語言智能技術發展與語言數據治理技術模式構建
2022-07-15 01:29:25張凱薛嗣媛周建設
語言戰略研究 2022年4期
張凱 薛嗣媛 周建設


提 要 梳理近60年(1960~2019)語言智能技術專利申請文獻,可以發現近5年語言智能技術進步顯著,預計在未來較長一段時期內仍將處于技術爆發期。當下,語言數據治理的重要性日漸凸顯。分析當前智能技術賦能下機器翻譯、智能客服、網絡輿情監測、多語言資源建設等語言數據熱點服務,指出語言數據治理體系面臨的技術困境:(1)語言數據的偏見現象;(2)經典語言治理模型的短板。為破解困境并彌補經典數據挖掘模式的短板,提出點狀聚合、線性組合和多層事態3種語言數據治理模式并展開對比分析,以期對智能化數據治理提供參考。
關鍵詞 專利文獻分析;語言智能技術發展;語言數據治理;語言數據治理技術模式
中圖分類號 H002 文獻標識碼 A 文章編號 2096-1014(2022)04-0035-14
DOI 10.19689/j.cnki.cn10-1361/h.20220403
A review of the literature on patent applications for language intelligence technology over the past 60 years (1960– 2019) reveals that language intelligence technology has advanced significantly in the past five years. It is anticipated that the technological explosion will last for a long time in the future. The rapid development of language intelligence technology highlights the increasing importance of language data governance. Focusing on language data service sectors such as machine translation, intelligent customer service, opinion monitoring, and multilingual resource construction, this review paper analyses the tendencies of language data service development empowered by intelligent technologies. It points out that the language data governance system faces two technical complications, namely language data bias, and limitations of the traditional language governance models. In order to resolve the dilemma and challenges in language data processing and mining, three language data governance models are proposed and comparatively analysed, i.e., point aggregation, linear combination, and multi-layer state of affairs, which may serve as a reference for intelligent data governance.
patent document analysis; language intelligence technology; language data governance; language data governance model
當前人類社會正處于從信息時代到智能時代的過渡期,智能技術給人類生活帶來了深遠影響和美好前景。在人類不斷探索智能技術的過程中,數據資源的重要性日益凸顯,數據“管理”也逐漸走向數據“治理”。這意味著以語言符號體系為基礎構成的各種數據將在開放的視野中被重新審視。
語言智能、語言數據治理均以語言符號為起點,分別向機器數字空間和社會文化領域展開探索,智能技術為關注社會群體空間和網絡虛擬空間的語言數據研究提供了信息化條件下的治理手段,使治理的智能化發展成為可能。語言教學、新媒體及自媒體等現實場景,對智能技術和數據治理提出了更高的標準和要求。本文結合語言智能技術發展趨勢,總結技術發展面臨的挑戰,綜述技術賦能語言數據治理的現狀,探索語言數據治理智能化發展的新模式。
