基于聚類與Markov 鏈法的西安市某線路城市客車工況構建
2022-07-17 07:43:38李耀華邵攀登翟登旺任田園宋偉萍趙承輝
汽車安全與節能學報 2022年2期
李耀華,邵攀登,翟登旺,任田園,宋偉萍,劉 洋,趙承輝
(長安大學 汽車學院,西安 710064,中國)
汽車行駛工況是基于汽車實際行駛數據,并結合相關數理統計方法來定量描述典型道路車輛行駛狀況的速度—時間曲線。高精度的汽車行駛工況能夠真實反映在實際行駛過程中車輛狀態的變化規律和用戶的使用需求,是汽車行業中的一項極其重要的共性技術[1-3]。中國幅員遼闊,地區差異較大,各個城市間的道路和交通狀況和駕駛員駕駛習慣存在差異。劉希玲等曾對北京、天津、上海、大連和廣州5 個城市的汽車行駛工況做了對比,結果表明各城市間的車輛行駛狀況有很大差別。因此,針對特定區域構建符合當地車輛行駛特征的行駛工況就有著較大的意義[4]。
目前,工況構建方法大多基于短行程,采用V-A矩陣法、聚類分析法、Markov 鏈法等方法構建工況。S. K. Mayakuntla 等[5]提出了一種基于行程段的汽車行駛工況構建方法。王國林[6]等利用傳統的短行程法構建了輕型乘用車的行駛工況。杜常清等[7]基于GPS/GIS 的短行程構建方法,將交通領域的大數據應用于城市工況構建中。N. H. Arun 等[8]基于全球定位系統(global positioning system, GPS)數據構建印度金奈地區乘用車和摩托車的行駛工況。G. Günther 等[9]利用短行程構建德國漢堡公交車行駛工況。李耀華等[10]基于主成分分析與聚類分析法構建了西安市電動客車行駛工況,并與其他典型城市工況進行了對比分析。C. Chandrashekar 等[11]探索了隨機選擇和k均值聚類2 種方法來構建工況。董恩源等[12-13]通過聚類分析法構建城市公交行駛工況。L. Berzi 等[14]擴充了部分運動學特征參數,構建意大利佛羅倫薩電動汽車的行駛工況。李耀華等[15-17]基于Markov 鏈法構建城市公交線路工況。P. G. Seers 等[18]考慮了郊區車輛和機場車輛的運行特殊性,構建有針對性的行駛工況。G.Amirjamshidi 等[19]利用多目標遺傳算法校準仿真模型,基于仿真數據構建多倫多地區不同類型汽車的行駛工況。
本文結合聚類與Markov 鏈法構建了西安市某線路城市客車的行駛工況,確定了聚類個數及特征參數組合,提出了Markov 鏈法構建工況長度的確定方法,從能耗角度定義汽車行駛時的單位里程比能耗作為工況選取標準,從50 條候選工況中篩選出該線路的代表工況,并建立了基于Cruise 軟件的純電動客車整車模型,從數據結構和百千米能耗對比了聚類法工況、V-A矩陣法工況、基于聚類與馬爾科夫結合法工況與樣本數據的偏差情況。
1 數據采集及預處理
1.1 數據采集及片段劃分
車輛實際運行數據是行駛工況構建的基礎。本文采用車輛無線行駛記錄儀對車輛行駛數據采集,將其固定安裝在西安市某公交線路運營車輛上,從而實現對構建線路工況所需數據的不間斷采集。本文選取了西安市某公交線路,該線路由西安市西南至東北,貫穿西安市一環至三環區域,涵蓋了西安市主干道、次干道、城郊等典型的城市公交路線,線路路線長,運營強度大,具有較好的代表性。針對特定公交線路構建工況可為該線路公交車動力系統匹配選型和混合動力系統控制策略優化標定提供依據,實現精確的定制化服務和一線一標,為公交線路的運行能耗、排放及駕駛行為經濟性評價提供依據,為特定公交線路運營提供數據服務,并可結合整車建模建立關鍵零部件的耐久性極限測試工況[20-22]。
本文以所選線路上的若干正常運營車輛作為試驗車,進行了為期16 天的無間斷數據采集,最終得到111組車輛從起點站到終點站的運行數據,并進行數據預處理,對不合理采樣數據進行清洗。通過對采樣數據分析,發現GPS 和尖點數據。怠速異常點表現為當車輛處于停止狀態,由于GPS 存在擾動,采集數據有時并不為零,保持為一個較低數值。經分析,當車速處于4 km/h 以上時,車輛明顯處于運行狀態。車速數據處于4 km/h 以下時,速度處于0~1.5 km/h 的數據占比達到80%。因此,選取速度閾值為1.5 km/h。當車速低于1.5 km/h,則將其設定為零。從而保證怠速片段的精確性和完整性。車速離群點表現為車速明顯高于序列一般水平。經調研,該線路主要在西安市內運行,擁堵嚴重,公交車運行車速一般低于40 km/h。因此,將高于40 km/h 的數據視為車速離群點。經統計,該類異常值所占比重極小,對數據完整性影響也極小,故采用直接刪除處理方式。尖點數據表現為由于GPS 信號存在干擾,GPS 信號產生,使得加速度值出現過大的尖點。調研發現,該線路公交車實際運行的最大加速度與最大減速度分別為2.5、-3.5 m/s2,因此,將加速度超過限值的數據視為尖點,采用線性插值法處理。
研究表明:當樣本數據達到飽和后,數據量的增加已很難提高工況精度,反而會增加后續的工作量[13]。本文選擇加速比例、勻速比例、減速比例、怠速比例、平均車速和平均運行車速這6 個參數作為穩定性判定指標。定義其平均值隨采樣數據組增大的變化率為穩定度K,并將這6 個參數穩定度的平均值定義為綜合穩定度,分別如式(1)和式(2)所示,其中和ā6(j)分別為樣本數據增加到j組時的加速比例、勻速比例、減速比例、怠速比例、平均車速及平均運行車速。

