基于多頭注意力機制的端到端語音情感識別
2022-07-05 10:10:18楊磊趙紅東于快快
計算機應用 2022年6期
楊磊,趙紅東*,于快快
基于多頭注意力機制的端到端語音情感識別
楊磊1,趙紅東1*,于快快2
(1.河北工業大學 電子信息工程學院,天津 300401; 2.光電信息控制和安全技術重點實驗室,天津 300308)(*通信作者電子郵箱zhaohd@hebut.edu.cn)
針對語音情感數據集規模小且數據維度高的特點,為解決傳統循環神經網絡(RNN)長程依賴消失和卷積神經網絡(CNN)關注局部信息導致輸入序列內部各幀之間潛在關系沒有被充分挖掘的問題,提出一個基于多頭注意力(MHA)和支持向量機(SVM)的神經網絡MHA-SVM用于語音情感識別(SER)。首先將原始音頻數據輸入MHA網絡來訓練MHA的參數并得到MHA的分類結果;然后將原始音頻數據再次輸入到預訓練好的MHA中用于提取特征;最后通過全連接層后使用SVM對得到的特征進行分類獲得MHA-SVM的分類結果。充分評估MHA模塊中頭數和層數對實驗結果的影響后,發現MHA-SVM在IEMOCAP數據集上的識別準確率最高達到69.6%。實驗結果表明同基于RNN和CNN的模型相比,基于MHA機制的端到端模型更適合處理SER任務。
語音情感識別;多頭注意力;卷積神經網絡;支持向量機;端到端
0 引言
近年來,語音情感識別(Speech Emotion Recognition,SER)作為人機交互的重要媒介,引起越來越多國內外研究人員的關注。人類的情感在人類交流中一直扮演著重要角色,SER是指對隱藏在人類對話中的情感變化進行分析,通過提取語音的相關特征并將其輸入神經網絡中進行分類,從而識別說話者可能的情感變化。現實中SER有著廣泛的應用場景,如客服人員在與客戶電話溝通過程中,通過SER系統實時跟蹤客戶的情緒變化,以便更加主動地提供優質服務。由于情感的表達依賴于諸多因素,如說話者的性別、年齡、方言等,所以研究人員面臨的一個主要挑戰是如何更好地提取具有區別性、魯棒性和顯著影響力的特征,以提高模型的識別能力。目前,特征提取方式主要分為兩類:一類是從音頻信號中手動提取相關的短期特征,如梅爾頻譜倒譜系數、音高和能量等,然后將短期特征應用于傳統分類器,如高斯混合模型、矩陣分解和隱馬爾可夫模型等;另一類是使用神經網絡自動提取特征,如卷積神經網絡(Convolutional Neural Network, CNN)、自動編碼器、循環神經網絡(Recurrent Neural Network, RNN)、長短時記憶(Long Short-Term Memory, LSTM)模型、CNN+LSTM的組合等,文獻[1-2]的研究表明,這些方法在語音分類任務中都取得了很好的效果。
