基于CNN-BiLSTM 模型的日志異常檢測方法
2022-07-14 13:11:24孫嘉張建輝卜佑軍陳博胡楠王方玉
計算機工程 2022年7期
孫嘉,張建輝,卜佑軍,陳博,胡楠,王方玉
(1.鄭州大學(xué) 中原網(wǎng)絡(luò)安全研究院,鄭州 450001;2.中國人民解放軍戰(zhàn)略支援部隊信息工程大學(xué),鄭州 450001)
0 概述
隨著共享、開放的互聯(lián)網(wǎng)飛速發(fā)展,網(wǎng)絡(luò)攻擊方式也呈現(xiàn)出自動化、多樣化的發(fā)展趨勢,網(wǎng)絡(luò)安全面臨著前所未有的挑戰(zhàn)。網(wǎng)絡(luò)安全威脅主要包括系統(tǒng)內(nèi)部漏洞威脅、誤操作威脅和外部攻擊威脅。目前多數(shù)網(wǎng)絡(luò)系統(tǒng)都會輸出記錄系統(tǒng)運行狀態(tài)和執(zhí)行操作的日志文件,日志文件可以在入侵檢測、故障處理、事件關(guān)聯(lián)、事故處理、事后追究等諸多方面提供幫助。對日志進(jìn)行分析應(yīng)用于在線監(jiān)視和威脅檢測,是計算機安全領(lǐng)域中的研究熱點之一[1]。
傳統(tǒng)的日志分析方法多是開發(fā)人員根據(jù)專業(yè)領(lǐng)域知識,使用手動檢查、編寫規(guī)則、應(yīng)用統(tǒng)計學(xué)分析或聚類等方法,人工進(jìn)行特征識別和建立規(guī)則,但是隨著網(wǎng)絡(luò)入侵攻擊由獨立、簡單、直接、易暴露逐漸演變成有組織、有目標(biāo)、持續(xù)時間長的APT 等攻擊,以及逐漸規(guī)模化發(fā)展、分布式部署、高并行和冗余運行的系統(tǒng)應(yīng)用發(fā)展[2],海量的日志數(shù)據(jù)和高隱蔽性的攻擊手段導(dǎo)致人工選取特征、制定規(guī)則困難和檢測方法適用性低,而深度學(xué)習(xí)可為解決這些問題提供新的思路。
在大數(shù)據(jù)時代背景下,深度學(xué)習(xí)技術(shù)蓬勃發(fā)展,如聚焦學(xué)習(xí)樣本空間特征的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)[3]、挖掘發(fā)現(xiàn)時間序列特征的循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)[4]。深度學(xué)習(xí)模型在參數(shù)合適的情況下不需要人工提取特征,模型本身就能完成特征提取與檢測工作,在保證準(zhǔn)確率的同時大幅減少工作量。為保證深度學(xué)習(xí)檢測模型的準(zhǔn)確率,模型結(jié)構(gòu)應(yīng)與數(shù)據(jù)結(jié)構(gòu)相適應(yīng),并且需要足夠的數(shù)據(jù)進(jìn)行訓(xùn)練,而海量的日志數(shù)據(jù)正適用于訓(xùn)練深度學(xué)習(xí)模型。此外,還應(yīng)設(shè)置合適的模型參數(shù),目前存在網(wǎng)格搜索、隨機搜索、貝葉斯優(yōu)化等多種調(diào)參算法[5],可以協(xié)助定義模型參數(shù),進(jìn)一步降低工作量。
本文針對海量日志數(shù)據(jù)的特點,結(jié)合CNN 和Bi-LSTM 提取時空序列特征的優(yōu)勢,構(gòu)建適用于日志異常檢測的CNN-BiLSTM 深度學(xué)習(xí)模型。通過解析日志鍵和日志參數(shù),根據(jù)各自特點分別提取空間和時間序列特征,提高日志異常檢測準(zhǔn)確率。對比傳統(tǒng)日志異常檢測方法和單核結(jié)構(gòu)的深度學(xué)習(xí)模型,在HDFS 和WC_98day 數(shù)據(jù)集上進(jìn)行實驗,驗證CNN-BiLSTM 模型的普適性。同時,通過消融實驗從檢測效果和模型收斂速度兩個方面出發(fā),分別測評詞嵌入結(jié)構(gòu)和全連接層結(jié)構(gòu)對于CNN-BiLSTM模型的重要意義。
1 相關(guān)工作
1.1 傳統(tǒng)日志異常檢測方法
傳統(tǒng)日志分析方法對比如表1 所示,一般由開發(fā)人員根據(jù)相關(guān)領(lǐng)域知識或手動檢查,或編寫規(guī)則,或應(yīng)用統(tǒng)計學(xué)分析、聚類等方法分析日志數(shù)據(jù),但是傳統(tǒng)方法不僅存在高度依賴特征工程、普適性差等缺點,而且對處理海量數(shù)據(jù)、檢測復(fù)雜網(wǎng)絡(luò)攻擊缺少高效的解決方案。
