面向神經(jīng)機器翻譯的正向翻譯與反向翻譯相結(jié)合的改進方法
2022-07-15 08:58:24吳章淋魏代猛李宗耀於正哲商恒超陳瀟雨郭嘉鑫王明涵雷立志陶士敏
廈門大學(xué)學(xué)報(自然科學(xué)版) 2022年4期
吳章淋,魏代猛,李宗耀,於正哲,商恒超,陳瀟雨,郭嘉鑫,王明涵,雷立志,陶士敏,楊 浩,秦 瓔
(華為文本機器翻譯實驗室,北京 100038)
近年來,神經(jīng)機器翻譯(neural machine translation,NMT)[1]已經(jīng)取得了巨大的進步,相較于傳統(tǒng)的統(tǒng)計機器翻譯[2],NMT展現(xiàn)出更加卓越的性能和更強的適應(yīng)性.然而,NMT是一種數(shù)據(jù)依賴的方法,通常需要利用大量數(shù)據(jù)才能訓(xùn)練得到性能良好的NMT模型.在現(xiàn)實中,相比于龐大的單語數(shù)據(jù)量,高質(zhì)量的雙語數(shù)據(jù)比較有限,因此,如何有效地利用單語數(shù)據(jù)成為了NMT的重要研究課題.
目前,源語言和目標(biāo)語言單語數(shù)據(jù)已被證明可用來改進NMT,但如何更有效地同時使用源語言和目標(biāo)語言單語數(shù)據(jù)還需進一步地研究.為此,本文提出了一種基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法.為驗證該方法的有效性,在第十七屆全國機器翻譯大會(CCMT 2021)漢英和英漢新聞領(lǐng)域的翻譯評測任務(wù)上,與其他常用的幾種單語數(shù)據(jù)增強方法進行對比實驗.此外,本文還探究了領(lǐng)域知識遷移[3]后該方法的有效性,并分析了單語數(shù)據(jù)規(guī)模對該方法的影響和該方法對困惑度的影響,以及該方法是否能提升不同類型源句的翻譯質(zhì)量.
1 相關(guān)工作
基于反向翻譯的單語數(shù)據(jù)增強方法最早由Sennrich等[4]提出,具體地,在真實雙語數(shù)據(jù)上訓(xùn)練目標(biāo)語言到源語言的NMT模型,用該模型將目標(biāo)語言單語句子翻譯成源語言句子,構(gòu)造偽雙語數(shù)據(jù),然后利用偽雙語數(shù)據(jù)與真實雙語數(shù)據(jù)聯(lián)合訓(xùn)練源語言到目標(biāo)語言的NMT模型,從而達到提升源語言到目標(biāo)語言的NMT模型翻譯質(zhì)量的效果.隨后,Burlot等[5]對反向翻譯進行了系統(tǒng)的研究,再次證實了反向翻譯是非常有效的.
在反向翻譯的解碼策略方面,Edunov等[6]指出基于集束搜索的方法受源句類型的影響,只能提升源句為翻譯腔類型時的翻譯質(zhì)量,并表明了基于集束搜索加噪聲和基于隨機采樣的翻譯性能均優(yōu)于基于集束搜索的方法.在使用基于集束搜索的解碼策略時,Caswel等[7]表明了加噪聲的方法提升反向翻譯效果的原因是使NMT模型在訓(xùn)練過程中能夠有效區(qū)分偽雙語數(shù)據(jù)和真實雙語數(shù)據(jù),并提出了基于集束搜索加標(biāo)簽的方法,該方法使用額外的標(biāo)簽標(biāo)記偽雙語數(shù)據(jù)的源端,其效果好于基于集束搜索加噪聲的方法.而在使用隨機采樣的解碼策略時,往往會存在低質(zhì)量采樣句子的問題,因此,Gra?a等[8]提出了基于最優(yōu)N隨機采樣的改進方法,通過限制采樣空間的方式,提高偽雙語數(shù)據(jù)的質(zhì)量.
