基于全景視覺圖像的實(shí)時(shí)目標(biāo)檢測(cè)方法
2022-07-21 04:12:14黃天果沈慶陽
計(jì)算機(jī)工程與設(shè)計(jì) 2022年7期
黃天果,何 嘉,沈慶陽
(成都信息工程大學(xué) 計(jì)算機(jī)學(xué)院,四川 成都 610225)
0 引 言
隨著虛擬現(xiàn)實(shí)(virtual reality,VR)技術(shù)的飛速發(fā)展與廣泛應(yīng)用,360°全景視覺圖像的應(yīng)用也隨之增加。360°全景視覺圖像由于其對(duì)周圍環(huán)境無死角的全感知能力在無人駕駛領(lǐng)域中發(fā)揮越來越重要的作用。
基于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)的目標(biāo)檢測(cè)方法現(xiàn)已成為目標(biāo)檢測(cè)領(lǐng)域的主流方法。根據(jù)訓(xùn)練方式的不同,當(dāng)前目標(biāo)檢測(cè)方法主要分為基于區(qū)域候選框提取的雙階段方法和能實(shí)現(xiàn)端到端訓(xùn)練的單階段方法,其中雙階段方法以R-CNN[1]系列為主,通過提取候選框后加以訓(xùn)練實(shí)現(xiàn)高精度目標(biāo)檢測(cè)。但隨著實(shí)際應(yīng)用的深入以及對(duì)實(shí)時(shí)要求的提高,R-CNN系列方法很難用于無人駕駛等對(duì)實(shí)時(shí)性要求較高的領(lǐng)域,而端到端的單階段方法[2]的出現(xiàn)改變了這一情況,在可接受的范圍內(nèi)降低精確度而大幅提高檢測(cè)速度,使得單階段方法更受工業(yè)界歡迎。
通過實(shí)驗(yàn)可以驗(yàn)證,不同圖像輸入大小對(duì)基于全景視覺下的目標(biāo)檢測(cè)結(jié)果造成很大影響,采用高分辨率全景圖像能有效提高檢測(cè)精確度,但檢測(cè)速度較慢;目前基于道路場(chǎng)景下的全景目標(biāo)檢測(cè)數(shù)據(jù)集很少,導(dǎo)致訓(xùn)練缺乏足夠的樣本數(shù),對(duì)檢測(cè)精確度造成影響;針對(duì)原YOLO[2]作者Redmon提出的最新目標(biāo)檢測(cè)方法YOLOv3[3],改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu)使其在可接受范圍內(nèi)降低精確度并有效提高高分辨率全景圖像檢測(cè)速度。
1 相關(guān)工作
從三維的球面圖像變換到二維平面圖像的過程被稱為投影,根據(jù)球面不同位置的顯示需要,投影方式可以分為圓柱投影、圓錐投影和方位投影。在全景視覺圖像中等距柱狀投影(equirectangular projection,ERP)是最常用的投影格式。ERP投影方式屬于圓柱投影,由于其投影方式簡(jiǎn)單,導(dǎo)致圖像在南北極區(qū)周圍造成畸變,給目標(biāo)檢測(cè)帶來挑戰(zhàn)。但在無人駕駛領(lǐng)域,目標(biāo)檢測(cè)對(duì)物體的識(shí)別主要來自于水平方向目標(biāo)的檢測(cè),所以采用ERP投影是最好的方式。其次由于ERP全景視覺圖像的成像方式,決定了全景圖像中目標(biāo)對(duì)象的大小與其所在圖像中位置有關(guān),不同位置對(duì)目標(biāo)大小的縮放與畸變程度造成影響,從而導(dǎo)致低分辨率下圖像中目標(biāo)的有效像素相對(duì)更少,提高目標(biāo)檢測(cè)的難度。