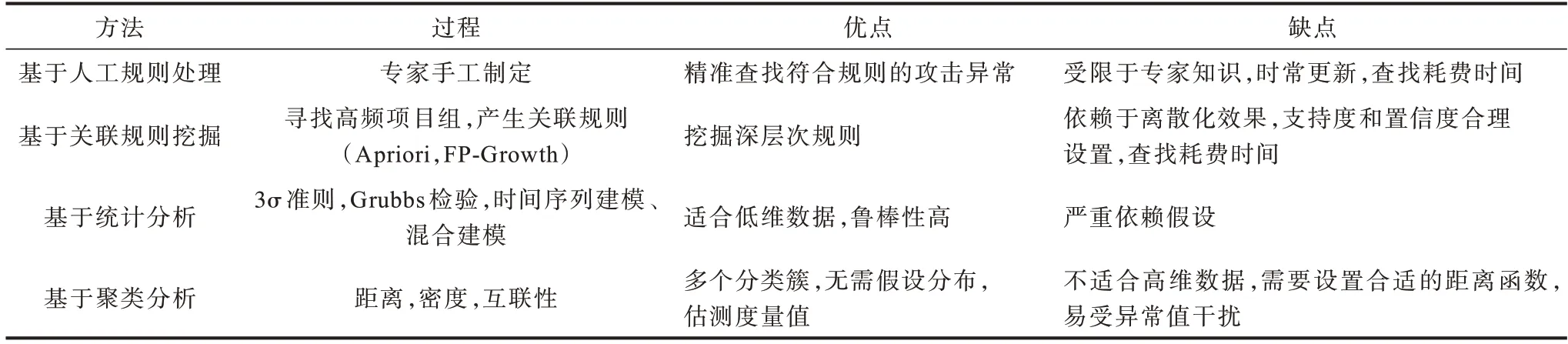
表1 傳統(tǒng)日志異常檢測方法分析Table 1 Analysis of traditional log anomaly detection methods
1.2 深度學(xué)習(xí)方法
目前,深度學(xué)習(xí)在日志異常檢測領(lǐng)域的應(yīng)用主要有以下3 個方面:
1)RNN 模型的應(yīng)用研究。在諸多模型中,RNN以其時間序列強大的學(xué)習(xí)能力而受到關(guān)注:MENG等通過加入同義詞和反義詞訓(xùn)練DLCE 詞向量,詞向量引入語義信息用以LSTM 順序檢測,并通過詞頻統(tǒng)計得到例如打開和關(guān)閉此類的量化關(guān)系用于定量檢測[6];YUAN 等利用LSTM 神經(jīng)網(wǎng)絡(luò)提出一種無監(jiān)督的在線日志異常檢測框架,并設(shè)計一種能夠動態(tài)調(diào)節(jié)歷史信息輸入長度的動態(tài)閾值算法。該算法可以根據(jù)最近的檢測事件決定輸入長度,在Los Alamos National 實驗室網(wǎng)絡(luò)安全日志數(shù)據(jù)集上的實驗結(jié)果表明,其達(dá)到F1 值約0.95 的優(yōu)越效果[7];DU等基于雙向長短時記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(Bi-directional Long Short-Term Memory network,Bi-LSTM)構(gòu)建根據(jù)任務(wù)分類的工作流模型,對日志異常實施在線檢測達(dá)到92%的正確率[8]。
2)CNN 模型的應(yīng)用研究。CNN 以其在圖像視覺領(lǐng)域的卓越效果引起諸多研究者的注意:HASHEMI 等將解析器、向量化器和分類器集成為一個深度網(wǎng)絡(luò)學(xué)習(xí)模型,并采用字符級CNN 處理日志事件,在綜合單項目、多項目的數(shù)據(jù)集上實驗評估該模型的魯棒性,并通過提前異常檢測測試評估模型預(yù)測異常的能力,達(dá)到F1 值約為0.99 的優(yōu)越性能[9];梅御東等使用CNN-Text 基于日志數(shù)據(jù)檢測軟件異常,在不同數(shù)據(jù)集上達(dá)到90%左右的準(zhǔn)確率[10]。
3)基于注意力機制的模型。注意力機制不僅能并行計算,提高處理效率,而且可以解決日志鍵長距離上的梯度消失問題[11]:HUANG 等基于注意力機制分別設(shè)計了日志序列編碼器和參數(shù)值編碼器,用以捕獲日志中蘊含的語義信息,并通過不穩(wěn)定的日志數(shù)據(jù)集實驗評估該方法的性能和魯棒性[12];GUO等構(gòu)建基于多頭注意力的序列模型,將日志流作為模板事件序列進(jìn)行處理,通過下一個事件的預(yù)測任務(wù)訓(xùn)練模型進(jìn)行日志異常檢測,在HDFS 數(shù)據(jù)集上不同注意力頭數(shù)的實驗F1 值均穩(wěn)定在0.97 左右[13];NEDELKOSKI 等構(gòu)建基于自注意力的編碼器模型,并使用系統(tǒng)切換時間等輔助信息增強訓(xùn)練數(shù)據(jù),通過密集的日志數(shù)據(jù)訓(xùn)練使模型能夠更有效地區(qū)分正常和異常日志之間的差異,同時,在BGL 等公開數(shù)據(jù)集上和PCA 方法進(jìn)行對比實驗,準(zhǔn)確率達(dá)到約90%,F(xiàn)1 值約為0.67[14]。
上述研究面對海量日志數(shù)據(jù)分析深度學(xué)習(xí)普遍優(yōu)于手工特征提取的傳統(tǒng)方法,但是依然存在不足,例如:將日志整體作為分析對象,忽視日志鍵和日志參數(shù)特征不同;單核模型偏重于處理時間序列或空間位置特征;模型普適性差等。因此,深度學(xué)習(xí)在日志異常檢測方面仍有較大的研究與提升空間。
本文分析日志數(shù)據(jù)的特征和傳統(tǒng)日志異常檢測方法的局限性,結(jié)合CNN 和Bi-LSTM 模型的優(yōu)勢,構(gòu)建CNN-BiLSTM 模型應(yīng)用于日志異常檢測。