隨著人工智能和硬件計算能力的提高,深度學習方法在音頻分類上的應用越來越廣泛。深度學習具有優秀的學習和泛化能力,能夠從大量訓練樣本中提取與任務相關的分層特征表示,在自動語音識別和音樂信息檢索[3-4]領域的研究工作中取得了巨大成功。文獻[5]中首先使用CNN學習語音情感顯著特征,并在幾個基準數據集上展示了CNN的優異性能。文獻[6]中使用一維CNN對音頻樣本進行預處理,目的是降低噪聲并強調音頻文件的特定區域。由于音頻信號可以在時域中傳遞上下文信息,即當前時刻的音頻信息與前一時刻的信息相關,因此在SER任務中可以應用RNN和LSTM捕捉與時間相關的特征表示。文獻[7]中提出了一種框架級語音特征結合注意力和LSTM的SER方法,該方法可以從波形中提取幀級語音特征來代替傳統的統計特征,從而通過幀序達到保持原始語音內部時序關系的目的。文獻[8-9]中將CNN和LSTM相結合挖掘輸入序列的時空特征,這也是語音情感分類任務中常見的一類處理方式。文獻[10]中進一步提出了基于注意力機制的卷積循環神經網絡,并以梅爾譜圖(Mel-spectrogram)作為輸入,有效提高了模型的識別能力。文獻[11]中采用基于注意力的雙向長短時記憶(Bi-directional LSTM, Bi-LSTM)模型與基于注意力的CNN并行組合的排列方式搭建網絡,用來學習特征,并結合VGG16進行梅爾譜圖的預處理,實現了較高的識別準確率,但模型規模相對較大,增加了訓練難度。這些模型的提出表明了注意力機制與神經網絡結合的有效性。
注意力機制是近年來序列-序列領域的一個熱門話題。作為一種注意力機制,自注意力通過學習輸入序列中幀與幀之間的潛在關系,捕捉整個輸入序列的內部結構特征。Transformer[12]是一種完全基于自注意力機制的序列模型,它在許多自然語言處理任務中表現出優異性能。與傳統的RNN相比,Transformer可以同時應用多個自注意力機制并行處理輸入序列上的所有幀,然后通過一定變換,最終映射成能代表整個輸入序列的注意力值。一些基于Transformer架構的方法,如預訓練語言模型[13-14]和端到端語音識別方法[15]證明了Transformer識別性能優于LSTM。支持向量機(Support Vector Machine, SVM)是一種監督學習方法,擅長處理具有小規模樣本、非線性和高維模式識別等特點的分類任務,它通過非線性映射將原始樣本從低維特征空間變換到高維特征空間甚至無限維特征空間(希爾伯特空間),利用徑向核函數構造高維空間的最優超平面,實現樣本的線性分離。受上述分析的啟發,針對語音情感數據集規模小、維度高的特點,本文提出了一種基于多頭注意力(Multi-Headed Attention, MHA)融合SVM的模型MHA-SVM來實現語音情感分類任務。為說明SVM適合處理語音情感分類任務,本文還給出了最鄰近法(-Nearest Neighbor,NN)和邏輯回歸法(Logistic Regression, LR)分類器的實驗結果。NN的思想是將個最近樣本中頻率最高的類別分配給該樣本;LR是在訓練數據的基礎上建立決策邊界的回歸方程,然后將回歸方程映射到分類函數來實現分類目的。實驗結果表明,相比NN和LR,本文提出的MHA-SVM在IEMOCAP數據集上可以進一步提升多頭注意力機制的分類效果。