一、從專利文獻看近60年全球語言智能技術趨勢及分布
專利文獻記載了發明創造的內容,是科研機構和高科技企業的核心競爭力,相較學術論文更貼近實際應用或產品,是一種重要的知識產權保護手段。挖掘和分析語言智能方向的專利文獻,可以通覽語言智能技術發展,明晰語言智能技術創新方向和重點,同時也能為語言數據挖掘和智能化治理提供技術依據。
(一)全球語言智能技術發展趨勢
作為人工智能范疇的專門術語(楊爾弘,等2018),“語言智能”是語言學、認知科學與人工智能的交叉和融合,是探究自然語言(人腦語言活動)和機器語言之間同構關系的科學(周建設,等2017;周建設2020)。語言智能包含計算智能和認知智能,依據數據對象分為人類生物特征處理、圖像信息處理、文本語言處理等方面的技術。故此,本文將近60年(1960~2019)上述3項技術專利文獻作為語言智能概念范疇下的分析對象。
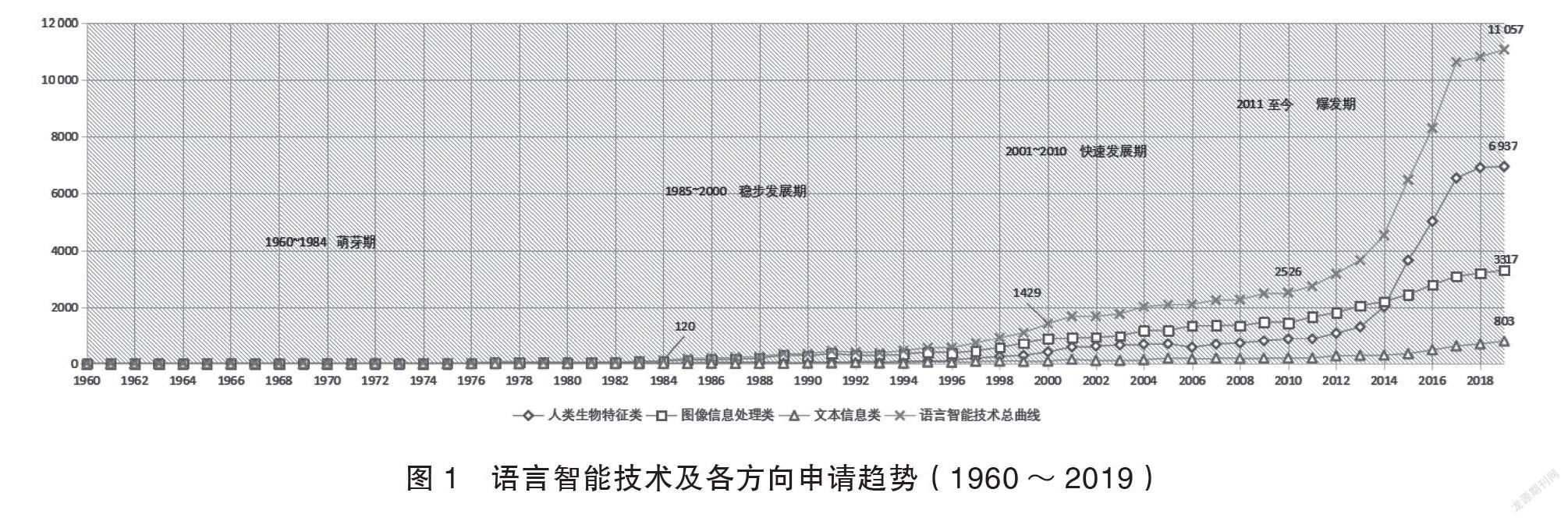
專利文獻數據來源于Inspiro、incoPat平臺,通過文獻內容篩選及數量統計,可知:人類生物特征處理類(共計41 059件,其中G06K9/00分類共計22 612件,占比約55%,多是針對語言衍生數據、人工語言數據的技術創新)和圖像信息處理類(共計40 387件,其中文字識別和G06K9/00分類共計3594件,占比約8.9%,多是針對語言學科數據、話語數據、人工語言數據的技術創新)的申請數量相當,各占比46%左右。語言文本信息處理技術類共計6347件,占比7.2%,多是針對語言學科數據、話語數據、語言代碼數據的技術創新。將上述技術文獻的歷年申請情況按時間先后進行統計,呈現出的趨勢如圖1所示。
圖1中,總曲線和3個方向技術的申請文獻呈現出一定規律性趨勢,同時三者之間也存在一定差異。按照總曲線趨勢可簡單進行如下階段性劃分。
(1)萌芽期(1960~1984)。自1960年起,每年3類處理技術均有少量的分布,申請量沒有明顯差距,總量維持在幾十項的規模。人類生物特征處理、圖像信息處理技術基本在同一階段開始被關注。1965~1975年的10年間,生物特征識別技術受到重視;1977年后針對圖像數據的內容對比、目標識別技術取得一定進展并引起了研究人員的持續關注。而文本符號處理技術發展一直相對滯后。1984年,語言智能技術專利單年申請量首次突破三位數,總曲線中出現了首個關鍵點,之后年份增速開始提升。
(2)穩步發展期(1985~2000)。該階段內各方向申請量出現明顯增加,增長速度較為穩定,2000年年底申請總量首次接近1500件/年,總曲線出現第二個關鍵點。圖像信息處理受到了更多的關注,增長量較其他類明顯,本階段結束時該方向增長約6倍,研究重點由圖像的內容對比轉移到了基于圖像內容的信息檢索技術研究,其間自然場景下的文字符號識別技術開始受到關注。文本符號處理技術在該時期復蘇,相較圖像信息處理技術發展申請量上存在約15年差距,直到1999年申請量單年破百(圖像信息處理1985年達到),此后關于文本符號的內容抽取技術受到更多青睞。
(3)快速發展期(2001~2010)。本階段結束時,語言智能技術申請總量增加0.76倍,圖像信息處理得到持續關注,圖像內容檢索技術、人類面部特征識別、文本內容結構化抽取、文本信息對比等技術點最為突出,增長趨勢愈發明顯。在快速發展期,圍繞語言符號的智能問答技術申請開始出現,圖像、文本內容分類的創新技術呈現較快發展。
(4)爆發期(2011年至今)。以深度學習為代表的人工智能技術快速發展,引起各類語言模型不同程度的發展和創新,對語言智能技術起到極大促進作用。該時期語言智能技術專利申請量呈井噴式增長,截至2019年年底,總量增長3.1倍,2015年后每年遞增25%左右。2014年年底,人類生物特征處理和圖像信息處理技術申請量首次持平,以生理特征智能識別為代表的生物處理技術快速突破,該類申請爆發,說明該階段有較強研究力量投入該領域且創新成果顯著。文本信息處理技術呈現技術點齊頭并進、增長明顯的態勢,其中語言數據的關系抽取、實體識別技術等逐步成為研究核心,分析可知該時期圍繞各類型語言數據開展了大量數據挖掘工作,進行了較好技術儲備,為展開數據治理提供了基礎。
由總曲線不難發現,近5年語言智能技術取得的進步是顯著的,同時在發展過程中研究關注點也出現多次轉移。參與本次分析的3類技術,在萌芽期數據相差不大,如今差異明顯。以2019年專利申請量為例:人類生物特征處理6937件、圖像處理3317件、文本處理803件,可以看出具有人類生物屬性和圖像符號屬性的數據相比文字類抽象數據的顯性特征更強,在技術創新方面率先取得突破。語言信息技術雖在2011年后得到顯著發展,但較其他兩類數據的處理技術申請量上仍有約15年的差距。依據總體趨勢預判,未來較長一段時期語言智能技術仍處于技術爆發期,更具抽象特性的語言數據將會受到更多研究人員的關注。