隨著采樣數據的增加,綜合穩定度K的變化趨勢如圖1 所示。
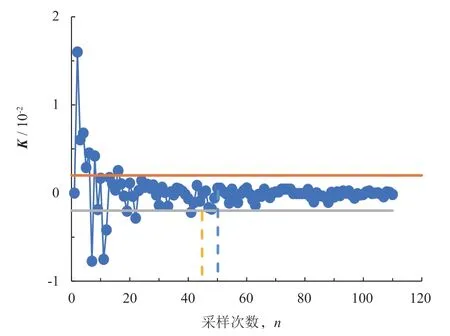
圖1 綜合穩定度K 的變化趨勢
由圖1 可知,綜合穩定度K隨著數據量的增加逐漸收斂至0。從第41 次采樣開始,連續5 次K的絕對值均小于0.002,且收斂速度開始變緩。因此,可認為樣本數據在采樣次數為45 時達到飽和。考慮到一定的裕度,本文取50 組采樣數據作為構建工況的樣本數據。
將車輛兩個怠速點之間的運行片段定義為一個短行程,如圖2 所示。通過對50 組數據的處理,本文最終得到2 830 個短行程。
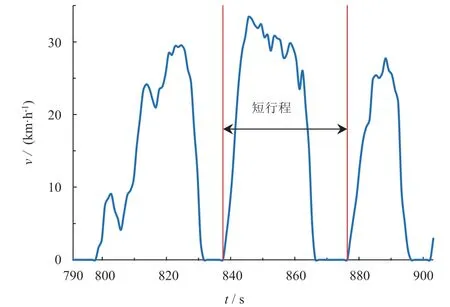
圖2 短行程示意圖
2.2 特征值組合及狀態個數確定
運行片段可以由片段的特征參數描述。車輛工況構建一般采用平均速度(vmean)、平均加速度(amean)、平均減速度(Dmean)、平均運行速度(vmr)、運行時間(t)、速度標準差(vsd)、加速度標準差(asd)、最大速度(vmax)、最大加速度(amax)、最大減速度(Dmax);0~10 km/h 的時間比例為λ0-10、10~20 km/h 的時間比例為λ10-20,以此類推,20~30、30~40、40-50 km/h 的時間比例分別為λ20-30、λ30-40、λ40-50;加速時間比例(λa)、減速時間比例(λd)、勻速時間比例(λc)、怠速時間比例(λi)、加速時間(ta)、減速時間(td)、勻速時間(tc)、怠速時間(ti)、運行距離(Lr),共24 個特征參數。為了消除這些特征參數由于量綱和取值范圍不同而引起的差異,本文對這24 個特征參數進行了z-score 標準化處理,如式(3)所示,