本文的主要工作有:
1)使用Transformer模型的編碼模塊搭建一個基于MHA的情感分類模型,利用并行處理結構來高效地學習分類特征,模型的分類性能優于以往的RNN模型。
2)針對語音情感數據集的特點,嘗試以MHA為特征提取器,SVM為任務分類器,二者的融合可以將MHA的分類效果提升1.9個百分點。為說明SVM的適用性,本文將SVM和其他兩個分類器NN和LR進行對比實驗,實驗結果表明基于多頭注意力機制和SVM的端到端模型非常適合處理SER問題,可以提高模型識別性能。
1 相關研究
在SER系統中,特征輸入、特征提取和融合網絡是模型獲得更好性能的重要保證,因此本文將回顧與上述過程相關的一些關鍵概念和技術。
1.1 卷積層
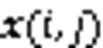
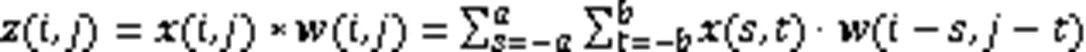
1.2 注意力機制
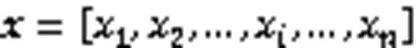
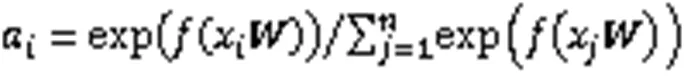
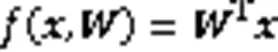
然后計算出輸入序列的加權平均和,從而取得整個序列注意力值,數學表達為
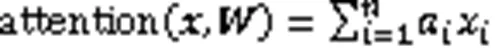
這種計算注意力的方式也被稱為軟注意力機制。
1.3 多頭注意力機制
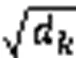
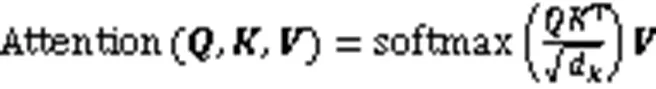
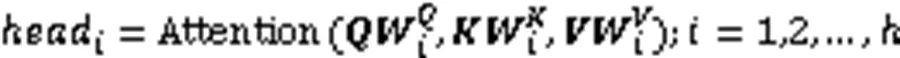
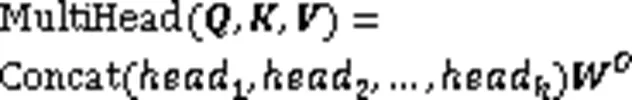

圖1 放縮點積注意力結構
1.4 位置編碼
音頻的信息表達依賴于音頻序列中幀的位置,所以位置編碼對于音頻序列至關重要。在RNN中,位置信息可以被自動記錄在網絡隱藏層中,而Transformer由于未采用循環結構,為保留輸入序列的順序信息,需要對輸入序列內的每一幀進行位置編碼,計算過程見式(8)、(9)。
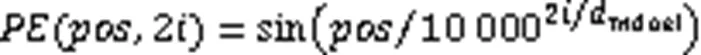
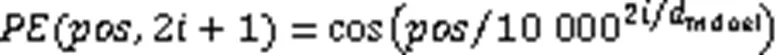
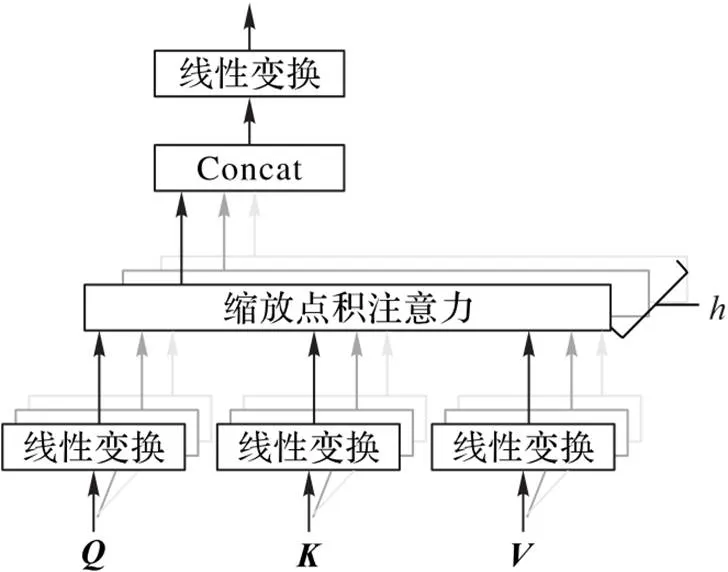
圖2 多頭注意力結構
1.5 支持向量機
為解決低維度空間線性不可分的問題,SVM使用核函數將數據從低維度的樣本空間映射到高維度的特征空間中,然后在特征空間中尋找一個超平面實現樣本線性可分[16]。非線性可分的SVM優化問題可描述為
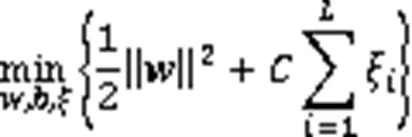

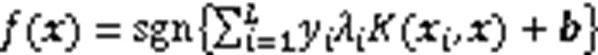