(二)語言智能技術分布情況
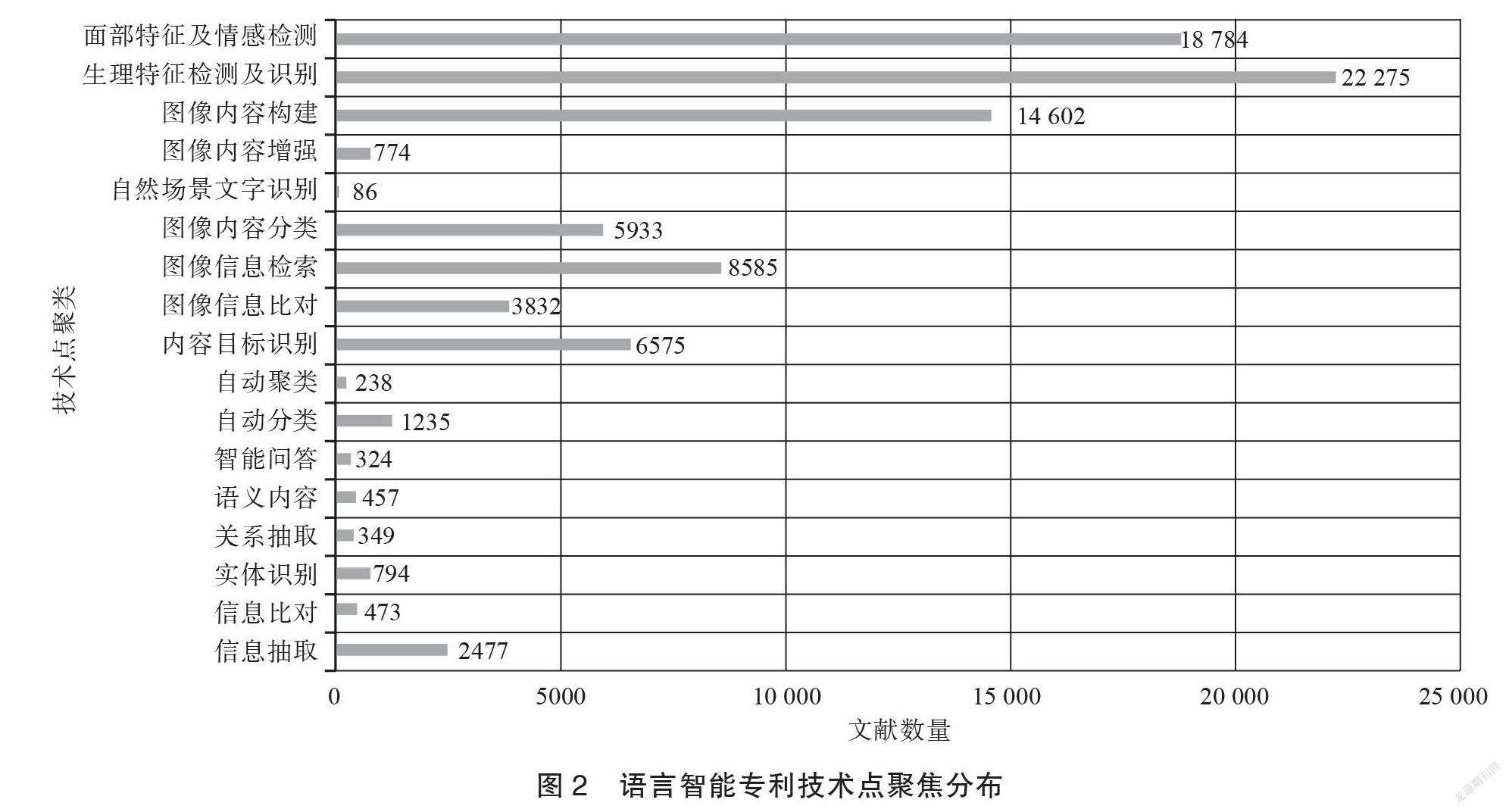
本研究共篩選出相關文獻87 793件,按照技術方向進行聚類分析,形成技術點聚焦分布圖。如圖2所示,共形成17種技術聚焦點,其中人類生物特征類2種,圖像信息處理類7種,語言信息類8種。
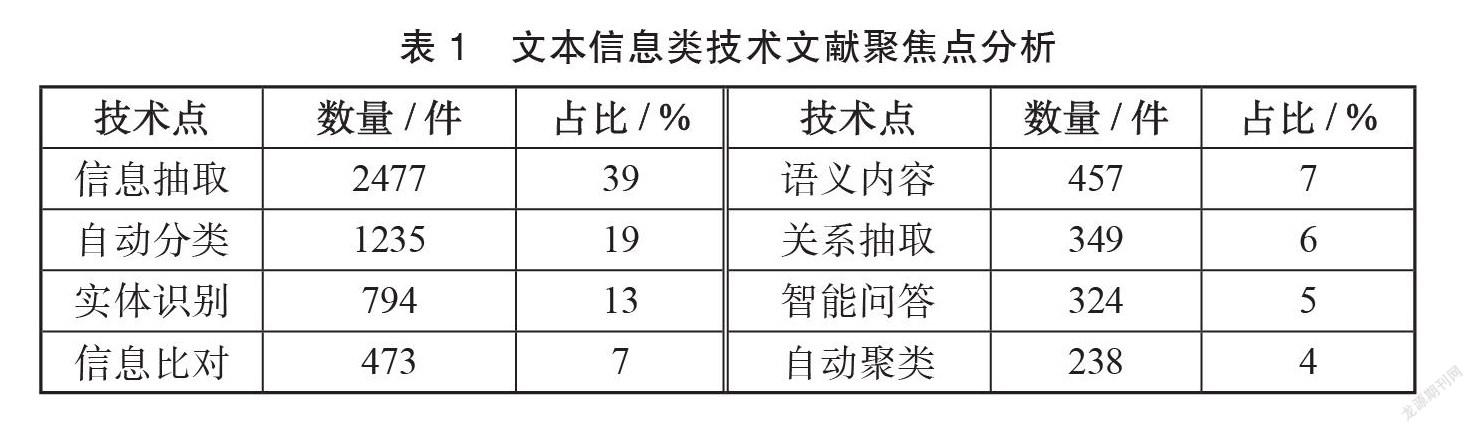
從申請量上看,文本符號信息技術文獻量較其他兩類存在較大差距,進一步觀察此類技術的6347件文獻并完成技術占比統計,具體結果見表1。
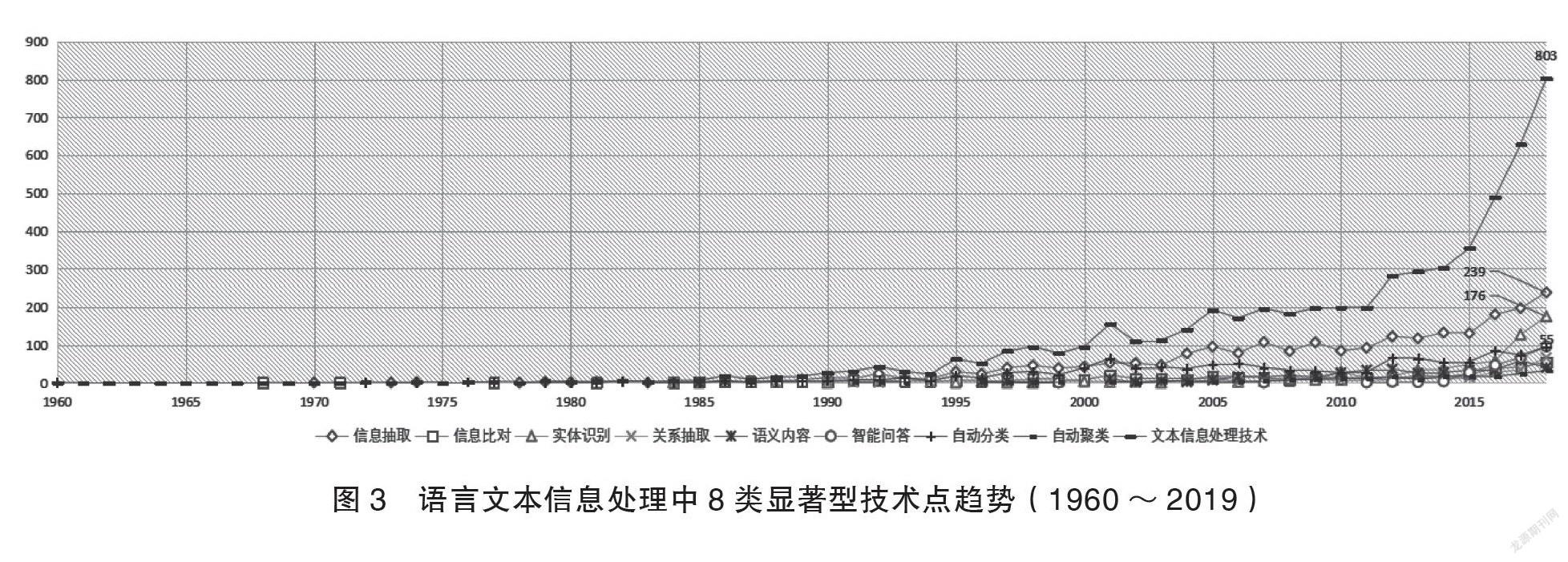
由表1可知,語言信息抽取(39%)是占比最大的細分領域,其次是自動分類(19%)和實體識別(13%),上述3類研究已有一定的技術儲備,在開展語言符號的信息處理中已發揮重要作用。語義內容(7%)、關系抽取(6%)、智能問答(5%)等聚焦點近年來雖然一直是研究熱點,但申請占比還不突出,由此來看,上述聚焦點距離業界實踐應用還有一定距離,仍將是重點和難點研究方向。表1中8類顯著型技術點發展趨勢顯示,上述技術點均在1990年后呈現增長態勢(見圖3)。1991~2010年的20年間,各技術點均得到快速發展,2011年后全球范圍內語言信息技術專利申請量增速明顯,其中語言信息抽取、實體識別技術最為突出,隨著各行業中語言數據資產化進程的開展,上述兩個方向仍將同步維持較高成果產出。
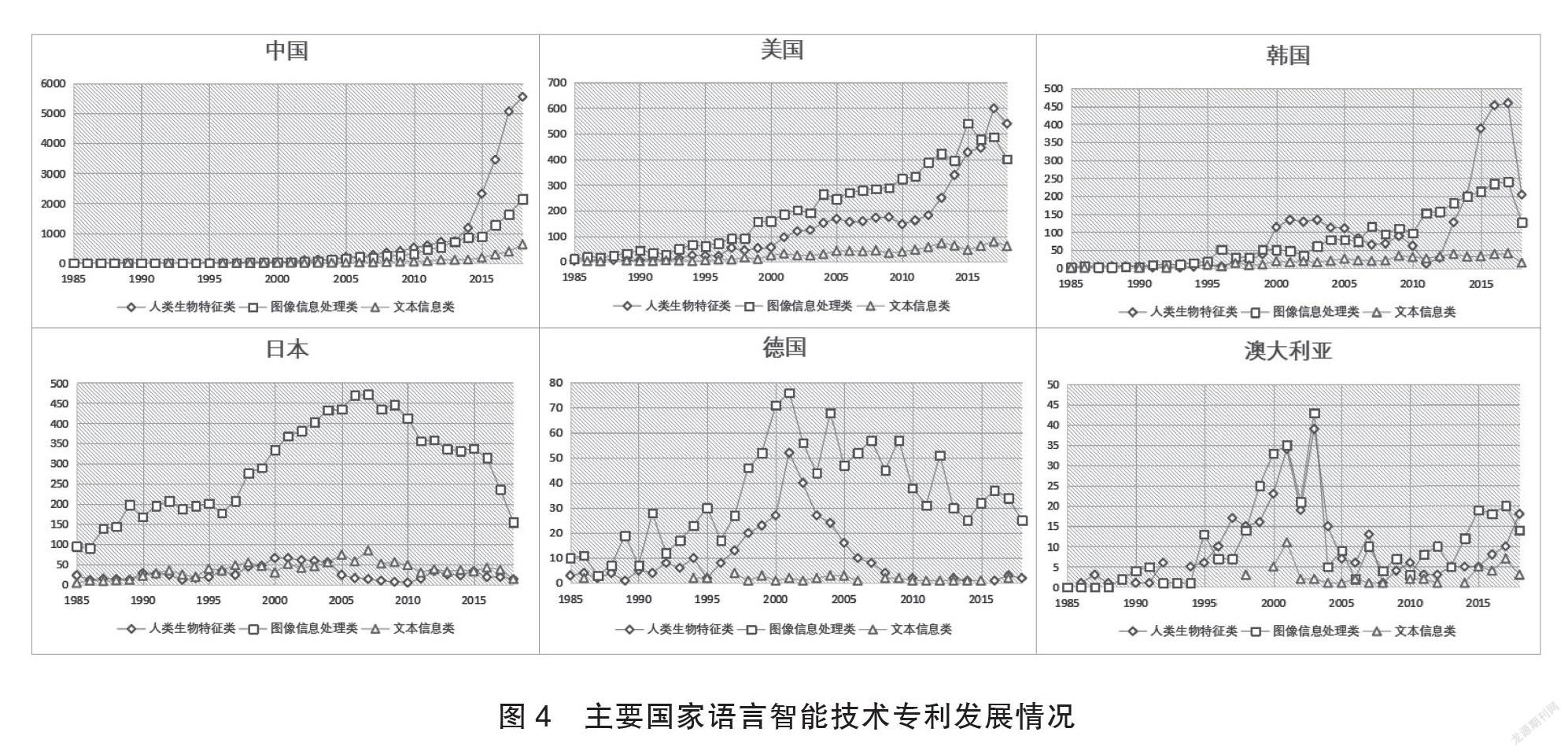
為分析全球主要國家語言智能技術發展情況,我們對文獻數據按國別分別進行分類統計,形成各國趨勢曲線(見圖4)。這些圖反映出各國的變化曲線呈現一定的差異。
從領域發展過程看,中國較美國、德國和日本等國技術起步較晚,到2005年后才出現明顯增速,10年后中國在該領域的技術專利擁有量已處于領先位置。分析各國3條技術曲線趨勢,美國、日本、德國和澳大利亞等國對圖像信息處理更為關注,其中日本的該條曲線最為突出,中美韓在人類生物信息處理研究上具備一定的優勢。在2005年前后,日本、德國和澳大利亞等國分別出現了曲線的下降拐點,可見此時期三國的研究焦點發生過轉移,而中美兩國的增長曲線相似,曲線分布較均衡,呈持續增長態勢。通過上述六國各自3條技術曲線的分布情況不難發現,文本信息處理研究有較大的發展空間。
2013年,我國率先提出人工智能范疇下的“語言智能”概念,與全球該方向專利申請的爆發期基本吻合,體現我國研究人員對此方向的持續重視和創新,此概念的提出恰逢其時。語言智能研究既是對多模態信息處理技術的繼承,也為計算智能和認知智能研究對象界定了范圍,成為多領域、多模態信息技術交叉融合發展的重要方向。未來5~10年間語言智能發展仍處于技術爆發增長期,是學術研究、產業發展的重點布局方向。
二、語言數據治理現狀及困境
數據具有生產要素性質,只有信息化發展到一定階段才能成為現實,才能被人認識(李宇明2020)。在近10年語言智能技術爆發式發展的背景下,2020年李宇明發表《語言數據是信息時代的生產要素》一文,明確語言數據是生產要素,并納入數字經濟視野。本節對信息時代下的語言數據來源、內涵進行初探,并對智能技術賦能語言數據應用及語言數據治理面臨的挑戰進行梳理。
(一)從語言數據到語言數據治理
人類形成前自然界只有“物理空間”,人類誕生后產生了“社會空間”,語言與社會空間共同發展,演變出以語音為載體的口頭語言。隨著社會空間發展,人類利用光波特性研究出有聲媒介,加速了語言信息傳播,伴隨互聯網時代的到來,人類邁入“信息空間”。當語言數據成為發展經濟和數字科技的核心要素,語言數據已經不僅僅是一種文化概念,它是“具有聲光電三大媒介,為人類與機器兩個‘物種’共享,將應用在社會、信息、物理三元空間中”(潘云鶴2019)的事物。我們作為智能時代語言數據的創造和使用者,更需要理解語言數據內涵,并認識語言數據的特性。
語言數據是以語言符號體系為基礎構成的各種數據,按數據功能簡單概括為:語言學科數據、話語數據、語言衍生數據、人工語言數據和語言代碼數據(李宇明,王春輝2022)。語言數據屬于數據范疇,天然擁有大數據的3個重要特性:“基因”的存儲性、規律的蘊含性、趨勢的預測性(周建設,等2014),同時也具有區別于大數據的語言特性,即物質性和動態性。物質性指語言數據必須借助一定的載體傳播信息,如語音、文字、圖片等媒介;動態性指語言數據在時間、空間維度上是動態的,如新型短視頻、中長視頻媒體的快速興起和應用,古文字研究在今天依然活躍,體現出語言數據的時空延展性。抖音日活躍用戶超6億(截至2020年12月,2019年日活躍用戶4億),快手日處理數據量超過3EB,日入數據量超5PB(5120TB)。大規模的數據以場景多片段構成(時間)、分布式存儲(空間)的結構,事件內容較傳統單篇文件、單視頻展示之間體現出明顯的時序關系,用戶關注度也隨時間在轉移。
