多尺度選擇金字塔網絡的小樣本目標檢測算法
2022-07-21 03:24:02李曉明
計算機與生活 2022年7期
彭 豪 ,李曉明,2+
1.太原科技大學 計算機科學與技術學院,太原030024
2.太原科技大學 計算機科學與技術學院 計算機重點實驗室,太原030024
在近幾年里,深度學習為目標檢測帶來了前所未有的進步,基于深度學習的各種目標檢測方法,例如R-CNN(regions with convolutional neural network features)、Fast R-CNN、Meta R-CNN、YOLO(you only look once)等效果提升到了一個較高的水平,在很多方面取代了人工。這些檢測器的檢測效果取決于網絡在詳盡標注的大規模標注數據集上經過訓練得到的模型。通常,這些數據來源需要大量人力資源手工標注,而手工標注的成本又非常高昂。當某些特殊場景缺少樣本時,模型往往會產生過擬合或是欠擬合等問題,容易導致檢測器泛化性能差無法識別新類別。
近些年來出現很多小樣本目標檢測方法。LSTD(low-shot transfer detector)結合了Faster R-CNN和SSD(single shot multi-box detector)在分類任務和邊框回歸任務上的特性,提出了知識遷移正則化和背景抑制正則化兩種方法,分別利用源域和目標域的知識增強模型對小樣本數據的泛化能力。RepMet(representative-based metric)引入了原型聚類,構造原型空間提取圖像的嵌入特征,使用歐式距離計算嵌入特征與支持集類別表示之間的距離。Feature Reweight使用元加權模型將支持集特征以通道相乘融合到查詢集特征,這種方法需要額外的掩膜分支,增加了計算復雜度。Attention-RPN將基于注意力的區域生成網絡(region proposal network,RPN)與比較訓練的策略相結合,利用Matching Networks的思想計算查詢實例和支持實例的相似性。LSCN(low-shot object detection via classification refinement)中提出了統一識別、全局接收場、類間分離和置信度校正四個組件,解決因為類指定參數過多導致分類置信度和定位精度存在嚴重誤差的問題。Wu等人和Han 等人研究了在小樣本目標檢測中的多尺度問題,設計了一個特征金字塔模塊生成多尺度特征,并在不同尺度上進行細化,但其網絡構造復雜,引入過多的參數增加了計算復雜度。
對于小樣本目標檢測來說,建立特征的相關性和增強新類參數的敏感性是提升小樣本目標檢測性能的關鍵。當有目標相互交錯在一起時,檢測器會因為只看到了不完整的anchor而發生漏檢。Context-Transformer認為從小樣本目標檢測的任務性質出發,邊框回歸任務在經過數據的充分訓練后再在新類上經過微調就可以取得不錯的效果,但分類卻很困難。造成這一困難首先是模型對于新類參數不敏感,其次在經過新類樣本二次訓練后也在一定程度上擾亂了基類已學習到的參數。而現有方法中大多考慮的是整體的檢測性能或是采用了簡單的融合策略,沒有專門針對新類與基類的參數融合問題進行探索。