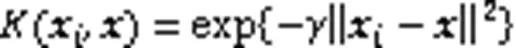
2 模型構建
2.1 數據集
IEMOCAP數據集由10個專業演員(5名女性和5名男性)進行12 h的音頻和視頻錄制,并在兩個不同性別的演員之間以演奏劇本或即興表演的方式進行5次對話。這些收集到的錄音被劃分為長度在3~15 s的短語句,每個語句被標注為10種情緒之一(中性、快樂、悲傷、憤怒、驚訝、恐懼、厭惡、沮喪、興奮和其他)。本文實驗只使用音頻數據,為與前人的作品[17-19]進行一致的比較,將所有標有“興奮”的話語與標有“高興”的話語合并為“高興”類別,且只考慮四種情緒類別(中性、高興、悲傷、生氣)。由表1可以看出類別間數據分布不平衡。

表1 IEMOCAP數據集類別情況
音頻信號的采樣率直接影響輸入樣本的維數,并最終影響模型的計算量。本文實驗以11 025 Hz的采樣率對輸入的原始語音信號進行采樣[20],以160個采樣點為一幀將每個樣本依序截取成277幀。考慮到數據集中樣本長短不一致,采用補零和截斷策略,將樣本的一維信號統一變換成大小為(277,160)的二維信號,取樣過程見圖3。
圖3 分幀圖
2.2 Transformer層
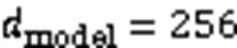
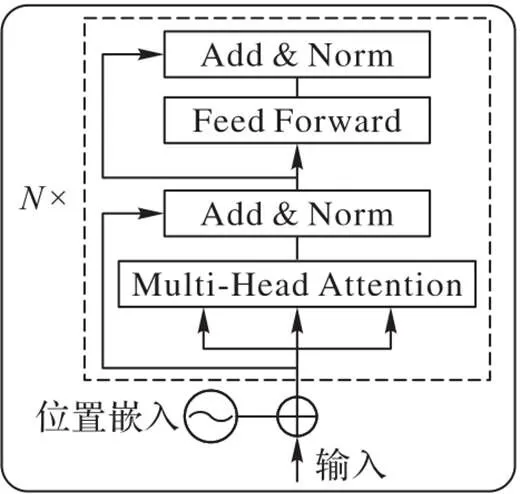
圖4 Transformer層結構
2.3 MHA-SVM模型
本文提出的端到端架構可以直接從原始音頻信號中學習特征表示,并在不同的語音上取得良好的分類性能,模型結構如圖5所示。
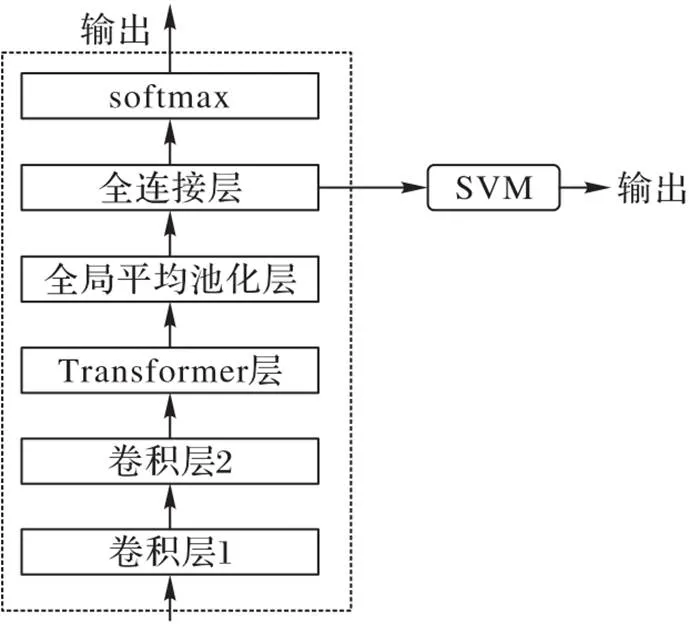
圖5 MHA-SVM結構
首先,對輸入原始波形應用兩個具有小濾波器尺寸的卷積層,以便提取局部特征;然后進入Transformer層,通過全連接層和softmax層得到MHA的分類結果和模型參數設置;最后將已訓練的MHA作為預訓練模型,原始波形輸入MHA中用于提取特征并訓練SVM分類器,得到SVM的分類結果。MHA的參數見表2。
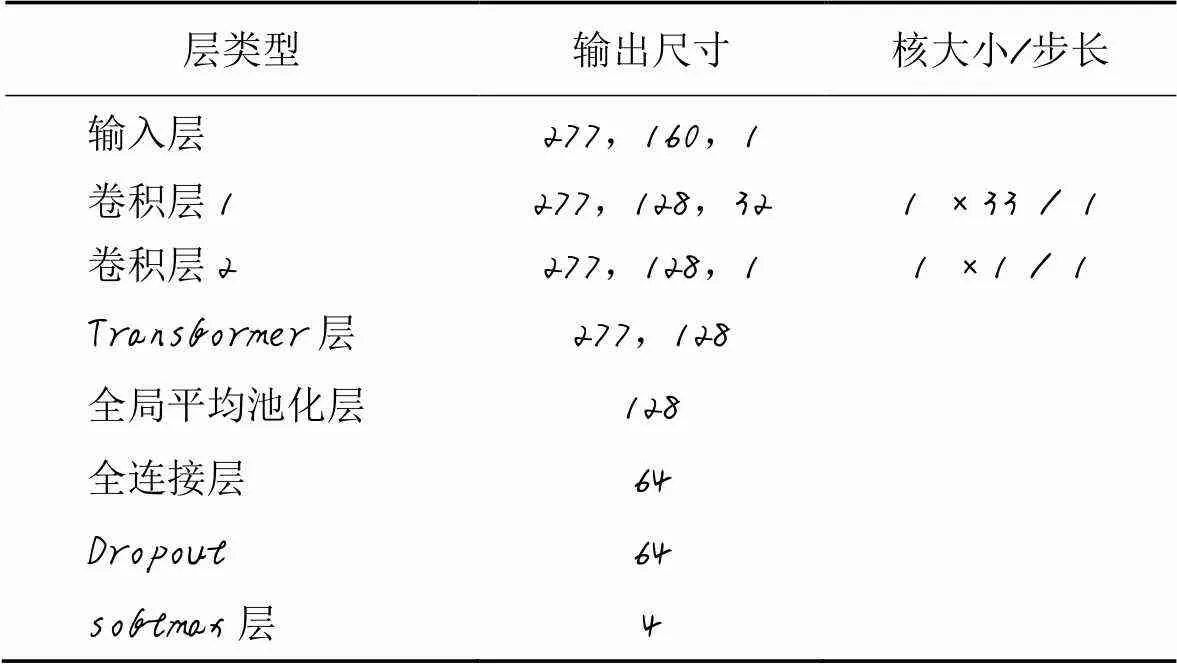
表2 MHA參數
3 模型的驗證
3.1 實驗環境與參數設置
在內存為16 GB的英偉達TITAN Xp GPU上驗證本文提出的語音情感識別方法。實驗超參數設置如下:10倍交叉驗證,按8∶1∶1的比例隨機劃分訓練集、測試集和驗證集;訓練集使用批量大小為64的200次迭代;Dropout參數為0.5;以ReLU為激活函數,利用Adam優化器將預測和真實類型標簽之間的分類損失函數最小化,選擇交叉熵作為損失函數,如式(12)所示。
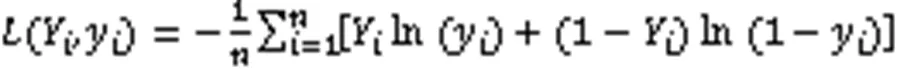
3.2 實驗評價指標
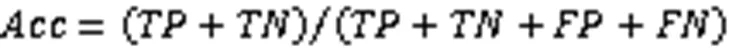
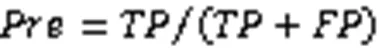
