基于混合模型的風電機組異常數據識別方法
2022-08-02 05:50:20林立棟
電力科學與工程 2022年7期
關鍵詞:水平
林立棟,郭 鵬,甘 雨
(華北電力大學 控制與計算機工程學院,北京 102206)
0 引言
SCADA(supervisory control and data aqurirement)運行數據能夠反映風電機組的運行特性和狀態。在實際運行過程中,由于天氣、環境、機組停機、通信噪聲和設備故障等因素,風電機組運行數據中存在大量異常數據。準確識別這些異常數據,才能有效提高后續以運行數據為基礎的風電機組功率預測、發電性能評價、狀態監測等工作的效率和精度[1]。
針對風電機組運行數據中異常數據的識別,文獻[2]提出了變點分組與四分位組合的方法——在不同風速區間上依次使用變點法和四分位法,對數據中堆積型異常數據和分散型異常數據進行有效識別。該方法清洗數據的損失率偏高,且不能完全識別、清除所有類型的異常數據。
文獻[3]提出四分位與DBSCAN(density-based spatial clustering of applications with noise)聚類相結合的異常數據清洗方法。因DBSCAN 算法對參數調整敏感,故該算法無法自動確定參數閾值,且對于高密度區域異常數據的清洗效果較差。
文獻[4]采用局部離群因子(local outlier factor,LOF)算法來識別異常數據。該算法利用加權距離計算數據的相對密度,把具有足夠高密度的區域劃分為簇,實現了分散型異常數據的有效識別與剔除。但該算法無法有效識別分布密度較高的堆積型異常數據。
文獻[5]提出基于圖像處理的異常數據清洗算法:將風速-功率散點轉換為風功率曲線的二值圖像,然后根據風功率曲線圖像中異常數據與正常數據的像素空間分布特征,通過圖像操作剔除異常數據的像素。該方法所需數據量較大,且像素與數據之間無法一一對應,即無法直接給出單個數據的正常或異常狀態。
文獻[6]提出結合堆疊去噪自編碼器(stack denoise auto-encoder,SDAE)和基于密度網格聚類方法的無監督異常值檢測方法:利用SDAE 提取原始數據的特征,然后基于密度網格的聚類方法來得到聚類結果,最后通過設置窗口寬度實現對異常數據的識別。由于計算時需要花費大量時間去過濾原始SCADA 數據,故該方法效率低。
針對以上文獻的局限,本文結合風電機組運行數據的分布特征,將參數模型與非參數模型結合,以實現風電機組異常運行數據的識別。以2 臺風電機組所具有的復雜異常數據為例,驗證本文所提方法的有效性。
1 數據分布特征分析
不同因素所產生的異常數據,在風速-功率(V-P)坐標系中的分布特征也各不相同。
功率散點:即每一條運行數據中,由風速和功率構成的數據對,簡稱為散點。