如圖1所示,Meta R-CNN 中設計了一個PRN模塊提取支持集類向量,以通道乘法對查詢集的實例級感興趣區域(region of interest,RoI)進行元加權。首先,查詢集圖片經過特征提取網絡和RPN 網絡得到感興趣區域的特征圖,然后支持集圖像和對應的真實標簽圖經過預測器重建模網絡(predictorhead remodeling network,PRN)得到每個類別對應的類別注意力向量,CNN 的特征提取網絡結構相同且權重共享,得到對應特征圖后,通過逐元素Sigmoid函數得到對應的注意力向量,最后將RPN 網絡輸出的感興趣區域特征圖和PRN網絡輸出的注意力向量通過逐通道相乘的方式進行融合,再利用Faster/Mask R-CNN中預測頭得到對應的檢測圖或分割圖。這種方法結構簡單,但是沒有考慮特征的相關性,在含有大量無效背景的特征中,檢測器很容易產生混淆。同時,對于少量樣本,模型對新類參數不敏感,檢測精度不高。
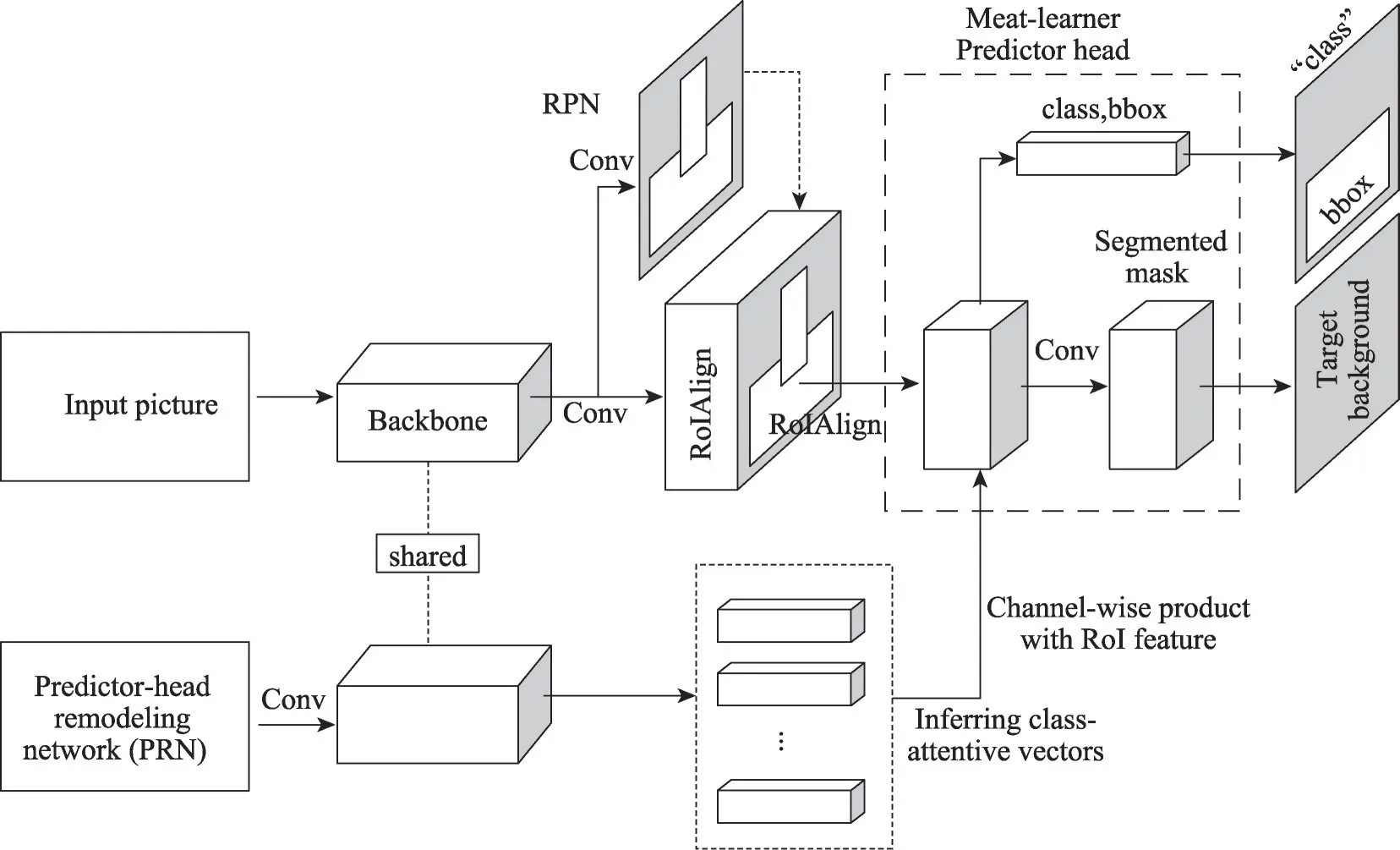
圖1 Meta R-CNN結構圖Fig. 1 Meta R-CNN structure diagram
因此在本文中,建立特征的相關性和增強新類參數的敏感性是提升小樣本目標檢測性能的關鍵。本文的主要貢獻總結如下:
(1)設計了一個用于小樣本目標檢測的尺度選擇金字塔網絡,它由三個組件組成:上下文層注意力(contextual layer of attention,CLA)模塊;特征尺度增強(feature scale enhancement,FSE),專注于特定尺度的物體;特征尺度選擇模塊(feature scale selection module,FSS),實現深層和淺層之間適當的特征共享。
(2)在RPN網絡產生的RoI特征后采用平均池化和最大池化來提升特征之間的相關性,在后面進行特征融合,并且采用特征減法(feature subtraction,FS)濾除特征圖像中的雜波,突出特征中的區分類信息,提升模型對新類參數的敏感度,保持模型對基類參數的穩定性。
(3)引入正交損失(orthogonal loss,OL),就是在隱藏層的特征空間施加正交性,保持不同類特征間的分離性,同一類特征的聚合性。從而保證模型在少量樣本情況下也能夠很好地衡量特征間的相似性。
1 基于多尺度選擇金字塔網絡的小樣本目標檢測
提出的基于多尺度選擇金字塔網絡的小樣本目標檢測算法的體系結構如圖2所示。首先,設計了一個用于小樣本目標檢測的尺度選擇金字塔網絡,它由三個組件組成:上下文層注意力模塊、特征尺度增強模塊、特征尺度選擇模塊。然后在RPN 網絡產生的RoI 特征后采用最大池化和平均池化來提升特征之間的相關性,之后進行特征融合,并且采用特征減法來突出特征中的類別信息;最后采用正交映射損失函數使模型在分類層前就約束特征。
