應用型本科數據挖掘技術課程教學方法的探索
2022-07-10 01:31:06周長敏佘佐明楊光臨
凱里學院學報 2022年3期
周長敏,佘佐明,楊光臨
(凱里學院,貴州凱里 556011)
0 引言
為積極響應國家的大數據戰略,國內眾多高校開設了大數據相關專業.截止到2021 年2 月,我國開設大數據相關本科專業的院校已達730所.凱里學院屬于地方院校,學校的人才培養目標是為民族地區經濟社會發展培養具有創新精神和實踐能力的應用型人才,根據學校的培養目標確立數據科學與大數據技術專業的人才培養目標是培養具有創新實踐能力和大數據處理、分析能力的應用型人才.2018年凱里學院獲批開設數據科學與大數據技術專業,數據挖掘技術作為數據科學與大數據技術專業的主干課程,是培養學生數據處理與數據分析能力、創新實踐能力的重要課程之一.數據挖掘技術課程的內容涉及線性代數、微積分、概率統計、數據庫、數據結構等數學、統計學、計算機科學的知識,是一門難度系數較高的綜合性課程.地方應用型本科院校的學生普遍存在數學基礎知識薄弱的問題,在數據挖掘課程教學過程中如果把重點放在大量的算法理論和公式推導上,學生會感到課程內容晦澀難懂,容易產生畏難情緒,從而失去學習興趣.應用型本科院校學生對實驗課的興趣遠遠大于理論課,因為實驗成果能夠讓學生獲得成就感,因此探索如何以實驗教學帶動理論教學,對于激發學生學習興趣和提高數據挖掘課程教學效果是非常有必要的.
在數據挖掘課程的教學研究方面,李艷玲[1]對數據挖掘實踐課程的教學模式進行了研究,提出了注重前導課、理論課和實踐課銜接的教學方法.劉波[2]等人在數據挖掘實踐課程的教學中采用了小組協作學習和項目式學習的教學模式.劉夢娟等[3]對數據挖掘課程的挑戰性綜合實驗的設計進行的研究.以上的研究取得了較好的教學效果,值得借鑒,但對于地方應用型本科院校來說,仍然需要結合學校培養目標探索適合學生實際情況的數據挖掘教學方法.
筆者結合凱里學院數據挖掘技術課程的教學實踐,提出“問題引導+案例分析”的理論實驗貫穿式教學方法,以實驗教學促進算法理論的學習,以提升學生的學習興趣和教學質量.
1 “問題引導+案例分析”的理論實驗貫穿式教學探索
1.1 教學內容設計
凱里學院的數據挖掘技術課程在第6 學期開設,主要的先導課程有高等數學、線性代數、數據結構、數據庫原理及應用、概率論與數理統計和Python 程序設計,課程總學時為64 學時,其中理論課32學時,實驗課32學時,實驗學時較充足.
在課程教學過程中,為激發學生的學習興趣,使用具體案例將理論課與實驗課貫穿起來.理論教學完成提出問題、引入案例、分析算法原理的任務,實驗教學完成解決問題、知識應用的任務.部分典型知識模塊的教學內容設計如表1所示.
