基于Stacking集成學習的巖性識別研究
2022-08-02 01:44:28曹茂俊鞏維嘉高志勇
計算機技術與發展 2022年7期
曹茂俊,鞏維嘉,高志勇
(東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318)
0 引 言
巖性識別是通過一些特定的方法來認識和區分巖性的過程。在地質學中,地下巖性分類是一項非常有意義的任務,精確地識別巖石的物理特征為地層評價、地質分析提供研究基礎[1]。傳統的巖性識別方法分為直接和間接兩種。直接法是指通過觀測地下巖心來確定巖性,此方法需要較強的專業知識并且不夠準確。間接方法是指通過測井資料建立解釋模型來進行巖性識別。目前,傳統的巖性識別模型已經遇到了瓶頸,存在識別準確率低,速度慢,并且難以解釋測井資料和巖性之間的復雜關系等問題,因此利用測井資料建立準確率較高的巖性識別模型成為當今的一個重點問題。
近年來,機器學習已經被引入到巖性識別問題當中,實現了巖性的自動化識別。張瑩等人[2]使用Byers準則建立了巖性識別分類模型。Shaoqun Dong等人[3]提供了KFD(核Fisher判別分析)進行巖性識別分類。Pan H等人[4]探索了K近鄰分類器識別巖性的性能。
不同巖性具有不同的物理性質,單一的機器學習算法無法全面地識別每種巖性,不能對測井資料進行很好地解釋,而集成學習可以結合各種算法,很好地解決這一弊端。Yunxin Xie[5]、T.S. Bressan[6]和Jian Sun[7]等人,將SVM、MLP和隨機森林算法分別用于巖性識別和地層評價。Vikrant A. Dev[8]在Yunxin xie等人的基礎上,使用LogitBoost算法來區分地層巖性。閆星宇等人[9]使用XGBoost算法進行致密砂巖氣儲層預測。Kaibo Zhou等人[10]將GBDT算法和SMOTE算法結合,應用于巖性識別。基于Stacking的集成算法能有效集成各個基模型的優點,更好地提高模型效果,段友祥[11]、鄒琪[12]等人使用該方法構建巖性識別模型。
集成學習分為同質集成和異質集成,同質集成學習通過組合同一個分類器來構造一個最終模型,因此,在擴大單一分類器優點的同時,缺點也會增加,這對結果是不可取的。然而,異質集成學習能抓住不同巖性識別模型的優點,具有更強的魯棒性和泛化性。它是通過疊加的方式對學習器進行無限疊加,它和同質集成學習除了基模型使用不同的模型之外,組合策略也不同,不是簡單地采用了平均法和投票法,而是使用了元模型方法進行組合。但是傳統的Stacking異質集成存在一定的缺點和不足,即沒有考慮每個基模型的實際預測結果,不同的基模型它們的可信度不同,如果不加以區分,則會影響最終元模型的訓練效果,從而影響整體準確率。