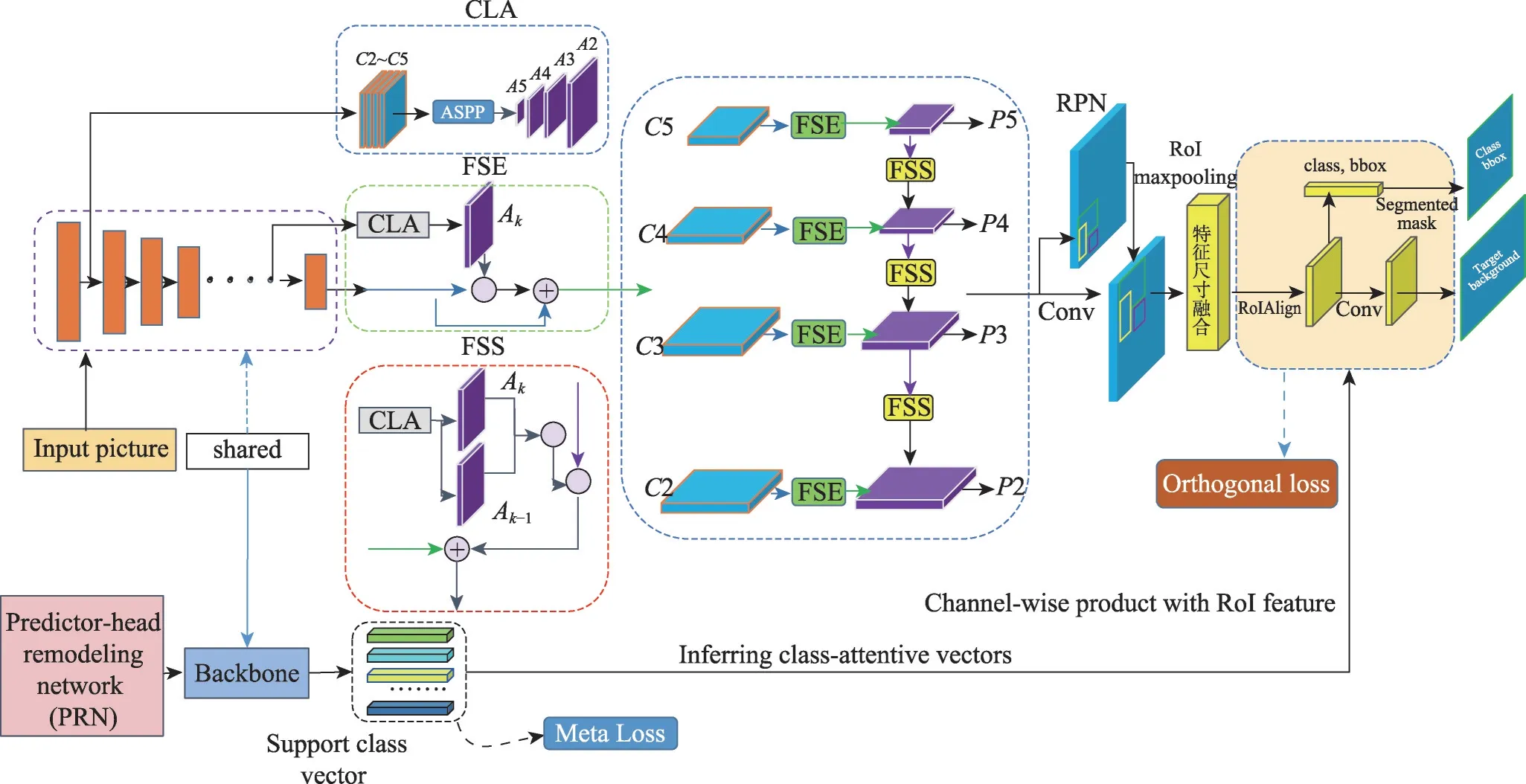
圖2 提出的小樣本目標檢測算法的體系結構Fig. 2 Architecture of proposed small sample target detection algorithm
1.1 上下文層注意力(CLA)
為了生成分層的attention heatmap,本文設計了CLA來生成不同層次的attention heatmap。因為上下文信息可以提高檢測小目標的性能,所以,本文首先將backbone 在不同stage 產生的特征進行上采樣,使其與底部的特征具有相同的形狀,并將它們連接起來。然后采用多尺度空間金字塔池算法(atrous spatial pyramid pooling,ASPP)提取的多尺度特征來尋找目標線索。ASPP 生成的上下文感知特征被傳遞到一個由多個3×3 卷積和sigmoid 激活函數組成的激活門。該激活門由多個不同stride的卷積和sigmoid激活函數組成,生成層次attention heatmap A:

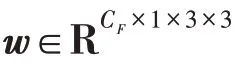

圖3 不同層注意力熱力圖和不同模塊互補作用分析Fig. 3 Heat map of attention on different layers and analysis of complementary effects of different modules
1.2 特征尺度增強(FSE)
采用FSE 增強目標物體的線索。目標信息在低層特征上信息少,因此作用于中高層中,使得FSE能夠產生尺度感知特征。

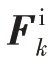
1.3 特征尺度選擇(FSS)
FSS引導淺層向深層提供合適的特征,如果相鄰層的目標都能被檢測到,那么深層將提供更多的語義特征,同時與下一層進行優化。FSS可以設計如下:
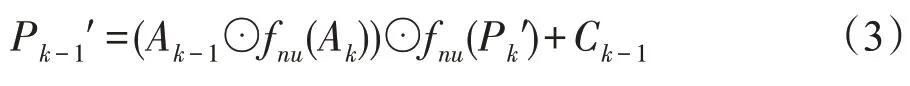
其中,A與A的交點為⊙,f為最近的上采樣操作,P′為第層的合并映射,C為第(-1)個殘塊的輸出。FSS 起著比例選擇的作用。對于下一層尺度范圍內的目標對應的特征將被視為合適的特征流入下一層,而其他特征將被弱化以抑制梯度計算中的不一致性。
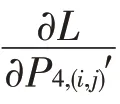
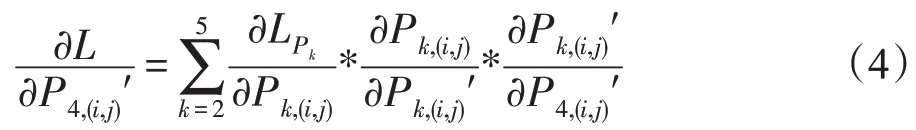
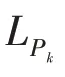