本文以2 臺1.5 MW 雙饋式風電機組(LY21和E17)10 min 間隔運行數據為算例。LY21 機組發電功率大于零的數據總計18 215 條,其散點分布如圖1 所示;E17 機組發電功率大于零的數據總計30 205 條,其散點分布如圖2 所示。
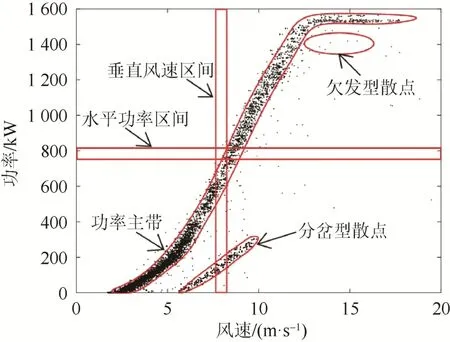
圖1 LY21 機組功率散點分布Fig. 1 Power dots distribution of LY21 unit
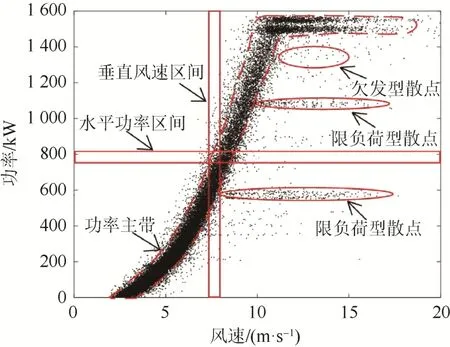
圖2 E17 機組功率散點分布Fig. 2 Power dots distribution of E17 unit
從圖1、圖2 中可看出,2 臺機組正常運行數據對應的功率散點分布密集,“功率主帶”呈“廠”字形分布。將顯著脫離風電機組正常運行狀態的運行數據,即“功率主帶”外的運行數據定義為異常運行數據,其所對應的功率散點即為異常散點。異常散點可分為以下3 類。
(1)欠發型散點。該類型散點表現為:隨機分布在功率主帶附近且密度較低,風速較高但功率較低。此類散點一般由于風電機組工況變化、數據采集異常、發電性能劣化等因素引起。
(2)分岔型散點。該類型散點表現為功率主帶附近的一條或者多條密度較為稀疏的功率副帶。此類散點產生的原因可能為風速計或轉速傳感器異常、變槳系統卡塞等。
(3)限負荷型散點。該類型散點表現為一條或多條位于功率主帶右側的橫向密集堆積的水平數據帶。此類散點產生的原因是:當機組出現棄風限電時,風電機組提前變槳,控制機組在限定功率狀態下運行。
由于風電機組功率散點分布復雜,直接對風速-功率坐標系內所有功率散點進行異常數據識別的難度較大。因此,需要對功率散點進行分區,通過建立不同區間內的散點概率模型,實現對各區間內散點分布情況的準確描述,從而完成異常數據的識別。
參數模型,如正態分布模型、威布爾分布模型等,其優點是參數具有顯著的物理意義,能夠直觀準確描述數據的整體分布特征,具有全局性。但是,使用參數模型需預知數據分布是否符合該模型特征,并需首先將水平功率區間內散點的分布轉換為頻率直方圖,再用頻率直方圖數據擬合模型參數。如圖1、圖2 所示,2 臺機組各水平功率區間數據分布情況復雜,無法直接判斷其較為符合哪類參數模型,且頻率直方圖的分區寬度難以確定。
非參數模型,如核密度估計模型等,其優點是使用時無需事先知道數據的分布,僅從數據本身即可得到數據的概率密度分布;但是,因其缺少能直觀描述數據整體分布特征的模型參數,所以其具有局部性,缺乏整體性。
本文將非參數模型與參數模型兩者相結合。在未知各水平功率區間中數據分布前提下,首先應用非參數模型(擴散核密度估計)得到功率散點的概率分布;再引入參數模型對概率分布進行擬合,采用擬合的模型參數來準確描述數據整體分布特性。
2 擴散核密度估計概率分布
2.1 擴散核密度估計