目標(biāo)檢測(cè)模型訓(xùn)練過程中,在數(shù)據(jù)集不足情況下為避免出現(xiàn)過擬合,進(jìn)行數(shù)據(jù)增強(qiáng)是非常有必要的。針對(duì)低分辨率數(shù)據(jù)集如經(jīng)典目標(biāo)檢測(cè)數(shù)據(jù)集Pascal VOC(the pascal visual object classes challenge),數(shù)據(jù)增強(qiáng)方法包括水平翻轉(zhuǎn)、圖像旋轉(zhuǎn)、隨機(jī)剪裁、平移變換、尺度縮放、顏色擾動(dòng)以及添加噪聲等[4],文獻(xiàn)[5]中提出馬賽克數(shù)據(jù)增強(qiáng)方法選擇4張不同圖片經(jīng)隨機(jī)縮放和剪裁等操作后拼成一張圖片作為訓(xùn)練輸入獲得4個(gè)不同的上下文混合特征,顯著減少對(duì)大批量數(shù)據(jù)的需求。當(dāng)采用高分辨率(512×1024)的全景圖片作為輸入,對(duì)于以608×608為最高輸入大小的YOLOv3來說,簡(jiǎn)單地將圖片進(jìn)行縮放翻轉(zhuǎn)或多張圖結(jié)合并不能使存在畸變的全景圖像目標(biāo)對(duì)象特征得到增強(qiáng)。本文針對(duì)全景ERP圖像成像原理,提出全景數(shù)據(jù)增強(qiáng)方法能有效增加目標(biāo)對(duì)象畸變特征,增加模型對(duì)不同程度畸變的泛化能力并提高模型檢測(cè)結(jié)果。

本文基于MobileNet[10]網(wǎng)絡(luò)結(jié)構(gòu)思想為單階段檢測(cè)模型YOLOv3框架引入深度可分離卷積結(jié)構(gòu)來構(gòu)建主干網(wǎng)絡(luò),針對(duì)全景圖像成像特點(diǎn)改進(jìn)YOLOv3網(wǎng)絡(luò)。新的網(wǎng)絡(luò)結(jié)構(gòu)相對(duì)原始YOLOv3網(wǎng)絡(luò)在參數(shù)量上減少65.08%。實(shí)驗(yàn)數(shù)據(jù)采用全景數(shù)據(jù)集OSV(omnidirectional street-view)[6]。為了解決全景數(shù)據(jù)集不足的問題,本文提出針對(duì)全景圖像的數(shù)據(jù)增強(qiáng)方法,對(duì)原始數(shù)據(jù)集擴(kuò)充一倍訓(xùn)練樣本量。實(shí)驗(yàn)結(jié)果表明,擴(kuò)充后的訓(xùn)練數(shù)據(jù)集訓(xùn)練模型在交并比(intersection over union,IOU)為0.5的條件下評(píng)估的模型平均精確度(mean average precision,mAP)相比原始訓(xùn)練數(shù)據(jù)集訓(xùn)練模型提高4.75%。
2 方法分析
2.1 全景數(shù)據(jù)集增強(qiáng)方法
在全景視覺圖像中,采用的全景相機(jī)通常會(huì)有多個(gè)攝像頭分布在相機(jī)周圍,采集后的多個(gè)圖像采用圖像拼接成一個(gè)球面后以各種投影格式存儲(chǔ)成二維圖像,主要有立方體投影、圓形投影、小行星投影和球面投影等。其中球面投影即ERP格式投影圖像,如圖1所示。

圖1 ERP格式全景模版