在特征提取過程中,高層特征丟失了大量位置信息,在目標定位,特別是小目標的定位上影響較大,因此考慮將ASPP生成的上下文感知特征疊加到高層特征中減少背景信息對小目標的影響,增加分類準確性。對于小的目標而言,目標特征經過多次卷積池化的操作后,特征信息容易丟失。但是在高層特征的分類中有用信息又主要集中在高層,FSE作用于高層的最后2~3層特征上,跟單純的特征疊加不同,小目標有相對較小的尺度,合適的A將會把感覺興趣的區域放在目標特征上。FSS 在特征從淺層往深層的流動中,起到一個篩選作用。圖3右側直觀展示了增加不同模塊后的特征熱力圖的效果。
1.4 多元特征融合(MFF)
Meta R-CNN 保留了Faster R-CNN 的兩段式結構,由RPN生成圖像中目標的候選邊界框anchors,然后經過RoI Pooling層和RoI Align層后網絡從候選邊界框中提取感興趣區域的目標特征,由分類器和回歸器分別對目標特征進行分類和邊框回歸。網絡對特征的提取以及處理模式是固定的,當數據量比較少時,這樣的處理往往會遺漏圖像的重要特征。通常來講,網絡的高層語義特征對于分類任務都是有所幫助的,因此本文使用RoI mean-pooling 來獲得網絡中的CLA 整體信息,計算特征基于通道的相關性。最大池化作用于FSE,可以濾除無關信息,兩者的結合形成多元特征,對于少量樣本信息,提取保留更多紋理等細節特征,以此來提升模型對新類參數的敏感度,具體如圖4所示。
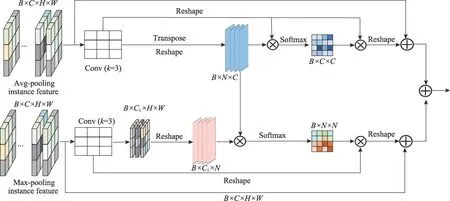
圖4 多元特征融合示意圖Fig. 4 Schematic diagram of multiple feature fusion
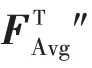

關系矩陣經過softmax 后得到跨通道關系注意力特征圖Ψ:
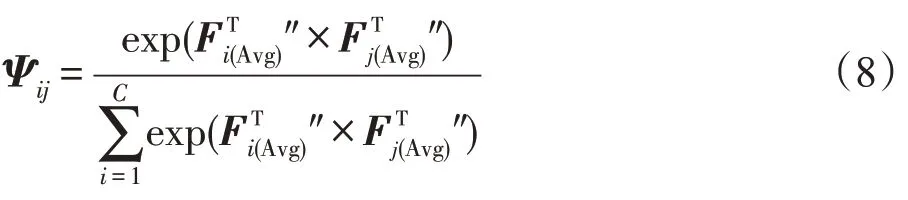
式中,Ψ表示第個通道對于第個通道的關系分數,矩陣的每一行都表示了特征上通道間的互相關程度。注意力特征圖Ψ通過矩陣乘法映射到特征″上得到特征向量。最后,經過維度變換后以元素相加的方式疊加到原始特征′上增強跨通道的特征表示,得到基于通道的互相關特征。


之后,通過softmax函數得關系注意力特征圖Θ:
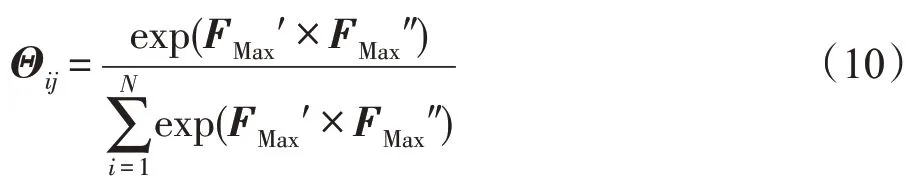
為了突出特征顯著性,將Θ通過矩陣乘法映射到″上得到特征向量,最后把經過維度變換后以元素相加的方式疊加到原始特征′上增強跨像素空間的特征表示,得到基于像素空間的互相關特征。
最后,基于像素空間的互相關特征和基于通道的互相關特征拼接起來,最終輸出為:

特征減法(FS)可以濾除圖像中的雜波,能夠突出特征中的區分類信息,結構如圖5所示。
圖5中,是每個批中包含的樣本實例數,是特征通道數,是卷積核的大小,和分別表示生成的得分向量和新類加權系數。使用卷積得到一個可學習的參數,將特征取絕對值,通過激活函數后將維度還原,這里采用Sigmoid 函數只是充當一個門控作用,緩解查詢集圖像中存在的過多背景和無用特征對分類器的影響,還可以濾除一些雜波,然后加權增加新類參數的敏感性。避免通道上的局部交互特征受維度的影響。輸出可以表示為:
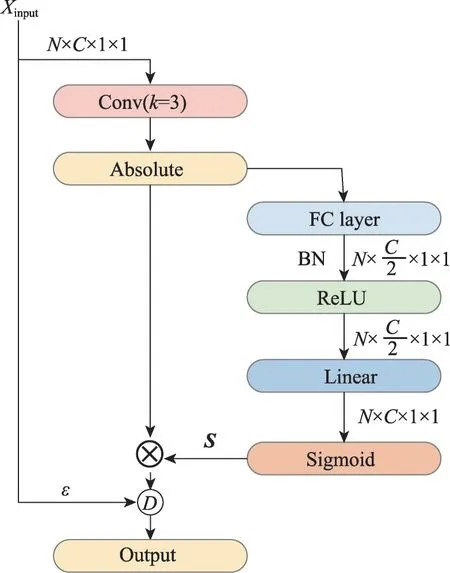
圖5 特征減法示意圖Fig. 5 Schematic diagram of feature subtraction

這種做法能盡量避免產生高維特征,有助于模型泛化,保持穩定性。
1.5 損失函數構建
在小樣本目標檢測任務中,由于新類中可學習樣本數量較少,神經網絡往往難以在幾個實例上就學到可靠的特征表示,不夠明確的特征參數給分類器帶來了很大的困難。除此之外,如果直接將隱藏層特征輸入到分類層,分類器很容易會產生現有類與新增加類的混淆。為減輕這種混淆給檢測模型帶來的影響,采用了一種正交損失,在隱藏層的特征空間施加正交性,保持不同類特征間的分離性,同一類特征的聚合性。
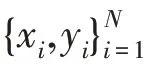

式中,為一個控制權重的超參數,|·|表示絕對值操作,余弦相似度的具體計算如下:

其中,||·||表示向量的2 范數。在等式中通過約束逼近1 來保持同類樣本間聚類,逼近0 讓不同類樣本間保持距離,以減輕特征混淆對分類器的影響。這種方法沒有多余的參數需要學習,簡單高效,帶來的性能提升將在后面的消融實驗中進行分析。
網絡架構基于類似于Meta R-CNN,采用兩階段訓練方法,訓練過程中的損失函數可以表示如下:
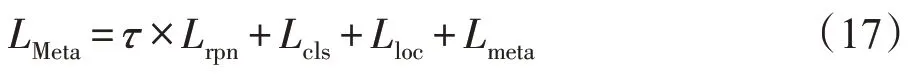
其中,為應用于RPN 網絡區分前景背景和微調anchors 的損失;為R-CNN 中用于分類的交叉熵損失;為R-CNN 中用于邊框回歸的Smooth損失;為Meta R-CNN中用于生成支持集類向量的交叉熵損失。特征相關性構建模塊和特征融合模塊添加約束,整個網絡中應用的損失函數可以表示如下:

在實驗中,通過權重可以增加前景與背景作用提高不同類特征間的分離性,起到分類作用,因的作用有限,在中增加損失,增強相同特征的聚合性和不同特征之間的分離性,通過改變和使得模型達到最好的效果。
2 實驗結果與分析
2.1 數據集介紹
VOC07 常用來衡量圖像分類檢測能力,其中訓練集(5 011 幅),測試集(4 952 幅),共計9 963 幅圖,共包含20 個種類。COCO2014有91 個分類,其中82個分類每個都超過5 000個實例對象,為了能更好地學習每個對象的位置信息,在每個類別的對象數目上也是遠遠超過VOC07 數據集。為了公平比較,本文的實驗設置與文獻[3]一致,所有實驗結果都通過隨機數據采樣運行10次計算平均值得到。
2.2 訓練參數設置
