人工智能技術在智能駕駛控制中的應用
2022-08-03 02:41:20潘振華潘衛國
北京聯合大學學報 2022年3期
潘 峰,潘振華,熊 亮,潘衛國
(1.北京聯合大學 機器人學院,北京 100101;2.北京理工大學 自動化學院,北京 100081)
0 引言
智能車輛的控制可解耦為橫向和縱向控制,傳統的控制方法一般從數學解析模型入手,將控制問題轉化為優化問題,并使用數學算法進行求解。然而,較高精度的動力學和運動學模型都具有復雜的結構和大量的參數,往往求解困難,實時性較差。近年來,越來越多的基于人工智能的方法被引入智能汽車決策和控制中,開辟了一條和傳統汽車工程完全不同的研究思路。
人工智能通常是指通過計算機技術來呈現人類智能,涵蓋了計算機、仿生學、心理學及統計學等多門學科。李德毅院士提出了一種基于人工智能技術的自學習型控制決策核心的概念,并命名為“駕駛腦”[2]。Waymo公司為了進一步實現人工智能技術在智能駕駛中的成熟應用,于2019年收購了Latent Logic公司,這是一家專門研究使用模仿學習算法進行智能駕駛的高科技企業。同時,國內的智能駕駛研究及其商業化也在如火如荼地開展,除了新涌現的諸多造車新勢力,還有以百度、華為為首的眾多IT企業也通過與傳統車企合作,開展智能駕駛的應用研究。2014年,百度公司啟動“百度自動駕駛汽車”研發計劃,隨后不久就推出了Apollo智能駕駛系統,并于2016年在美國加州取得了自動駕駛牌照,隨后又推出了百度大腦,進一步推動了人工智能技術在智能車輛領域中的應用。
智能車輛可視為一種輪式機器人,當處于復雜環境中時,如真實場景下的交通流中,傳統的基于先驗模型的控制器往往無法預見所有的復雜狀況,而人工智能則具有自學習能力,智能控制器會在探索環境的過程中不斷訓練,從而逐步學習并優化其模型。傳統的控制方法也可以結合人工智能技術,如模型預測控制(Model Predictive Control,MPC)的代價函數可以通過機器學習來獲得,從而獲得更好的穩定性和魯棒性[3]。深度學習是人工智能領域具有革命性的技術,在智能駕駛感知層獲得了眾多成熟的應用,而且深度學習與強化學習相結合,還產生了深度強化學習(Deep Reinforcement Learning, DRL)。DRL具有深度學習的感知能力,還具有強化學習的決策能力,不但可以對輸入的諸如圖像(或雷達點云)這樣的高維數據進行特征提取,還可以通過強化訓練得到控制策略。人工智能方法的大量引入,使得智能駕駛系統在控制層面得到了更多的解決思路。
1 傳統智能駕駛控制技術現狀
1.1 智能駕駛系統架構
智能駕駛車輛系統的架構包括分層架構和端到端架構兩種。大部分智能駕駛系統采用分層架構,如劃分為感知、決策、控制和執行機構4個層次,如圖1所示。端到端架構則通過深度學習等人工智能方法,直接將圖像等傳感器數據映射為控制器輸出,如圖2所示。
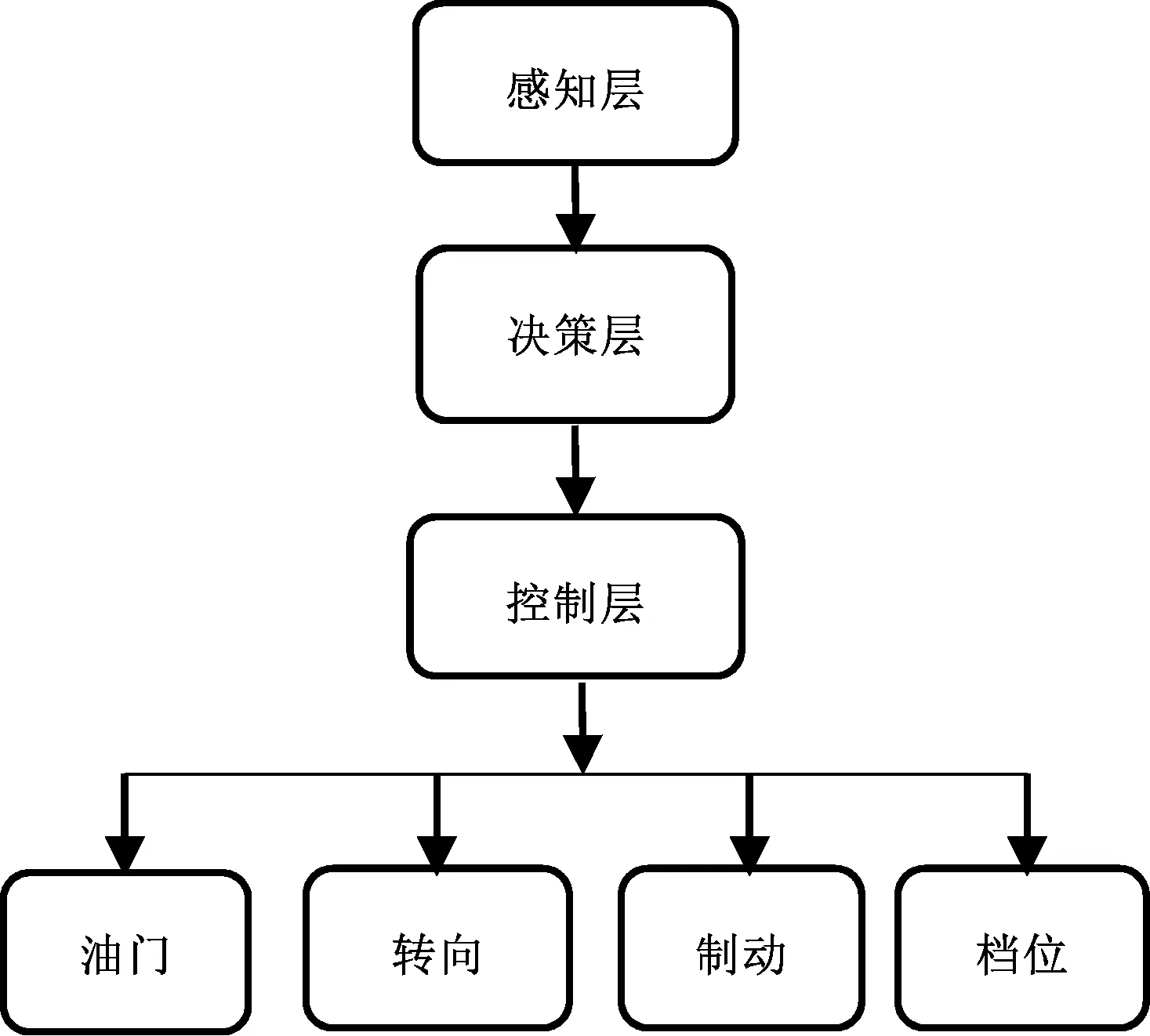