通過將ERP格式全景圖重新投影到球面上,使球面在三維笛卡爾坐標(biāo)系下隨機(jī)旋轉(zhuǎn),再投影到二維平面,獲取旋轉(zhuǎn)變換后點(diǎn)的位置對(duì)應(yīng)旋轉(zhuǎn)前位置的像素點(diǎn),實(shí)現(xiàn)圖像變換。以此能有效增加圖像中目標(biāo)對(duì)象的畸變特征,使目標(biāo)對(duì)象畸變多樣化,針對(duì)全景圖像增加訓(xùn)練樣本。數(shù)據(jù)增強(qiáng)方法過程如下:
首先需要將二維平面上ERP格式圖像上各像素點(diǎn)在位置上進(jìn)行歸一化,將圖像像素點(diǎn)信息從平面直角坐標(biāo)系轉(zhuǎn)化到空間極坐標(biāo)系,其過程可以表示為
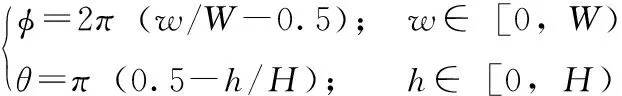
(1)
其中,W表示原始ERP圖像寬度,H表示原始ERP圖像高度;φ為原點(diǎn)到球面上點(diǎn)的射線與X軸形成的角度,θ為原點(diǎn)到球面上點(diǎn)的射線與Y軸形成的角度。文本設(shè)球面為半徑置1的單位球,用以簡(jiǎn)化位置計(jì)算量。將圖像像素信息從平面直角坐標(biāo)系轉(zhuǎn)換到空間極坐標(biāo)系后需要再轉(zhuǎn)換到空間直角坐標(biāo)系,從而實(shí)現(xiàn)球面在空間的旋轉(zhuǎn)操作。其過程表示為

(2)
其中,X、Y、Z分別對(duì)應(yīng)空間直角坐標(biāo)系下的X軸、Y軸和Z軸,通過空間矩陣變換可以實(shí)現(xiàn)球面在空間的旋轉(zhuǎn),對(duì)空間直角坐標(biāo)系下的各點(diǎn)進(jìn)行矩陣變換,其變換矩陣表示為
(3)
(4)
(5)
其中,Rx、Ry、Rz分別表示在空間直角坐標(biāo)系中一點(diǎn)繞X、Y、Z軸旋轉(zhuǎn)的變換矩陣,rx、ry、rz分別表示繞X、Y、Z軸旋轉(zhuǎn)度數(shù)(單位:弧度)。
實(shí)驗(yàn)結(jié)果表明,ERP格式下全景圖像在空間中進(jìn)行繞軸旋轉(zhuǎn),其中,針對(duì)Z軸進(jìn)行繞軸旋轉(zhuǎn)表現(xiàn)在平面ERP格式圖像中是圖像左右平移,對(duì)于平移的ERP圖像,其畸變信息并不會(huì)隨平移量的增加減少產(chǎn)生變化,所以針對(duì)繞Z軸旋轉(zhuǎn)的旋轉(zhuǎn)度數(shù)rz可以是任意度數(shù) ([-2π,2π]); 針對(duì)X軸的繞軸旋轉(zhuǎn)表現(xiàn)為左右兩模塊的順逆時(shí)針旋轉(zhuǎn),引發(fā)前后模塊上下移動(dòng)并伴隨畸變程度增加;針對(duì)Y軸的繞軸旋轉(zhuǎn)表現(xiàn)為前后模塊的順逆旋轉(zhuǎn),引發(fā)左右模塊上下移動(dòng)并伴隨畸變程度增加。
針對(duì)畸變程度,本文指定繞X軸、Y軸旋轉(zhuǎn)度數(shù)控制在 [-π/12,π/12] (其中負(fù)號(hào)表示反方向旋轉(zhuǎn)),其原因?yàn)檫^大旋轉(zhuǎn)度數(shù)對(duì)于繞X軸和Y軸會(huì)使圖像產(chǎn)生不可逆轉(zhuǎn)的畸變程度,直接導(dǎo)致圖像中目標(biāo)對(duì)象失去真實(shí)性從而降低檢測(cè)模型性能。實(shí)驗(yàn)結(jié)果表明旋轉(zhuǎn)度數(shù)控制在 [-π/12,π/12] 能有效避免圖像產(chǎn)生過大的畸變影響檢測(cè)效果。
定義空間中一個(gè)點(diǎn)坐標(biāo)為
[XijYijZij];i∈[0,H),j∈[0,W)
(6)
設(shè)該點(diǎn)繞X、Y、Z軸旋轉(zhuǎn)弧度分別為rx、ry、rz, 旋轉(zhuǎn)后的點(diǎn)表示為