本文中使用Meta R-CNN 作為網絡基本架構,ResNet101作為主干網,在初始化時使用ImageNet上預先訓練的權值。本文的訓練策略與文獻[3]相同,使用隨機梯度下降作為網絡的優化器,整個訓練過程分為兩個階段:第一階段只訓練數據豐富標注完備的基類,設置初始學習率為10,batchsize 為4,一共訓練20 個epochs,每個epoch 迭代3 000 次,每5個epochs 后學習率衰減為原來的1/10。第二階段在同時包含基類和新類的小樣本數據集上訓練,設置初始學習率為10,batchsize 大小為4,一共訓練9 個epochs,在訓練5 個epochs 后學習率衰減為10,繼續訓練剩余4 個epochs。此外,設置中參數=2,=1.3,=1.8。所有實驗使用GTX 3090 在Pytorch上實現。
2.3 VOC實驗
實驗分為兩階段:
第一階段,使用一種low-shot 實驗設置,在VOC07上考慮了三種不同的數據集拆分設置(如表1第2行),這一階段,只考慮基類對象。在每一個訓練基類中都有3 000個帶標注的bbox,其中∈{1,2,3,5,10}。為了公平評估,正確的預測應該與Ground Truth的交并比(intersection over union,IoU)大于0.5,并以平均準確率(mean average precision,mAP)作為評價指標。第一階段結果如表1所示。
從表1 可以看出,本文模型的檢測性能優于Meta R-CNN。在VOC split 3 實驗中,本文模型都達到了最佳性能。當極標注類別比較少(=1,2,3)時,Meta R-CNN 很難提高檢測性能,本文模型可以有更好的性能,并且隨著的增加,優勢更加明顯。在=10 與baseline相差分別為12.0個百分點、7.9個百分點和9.5個百分點。相比其他先進方法,本文方法也有明顯優勢。
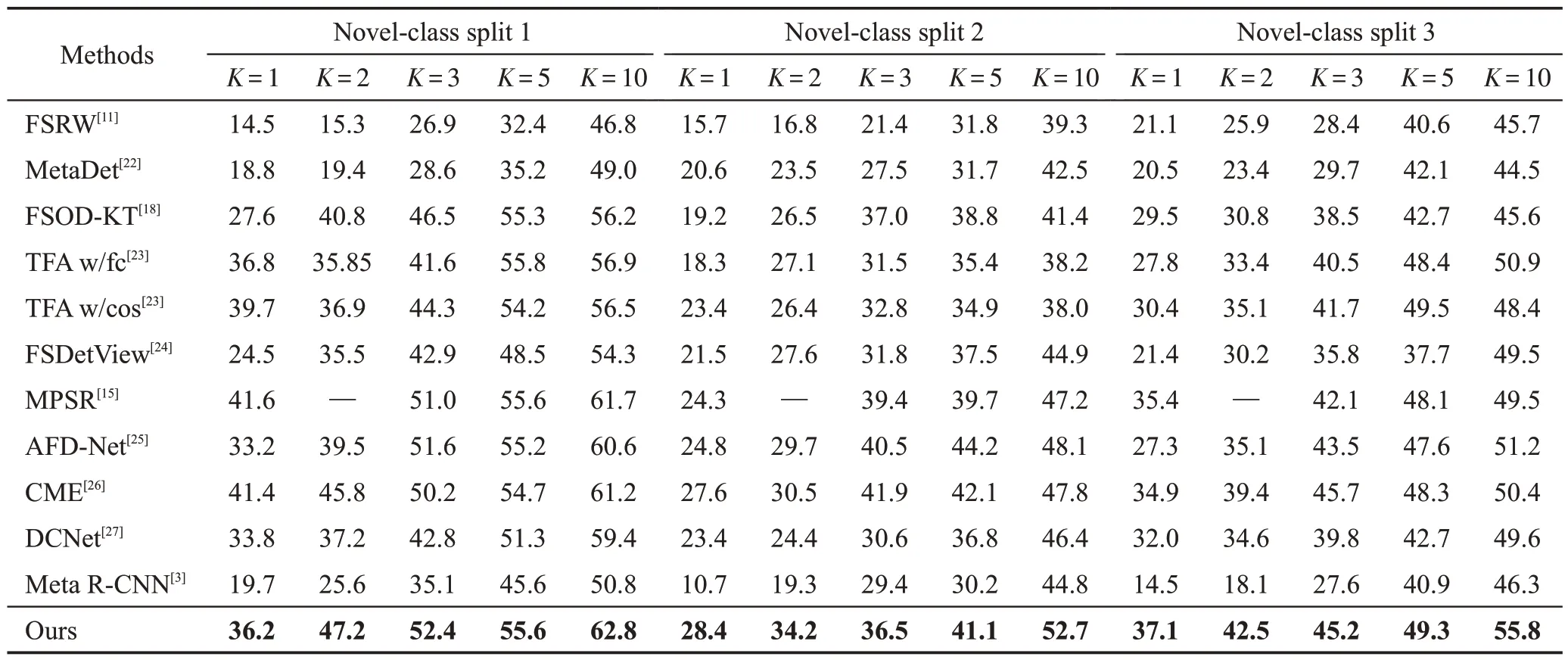
表1 VOC07測試集上的low-shot檢測mAPTable 1 Low-shot detection mAP on VOC07 test suite %
第二階段,數據被隨機分為15 個基本類別和5種新類別。模型在包含15個類別的基類數據集上進行訓練,每個基類中的對象有3 000個標注的邊界框用于訓練,在5 個新類數據集上測試。表2 記錄了VOC 在拆分數據上每個新類別的評估結果。首先,與基準相比,Meta R-CNN 在VOC 的3 個分割上的“sofa”檢測性能較差,特別是當=1 時。在本文方法中,VOC spilt 1 中“sofa”的單次檢測性能增加了20.77個百分點,而雙次檢測性能增加了29.40個百分點。在其他方法中,VOC split 2 中“bottle”的檢測性能并不理想,本文方法得到的mAP 高于其他方法。將值對應的3 次平均精度展示在圖6 中。總體而言,該方法在所有類別的測試結果中都更具競爭力。VOC 中的“bottle”往往過于密集,所占比例相對較小,實驗結果證明該模型也可以聚焦于此類對象。
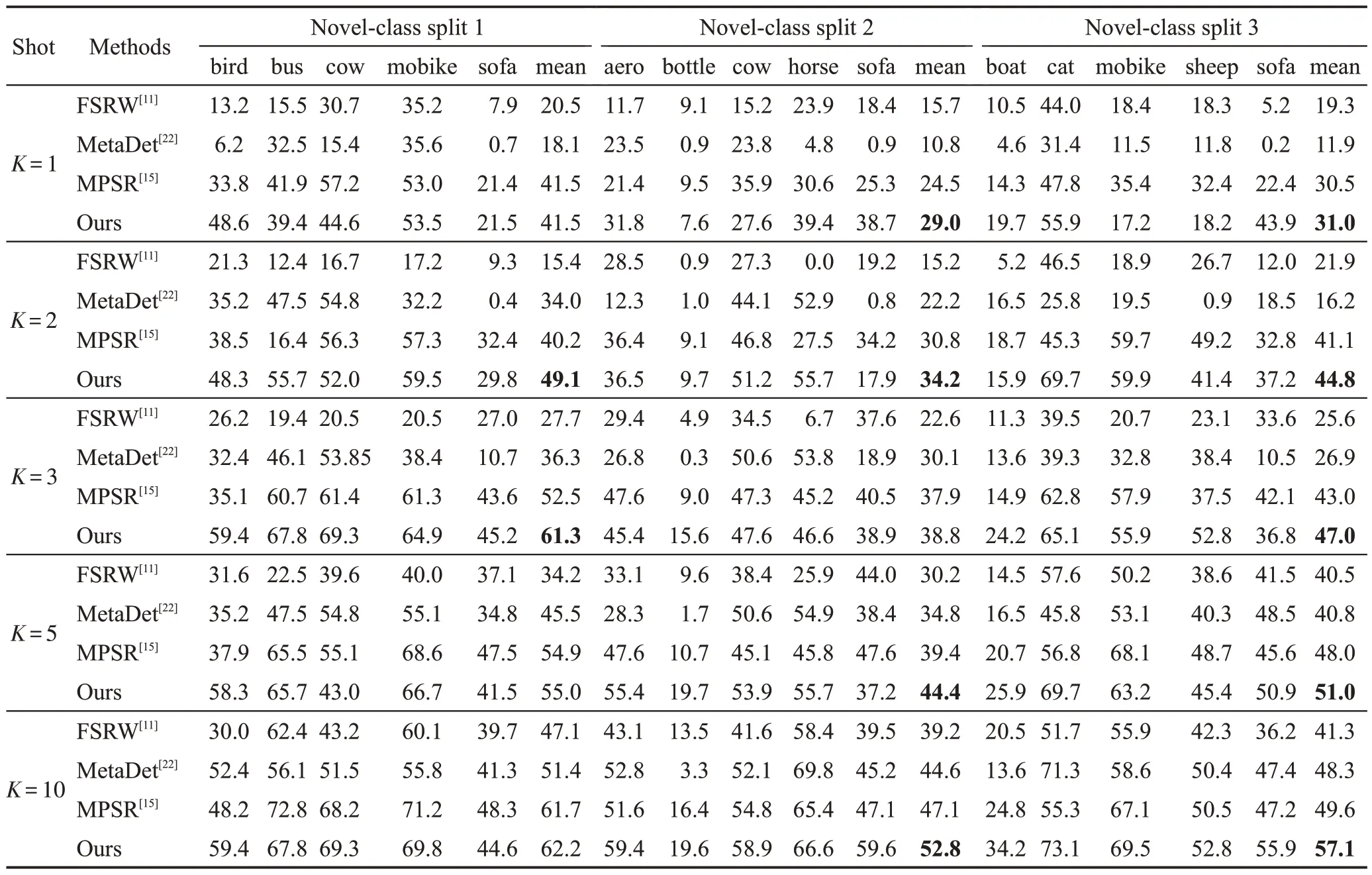