2 理論基礎(chǔ)
2.1 詞向量表示
深度學(xué)習(xí)模型的輸入只能是數(shù)值化的張量,Word2Vec 是目前自然語言處理領(lǐng)域常用的詞向量編碼方式,包含CBOW 和Skip-Gram 兩種訓(xùn)練方式,其中CBOW 適合小規(guī)模語料,而Skip-Gram 在大規(guī)模語料上表現(xiàn)更佳。根據(jù)數(shù)據(jù)量大這一特點,日志編碼選擇Skip-Gram 方式,其結(jié)構(gòu)中的詞嵌入層由包含線性變換的隱含層組成[15],通過根據(jù)當(dāng)前詞預(yù)測上下文可能出現(xiàn)的詞,最大化日志訓(xùn)練語料相關(guān)詞出現(xiàn)的概率,以學(xué)習(xí)語料之間的相關(guān)關(guān)系。
令W是對應(yīng)的詞向量矩陣,C為單個數(shù)據(jù)長度,則W矩陣中的每一行為單個切分詞組的Nc維詞向量Mi:

其中:Xi為切詞后的單個詞組one-hot 編碼,第i位為1,其余位皆為0。
2.2 卷積神經(jīng)網(wǎng)絡(luò)
文本卷積神經(jīng)網(wǎng)絡(luò)(Text-CNN)提取文本主要特征以進(jìn)行分類,不同于圖像的卷積過程,為能多角度提取特征和維護文本完整特征表達(dá),Text-CNN 使用多種規(guī)格卷積窗口進(jìn)行一維滑動,且卷積窗口寬度與詞向量長度相等。
如圖1 所示,Text-CNN 是只構(gòu)建輸入層、卷積層、池化層、全連接層四層的卷積模型,其中Mi∈Wc是數(shù)據(jù)中第i個切分詞組對應(yīng)的Nc維詞向量,卷積運算類似濾波器C∈Wh-c,該過程使用RELU 激活函數(shù),將其應(yīng)用于h個詞組的詞向量矩陣提取特征,如從Mi:i+h-1的窗口內(nèi)提取特征Yi:
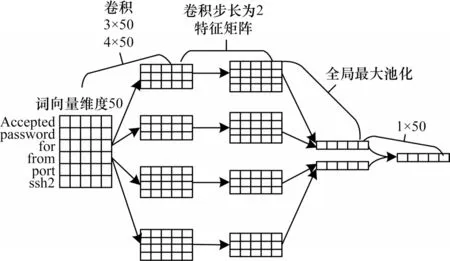
圖1 Text-CNN 特征提取過程Fig.1 Text-CNN feature extraction process

其中:b為偏置項;f為非線性函數(shù)。為防止訓(xùn)練過程中過度依賴局部特征,同時避免過擬合和增強模型泛化能力,在反向傳播過程中使用Dropout 函數(shù),使神經(jīng)元激活值按照概率P隨機丟失,如式(3)所示:

其中:o是逐元素乘法運算符;r是Bernoulli 函數(shù)按照概率P隨機生成的0 或1。
通過多種規(guī)格的卷積窗口提取數(shù)據(jù)不同角度的空間特征,并經(jīng)過池化層選取價值最高的特征向量。
2.3 雙向長短時記憶循環(huán)神經(jīng)網(wǎng)絡(luò)
雙向長短時記憶循環(huán)神經(jīng)網(wǎng)絡(luò)(Bi-LSTM)是在長短時記憶神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)上增加雙向輸入進(jìn)行改進(jìn)[16]。Bi-LSTM 不僅設(shè)置輸入門、遺忘門、輸出門以解決循環(huán)神經(jīng)記憶網(wǎng)絡(luò)長期依賴缺失的問題,而且利用雙向輸入同時捕獲序列正反方向特征信息,從更多角度學(xué)習(xí)序列特征信息。
如圖2所示,Bi-LSTM 借鑒雙向RNN 輸入方式,將RNN 中的循環(huán)單元替換為帶有門控單元的LSTM 循環(huán)單元,等同于在序列兩端各構(gòu)建單向LSTM,且都連接于同一層,這個結(jié)構(gòu)提供輸出層輸入序列中完整的上下文信息,從正反兩個方向?qū)W習(xí)序列特征。
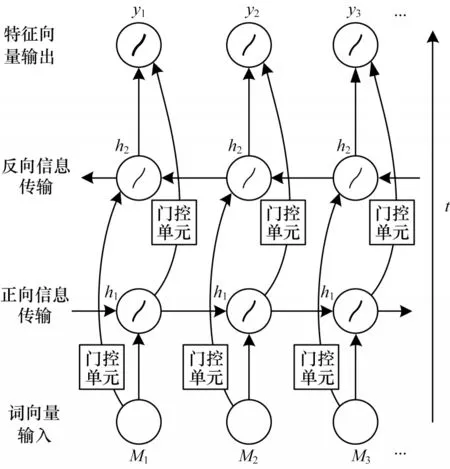
圖2 Bi-LSTM 特征提取過程Fig.2 Bi-LSTM feature extraction process
神經(jīng)網(wǎng)絡(luò)正向更新為:
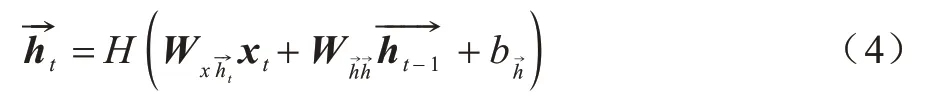
神經(jīng)網(wǎng)絡(luò)反向更新為:
因此,正反雙向循環(huán)神經(jīng)網(wǎng)絡(luò)層結(jié)合輸出為:

其中:t是時間序列;h對應(yīng)下標(biāo)時間的隱層向量;x對應(yīng)下標(biāo)時間的輸入;y對應(yīng)下標(biāo)時間的輸出;W表示對應(yīng)下標(biāo)輸入和隱層、隱層和隱層、隱層和輸出之間的權(quán)重矩陣;b為對應(yīng)下標(biāo)隱層或輸出層偏置向量;H為隱層sigmoid 激活函數(shù)。
3 CNN-BiLSTM 模型
如圖3 所示,基于深度學(xué)習(xí)進(jìn)行日志異常檢測實際是序列預(yù)測任務(wù)[17],本節(jié)根據(jù)日志結(jié)構(gòu)特點,結(jié)合CNN 和Bi-LSTM 模型的優(yōu)勢構(gòu)建CNN-BiLSTM模型應(yīng)用于日志異常檢測。
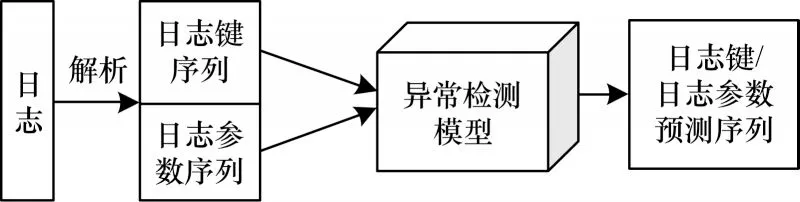
圖3 日志異常檢測流程Fig.3 Procedure of log anomaly detection
3.1 模型結(jié)構(gòu)
CNN 和Bi-LSTM 存在兩種融合結(jié)構(gòu):一種是并行處理結(jié)構(gòu),兩種模型提取特征向量后,拼接融合輸入分類器;另一種是先CNN 后Bi-LSTM 或先Bi-LSTM 后CNN的串行處理結(jié)構(gòu),特征疊加到同一向量進(jìn)行表達(dá)。選擇融合方式需要深入分析日志特征。
日志格式各不相同,但都是由源代碼輸出語句生成[18],如源代碼中的日志打印語句為printf("Accepted password for %s from %s port %d ssh2 ",user,host,port),意圖打印使用安全外殼協(xié)議ssh2 從訪問主機名、IP 地址、端口接收到密碼,就會生成如Feb 28 04:48:54 combo sshd(pam_unix)[6741]:Accepted password for root from 112.64.243.186 port 2371 ssh2 的日志記錄,其中源代碼生成的固定內(nèi)容稱為日志鍵或日志常量,隨系統(tǒng)狀態(tài)變化而生成的變量稱為日志參數(shù),同一源代碼生成的日志記錄為相同類型。日志的基本特征可總結(jié)如下:
1)日志是具有一定格式的文本數(shù)據(jù),日志內(nèi)容可以分為常量的日志鍵以及變量的日志參數(shù)。
2)日志鍵決定日志生成順序,且由于部分任務(wù)時間跨度長、并發(fā)或并行執(zhí)行的原因,其在較長的時間維度上與前后日志條目存在較強的相關(guān)性。
3)同一日志條目內(nèi)日志參數(shù)之間存在關(guān)聯(lián)意義,不同日志條目之間的日志參數(shù)相關(guān)性較弱。
由上分析可知,日志鍵和日志參數(shù)特征存在較大的差異,需要分別處理。一方面,在并聯(lián)結(jié)構(gòu)中,并行處理不僅有利于提高處理效率,而且卷積和循環(huán)神經(jīng)結(jié)構(gòu)互不影響,能夠使特征向量更純粹地表達(dá)日志鍵的長距離序列特征或日志參數(shù)的短距離特征信息;另一方面,在串聯(lián)結(jié)構(gòu)中,日志鍵特征向量經(jīng)過CNN 卷積結(jié)構(gòu)后,只能保留卷積窗口長度內(nèi)的時間序列特征,日志參數(shù)特征向量經(jīng)過Bi-LSTM 后也會受到冗余的長距離依賴關(guān)系的影響,不利于短距離上的空間特征表達(dá)[19-20],而且較深的網(wǎng)絡(luò)結(jié)構(gòu)也不利于日志淺層特征的表達(dá)。綜上,選擇并行的模型結(jié)構(gòu)更有利于日志鍵和日志參數(shù)的特征表達(dá)。
CNN-BiLSTM 模型結(jié)構(gòu)如圖4 所示,其主要由詞嵌入層、卷積-循環(huán)層、特征融合層、分類層四部分組成。模型主要參數(shù)如表2 所示。
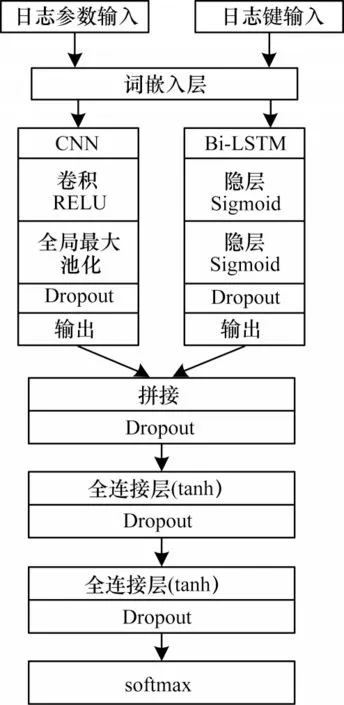
圖4 CNN-BiLSTM 模型結(jié)構(gòu)Fig.4 CNN-BiLSTM model structure

表2 CNN-BiLSTM 參數(shù)設(shè)置Table 2 CNN-BiLSTM parameters setting
詞嵌入層將解析后的日志鍵和日志參數(shù)通過Word2Vec 映射為向量矩陣,即將切分后的日志鍵和日志參數(shù)中的詞組映射為具有固定長度L的一列向量,則單個日志條目映射為N×L大小向量矩陣。在CNN-BiLSTM 模型實驗中,詞嵌入層輸出維度為50,即一條日志鍵或日志參數(shù)經(jīng)詞嵌入層映射為10×50 的向量矩陣作為卷積-循環(huán)層輸入。