(7)
經(jīng)過空間旋轉(zhuǎn)操作后,空間直角坐標(biāo)系下的像素信息需要重新投影到平面上,其過程為式(1)、式(2)的逆過程,具體操作如下:首先將旋轉(zhuǎn)后的空間直角坐標(biāo)點(diǎn)重新轉(zhuǎn)換到空間極坐標(biāo)系,其過程表示為
(8)
最后將空間極坐標(biāo)轉(zhuǎn)為平面坐標(biāo),其過程表現(xiàn)為
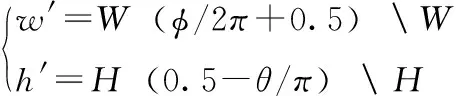
(9)
其中,“”表示對(duì)W和H取余。
到此完成對(duì)ERP圖像的旋轉(zhuǎn)投影工作。如圖2所示,將平面ERP圖像上點(diǎn)在空間坐標(biāo)系下繞X軸旋轉(zhuǎn)π/12,繞Y軸旋轉(zhuǎn)π/12,繞Z軸旋轉(zhuǎn)π/4后再投影的結(jié)果。

圖2 ERP旋轉(zhuǎn)投影展示
由圖2可以看出,在進(jìn)行ERP圖像旋轉(zhuǎn)投影之后,相比于圖1圖像整體信息發(fā)生改變,針對(duì)Z軸旋轉(zhuǎn)實(shí)現(xiàn)圖像左右平移使原本在正前方的模塊移動(dòng)到右邊,針對(duì)X軸和Y軸的旋轉(zhuǎn)實(shí)現(xiàn)不同模塊的旋轉(zhuǎn)。其中也能看出上下模塊畸變程度增加最為強(qiáng)烈,但由于全景視覺在實(shí)時(shí)目標(biāo)檢測(cè)中的應(yīng)用并不關(guān)注上下模塊,使得其變化對(duì)檢測(cè)的影響不大。
2.2 目標(biāo)檢測(cè)已有方法分析
單階段目標(biāo)檢測(cè)方法采用端到端的訓(xùn)練方式,其檢測(cè)流程通常為:首先輸入一定尺寸的圖片,然后通過主干網(wǎng)絡(luò)(backbone)提取深度特征,將提取的特征輸入頸部網(wǎng)絡(luò)(neck)進(jìn)行特征融合等操作使網(wǎng)絡(luò)更好地適應(yīng)特征,最后通過頭部網(wǎng)絡(luò)(head)進(jìn)行分類回歸獲取目標(biāo)對(duì)象。其優(yōu)勢(shì)表現(xiàn)在端到端訓(xùn)練網(wǎng)絡(luò)模型在檢測(cè)速度時(shí)更快,相比于雙階段目標(biāo)檢測(cè)方法,單階段目標(biāo)檢測(cè)方法省去了提取候選框的步驟引入錨框的概念,實(shí)現(xiàn)直接分類回歸節(jié)省大量時(shí)間,但同時(shí)也降低了檢測(cè)精度。
在YOLOv3原文中,作者定義網(wǎng)絡(luò)輸入大小最小為416×416,最大為608×608。由于采用Darknet53[3]作為主干網(wǎng)絡(luò),從3個(gè)尺度提取特征分別是/8(縮小8倍),/16,/32,所以圖像輸入需要滿足32的倍數(shù)。在Darknet53中,主要采用的組件是殘差網(wǎng)絡(luò)[3],其結(jié)構(gòu)如圖3所示。

圖3 殘差網(wǎng)絡(luò)結(jié)構(gòu)
通過主干網(wǎng)絡(luò)提取3個(gè)尺度下的特征分別對(duì)應(yīng)3種不同大小的目標(biāo)對(duì)象,在YOLOv3頭部結(jié)構(gòu)中輸出最小的特征(/32)會(huì)通過上采樣與大尺度特征進(jìn)行特征融合最后實(shí)現(xiàn)融合后的多尺度輸出。通過YOLOv3結(jié)構(gòu)輸出的特征在與預(yù)定義錨框(anchor-box)結(jié)合訓(xùn)練時(shí)需要首先進(jìn)行解碼操作:將不同尺度目標(biāo)特征與對(duì)應(yīng)縮小倍數(shù)(stride)相乘;對(duì)置信度和預(yù)測(cè)類別進(jìn)行Sigmoid操作使其控制在[0,1]。
