基于注意力機(jī)制的前方道路場景識(shí)別算法
2022-08-03 02:41:20李學(xué)偉張同宇樂海豐
北京聯(lián)合大學(xué)學(xué)報(bào) 2022年3期
溫 爽,李學(xué)偉,張同宇,樂海豐
(1.北京聯(lián)合大學(xué) 城市軌道交通與物流學(xué)院,北京 100101;2.北京交通大學(xué) 經(jīng)濟(jì)管理學(xué)院,北京 100044;3.北京聯(lián)合大學(xué) 北京市信息服務(wù)工程重點(diǎn)實(shí)驗(yàn)室,北京 100101)
0 引言
由于我國機(jī)動(dòng)車的保有量不斷上升,而路網(wǎng)的建設(shè)相對(duì)緩慢,容易引起交通擁堵和安全事故[1],通過深度學(xué)習(xí)技術(shù)進(jìn)行輔助駕駛成為學(xué)術(shù)界的熱點(diǎn)話題[2]。近年來,深度學(xué)習(xí)作為一種新興的圖像處理算法,由于其具有識(shí)別精度高、泛化性能強(qiáng)的特點(diǎn)而受到廣泛關(guān)注[3-4]。隨著計(jì)算機(jī)性能和圖像算法的發(fā)展,高性能計(jì)算機(jī)、圖像加速計(jì)算單元等硬件條件的提高為深度學(xué)習(xí)提供了堅(jiān)實(shí)的基礎(chǔ),使用深度學(xué)習(xí)方法提取圖像的特征已成為計(jì)算機(jī)視覺領(lǐng)域的研究熱點(diǎn)[5-6]。隨著深度學(xué)習(xí)領(lǐng)域研究的不斷深入,卷積神經(jīng)網(wǎng)絡(luò)已在多個(gè)領(lǐng)域得到應(yīng)用,主要有圖像分類、人臉識(shí)別、目標(biāo)檢測和無人駕駛等領(lǐng)域[7]。基于深度學(xué)習(xí)的任務(wù)逐漸增多,圖像分類任務(wù)和目標(biāo)檢測任務(wù)作為計(jì)算機(jī)圖像處理中常見的工作任務(wù),也在不斷促進(jìn)識(shí)別技術(shù)的進(jìn)步,相比于傳統(tǒng)機(jī)器學(xué)習(xí)方法而言,深度學(xué)習(xí)方法的準(zhǔn)確性和實(shí)用性得到有效提升[8-9]。
在圖像分類任務(wù)中,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)被廣泛使用,使用二維卷積計(jì)算能夠提取到圖像的空間信息。基于ImageNet數(shù)據(jù)集舉辦的圖像分類大賽ILSVRC產(chǎn)生較大影響[10]。隨著計(jì)算技術(shù)的發(fā)展和圖像數(shù)量的不斷增長,各研究機(jī)構(gòu)按照實(shí)際任務(wù)需求整理出各類數(shù)據(jù)集,用于解決圖像分類問題的算法模型也在不斷更新[11-12]。在大部分領(lǐng)域中,計(jì)算機(jī)的圖像分類精度已取得良好效果[13]。
目前,單標(biāo)簽的圖像分類問題可以分為以下3類:跨物種語義級(jí)別的圖像分類、細(xì)粒度圖像分類和實(shí)例級(jí)圖像分類。跨物種語義級(jí)別的圖像分類用于區(qū)別不同類別的對(duì)象,常見的分類場景有貓狗分類、果蔬分類等。在物種級(jí)別的分類任務(wù)中,由于目標(biāo)對(duì)象所屬的物種或者類別不同,通常其外表特征和圖像語義差別較大,整體呈現(xiàn)出同種類別間對(duì)象差異小、不同類別間對(duì)象差異大的特征,所以可直接使用分類器對(duì)圖像特征進(jìn)行分類[14]。子類的細(xì)粒度圖像分類一般屬于同物種對(duì)象間的圖像分類任務(wù),如不同鳥類、不同花卉、不同犬類的分類等[15]。由于同種類物體通常呈現(xiàn)出類間差異小、難分類的特征,通用方法準(zhǔn)確率較低,所以細(xì)粒度分類任務(wù)需要針對(duì)數(shù)據(jù)進(jìn)行特殊處理。實(shí)例級(jí)圖像分類需要區(qū)分不同的實(shí)例,典型的任務(wù)有人臉識(shí)別。人臉識(shí)別需要根據(jù)不同個(gè)體的人臉特征進(jìn)行精準(zhǔn)分類來識(shí)別人的身份,從而達(dá)到考勤和身份認(rèn)證等功能。
