基于EEMD-LSTM的森林火災成災面積預測模型
2022-07-04 07:05:34徐艷杰
農業與技術 2022年12期
關鍵詞:模型
徐艷杰
(內蒙古森林消防總隊興安盟支隊,內蒙古 興安盟 137400)
1 研究背景
森林火災是一種隨機性強、破壞性大的自然災害,對林業發展和生態環境保護影響惡劣,同時造成了較為嚴重的生命和財產損失[1]。我國是森林火災發生頻次高、受災面積廣的國家之一,2007—2017年我國森林火災平均成災面積達26467hm2,各省市均經歷了不同程度的森林火災。由于全球氣候不斷變暖,加之火災還受到地形和人為等眾多因素的干擾和影響,林火發生概率逐漸提高[2]。因此,構建準確的森林火災成災面積預測模型,可以為林火預防工作提供指導,從而減少相應損失。
目前針對森林火災面積預測方面,一些學者開展了相關研究。沈姣姣等[3]采用聚類分析對陜西省森林火災成災面積、次數等特征進行分析,考慮溫度、濕度等氣候因素,建立了森林火災面積預測模型,模型正確率超過70%。汪文野等[4]從時間和空間尺度進行了氣候條件分析,建立了深度學習算法-森林火災面積預測模型,研究表明預測模型的數據泛化能力提升,預測精度較高。徐海龍等[5]根據主成分分析消除了所選取10個氣象因子之間的共線性關系,利用多元回歸構建了森林火災成災面積預測模型,結果表明模型的相關系數為0.66,預測結果較為符合實際情況。黃家榮等[6]建立了3層神經網絡森林火災面積預測模型,引入變結構法確定了預測模型的主要參數,預測結果與實際受災面積吻合度較好,為森林火災預防提供了一種較為可靠的方法。
針對森林火災發生具有隨機性和不確定性等特點,且受到諸多因素的影響,森林火災成災面積時間序列往往具有較大的波動性,屬于非平穩時間序列[7]。因此,本文將集合經驗模態分解EEMD和長短期記憶網絡LSTM相結合,提出了基于EEMD-LSTM的森林火災成災面積預測模型,根據集合經驗模態分解EEMD將樣本數據分解,采用長短期記憶網絡LSTM對分解后的各分量進行預測并將各分量預測結果疊加重構。基于1992—2017年我國森林火災成災面積對上述所建預測模型應用驗證,并與BP和LSTM神經網絡模型的預測結果進行比較,所建EEMD-LSTM預測模型的平均絕對誤差MAE和均方根誤差RMSE最小,驗證了該模型在森林火災成災面積預測方面具有更高的預測精度。