語言數據治理對于確保語言數據的準確、適度分享和保護是至關重要的。關注語言數據質量,保障語言數據穩定性、準確性,將語言數據從混亂治理成為有序,已逐漸成為國內外研究熱點。語言數據治理是將語言數據作為治理對象的數據治理,目標是為國家或組織發展提供基礎性和戰略性語言資源,促進語言數據資產的價值創造,提升語言服務和語言治理能力。語言數據治理涉及元數據構建、語言數據標準制定、語言數據安全建設、語言數據存儲及語言智能服務等多方面。實現全流程的語言數據治理是個極其復雜、系統和長期的工程,本文重點關注語言數據治理中數據到知識的治理環節,未涉及安全、經濟、控制與管理等內容。
(二)語言數據賦能語言智能技術的重要任務
語言智能的核心目標是研究人類語言與機器語言之間的同構關系,當前語言數據已賦能多種語言智能技術的應用場景。每次技術革新都帶來專利申請曲線的波動,隨后為社會帶來更優質的語言智能服務,本節圍繞機器翻譯、智能客服、網絡輿情、多語言資源建設等4個語言數據服務展開技術發展的趨勢分析。
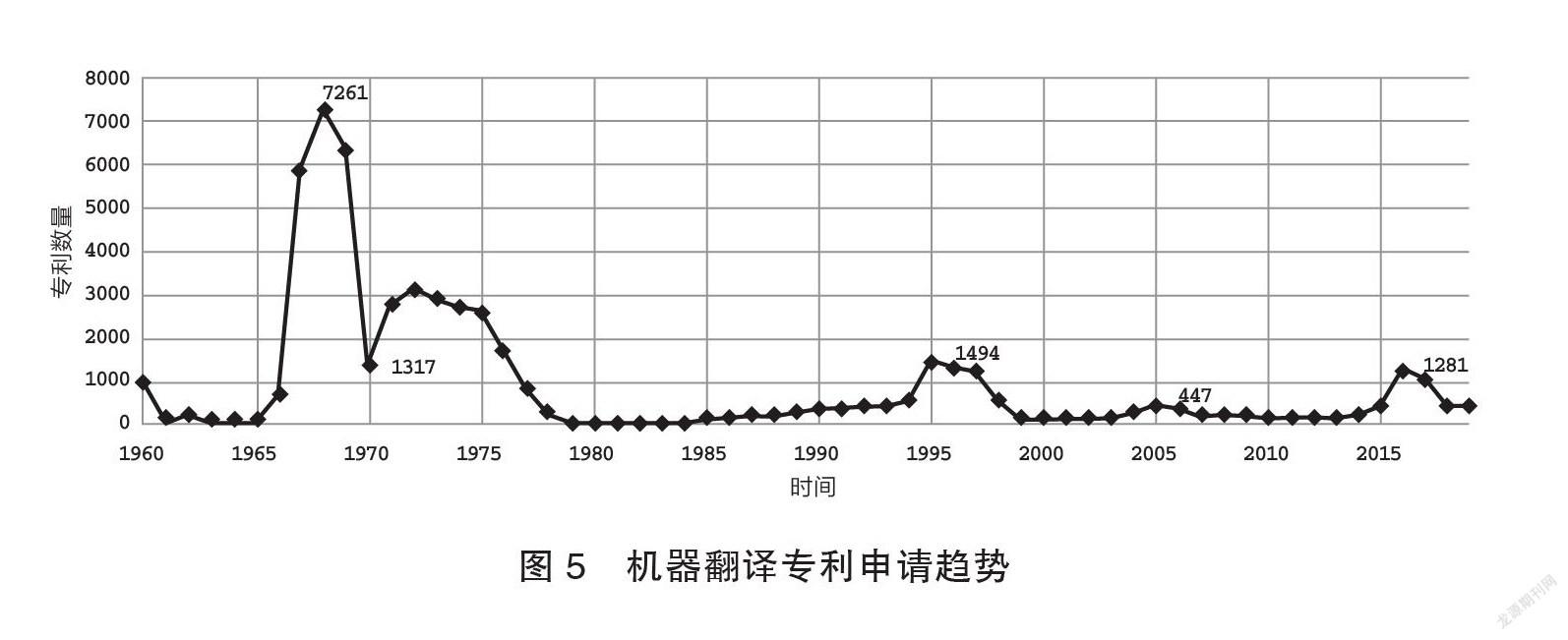
由圖5可知,20世紀90年代前,機器翻譯技術利用詞典匹配技術(Blazevic 1977)實現,1968年出現申請峰值。而后是詞典結合語言學知識的規則翻譯(陳肇雄1997),1995年出現申請峰值。基于語料庫的統計機器翻譯(宋金平2004)取得較大進步,2005年出現了申請峰值。隨著運算能力提高和多語資源的增長,神經網絡文本翻譯(Li & Liu 2020)取得了明顯成效,2016年出現了申請峰值。但實時語音翻譯或自動同聲傳譯還面臨很大挑戰,語篇如論文、小說等文體翻譯時,術語一致性問題對模型可理解性提出了更高要求。
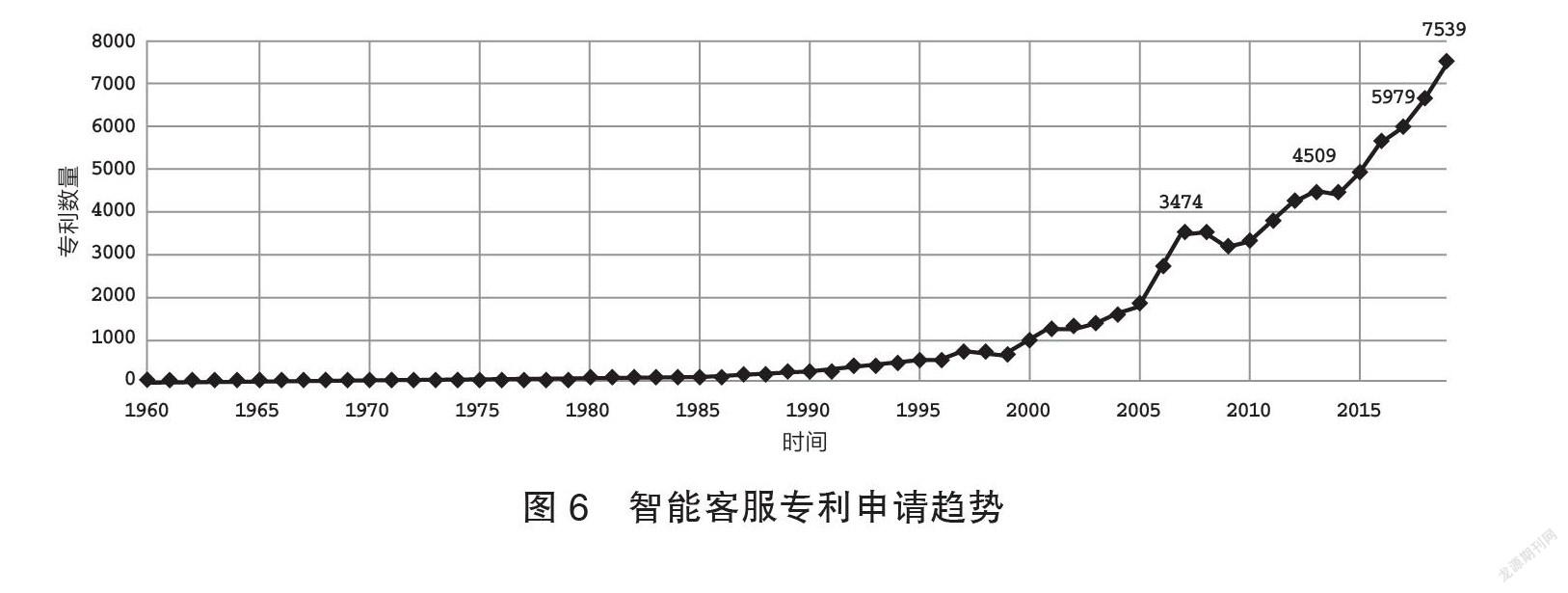
由圖6可知,智能客服技術起步較晚但呈現申請量快速增長趨勢。其應用形式上有聊天(Miyashita 2002;楊敏,等2008)、問答(Horvitz 2002;楊海松,等2006)、任務式對話(田春霖,王翔2019;趙丙來,許文軒2021)等,涉及語音識別、語義理解、對話狀態追蹤、語言生成、對話心理等技術,因對話生成缺乏源語言語義約束,涉及問題的復雜程度沒有任何限制。閑聊對話和以領域性知識圖譜為中心的跨領域、跨交互形式的知性會話系統(黃民烈,馬文暢2021)成為當前熱點。
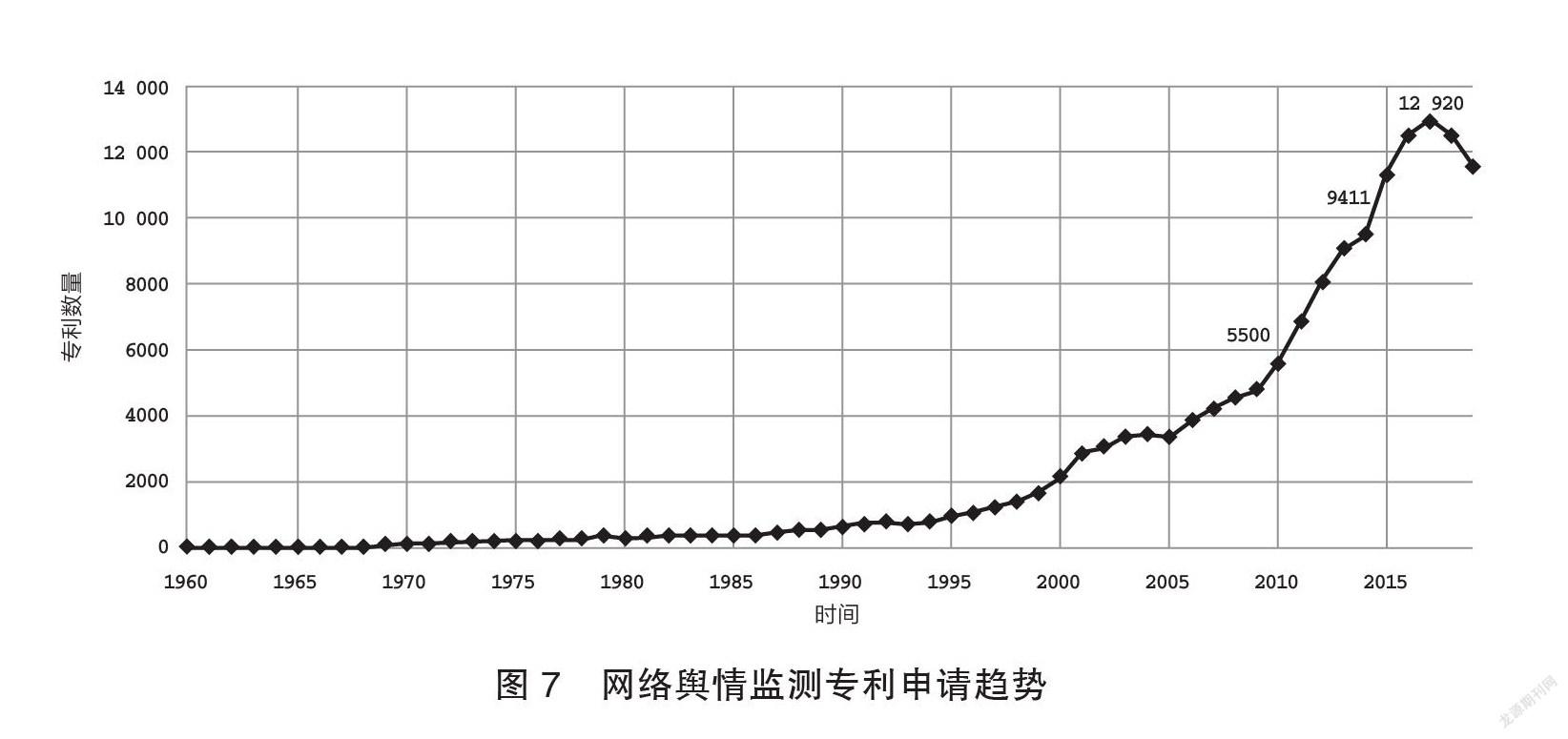
由圖7可知,網絡輿情監測相較其他語言服務專利申請規模更大,體現出各國對這方面的高度重視。早期監測策略通常由“關鍵詞”搭配基本邏輯符號進行語言數據檢索(Belagodu et al. 2013),往往需要輔以大量的人工,對語言數據進行二次處理。語言智能技術則讓輿情監測從信息檢索走向內容多維度識別(張黎娜,等2020),并通過情感分析(仁慶道爾吉,等2021)獲取明確情感、立場、觀點、態度、意圖等敏感信息,提高了語言數據背后隱含意圖和傾向信息理解的準確性。網絡輿情監測正在通過事理圖譜、熱點聚類、文本分類等方法,向輿情事件延展、事件特征、風險等級等智能分析階段發展。
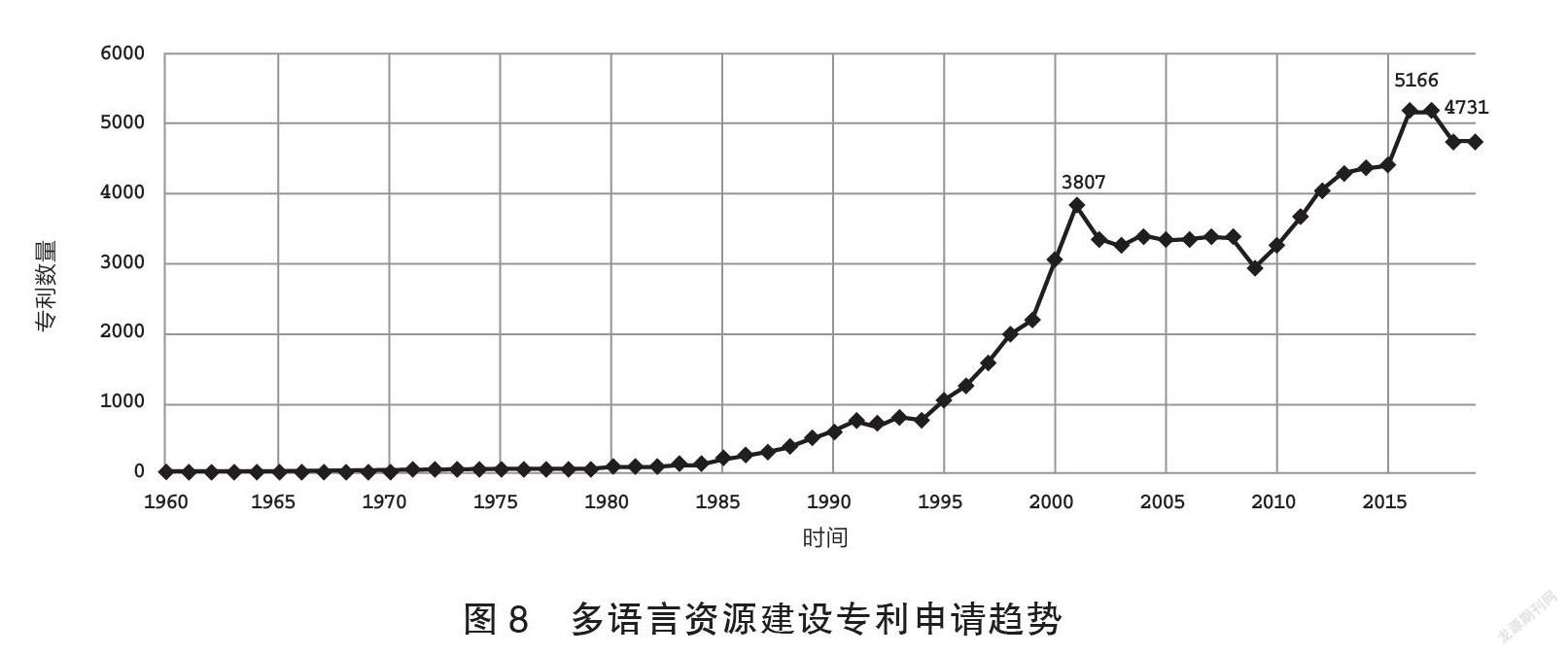
由圖8可知,在2000年前的資源構建中多以語言本體數據為對象,構建各語種知識本體、敘詞本體詞網等(Torrence 1979),之后圍繞民族語言資源(姚聰,等2015)、話題發現和輿論導向(曾倬穎,張權2017)等方面的研究成為一種趨勢。2015年后,圍繞語義標注、資源保護、語言模型和智能評測(胡韌奮,等2021)等技術研發成為新方向。近年來,以古文字為對象的專利開始出現,如多特征融合技術的拓片資源保護(陳善雄,等2019;高未澤,等2020;肖旭東,等2021)、古籍漢字可視化識別、文本挖掘的古籍數字化(毛建軍2006)、古籍漢字圖像質量提升(宋傳鳴,等2021;李邦,等2021)、古籍詞語發現(楊存耿,等2016;謝昱,等2019)和古籍知識庫構建(徐小力,等2016)。
(三)語言數據治理面臨的挑戰
“語言文字智治現代化”(王春輝2020)將語言智能技術與語言數據治理密切關聯,充分運用語言信息化手段,發展和運用語言智能,利用語言智能來集成信息、發布信息、共享信息、保證信息安全等(李宇明,王海蘭2020),是進行語言數據治理的必經之路。優質、安全和高效的語言數據應用及服務是語言數據治理的目標,治理工作的開展受到政策、經濟、文化、技術等多方面因素影響,本節從數據質量本身及其數據治理模式兩方面總結語言治理工作面臨的突出難題。
1.語言數據的偏見現象