2.3 YOLOv3網(wǎng)絡(luò)輕量化
通過對(duì)原始YOLOv3網(wǎng)絡(luò)的分析與實(shí)驗(yàn)可知,在高分辨率全景圖像輸入情況下,圖像檢測(cè)耗時(shí)主要在網(wǎng)絡(luò)計(jì)算和解碼操作上。針對(duì)耗時(shí)原因,采取以下方式實(shí)現(xiàn)實(shí)時(shí)檢測(cè)。
2.3.1 基于深度可分離卷積神經(jīng)思想的主干網(wǎng)絡(luò)
深度可分離卷積神經(jīng)網(wǎng)絡(luò)經(jīng)過實(shí)驗(yàn)驗(yàn)證[11]可以在更少的參數(shù)量實(shí)現(xiàn)同等卷積效果,其運(yùn)算過程可以表示為
(10)
其中,βi表示網(wǎng)絡(luò)第i層的輸入特征圖;ξin表示第i層特征圖的第n個(gè)通道;k表示卷積核;通過D(·) 操作實(shí)現(xiàn)深度可分離卷積操作中逐通道卷積操作,與常規(guī)卷積操作中輸入層中各個(gè)通道都需要與每個(gè)卷積核對(duì)應(yīng)通道進(jìn)行卷積不同,逐通道卷積中卷積核通道數(shù)不是輸出通道數(shù),而是采用輸入通道數(shù),通過對(duì)應(yīng)通道卷積實(shí)現(xiàn)深度可分離卷積的第一次卷積操作;S(·) 是將逐通道操作的輸出進(jìn)行逐點(diǎn)卷積操作,其過程為通過輸出通道個(gè)數(shù)的1×1大小卷積核與當(dāng)前輸入特征圖進(jìn)行常規(guī)卷積操作,從而實(shí)現(xiàn)卷積計(jì)算量的大幅下降。τ為D(·) 操作的輸出表示第i層特征在經(jīng)過逐通道卷積后的狀態(tài),并作為S(·) 操作的輸入。最終輸出βi+1表示第i+1層的輸入。
假設(shè)輸入特征圖通道數(shù)為n, 卷積核大小為k×k, 輸出通道數(shù)為m, 相比于常規(guī)卷積操作,深度可分離卷積參數(shù)量減少1-1/m-1/k2。 基于以上分析,采用深度可分離卷積替換Darknet53殘差網(wǎng)絡(luò)中的兩次常規(guī)卷積操作能有效減少網(wǎng)絡(luò)參數(shù)量,本文稱其為深度可分離特征融合塊(depth separability feature fusion block,DSFF_Block)。
2.3.2 針對(duì)解碼耗時(shí)問題改進(jìn)頭部網(wǎng)絡(luò)
通過Darknet53主干網(wǎng)絡(luò)會(huì)輸出3種尺度(/8,/16,/32)的特征圖,在YOLOv3頭部網(wǎng)絡(luò)中,將最小尺度(/32)的特征圖直接進(jìn)行分類回歸,并對(duì)其上采樣與中型尺度(/16)結(jié)合進(jìn)行輸出,同理上采樣與最大尺度(/8)結(jié)合作為最大尺度輸出。在YOLOv3中作者沒有加入全連接層(fully connected layer,F(xiàn)C),而是分別對(duì)3種尺寸特征圖解碼到標(biāo)簽格式,以供訓(xùn)練。
針對(duì)3種尺寸的解碼會(huì)造成大量計(jì)算,而根據(jù)高分辨率全景圖像目標(biāo)對(duì)象分布情況,本文取消頭部網(wǎng)絡(luò)中中尺度特征圖(/16)的輸出,改進(jìn)為將其進(jìn)行向上向下采樣并分別與最大尺度和最小尺度結(jié)合的方式實(shí)現(xiàn)特征融合。改進(jìn)后的網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