因此,該文將PCA算法融入到模型中,訓練模型的同時,計算并賦予每個基模型相應的權重,以此來提高元模型訓練數據的質量,最終提高模型整體表現。該方法融合了CART決策樹、KNN、多層感知機、SVM和邏輯回歸(LR)五種機器學習方法,利用中國延安氣田某井數據進行巖性識別,結果表明該模型和其他機器學習模型相比效果顯著提升。
1 相關研究基礎
1.1 CART決策樹
CART決策樹是由Breinman等人提出的一種有監督分類算法,它是在給定輸入X的條件下,輸出隨機變量Y的條件概率分布的學習方法,比較適用于離散型變量和連續型變量。對于離散型變量,CART算法生成分類樹。對于連續型變量,CART算法生成回歸樹[13]。該文是通過測井曲線數據對巖性進行分類,因此采用CART分類樹算法。CART決策樹的核心思想是根據學習區域變量和目標變量,對原始數據集以二叉樹的結構形式進行循環分析,構建模型時選用Gini系數作為分類屬性,Gini系數越小,樣本純度越大,分類效果越好。概率分布的Gini系數定義如下:
(1)
其中,K表示類別數量,pk表示樣本點屬于第K類的概率。
1.2 K近鄰算法
K近鄰算法也稱KNN算法,屬于有監督學習分類算法。它的基本思想是,給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最近鄰的M個實例,這M個實例的多數屬于某類,就把該輸入實例分類到這個類下。由此可知,KNN算法在分類決策的過程中有兩個任務:根據K值尋找目標點附近的其他數據點,用這些數據點進行投票表決。算法步驟如下:
訓練數據集T={(X1,Y1),(X2,Y2),…,(XN,YN)},其中Xi為實例的特征向量,Yi={C1,C2,…,Ck}為實例類別。
(1)計算目標點X與訓練集T中其他樣本點的歐氏距離。
(2)選取與實例X最近的k個點,這k個點的鄰域為Nk(X)。
(3)根據少數服從多數投票,讓未知實例歸類為k個最近鄰樣本中最多數的類別。
從上述流程看,KNN算法只有一個超參數K,不同的K值會使算法產生不同的預測結果,如果選取的K值過小,模型容易產生過擬合。如果選取的K值過大,會使得模型的預測誤差減小,模型會變得簡單。因此K值的確定對模型的分類性能有著十分重要的影響。
1.3 邏輯回歸
