混合特征選擇和集成學習驅動的代碼異味檢測
2022-07-14 13:11:30艾成豪高建華黃子杰
計算機工程 2022年7期
艾成豪,高建華,黃子杰
(1.上海師范大學 計算機科學與技術系,上海 200234;2.華東理工大學 計算機科學與工程系,上海 200237)
0 概述
為了評估軟件的可維護性,FOWLER等[1]引入代碼異味的概念,其表示開發人員在實現軟件系統的過程中使用的不良設計和代碼實現。代碼異味使軟件的易變性和易錯性提高[2],且其擁有很長的生命周期[3]。若代碼異味未被及時消除,因它們所導致的工作量和維護成本將會成倍增加,消除代碼異味也會變得更加困難[4],及時檢測出源代碼中所含的代碼異味能夠有效避免此類問題的產生。
目前,已經有很多研究人員提出多種代碼異味檢測技術[5-7],它們中的大多數都是基于規則或啟發式方法,即應用檢測規則從源代碼中計算相關度量值,并與統計所得的閾值進行比較,以確定源代碼中是否含有代碼異味[8]。然而,這些技術均存在一定的局限性,如開發人員對代碼異味的理解不同,在對閾值的設定和度量的選擇過程中帶有主觀性[9],從而導致不同檢測技術對相同代碼異味的檢測結果存在差異[10]。機器學習技術被視為解決上述問題的一種有效方法,其能自動地組合代碼度量,且無需指定任何閾值。目前大部分通用機器學習算法都能取得較高的檢測性能[11],但是它們仍然存在待改進的部分。
在模型選擇方面,沒有一種單一模型能在所有代碼異味檢測中都取得良好的表現[12]。為此,集成學習方法被應用于代碼異味檢測,但是,以往的研究都側重于使用同構集成學習,而對于異構集成學習的研究較少。
在類平衡方面,代碼異味的數據普遍存在不平衡的問題,受代碼異味影響的樣本偏少[13]。相關學者首先使用采樣技術平衡代碼異味正、負(即有異味與無異味)樣本比例,然后利用特征選擇方法得到最優特征子集,將其送入機器學習方法中進行檢測,最終取得較高的檢測性能[14-15]。然而,近期有相關研究指出,類平衡算法可能會降低模型性能,從類對于軟件系統重要性的角度出發,也沒有任何的類需要“被平衡”[16]。
在特征選擇方面,若使用大量特征進行訓練可能會造成“維度災難”問題,從而增加模型訓練時間并使其產生過擬合[17]。然而,代碼異味的特征度量可能存在高度共線問題[18],這意味著在原始數據集中存在的多數度量對代碼異味預測沒有任何幫助,而且會導致模型過擬合。文獻[19]結合多種特征選擇方法,首先使用Spearman 相關系數檢測特征對之間的相關性,選出相關性較高的特征對,然后刪除特征對中信息增益率較小的部分,分析結果表明,該方法的分類性能取得一定提升。
本文針對上述模型和特征選擇中存在的問題,提出一種混合特征選擇和集成學習驅動的代碼異味檢測方法。比較多種機器學習模型在不同代碼異味上的分類性能,以選擇適合被測異味的模型。設計一種混合特征選擇方法,用于去除對分類結果影響較小的無關特征。在此基礎上,構建一種兩層結構的Stacking 集成學習模型,通過集成單一模型的優點來提升分類性能。
1 相關技術
1.1 代碼異味