道路場景識(shí)別情況較為復(fù)雜,介于跨物種語義級(jí)別的圖像分類和細(xì)粒度圖像分類之間,對(duì)網(wǎng)絡(luò)實(shí)時(shí)性有一定要求。本文在研究目前主流的圖像特征提取網(wǎng)絡(luò)LeNet5[16]、ResNet[17]和VGG[18]的基礎(chǔ)上,提出基于注意力機(jī)制的前方道路場景識(shí)別方法,提高道路場景識(shí)別的準(zhǔn)確率,用于在行駛過程中識(shí)別道路岔口,預(yù)防與路口車輛或行人發(fā)生碰撞。
1 算法改進(jìn)
1.1 ResNet殘差模塊
綜合考慮前方道路場景圖像識(shí)別的難度和對(duì)實(shí)時(shí)性的要求,本文對(duì)ResNet18網(wǎng)絡(luò)進(jìn)行改進(jìn),在盡可能不降低算法推理速度的條件下,提高識(shí)別的準(zhǔn)確率。ResNet18通過堆疊多個(gè)殘差模塊構(gòu)建(見圖1),殘差塊之間有一個(gè)跳躍的殘差連接,可以使網(wǎng)絡(luò)在訓(xùn)練階段避免由于網(wǎng)絡(luò)過深出現(xiàn)梯度彌散而制約模型訓(xùn)練的精度。

圖1 ResNet殘差結(jié)構(gòu)圖Fig.1 Residual Structure Diagram of ResNet
1.2 改進(jìn)后的網(wǎng)絡(luò)模型
基于注意力機(jī)制改進(jìn)的道路場景分類算法的設(shè)計(jì)分為3部分(見圖2):對(duì)輸入數(shù)據(jù)進(jìn)行動(dòng)態(tài)數(shù)據(jù)增強(qiáng)的預(yù)處理部分、基于空間注意力機(jī)制的特征提取網(wǎng)絡(luò)和用于網(wǎng)絡(luò)輸出的分類器。輸入數(shù)據(jù)為經(jīng)過隨機(jī)裁剪和Mixup混合后的增強(qiáng)圖像,經(jīng)特征提取骨干網(wǎng)絡(luò)后得到512×7×7的特征圖,最后使用全局平均池化和全連接輸出分類結(jié)果。ResNet18的特征提取層主要包括5個(gè)卷積塊,在網(wǎng)絡(luò)中插入基于空間注意力機(jī)制的Attention模塊(見圖2虛線框部分),用于整合圖像的空間信息,增強(qiáng)模型性能。
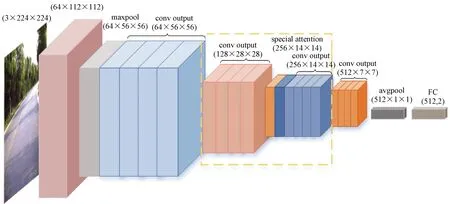
圖2 改進(jìn)ResNet18網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Optimized ResNet18 Network Structure
空間注意力模塊結(jié)構(gòu)如圖3所示,將卷積塊輸出為256×14×14的特征圖經(jīng)過均值池化和最大值池化后獲取兩個(gè)二維特征向量,經(jīng)過Concat拼接后進(jìn)行卷積計(jì)算,得到一個(gè)二維空間注意力特征圖,再將其與輸入的特征圖按元素相乘獲得注意力模塊輸出結(jié)果。其中,普通卷積層使用ReLU作為激活函數(shù),Attention模塊中的卷積層使用Sigmoid作為激活函數(shù)。

圖3 空間注意力模塊結(jié)構(gòu)Fig.3 Spatial Attention Module Structure
2 實(shí)驗(yàn)
2.1 實(shí)驗(yàn)環(huán)境
在實(shí)驗(yàn)過程中,服務(wù)器設(shè)備采用Ubuntu 20.04系統(tǒng),深度學(xué)習(xí)框架為PyTorch 1.7.1,CPU為Xeon(R) Gold 6230R,內(nèi)存為128 G,GPU為NVIDIA GeForce 3090×2,搭建PyTorch 1.7.1深度學(xué)習(xí)環(huán)境。PyTorch是開源的神經(jīng)網(wǎng)絡(luò)框架,在圖像向量計(jì)算中針對(duì)GPU進(jìn)行加速,極大地降低了圖像算法的編程門檻,成為研究人員目前首選的深度學(xué)習(xí)框架。基于深度學(xué)習(xí)的圖像分類流程主要包括3個(gè)部分,分別是數(shù)據(jù)準(zhǔn)備、模型學(xué)習(xí)和測試驗(yàn)證。
2.2 數(shù)據(jù)集