圖1 通用無人駕駛系統框圖Fig. 1 Universal Driverless System Framework
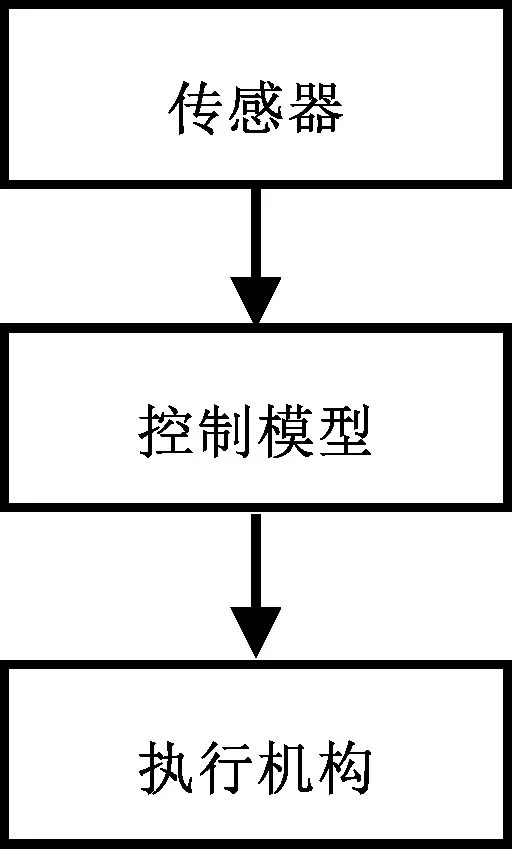
圖2 端到端駕駛系統框圖Fig. 2 End to End Driving System Framework
1.2 傳統智能駕駛控制方法
大部分智能駕駛系統采用分層架構,控制層處于決策層和執行器之間,作為一個關鍵環節,起到了承上啟下的作用。大多數研究都將控制層解耦為縱向控制和橫向控制兩種。縱向控制主要針對車輛縱向行駛時的速度和距離進行控制,既要滿足車輛運動學和動力學約束,還要保證車輛的縱向安全車距,其輸出大多為車輛加速度,并轉化為具體的油門和制動指令。橫向控制主要控制車輛的轉向,引導車輛沿規劃的路徑行駛。橫向控制器可視為一個路徑跟蹤控制器,其目標就是最小化車輛和規劃路徑之間的橫向偏差和方向偏差,同時也要兼顧車輛的平滑運動以維持穩定性和舒適性[4]。
1.2.1傳統的縱向控制方法
縱向控制系統主要控制的對象是速度和加速度,執行機構為油門和制動系統。智能駕駛車輛的縱向控制系統本質上是一個自適應巡航系統(Adaptive Cruise Control,ACC),其作用是保持安全車距和合理的車速。
兩組腦梗塞患者在進入醫院后,探討疾病護理方案期間,對照組:選擇常規護理方案完成;觀察組:選擇常規護理+早期護理干預方案完成;對于對照組,在患者病癥表現平穩后,依據其基本表現,展開對應康復護理干預;對于觀察組:
傳統的縱向控制器只是簡單的速度控制,大多采用PID或改進的PI控制方法。如斯坦福大學在2005年參加DARPA的參賽車輛——Stanley,使用的就是簡單PI控制[5]。傳統的PID方法雖然可以達到較高的速度控制精度,但是往往存在超調和執行延遲等問題,而且PID方法需要根據不同的工況和駕駛風格對參數進行調校,常常在某些工況下表現良好,而在另一些工況下卻出現性能下降的現象。
為了增強ACC系統對復雜環境的適應性,現有的ACC系統大多采用分工況控制。分工況控制是根據不同的車輛跟隨場景進行細分,在不同的場景下設計相應的控制算法。如距離控制模式和速度控制模式,其工況的切換邏輯是基于車間距與相對速度的變化進行設計的,最早由美國密歇根大學的Fancher等人提出,并被廣泛采用[6]。Moon等采集了數百名駕駛者的跟車數據并對其進行分析,根據加速度的取值將跟隨工況劃分為急減速、普通和舒適3個工況,并基于碰撞時間和警報指標將ACC工作區域分為安全、危險、高速警報和低速警報[7]。裴曉飛等將車輛縱向運動狀態劃分為8種工況和6種控制模式,系統根據實際路況切換控制模式[8]。張德兆等將控制模式進一步細分,提出了接近前車和超車兩種額外的控制模式,以及基于零期望加速度切換策略[9]。
1.2.2傳統的橫向控制方法