邏輯回歸(LR)是一種經典的二分類機器學習算法,也可以解決多分類問題,它可以用來估量某個事件發生的概率。邏輯回歸模型的學習包括構造代價函數和模型訓練,構造代價函數使用了統計學中的極大似然估計,而模型訓練的實質就是尋找一組參數,使得代價函數最小化的過程。邏輯回歸算法的主要步驟如下(其中θ指的是回歸參數):
(1)尋找預測函數h(x),邏輯回歸構造的預測函數如下:
(2)
(2)構造損失函數J,其中m代表樣本個數:
(3)
(3)通過梯度下降法使得損失函數最小,并求得回歸參數。
訓練結束得到模型后,將測試數據輸入模型,若預測值大于0.5,則將該測試數據分為正例,否則將該測試數據分為負例。
1.4 多層感知機
多層感知機(MLP),也叫人工神經網絡,是由一系列層、神經元和連接組成的,主要由輸入、輸出、隱藏層三部分組成,是一種高度并行的信息處理系統,能處理復雜的多輸入、多輸出的非線性問題,對于分類問題有很好的處理能力。
除了輸入輸出層之外,中間的隱藏層可以有多層,各個層之間是全連接的,即上層的全部神經元和下層的全部神經元都有連接,其計算過程如下:
(1)輸入層獲得n維向量,即n個神經元。
(2)隱藏層的神經元是由輸入層的輸出得來的,假設輸入層用向量X表示,則隱藏層的輸出表示為f(Wx+b)。
(3)隱藏層通過多類別的邏輯回歸得到輸出層,三層多層感知機的公式如下,其中G是SoftMax函數:
f(x)=G(b(2)+W(2)(s(b(1)+W(1)x)))
(4)
1.5 支持向量機
多分類問題可以通過多個SVM的組合來解決,一對多SVM分類算法在對多個不同樣本分類時,速度較快,它是訓練時依次把某個樣本歸為一類,剩余的歸為一類,構造多個SVM模型[14]。其算法思想如下:
(1)x表示樣本,y表示類別,θ表示支持向量,假設存在一個超平面可以將樣本正確分類則:
(5)
(2)兩種不同類別支持向量到決策邊界距離之和為:
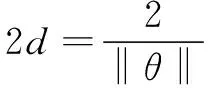
(6)
(3)將最大化間距問題轉換成最小化問題,公式如下:
(7)
2 面向巖性識別的Stacking集成模型設計
2.1 基模型選取
針對測井曲線數據的特征,該文選取了CART決策樹、KNN、MLP、SVM四種基模型來進行構建。基模型的差異性是提高模型整體表現的重要因素之一。因此,為了提高Stacking集成模型的識別效果,該文選取了四種結構差異較大的機器學習模型作為基模型。