代碼異味最初的版本涵蓋了22 種異味,其為一種設計上的缺陷,會對軟件維護帶來一定的影響,通常利用重構對代碼異味進行干預。本文主要研究以下4 種在開發過程中較為常見的代碼異味:
1)LM(LongMethod):類中方法具有過長的代碼行數[4]。
2)LC(LazyClass):復雜性較低的類,包含簡單的方法[4]。
3)CDSBP(ClassDataShouldBePrivate):類存在公開(Public)字段,因而違反了封裝中的可見性要求[20]。
4)LPL(LongParameterList):類中方法存在過長的參數列表[20]。
1.2 源代碼度量
源代碼度量(即特征度量)是一組從不同角度對軟件系統進行描述的值,其能使開發人員更好地了解他們正在編寫的代碼。源代碼度量標準主要分為產品度量和過程度量兩大類,產品度量包括代碼規模度量、復雜性度量等,過程度量包括代碼變更度量、開發人員度量等。源代碼度量是代碼異味檢測中的重要依據,不同代碼異味對應的源代碼度量不同,表1 所示為一些常見的代碼異味檢測規則。

表1 代碼異味檢測規則Table 1 Code smell detection rules
1.3 特征選擇
從源代碼中提取的大量代碼度量可能是無關的,即特征與分類標簽(是否為異味)之間的相關性較低。若存在大量無關的特征,會產生“維度災難”問題,從而增加模型運行時間并降低分類性能。特征選擇是解決此類問題最有效的方法之一。特征選擇主要分為過濾法(Filter)、包裝法(Wrapper)和嵌入法(Embedded)[25]3 種:過濾法選取所有特征中最具區別性、不依賴于任何分類算法的特征,其計算所有特征與分類標簽之間的相關性,過濾掉相關性較低的特征,將保留的高相關性特征作為后續模型的輸入;包裝法依據分類算法的預測性能來評判所選特征子集的質量,其預先制定好一種搜索策略,將搜索得到的特征子集送入分類器,預測結果越好,則該子集越有效;嵌入法結合了上述兩者的思想,即將特征選擇過程嵌入到分類算法中,從而篩選出最優子集。
本文采用一種混合特征選擇方法,該方法結合過濾法和嵌入法的優點,融合通過ReliefF、XGBoost特征重要性和Pearson 相關系數得到的特征權重值,以去除與分類標簽無關的特征。
1.3.1 ReliefF
ReliefF 是對Relief 的擴展,其能夠處理多分類數據。ReliefF 是一種過濾法,根據特征對近距離樣本的區分能力賦予特征不同的權重,權重越大,則分類能力越強。每次從樣本集中隨機選擇一個樣本S,尋找與它同類別的K個近鄰樣本,記為NH;從不同于樣本S的類別中各選出K個近鄰樣本,記為NM(C)。迭代更新所有特征的權重ω(x)[26],如式(1)所示:

其中:m為迭代次數;P(C)為第C類的概率;Class(S)為樣本S所屬的類別;NHj為與S同類別的第j個近鄰;NM(C)j為與S不同類別的第j個近鄰;diff(X,S,S')為特征X上樣本S和S'之間的距離。diff(X,S,S')的計算如式(2)所示:
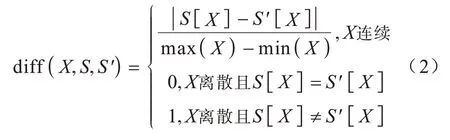
1.3.2 Pearson 相關系數