機器學習的基本原理是根據已有的訓練數據推導出能夠描述出“經驗”的模型,并根據得出的模型實現對未知的測試數據的最優預測。受機器學習原理和技術特征的影響,其決策結果會產生一定偏見,如簡歷篩選系統會依據應聘者無法控制的特質(性別、種族等)做出帶有歧視的篩選。語言數據偏見產生的原因較為復雜,在機器學習的生命周期中包含了數據采集、算法訓練、人機交互等多個環節,這其中每個階段都會存在一定的偏見。
第一,來源于語言數據本身的偏見。包括:(1)地域偏見,不同的地域文化和社會習俗等會滲透到語言數據中,影響機器決策并產生偏見。(2)群體偏見,語言數據采集者容易主觀性代表部分群體的特征屬性,而此特征屬性與應用目標群體存在的差異,容易產生偏見現象。這類型偏見同時會產生觀察者偏差和聯想偏差,即無意間在語言數據標注時加強了研究者本身的主觀意見,造成數據噪音(Suresh &Guttag 2019)。(3)測量偏差,當前機器學習算法都基于大量語言數據進行運算,在收集數據時,使用不同的數據采集工具或者使用觀點不統一的語言數據標記規范,最終會導致數據產生大量噪音,測量產生偏差(Olteanu et al. 2019)。(4)表示偏見,當數據采集時沒有充分覆蓋目標群體的特征,某些樣本的特性并未得到充分表示,這種代表性不足的數據表征在運算中也會加劇偏見現象。
第二是來源于智能技術的偏見。包括:(1)算法偏見,機器學習的特性就是捕捉大數據中的經驗規律,同時也會極大程度上忽略少數群體在訓練過程中的權重,導致其不能完全代表目標群體,由此產生算法決策偏見。(2)排名偏見,基于協同過濾技術的智能推薦系統,其背后利用了人類的認知架構,對用戶語言屬性(歷史行為、相關偏好等)進行挖掘,并且依據使用者習慣和喜好進行優先級排序,排名靠前則會極大程度上吸引關注度(Buolamwini&Gebru 2018)。(3)變量偏差,當進行模型設計時未能完整考慮到影響模型的重要變量,模型預測會產生一定偏差(Schmitz et al. 2022)。
第三是來源于人機交互的偏見。包括:(1)交互偏見,在不同社交平臺和應用場下不同群體的交互行為會存在偏差,如“微信”和“淘寶”這兩類軟件的交互手段存在差異。此外,信息呈現的方式也同樣影響交互效果(Olteanu et al. 2019)。(2)內容偏見,一個人居住在不同地域、處于不同群體、擔當不同角色所使用的語言內容都具有本質的差別,當進行一定語言習慣轉換時所產生的內容結構、語法、語義等誤差,被認為是內容偏見(Olteanu et al. 2019)。
本節對語言數據偏見現象產生原因進行了粗略歸納,以期了解在語言智能技術發展的環境下所產生的偏見現象。存在偏差的語言數據影響語言數據質量,不良數據將持續加重智能技術的不公平現象。
2.經典語言治理模型的短板
數據挖掘的目的是從大數據中發現“有趣知識”,根據任務不同可分為概念描述、關聯相關、分類和預測、聚類分析、離群點和演變分析等經典數據挖掘模式(圖2及表1中含有相關的基礎技術)。經典模式下,首先會將待解決的數據治理問題轉化成正確的數據挖掘任務,然后根據任務選擇某種或幾種挖掘模式(Han et al. 2012)。經典挖掘模式具有一定的普遍性,在行業應用中受到廣泛關注,但在服務于語言數據治理時,將會面臨如下難題。
第一,傳統方法不適用。以業務為導向的數據挖掘標準體系忽視了語言數據自身的特性。經典數據挖掘模式已在金融、醫療、司法、零售、制造、保險等行業廣泛應用,其中也多有語言數據參與,但其核心目標是為領域業務服務。語言數據除具備一般數據特征外,還有其自身的內涵與規律。當傳統數據挖掘方法面臨特殊的語言數據信息,以業務為導向的治理模式并不能適用。
第二,知識獲取不充分。語言數據僅是知識獲取的渠道之一,但在網絡空間中,語言信息資源、語種語類資源的建設、管理和利用都很不充分。社交網絡源生語言資源粗放雜亂,不僅造成了數據冗余,而且導致語言優質資源的通行度下降,降低了信息檢索的服務質量,以致產生了現在“語言數據豐富,但語言知識貧乏”的現象。
經典數據挖掘模式能力不足、語言智能技術仍存在瓶頸、語言數據對資源依賴性更高,決定了若要在語言數據治理的國際競爭中取得主動權,必須雙管齊下:既要關注語言數據的數量與質量(降低對其他資源過度依賴和知識挖掘難度),也要重視治理模式的優化與創新(提升語言知識獲取和治理模式通用的能力)。在當前信息基礎設施相對完善而算法工具不變的條件下,模式問題已成為矛盾的主要方面,也是世界各國面臨的普遍難題。
三、語言數據治理的技術模式
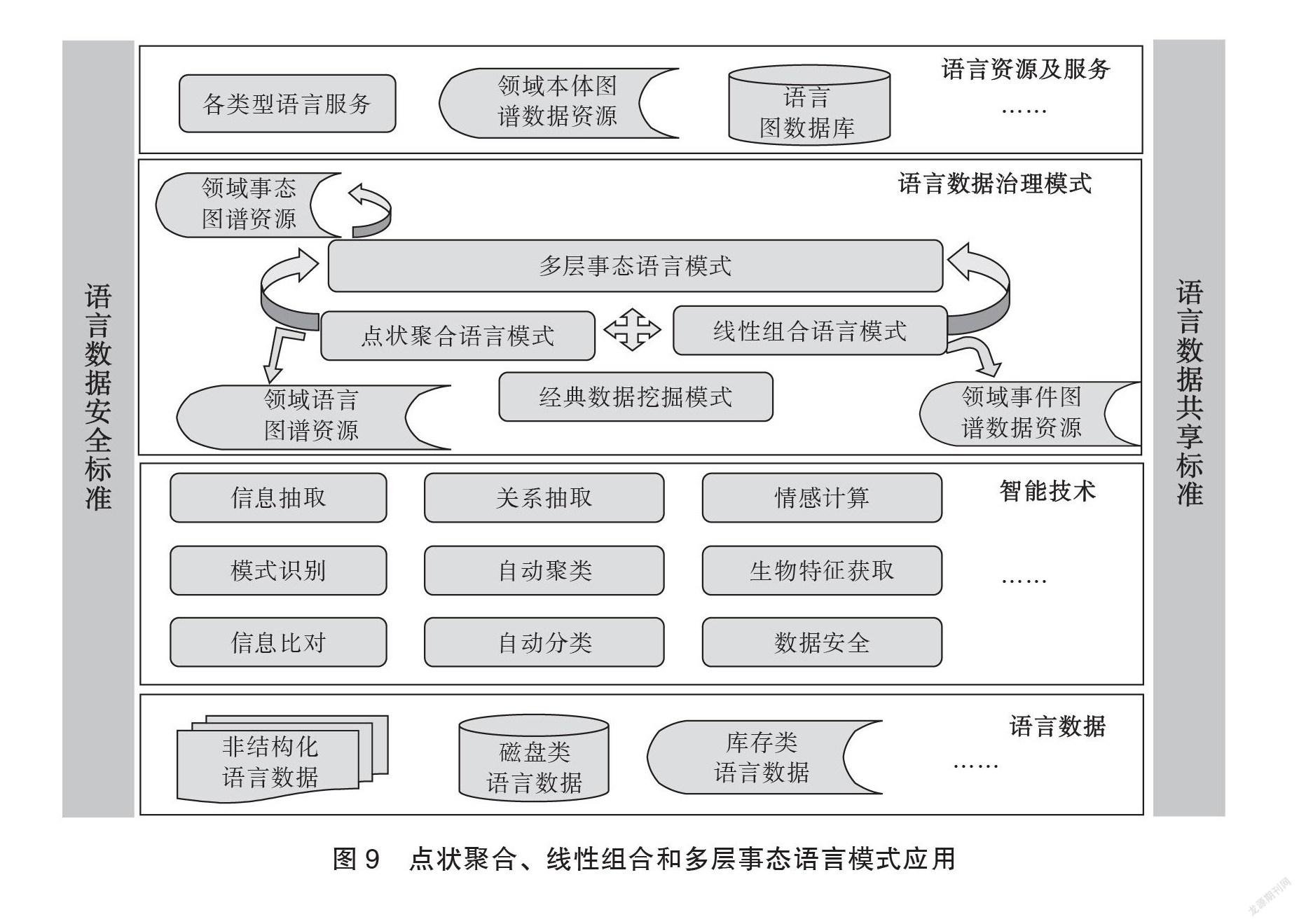
科學合理構建語言數據治理模式可有效應對挑戰,對語言數據資源和智能技術的發展均有裨益。其一,語言數據作為重要的生產要素,開展治理研究對于確保數據準確(解決語言符號的知識表達問題)、知識發現(解決語言符號的知識計算問題)、適度分享和保護(解決語言符號的知識傳播與保護問題)至關重要。其二,清晰、有效的語言數據治理需求和場景,可推動語言智能技術良性發展,不斷積累的語言數據治理經驗要求技術模式的規范化和標準化。本節重點探討并設計語言數據治理的點狀聚合、線性組合和多層事態語言模式。