其中,CART決策樹算法完全不受數據縮放的影響,每個測井曲線特征能夠被單獨處理,它更容易考慮到每個測井曲線的特征和每個測井曲線對巖性識別的貢獻。但是,該算法非常容易過擬合,而且泛化性能較差。KNN算法可以用于非線性分類,并且該方法主要靠周圍有限的鄰近樣本進行分類,從測井曲線和巖性類別關系的角度來看,該方法有助于巖性劃分。但是,當樣本類別不均衡時,該方法對稀有類別預測準確率低。MLP能夠借助非線性激活函數,學到高階的特征組合,該算法有助于結合不同測井曲線特征,更好地分析測井資料和巖性的關系。但是該算法收斂速度慢,對數據質量要求較高。SVM算法針對高維特征分類具有很好的效果,針對多種測井曲線,該算法對曲線有較好的解釋性。但是對大規模樣本訓練卻難以支持,并且在多分類問題上,它的準確率不是很好。
2.2 基于PCA的基模型權重選取方法
傳統的Stacking集成學習模型沒有考慮到每個基模型在實際數據上的預測結果,每個基模型對樣本數據的預測結果都是要作為元模型的訓練數據,如果直接使用基模型預測的結果作為訓練集,則會影響最終模型的分類效果,導致模型準確率不高。這是因為基模型的訓練數據和算法是不同的,每個基模型為元模型提供的信息具有一定的差異性。因此,每個基模型都應該被賦予一個權重。該文通過PCA算法計算出每個模型的權重,并且將權重融合到每個基模型的輸出特征中,作為元模型的訓練數據。權重的計算步驟如下:
(1)利用PCA算法計算第一層基模型輸出數據的貢獻方差、方差貢獻率和成分矩陣。X、Y表示隨機變量,E表示期望方差,協方差計算公式如下:
Cov[X,Y]=E[(X-E(X))(Y-E(Y))]
(8)
(2)根據成分矩陣C和貢獻方差T求得成分得分系數矩陣K。計算公式如下:
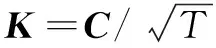
(9)
(3)根據貢獻方差T和成分得分矩陣K,得出權重矩陣W。計算公式如下:
(10)
(4)對權重矩陣W進行歸一化處理,求得最終的權重矩陣。
這種改進方式考慮了基模型的訓練情況,對于準確率高的基分類器賦予較高的權重,從而為元模型提供更多的預測信息,對于準確率低的基模型賦予較低的權重,以此來提高元分類器的訓練效果。
2.3 Stacking集成模型設計
通過集成以上選取的五種模型,構建了一個兩層集成學習模型。第一層選用CART決策樹、KNN、MLP和SVM四種模型作為基模型,第二層選取邏輯回歸作為元模型。由于第一層選用了復雜的非線性變化模型提取特征,這樣容易產生過擬合風險。因此,第二層元模型選擇邏輯回歸廣義線性模型,在第一層模型中取長補短,提升預測準確率。整體模型架構如圖1所示。
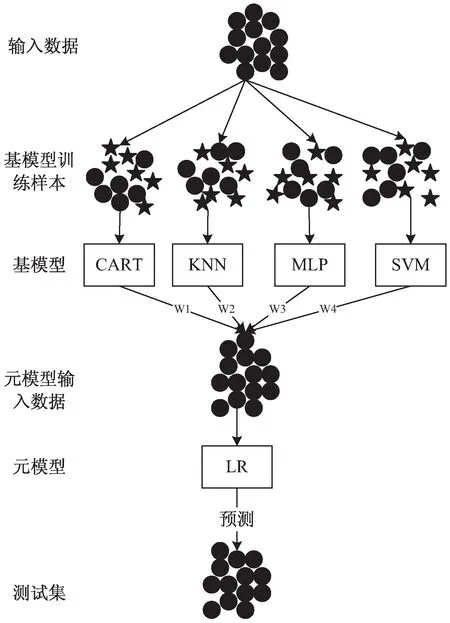