Pearson 相關系數是一種過濾法,其能夠衡量2 個變量X和Y之間相關性的強弱,當一個變量的變化能引起另一個變量改變時,則稱它們之間具有相關性[27]。Pearson 相關系數的計算公式如式(3)所示:
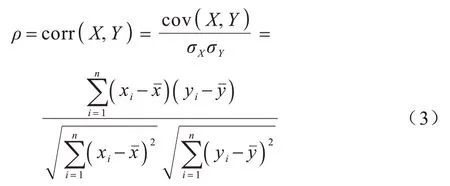
其中:σX、σY分別表示2 個變量的標準差;cov(X,Y)表示2個變量的協方 差;n為樣本數量;xˉ與yˉ分別為變量X和Y的均值。
Pearson 相關系數輸出值ρ的取值范圍在?1~1之間:當取值為負數時,表示2 個變量呈負相關;當取值為0 時,表示2 個變量之間獨立;當取值為正數時,表示2 個變量呈正相關。ρ的絕對值越接近1,則2 個變量的相關性越高,它們之間的聯系也越緊密。
1.3.3 XGBoost 特征重要性
XGBoost 由CHEN等[28]于2016 年提出,其為一種高效、可擴展的機器學習模型。XGBoost 是基于梯度提升決策樹(GBDT)改進的模型,通過Boosting方式組合多棵CART 決策樹,其主要思想是通過迭代添加新的分類器來擬合之前的殘差。XGBoost 對損失函數進行二階泰勒展開來近似目標函數,并通過向目標函數添加控制模型復雜度的正則項來獲取更好的泛化性,從而避免過擬合問題。此外,XGBoost 能充分發揮多核CPU 的優勢進行并行計算,大幅縮短了運行時間。
XGBoost 特征重要性(XGBI)是嵌入法中的一種,其通過XGBoost 在訓練過程中得到每個特征的重要性,特征重要性值越高,則該特征在模型構建與訓練過程中的貢獻越大。XGBoost 利用貪心算法來確定樹的結構,即尋找最優切分點,其通過遍歷所有節點并計算分裂前后的差值得到增益,選擇增益最大的節點進行分裂[29]。
增益的計算公式如式(4)所示:
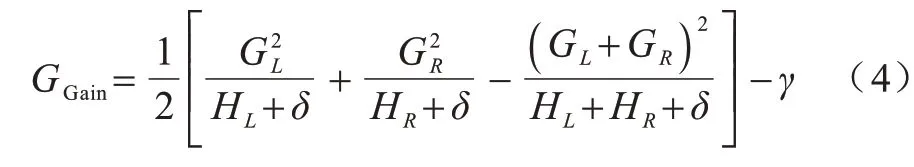
1.4 集成學習
集成學習利用特定的策略組合多個基分類器(即機器學習模型)來構建相對穩定和準確的模型。與單個分類器相比,集成學習能取得更好的結果和更強的泛化能力。在通常情況下,集成學習遵循以下2個原則:
1)基分類器的準確率高于隨機猜測。
2)基分類器之間具有多樣性[30]。
集成學習主要分為Boosting、Bagging 和Stacking這3 種:Boosting 是串行關系,其按順序逐一構造多個基分類器,并以迭代方式調整前一個分類器錯誤分類的樣本權重,用于訓練下一個分類器;Bagging對訓練樣本采用Bootstrap 抽樣策略,并行地訓練多個獨立的基分類器,并將它們的結果以多數投票或取平均的方法進行結合。以上2 種集成學習是同質集成,即只包含同種類型的基分類器。本文采用的Stacking 是一種異構集成學習模型,該模型由WOLPERT[31]于1992 年提出,其通過結合多種不同類型的機器學習模型,使得模型的邊界變得更穩定,避免單一模型預測性能不佳、魯棒性較差的問題。Stacking 集成學習模型通常被設計為兩層框架的結構,為此引入了基分類器和元分類器的概念。第一層由多個基分類器組成,為了防止過擬合,采用K 折交叉驗證對其進行訓練,合并它們的預測結果形成新數據集后輸入第二層的元分類器中,從而得到最終的結果。Stacking 集成學習模型的構建過程如圖1所示,第一層以5 折交叉驗證為例,其實現過程如算法1 所示。