核密度估計(kernel density estimation,KDE)是一種常見的非參數密度估計方法[7-9]。該方法可直接估計樣本數據的概率密度,無需事先假設樣本是否服從某個總體分布。
傳統核密度估計的表達式為:
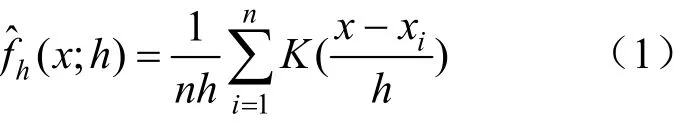
式中:x1,···,xn為總體樣本的獨立分布隨機變量;n為樣本數量;h為與n有關的常數,稱為帶寬或光滑參數;為核函數,本文選取高斯核作為核函數。
本文采用擴散核密度估計法(diffusion-based kernel density method,DKDM)替代KDE,有效解決KDE 帶寬選取以及邊界校正的問題,并提高KDE 的局部適應性[10]。
DKDM 將核函數等效于熱擴散過程的轉移密度,從而建立熱擴散與普通核密度估計的聯系。
DKDM 的核密度估計公式為:
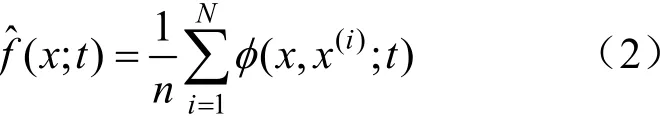
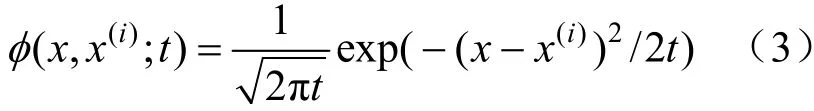
式(2)為下述傅里葉熱擴散偏微分方程(diffusion partial differential equation,DPDE)的唯一解[10]:
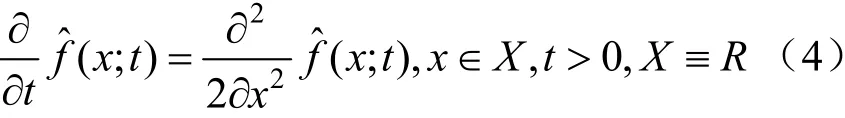
式(4)的初始條件為:
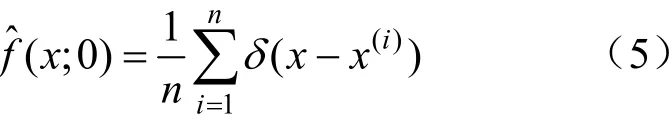
式中:δ為狄拉克函數。
當采用傳統核密度估計時,若隨機變量x的定義域有界,則需要對邊界進行校正。若采用
DPDE,則僅需在初始條件(5)和諾埃曼邊界條件式(6)下求解式(4)。
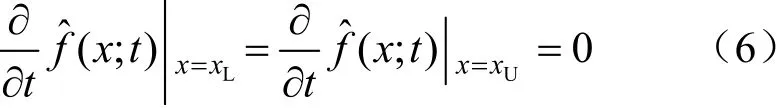
式中:xL為隨機變量x定義域的下界;xU為隨機變量x定義域的上界。
假設定義域為[0,1],則基于擴散方程的核密度估計的解析解為[11]:
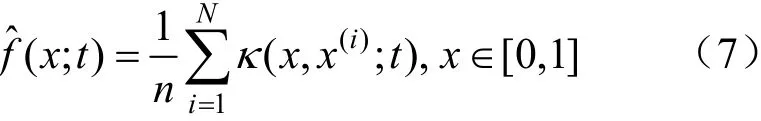
式中:κ為θ函數,其表達式為:
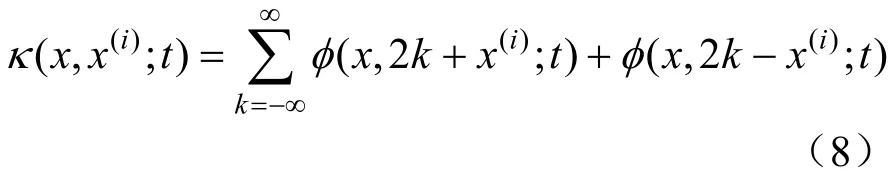
式(7)在式(1)的基礎上,考慮到了帶寬選擇與邊界校正,能夠很好地解決傳統核密度估計帶寬選取和邊界擬合誤差這2 個問題。
2.2 水平功率區間功率散點概率分布
在滿發狀態時,機組運行在額定功率附近,此時產生的散點均屬于正常數據,無需再進行分析;因此,本文僅對額定功率下的功率散點進行區間劃分并做相應的分析。
為保證每個水平功率區間內包含足夠多的散點,在本文中:水平方向上,將機組分為30 個功率區間;功率區間的間隔為50 kW。
用DKDM 估計概率分布,結果如圖3 所示。