有效的語言數據治理框架會通過優化模式、縮減計算成本、降低輿情風險和提高安全合規等方式,將語言數據(知識)價值優質、高效回饋于應用,最終服務于語言文字事業發展。本節在語言智能技術的背景下,以經典數據挖掘模式為基礎,就現有語言數據治理模式組織歸納,提出點狀聚合模式、線性組合模式和多層事態等語言模式。3類語言數據治理的模式對應不同的場景或語言數據任務,分別圍繞語言數據不同層次展開技術構建。
點狀聚合模式(單點)以語言符號中的詞性(如名詞)為關注點,圍繞實體詞,以屬性為橋梁,通過實體點聚合,構建一個空間知識體系,目標是構成結構化的語義知識庫。計算機數據結構上對應的是有向圖結構,呈現<實體,關系,實體>的點狀聚合特點,其中實體由<屬性,值>構成,實體間通過屬性關系進行關聯。該模式圍繞實體點構成語言符號的知識結構,存儲于圖數據庫中。點狀聚合模式的知識結構是對現有語義網的擴充,對語言數據做行業細分,以單個術語為實體,在經典數據挖掘模式基礎上,結合語言資源特點可以構建出細分行業語義庫。該模式體現出語言數據“基因”的存儲性和規律的蘊含性特征。
線性組合模式(交互)以語言符號中事件關系為關注點(如謂詞邏輯),目標是構建出結構化的事件組合場景,該模式的中心點持續圍繞謂詞變化而轉移,通過場景切換形成具有一定概率的事件組合庫。計算機數據結構上對應的是具有概率屬性的有向圖結構,呈現出<事件,關系,事件>的線性組合特點,其中事件由<屬性,概率>構成,事件間通過事件關系進行關聯。該模式圍繞事件序列構成語言符號的知識結構并存儲于圖數據庫中,模式的發展通過事件轉移矩陣確定趨勢方向。該模式體現出語言數據的趨勢預測性。
多層事態模式(事態)以語言符號整體為著眼點,化形于現實世界,通過追蹤語言符號的事態變化,形成具有特定場景的、具有語義完備性的多層事態模式,該模式的目標是形成個體化語義場景描述的數據結構。計算機數據結構上對應復雜網絡結構,形成<實體,知識圖譜,事態,事件,事理圖譜>結構的多層形態,其中事態即事件的狀態,指表示事件發生與否、出現與否、存在與否。事態與動態兩者著眼點不同,動態關注的是謂詞所表示的動作變化,通過時態或狀態體現,事態關注的是句子所表示的事件狀態,由事態語氣或時間狀態體現。多層事態模式體現出語言數據的時序和空間的延展性。
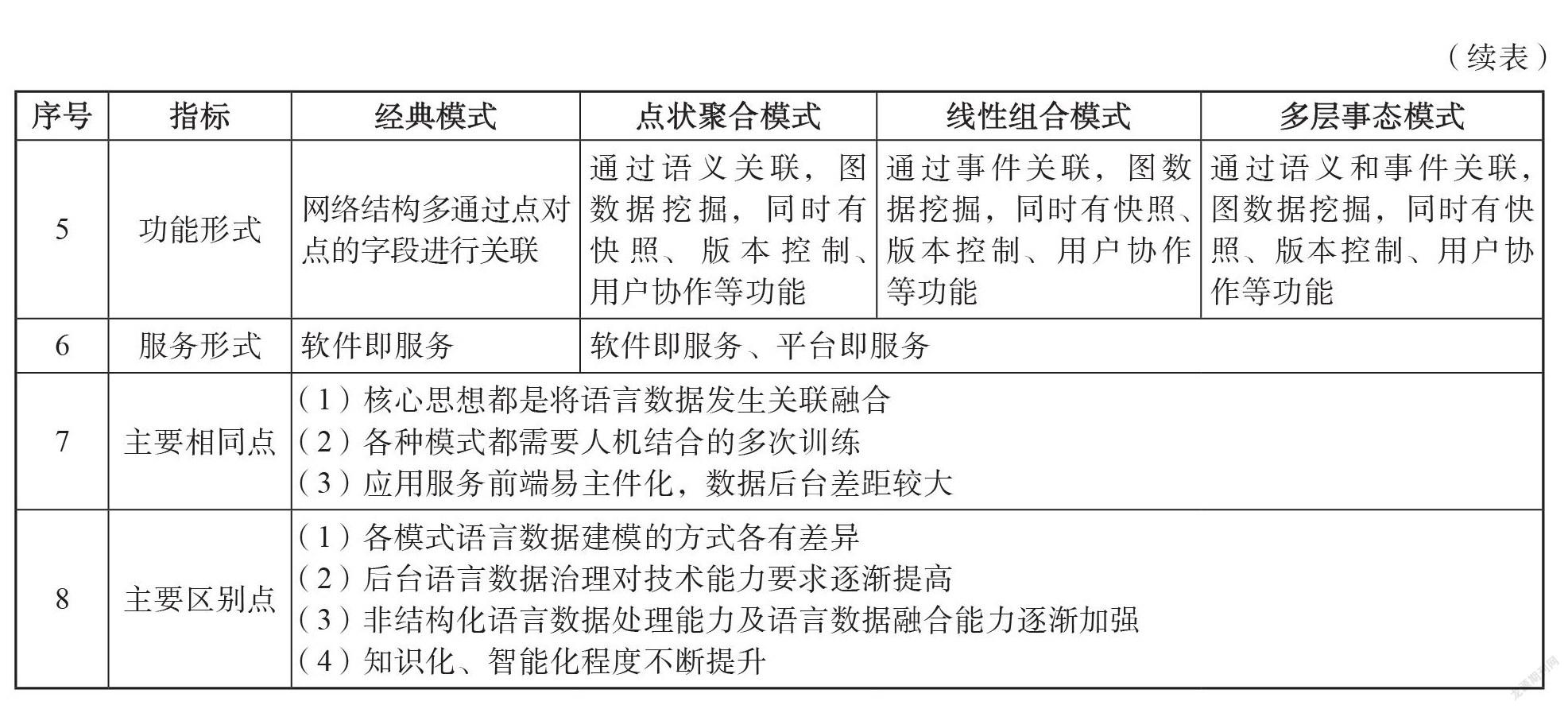
結合經典數據挖掘模式,我們對點狀聚合、線性組合和多層事態治理模式的各自特點分別進行多維度對照分析,詳見表3。在具體的語言數據治理任務中,可根據不同的治理目標采取某種或幾種模式。
在語言數據安全和共享標準支持下,我們結合語言數據資源構建流程,展示本文設計的3種語言模式的聯系,共同為語言資源和服務建設提供支撐,詳見圖9。智能化條件下語言數據治理的核心思想是語言數據間的關聯融合,所有模式均需要進行“人-機”結合的多次模型訓練,以期達到最佳的治理效果。雖然語言數據由于自身蘊含特征規律的表現形式不同,造成語言數據治理模式的差異化,但建立在治理模式上的語言數據應用服務卻容易形成相對穩定的結構。隨著上述模式結構的復雜性增加,對語言數據治理的基礎技術能力要求也逐漸提高。
四、結 語
語言智能技術是科技創新的重要動力和源泉,圍繞語音識別、人機對話、機器翻譯、多模態語義分析技術所衍生的新興業態,已由實驗階段走向市場應用。本文通過對近60年語言智能技術專利文獻進行挖掘,就技術發展趨勢及布局變遷進行總結,探索了技術發展的規律和成熟度,為展開語言數據治理提供技術儲備。依據專利熱點分析技術賦能語言數據服務的最新趨勢并歸納語言數據治理面臨的技術挑戰。為應對技術挑戰,彌補經典數據挖掘模式的不足,本文提出了語言數據治理的3種語言模式并展開應用分析。語言數據是對象,語言智能技術是手段,語言模式是方法,語言治理是目的,本文厘清語言智能技術整體發展和未來趨勢,探討了語言數據治理中存在的技術難題并探索性地提出語言數據治理模式,以期為智能化數據治理提供參考。
參考文獻
陳善雄,莫伯峰,高未澤,等 2019 一種基于局部CNN框架的甲骨拓片分類方法,中國:CN201910917806.X,2019-09-26。
陳肇雄 1997 機器翻譯中的復雜上下文相關處理方法,中國:CN97111944.9,1997-07-02。
高未澤,田瑤琳,陳善雄,等 2020 基于曲線輪廓匹配的甲骨拓片綴合方法,中國:CN202010191701.3,2020-03-18。
胡韌奮,王予沛,彭一平,等 2021 一種漢語二語作文自動評分方法,中國:CN202110896135.0,2021-08-05。
黃民烈,馬文暢 2021 基于知識圖譜的智能對話推薦方法及裝置,中國:CN202110426610.8,2021-04-20。