圖1 Stacking 集成學習模型構建過程Fig.1 Construction procedure of Stacking ensemble learning model
算法1Stacking 集成學習模型算法


2 本文代碼異味檢測方法
針對使用大量特征進行訓練可能引起“維度災難”以及單一模型泛化性能不佳的問題,本文提出一種混合特征選擇和集成學習驅動的代碼異味檢測方法。該方法首先從開源項目中提取度量并與對應的分類標簽合并構成代碼異味數據集,然后對數據歸一化后的數據集進行混合特征選擇,最后將得到的特征子集送入后續的Stacking 集成學習模型進行分類。本文方法流程如圖2 所示。
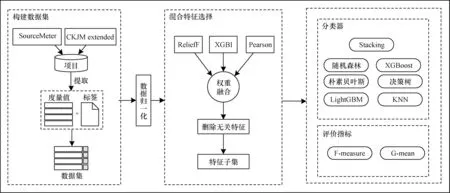
圖2 本文代碼異味檢測方法流程Fig.2 The procedure of code smell detection method in this paper
2.1 數據集
本文考慮4 個大小不一且屬于不同領域的Java開源項目,分別為Rhino 1.6R6、ArgoUML0.26、Mylyn 3.1.1 和Eclipse 3.3.1,用以構建代碼異味數據集。由于本文方法需要大量自變量,即面向對象的度量值,因此使用SourceMeter 和CKJM extended 這2 種常用的度量計算工具,共提取78 個度量,度量說明如表2、表3 所示。
在所提取的度量中,存在一小部分相同的度量,本文按照文獻[32]中的做法將它們保留,保留的原因是所用的度量計算工具針對的對象不同,SourceMeter 是針對源文件,而CKJM extended 是對字節碼文件進行計算,因此,兩者得到的度量值不同[33]。數據集中的異味標簽均來自于文獻[20],最后,利用類名作為匹配鍵合并度量與異味標簽,得到一個含有14 063 條樣本、78 個度量以及4 種代碼異味的數據集,數據集格式如圖3 所示。
2.2 數據歸一化
在模型構建之前,通常需要將不同規格的數據轉換為統一規格,或將不同分布的數據轉換成所需的特定分布,即數據需要無量綱化。文獻[34]指出數據歸一化不僅能夠增強分類器的性能,而且可以加快求解速度,提高模型的求解質量。Min-Max 歸一化是最常用的數據歸一化方法,其對原始數據進行線性變換,轉換公式如式(5)所示:
其中:Xmin和Xmax分別是第i個特征的最小值和最大值;X*的取值在[0,1]范圍內。
2.3 混合特征選擇
使用原始的高維特征集不但會增加分類器的計算成本,還可能降低其識別性能,因此,需要使用特征選擇方法優化特征數量。文獻[25]指出單一的特征選擇方法可能會在篩選特征的過程中忽略一些潛在信息,導致結果不穩定。文獻[35]通過結合多種特征選擇方法來提高特征選擇的魯棒性。本文提出一種混合特征選擇方法,該方法結合ReliefF、XGBoost 特征重要性和Pearson 相關系數這3 種常見的特征選擇方法,計算出特征權重并進行融合,然后去除權重值較低的無關特征。在對特征權重向量融合的過程中,需要確保不同方法所生成的權重具有可比性,因此,在此之前需對權重向量進行Min-Max歸一化。本文混合特征選擇方法的輸入是歸一化后的數據集,輸出是特征子集,具體步驟如下:
步驟1由ReliefF、XGBoost特征重要性和Pearson相關系數分別生成含有所有特征的權重向量。
由ReliefF 得到的權重向量為:
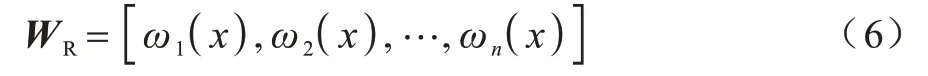
由XGBoost 特征重要性得到的權重向量為:
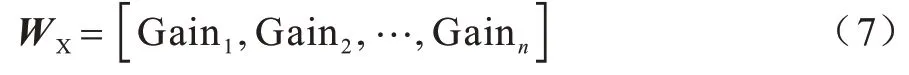
由Pearson 相關系數得到的權重向量為:

步驟2利用融合策略,將通過3 種特征選擇方法得到的權重向量進行合并,融合策略為:

步驟3將特征權重融合后的值按從高到低降序排列,刪除權重值較低的后20%的特征,這些特征與分類標簽的相關性較弱。
不同特征選擇方法的側重點不同,將它們結合可能會在特征空間中產生更好的表示以描述數據,從而彌補單一特征選擇方法偏向某一方面的缺陷。本文方法能在一定程度上減少無關特征,避免有效特征信息損失,以達到降低計算成本并提高后續算法性能的目的。
2.4 Stacking 集成學習模型構建
為了更好地檢測代碼異味,避免單一模型泛化性能不佳的問題,本文構建一種兩層結構的Stacking集成學習模型。該模型的第一層由異構基分類器構成,這些基分類器需要具有較高的準確性以及多樣性,為此本文使用LGB(LightGBM)、XGB(XGBoost)和RF(Random Forest)這3 種理論較成熟的模型,它們之間具有一定差異,能通過使用不同的學習策略來從不同角度和空間學習特征,實現模型間的互補,從而提升Stacking 集成學習模型的整體性能。
第一層采用K 折交叉驗證對基分類器進行訓練,即將數據隨機劃分成K 份,其中的K?1 份作為訓練集,剩余的1 份作為測試集,重復K 次。由于代碼異味數據集大多呈不平衡狀態,因此本文在此層的每一折中都應用分層抽樣,以保證代碼異味的分布與原始訓練集中的分布相同[23]。
第二層元分類器的輸入不再是原始數據的特征,而是各基分類器的預測結果合并變換后的數據。文獻[36]指出基分類器使用復雜的非線性變換提取數據特征,容易過擬合,元分類器無需使用復雜的分類器,因此,本文使用與其相同的分類器LR(Logistic Regression),該分類器通常被用來處理二分類問題,其結構簡單且可以通過正則化進一步防止過擬合。
本文所構建的Stacking 集成學習模型流程如圖4 所示。
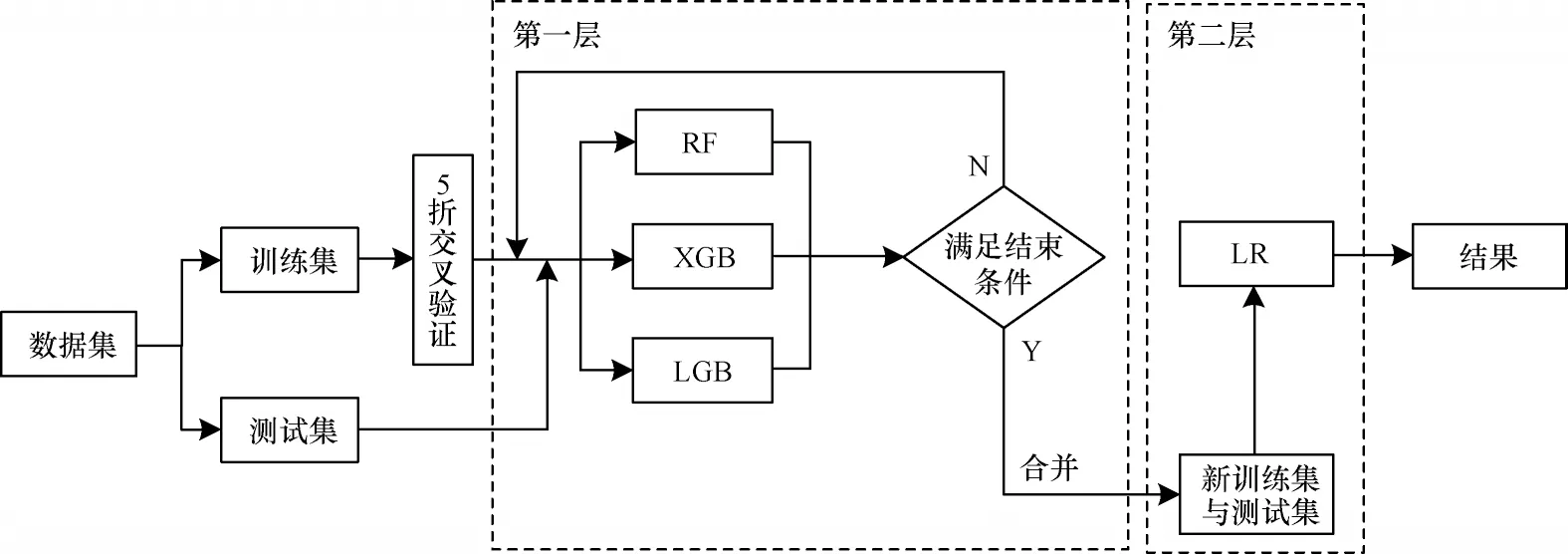
圖4 Stacking 集成學習模型流程Fig.4 The procedure of Stacking ensemble learning model
3 實驗結果與分析
本節在4 個項目上驗證混合特征選擇和集成學習驅動的代碼異味檢測方法的有效性,主要解決如下4 個問題:
Q1:哪些機器學習模型能夠在本文所檢測的代碼異味中取得良好的表現?