風電機組功率主帶所對應的功率散點分布十分密集,因此該處概率密度估計值應明顯較高。在圖3 中,可以非常直觀地看出,2 臺機組的每一個水平功率區間中至少存在一個波峰,該波峰的概率密度值明顯高于此功率區間中其余位置。結合圖1、圖2 及核密度估計的原理可知,該波峰對應的即為功率主帶的中心位置。
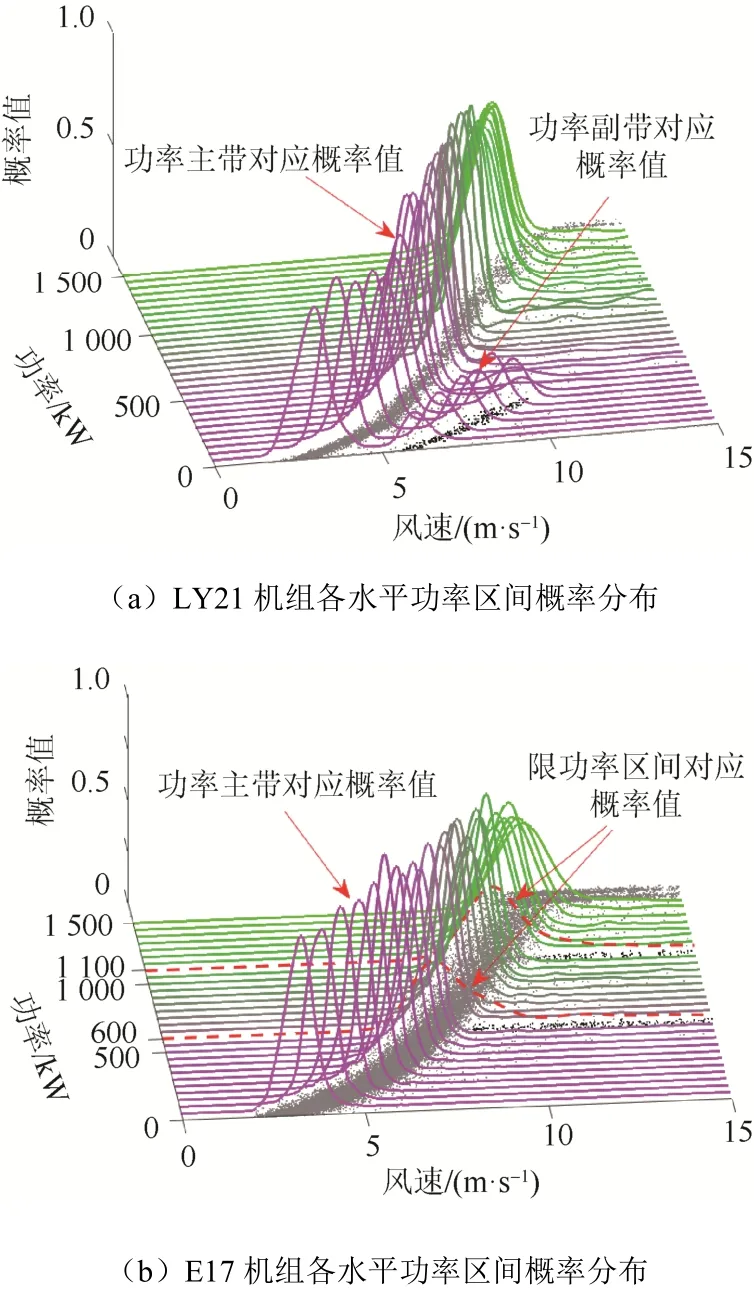
圖3 DKDM 概率密度估計結果Fig. 3 Probability density estimation results by DKDM
LY21 機組前6 個功率區間(0~300 kW)的概率密度分布曲線均出現了雙峰現象:在水平功率區間中,除功率主帶對應的概率密度峰值外,還存在與圖1 中分岔型散點(即稀疏功率副帶)相對應的另一個分布密度低于功率主帶的次峰值。
E17 機組各水平功率區間概率密度分布曲線均呈單峰現象。但是,在第12(550 kW~600 kW)和第22(1 050 kW~1 100 kW)個功率區間,可以明顯看出其概率密度峰值遠低于其它功率區間,且概率密度曲線水平向右延伸很遠,呈現拖尾狀態[12]。與圖2 中對應位置的功率散點分布進行對照分析,結論為:在這2 個功率區間中,出現向右延伸的人為限負荷橫向堆積型數據。
通過對每一水平功率區間內功率散點進行擴散核密度估計,將原來只能人為觀察的散點疏密分布轉換為數字概率密度曲線。但由于擴散核密度估計方法屬于非參數模型,沒有能夠簡單直觀描述如LY21 機組雙峰或E17 機組拖尾等水平功率區間的整體分布特征的模型參數。因此,本文采用參數模型,即混合威布爾分布模型,對擴散核密度估計的概率密度曲線進行參數化擬合;通過擬合參數提取和描述各水平功率區間散點的整體分布特征。
3 概率密度曲線參數擬合
威布爾分布模型常用于風速和風能概率密度估計[13-15],但對于圖2、圖3 這樣的概率密度曲線,用單一威布爾分布并不能達到很好的擬合效果[16]。
混合威布爾分布模型由多個單一威布爾分布加權組合而成。該模型的適用性較強,對于各種復雜概率密度曲線的擬合效果較好,且模型各參數的不同組合,可以反映出所擬合曲線形狀的多種復雜特征[17]。擬合后,混合威布爾分布的權重、形狀參數和尺度參數即可精確量化反映某一水平功率區間中擴散核密度估計概率密度曲線形狀特征,即功率散點整體分布特征。
3.1 混合威布爾模型
假設一個總體樣本可分為m個子體,每個子體均服從相同分布。假設各個子體的概率密度函數分別為f1(t),f2(t),…,f m(t),各個子體所占的權重分別為p1,p2, …,pm。于是,混合威布爾分布的模型可表示為:
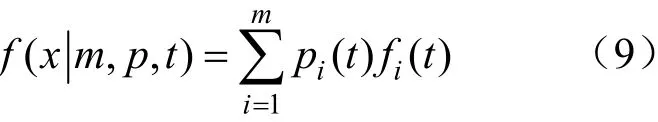
若每個子體都服從威布爾分布,則fi(t)為:
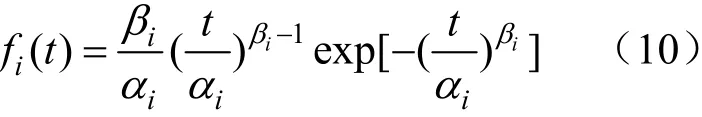
式中:αi為第i個威布爾分布尺度參數;βi為第i個威布爾分布形狀參數。