李 邦,張 展,郭 安,等 2021 基于生成對抗網絡的甲骨片輪廓與字符痕跡自動提取方法,中國:CN202110888155.3,2021-11-02。
李宇明 2020 《語言數據是信息時代的生產要素》,《光明日報》7月4日第12版。
李宇明,王春輝 2022 《從數據到語言數據》,《語言戰略研究》第4期。
李宇明,王海蘭 2020 《粵港澳大灣區的四大基本語言建設》,《語言戰略研究》第5期。
毛建軍 2006 《古籍數字化概念的形成過程探析》,《科技情報開發與經濟》第22期。
潘云鶴 2019 《“人工智能2.0”與數字經濟》,《杭州科技》第5期。
仁慶道爾吉,尹玉娟,麻澤蕊,等 2021 一種基于多尺寸CNN和LSTM模型的蒙古語文本情感分析方法,中國:CN202110533016.9,2021-05-17。
宋傳鳴,王一琦,何熠輝,等 2021 LM濾波器組引導紋理特征自主學習的甲骨文字檢測方法,中國:CN202110900543.9,2021-11-19。
宋金平 2004 基于語言知識庫的機器翻譯方法與裝置,中國:CN200410001187.3,2004-02-04。
田春霖,王 翔 2019 面向任務式對話系統意圖識別的語料庫生成方法和裝置,中國:CN201910163098.5,2019-03-05。
王春輝 2020 《關于語言文字治理現代化的若干思考》,《語言戰略研究》第6期。
肖旭東,李 勇,喬 丹,等 2021 一種噴丸覆蓋率的拓印測量方法,中國:CN202110864413.4,2021-11-12。
謝 昱,江 路,林金瑞,等 2019 一種多功能信息化古籍書影管理平臺及方法,中國:CN201910509035.0,2019-06-13。
徐小力,吳國新,王紅軍,等 2016 一種東巴經典古籍數字化釋讀庫的建立方法,中國:CN201610304529.1,2016-05-10。
楊存耿,謝術清,楊曉強,等 2016 一種SaaS古籍知識服務云平臺,中國:CN201621020211.2,2016-08-31。
楊爾弘,劉鵬遠,韓林濤,等 2018 《語言智能那些事兒》,載國家語言文字工作委員會組編《中國語言生活狀況報告(2018)》,北京:商務印書館。
楊海松,鄧大付,余祥鑫,等 2006 自動問答方法及系統,中國:CN200610059919.3,2006-02-28。
楊 敏,遲長燕,肖文鵬,等 2008 保持聊天記錄和聊天內容的對應關系的設備和方法,中國:CN200810127448.4,2008-06-30。
楊文珍,吳新麗,宣建強,等 2017 一種漢文到盲文的自動高效翻譯轉換方法,中國:CN201710550659.8,2017-07-07。
姚 聰,周舒暢,周昕宇,等 2015 基于圖像的語種識別方法及裝置,中國: CN201510520119.6,2015-08-21。
張黎娜,錢 婧,袁 磊,等 2020 文本內容識別和違規廣告識別方法、裝置及電子設備,中國:CN202011044853.7,2020-09-28。
張 引,陳琴菲 2019 一種多特征融合的古今漢語自動翻譯方法,中國:CN201910033155.8,2019-01-14。
趙丙來,許文軒 2021 基于語義規則的心理知識與方法推薦系統,中國:CN202110882966.2,2021-08-02。
曾倬穎,張 權 2017 網絡輿情態勢的安全評估方法、終端及計算機存儲介質,中國:CN201710595532.8,2017-07-20。
周建設 2020 《加快科技創新 攻關語言智能》,《人民日報》12月21日第19版。
周建設,呂學強,史金生,等 2017 《語言智能研究漸成熱點》,《中國社會科學報》2月7日第003版。
周建設,彭 琰,張 躍,等 2014 《基于大數據的漢語表達智能模型及其理論基礎》,《首都師范大學學報(社會科學版)》第5期。
Han, J. W., M. Kamber& J. Pei. 2012. 《數據挖掘概念與技術》,范明,孟小峰譯,北京:機械工業出版社。
Belagodu, A., N. Dittakavi& V. Ganti. Data retrieval system. USA: US14010477, 2013-08-26.
Blazevic, M. 1977. Device for automatically recording, reproducing and translating, a magnetic transducer. USA: US05/768563, 1977-02-14.
Buolamwini, J. & T. Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. , 77–91.
