基于冷軋工藝數據的熱鍍鋅帶鋼機械性能統計建模與預測
2022-07-09 01:24:14俞鴻毅王學敏
寶鋼技術 2022年2期
俞鴻毅,王 勁,王學敏
(寶山鋼鐵股份有限公司 1.冷軋廠,上海 201900; 2.中央研究院,上海 201999)
1 概述
智能制造在當代工業中的作用愈來愈重要。“十四五”規劃綱要指出要堅持把發展經濟的著力點放在實體經濟上,堅定不移建設制造強國、質量強國、網絡強國、數字中國。鋼鐵冶金行業的智能制造是實現我國工業及制造業升級的基礎和重點之一[1-2]。熱鍍鋅鋼卷薄板在汽車、建筑和交通等領域具有廣泛應用,是寶鋼的重要產品[2]。寶鋼某機組以“數字鋼卷”的形式在冷軋產品的數字化方面進行了探索。本文介紹基于“數字鋼卷”開發的熱鍍鋅帶鋼機械性能統計模型與預測系統,該研究利用統計方法和機器學習技術,為數字鋼卷提供了一個實用的智能化應用案例。
寶鋼某機組主要加工熱鍍鋅鋼卷薄板(帶鋼)產品。鋼板主要質量指標中的屈服強度(Yield Strength,以下簡稱YS)、抗拉強度(Tension Strength,以下簡稱TS)、延伸率(Elongation,以下簡稱El)受到原料品質和煉鋼、熱軋、冷軋、退火、平整、拉矯等一系列流程工藝因素的影響,其中冷軋機組包含退火爐、平整機、拉矯機等相關的工藝段是帶鋼產品最后成形的關鍵[3]。機組出口剪切帶鋼的試樣,送到離線實驗室進行拉伸測試以評估鋼卷性能。因此,離線測試具有延時性,在此之前對機械性能進行實時預報,對質量控制、工藝優化和節約成本具有重要意義[4-5]。
利用化學成分和熱軋、冷軋等工藝數據對鋼板產品機械性能進行建模預測已有一些很好的工作。李維剛等[4]和王蕾等[5]根據冶金機理建立了組織模型用于鋼板力學性能預報,林傳華等[6]應用BP神經網絡算法建立了熱鍍鋅過渡卷力學性能預報模型,王偉等[7]應用梯度提升樹模型對熱鍍鋅鋼板力學性能進行了預報。現有模型的變量來源比較多,包括煉鋼、熱軋、冷軋等不同工藝線上的數據。本研究為了適應并充分利用冷軋某機組“數字鋼卷”系統,采用機組工藝數據、速度和來料數據為主要變量建立統計模型。另外,已有工作多采用神經網絡、決策樹和基于神經網絡或決策樹的集成學習模型等[6-7]。這些機器學習模型擬合效果比較好,注重預測精度[8],但是它們的統計解釋能力和相應的估計、假設檢驗等統計推斷分析方法不如廣義線性模型理論成熟[8-9]。本文為了利用模型進行變量分析和其他后續研究中的統計檢驗等目的,針對不同出鋼記號,在廣義線性模型框架下進行統計建模。
針對寶鋼某冷軋機組2017和2018年歷史數據,經過數據整理、清洗、融合匹配,得到了配對數據29 955條。在廣義線性模型框架下,經過數據變換、變量篩選和正則項約束等處理,構建了不同出鋼記號下冷軋帶鋼的屈服強度、抗拉強度、延伸率3個主要力學機械性能的統計模型,并針對數字鋼卷系統設計了在線匹配算法,將統計模型應用于鋼卷機械性能的實時在線預測。檢測案例展示了模型的離線和在線預測在相對誤差標注下都達到了不錯的精度。
2 歷史數據處理與統計模型建立
2.1 數據清洗與拼接
獲取的2017和2018年的原始數據來源于生產線的不同數據庫,主要分為工藝參數與機械性能兩類數據,涉及多張表格以及大量字段名,也存在許多刪失數據,需要進行數據清洗。為此,對大量缺失的數據進行刪除,對于每卷鋼卷的大量數據進行平均化等處理。對最重要的目標變量——機械性能表格中的鋼卷離線試驗結果中大量重復數值,按照“軋硬卷”號進行去重以及首尾平均的計算,保證樣本處于基本可用的范圍內。
清洗數據后,針對不同數據庫、數據子表中的結構化數據進行數據融合匹配。由于不同數據源字段不統一,需要尋找各工藝數據表與機械性能數據表中重合程度最高的字段進行匹配。通過遍歷各字段,計算其在工藝數據表與機械性能數據表中的重合程度,并結合工藝經驗,確定選取“軋硬卷”字段以及“入口卷號”作為異源數據的匹配ID進行表格的勾連和統一,以構造出新的融合數據表。對融合匹配后的數據再做異常數據識別、缺失數據填充、數據格式同一、數據歸一化等處理,最終得到包括不同帶鋼的型號、機組工藝變量、速度和包括屈服強度、抗拉強度、延伸率等帶鋼機械性能變量的配對數據29 955條。
2.2 統計模型建立
2.2.1 數據特征與建模思路
實現異源數據融合匹配后,進行機械性能統計建模。針對研究問題,不同鋼種帶鋼沿傳送方向分別經過退火爐、平整機、拉矯機等生產工藝段。每隔一定時間對待研究工藝數據進行采集,并由出口段在線性能檢測儀得到多位置點的性能數據。將每卷帶鋼看作一獨立樣本,樣本集為i=1,……,n。對于每一個待研究的工藝數據xk,在每卷帶鋼上都可以采集到一個序列數據。加上帶鋼出鋼記號、厚度等來料數據,帶鋼經過每一個傳感器采樣時間和采集到的帶鋼運行速度等其他數據,組成建模所用到的控制變量。機械性能指標屈服強度、抗拉強度、延伸率即為響應變量y。
由上述分析,可把目標抽象成通過多個待研究工藝數據變量、帶鋼運行速度、鋼卷特性數據等信息預測機械性能指標取值的相關性統計模型,如式(1)所示,其中θ是模型參數向量。
yi~f(θ,xi1,xi2,……,xim)
(1)
建模過程框架如圖1所示。