橫向控制的本質是一個循跡控制。研究者們對駕駛員的駕駛行為進行分析,并通過建立駕駛員橫向控制模型來實現對道路的跟隨控制。從20世紀80年代早期到21世紀初期,最有影響力的研究是由MacAdam[10]和郭孔輝院士等[11]提出的最優預瞄控制理論。傳統的橫向控制器設計主要可分為基于經典控制理論的方法和基于幾何的方法兩類。
1)基于經典控制理論的方法
基于經典控制理論的方法又可以分為基于車輛模型和基于誤差反饋兩大類。
基于車輛模型的方法本質上是利用車輛動力學和運動學方程,并在各種約束條件下使用優化方法求解橫向控制的最優解。在此類方法中,MPC[12]是運用較為廣泛的。除此之外,Huang 等還提出了基于模糊控制的停車路徑跟蹤方法[13]。線性二次型調節器(Linear Quadratic Regulator,LQR)也是經常被使用的方法,Levinson等參加DARPA比賽就使用了LQR方法,該方法利用底層反饋信息求解最佳轉向角,從而實現對車輛的橫向控制。孫正平等提出了Ribbon模型,解決了預瞄距離和車輛速度相對于方向控制耦合度高的問題。王家恩等使用車輛狀態信息及車路相對位置來生成期望的擺角速度[14]。百度在Apollo項目中的路徑跟蹤控制方法則綜合使用了LQR和MPC兩種方法[15]。
基于誤差反饋的方法大多基于PID框架,此類方法的創新點大多集中于如何進行參數的整定和自適應上。趙盼等提出了一種自適應PID方法,實現車輛的橫向控制[16]。Chatzikomis等基于橫向誤差和方向誤差進行PD控制,其控制器的比例系數能夠根據車速進行動態調整,從而協調側向和縱向控制的耦合關系[17]。Talukdar等使用神經網絡來優化PID的增益,使其在不同的速度下能夠自適應[18]。高振海等通過簡化的車輛動力學模型,對模型參數進行辨識,實現對PID控制器的參數整定[19]。陳煥明等引入遺傳算法,實現PID控制器的參數優化[20]。丁海濤等使用預瞄—跟隨模型,根據加速度反饋實現車輛的橫縱向控制[21]。
2)基于幾何的方法
基于幾何方法的控制器是智能駕駛橫向控制領域較為流行的方法,該類控制器通過車輛和預設路徑之間的幾何關系來計算理想的控制量。在這類控制器中,Pure Pursuit和Stanley是應用較早、使用最廣泛的兩種方法。
1985年,Wallace等首先提出了純跟蹤的基本原理,并將其應用在無人駕駛車輛的橫向控制中,該方法利用車輛與道路中線的橫向偏差來計算前輪的轉角。Amidi等在該方法的基礎上提出了正式的純跟蹤理論,并討論了這種方法的應用。隨后,Coulter詳細描述了純跟蹤的應用細節,并將其應用到室內外機器人的橫向控制中[22]。Rankin等將PID方法和純跟蹤方法相結合設計了一個控制器,并通過仿真和真實道路測試,證明了該方法的有效性[23]。Morales等利用純跟蹤方法對人、墻壁及走廊等進行跟蹤,并應用于室內導航環境[24]。段建民等使用純跟蹤方法控制無人駕駛車輛,以實現對GPS軌跡的準確跟蹤[25]。名古屋大學的Autoware項目中也使用了純跟蹤方法。