表1 特征參數標準化矩陣
聚類是構建工況中的關鍵一步。通過聚類可將數據片段合理的劃分到不同的狀態,然后根據各片段隸屬狀態的結果求取狀態轉移概率矩陣,最后在片段拼接時從所跳轉的狀態中挑選合適的片段進行工況長度的延伸。因此,聚類的結果好壞對工況構建的精度有較大的影響。
聚類試驗結果表明,選取不同特征值組合與類的個數進行聚類,聚類的結果會有較大的差別[23-29]。為找出最佳特征值組合和類的個數,本文選取了30 組不同的特征值組合進行了類個數為3 個、4 個和5 個共90 次聚類交叉試驗。90 次聚類試驗的各類短行程個數分布如表2 所示。

表2 不同類個數和不同特征參數組合的聚類分析結果
經過交叉試驗可知,絕大多數情況下,選擇的類的個數越多,聚類后在每一類中短行程個數的分布越不均衡,出現某一類中短行程個數過小情景的概率越大。對于本文的工況構建,聚類得到的結果即為Markov 鏈的狀態空間。如果狀態空間中某一狀態的短行程個數過少,在進行狀態跳轉時,從上一時刻的狀態跳轉到該狀態的概率幾乎可以忽略不計,即使跳轉到該狀態,對最終構建出來工況的精度也有很大影響。因此,在選擇狀態空間時,應極力避免這種狀況,結合表2,本文選擇的聚類個數為3 個。此時,不同特征值組合聚類后得到的狀態轉移概率矩陣(P)如圖3 所示。
車輛的行駛過程是一個連續且穩定的過程,發生狀態躍遷的概率不大,反映到狀態轉移概率矩陣上即為對角線上的概率明顯大于其他區域。聚類試驗所得的結果中,圖3d 所示的狀態轉移概率矩陣明顯符合此特征。該特征值組合聚類所得樣本數據的狀態轉移概率矩陣如式(4)所示。式(4)中對角線上數據最大,符合狀態轉移概率矩陣特征。
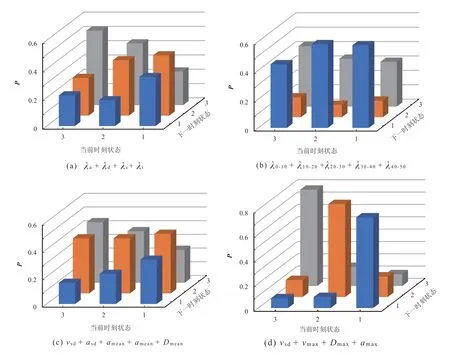
圖3 不同特征值組合聚類后樣本數據的狀態轉移概率矩陣

因此,本文選取的特征值組合為速度標準差vsd、最大速度(vmax)、最大加速度(amax)和最大減速度(Dmax)。
3 候選工況構建
在進行候選工況構建時應先選擇合適的初始片段,判斷初始片段的狀態后結合狀態轉移概率矩陣進行狀態跳轉,而后從跳轉的狀態中選擇拼接后與樣本數據最相似的片段進行拼接。在多次的狀態判定、狀態跳轉和片段選擇的循環后,若拼接片段達到穩定即可結束工況構建,候選工況構建的主要流程如圖4 所示。

圖4 候選工況構建流程
3.1 Markov 狀態轉移過程
Markov 過程是一個隨機過程,記為Zt(t= 1, 2,…,T),狀態空間記為S={1, 2, …,K}。Zt為每個狀態t的模型事件,狀態空間S是收集了相似模型事件編入事件組對的集合。對于t和所有的狀態s1,s2, …,st,當前狀態st的概率只與前一個狀態st-1有關,對于一個Markov 過程,根據最大似然函數,其狀態轉移概率方程如式(5)所示。