本文采用混合威布爾分布對LY21、E17 機組各個水平功率區間概率密度曲線進行擬合。幾個典型區間的參數,如表1 所示。
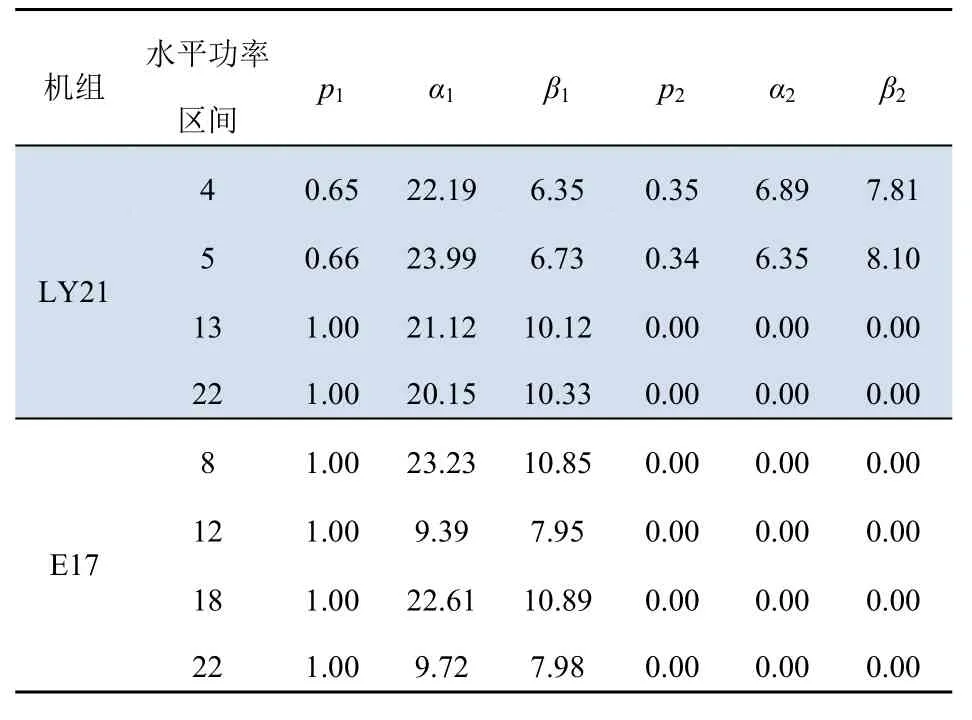
表1 混合威布爾典型參數Tab. 1 Mixed Weibull typical parameters
擬合效果如圖4 所示。
從圖4 中可看出,混合威布爾分布能夠較好地完成對擴散核密度估計概率密度曲線的擬合。計算擬合曲線與概率密度曲線的均方根誤差,發現均方根誤差均小于0.04。這說明,擬合曲線能夠準確反映水平功率區間內功率散點的分布情況。
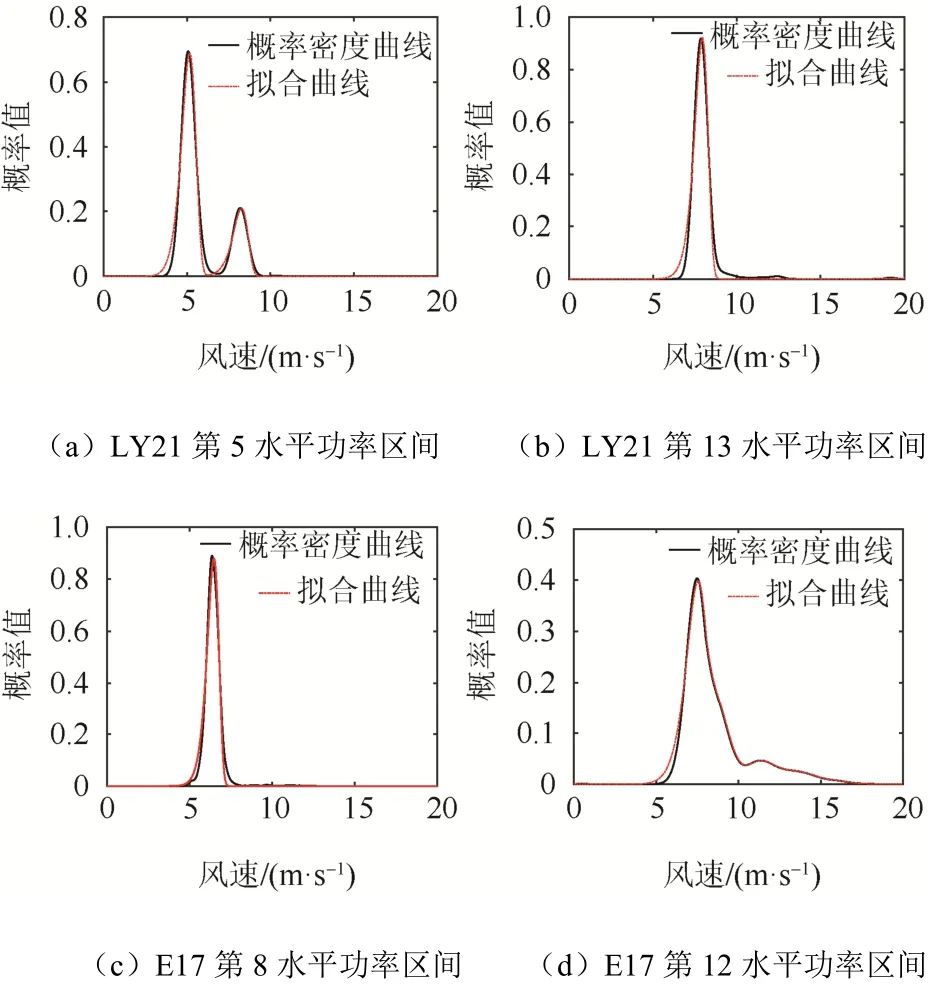
圖4 混合威布爾分布對水平功率區間概率密度曲線擬合效果Fig. 4 Fitting effect of mixed Weibull distribution for probability density curves in horizontal power intervals
混合威布爾分布的權重p表示各子體數據在總體數據中所占比例。p的個數i代表著子體的個數。當i=1 時,為單峰情況;當i>1 時,為多峰情況。
混合威布爾分布的形狀參數β決定擬合函數的形狀:當β≤1 時,擬合函數呈指數減函數;當β>1 時,呈現尖峰特性[18];當β>3.5 時,整體形狀與正態分布相似,且β越大,概率密度分布越集中在其峰值附近。
由表1 可知,LY21、E17 機組的形狀參數β均大于3.5,這說明擬合曲線均呈現近似正態分布形狀。
混合威布爾分布的尺度參數α主要起到拉伸整個函數的作用。α的大小決定擬合函數的陡峭程度:α越小,擬合函數越平緩,右側尾部占比越大,呈“胖尾”特性;α越大,擬合函數越陡峭,尾部占比越小,呈“瘦尾”特性[19]。
根據混合威布爾分布3 個參數的定義以及表1 的具體數據,可分析得出LY21、E17 機組包含3 種類型水平功率區間:正常水平功率區間,限功率水平功率區間,分岔型水平功率區間。以下針對3 種類型詳細說明。
(1)正常水平功率區間
以E17 機組第8 水平功率區間為例。具體計算結果如圖5 以及表2 所示。
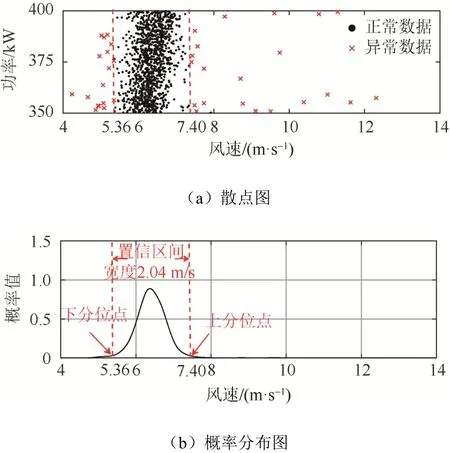
圖5 E17 機組第8 水平功率區間散點及概率分布圖Fig. 5 Dots and probability density distribution for the 8th horizontal power interval of E17 unit

表2 E17 機組第8 水平功率區間混合威布爾參數Tab. 2 Mixed Weibull parameters for the 8th horizontal power interval of E17 unit