Stanley方法是基于幾何模型的另一種廣泛應用的方法,該方法使用了在2006年DARPA比賽中獲得冠軍的車輛名稱命名。該方法綜合考慮了方向誤差和橫向偏差,并基于車輛前軸的中心和預設軌跡上的最近點來計算誤差。Snider等使用Stanley方法取得了很好的實驗效果,然而該方法要求預設軌跡足夠平滑,且該方法的魯棒性相對于純跟蹤方法差一些。
2 基于AI的智能駕駛控制方法
2.1 學習型控制器
與具有固定參數的控制器不同,隨著時間的推移,學習型控制器利用訓練信息不斷學習其模型。基于每批收集的訓練數據,真實系統模型的近似值變得更加準確。研究者在很多工作中已經引入了簡單的函數逼近器,用于訓練學習型控制器,例如高斯過程建模[26]或支持向量回歸等[27]。
人工智能中的機器學習技術也常用于學習動力學模型,從而改進迭代學習控制和模型預測控制中的先驗系統模型。迭代學習控制主要應用于以重復模式工作的系統中,如智能控制的路徑跟蹤,并成功應用于越野地形導航,以及自動泊車和轉向動力學建模等。模型預測控制一般通過解決優化問題來計算控制動作,能夠處理具有狀態和輸入約束的復雜非線性系統。Lefèvre等將機器學習與MPC相結合學習駕駛模型[28],Brunner等則使用MPC結合人工智能來提高路徑跟蹤精度。這些方法使人們能夠更好地預測車輛的干擾和行為,從而將最佳舒適度和安全性約束應用于控制輸入。
學習型控制器的主要優點是,它們將傳統的基于模型的控制理論與學習算法完美地結合在一起。這使得設計者仍然可以使用已建立的方法進行控制器設計和穩定性分析,以及在系統識別和預測中應用強大的學習組件。
2.2 端到端的智能駕駛控制
與傳統的智能駕駛系統的分層架構不同,端到端的智能駕駛控制將原始圖像等傳感器數據直接映射到底層,取消了感知層和決策規劃層。圖2中的控制模型大多由深度神經網絡構成,其模型的訓練大致可以分為兩大類:一類為模仿學習,主要基于監督式學習訓練;另一類則基于強化學習的方法訓練,大多使用深度神經網絡,而且研究趨勢逐漸由單一的圖像傳感器映射向多傳感器數據融合的方向發展。Sallab使用深度強化學習DQN和DDAC方法并基于TORCS模擬器,實現了車道保持任務[29]。Bojarski使用深度學習技術來實現端到端的無人駕駛,即直接將感知層的圖像映射到執行機構的動作[30]。Eraqi等使用C_LSTM方法結合機器視覺,訓練無人駕駛橫向控制模型[31]。Chi等使用真實的圖像數據并通過深度神經網絡,訓練車輛的橫向控制模型[32]。Lee等使用監督式學習和強化學習的方法訓練模型,完成了車輛跟馳和換道任務[33]。Xiao等使用深度RGB數據并整合多種傳感器信息作為神經網絡的輸入,基于CARLA模擬器,解決智能駕駛的控制任務[34]。Haris等也使用RGB圖像和Lidar數據融合的方法,實現了端到端的智能駕駛控制,并基于CARLA模擬器進行了仿真[35]。
2.3 強化學習