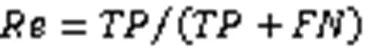

其中:(True Positive)代表真實值為正且預測為正的樣本數量;(False Positive)代表真實值為負且預測為正的樣本數量;(False Negative)代表真實值為正且預測為負的樣本數量;(True Negative)為真實值為負且預測為負的樣本數量。
3.3 實驗結果與討論
為驗證模型效果,先進行消融實驗,去除Transformer層,僅使用卷積網絡進行分類實驗,識別準確率為47.2%(圖6(a));其次,對比自注意力與多頭注意力對分類的影響,將Transformer層用LSTM層和注意力層替換,其中LSTM層的輸出維度為128,其他設置不變,識別準確率為60.1%(圖6(b))。
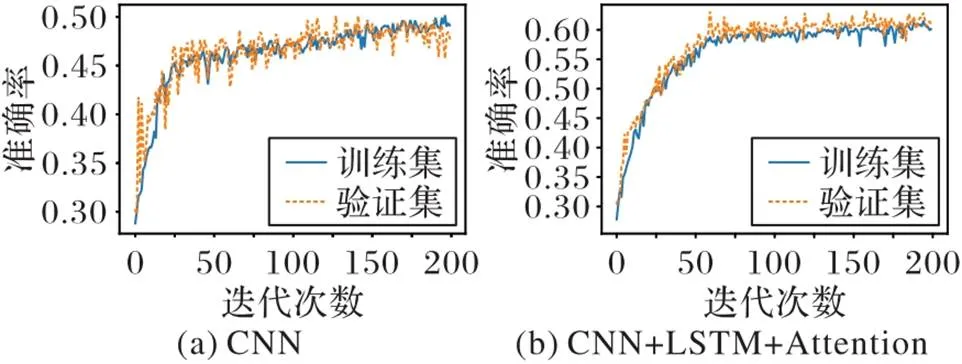
圖6 消融實驗中訓練集和驗證集的準確率曲線
其次,使用LR和NN進行對比實驗,與SVM設置相同,LR和NN都是連接在MHA的全連接層后面。考慮到模型復雜度與數據量相對有限的數據集,設置模型頭數為2、4、8,設置層數為1、2。表3是在不同頭數和層數下MHA、MHA-SVM、MHA-LR和MHA-NN的識別準確率結果。可以看出,在“頭”數量較少時,隱藏向量的表達能力不足,模型準確率相對較低,增加“頭”數量后可以提升模型對細節的表示能力,設置“頭”數量為8時,準確率達到最高。同時,1層的模型就可以獲得較好效果,層數對模型的影響相對不太敏感,而且由于層數增加,導致模型復雜度提升,對于訓練數據量較小的數據集,容易導致過擬合,從而影響模型的泛化能力。從表3中還可以看出,SVM分類器可以進一步提升MHA的分類效果,而LR和NN則對MHA的影響較小。當頭數為8且層數為1時,MHA和MHA-SVM的識別準確率都達到最高,分別為67.7%和69.6%。圖7分別是準確率曲線、混淆矩陣和t分布-隨機鄰近嵌入(T-distribution Stochastic Neighbour Embedding, t-SNE)圖。
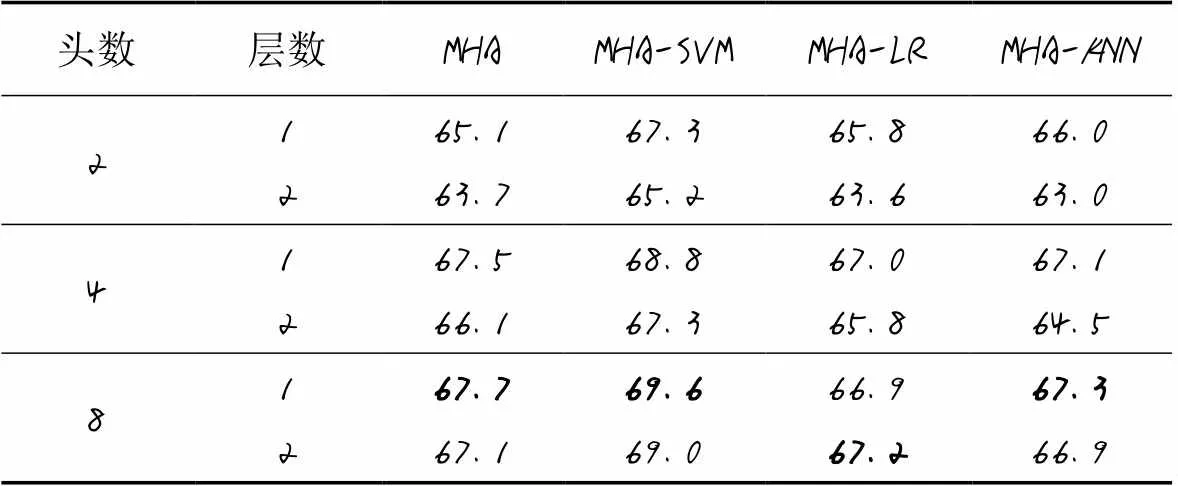
表3 不同頭數和層數下模型的識別準確率比較 單位: %
由表4可以看出,除“悲傷”類別外,其余三個類別的精準率都在70%以上。由于訓練集中“悲傷”類別的訓練樣本數相對較少,模型只能從有限的樣本中學習特征,從而容易將測試集中的“悲傷”樣本錯誤地分類到“中性”或“高興”類別。從總體上看,所有模型的F1分數都達到70%,這表明MHA-SVM在不平衡數據集上具有很好的識別性能。
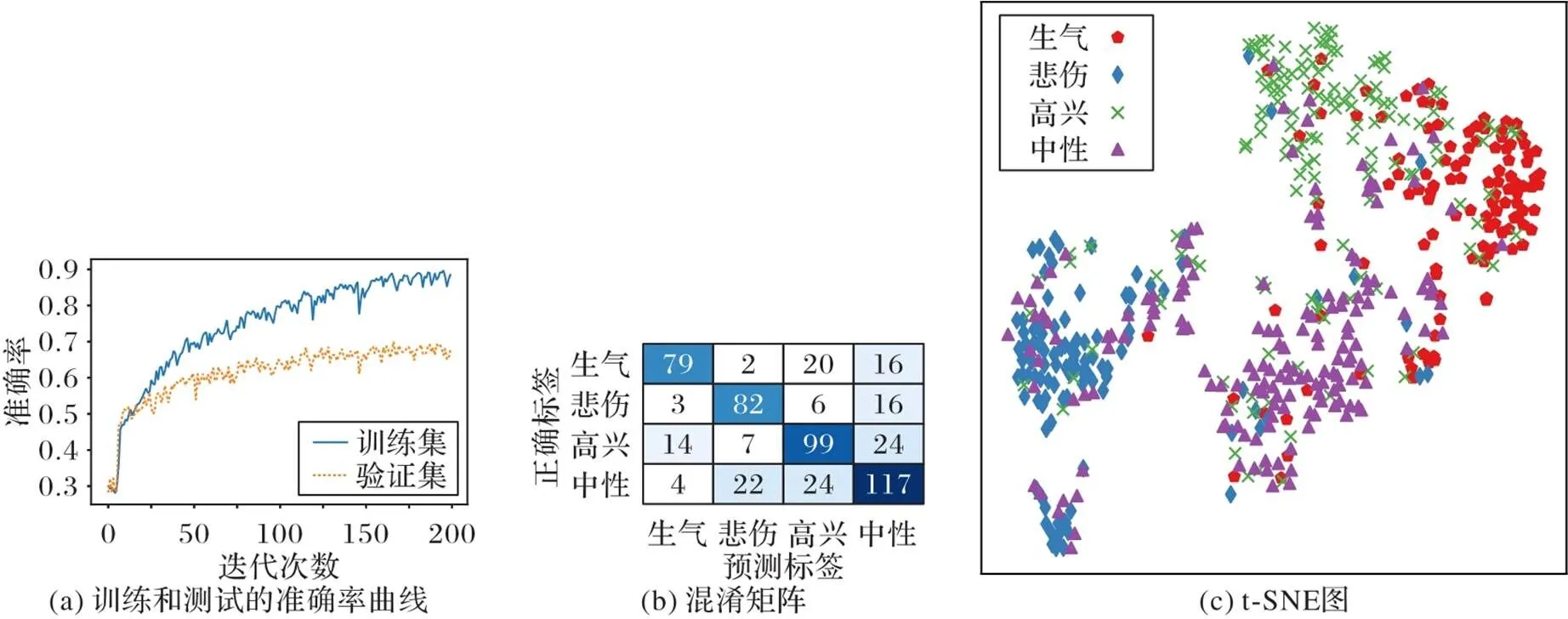
圖7 實驗結果