圖1 改進的Stacking集成學習流程
針對相同的數據,該集成模型集成了多種不同的基模型,并且通過PCA算法對基模型進行權重分析,為每個基模型賦予權重,提高了元模型訓練數據的可靠性,每個基模型都有自己的優點和側重,因此具有很好的泛化能力和抗干擾能力。通過改進的Stacking集成算法進行模型融合,使得最終的集成模型具有很好的識別效果,準確率較高。
3 基于Stacking集成模型的巖性識別方法
3.1 數據預處理
3.1.1 數據標準化
首先對數據進行標準化(standardization)處理,本次實驗采用數據標準化(又叫Z-score標準化)。數據標準化是機器學習任務中的一項基本任務,它是數據預處理必不可少的一步。數據預處理是從數據中檢測、糾正或者刪除不適用于模型的記錄的過程。由于各種不同類型的測井數據量綱不同,數值間差異較大,因此需要對原始測井數據進行標準化處理,從而消除測井數據間的差異性,便于模型更好地學習特征。處理后的數據會服從均值為0,方差為1的正態分布。該文采用的數據標準化公式如下:
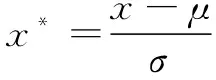
(11)
其中,μ為數據的均值,σ為標準差,當數據x按均值(μ)中心化后,再按標準差(σ)縮放,數據就會服從均值為0,方差為1的正態分布。標準化后的變量值圍繞0上下波動,大于0說明高于平均水平,小于0說明低于平均水平。
3.1.2 相關性分析
相關性分析是指對多個變量進行相關密切程度的衡量,并不是所有的特征都可以進行相關性分析,需要特征之間存在一定的聯系或者概率才可以進行分析,在測井曲線數據中,不同的測井曲線數據之間存在一定的相關性,它們同時反映了一個區域之間地層特征,因此可以進行相關性分析。
在訓練過程中,并不是特征參數越多,模型的識別效果就越好,相反,如果特征參數過多,特征與特征之間就會產生冗余現象,反而不利于提高模型的識別效果。相關性分析指的是對多個具備相關性的變量元素進行分析,得到這些變量因素的相關程度,一組數據特征之間相關性低,則說明特征之間依存關系弱,適合用來進行分析。通過對測井曲線進行Pearson相關性分析,可得各個測井曲線特征它們之間的Pearson相關系數,選擇相關性較弱的特征數據作為訓練特征。
3.1.3 不均衡樣本處理
如圖2所示,不同類別的數據分布嚴重不均衡,如果某個類別數量特別少,模型對其學習效果不佳,則會造成模型對其識別準確率低,影響最終識別效果[15]。針對數據不均衡問題,該文采用了SMOTE算法對數據進行補齊,使得各個樣本的數據量相等。