其中:prs為狀態轉移概率,Nrs表示時間為(t-1)時狀態r轉移到時間為t時狀態s的事件個數。
3.2 初始片段選取
初始片段的選取在Markov 法構建工況過程中對后續片段的拼接和最終結果的偏差有著至關重要的作用。本文將每個長行程的第1 個短行程(即公交車起點起步過程)作為候選工況的初始片段。圖5 為某條候選工況初始片段。
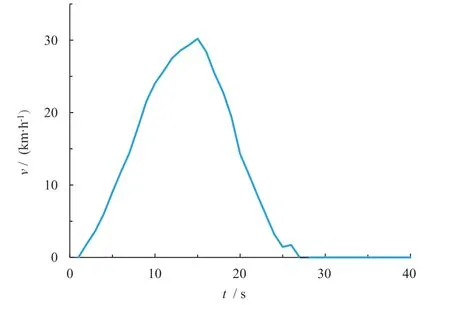
圖5 某候選工況初始片段
3.3 工況構建
在工況構建時,每次狀態跳轉時都選擇在不重復的情況下該片段在當前狀態中拼接后與樣本數據的V-A 矩陣相似度最高的片段進行拼接。判斷片段與樣本數據V-A 矩陣相似度的方法是先將2 個矩陣按同一種方式轉化為一維數組,然后計算二者的Pearson 相關系數[r(x, y)]。Pearson 相關系數是將數據歸一化后進行的余弦相似度計算,如式(6)所示,其中x和y為矩陣降維后的一維向量;為矩陣中所有元素的平均值;xi和yi為一維向量中的元素。該系數越接近于1,說明兩個矩陣的相似度越高。
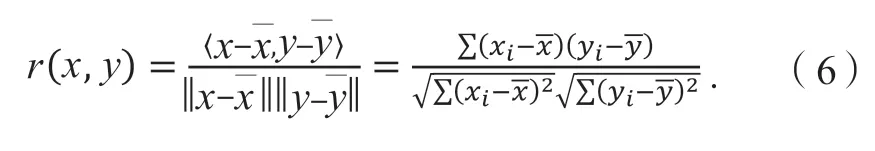
合理的工況長度對構建工況也很重要。工況長度如果過短,則無法反應城市客車的實際運行狀況,但如果長度過長,則會無謂地增加工況構建及后期應用的工作量。本文將進行拼接后的片段與樣本數據的V-A矩陣歐氏距離作為判斷該矩陣是否穩定的標準,通過判斷工況構建過程中的V-A 矩陣是否穩定來確定工況構建的長度是否合適。
V-A 矩陣的歐氏距離(D)計算式如式(7)所示,其中uij為樣本數據V-A 矩陣元素;vij為拼接后片段V-A矩陣元素;m和n為V-A 矩陣行列數。
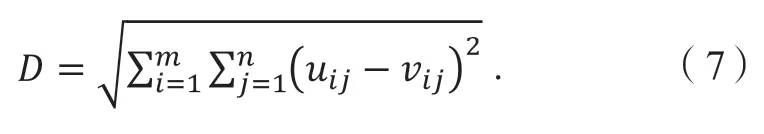
某工況構建過程中歐氏距離D值的變化如圖6 所示。由圖6 可知:該工況在拼接14 次(D= 0.033 919)之后曲線已經趨于穩定,此時再增加長度,對工況的精度提升不大,故該工況在拼接次數達到14 次時可跳出循環,結束工況構建。
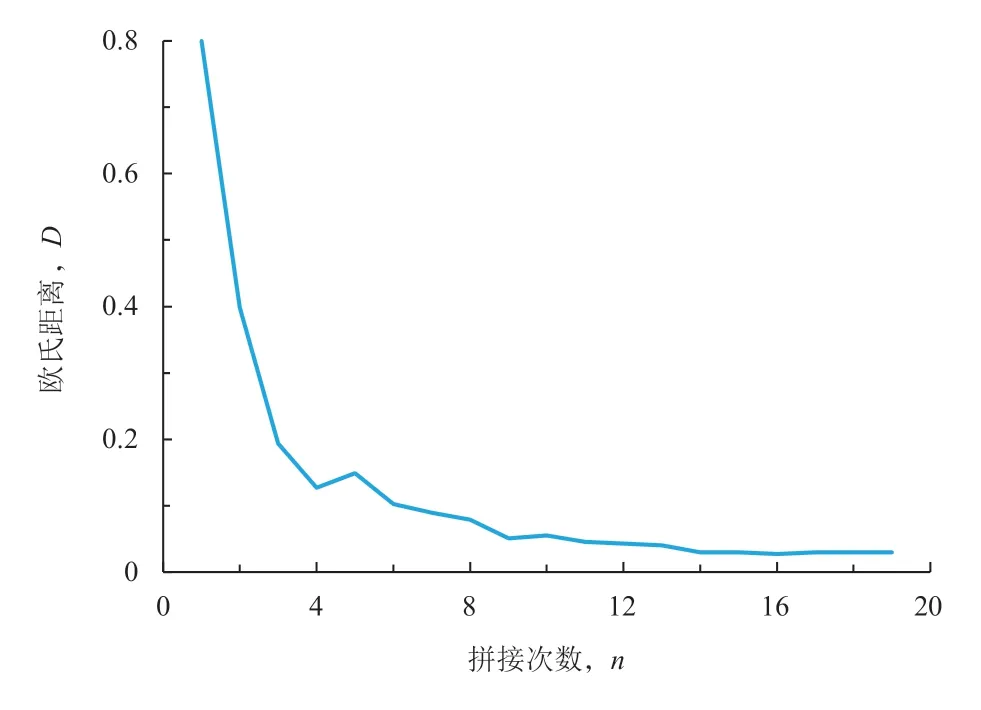
圖6 某工況構建過程中歐氏距離D 值的變化
4 代表工況選取
為了體現汽車行駛時的能耗狀況,本文從能耗角度定義汽車行駛時的單位里程比能耗作為工況選取參考,如式(8)所示。