Q2:混合特征選擇方法是否有效?
Q3:Stacking 集成學習模型能否提高代碼異味檢測的性能?
Q4:與其他方法相比,本文所提方法是否具有優勢?
3.1 實驗環境
本文實驗環境設置:操作系統為Windows 10,處理器為Intel?CoreTMi7-8550U @1.80 GHz,內存為16 GB,實驗工具為Jupyter Notebook,編程語言為Python。在實驗過程中,采用10×5 折交叉驗證的方式進行驗證,即取10 次5 折交叉驗證的平均值,以確保結論的可靠性。
3.2 評價指標
由于本文構建的模型是用于檢測模塊中是否含有代碼異味,屬于二分類問題,因此模型性能的好壞可以通過混淆矩陣展現,混淆矩陣如表4 所示。
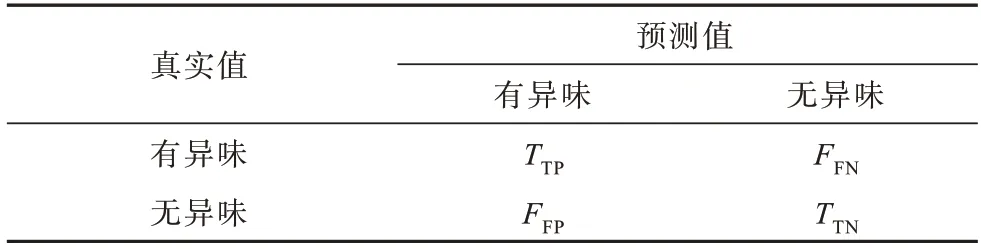
表4 混淆矩陣Table 4 Confusion matrix
混淆矩陣中各元素的含義分別為:1)TTP(True Positive):正確識別為異味的異味樣本數;2)TTN(True Negative):正確識別為無異味的無異味樣本數;3)FFN(False Negative):錯誤識別為無異味的異味樣本數;4)FF(PFalse Positive):錯誤識別為異味的無異味樣本數。
由混淆矩陣衍生出多種評價指標,為了更直觀地評估本文方法的性能,考慮F-measure 和G-mean這2 種指標,F-measure 和G-mean 均含有精確率(Precision)和召回率(Recall)。
Precision 表示預測為異味的樣本中真正為異味的樣本占比,如式(10)所示:

Recall 表示正確預測為有異味的樣本占真實異味樣本的比例,如式(11)所示:

F-measure 是一個綜合評價指標,因為Precision和Recall 會出現相互矛盾的狀況,存在一定的局限性,難以單獨用于評價分類性能,因此,必須綜合考慮這兩者。F-measure 是Precision 和Recall 的加權調和平均值,其值越大,則模型性能較好。F-measure計算如式(12)所示:
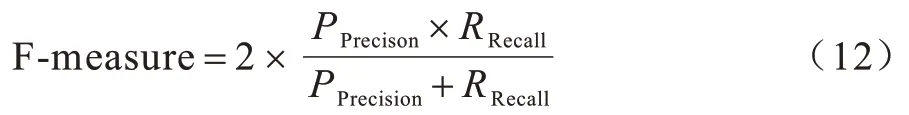
代碼異味數據集通常呈現類不平衡狀態,G-mean 指標能夠更直觀地評價類不平衡性能,其計算如式(13)所示:
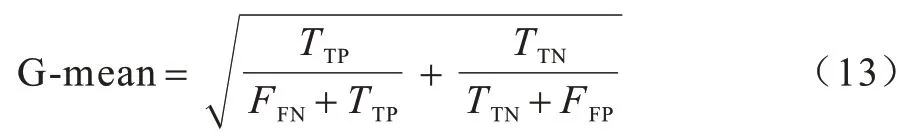
3.3 結果分析
1)解決Q1 問題。