在反向翻譯的訓(xùn)練策略方面,Hoang等[9]提出迭代式反向翻譯的方法,利用反向翻譯增強后的模型重新進行反向翻譯,通過迭代的方式逐步提升NMT模型的翻譯質(zhì)量.Abdulmumin等[10]則提出了一種不需要加標(biāo)簽的反向翻譯方法,將偽雙語數(shù)據(jù)用作域外數(shù)據(jù)預(yù)先訓(xùn)練模型,然后使用真實雙語數(shù)據(jù)作為域內(nèi)數(shù)據(jù)來微調(diào)預(yù)訓(xùn)練的翻譯模型,旨在通過預(yù)訓(xùn)練和微調(diào),使模型能夠有效地從這兩個數(shù)據(jù)中學(xué)習(xí).Jiao等[11]也提出了一種交替訓(xùn)練的反向翻譯方法,其基本思想是在訓(xùn)練過程中迭代地交替?zhèn)坞p語數(shù)據(jù)和真實雙語數(shù)據(jù).
當(dāng)目標(biāo)語言單語數(shù)據(jù)已被證明通過反向翻譯改進NMT的翻譯質(zhì)量非常有用時,Zhang等[12]提出了正向翻譯的方法,采用自學(xué)習(xí)算法生成源語言單語數(shù)據(jù)對應(yīng)的偽雙語數(shù)據(jù),用于與真實雙語數(shù)據(jù)聯(lián)合訓(xùn)練,提升NMT模型的翻譯質(zhì)量.值得注意的是,其實驗結(jié)果表明,源語言單語數(shù)據(jù)并不總是改善NMT,正向翻譯只有使用密切相關(guān)的源語言單語數(shù)據(jù)才可以獲得更好的翻譯質(zhì)量,當(dāng)使用更多不相關(guān)的源語言單語數(shù)據(jù)時,會導(dǎo)致翻譯質(zhì)量下降.Wu等[13]對如何同時使用源語言和目標(biāo)語言單語數(shù)據(jù)促進NMT的翻譯質(zhì)量進行了研究,提出了基于集束搜索的正向翻譯和反向翻譯的組合方法,實驗結(jié)果表明,源語言和目標(biāo)語言單語數(shù)據(jù)混合使用是一種有效的方法,其效果優(yōu)于單獨使用源語言單語數(shù)據(jù)或目標(biāo)語言單語數(shù)據(jù),且NMT模型的翻譯質(zhì)量可以隨著單語數(shù)據(jù)的增加而不斷提升.
2 方 法
2.1 NMT模型
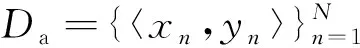
2.2 正向翻譯
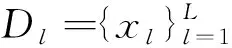
首先,基于真實雙語數(shù)據(jù)Da訓(xùn)練一個源語言到目標(biāo)語言的NMT模型:
然后,利用源語言到目標(biāo)語言的NMT模型翻譯源語言單語數(shù)據(jù)Dl(l=1,2,…,L):

在翻譯源語言單語數(shù)據(jù)時,通常采用基于集束搜索解碼的方式.盡管源語言單語數(shù)據(jù)與真實雙語數(shù)據(jù)共享源語言詞匯表,并且無法生成新的單詞翻譯,但源語言單語數(shù)據(jù)提供了詞匯表中單詞的更多排列.使用真實雙語數(shù)據(jù)和源語言偽雙語數(shù)據(jù)聯(lián)合訓(xùn)練,可以泛化NMT模型的編碼能力,從而提升NMT模型的翻譯質(zhì)量.
2.3 反向翻譯
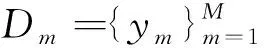
首先,基于真實雙語數(shù)據(jù)Da訓(xùn)練一個目標(biāo)語言到源語言的NMT模型:
然后,利用目標(biāo)語言到源語言的NMT模型翻譯目標(biāo)語言單語數(shù)據(jù)Dm(m=1,2,…,M):
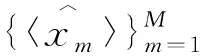
在翻譯目標(biāo)語言單語數(shù)據(jù)時,有兩種解碼方式,即基于集束搜索解碼與基于隨機采樣解碼的方式.基于集束搜索解碼的方式[4]側(cè)重于翻譯出最可能的結(jié)果,會導(dǎo)致偽雙語數(shù)據(jù)的多樣性較差,直接使用這類偽雙語數(shù)據(jù)和真實雙語數(shù)據(jù)聯(lián)合訓(xùn)練,給NMT模型帶來的提升效果可能會不明顯.另外,由于偽雙語的數(shù)據(jù)分布與真實雙語的數(shù)據(jù)分布差距較大,通過加標(biāo)簽[7]或加噪聲[6]的方法向模型表明偽雙語數(shù)據(jù)是合成的,可以給模型提供更強的訓(xùn)練信號,從而實現(xiàn)更好的提升效果.而基于隨機采樣解碼的方式[6]可以生成更多樣化的偽雙語數(shù)據(jù),還可以通過最優(yōu)N隨機采樣的方式[8]限制采樣空間避免偽雙語數(shù)據(jù)的質(zhì)量過低,這種方式對模型的增強效果會比較明顯.