SMOTE算法是基于隨機過采樣算法的一種改進算法,它可以有效地防止隨機過采樣算法采取簡單復制樣本的策略來增加少數類樣本產生的模型過擬合問題,它的基本思想是對少數類樣本進行分析,根據少數類樣本人工合成新樣本添加到數據集中。算法流程如下:
(1)計算少數類中每一個樣本到少數類全部樣本集中所有樣本的歐氏距離。
(2)根據樣本不平衡比例,設置一個采樣比例,以確定采樣倍率N,對于每一個少數類樣本a,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為b。
(3)對于每一個隨機選出的近鄰b,分別與原樣本a構建新的樣本c。
算法使用前后的效果如圖2、圖3所示。從圖2和圖3中可以明顯看出,使用SMOTE算法后各個數據類別數量得到了補齊,為模型訓練提供了良好的數據支持。
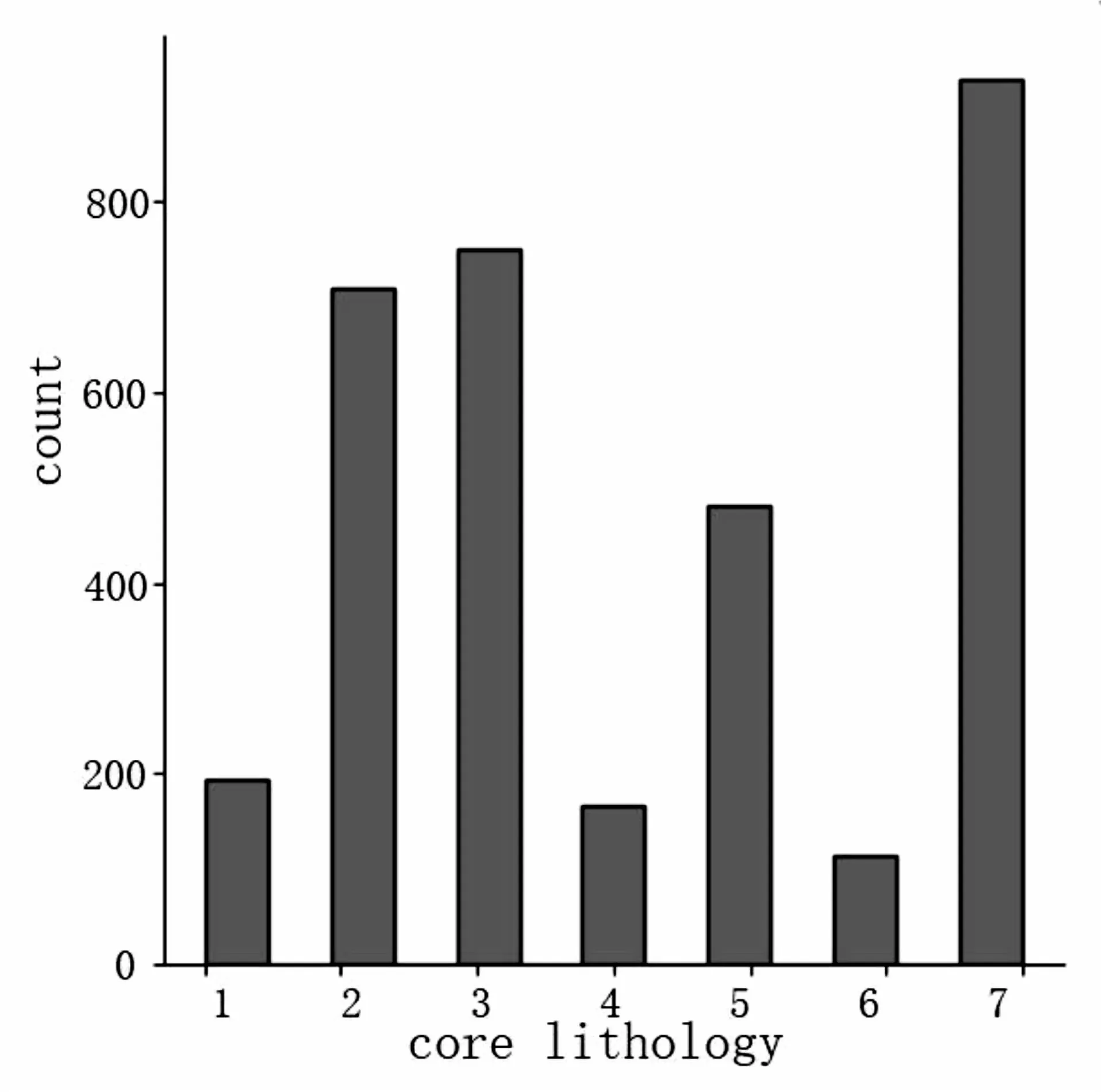
圖2 原始數據分布
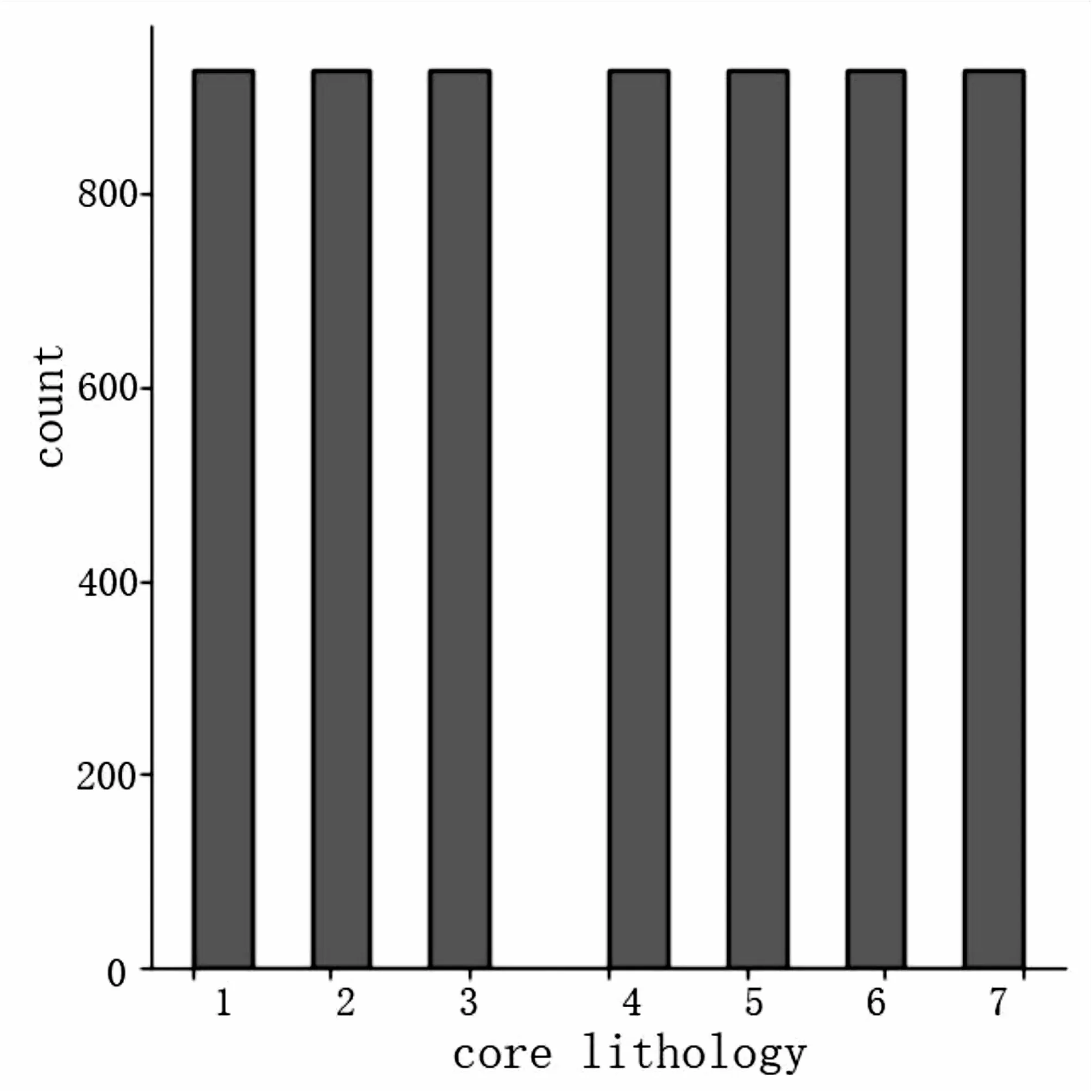
圖3 數據補齊后的分布
3.2 Stacking集成模型的訓練與測試
通過以上步驟對測井曲線數據進行數據預處理,然后將上述處理完的數據輸入到模型中進行訓練與測試,檢驗Stacking集成模型的可靠性。為了提高基模型的差異性和防止過擬合現象,該模型的訓練采用K折交叉驗證的思想,對模型進行訓練,來保證訓練模型的準確率和泛化性。
具體的訓練步驟如下:
(1)將訓練數據進行K折劃分,分成數量相同的K組數據。
(2)用選取的多個基模型進行K次訓練,訓練樣本為K-1份,剩下的一份作為訓練后的數據。
(3)將預測的K份數據組成新的訓練樣本,通過PCA算法計算基模型所占權重,將權重融入到預測的數據中,組成元模型的訓練數據。
(4)將第三步的數據輸入到第二層的元模型中進行預測,得到最終的預測結果。
對Stacking集成模型進行測試,如果該模型在驗證集上識別效果較好,則可以將模型用于訓練集數據進行訓練。否則,需要對集成模型進行優化調整,重新測試。
4 實際應用效果及分析
4.1 數據資料
本次實驗的數據來自于中國延安氣田的某井區數據。訓練數據集包括31口生產井的3 345條測井數據,其中主要的巖性分類為:粗砂巖、中砂巖、細砂巖、粉砂巖、白云巖、灰巖和泥巖,總共七種巖性。其中,粗砂巖樣本194條,中砂巖樣本710條,細砂巖樣本751條,白云巖樣本166條,石灰巖樣本482條,泥巖樣本114條,粉砂巖樣本928條。測井曲線包括聲波測井(AC)、井徑測井(CAL)、伽馬射線測井(GR)、鉀測井(K)、深探雙側向電阻率測井(RD)和自然電位測井(SP)6條測井曲線。巖性復雜,并且巖性識別較為困難。