表5 所示為XGB(XGBoost)、LGB(LightGBM)、隨機森林(RF)、決策樹(DT)、K 最近鄰(KNN)和樸素貝葉斯(NB)這6 種機器學習模型在不同代碼異味上的檢測性能,最優結果加粗表示。從表5 可以看出,綜合性能排在前三的模型為XGB、LGB 和RF,它們都是基于樹的模型,與文獻[37]中的結論相符,即基于樹的模型在代碼異味檢測中都有著良好的表現。分析表中的數據可以發現,在LC、CDSBP、LPL這3 種代碼異味上XGB 表現最好,而LGB 在LM 這一種異味上優于其他模型,由此可得,并沒有一種模型適合檢測所有的代碼異味。因此,本文選擇XGB、LGB 和RF 作為后續Stacking 集成學習模型的基分類器,以避免單一模型泛化性能不佳的問題。
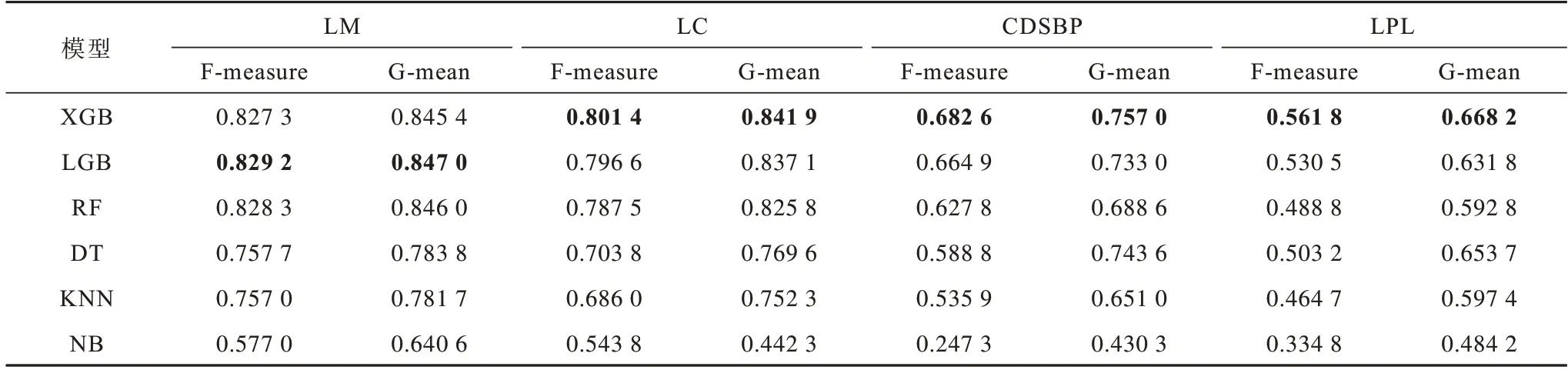
表5 不同分類器的代碼異味檢測結果Table 5 Code smell detection results of different classifiers
2)解決Q2 問題。
表6 所示為特征選擇前后XGB、LGB 和RF 模型在不同代碼異味上的F-measure 對比結果。從表6可以看出,在多數情況下,特征選擇前后的F-measure 值相差不大,由此可得數據集中存在無關特征,去除這些無關特征并不會對結果造成影響。

表6 特征選擇前后模型的F-measure 值對比Table 6 Comparison of F-measure values of models before and after feature selection
圖5 所示為所選機器學習模型在4 種代碼異味數據集上進行特征選擇前后的平均訓練時間,即進行一次5 折交叉驗證的時間。從圖5 可以看出,XGB、LGB 與RF 在特征選擇后的平均訓練時間相較特征選擇前都有所降低,其中,XGB 下降幅度最大,RF 其次,下降幅度最小的是LGB。以XGB 為例,在特征選擇前,其在4 種代碼異味數據集上的訓練時間為31.23 s,而經過特征選擇后,訓練時間減少至26.18 s,時間縮短效率為16.17%。由此可見,特征選擇在確保F-measure 的同時能夠在一定程度上縮短模型的訓練時間。

圖5 特征選擇前后模型的平均訓練時間對比Fig.5 Comparison of average training time of models before and after feature selection
3)解決Q3 問題。