2.4 正向翻譯和反向翻譯組合與改進

Wu等[13]提出的正向翻譯與反向翻譯的組合方法已經(jīng)被證明優(yōu)于僅使用正向翻譯或反向翻譯的方法,其在構(gòu)造偽雙語數(shù)據(jù)時,均采用基于集束搜索的解碼方式.本文改進了組合方法中反向翻譯的解碼方式,增加了目標(biāo)語言偽雙語數(shù)據(jù)的多樣性,提出了基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法.
2.5 領(lǐng)域知識遷移、正向翻譯與反向翻譯組合與改進
領(lǐng)域知識遷移[3]是指,用一個更接近目標(biāo)評測領(lǐng)域的小數(shù)據(jù)集對NMT模型進行增量訓(xùn)練,加強NMT模型對目標(biāo)領(lǐng)域知識的理解,從而提升NMT模型在目標(biāo)領(lǐng)域的翻譯質(zhì)量.先使用領(lǐng)域知識遷移方法,再使用本文提出的基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法,可以更好地提升NMT模型在目標(biāo)領(lǐng)域的翻譯質(zhì)量.
3 實 驗
實驗基于Pytorch實現(xiàn)的fairseq[14]開源框架,使用Wang等[15]提出的層歸一化前置的Deep Transformer模型作為基準(zhǔn)系統(tǒng).其中,編碼器層數(shù)設(shè)為25,解碼器層數(shù)設(shè)為6,詞向量維度設(shè)為512,隱層狀態(tài)維度設(shè)為2 048,多頭自注意力機制使用8個頭.實驗的其他主要參數(shù)設(shè)置如下,每個模型使用8塊GPU進行訓(xùn)練,batch大小為2 048,參數(shù)更新頻率設(shè)置為32[16],學(xué)習(xí)率為5×10-4,標(biāo)簽平滑率為0.1[17],warmup步數(shù)為4 000,采用了dropout機制,dropout設(shè)為0.1;使用Adam調(diào)優(yōu)器[18]調(diào)優(yōu),參數(shù)設(shè)置為β1=0.9,β2=0.98.訓(xùn)練數(shù)據(jù)先分詞再用雙字節(jié)切分(BPE)[19]切分,源語言及目標(biāo)語言的詞表共享設(shè)定為32×103,漢語分詞采用jieba,英語分詞采用Moses[20].在推理階段,本次實驗采用Marian[21]工具進行解碼,集束大小設(shè)置為10,漢英翻譯實驗的長度懲罰設(shè)置為1.2,而英漢翻譯實驗的長度懲罰設(shè)置為0.8.此外,在基于最優(yōu)N隨機采樣制造偽雙語數(shù)據(jù)時,使用的是fairseq進行解碼,解碼參數(shù)beam設(shè)為1,sampling設(shè)為True,sampling_topk設(shè)為10.
3.1 實驗數(shù)據(jù)
本文使用CCMT 2021和WMT 2021漢英和英漢新聞領(lǐng)域機器翻譯任務(wù)提供的雙語和單語數(shù)據(jù)搭建NMT系統(tǒng),表1為使用的詳細數(shù)據(jù)情況.在數(shù)據(jù)預(yù)處理時,針對評測方發(fā)布的數(shù)據(jù):一方面,采取多種不同的數(shù)據(jù)過濾方法減少數(shù)據(jù)噪聲以提高訓(xùn)練數(shù)據(jù)的質(zhì)量;另一方面,訓(xùn)練領(lǐng)域分類器以選取更接近新聞領(lǐng)域的數(shù)據(jù),其具體做法為使用新聞單語和非新聞單語,分別訓(xùn)練漢語和英語的fasttext[22]二分類模型,用于打分排序挑選新聞領(lǐng)域數(shù)據(jù).