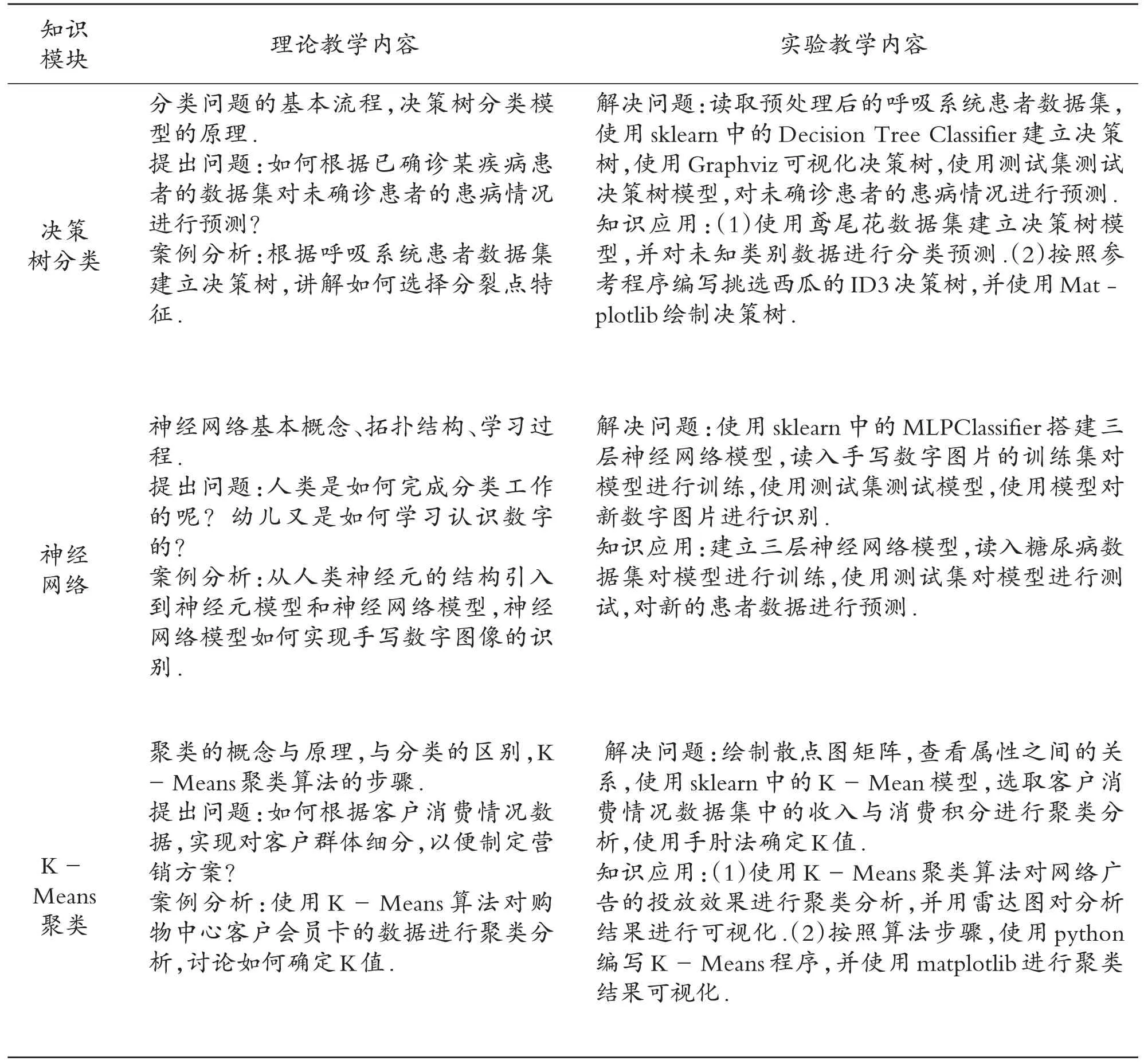
表1 數據挖掘技術教學內容設計
1.2 教學過程設計
教學過程包括課前、課中、課后三個主要環節.課前任務主要是根據老師推送到雨課堂的學習資料和練習進行課前預習;理論課堂任務是通過案例分析學習挖掘算法知識,實驗課堂任務是根據理論課學習的建模思路編寫解決案例問題的程序并調試生成分析結果;課后利用實驗課堂中實現的方法對新數據集進行分析和挖掘.下面以樸素貝葉斯分類為例,介紹具體的課堂教學過程.
1.2.1 設問題情境,引入案例
現有4000 條財經、體育、娛樂、健康4 個類別的新聞文本數據集,要求建立一個分類模型,使用文本數據集訓練分類模型,讓模型判斷“中國女排11 連勝衛冕世界杯”屬于哪一類新聞,請問這個任務使用上節課學習的決策樹模型能解決嗎?讓學生思考并回答.這個問題的設計既能夠引導學生回顧決策樹的知識,又能引導學生思考,起到承上啟下和激發興趣的作用.
1.2.2 給出解決問題的思路,講解樸素貝葉斯分類算法
提示解題思路為通過計算“中國女排11 連勝衛冕世界杯”中的關鍵詞在哪一類文本中出現的概率最大來判斷該新聞的類別.引出貝葉斯分類的思想:對于給出的待分類項,求解在此項出現的條件(特征)下各個類別出現的概率,哪個類別概率值最大,就認為此待分類項屬于哪個類別.讓學生根據課前預習的例題資料,回顧貝葉斯定理,引出完整的樸素貝葉斯分類的概念.通過判斷蘋果類別的實例介紹樸素貝葉斯分類算法的步驟.這個環節的目標是讓學生能夠盡快理解算法的原理,因此選取較簡單實例能夠讓學生不必糾結于復雜的計算.
1.2.3 案例分析,應用樸素貝葉斯分類算法解決文本分類問題
引導學生思考以下問題:文本屬于半結構化數據,如何量化成適用于計算機分析的數據呢?文本分類中關鍵的步驟是將文檔表示為量化模型,引出文檔的TF-IDF量化模型的概念.結合新聞分類的案例,介紹文檔TF-IDF 矩陣生成原理.將文檔的TF-IDF 矩陣作為數據集,使用樸素貝葉斯分類算法模型判斷“中國女排11 連勝衛冕世界杯”的類別.案例分析結束后,趁學生興趣濃厚時進一步介紹案例模型的編程實現方法并布置實驗任務.使用文本分類作為案例是因為樸素貝葉斯分類算法最典型的應用是文本分類,這樣設計的目的是讓學生在以后的知識應用過程中能夠根據數據集的特點確定最佳的挖掘方法.該案例的重點是介紹樸素貝葉斯分類算法如何實現文本分類,為了不喧賓奪主,在課前給學生分享TF-IDF 模型基礎知識的視頻資料,課堂上再結合實例講解,使得知識點能夠較快被學生接受而不會占用太多課堂時間.