考察表2 所示結果。E17 機組第8 水平功率區間僅包含一組參數p1、α1、β1,這說明:混合威布爾分布只擬合出一組參數,為單一威布爾分布;模型中只包含一個子體,概率密度曲線只包含單峰。同時由于α1的數值為23.23,數值較大,概率密度曲線呈現典型正態“瘦尾”特性,即概率密度曲線呈現瘦高、陡峭現象,不存在拖尾特性,如圖5 所示;功率散點密集分布在功率主帶上,符合正常功率散點的分布特征,因此判斷該水平功率帶為正常水平功率區間。
由此:若某一水平功率區間混合威布爾分布為單峰型,形狀參數β>3.5 且尺度參數α>20,對應概率密度曲線呈現單峰、陡峭、不拖尾特性,可判斷該水平功率區間中散點分布正常,為正常水平功率區間。
(2)限功率水平功率區間
以E17 機組第12 水平功率區間為例。具體計算結果如圖6 以及表3 所示。
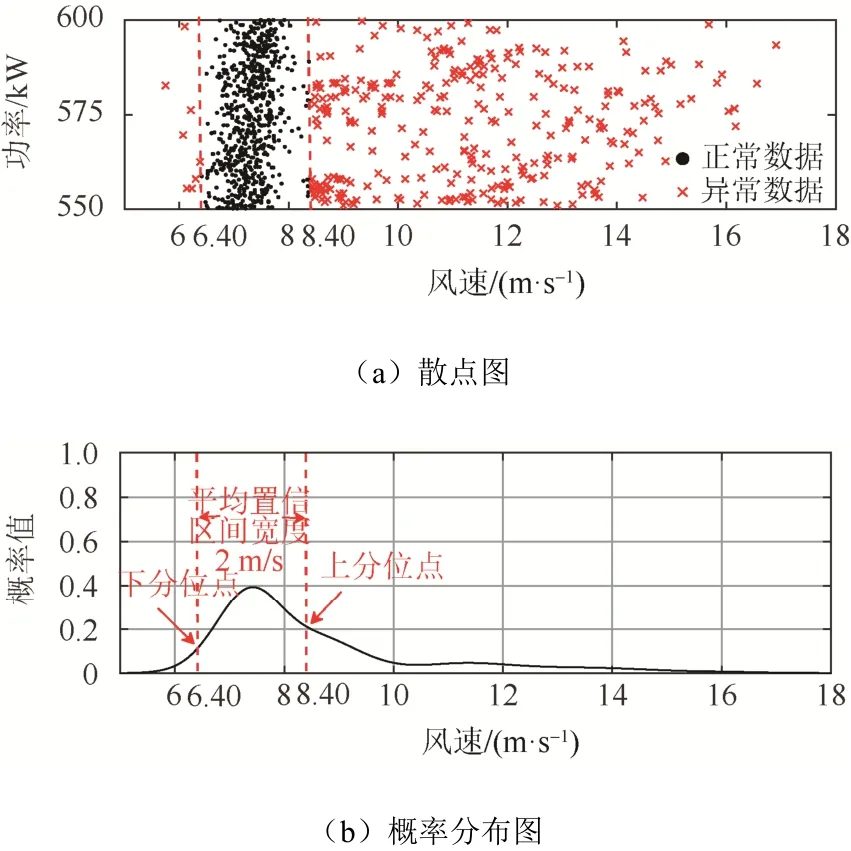
圖6 E17 機組第12 水平功率區間散點及概率分布圖Fig. 6 Dots and probability density distribution for the 12th horizontal power interval of E17 unit

表3 E17 機組第12 水平功率區間混合威布爾參數Tab. 3 Mixed Weibull parameters for the 12th horizontal power interval of E17 unit
考察表3 所示結果。E17 機組第12 水平功率區間僅包含一組參數p1、α1、β1。同上文所述,判斷模型只包含單峰。E17 機組第12 水平功率區間α1的數值為9.39,顯著小于其第8 水平功率區間的α1值(α1為23.23)。此時概率密度曲線呈現“胖尾”特性,即概率密度曲線呈現矮胖、右側拖尾現象,如圖6 所示。此時功率散點除分布在功率主帶上,還存在水平向右延伸的密集堆積型散點,因此判斷該水平功率帶為限功率水平功率區間。
(3)分岔型水平功率區間
以LY21 機組第5 水平功率區間為例。具體計算結果如圖7 以及表4 所示。

表4 LY21 機組第5 水平功率區間混合威布爾參數Tab. 4 Mixed Weibull parameters for the 5th horizontal power interval of LY21 unit
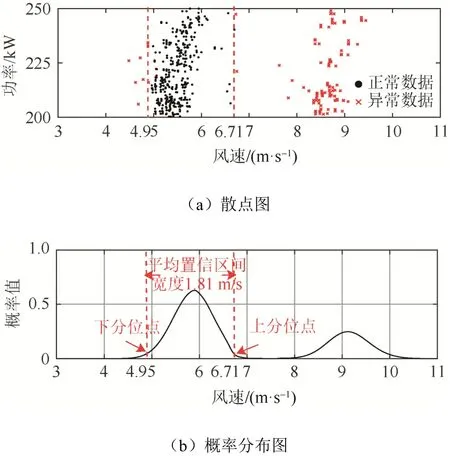
圖7 LY21 機組第5 水平功率區間散點及概率分布圖Fig. 7 Dots and probability density distribution for the 5th horizontal power interval of LY21 unit