訓(xùn)練圖像在輸入模型后,會(huì)首先經(jīng)過一個(gè)32×3×3的卷積操作主要是為提取圖像特征進(jìn)行圖像通道數(shù)預(yù)擴(kuò)大。之后連續(xù)經(jīng)過5次DSFF_Block,每一個(gè)DSFF_Block都有不同大小的特征圖輸出(經(jīng)過不同個(gè)數(shù)卷積核進(jìn)行卷積操作,如圖4中64,128分別表示經(jīng)過64×3×3和128×3×3的卷積操作)和不同的循環(huán)次數(shù)(如圖4中1×,2×,4×分別表示進(jìn)行1、2、4次循環(huán)),且每一個(gè)DSFF_Block循環(huán)塊在進(jìn)行循環(huán)前包含一次下采樣操作,每執(zhí)行一次DSFF_Block操作對(duì)其輸出進(jìn)行一次非線性運(yùn)算:表現(xiàn)為批量歸一化和線性修正單元(rectufied lear unit,ReLU)的組合。

圖4 改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu)
經(jīng)過主干網(wǎng)絡(luò)輸出3種尺度的特征圖,在頸部網(wǎng)絡(luò)中通過上下采樣實(shí)現(xiàn)多維特征融合,最后網(wǎng)絡(luò)輸出為兩種尺寸的多維向量,再經(jīng)過解碼操作后,網(wǎng)絡(luò)輸出為向量
(batch_size,r_h,r_w,3,num_class+5)
(11)
其中,batch_size表示批處理數(shù),即單次向模型輸入圖像的數(shù)量;r_h和r_w表示兩種尺度的特征圖;3表示3種預(yù)定義的anchor-box;num_class表示目標(biāo)種類個(gè)數(shù),采用one-hot編碼表示;5表示預(yù)測(cè)框信息(中心點(diǎn)位置以及寬高)和置信度。
3 實(shí) 驗(yàn)
本文進(jìn)行了3個(gè)實(shí)驗(yàn):實(shí)驗(yàn)一針對(duì)原始YOLOv3采用不同分辨率全景圖像作為輸入,考察不同分辨率輸入對(duì)模型檢測(cè)精度和速度的影響;實(shí)驗(yàn)二驗(yàn)證擴(kuò)充數(shù)據(jù)集的有效性;實(shí)驗(yàn)三量化改進(jìn)網(wǎng)絡(luò)結(jié)構(gòu)后模型的性能。
3.1 損失函數(shù)及訓(xùn)練超參數(shù)
網(wǎng)絡(luò)訓(xùn)練損失函數(shù)采用多目標(biāo)函數(shù)衡量,分別是目標(biāo)框回歸損失函數(shù)、類別損失函數(shù)以及置信度損失函數(shù)。其中目標(biāo)框回歸損失采用CIoU[12]指導(dǎo)損失,類別損失函數(shù)采用原始Sigmoid交叉熵?fù)p失函數(shù),并采用Focal Loss[13]指導(dǎo)置信度損失。