卷積-循環(huán)層使用卷積神經(jīng)網(wǎng)絡(luò)提取日志參數(shù)的短距離序列特征,同時使用循環(huán)神經(jīng)網(wǎng)絡(luò)提取日志鍵的時間序列特征。CNN-BiLSTM 模型卷積神經(jīng)網(wǎng)絡(luò)使用寬為3、4 的卷積窗口各50 個,且卷積步長為2。為得到區(qū)分度明顯的特征,使用全局最大池化,單個日志條目經(jīng)過最大池化層后得到長度為50 的輸出向量。雙向循環(huán)神經(jīng)網(wǎng)絡(luò)隱層神經(jīng)元各為25,即得到蘊含時間特征信息長度為50 的特征向量。
特征融合層主要是拼接卷積-循環(huán)層得到的兩種特征向量,并且為增強特征融合度和模型擬合能力,連接兩層使用tanh 激活函數(shù)的全連接神經(jīng)網(wǎng)絡(luò)。根據(jù)卷積-循環(huán)層的輸出,CNN-BiLSTM 模型特征向量融合后會得到1×100 的融合特征向量。
分類層使用softmax 函數(shù),給予預(yù)測序列概率分布判斷日志異常與否。在測試階段,當(dāng)實際日志序列與分布概率最高的預(yù)測日志序列不同,即判斷為異常。
模型使用Adam 優(yōu)化器,學(xué)習(xí)率為1e-5。為進(jìn)行正則化和防止過擬合,全局使用值為0.5的5層Dropout。
3.2 復(fù)雜度分析
由于卷積神經(jīng)網(wǎng)絡(luò)主要操作時間為各個卷積層上的卷積窗口滑動時間,層內(nèi)相乘,層間累加,因此卷積神經(jīng)網(wǎng)絡(luò)時間復(fù)雜度定義為其中:D是卷積層數(shù);l是第l個卷積層;m是輸入向量維度;k是卷積步長;s是卷積核滑動維度;C是通道數(shù)即卷積核個數(shù)。CNN-BiLSTM 模型中使用兩種規(guī)格的卷積核各50 個,且窗口只進(jìn)行一維滑動,因此,時間復(fù)雜度為
循環(huán)神經(jīng)網(wǎng)絡(luò)主要操作時間是輸入向量在各個隱藏單元之間的映射運算時間,因為每個單元都與其他單元之間存在映射關(guān)系,所以循環(huán)神經(jīng)網(wǎng)絡(luò)時間復(fù)雜度定義為O(nd2),其中:n為序列操作次數(shù);d為隱藏單元數(shù)。CNN-BiLSTM 模型使用兩層全連接層實現(xiàn)模型特征融合,由于全連接層實現(xiàn)線性映射運算,因此全連接層時間復(fù)雜度為O(f1?f2+f2?f3+f3?1),其中:f1是輸入向量長度;f2、f3是全連接層神經(jīng)元數(shù)。對于問題規(guī)模f=f1,各層神經(jīng)元個數(shù)為常量,則時間復(fù)雜度為O(f)。
根據(jù)以上分析可知,CNN-BiLSTM 模型中卷積和循環(huán)為并行結(jié)構(gòu),全連接層映射為串行結(jié)構(gòu),因此,CNN-BiLSTM 模型整體時間復(fù)雜度為
相對 于CNN 和LSTM 模型,CNN-BiLSTM模型在兼顧兩種模型優(yōu)勢的同時,其時間復(fù)雜度并未有較高提升,而是于合理時間范疇內(nèi)趨于卷積和循環(huán)結(jié)構(gòu)中較高的時間復(fù)雜度。關(guān)于CNN-BiLSTM 模型的空間復(fù)雜度,考慮到目前系統(tǒng)較高的硬件性能與計算能力,本文不作分析。
4 實驗驗證與分析
本節(jié)對CNN-BiLSTM 深度學(xué)習(xí)模型應(yīng)用于日志異常檢測的性能進(jìn)行驗證。實驗以主流用于日志異常檢測的CNN 和Bi-LSTM 深度學(xué)習(xí)模型為基準(zhǔn)模型,并使用HDFS 和WC_day13 兩個數(shù)據(jù)集作為實驗數(shù)據(jù)集,以驗證CNN-BiLSTM 模型的準(zhǔn)確率和普適性。實驗所涉及深度學(xué)習(xí)模型均基于編程框架keras 實現(xiàn)。
4.1 數(shù)據(jù)集分析與處理
實驗使用從Amazon EC2 平臺收集的公開Hadoop 日志的HDFS 數(shù)據(jù)集,以及包含1998 年世界杯賽官網(wǎng)92 天訪問信息的WC98_day 公開日志數(shù)據(jù)集。