2 算法介紹
2.1 EEMD算法
集合經驗模態分解EEMD(Ensemble Empirical Mode Decomposition,EEMD)是一種新型自適應信號處理方法,廣泛應用于從噪聲非線性和非平穩過程中產生的數據提取信號。集合經驗模態分解EEMD將樣本數據分解成多個本征模函數IMF(Intrinsic Mode Function)和趨勢項RES(Trend Items),實現非平穩數據序列的平穩化處理,具體過程如下。
生成幅值為k的白噪聲序列n(t),設置EMD分解運算的總次數M和初始迭代次數m=1。
進行第m次EMD運算,分解流程如下。
①將生成的白噪聲序列nm(t)加入森林成災面積時間序列x(t),得到新的森林成災面積時間序列xm(t):
xm(t)=x(t)+k×nm(t)
(1)
②循環變量初始化:
i=1,j=1,x1(t)=x(t),y1(t)=xi(t)。
③對森林成災面積時間序列yj(t)的局部極大值點進行統計,根據3次樣條插值擬合形成上包絡線lj(t);同理,對局部極小值點進行統計擬合形成下包絡線nj(t),求出2條線的均值pj(t):
(2)
④計算森林成災面積時間序列yj(t)與pj(t)的差值hj(t):
hj(t)=yj(t)-pj(t)
(3)
⑤根據EMD分解的要求對hj(t)進行判斷,滿足條件則得到分解量Ci(t),不滿足則重復上述③和④,Ci(t):
Ci(t)=hj(t)
(4)
⑥計算剩余分解量ri(t):
ri(t)=xi(t)-Ci(t)
(5)
⑦循環i和j進行計算,得到n個IMF分量和1個剩余分量:
Ci,m(t)=hj,m(t),i=1,2,…,n
(6)
rn,m(t)=rn-1,m(t)-Cn,m(t)
(7)
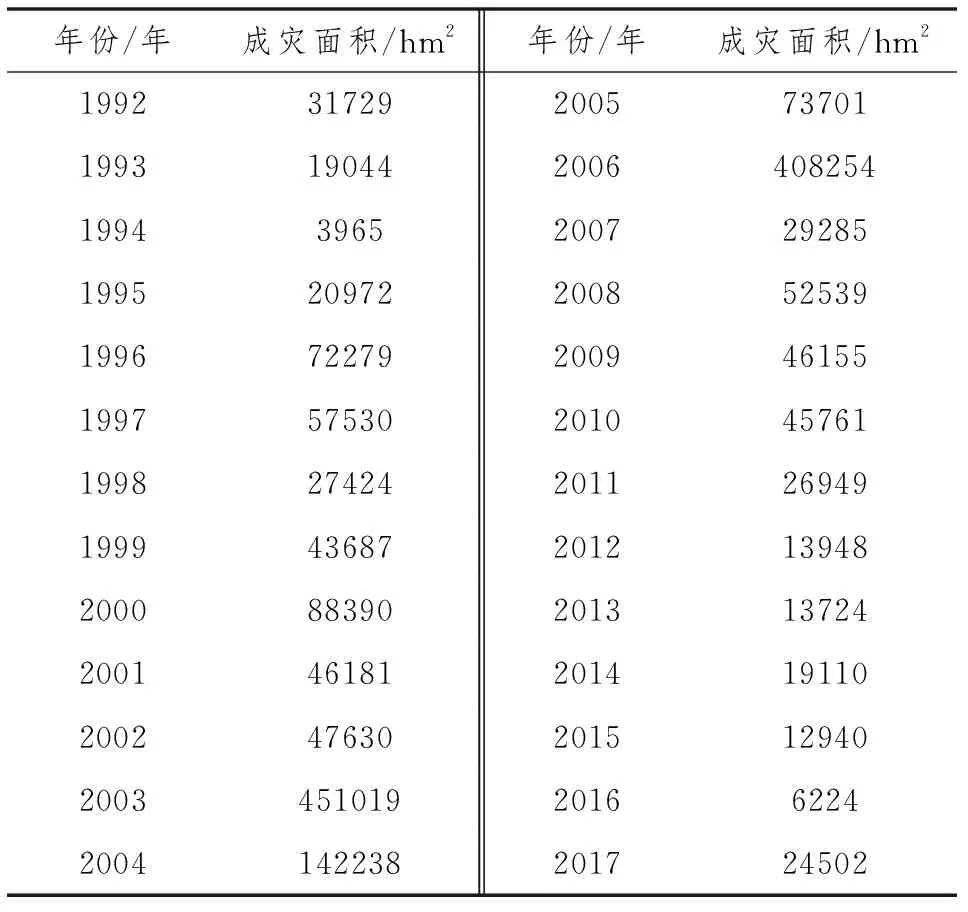
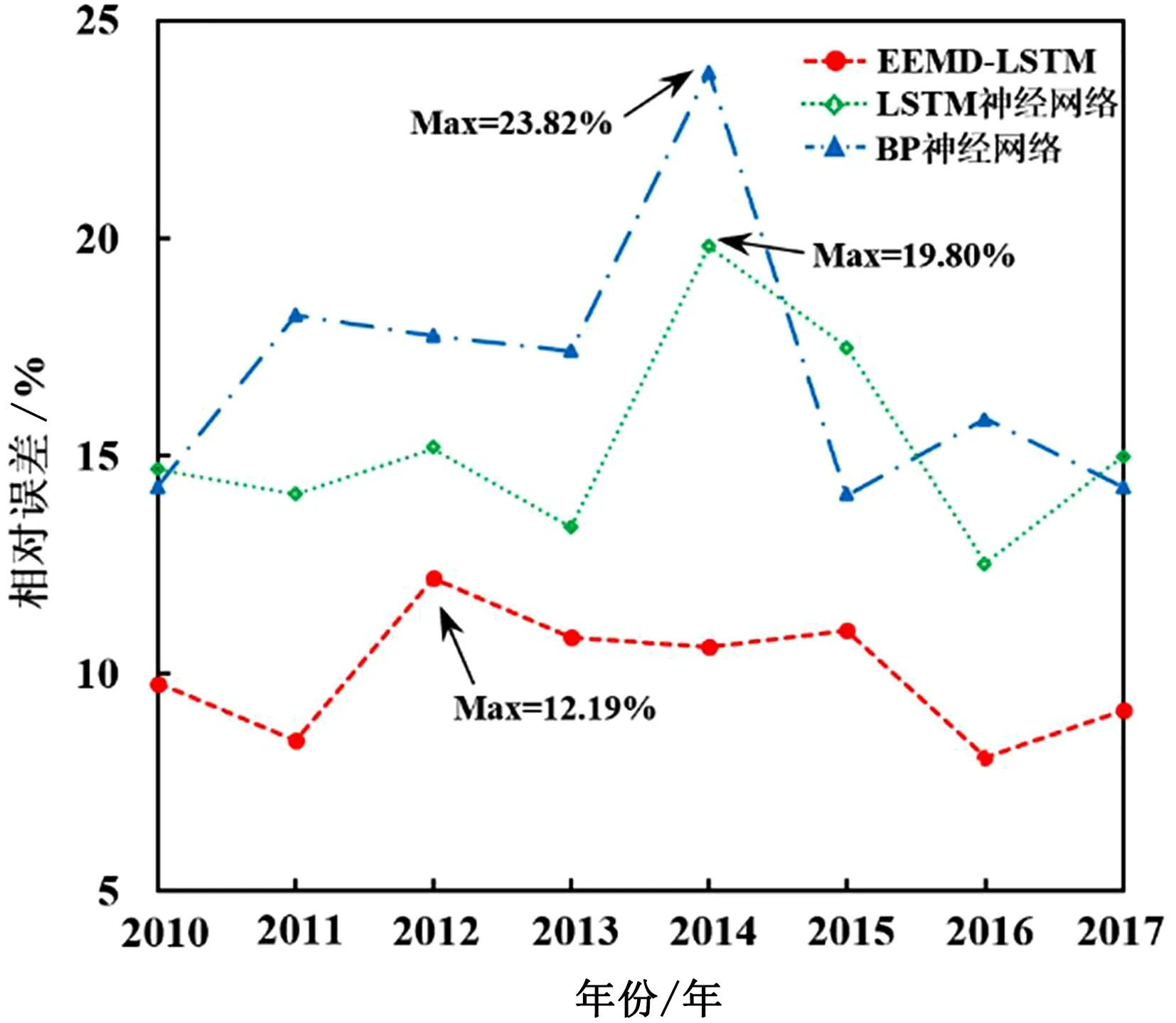
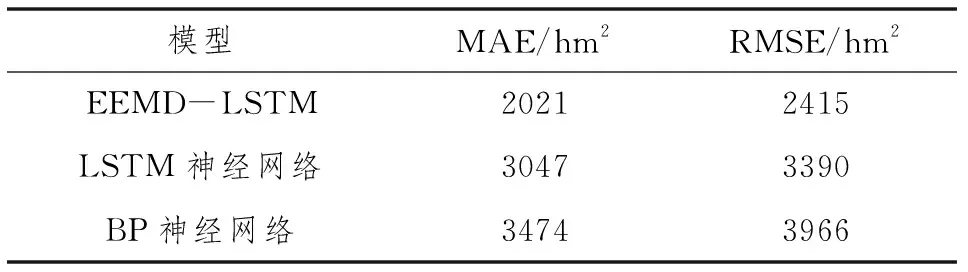