圖1 建模過程框架Fig.1 Modelingprocess framework
2.2.2 變量確定
進入模型的變量選擇對模型質量至關重要。綜合考慮工藝專家的專業建議、變量與機械性能的相關系數、初步線性回歸的p值等因素,進行了變量篩選和確定,最終選取出鋼記號、鋼卷厚度、諸化學元素,退火爐加熱段、均熱段、緩冷段、快冷段、均衡段的爐溫和帶溫,露點值、平整機的軋制力、平整延伸率、平整入口張力值、平整出口張力值及拉矯機延伸率等58個變量進入模型。
2.2.3 建模過程與模型展示
將歷史數據的70%隨機抽樣提取為訓練集進行統計建模,剩余30%作為測試集進行離線測試。對機組的每種出鋼記號都分別進行建模擬合,模型擬合的基本思想為式(2)的極小化模型函數:
(2)

使用牛頓迭代算法求解式(1)的系數。在上述總模型框架下,依據不同變量的具體數據特征,針對性地進行了調整,比如對于一些變量,進行了式(3)的Box-Cox變換[8],使得其滿足正態性的假設。
(3)
對于一些初步擬合中p值較大的變量,根據生產經驗對其進行篩選,通過標準化、平方、對數等手段進行數據的變換加入模型統籌。
最終機械性能預測模型表達式見式(4):
y=μSteelGrade+β1·EntryThick+β2·
SpmRollForce+β3·SpmElongation+
β4·SpmPreTen+β5·SpmPostTen+
w·g(x1,……,xm)
(4)
式中:y為SteelGrade、EntryThick等6個主要變量(變量含義見表1)和其余52個變量(x1,……,xm)的廣義線性回歸;μSteelGrade為訓練集中該鋼種對應機械性能的平均值;β1~β5是回歸系數;g(x1,……,xm)為其余變量經過變換后的一個截斷線性函數;w是權重系數。

表1 主要變量含義Table 1 Key variable meaning
模型(4)本質上是一個廣義線性函數,其中待估參數有μSteelGrade,β1~β5,w和g(x1,……,xm)中的變量系數及其截斷值,需要對不同出鋼記號進行擬合。其中,g(x1,……,xm)公式如式(5)所示:
(5)
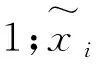
根據歷史訓練集數據交叉驗證結果,參數w的經驗取值區間為[0.05,0.1],機械性能YS、TS和El的截斷上、下闕界分別為[140,700]、[200,1000]和[15,80]。表2和表3列出了兩個鋼種的部分模型參數。經檢驗這些參數在0.05水平下都顯著。