HDFS 日志數(shù)據(jù)集通過200 多個Amazon EC2 節(jié)點上運行的基于Hadoop 的map-reduce 作業(yè)生成,共包含11 175 629 條日志信息,信息包括時間(年月日、時分秒)、源IP、數(shù)據(jù)大小等字段,根據(jù)Block 操作碼可以劃分為575 062 組操作序列,其中2.9% 被Hadoop 領(lǐng)域相關(guān)專家標(biāo)記為異常,類型包括寫入異常等事件,常用于在線主成分分析研究使用[21],后被研究者應(yīng)用于日志異常識別的深度學(xué)習(xí)模型訓(xùn)練。
在HDFS 數(shù)據(jù)預(yù)處理過程中,首先刪除重復(fù)、空白數(shù)據(jù),原11 175 629 條日志信息余11 173 720 條日志信息,之后基于標(biāo)點符號、空格信息,利用正則表達(dá)式解析日志鍵和日志參數(shù)以及Block 標(biāo)簽信息,并刪除不存在區(qū)分度的INFO、dfs、數(shù)字等字段,然后根據(jù)Block 標(biāo)簽信息對應(yīng)日志鍵和日志參數(shù)。
WC98_day 數(shù)據(jù)集用以驗證CNN-BiLSTM 模型的普適性,數(shù)據(jù)收集1998 年4 月26 日—1998 年7 月26 日的92 天世界杯期間賽事官網(wǎng)的1 352 804 107 次請求信息,數(shù)據(jù)記錄包括時間、用戶臨時ID、登錄協(xié)議、登錄狀態(tài)碼、登錄詳情等信息,其中約10%為異常日志。
4.2 評價方法與指標(biāo)
為避免出現(xiàn)測試數(shù)據(jù)中預(yù)測樣本數(shù)據(jù)全為正常以致高準(zhǔn)確率的現(xiàn)象,實驗選用準(zhǔn)確率AAccurary、查準(zhǔn)率PPrecision、召回率RRecall和F1值4個指標(biāo)[22],計算公式如下:


其中:NALL是總樣本數(shù);T是預(yù)測正確的樣本數(shù);TP是正常且預(yù)測為正常的樣本數(shù);FP是正常預(yù)測為異常的樣本數(shù);FN是異常預(yù)測為正常的樣本數(shù)。
準(zhǔn)確率可以直觀體現(xiàn)模型的準(zhǔn)確性。查準(zhǔn)率和召回率可以反映模型是否處于過擬合狀態(tài):查準(zhǔn)率較低說明模型偏向于輸出異常標(biāo)簽,召回率較低說明模型偏向于輸出正常標(biāo)簽;F1 值則綜合反映查準(zhǔn)率和召回率兩個指標(biāo),其值越高說明模型擬合效果越好。
4.3 實驗分析
本節(jié)進(jìn)行3 組對比實驗,驗證CNN-BiLSTM 深度學(xué)習(xí)模型檢測異常日志能力:基于HDFS 數(shù)據(jù)集對比SVM、CNN-BiLSTM、CNN 和Bi-LSTM 模型檢測效果的實驗;基于WC98_day 數(shù)據(jù)集的檢驗CNNBiLSTM、CNN 和Bi-LSTM 模型普適性的對比實驗;基于HDFS 數(shù)據(jù)集的CNN-BiLSTM 模型消融實驗。
實驗1基于HDFS 數(shù)據(jù)集對比SVM、CNNBiLSTM、CNN 和Bi-LSTM 模型檢測效果。通過檢測HDSF 日志數(shù)據(jù)集中的異常日志,并對比常用于海量日志異常檢測的兩種深度學(xué)習(xí)模型CNN 和Bi-LSTM,衡量CNN-BiLSTM 深度學(xué)習(xí)模型的檢測能力。HDFS 數(shù)據(jù)集中60%用于訓(xùn)練數(shù)據(jù),其他40%作為測試數(shù)據(jù)。考慮到數(shù)據(jù)不平衡問題,實驗過程中調(diào)試class_weight 設(shè)置為正常∶異常=0.930 9∶0.069 1 時,模型訓(xùn)練效果較好。
為更客觀地衡量CNN-BiLSTM 模型檢測能力,如表3 所示,CNN 和Bi-LSTM 各模型超參數(shù)分別與CNN-BiLSTM 模型卷積和循環(huán)結(jié)構(gòu)超參數(shù)相同,且輸入是Word2Vec 編碼后的相同詞向量,模型后同樣連接兩層全連接神經(jīng)網(wǎng)絡(luò)。
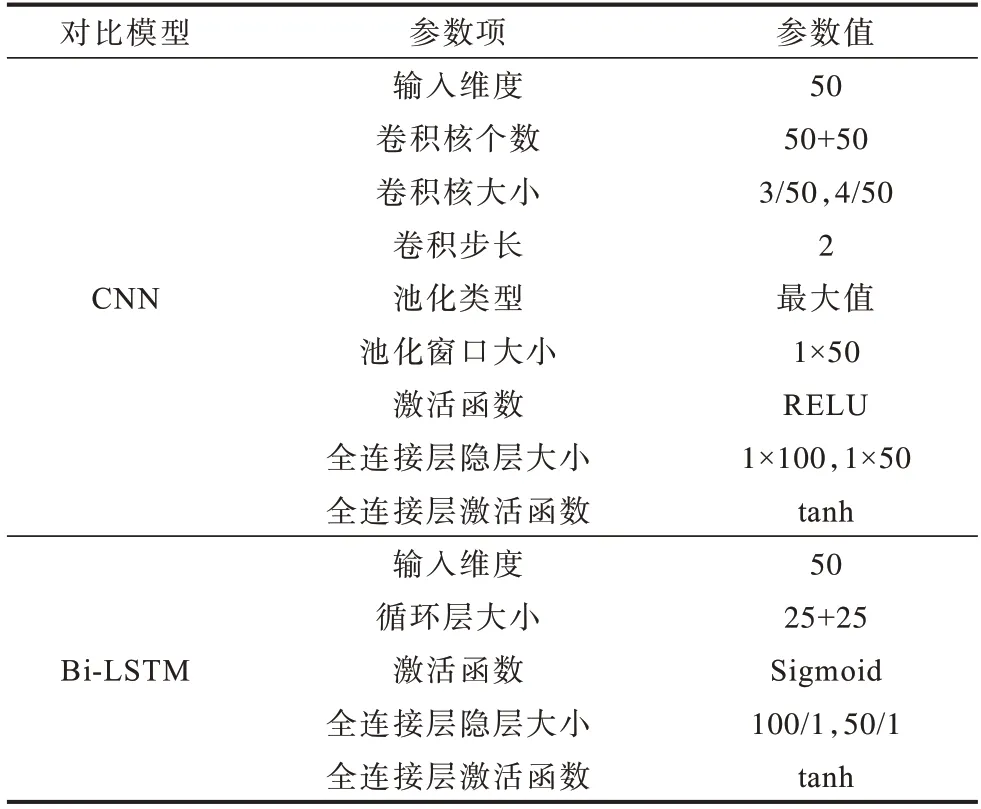