測試數據集來自3口生產井的366條測井數據。在測試集合中,巖性數據包括:粗砂巖樣本20條,中砂巖樣本80條,細砂巖樣本80條,白云巖樣本53條,石灰巖樣本13條,泥巖樣本100條,粉砂巖樣本20條。本次實驗的所有巖性分類模型使用Python的scikit-learn框架進行編寫,它是Python的一個模塊,提供了廣泛的機器學習算法,包括監督學習和無監督學習。
4.2 實驗結果
在模型評價方面,本次實驗采用準確率和F1-Score對各個模型的表現進行評判。其中準確率表示預測結果和真實結果的差異,它的計算方式主要是分類正確的樣本個數和總樣本個數的比值。F1-Score兼顧了分類模型中的準確率和召回率,是對模型準確率和召回率的加權平均,它更能全面地評價模型的優劣。各個基模型的參數設置以及準確率和F1-Score如表1、表2所示。
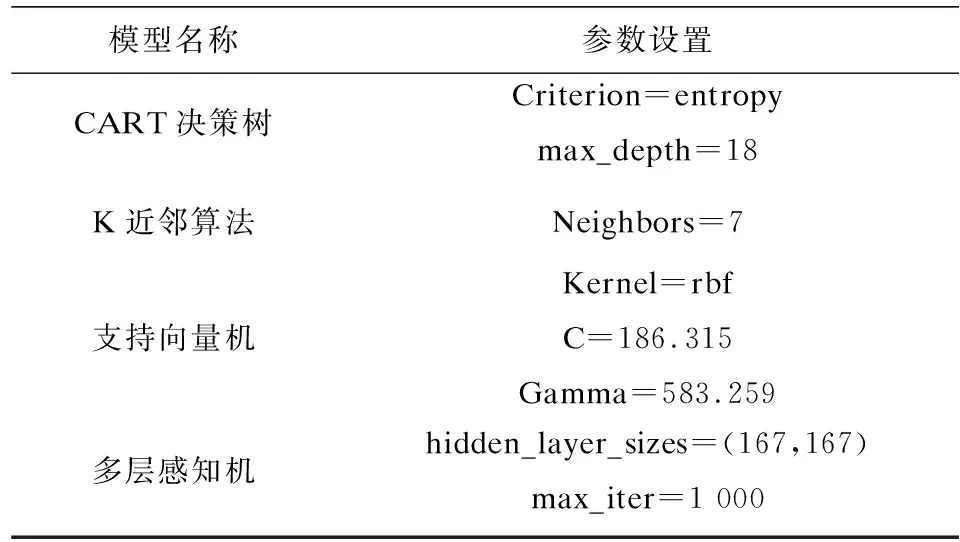
表1 基模型參數設置
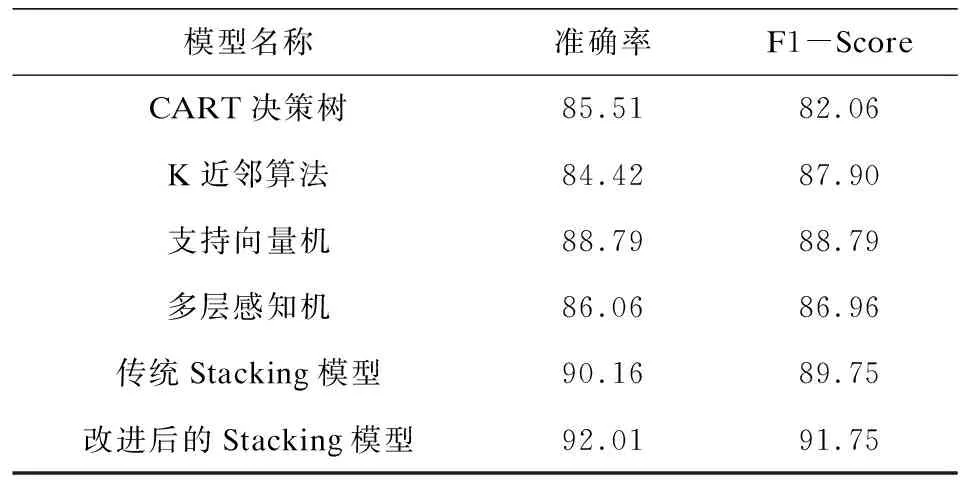
表2 各個模型的準確率和F1-Score %
各個模型在不同巖性種類上的準確率如表3所示。通過對比各個模型在測試集上的指標,可以得出如下結論:在模型準確率方面,所有基模型中支持向量機的準確率最高,達到了88.79%,K近鄰算法準確率最低,達到了84.42%。改進后的集成模型準確率達到了92.01%,相比較于CART決策樹,準確率提高了9.5個百分點,相比較于KNN算法,準確率提高了7.59個百分點,相比較于MLP,準確率提高了5.95個百分點,相比較于SVM,準確率提高了3.22個百分點。相比較于傳統Stacking模型,準確率提高了1.85個百分點。
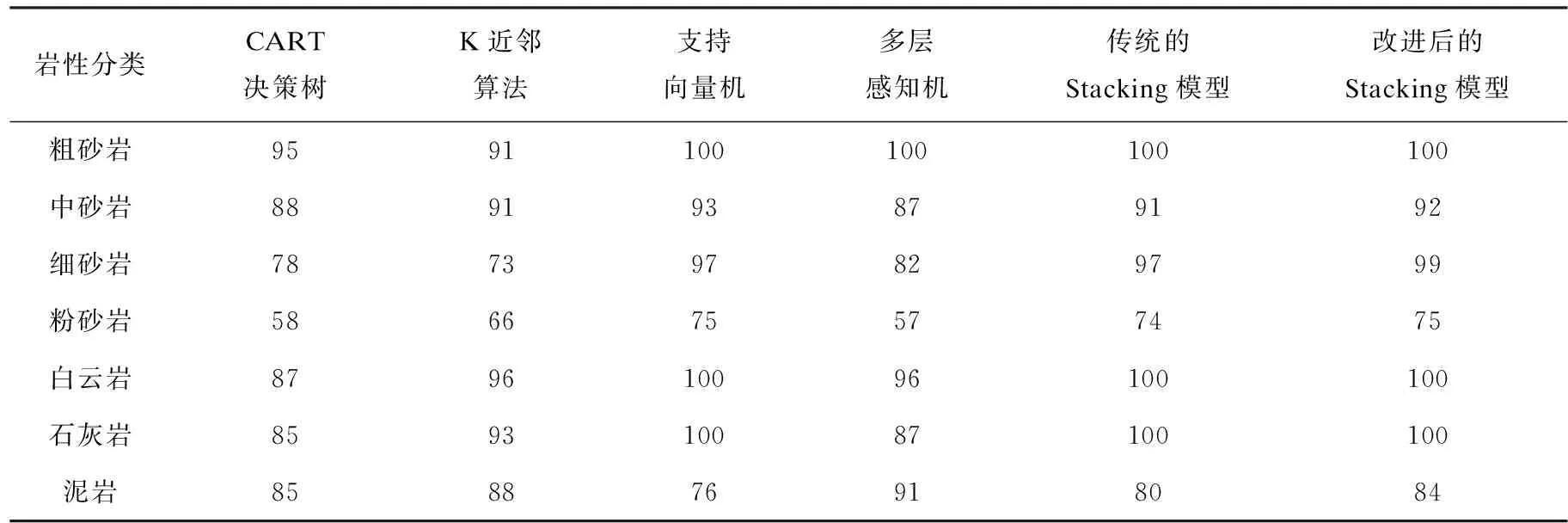
表3 各個模型在不同巖性類別上的準確率 %
對于各個巖性類別分類準確度,集成模型也有一定的提升。其中,在識別效果最差的粉砂巖上,集成模型也得到了較好的識別效果。在F1-Score方面,所有的基模型中,支持向量機的F1-Score最高,達到了88.79%,CART決策樹的F1-Score最低,達到了82.06%。改進后的集成模型F1-Score達到了91.75%,相比較于CART決策樹,F1-Score提高了9.69個百分點,相比較于KNN算法,F1-Score提高了3.85個百分點,相比較于MLP,F1-Score提高了4.79個百分點,相比較于SVM,F1-Score提高了2.96個百分點。相比較于傳統Stacking模型,F1-Score提高了2個百分點。