深度學習的出現大大推動了監督式學習在智能駕駛感知領域中的應用,使得監督式學習被廣泛應用于行人識別及交通標志識別等感知問題。除了目標識別,深度學習也被大量使用在駕駛場景理解、駕駛場景語義分割及車輛定位等方面。同時,基于模仿學習的端到端智能駕駛控制主要也是基于監督式學習方法。
機器學習的另一個主要類型是強化學習[36],其應用多集中于智能駕駛的決策層和控制層。2012年,Lange等使用深度擬合Q學習的方法訓練微型賽車,在仿真環境下取得了媲美人類玩家的性能表現,這是深度強化學習應用于車輛控制的先例。然而,與眾多智能駕駛研究一樣,該方法并未在真實車輛平臺上得到應用,主要因為其實時性達不到實際應用的要求,而且只能輸出很少的離散化動作,不適于連續的動作空間。2016年,Sallab等用深度強化學習方法訓練賽車,在開源賽車模擬器(TORCS)環境下實現了車道保持,其提出的 DDAC方法可用于連續動作空間,而且實現了良好的控制效果[29]。Sallab提出的端到端控制思想正是基于深度學習和強化學習的結合,由深度神經網絡對高維輸入進行特征提取,再使用強化學習方法訓練智能體探索環境,最終將原始的高維圖像映射為執行器的動作。這種方法的魯棒性要超過傳統基于模仿學習的方法。DQN方法是深度強化學習的典型方法,2017年,Hynmin Chae等就將DQN算法應用于車輛的剎車控制,主要解決避讓行人的問題。Zong等在TORCS環境下使用DDPG方法訓練智能體的速度控制和轉向策略,達到自主避障的目的[37]。Shalev-shwartz等將LSTM方法和強化學習相結合,訓練了一個ACC跟車模型,并解決了環島匯入的控制[38]。楊順提出了基于視覺場景理解的深度強化學習控制方法,該方法結合了深度學習和DDPG方法[39]。2018年,微軟公司提出了分布式云端深度強化學習的框架,旨在提高強化學習的訓練效率。Liang等參考人類學習的模式,提出了可控模仿強化學習(CIRL)的方法,并在CARLA模擬器環境中進行了測試,取得了較好的測試結果。這種方法的思想是先使用模仿學習方法,并基于監督式學習的訓練方法對網絡的權重初始化,再使用DDPG方法優化控制策略。這種方法比單獨的模仿學習具有更好的魯棒性,更加適應復雜的未知環境,而且訓練也更加穩定。韓向敏等則使用DDPG算法訓練智能車輛的縱向控制模型,該模型具有自學習能力,通過對控制策略的不斷優化達到人類的控制水平[40]。潘峰等提出了基于人類駕駛特征的智能駕駛控制方法,該方法通過采集大量數據并分析得到人類駕駛員的駕駛特性,結合反向強化學習的方法,通過優化獎勵函數引導智能體訓練,最終使其駕駛行為更加符合人類駕駛習慣[41]
2.4 多智能體強化學習