表3 對比模型參數(shù)Table 3 Comparison model parameters
訓(xùn)練使用K折交叉驗證方法,K值為5,最終得到各模型平均準(zhǔn)確率、查準(zhǔn)率、召回率、F1值指標(biāo)如表4 所示。
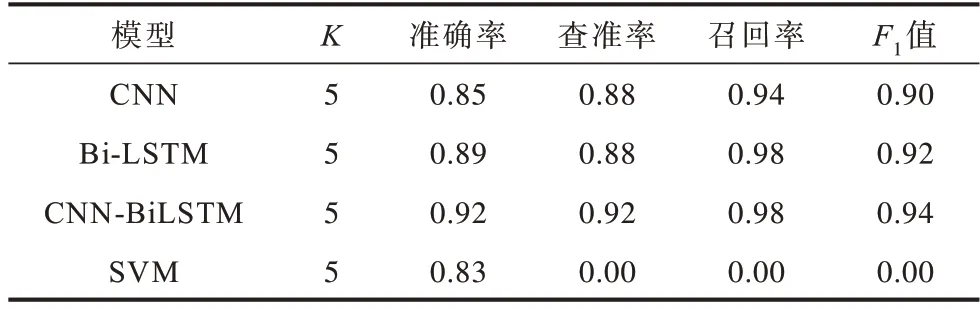
表4 5 折交叉實驗結(jié)果對比Table 4 Comparison of 5-fold crossover experiment results
將4 種模型用于測試數(shù)據(jù)進(jìn)行對比分析,結(jié)果如圖5 所示。可以看出,在超參數(shù)相同的情況下,CNN-BiLSTM 深度學(xué)習(xí)模型較單個CNN、傳統(tǒng)SVM方法準(zhǔn)確率約提高0.14,其查準(zhǔn)率和F1 值也處于領(lǐng)先水平,這說明CNN-BiLSTM 深度學(xué)習(xí)模型兼顧CNN 和Bi-LSTM 模型優(yōu)勢,對比單核模型,性能提升顯著。但其召回率低于最高水平Bi-LSTM 模型約0.11,低于模型本身查準(zhǔn)率約0.15,這是由于數(shù)據(jù)集中正常數(shù)據(jù)遠(yuǎn)多于異常數(shù)據(jù)造成的影響,由此可見,訓(xùn)練過程中CNN-BiLSTM 相比于對比模型更容易受到數(shù)據(jù)集不平衡的影響,更傾向于將異常樣本預(yù)測為正常樣本。
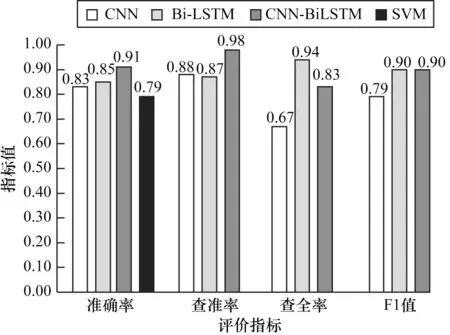
圖5 HDFS 日志異常檢測結(jié)果Fig.5 HDFS log anomaly detection result
實驗2基于WC98_day數(shù)據(jù)集檢驗CNN-BiLSTM、CNN 和Bi-LSTM 模型的普適性,以及使用欠采樣方法解決數(shù)據(jù)不平衡問題的對比實驗。CNN-BiL‐STM、CNN、Bi-LSTM 三種深度學(xué)習(xí)模型在保證公共超參數(shù)相同的情況下,在WC98_day 日志數(shù)據(jù)集上進(jìn)行異常檢測實驗。數(shù)據(jù)集中欠采樣正常和異常數(shù)據(jù)各100 000 條,其中60%作為訓(xùn)練數(shù)據(jù),40%作為測試數(shù)據(jù),class_weight 參數(shù)調(diào)整為正常∶異常=0.5∶0.5,得到各模型準(zhǔn)確率、查準(zhǔn)率、召回率、F1 值指標(biāo)如圖6 所示。
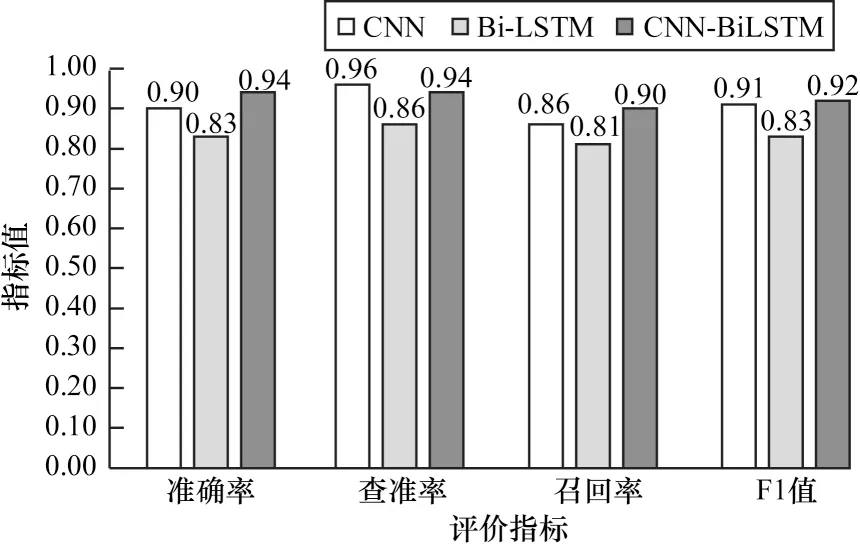
圖6 WC98_day 日志異常檢測結(jié)果Fig.6 WC98_day log abnormal detection result
由實驗結(jié)果分析可知,從HDFS 數(shù)據(jù)集至WC98_day數(shù)據(jù)集的模型遷移實驗中,CNN-BiLSTM 模型依然保持較高的性能優(yōu)勢,其準(zhǔn)確率、召回率、F1 值三個指標(biāo)分別高于次優(yōu)模型CNN 為約0.04、0.05、0.01,同時模型自身召回率低于查準(zhǔn)率0.04,但遠(yuǎn)低于實驗1 中15%的差值,這說明過采樣、欠采樣等這類調(diào)整數(shù)據(jù)數(shù)量但不豐富數(shù)據(jù)特征的方法,能夠在一定程度上解決數(shù)據(jù)集不平衡問題。
此外,對比HDFS 和WC_98day 兩個數(shù)據(jù)集上3 個模型的實驗結(jié)果,結(jié)果表明,CNN 和CNNBiLSTM 模型在WC98_day 數(shù)據(jù)集的上準(zhǔn)確率高于HDFS 數(shù)據(jù)集,WC98_day 相比于HDFS 數(shù)據(jù)集包含更多的文本文字特征,而HDFS 數(shù)據(jù)集日志參數(shù)包含更多的數(shù)值特征,由此可見,CNN 和CNN-BiLSTM模型更擅長提取文本特征,HDFS 數(shù)據(jù)集上的檢測效果受到丟棄的數(shù)值特征影響而降低。
實驗3基于HDFS 數(shù)據(jù)集的CNN-BiLSTM 模型消融實驗。在不影響CNN-BiLSTM 模型提取日志空間和時間序列特征能力的情況下,通過消融CNN-BiLSTM 深度學(xué)習(xí)模型部分結(jié)構(gòu),研究其對于模型的價值:
1)消融CNN-BiLSTM 模型詞嵌入層,將HDFS數(shù)據(jù)集中的訓(xùn)練數(shù)據(jù)自然編碼后作為CNN-BiLSTM模型的輸入,實驗結(jié)果如圖7 所示。可以看出,詞向量CNN-BiLSTM 模型準(zhǔn)確率、查準(zhǔn)率、召回率、F1 值指標(biāo)分別高于自然編碼CNN-BiLSTM 模型13%、8%、6%、13%,由此可見詞嵌入層對模型性能具有積極影響。根據(jù)訓(xùn)練Loss(TrainLoss)和驗證Loss(ValLoss)變化趨勢,可以判斷詞向量CNN-BiLSTM模型在第6 次迭代就已經(jīng)達(dá)到收斂平衡,而自然編碼CNN-BiLSTM 模型在第8 次達(dá)到收斂平衡,證明經(jīng)過日志語料訓(xùn)練Word2Vec 產(chǎn)生的詞向量相比于自然編碼更能凸顯日志語料特征,其在放大特征的同時亦保持良好語料間依賴關(guān)系,比較適合CNNBiLSTM 模型的輸入。
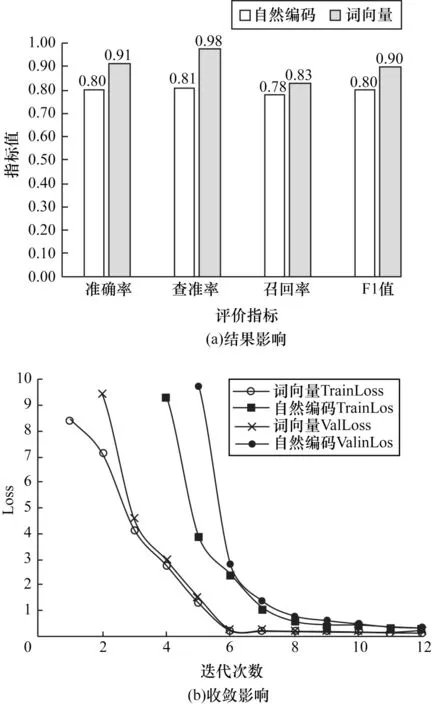
圖7 消融實驗結(jié)果(詞嵌入層)Fig.7 Ablation experiment result(word embedding layer)
2)消融CNN-BiLSTM 模型全連接層,分別設(shè)計兩層全連接層、無全連接層、四層全連接層3 種CNN-BiLSTM 模型,根據(jù)Loss 判斷其對模型收斂速度的影響,實驗結(jié)果如圖8 所示。可以看出,2 層全連接網(wǎng)絡(luò)CNN-BiLSTM 模型在第6 次迭代達(dá)到全局收斂,而無全連接層的CNN-BiLSTM 模型在第11 次迭代達(dá)到收斂,4 層全連接層在第7 次迭代會產(chǎn)生過擬合問題,且含有2 層全連接層網(wǎng)絡(luò)的CNN-BiLSTM深度學(xué)習(xí)模型準(zhǔn)確率為0.91,高于無全連接網(wǎng)絡(luò)模型0.83 的準(zhǔn)確率。實驗結(jié)果表明,合適的全連接網(wǎng)絡(luò)層數(shù)能夠提高模型的擬合能力與特征表達(dá)能力,且在一定程度上促進(jìn)日志鍵時序特征與日志參數(shù)空間特征產(chǎn)生融合關(guān)系,而添加過深的全連接層網(wǎng)絡(luò),容易在訓(xùn)練過程中產(chǎn)生過擬合問題。
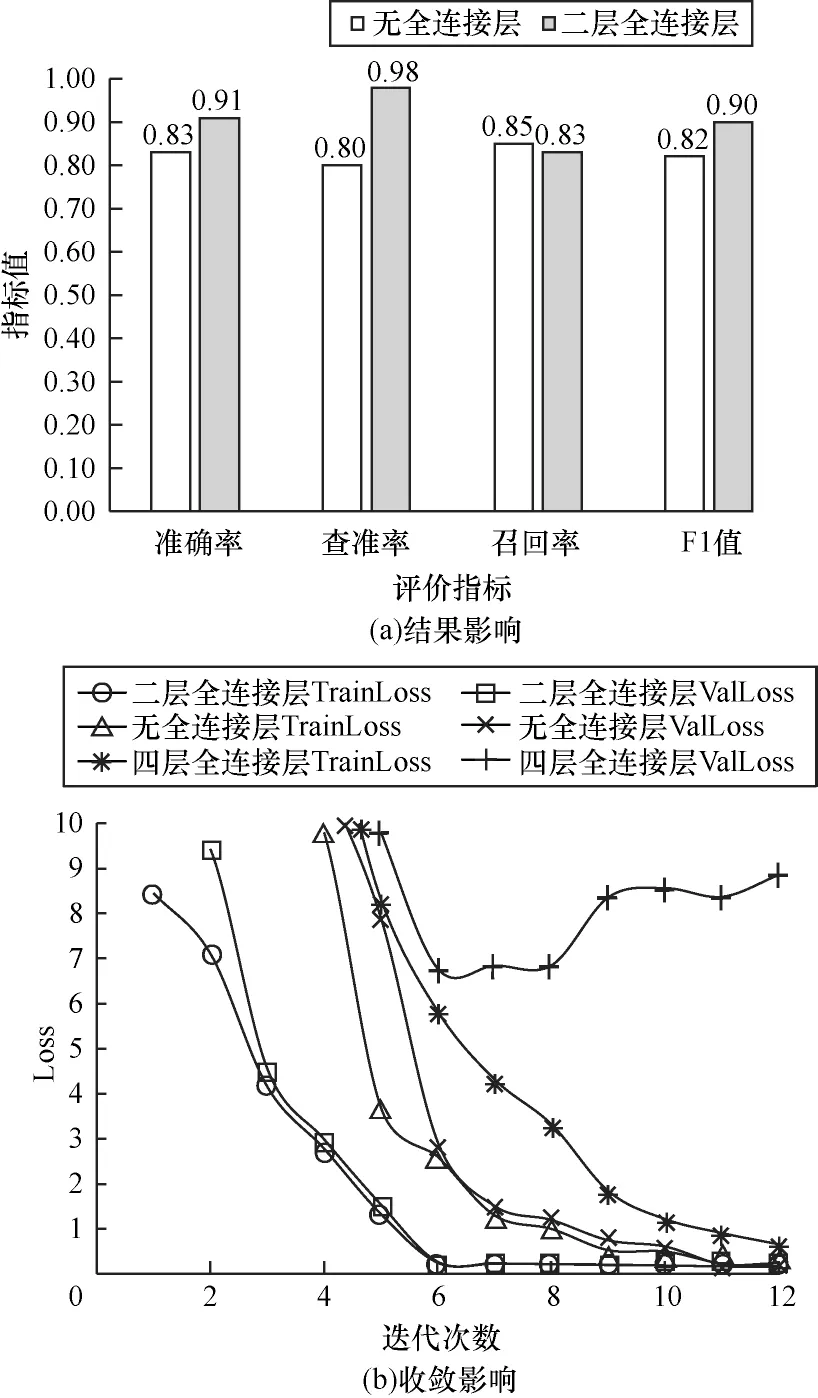
圖8 消融實驗結(jié)果(全連接層)Fig.8 Ablation experiment result(fully connected layer)
以上3 組實驗結(jié)果表明,對比同等深度學(xué)習(xí)模型,CNN-BiLSTM 深度學(xué)習(xí)模型在針對日志異常檢測任務(wù)中,不僅能夠提取日志時間和空間序列特征,達(dá)到領(lǐng)先的檢測水準(zhǔn),而且通過遷移模型至另一數(shù)據(jù)集的實驗證明,其在普適性方面優(yōu)于單核模型,并在保證一定檢測能力的情況下,基本不需要特征工程工作,降低工作量的優(yōu)勢明顯。另一方面,根據(jù)CNN-BiLSTM 模型兩種數(shù)據(jù)集的不同檢測效果對比,亦說明CNN-BiLSTM 模型比較適用于文本特征的學(xué)習(xí)與檢測。
5 結(jié)束語
本文結(jié)合CNN和Bi-LSTM構(gòu)建雙核CNN-BiLSTM模型用于完成日志異常檢測任務(wù),解決海量日志異常檢測模型普適性差、準(zhǔn)確率低等問題。實驗結(jié)果表明,CNN-BiLSTM 模型相比于CNN 和Bi-LSTM模型,準(zhǔn)確率、查準(zhǔn)率、召回率和F1 值指標(biāo)均有不同程度的提升,能夠在提高準(zhǔn)確率的同時降低誤報率。后續(xù)將針對數(shù)據(jù)集不平衡使模型預(yù)測產(chǎn)生偏向的問題,從訓(xùn)練數(shù)據(jù)角度進(jìn)一步提高CNN-BiLSTM 模型性能,同時結(jié)合具體工作場景,在CNN-BiLSTM模型的基礎(chǔ)上研究多核模型在多源日志融合檢測方面的適用性,提高模型輔助解決系統(tǒng)異常問題的能力。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