綜上分析,改進后的集成學習模型從準確率和F1-Score方面得到了較大的提高,從實驗數據來看,改進后的Stacking集成模型整體效果最好,從而證明了該改進方法的有效性。
4.3 實驗結果分析
Stacking集成模型相較于單一的機器學習模型效果較好。因為它集成了四種基模型,融合了它們各自的優點,即CART決策樹容易考慮到每個測井曲線特征,KNN適用于非線性分類,MLP易于學到高階特征,SVM在高階特征上有良好的分類效果。而從2.1節中可以得出,每個基模型自身都存在一定的局限性,導致其效果不理想。因此,該文的Stacking集成學習準確率普遍高于單一的機器學習模型。并且,改進的Stacking集成學習模型相較于傳統的Stacking集成學習模型,效果也得到了提升,因為其更加注重基模型之間的差異性。在各個基模型中,正確的預測能夠幫助元分類器進行決策,錯誤的預測結果會降低元分類器的分類性能。因此,提出的模型為各個基模型分配權重,考慮了每個基模型的真實預測信息,有效地提高了分類準確率和F1-Score。
但是,從實驗數據中也可以發現,改進的集成學習模型在部分巖性上的識別準確率沒有得到很大的提升,例如粉砂巖,它的識別準確率只是達到了基模型識別準確率的最高值。而且,部分巖性的識別準確率不但沒有得到提升,反而有所下降,例如中砂巖和泥巖,這是由于集成策略仍然存在一定的缺陷,導致最終的集成模型沒有學習到相關類別的特征信息,因此,該模型仍然有待進一步提高。
5 結束語
通過分析測井曲線數據,有助于識別不同的巖性,該文通過對CART決策樹、KNN、MLP和SVM四種模型進行分析,結合了它們各自的優點,通過PCA算法為其分配權重,將其結果輸入到元模型中進行訓練。通過此方法,極大地融合了每個模型的優點,完善了每個模型的不足,最終建立了一個穩定高效的用于巖性識別的集成學習模型。經過多次對比實驗,發現該模型相較于傳統的巖性識別模型,具有較好的穩定性和準確性,為廣大學者利用集成學習技術進行巖性識別分析提供了新的方法和思路。從實驗數據中可以得到,針對分類效果較差的巖性類別,該集成模型提升效果不顯著,并且部分類別的準確率有所下降,因此,如何選取更巧妙的集成策略,提高各個分類類別的準確率,最終提高模型的整體表現,還需要進一步地探索和研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