表2 鋼種1模型部分參數估計值Table 2 Selected estimates of model parameters for SteelGrade1
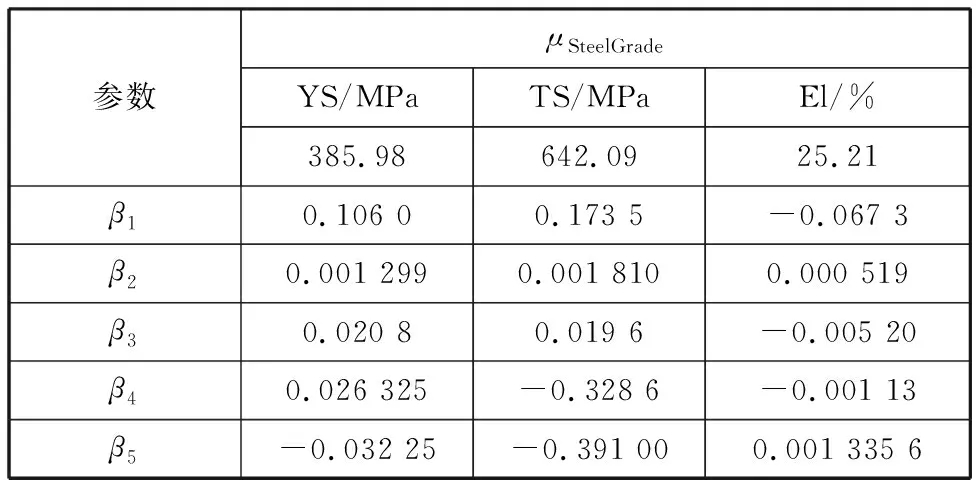
表3 鋼種2模型部分參數估計值Table 3 Selected estimates of model parameters for SteelGrade2
3 模型在線預測
模型以json格式,從機組的數字鋼卷系統獲得輸入變量的實際值。由于這些實際值的測量設備分布在機組不同的物理位置,同一帶鋼運行方向位置經過這些測量設備的時刻不同,所以本文設計了在線匹配系統和在線預測系統。其中,在線匹配系統主要功能是完成各個輸入變量在同一帶鋼運行方向位置上的數據對齊。
通過在線匹配系統實時匹配出的樣本數據會經過篩選、輸入模型和結果返回3個步驟。其中,篩選是為了檢驗數字鋼卷系統采集的數據是否出現異常值,如關鍵變量出現0、空值或者明顯異于數據所應處于的范圍時,程序將不會調用模型,而會返回數據錯誤提示。
若數據通過篩選則作為變量輸入模型中,計算出相應的機械性能預測值后,將以json格式返回給數字鋼卷系統。
4 模型預測精度評估
為了檢驗所構建的統計模型預測效果,采用機械性能預測結果和寶鋼現場實際檢測儀檢驗結果的預測誤差為衡量指標,計算公式見式(6):

(6)
下面以兩個鋼種作為案例,分別從歷史離線數據測試集和在線預測結果兩方面展示預測準確率,與其他鋼種的預測誤差結果類似。
4.1 模型預測精度離線評估
測試集中鋼種1和鋼種2的鋼卷分別為33卷和35卷,機械性能預測準確率箱型圖如圖2所示,其中預測誤差在10%內的占比如表4所示。從圖2和表4可知,統計模型對兩種鋼的YS和TS預測誤差小于10%的案例占比都超過90%,對El預測誤差小于10%的案例占比超過80%,其中對TS預測效果最好。
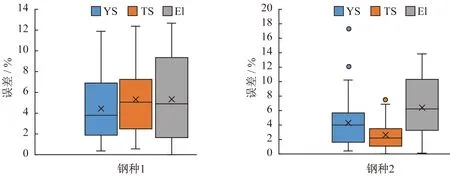
圖2 歷史測試集數據預測誤差箱型圖Fig.2 Box plot of percent prediction error for historical test data

表4 歷史測試集數據預測誤差在10%內占比Table 4 Percentage of prediction error within 10% historical test data %
4.2 模型預測精度在線評估
統計模型在線預測系統穩定上線一段時間后,2020年10月對上述兩個鋼種進行了實際性能檢驗數據的評估。兩個鋼種分別生產了62卷和56卷,圖3為機械性能預測準確率箱型圖,表5計算了預測誤差在10%內的比例是85%~100%。從圖3和表5可見,這兩個鋼種的模型在線預測精度優于離線的。

表5 2020年10月在線數據預測誤差在10%內占比Table 5 Percentage of prediction error within 10% for online data of October,2020

圖3 2020年10月在線數據預測誤差箱型圖 Fig.3 Box plot of percent prediction error for online data of October,2020
(1) 鋼種1,YS和TS預測誤差小于10%的案例占比都超過90%,El預測誤差小于10%的案例占比超過80%。
(2) 鋼種2,3個機械性能指標的預測誤差小于10%的占比都超過了90%。
綜合上述結果和其他鋼種數據結果,機械性能統計模型總體對TS預測最好,對YS預測次之,對El預測稍差,但都能大于80%。
5 結語
整合、清洗了寶鋼冷軋某條機組歷史數據,針對不同規格帶鋼的屈服強度、抗拉強度和延伸率3個力學機械性能建立了廣義線性統計模型,具有良好統計解釋性。模型預測精度在歷史測試集數據和在線數據都表現良好。由此驗證了基于數據的統計模型用于機械性能預測的可行性。接下來,將進一步利用統計推斷方法探究機組差異性分析和退火曲線等工藝的改進。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
山東冶金(2019年6期)2020-01-06 07:45:54
世界農藥(2019年2期)2019-07-13 05:55:12
光學精密工程(2016年6期)2016-11-07 09:07:19
銅業工程(2015年4期)2015-12-29 02:48:39
新疆鋼鐵(2015年3期)2015-11-08 01:59:52
核科學與工程(2015年4期)2015-09-26 11:59:03
石油化工應用(2014年8期)2014-03-11 17:40:03