其中:Ws為車輛行駛過程中的單位里程比能耗[J/(kg·km)],γp為機動車比功率(kW/kg),L為車輛行駛里程(km)。根據比功率的定義,該采樣車型γp計算公式如式(9)所示[30-32]。
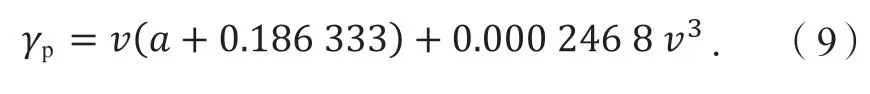
其中:v為車速,a為車輛加速度。
單位里程比能耗直接反映了車輛行駛過程中克服阻力做功的大小,其值越大表明做功越多。經計算,50 條候選工況的單位里程比能耗計算如表3 所示。
經計算,樣本數據的平均單位里程比能耗為168.04 J/(kg·km)。由表3 可知,第14 條候選工況與樣本數據的單位里程比能耗相差最小,為168.06 J/(kg·km),相差0.02 J/(kg·km),偏差率最小,僅為0.012%。因此,本文將其作為西安市該線路城市客車的代表工況,如圖7 所示,工況時長為1 419 s。

圖7 西安市某線路城市客車行駛工況
該代表工況的部分特征值如表4 所示。
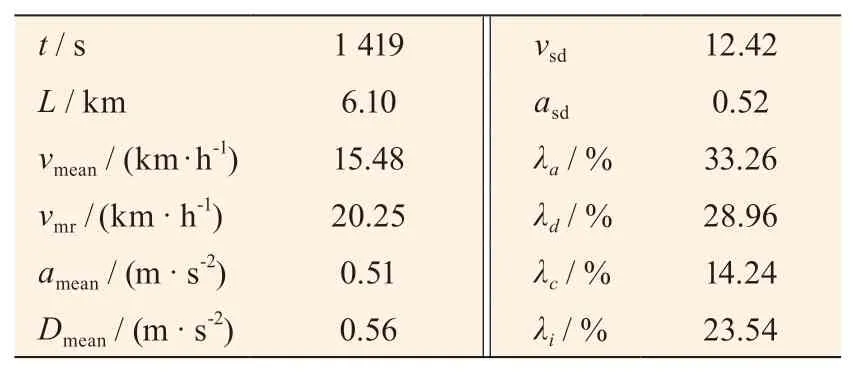
表4 西安市某線路城市客車行駛工況特征值
本文從數據結構相似度也對代表工況進行驗證。樣本數據和該代表工況的速度與加速度聯合概率分布如圖8 所示。圖8 表明本文構建的工況與樣本數據的速度與加速度聯合概率分布基本一致。經計算,二者V-A 矩陣的歐氏距離僅為0.036 742,具有很高的相似度。

