;CHI平方統計;TFIDF;分類準確性
隨著在線信息的快速發展,如何有效地處理大量文本成為一個熱門的研究課題,文本分類是其中的關鍵任務之一。文本分類是將新文檔分配給預先存在的類別,并且已廣泛用于許多領域,如信息檢索、電子郵件分類、垃圾郵件過濾、主題定位。
近年來,大多數研究集中在尋找新的分類算法上,對信息檢索的文獻表示模型的改進研究很少。傳統模型有三種:向量空問模型、概率模型、推理網絡模型。向量空問模型把對文本內容的處理簡化為向量空間中的向量運算,并且它以空間上的相似度表達語義的相似度,直觀易懂,使用最廣泛。在向量空間模型中,有一些常用的加權方法,如布爾加權、頻率加權、TF-IDF加權、TFC加權、LTC加權、熵加權,其中TF-IDF加權是其中使用最廣泛的一種。
提出了對向量空間模型的TF-IDF加權算法的改進算法。TF-IDF考慮術語頻率(TF)和逆文檔頻率(IDF),在這種方法中,如果術語頻率高并且該術語僅出現在一小部分文檔中,那么這個術語具有很好的區分能力,這種方法強調能夠更多地區分不同的類,但忽略了這樣一個事實,即經常出現在屬于同一類的文檔中的術語可以代表該特征。因此引入一個新的參數來表示類內特性,然后進行了一些實驗來比較效果,結果顯示這種改進具有更好的準確性。
1文本分類步驟
文本分類通常包括5個主要步驟:文檔預處理、文檔表示、降維、模型訓練、測試和評估。
1.1文檔預處理
在這一步中,需要刪除html標簽、稀有單詞、停用詞,并且需要標注一些詞干,這在英語中很簡單,但在中文、日語和其他一些語言中很難。通過文本預處理后,文檔內部的噪音數據就被剔除。文檔在內容方面就能進行分類使用了。
1.2文件表示
在進行分類之前,需要將文檔轉換為計算機可以識別的格式,矢量空間模型(VSM)是最常用的方法。此模型將文檔作為多維向量,并將從數據集中選擇的特征作為此向量的維度。其中每一個維度對應一個特征詞,如果某個特征詞存在于某個文檔中,那它在矢量空間模型的向量中的值為非零。
1.3降維
因為在文檔中,有成千上萬的單詞,不做處理的話就有成千上萬個特征詞。如果選擇所有單詞作為特征,那么進行分類是不可行的,因為計算機無法處理這樣的數據量。因此需要選擇那些最有意義和最具代表性的分類特征作為特征詞,最常用的特征選擇方法包括CHI平方統計、信息增益、互信息、文檔頻率、潛在語義分析。
1.4模型訓練
這是文本分類中最重要的部分。寫好改進算法的代碼之后,通過從語料庫中選擇一部分文檔以組成訓練集,剩下文檔作為測試集。在訓練集上執行學習,然后生成模型。
1.5測試和評估
此步驟使用從步驟4生成的模型,并對得到的測試集執行分類,最后選擇適當的索引進行評估。
2 TF-IDF
在向量空間模型中,TF-IDF(術語頻率一逆文檔頻率)是一種廣泛使用的加權方法,TF-IDF算法是基于這種假設的:對于最優特征詞來說,這些特征詞在一類或一部分文檔中大量出現,而在其他文檔中很少出現或者不出現。所以使用術語頻率TF就可以劃分相同文本。
另外,考慮一個特征詞在所在文本當中的重要程度,認為一個文本中,特征詞出現次數越高,特征詞就越重要,因此引入了逆文檔頻率IDF。以術語頻率TF和逆文檔頻率IDF的乘積作為向量空間模型的取值測度。不過在本質上IDF是避免噪音數據的一種加權手段,同時認為文本量少就重要,文本量多就不重要,這明顯是有不完全正確的。所以該算法的精度并不高。