表1 數(shù)據(jù)詳情
3.2 主要實驗結(jié)果
本文在CCMT 2021漢英和英漢新聞領(lǐng)域的翻譯評測任務(wù)上對不同的單語數(shù)據(jù)增強方法進行了對比實驗,評測指標(biāo)采用sacrebleu[23],評測集為CCMT 2019測試集,表2為詳細的實驗結(jié)果.由于評測集有4個參考譯文,本文在計算BLEU值時,分別選用了1個和4個參考譯文,記為1ref和4ref.在表2中,Baseline為雙語基線,NoiseBT為基于集束搜索加噪聲的反向翻譯方法,TagBT為基于集束搜索加標(biāo)簽的反向翻譯方法,ST為基于最優(yōu)N隨機采樣的反向翻譯方法,F(xiàn)TBT為基于集束搜索的正向翻譯和反向翻譯的組合方法,F(xiàn)TST為本文提出的基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法,DTFTST為使用領(lǐng)域知識遷移后的基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法.
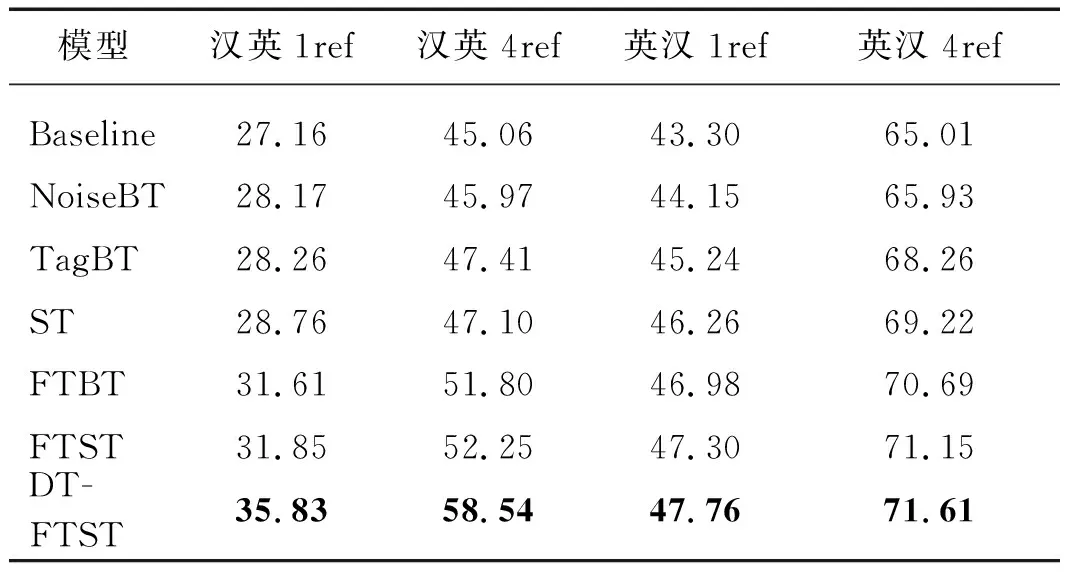
表2 不同單語數(shù)據(jù)增強方法的BLEU值
從CCMT 2021漢英新聞領(lǐng)域機器翻譯和英漢新聞領(lǐng)域機器翻譯任務(wù)上的實驗結(jié)果來看,與其他常用的幾種單語增強策略(NoiseBT、TagBT、ST和FTBT)相比,本文提出的FTST取得了最顯著的增強效果.與雙語基線相比,F(xiàn)TST模型在漢英和英漢CCMT 2019測試集1ref上的BLEU值均提升了4個百分點以上.此外,DTFTST在FTST的基礎(chǔ)上取得了更進一步的翻譯質(zhì)量提升,特別是在漢英翻譯上,提升比較明顯.與FTST相比,DTFTST在漢英1ref上的BLEU值進一步提升了3.98個百分點.DTFTST方法在漢英和英漢翻譯上提升幅度不一致,這一現(xiàn)象主要是因為使用領(lǐng)域小數(shù)據(jù)集在漢英和英漢模型上進行增量訓(xùn)練時帶來的收益有差異導(dǎo)致的.