在訓(xùn)練過程中,由于圖像大小輸入分辨率高,batch_size設(shè)置為8,Epoch為100;對(duì)于多世代(epoch)的深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練,學(xué)習(xí)率(learning rate,LR)直接影響網(wǎng)絡(luò)損失收斂方向,也對(duì)有網(wǎng)絡(luò)收斂速度造成影響,通常學(xué)習(xí)率調(diào)整策略包括在訓(xùn)練中微調(diào)、隨迭代次數(shù)增加的線性變化以及周期性變化等。本實(shí)驗(yàn)通過設(shè)置動(dòng)態(tài)學(xué)習(xí)率實(shí)現(xiàn)學(xué)習(xí)率隨迭代次數(shù)增加的非線性變化,其過程可以表示為
(12)
(13)
其中,Lx表示最大學(xué)習(xí)率設(shè)為10-4,Ls表示最小學(xué)習(xí)率設(shè)為10-6;i為訓(xùn)練到第幾個(gè)Epoch;G為訓(xùn)練樣本總數(shù);E為預(yù)熱階段Epoch數(shù);由此,學(xué)習(xí)率在第U步達(dá)到最大值;T為總的訓(xùn)練步數(shù),在達(dá)到最大值后以非線性曲線下降,在最后一個(gè)Epoch達(dá)到最低值。
3.2 不同分辨率輸入對(duì)模型的影響
本實(shí)驗(yàn)中算法模型采用YOLOv3進(jìn)行實(shí)驗(yàn)主要驗(yàn)證不同分辨率圖像作為輸入時(shí)對(duì)模型檢測(cè)精度和速度的影響。在原始YOLOv3中作者采用416×416作為圖像輸入大小,針對(duì)全景圖像目標(biāo)對(duì)象大小與原圖像比例的關(guān)系,本實(shí)驗(yàn)最小輸入采用608×608,再分別使用1024×1024,512×1024作為輸入大小進(jìn)行驗(yàn)證。實(shí)驗(yàn)結(jié)果見表1。

表1 不同分辨率輸入大小在YOLOv3上測(cè)試結(jié)果
由表1數(shù)據(jù)可知,相對(duì)于608×608輸入大小,1024×1024輸入大小在mAP上提高了31.68%,但在檢測(cè)速度上,每秒幀數(shù)下降47.5%,由此可以得出結(jié)論,由于深度神經(jīng)網(wǎng)絡(luò)多次卷積操作提取特征造成感受野的固定化,高分辨率全景圖像輸入能提取更大的感受野使得檢測(cè)精度提高,同時(shí)需要更多的計(jì)算造成檢測(cè)速度下降。通過將512×1024作為輸入和1024×1024輸入進(jìn)行比較可以看出,盡管在檢測(cè)精度上只有較小的下降,但仍無法滿足實(shí)時(shí)檢測(cè)的要求(通常認(rèn)為20 FPS以上基本滿足實(shí)時(shí))。
3.3 針對(duì)全景數(shù)據(jù)集的數(shù)據(jù)增強(qiáng)方法的有效性驗(yàn)證
由表2數(shù)據(jù)顯示,擴(kuò)充后的數(shù)據(jù)集相比原數(shù)據(jù)集對(duì)基于全景圖像的目標(biāo)檢測(cè)平均精確度有積極作用,在采用YOLOv3和MobileNet作為檢測(cè)方法進(jìn)行訓(xùn)練的模型在檢測(cè)精度上分別提高了4.75%和7.49%,驗(yàn)證了全景數(shù)據(jù)集數(shù)據(jù)增強(qiáng)方法能有效提高全景視覺圖像目標(biāo)對(duì)象的畸變特征,增強(qiáng)模型對(duì)畸變檢測(cè)的泛化能力。

表2 全景圖像數(shù)據(jù)集數(shù)據(jù)增強(qiáng)方法有效性測(cè)試結(jié)果
3.4 YOLOv3輕量化網(wǎng)絡(luò)模型性能測(cè)試