考察表4 所示結果。LY21 機組第5 水平功率區間出現了2 組參數:p1、α1、β1以及p2、α2、β2。根據混合威布爾分布原理可知,此時所擬合的模型中包含2 個子體,即所擬合的模型中包含2 個威布爾分布,可判斷出現了雙峰現象。由于α1大于α2,表明LY21 機組第5 水平功率區間第一個峰比第二個峰更瘦更高,如圖7 所示。此時功率散點除了密集堆積在功率主帶上,在功率主帶向右位置也出現了較為密集堆積的散點,判斷該水平功率區間為分岔型水平功率區間。當多個相鄰水平功率區間均出現此現象時(如LY21 機組第1至6 個水平功率區間),則反映為在功率主帶右邊出現分岔現象,即出現了一條稀疏功率副帶。
對照分析可知,3 類典型水平功率區間的功率散點分布、對應擴散核密度估計概率密度曲線以及混合威布爾分布模型擬合參數所表達的結果完全相符。因此可以得出結論:混合威布爾分布的權重、形狀參數和尺度參數,能夠定量、準確地表征各個水平功率區間運行數據的整體分布特征,可作為判斷該區間數據分布正常與否的重要依據。
3.2 基于平均置信區間的異常數據識別
對于異常數據較多的風電機組如LY21 和E17,除正常水平功率區間外,還存在如限負荷型、分岔型等非正常水平功率區間。
本文提出平均置信區間方法,分別對正常水平功率區間和非正常水平功率區間進行異常數據識別。
依據某一水平功率區間的混合威布爾擬合參數及上述正常水平功率區間的判別方法,即可確定該區間是否為正常水平功率區間。
(1)正常水平功率區間異常數據識別。
對于正常水平功率區間,以概率密度曲線峰值為中心,向左側和右側對稱確定置信度為95%的雙邊分位點及置信區間寬度。置信區間內的功率散點即為正常數據,區間外的即為異常數據。如圖5(b)中E17 機組第8 水平功率區間所示,其置信分位點分別為5.36 m/s 和7.40 m/s,置信區間寬度為2.04 m/s。
將機組所有判斷為正常水平功率區間的置信區間寬度求取平均值即可得到平均置信區間寬度。E17 機組的正常水平功率區間共28 個,平均置信區間寬度為2.00 m/s。LY21 機組的正常水平功率區間共24 個,平均置信區間寬度為1.81 m/s。
(2)非正常水平功率區間異常數據識別。
對于通過混合威布爾分布擬合參數判定為具有拖尾或雙峰等特征的限負荷、分岔型等非正常水平功率區間,采用平均置信區間方法識別異常數據。
以非正常水平功率區間的概率密度曲線最大峰值為中心,向左側和右側對稱確定置信分位點,分位點之間的置信區間寬度為該機組的平均置信區間寬度。如圖6 中,E17 機組第12 個限功率水平功率區間采用E17 機組的平均置信區間寬度2.00 m/s。圖7 中LY21 機組第5 個分岔型水平功率區間采用LY21 機組的平均置信區間寬度1.81 m/s。置信區間內的功率散點為正常數據,區間外的為異常數據。
采用上述方法依次對額定功率以下的各個水平功率區間進行異常數據識別。LY21 和E17 機組的異常數據識別結果如圖8 所示。圖8 中,黑色散點表示正常數據,紅色散點表示異常數據。