表2 VOC07測試集上的AP 和mAPTable 2 AP and mAP on VOC07 test suite %
如圖6 所示,分別是表2 中不同的平均精度,最后一圖是各方法的平均精度。本文方法在各類值上均有優勢,換句話說,模型能夠在適當關注圖像中的每個對象的同時學習對象的鑒別特征。
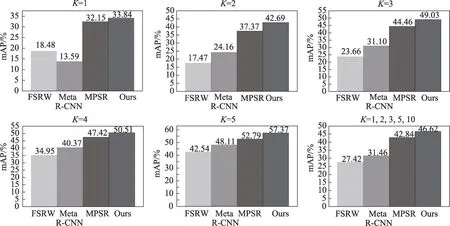
圖6 在不同K 下的平均精度Fig. 6 Average accuracy under different K
2.4 COCO實驗
COCO2014 包含80 個類別,其中20 個類別與VOC07中的類別相同。與VOC實驗類似,使用60個與VOC 不相交的類別作為訓練的基類,20 個作為新類。每個類都有個帶標簽的對象實例,分別取10 和50。評價指標包括、、和、、。其中是指IoU 的平均精度,學習率保持為0.05,指的是的平均精度,指的是的平均精度。指的是圖像中小于32×32的物體的平均檢測精度,指的是圖像中大于32×32,小于96×96 的物體的平均檢測精度,是指圖像中大于96×96 的物體的平均檢測精度。結果記錄于表3中。
從表3 中可以看出,在10-shot 中本文方法在和上達到最優15.9%和28.4%,在其他評估指標下該方法也能達到較好水平。在30-shot 中,能達到32.9%。
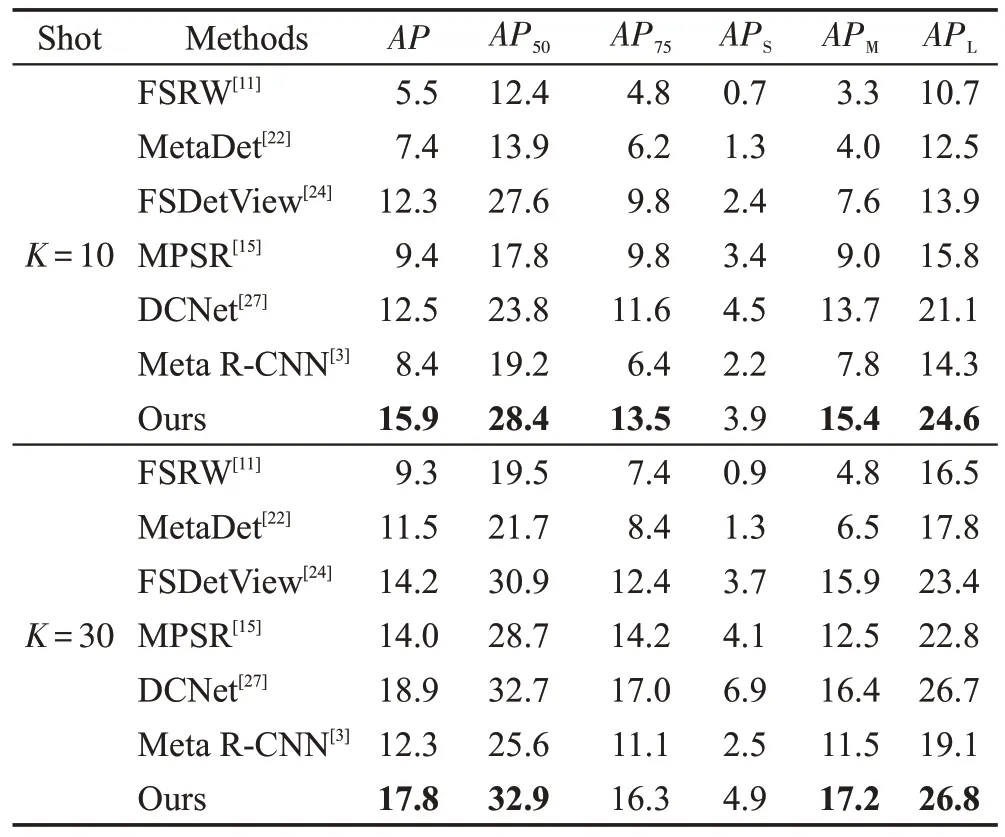
表3 COCO2014測試集上的AP 和mAPTable 3 AP and mAP on COCO2014 test suite %
2.5 混合實驗
最后,進行COCO 到VOC 的跨數據集驗證。使用COCO 中與VOC 不相交的60 個類別作為源域數據訓練,在VOC07 測試集上進行測試。本文實驗的訓練參數設置與之前的相同,在評估實驗中設置了每個類包含10 個實例,即=10。結果繪制在圖7中。如圖7 所示,在=10 時本文模型比Meta R-CNN 平均精度高7.36 個百分點,證明所提方法確實可以提高小樣本的檢測精度。
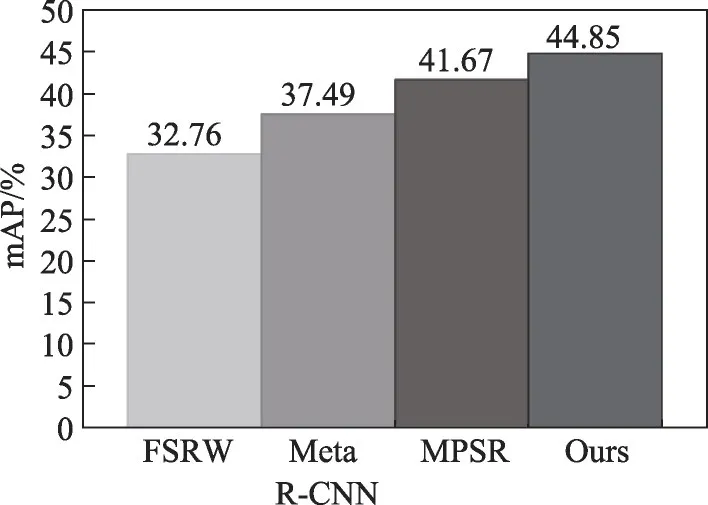
圖7 混合平均精度對比Fig. 7 Comparison of mixed average accuracy
2.6 消融實驗
針對VOC07 數據集,分析了各個組件對模型性能的貢獻,并分析了這些組件產生效果的具體原因。在本節中,通過逐步應用這些模塊來分析提出方法中每個模塊的效果。在VOC07 split 1數據集上評估各個模塊的貢獻,并在表4中記錄。

表4 不同模塊在VOC07測試集上的low-shot檢測mAPTable 4 Low-shot detection mAP of different modules on VOC07 test suite %