1.2.4 實驗上機,編程實現分類模型
學生根據教師提前下發的實驗參考資料學習TF-IDF矩陣、貝葉斯分類器的調用方法,編寫程序生成文本分類模型實現對“中國女排11連勝衛冕世界杯”的所屬新聞類別的判斷.分類模型保存到硬盤,加載模型即可實現對任意輸入的新聞進行分類,準確率可達到95%以上.通過實驗,學生一步一步地解決案例中涉及的問題,最后得到分析結果并且能夠應用模型對輸入的新聞進行分類.通過實驗課將復雜的理論變成可運行的模型,學生在這個過程中獲得成就感,能夠極大的激發學生的學習興趣和主動性.在興趣和成就感的驅動下,學生能夠通過自己查閱資料、主動尋求教師幫助等方式去對算法理論進行更深入的學習和研究,形成良性循環,提高了理論課堂教學的效果.
1.3 實驗運行環境的選擇
數據挖掘技術實驗編程使用Python 語言,程序編寫與運行環境使用Jupyter Notebook.選擇Jupyter Notebook 作為實驗環境是因為其具有以下優勢:第一,持實時代碼,程序代碼與運行結果一起顯示,方便學生觀察和理解程序,算法講解和代碼演示可以同時進行也便于教師開展實驗指導,做到理論教學和實踐教學相融合.第二,可直接安裝第三方庫,支持目前主流的科學計算、數據分析、數據處理、機器學習、數據可視化開發包.第三,程序代碼和運行結果可生成HTML、PDF等格式文檔,方便分享和提交實驗資料.第四,支持交互式可視化展示,生成可縮放的地圖和可旋轉的三維圖形,提供豐富課堂展示效果.第五,支持分布式運行,可以加載遠程資源和本地資源同時進行代碼運行和展示[4],解決了實驗教學中運行環境配置不可移植的問題,節約了課堂教學時間.
1.4 課程考核
為更合理地對學生的學習情況進行評價,數據挖掘技術課程加大了對學生學習過程的考核.課程的總評成績由過程性考核成績(占20%)、實驗考核成績(占20%)、期末考核成績(占60%)三個部分組成.過程性考核的主要內容包括理論課堂表現(占5%)、平時作業(占10%)、階段性測試(5%).實驗考核包括實驗課堂表現(占10%)和綜合實驗作業(占10%).實驗課堂表現成績根據學生的實驗完成情況進行當堂評定,學生在Jupyter Notebook環境下完成實驗后,教師在課堂上對學生實驗情況進行檢查驗收后給出成績.綜合實驗作業要求學生使用所學習的數據挖掘知識對給定的數據集進行分析與挖掘,并撰寫數據分析報告.為激發學生的興趣,綜合實驗作業中使用的數據集都來源于學生的生活實際,包括脫敏后的本校學生的心理測評數據、體測數據、圖書借閱數據等.通過綜合實驗作業讓學生在體會學以致用的同時也能夠培養學生解決復雜實際問題的能力.
2 教學效果及反思
“問題引導+案例分析”的理論實驗貫穿式教學方法在數據科學與大數據技術專業的數據挖掘技術課程中進行了一輪教學實踐,取得了較好的教學效果.通過問卷調查顯示,學生對此教學方法的滿意度達到92.9%,認為此方法提升了他們的自主學習能力和知識應用能力.學生應用數據挖掘知識對本校學生的心理測評數據、就業數據進行挖掘和分析,申報創新創業項目獲得2項立項,在“泰迪杯”“未來云杯”等數據分析比賽中獲得多個獎項.
以上的教學方法雖然取得了較好的教學效果,但在教學過程仍存在一些問題,部分學生由于Python 語言的基礎較差,不能按時完成實驗任務,導致學習進度跟不上而產生學習倦怠的情況.在今后的教學中,將繼續探索和改進教學方法,根據學生的基礎為學生提供個性化的教學資源,采取多樣化的督促和激勵方法,激發學生的學習積極性,使不同基礎的學生都能夠主動學習.
3 結束語
針對地方應用型本科院校學生在數據挖掘課程學習中出現畏難情緒、學習主動性不夠的情況,提出“問題引導+案例分析”的理論實驗貫穿式教學方法,圍繞案例開展理論教學與實驗教學,讓學生通過解決問題獲得成就感和學習內驅力,從而主動對算法理論進行更深入的學習和研究.實踐證明以上方法能夠激發學生的積極性和主動性,取得了較好的教學效果.在課程教學實施的過程中也暴露出了一些問題,還需要在今后的教學過程中繼續探索和改進.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
少先隊活動(2021年2期)2021-03-29 05:40:48
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國公路(2017年7期)2017-07-24 13:56:38
電力與能源(2017年6期)2017-05-14 06:19:37
信息通信技術(2015年6期)2015-12-26 01:16:46