多智能體強化學習(MARL)是專注于實現具有多個智能體的自主和自學習系統的領域,是強化學習算法在多智能體系統上的延伸,已經成為人工智能研究領域的一大熱點,在智能駕駛控制中具有豐富的研究成果。Chu等通過將交通網格動態劃分為更小的區域,并在每個區域部署一個本地代理來減少行動空間,應用于大中型交通燈控制[42]。Li等利用深度Q-learning (DQL)來控制交通燈,并部署深層堆疊自編碼器(SAE)神經網絡,從而減少表格型Q學習方法帶來的巨大狀態空間。Zhou等提出了一種基于邊緣的分散強化學習方法,用于車內交通燈控制[43]。DRLE利用車聯網的普遍性,加速交通數據的收集和解釋,以更好地控制交通燈和緩解擁堵。Ngai等采用多目標強化學習框架解決車輛超車問題,根據每個目標的重要性構造一個融合函數,最終得出一個整體一致的行動決策[44]。Wu等提出了一種基于多智能體的深度強化學習(DRL)方法,允許智能體對非結構化輸入數據做出動態決策,旨在解決車聯網中邊緣節點的資源分配問題(如通信資源、計算資源、頻譜資源等的分配)[45]。Wang等提出了一種基于協作群的多智能體強化學習-ATSC (CGB-MATSC)框架,基于協作車輛的基礎設施系統(CVIS)實現對大規模路網的有效控制[46]。Choe等提出一種基于協同強化學習(RL)的智能信道接入算法,車輛在該算法中以完全分布式的協調信道接入[47]。Ku?i等提出了一種基于分布式多智能體強化學習的高速公路交通流時空控制方法[48]。Abdoos等利用博弈和強化學習,開發用于多個交叉口的交通信號控制器,提出了一種雙模式智能體系結構,通過獨立和協作的過程,有效地控制交通擁塞問題[49]。Khamis等開發了一個多智能體多目標強化學習(RL)交通信號控制框架,可在空間和時間維度上連續模擬駕駛員的加減速行為[50]。類似地,Balaji等提出一種基于分布式多智能體強化學習的交通信號控制方法,用于優化城市主干道網絡的綠色配時,以減少車輛的總行駛時間和延誤[51]。Yang等基于Software Defined Internet of Things(SD-IoT)采集數據,對交通燈和車輛進行控制,該方法具有較好的競爭性能和穩定性[52]。針對隨機到達和不完全觀察環境而對智能體產生噪聲的自動公交車隊控制問題,Wang等提出了一種結合高級策略梯度算法的多智能體強化學習方法[53]。
3 AI方法在智能駕駛控制中的挑戰
智能駕駛實驗具有極大的危險性,當前基于人工智能方法訓練的模型大多使用視頻游戲模擬引擎進行訓練和仿真,如TORCS、CarSim和CARLA等。基于模擬仿真環境訓練的模型往往因為虛擬世界的建模誤差,而在真實實驗平臺上表現欠佳,生成對抗網絡和對抗學習的出現則提供了一個解決思路。Ferdowsi等提出了一種新型對抗深度強化學習的方案,用于解決智能駕駛汽車在真實場景下測試的安全性問題[54]。然而,深度強化學習作為智能駕駛控制中較為常見的一種人工智能方法,也存在較多的挑戰。
多智能體強化學習是強化學習目前發展的一個主要方向。在真實的交通場景中,駕駛員的決策往往是多個交通參與者相互博弈的結果。這種場景并不完全符合強化學習的理論基礎——馬爾科夫性,即在智能駕駛應用中,狀態轉換不但依賴于智能體自身的策略,也包括環境中其他參與者的策略。多智能體強化學習方法,如minimax-Q learning、Nash-Q learning等,就是用于解決這一問題的。然而,多智能體強化學習的訓練算法比單智能體要復雜得多。