⑧如果m 長短期記憶網絡(Long Short-Term Memory,LSTM)是一類機器學習智能算法,廣泛應用于信號建模、時間序列預測等研究,能夠有效解決循環神經網絡RNN所帶來的一系列梯度問題影響。長短期記憶網絡LSTM主要由3種門狀態組成,具體內容見圖1。 長短期記憶網絡LSTM具體計算公式: ft=σ(ωf[qt-1,xt]+bf) (8) it=σ(ωi[qt-1,xt]+bf) (9) s′t=tanh(ωc[qt-1,xt]+bc) (10) st=ftst-1+its′t (11) ot=σ(ωo[qt-1,xt]+bo) (12) qt=ot×tanh(st) (13) 式中,ft表示遺忘門的輸出;it表示輸入門的輸出;s′t表示前一時刻細胞狀態;st表示當前時刻細胞狀態;ot表示輸出門的輸出;qt表示t時刻單元輸出;xt表示t時刻的輸入;σ表示sigmoid函數;ωf、ωi、ωc、ωo分別表示對應門或細胞狀態的權重值;bf、bi、bc、bo分別表示對應門或細胞狀態的偏移值。 將1992—2017年共計26個年份的全國森林火災成災面積作為本文預測模型的輸入樣本,資料選自《中國林業統計年鑒》,具體見表1。 表1 1992—2017年全國森林火災成災面積數據 將1992—2009年的樣本數據作為訓練集,2010—2017年的樣本數據作為測試集。采用集合經驗模態分解EEMD對全國森林火災成災面積數據時間序列有效分解,將分解后的各分量分別代入LSTM模型進行預測,將所有分量預測的數據進行組合重構,得到EEMD-LSTM模型的預測結果。為驗證所建EEMD-LSTM模型的預測性能和可靠性,分別采用BP和LSTM神經網絡模型對森林火災成災面積時間序列進行預測。3種模型預測結果的相對誤差如圖2所示。 圖2 3種模型預測結果的相對誤差對比 從圖2可以看出,EEMD-LSTM模型預測結果的相對誤差較為穩定,最大相對誤差出現在2012年,其值為12.19%,2010年、2011年、2016年、2017年4個年份預測結果的相對誤差小于10%。另外2個模型預測結果相對誤差的波動變化較為明顯,尤其是從2014—2015年,LSTM模型預測結果的相對誤差從最大值23.82%變化為不到15%。