最后,表5給出了SER領域近年的研究成果及其研究方法。這些研究工作的準確率都不高于70%,這主要是由IEMOCAP數據內部結構特點決定[23]。IEMOCAP數據集采集過程使用兩個麥克風分別獨立采集男演員聲音和女演員聲音,兩類演員在對話表演中會相互打斷,話語會相交,這個交集時間占整個對話時間的9%,由于麥克風放置位置相對接近對方,這會導致單一麥克風同時記錄兩個聲音,從而增加音頻片段內容的判斷難度和數據類型的非平衡性。另外,數據標注質量進一步降低了IMMOCAP數據集的識別準確率,根據標注規則,對音頻片段所含情緒類別的判斷需取得半數以上專家一致評價時,才能對該片段進行標注,數據集中約有25%的音頻片段無法被分配到情緒標簽,而標注片段中能取得所有專家一致評價的占比不到50%,這進一步說明人類情緒表達的復雜性和情緒評估的主觀性。由表5可以看出,與其他對比方法相比,在IEMOCAP數據集上本文模型的識別性能最優。傳統機器學習方法SVM[24-25]的識別性能要弱于神經網絡,其中文獻[24]中以低水平特征集為輸入使用單一SVM獲得57.5%準確率;文獻[25]中將原始音頻輸入以SVM為內部節點的決策樹中,逐步識別各情緒類別。以原始音頻為輸入的端到端CNN-BLSTM[8]中,從原始音頻提取潛在關系的能力都遠遜于基于MHA的模型,而且網絡深度增加帶來的運算效率的降低不利于其在移動終端的部署實施。以手工提取的梅爾譜圖等聲音特征作為輸入的模型[10-11]雖然網絡結構較前面模型簡潔,但受限于人為選擇聲音特征的偏差和樣本數據維度高、規模小的問題,無法針對具體語音情感數據集的特點,自主挖掘聲音序列的內部潛在特征,模型的泛化能力弱于基于MHA的模型。實驗結果說明基于MHA的模型可以有效地捕捉原始聲音序列中的內部時空關系,而SVM作為分類器對高維小規模樣本的聲音特征分類有積極的促進作用。
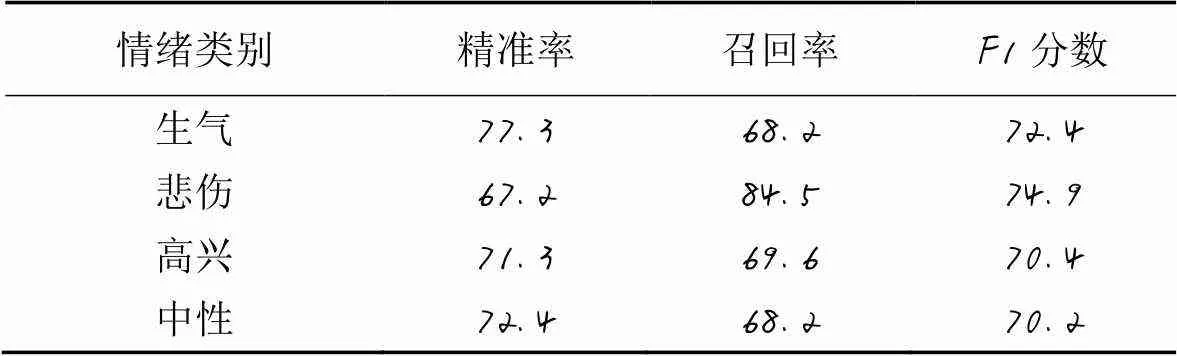
表4 MHA-SVM在IEMOCAP數據集上四個情緒類別的性能比較 單位: %
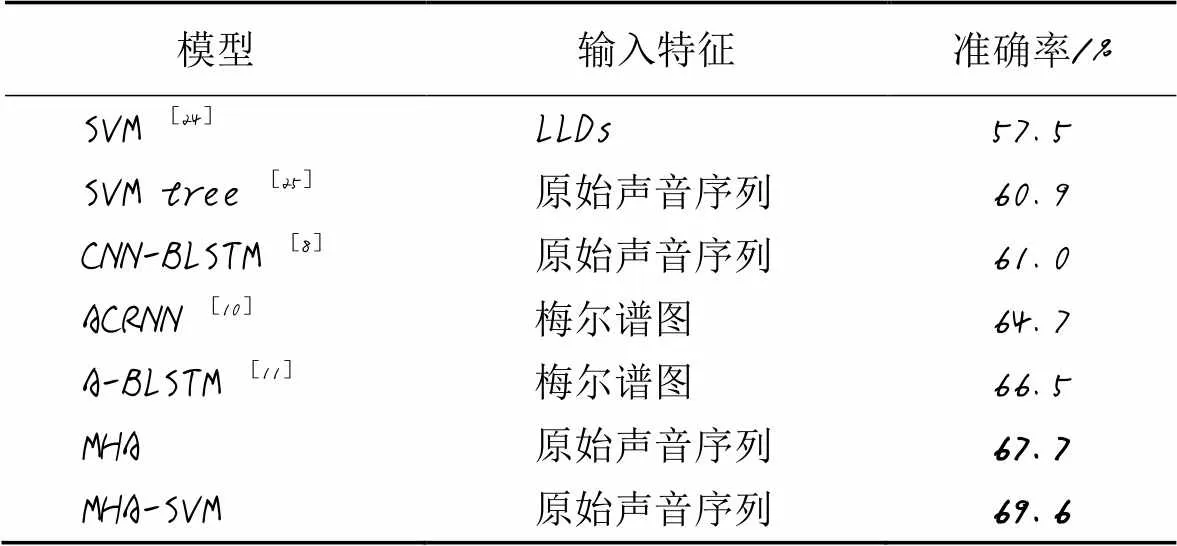
表5 IEMOCAP數據集上7種模型的準確率對比
4 結語
本文提出了以原始音頻為輸入的基于多頭注意力的端到端語音情感識別模型。模型中的卷積層能夠有效提取語音信號的低維特征,多頭注意機制可以減小序列信息的長度,充分挖掘語音信號的時空結構信息,并結合SVM進一步提高語音情感分類的識別準確率。實驗結果表明該模型比基于梅爾譜圖的模型具有更大的優勢,由于輸入為原始波形,且無需手工特征提取步驟,這給模型部署在移動端帶來了便利。未來的工作中,我們將繼續優化模型,提高模型識別準確率,使模型在移動端具有開發應用前景。
[1] SALAMON J, BELLO J P. Deep convolutional neural networks and data augmentation for environmental sound classification[J]. IEEE Signal Processing Letters, 2017, 24(3): 279-283.