TF-IDF沒有考慮不同文件長度對加權的影響,為了改進這一點,提出了TFC,它實際上是公式(1)的標準化。同時當N等于n時,a變為零,這通常出現在小數據集中。為防止計算中出現零的結果需要改進公式(1),TFC如下所示:
LTC是TF-IDF的一種不同格式,它考慮了小數據集的限制,它實際上是公式(2)的歸一化。公式為:
3 TF-IDF-IF
關于TF-IDF的缺點,引入了一個新的參數來表示類內特征,稱之為類頻率,它計算一個類中文檔中的術語頻率。然后將這個新的加權方法重命名為TF-IDF-IF,其公式基于公式(2):
該方法通過引入類中文檔中的術語頻率,可以緩解IDF認為文本量少就重要、文本量多就不重要的問題。
4實驗和分析
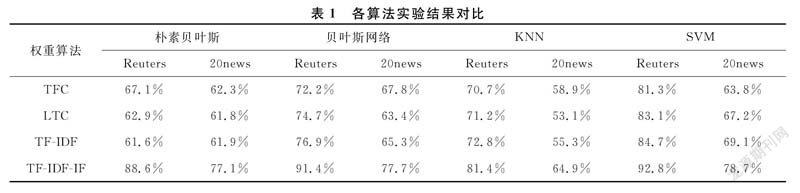
在實驗中,選擇使用常用的路透社Reuters數據集和20newsgroup數據集。在繼續之前,進行一些預處理,例如刪除html標簽,過濾無效字符,刪除停用詞。在此處理之后,對于路透社,選擇了6088個訓練樣本,2800個測試樣本共59個類別。對于20newsgroup,選擇8000個訓練樣本,2000個測試樣本共20個類。然后使用CHI卡方統計特征選擇方法來選擇1000個特征,然后分別使用TF-IDF、TF-IDF-CF、LTC、TFC方法在一些常用的分類器如樸素貝葉斯、貝葉斯網絡、KNN、SVM中進行實驗。實驗結束后,比較了TF-IDF-IF與TF-IDF,LTC,TFC的結果。
4.1CHI卡方統計
卡方統計是一種非常有用的文本分類特征選擇方法,它可以測量特征和類之間的相關性。設N是訓練樣本文本總數,A是文本集中包含特征t且在類別c中的文本個數,B是文本集中包含特征t在但不屬于類別c的文本個數,D是文本集中屬于類別c但不包含特征t的文本個數,E是文本集中不包含特征t也不在類別c中的文本個數。卡方統計可以描述為:
當卡方統計量y2(t,c)=0時,表示特征和類別沒有關系,即特征和類別相互獨立。卡方統計量x2(t,c)越大表示兩者關系越密切。
4.2實驗
基于這兩個數據集,使用CHI平方統計方法來選擇1000個特征,然后使用一些常用的算法如樸素貝葉斯,貝葉斯網絡,KNN,SVM在一個著名的數據挖掘工具WEKA上進行實驗,只考慮比較結果時的分類準確度:
4.3分析
從表1的實驗結果可以看出,改進的TF-IDF-CF加權方法在路透社Reuters和20newsgroup中具有最佳精度,與原始TF-IDF加權方法相比,精度大大提高。雖然TFC和LTC在像樸素貝葉斯這樣的分類器上比TF-IDF有更好的結果,但它不像TF-IDF那樣有意義,所以它們通常不用于計算加權。新方法大大提高精度的原因是TF-IDF只強調區分不同類的能力,但低估了表示類本身的能力。在一個類的文檔中出現的術語越多,該術語代表該類的重要性就越大。從理論和實驗中,可以看到這種改進可以達到更好的準確性。
5結論
文本分類是當前信息檢索的熱門研究課題,是數據挖掘和信息檢索的重要分支。如何提高分類準確率是文本分類中的一個重要課題,為了解決這個問題,已經做了大量的研究來尋找能夠提高準確性的新分類器,而本文試圖通過提出改進TF-IDF加權方法來提高準確性。從實驗中可以看出這種改進顯著提高了準確性,因此認為這種改進是可以接受的。