4 分 析
4.1 單語數(shù)據(jù)規(guī)模的影響
單語數(shù)據(jù)規(guī)模往往影響著單語數(shù)據(jù)增強方法對NMT模型的提升效果.本文提出的FTST是在Wu等[13]的工作上進行的改進,因此,本文探究了在不同單語數(shù)據(jù)規(guī)模下,F(xiàn)TST方法是否能始終優(yōu)于Wu等[13]提出的FTBT.此外,本文也探究了單語數(shù)據(jù)規(guī)模對FTBT和FTST方法的影響,因為Wu等[13]的工作表明,FTBT方法可以隨著單語數(shù)據(jù)的增加而不斷提升NMT模型的翻譯質(zhì)量.具體地,本文在16.5×106雙語基礎(chǔ)上,分別選取了40×106、80×106、160×106以及300×106單語數(shù)據(jù)(其中,源語言單語和目標(biāo)語言單語各占一半比例),然后分別使用FTBT和FTST方法增強NMT模型.圖1給出了不同數(shù)據(jù)規(guī)模下漢英和英漢翻譯任務(wù)上使用CCMT 2019測試集源句與參考譯文1進行評測的結(jié)果.實驗結(jié)果表明,在不同單語數(shù)據(jù)規(guī)模下,F(xiàn)TST方法始終優(yōu)于FTBT方法.此外,使用FTST方法時,隨著單語數(shù)據(jù)規(guī)模增大,NMT模型的翻譯質(zhì)量并沒有一直提高,甚至還會略微下降,這似乎與Wu等[13]的實驗結(jié)果相反.本文分析,增加單語數(shù)據(jù)規(guī)模并沒有提升翻譯質(zhì)量有可能是因為中文單語大部分是與測試集不相關(guān)的Common Crawl數(shù)據(jù)導(dǎo)致的.因為Zhang等[12]的工作表明,單語數(shù)據(jù)并不總是改善NMT,只有使用密切相關(guān)的單語數(shù)據(jù)才可以獲得更好的翻譯質(zhì)量,當(dāng)使用更多不相關(guān)的單語數(shù)據(jù)時,會導(dǎo)致翻譯質(zhì)量下降.

圖1 不同單語數(shù)據(jù)規(guī)模的對比結(jié)果Fig.1 Comparison results of different scale monolingual data
4.2 對困惑度的影響
困惑度是語言模型效果好壞的常用評價指標(biāo),在測試集上得到的困惑度越低,說明語言模型的效果越好.本文探究了FTST在提升NMT模型翻譯質(zhì)量的同時對困惑度的影響.圖2為參考譯文的困惑度與不同NMT模型在CCMT2019測試集上譯文的困惑度,其中,譯文困惑度由所有句子困惑度的平均來表示,而句子困惑度由KenLM[24]工具計算.結(jié)果表明,與其他常用的單語數(shù)據(jù)增強方法一樣,基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法在提升NMT模型翻譯質(zhì)量的同時也增加了困惑度.本文分析,困惑度增加是因為參考譯文本身的困惑度比較高,單語數(shù)據(jù)增強后的NMT模型得到的譯文雖然困惑度提高了,但與參考譯文更加接近了.