從表4 中可以看出,特征尺度增強模塊(FSE)使網絡能夠聚焦于特定尺度的物體,而不是廣闊的背景,有效提高了檢測性能。特征尺度選擇模塊(FSS)可以將那些合適的特征從深層傳遞到淺層用以幫助檢測。多元特征融合模塊的加入對檢測性能影響較大,最大池化和平均池化的特征來挖掘特征相關性,同時保留特征細節和紋理以增強顯著特征,可以在視覺信息缺乏的情況下盡可能多地保留住重要特征。隨著可學習信息數量的增加(增大),簡單的網絡構造模塊不足以對每個樣本進行深度挖掘和特征引導,因此獲得的性能增益不高。特征減法濾除一些特征中的雜波,增加新類參數的敏感性,對性能有較小的提升。正交映射損失減輕了類間和類內特征的混淆,對性能有較好的增益,特別是當增大,信息混淆的減少幫助會更大。圖8 對比了部分圖片的測試結果。

圖8 部分測試結果對比Fig. 8 Comparison of partial test results
2.7 參數分析
在實驗中具體評估了正交損失對模型性能影響。從表4中第6、7行可知,在使用正交損失后對應={1,2,3,5,10} 的模型性能分別提升了1.4 個百分點、3.5 個百分點、3.8 個百分點、3.3 個百分點、6.5 個百分點。多元特征融合在整體性能提升中發揮了很大的作用,但是隨著標簽樣本的增加(的增大),特征相關性構建模塊帶來的性能增益降低。主要因為特征的類間和類內混淆導致了標簽樣本增加而性能增益并不明顯,這也是一個固有的問題,而該損失函數可以緩解這種情況。此外,針對正交損失中使用的兩個超參數進行了參數分析,具體將分別取0.1、0.5、0.9,分別取0.1、0.4、0.9、1.8,組成參數組=(,),在VOC split 1上的分析結果如圖9 所示。可以看出當=(0.5,0.9)時mAP最大。
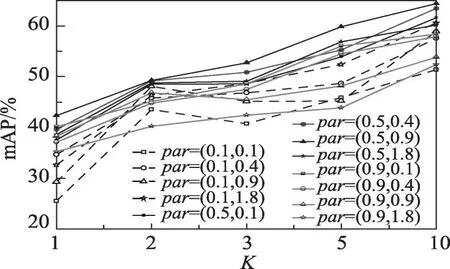
圖9 正交損失不同參數的mAP對比圖Fig. 9 mAP of different parameters of orthogonal loss
3 結束語
為進一步提高小樣本的檢測效果,提出了一種多尺度選擇金字塔網絡的小樣本目標檢測方法。跟以往通過簡單的特征提取從幾個樣本中學習特征的方法不同,在特征提取的過程中,使用尺度選擇金字塔網絡對特征進行有效篩選,其次采用最大最小池化分別進行特征處理,再對特征進行融合,最大限度地保留小樣本信息。另外,考慮無效特征和參數敏感性對檢測效果的影響,采用特征減法,使用Sigmoid函數作為濾波器的融合方法。除此之外,結合了正交損失對特征進一步約束避免分類器產生混淆,提高新類的檢測性能。在實驗中,通過對兩個基準數據集的綜合評估,所提出的方法與基準方法相比有更好的性能。經過消融實驗,可以發現多元特征融合在少量標注信息時對檢測性能提升最大。樣本數增多,基準方法穩定在一個較低的水平,特征減法和正交損失的加入,新類的檢測性能提升明顯。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