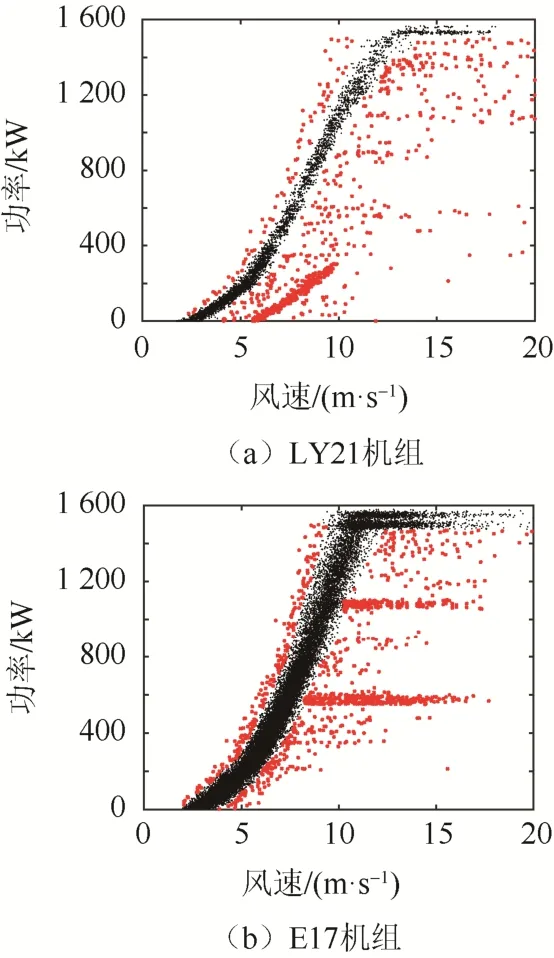
圖8 異常運行數據識別結果Fig. 8 Abnormal operational data identification results
3.3 算法對比分析
文獻[4]采用LOF(local outlier factor)算法對2 臺實驗機組進行異常數據識別。LOF 算法的思想是:利用加權距離計算數據的相對密度;把具有足夠高密度的區域劃分為簇;通過設定閾值,實現對異常數據的清洗。
對于本文算例,該算法識別效果如圖9 所示。
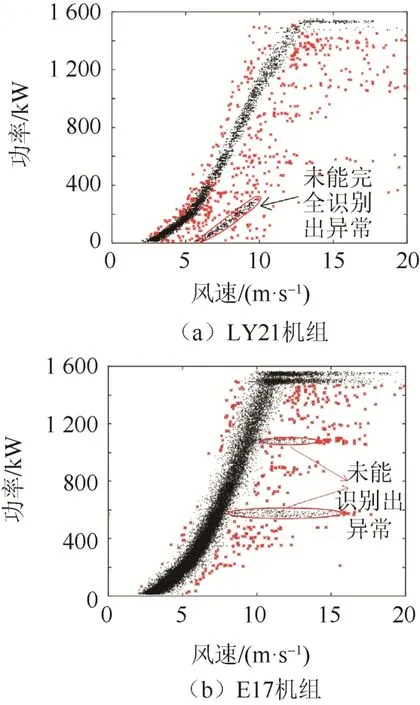
圖9 LOF 算法異常運行數據識別結果Fig. 9 Abnormal operational data identification results
對于LY21 及E17 機組,本文所提方法的數據剔除率分別為12.6%與3.68%,LOF 算法的數據剔除率分別為3.43%與1.12%。
由此可知,本文方法在識別堆積型異常數據方面具有優勢。
4 結論
以2 臺機組的復雜異常數據為例,驗證了本文方法的有效性。
(1)對風電機組運行數據進行分析與處理時,在水平功率方向上以一定功率間隔分層劃分工況,采用非參數模型擴散核密度估計方法對各個水平功率區間運行數據進行概率分布估計,從而克服了KDE 帶寬選取以及邊界校正問題,提高了KDE 的局部適應性。
(2)利用參數模型混合威布爾分布擬合擴散核密度估計的概率密度曲線。模型參數p,α,β能夠直觀準確描述水平功率區間中數據整體分布特征,可依此準確判別水平功率區間中運行數據分布是否正常。
(3)采用平均置信區間異常數據清洗方法。對非正常水平功率區間,采用平均置信區間寬度確定識別異常數據的上下分位點,實現異常數據的準確識別與剔除。
在后續研究中,將對水平功率區間的劃分間隔開展深入研究,力圖在保證核密度估計效果的基礎上給出區間劃分依據,進一步提高異常數據識別的效果。
猜你喜歡
美與時代·美術學刊(2022年3期)2022-04-27 01:18:15
火花(2019年12期)2019-12-26 01:00:28
人大建設(2019年6期)2019-10-08 08:55:48
人大建設(2019年12期)2019-05-21 02:55:32
雜文月刊(2018年21期)2019-01-05 05:55:28
人大建設(2017年6期)2017-09-26 11:50:44
學苑創造·A版(2015年11期)2016-01-14 09:03:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
中國火炬(2010年12期)2010-07-25 13:26:22
中國火炬(2010年8期)2010-07-25 11:34:30