從表7 可以看出,相較單一模型,Stacking 集成學習模型在特征選擇后的數據中都能夠取得良好的分類性能,在F-measure 和G-mean 評價指標上均有一定提升。經分析,Stacking 集成學習模型優于單一模型的原因如下:Stacking 集成學習模型能夠結合多樣化的模型,這些模型能夠從不同角度來觀測數據,從而充分發揮每一種模型的優勢,同時屏除分類結果較差的部分,以糾正單一模型的預測偏差;從模型優化的角度來看,單一模型在訓練過程中可能會有陷入局部最優的風險,導致其泛化性能不佳,而集成多種模型可以減少此類風險發生的概率[38];Stacking集成學習模型通常為兩層結構,第二層結構能糾正第一層結構產生的誤差,從而提高模型的分類精度。

表7 特征選擇后單一模型和Stacking 集成學習模型的性能比較Table 7 Performance comparison of single model and Stacking ensemble learning model after feature selection
4)解決Q4 問題。
將本文模型與文獻[39]模型、文獻[40]模型以及異構集成學習中的Voting 模型進行比較,這些對比模型均采用本文的數據集,以確保可比性。針對文獻[39]模型,使用自編碼器將原始數據降至與本文特征選擇后相同的維度,而對于文獻[40]模型以及Voting 模型,均使用本文特征選擇后的數據,并將Voting 模型中的基分類器與本文中的Stacking 模型保持一致,即XGB、LGB 和RF。從表8 可以看出,文獻[39]模型和文獻[40]模型的性能指標均低于本文模型,而Voting 模型僅在檢測LM 代碼異味時略優于本文模型,由此可見,本文模型具有良好的魯棒性。

表8 不同模型的性能比較Table 8 Performance comparison of different models
4 結束語
本文提出一種混合特征選擇和集成學習驅動的代碼異味檢測方法,其融合由多種特征選擇方法得到的特征權重以去除無關特征,同時利用Stacking集成學習模型結合多種單一機器學習模型的優勢來提升最終的分類性能。實驗結果表明,使用混合特征選擇和集成學習方法能夠取得較好的代碼異味檢測結果,即本文所提檢測方法具有有效性。代碼異味通常都呈類不平衡狀態,可能會對檢測結果產生一定影響從而降低模型的性能,可利用采樣技術來平衡代碼異味數據集,因此,下一步將求證該技術在代碼異味檢測中是否有效,并使用模型可解釋性方法探究采樣技術對代碼異味預測模型性能的影響。此外,本文僅使用了產品度量,加入過程度量后是否能提高分類精度也是今后的一個研究課題。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