圖8 速度與加速度聯合概率分布圖
同時,本文選取了平均速度(vmean)、平均加速度(amean)、平均減速度(Dmean)、平均運行速度(vmr)、速度標準差(vsd)、加速度標準差(asd)、加速時間比例(λa)、減速時間比例(λd)、勻速時間比例(λc)、怠速時間比例(λi)等10 個在工況構建中非常重要的統計量,分別計算了這50 條候選工況的10 個特征值,并將其分別與樣本數據做了平均偏差檢驗。50 條候選工況與樣本數據這10 個特征值的偏差率的平均值定義為平均偏差率,經計算結果如表5 所示。由表5 可知,本文構建的行駛工況與樣本數據偏差較小,平均偏差率為1.17%。在數據結構上與樣本數據相似度較高。
表5 50 條候選工況與樣本總數據平均偏差率
5 仿真驗證
為了驗證基于聚類與Markov 結合法構建工況的精度,基于相同的樣本數據,本文分別使用聚類法和V-A 矩陣法構建了2 條工況。采用聚類與Markov 鏈法 (簡稱B 法)、聚類法和V-A 矩陣法構建得到的工況與采樣數據的數據特征如表6 所示,其誤差分別為1.17%、5.80%、9.37%。從數據特征角度表明采用聚類與Markov 鏈法構建得到的工況與采樣數據的誤差更小。

表6 數據特征值
基于Cruise 軟件搭建了純電動客車整車模型,對3 條工況及樣本數據進行能耗仿真。純電動客車整車參數如表7 所示。

表7 仿真建模所用整車參數
為了避免因工況長度不同帶來的影響,將仿真能耗結果換算成百千米電耗。使用樣本數據的百千米電耗為72.91 kWh。聚類與Markov 鏈法結合(B 法)、聚類法和V-A 矩陣法構建工況百千米電耗及與樣本數據百千米電耗的偏差率如表8 所示。

表8 能耗仿真結果
由表8 可知,聚類與Markov 鏈法構建得到的工況百千米電耗仿真結果為72.86 kWh,與樣本數據百千米電耗相差最小,偏差率僅為0.069%,說明利用該方法構建的行駛工況精度更高,更能反映車輛的實際行駛狀況,百千米電耗仿真數據也可為該公交線路的運行能耗和駕駛行為經濟性評價提供依據。
6 結 論
本文基于聚類與Markov 鏈結合的方法構建了西安市某線路城市客車的行駛工況,以單位里程比能耗為標準選取典型工況,并與聚類法和V-A 矩陣法構建得到的工況進行了數據特征誤差率和仿真百千米電耗對比,得出結論如下:
1) 聚類與Markov 鏈法中聚類個數和特征參數的選取應以每類短行程個數和狀態轉移矩陣決定,并不是特征參數選取越多,聚類效果越好。
2) 聚類與Markov 鏈法工況構建過程中,可根據片段拼接后的V-A 矩陣的歐式距離是否穩定來決定構建工況的長度,從而滿足工況構建需求,并減小工況構建及后期應用的工作量。
3) 可定義汽車行駛時的單位里程比能耗作為代表工況選取標準,從能耗角度來篩選代表工況。由此得到的工況與樣本數據的數據結構相似度也很高。
4) 數據特征誤差率和仿真能耗對比表明:與聚類法和V-A 矩陣法相比,聚類與Markov 鏈法構建得到的工況與樣本的數據特征和能耗結果最為接近。
5) 基于構建得到的工況,后續可開展動力系統匹配選型、混合動力汽車最優能耗及控制策略確定、公交線路的運行能耗、排放及駕駛行為經濟性評價研究,并可結合整車模型構建關鍵零部件的耐久性極限測試工況。