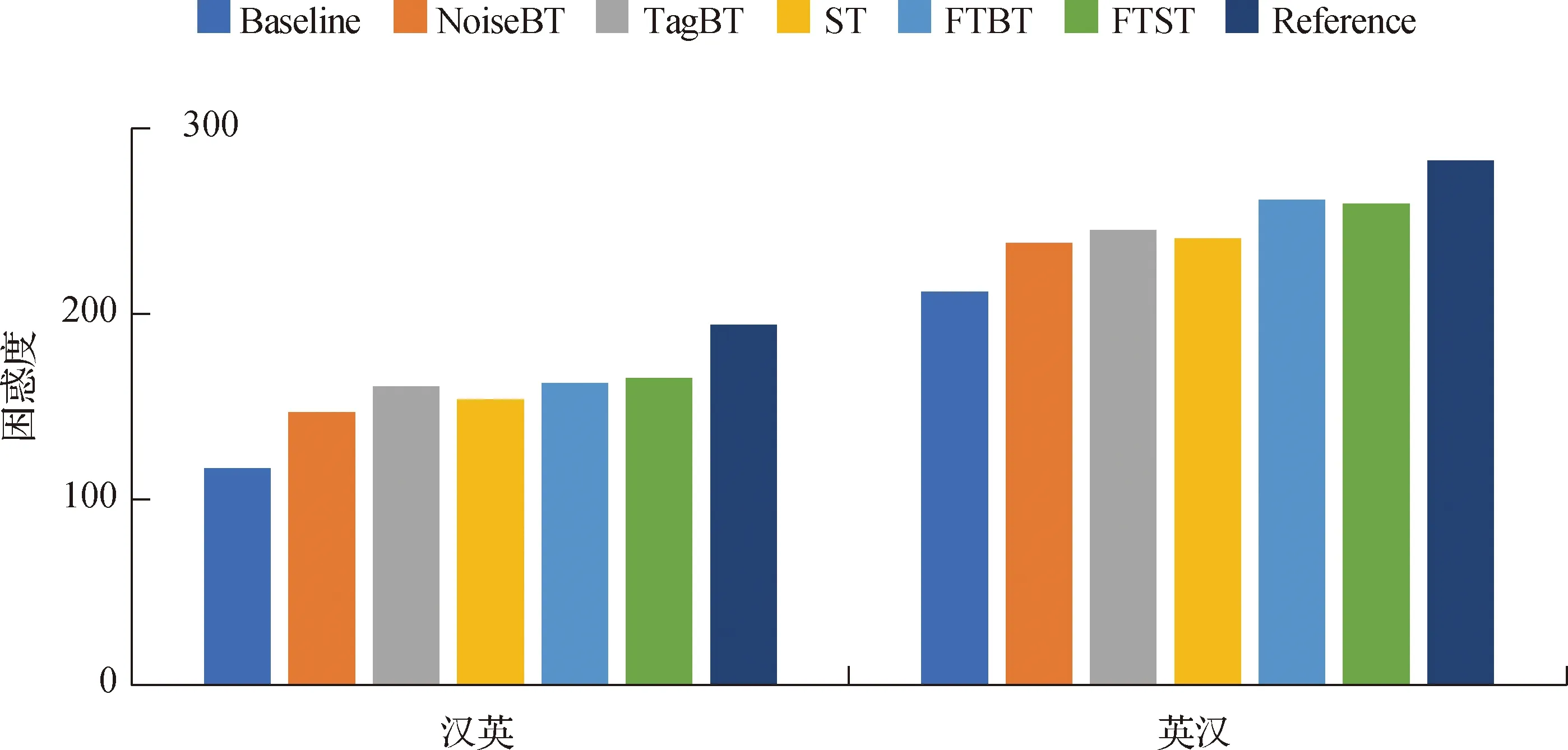
圖2 不同NMT模型譯文的困惑度Fig.2 The perplexity of translation of different NMT models
4.3 源句類型的影響
測試集的源句可以按創(chuàng)建來源分為兩種不同的類型,即翻譯腔類型與非翻譯腔類型,前者來源于人工翻譯,后者來源于自然文本.Edunov等[6]指出,基于集束搜索的反向翻譯方法只能提升源句為翻譯腔類型時的翻譯質(zhì)量,而當(dāng)句子為非翻譯腔類型時,該方法并不提供任何改進.因此,本文探究了FTST以及其他常用的單語數(shù)據(jù)增強方法是否也受源句類型的影響,表3為選用CCMT 2019測試集源句和參考譯文1做評測的實驗結(jié)果.其中,X和Y為非翻譯腔類型文本,X*和Y*為翻譯腔類型文本,以漢英模型為例,X→Y*是指測試集采用漢英測試集,X*→Y是指測試集采用英漢測試集.結(jié)果表明,與其他常用的單語數(shù)據(jù)增強方法一樣,基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法不受源句類型的影響,即不論源句是否為翻譯腔類型,均能有效提升NMT模型的翻譯質(zhì)量.

表3 不同類型測試集的對比結(jié)果
5 總 結(jié)
本文提出了基于集束搜索的正向翻譯和基于最優(yōu)N隨機采樣的反向翻譯的組合方法(FTST),并在CCMT 2021漢英和英漢新聞領(lǐng)域機器翻譯任務(wù)上與其他單語數(shù)據(jù)增強方法進行了對比實驗.結(jié)果表明,在大規(guī)模單語數(shù)據(jù)場景下,與其他常用的單語增強方法相比,F(xiàn)TST可以取得更優(yōu)的效果,而且在使用該方法之前,先進行領(lǐng)域知識遷移還可以進一步取得翻譯質(zhì)量的提升.此外,還分析了單語數(shù)據(jù)規(guī)模對該方法的影響和該方法對困惑度的影響,以及該方法是否能提升不同類型源句的翻譯質(zhì)量.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學(xué)生數(shù)理化·中考版(2020年10期)2020-11-27 01:59:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