深度強化學習方法的另一難點是真實環境下的獎勵函數設計。在強化學習的設定中,智能體不斷探索環境并優化其策略,以獲得累積的獎勵最大化。獎勵函數對于引導智能體訓練并獲得理想的策略至關重要,然而,在強化學習的實例中,獎勵函數往往由系統設計人員手動編碼,并未經過精心設計。雖然某些任務存在明顯的獎勵函數,如財務利潤、游戲得分等,但是現實中的很多任務,其獎勵函數都是未知的,真實環境中的獎勵往往需要在多個因素之間進行權衡。錯誤或者不合理的獎勵函數可能會造成智能體收斂到錯誤的方向或者得到并非最優的策略。以智能駕駛為例,不但要考慮安全性、穩定性,還要考慮如何讓智能體學習到的行為策略更加符合人類駕駛習慣。北京聯合大學的智能駕駛團隊通過采集人類駕駛員的駕駛數據,并對其進行分析,再利用反向強化學習方法優化獎勵函數,引導智能體在縱向控制方面更加符合人類駕駛習慣,提高跟車行駛的舒適性[41]。對于如何獲取真實的獎勵函數,模仿學習和反向強化學習都提供了較好的解決思路。研究獎勵函數對智能體最終行為特性的影響也是智能駕駛中的一個研究熱點[55]。
4 結束語
智能駕駛車輛的控制層是整個分層系統中的一個關鍵環節,良好的橫縱向控制能夠保證車輛行駛的安全性和舒適性。智能駕駛車輛的控制方法可分為傳統方法和基于人工智能的方法。傳統方法多基于精確的數學模型或者基于規則設計,然而在真實世界中,交通場景復雜多變,難以設計精確的數學模型,規則的數目也會隨交通場景的復雜程度呈指數增長。人工智能方法的應用使得控制系統可以與環境交互并自主學習和優化,這種學習型控制器在充分探索環境并進行訓練后能夠更好地應對復雜的交通場景。對比兩者,傳統方法相對比較成熟,具有較強的數學可解釋性,可通過調整數學模型參數來優化控制效果,然而復雜的高精度數學模型的求解仍然比較困難,難以保證實時性。人工智能方法的數學可解釋性較差,但是其通過訓練優化模型的自學習能力和應對高維特征的處理能力都是傳統方法不具備的。在某些應用中,人工智能方法也可以和傳統方法進行互補,如優化代價函數的求解及復雜模型的建模等。人工智能技術在智能駕駛領域展示出廣闊的應用前景,但仍然面臨諸多挑戰。這也是該領域在未來進一步的研究方向,包括在多個復雜環境下的多智能體強化學習問題,在真實交通環境中的遷移、部署和測試問題,以及塑造符合人類駕駛員特性的獎勵函數問題。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
商界(2019年12期)2019-01-03 06:59:05
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
IT經理世界(2018年20期)2018-10-24 02:38:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