[2] LIM W, JANG D, LEE T. Speech emotion recognition using convolutional and recurrent neural networks[C]// Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2016: 1-4.
[3] HINTON G, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[4] SCHEDL M, GóMEZ E, URBANO J. Music information retrieval: recent developments and applications[J]. Foundations and Trends in Information Retrieval, 2014, 8(2/3): 127-261.
[5] MAO Q R, DONG M, HUANG Z W, et al. Learning salient features for speech emotion recognition using convolutional neural networks[J]. IEEE Transactions on Multimedia, 2014, 16(8): 2203-2213.
[6] ISSA D, DEMIRCI M F, YAZICI A. Speech emotion recognition with deep convolutional neural networks[J]. Biomedical Signal Processing Control, 2020, 59: No.101894.
[7] XIE Y, LIANG R Y, LIANG Z L, et al. Speech emotion classification using attention-based LSTM[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(11): 1675-1685.
[8] 呂惠煉,胡維平. 基于端到端深度神經網絡的語言情感識別研究[J].廣西師范大學學報(自然科學版), 2021, 39(3): 20-26.(LYU H L, HU W P. Research on speech emotion recognition based on end-to-end deep neural network[J]. Journal of Guangxi Normal University (Natural Science Edition), 2021, 39(3): 20-26.)
[9] LATIF S, RANA R, KHALIFA S, et al. Direct modelling of speech emotion from raw speech[EB/OL]. (2020-07-28)[2021-01-25].https://arxiv.org/pdf/1904.03833.pdf.