本實(shí)驗(yàn)驗(yàn)證所提出的輕量化YOLOv3結(jié)構(gòu)能有效提升高分辨率全景圖像輸入下目標(biāo)檢測(cè)速度。與經(jīng)典雙階段目標(biāo)檢測(cè)方法Faster R-CNN[7]以及各種單階段目標(biāo)檢測(cè)方法包括SSD[15]、YOLOv3以及輕量化模型MobileNetv3進(jìn)行比較,實(shí)驗(yàn)采用512×1024作為圖像輸入大小,采用擴(kuò)充的全景數(shù)據(jù)集(OSV-EX)作為實(shí)驗(yàn)數(shù)據(jù)集,實(shí)驗(yàn)結(jié)果見表3。

表3 針對(duì)全景目標(biāo)檢測(cè)的YOLOv3輕量化 網(wǎng)絡(luò)結(jié)構(gòu)測(cè)試結(jié)果
由表3數(shù)據(jù)顯示,F(xiàn)aster R-CNN作為R-CNN系列雙階段目標(biāo)檢測(cè)算法,也是第一次通過RPN網(wǎng)絡(luò)引入Anchor概念,其在全景圖像中的檢測(cè)精確度上達(dá)到最高的88.81%,但檢測(cè)速度只有1.81 FPS,驗(yàn)證雙階段目標(biāo)檢測(cè)算法在實(shí)時(shí)檢測(cè)性能上的不足;而端到端訓(xùn)練的SSD方法在高分辨率的全景圖像輸入下也難以達(dá)到實(shí)時(shí)檢測(cè)。相比YOLOv3目標(biāo)檢測(cè)方法,本文提出的輕量化網(wǎng)絡(luò)結(jié)構(gòu)在網(wǎng)絡(luò)參數(shù)量上減少了65.08%,在可接受范圍內(nèi)下降一定檢測(cè)精度(3.08%),模型檢測(cè)速度提升31.81%,達(dá)到25.03 FPS,實(shí)現(xiàn)實(shí)時(shí)檢測(cè)。作為對(duì)照實(shí)驗(yàn),MobileNetv3盡管在檢測(cè)速度上達(dá)到23.64 FPS,但檢測(cè)精度相對(duì)較低,不利于實(shí)際應(yīng)用。
4 結(jié)束語
本文針對(duì)全景視覺圖像實(shí)時(shí)目標(biāo)檢測(cè)進(jìn)行相關(guān)研究。首先針對(duì)全景圖像訓(xùn)練數(shù)據(jù)集不足的問題,提出一種適用于全景圖像數(shù)據(jù)增強(qiáng)的方法,該方法能有效增強(qiáng)全景ERP格式圖像中目標(biāo)對(duì)象的畸變特征;基于YOLOv3結(jié)構(gòu)和深度可分離卷積實(shí)現(xiàn)主干網(wǎng)絡(luò)輕量化,同時(shí)對(duì)頭部網(wǎng)絡(luò)進(jìn)行優(yōu)化減少解碼過程計(jì)算量。實(shí)驗(yàn)結(jié)果表明,輕量化的網(wǎng)絡(luò)結(jié)構(gòu)在網(wǎng)絡(luò)參數(shù)量上減少了65.08%,實(shí)現(xiàn)高分辨率(512×1024)全景圖像輸入下的實(shí)時(shí)目標(biāo)檢測(cè)。
本文提出的輕量化網(wǎng)絡(luò)的方法在實(shí)現(xiàn)實(shí)時(shí)檢測(cè)的同時(shí)也造成了檢測(cè)精度的少量下降,主要是由于深度可分離卷積在降低參數(shù)量的同時(shí)對(duì)提取的特征造成壓縮對(duì)檢測(cè)器造成一定影響。在未來的工作中,將研究采用自適應(yīng)剪枝的方式對(duì)網(wǎng)絡(luò)進(jìn)行輕量化,并量化其對(duì)檢測(cè)性能的影響。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