整體而言,EEMD-LSTM模型的相對誤差明顯小于BP和LSTM模型的相對誤差,除2014年外,LSTM模型各年份的相對誤差均小于BP模型的相對誤差。 采用常見的評價指標平均絕對誤差MAE和均方根誤差RMSE,3個模型的具體計算結果見表2。 表2 3種模型預測精度對比 由表2可知,EEMD-LSTM模型預測結果的平均絕對誤差MAE和均方根誤差RMSE分別為2021hm2和2415hm2,根據2個預測結果評價指標可知,模型預測精度排序:EEMD-LSTM>LSTM神經網絡>BP神經網絡。從平均絕對誤差MAE考慮,相較于LSTM神經網絡和BP神經網絡,EEMD-LSTM模型的預測性能分別提高了33.7%和41.8%。從均方根誤差RMSE考慮,相較于LSTM神經網絡和BP神經網絡,EEMD-LSTM模型的預測性能分別提高了28.8%和39.1%。由此可知,EEMD-LSTM模型的預測結果準確性明顯高于另外2種模型,原因在于集合經驗模態分解EEMD將非平穩的森林成災面積時間序列轉化為多個不同變化規律的分量,各分量預測值重構后的預測結果較為準確,有效降低了預測的誤差,從而保障了預測精度。 考慮到集合經驗模態分解EEMD能夠將非平穩時間序列分解成具有不同變化規律的分量,基于先分解后重構的思想,將該方法與LSTM神經網絡相結合,建立了EEMD-LSTM森林成災面積預測模型,基于1992—2017年全國森林火災成災面積數據,將所建模型與單一BP和LSTM神經網絡模型進行比較驗證。研究結果表明,EEMD-LSTM模型預測結果的相對誤差較為穩定且明顯小于BP和LSTM神經網絡模型的相對誤差。EEMD-LSTM森林成災面積預測模型平均絕對誤差MAE的預測性能分別提高了33.7%和41.8%,均方根誤差RMSE的預測性能分別提高了28.8%和39.1%。相較于另外2個模型,EEMD-LSTM模型能夠更為準確地預測森林成災面積,為森林火災預測提供了一種新的方法。2.2 LSTM算法
3 實例應用
4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