Horvitz, E. J. 2002. System and methods for inferring informational goals and preferred level of detail of results in response to questions posed to an automated information-retrieval or question-answering service. USA: US10185150, 2002-06-28.
Li, Y. H. & B. Y. Liu. 2020. Method and apparatus for processing word vector of neural machine translation model, and non-transitory computer-readable recording medium. USA: US16809844, 2020-03-05.
Miyashita, K. 2002. Chat system displaying a link arrow directed from a hyperlink to content of an associated attachment file. USA: US10314226, 2002-12-09.
Olteanu, A., C. Castillo, F. Diaz, et al. 2019. Social data: Biases, methodological pitfalls, and ethical boundaries. 2. Accessed at https://www.microsoft.com/en-us/research/wp-content/uploads/2017/03/SSRN-id2886526.pdf.
Schmitz, M., R. Ahmed & J. Cao. 2022. Bias and fairness on multimodal emotion detection algorithms. arXiv preprint arXiv: 2205.08383.
Suresh, H. & J. V. Guttag. 2019. A framework for understanding unintended consequences of machine learning. arXiv preprint arXiv: 1901.10002.
Torrence, K. R. 1979. Method and apparatus for compensation during ultrasound examination. USA: US06/072717, 1979-09-04.
責任編輯:韓 暢
各國專利文獻主要包括專利申請書、說明書、公報、文摘、索引等各種官方文件和官方出版物,既包含與發明創造的研究、設計、開發和試驗成果相關的技術性資料,也包含與權利授予、權利變更、權利保護相關的法律性資料,本文分析中以專利文件和技術性資料為主。
因專利文獻公開有條件限制,在準備本文時,部分文獻未公開,或因本文設計查詢分析中存在一定技術性遺漏,所以實際文獻數可能大于分析文獻數,但對文中各統計結果與整體趨勢分析影響不大。
本文專利數據收集范圍包括中國(CN)、美國(US)、日本(JP)、德國(DE)、英國(GB)、法國(FR)、瑞士(CH)、韓國(KR)、歐洲專利局(EP)和世界知識產權局(WIPO)等100多個國家或地區、機構的專利文摘數據,輔以其他非專利文獻資料。
Inspiro是國內首個整合了全球及中國專利、商標、版權、地理標志、植物新品種、集成電路、知識產權法律文書、標準、科技期刊和企業商情等知識產權大數據資源的創新情報平臺,最新嵌入外觀設計和商標圖像智能檢索功能。incoPat是全球首個面向華語研發創新人員的專利情報平臺,提供及時、全面、準確的情報信息,幫助跟蹤最新的技術發展,規避專利侵權風險,掌握競爭對手的研發動態,實現知識產權的商業價值。
G06K9/00分類與語言數據處理相關,是表示用于閱讀、識別印刷、書寫字符或識別圖形的國際專利分類號。
這里采納李宇明、王春輝(2022)中語言數據的5種分類。
參見《2020年抖音數據分析報告》,https://wenku.baidu.com/view/78c448881937f111f18583d049649b6648d70988.html。
參見中華人民共和國國家標準《信息技術服務 治理 第5部分:數據治理規范》(GB/T 34960.5—2018)。
不局限于常規語種,出現了如漢語到盲文(楊文珍,等2017)、古今漢語(張引,陳琴菲2019)等互譯。
“語言文字智治現代化”涉及兩個層面:其一,提升針對語言數據的治理體系和治理能力現代化;其二,利用數字化和智能化的便利條件來提升語言治理的現代化水平。參見王春輝(2020)。
見二(一)中有關語言數據的特性分析。