[10] CHEN M Y, HE X J, YANG J, et al. 3-D convolutional recurrent neural networks with attention model for speech emotion recognition[J]. IEEE Signal Processing Letters, 2018, 25(10): 1440-1444.
[11] ZHAO Z P, BAO Z T, ZHAO Y Q, et al. Exploring deep spectrum representations via attention-based recurrent and convolutional neural networks for speech emotion recognition[J]. IEEE Access, 2019, 7:97515-97525.
[12] VASWANI A, SHAZEER N, PARMAR J, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[13] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2021-01-25].https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_ understanding_paper.pdf.
[14] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[15] KARITA S, SOPLIN N E Y, WATANABE M, et al. Improving transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration[C]// Proceedings of the 20th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2019: 1408-1412.
[16] 陳闖, RYAD C,邢尹,等. 改進GWO優化SVM的語音情感識別研究[J]. 計算機工程與應用, 2018, 54(16): 113-118.(CHEN C, RYAD C, XING Y, et al. Research on speech emotion recognition based on improved GWO optimized SVM[J]. Computer Engineering and Applications, 2018, 54(16): 113-118.)
[17] 余華,顏丙聰. 基于CTC-RNN的語音情感識別方法[J]. 電子器件, 2020, 43(4): 934-937.(YU H, YAN B C. Speech emotion recognition based on CTC-RNN[J]. Chinese Journal of Electron Devices, 2020, 43(4): 934-937.)
[18] YOON S, BYUN S, JUNG K. Multimodal speech emotion recognition using audio and text[C]// Proceedings of the 2018 IEEE Spoken Language Technology Workshop. Piscataway: IEEE, 2018: 112-118.
[19] CHO J, PAPPAGARI R, KULKARNI P, et al. Deep neural networks for emotion recognition combining audio and transcripts[C]// Proceedings of the 19th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2018: 247-251.
[20] ALDENEH Z, PROVOST E M. Using regional saliency for speech emotion recognition[C]// Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2017: 2741-2745.
[21] WAN M T, McAULEY J. Item recommendation on monotonic behavior chains[C]// Proceedings of the 12th ACM Conference on Recommender Systems. New York: ACM, 2018: 86-94.
[22] XIA Q L, JIANG P, SUN F, et al. Modeling consumer buying decision for recommendation based on multi-task deep learning[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 1703-1706.
[23] CHERNYKH V, PRIKHODKO P. Emotion recognition from speech with recurrent neural networks[EB/OL]. (2018-07-05)[2021-01-25].https://arxiv.org/pdf/1701.08071.pdf.
[24] TIAN L M, MOORE J D, CATHERINE L. Emotion recognition in spontaneous and acted dialogues[C]// Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction. Piscataway: IEEE, 2015: 698-704.
[25] ROZGI? V, ANANTHAKRISHNAN S, SALEEM S, et al. Ensemble of SVM trees for multimodal emotion recognition[C]// Proceedings of the 2012 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2012: 1-4.
End-to-end speech emotion recognition based on multi-head attention
YANG Lei1, ZHAO Hongdong1*, YU Kuaikuai2
(1,,300401,;2,300308,)
Aiming at the characteristics of small size and high data dimensionality of speech emotion datasets, to solve the problem of long-range dependence disappearance in traditional Recurrent Neural Network (RNN) and insufficient excavation of potential relationship between frames within the input sequence because of focus on local information of Convolutional Neural Network (CNN), a new neural network MAH-SVM based on Multi-Head Attention (MHA) and Support Vector Machine (SVM) was proposed for Speech Emotion Recognition (SER). First, the original audio data were input into the MHA network to train the parameters of MHA and obtain the classification results of MHA. Then, the same original audio data were input into the pre-trained MHA again for feature extraction. Finally, these obtained features were fed into SVM after the fully connected layer to obtain classification results of MHA-SVM. After fully evaluating the effect of the heads and layers in the MHA module on the experimental results, it was found that MHA-SVM achieved the highest recognition accuracy of 69.6% on IEMOCAP dataset. Experimental results indicate that the end-to-end model based on MHA mechanism is more suitable for SER tasks compared with models based on RNN and CNN.
Speech Emotion Recognition (SER); Multi-Head Attention (MHA); Convolutional Neural Network (CNN); Support Vector Machine (SVM); end-to-end
This work is partially supported by Fund of Science and Technology on Electro-Optical Information Security Control Laboratory (614210701041705).
YANG Lei, born in 1978, Ph. D. candidate. His research interests include intelligent information processing.
ZHAO Hongdong, born in 1968, Ph. D., professor. His research interests include photoelectric information processing, speech signal processing.
YU Kuaikuai, born in 1988, M. S., engineer. His research interests include electronic information.
TP183
A
1001-9081(2022)06-1869-07
10.11772/j.issn.1001-9081.2021040578
2021?04?14;
2021?07?19;
2021?07?23。
光電信息控制和安全技術重點實驗室基金資助項目(614210701041705)。
楊磊(1978—),男,吉林敦化人,博士研究生,CCF會員,主要研究方向:智能信息處理;趙紅東(1968—),男,河北滄州人,教授,博士生導師,博士,主要研究方向:光電信息處理及應用、語音信號處理;于快快(1988—),男,天津人,工程師,碩士,主要研究方向:電子信息。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