本文的實(shí)驗(yàn)數(shù)據(jù)集采集自北京市的多條街道,我們將采集好的視頻進(jìn)行分幀后轉(zhuǎn)換成圖片,篩選質(zhì)量較好的圖片作為數(shù)據(jù)集的圖片來源,包括路口和路段圖像共1 551張,樣例如圖4所示。由于采集設(shè)備的不同導(dǎo)致數(shù)據(jù)差異較大,為了提升模型訓(xùn)練效果,對(duì)通過不同設(shè)備采集得到的圖像進(jìn)行統(tǒng)一裁剪、色彩均衡等預(yù)處理。

圖4 道路場景圖像數(shù)據(jù)集樣例Fig.4 Dataset Example of Road Scene Image
為了防止訓(xùn)練過程中的過擬合導(dǎo)致模型泛化性能差,需要對(duì)數(shù)據(jù)集圖像進(jìn)行數(shù)據(jù)增強(qiáng)處理。根據(jù)目標(biāo)任務(wù)和已有的先驗(yàn)知識(shí),采用隨機(jī)圖像平移、水平翻轉(zhuǎn)等方式處理圖像,保證在目標(biāo)特征不變的情況下對(duì)數(shù)據(jù)集進(jìn)行擴(kuò)充。增強(qiáng)后的數(shù)據(jù)集共有6 000張圖像,隨機(jī)打亂數(shù)據(jù)集順序,并按照70%、10%、20%的比例劃分為訓(xùn)練集、驗(yàn)證集和測試集。其中,訓(xùn)練數(shù)據(jù)在模型訓(xùn)練階段用于迭代更新模型參數(shù),驗(yàn)證數(shù)據(jù)用于監(jiān)控模型的訓(xùn)練效果,測試數(shù)據(jù)用于評(píng)估模型最終的性能。
2.3 對(duì)比實(shí)驗(yàn)
將路段、路口照片分開后隨機(jī)打亂順序,并按比例劃分?jǐn)?shù)據(jù)集。模型輸入圖像采用經(jīng)縮放后大小固定的RGB圖像,縮放方法為雙線性插值法。在訓(xùn)練和推理階段使用不同的采樣策略:在模型訓(xùn)練時(shí)使用隨機(jī)縮放和隨機(jī)裁剪,在推理驗(yàn)證時(shí)則使用縮放和中心裁剪策略,以提升數(shù)據(jù)多樣性。在訓(xùn)練的初始階段,學(xué)習(xí)率為0.001,正則化項(xiàng)衰減系數(shù)為0.000 1;在訓(xùn)練時(shí),使用隨機(jī)梯度下降法優(yōu)化,每迭代50次進(jìn)行一次學(xué)習(xí)率衰減,衰減系數(shù)為0.9,使模型參數(shù)進(jìn)一步收斂。使用LeNet5、VGG16、ResNet18和改進(jìn)的ResNet18等模型分別對(duì)場景分類數(shù)據(jù)集進(jìn)行訓(xùn)練驗(yàn)證,控制試驗(yàn)變量,保證除模型外的其他條件均相同,訓(xùn)練階段的訓(xùn)練損失曲線和驗(yàn)證準(zhǔn)確率分別如圖5和圖6所示。

圖5 多個(gè)模型在道路場景數(shù)據(jù)集上訓(xùn)練損失曲線圖Fig.5 Training Loss Curve on Road Scene Dataset from Multiple Models
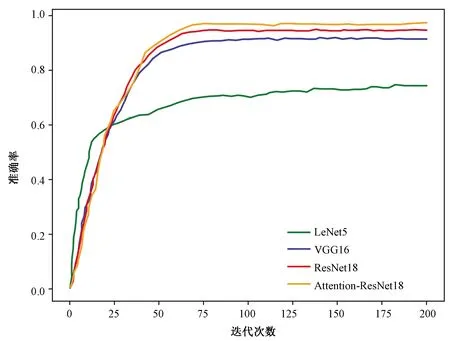
圖6 多個(gè)模型在道路場景數(shù)據(jù)集上驗(yàn)證準(zhǔn)確率曲線圖Fig.6 Verification Accuracy Curve on Road Scene Dataset from Multiple Models
3 實(shí)驗(yàn)結(jié)果分析
分類準(zhǔn)確率通常用于評(píng)估模型的好壞,準(zhǔn)確率越高,表明分類器分類的效果越好。分類準(zhǔn)確率的計(jì)算方法為
(1)
式中:A為準(zhǔn)確率;Tp(True positives)為被正確劃分為正例的個(gè)數(shù),即實(shí)際為正例且被分類器劃分為正例的實(shí)例數(shù)(樣本數(shù));Tn(True negatives)為被正確劃分為負(fù)例的個(gè)數(shù),即實(shí)際為負(fù)例且被分類器劃分為負(fù)例的實(shí)例數(shù);N為分類的總樣本數(shù)量。本實(shí)驗(yàn)將路口樣本作為正例,路段樣本作為負(fù)例。
在模型訓(xùn)練階段結(jié)束后,對(duì)場景識(shí)別數(shù)據(jù)集中的路口和路段圖像進(jìn)行分類,使用3個(gè)基礎(chǔ)模型和改進(jìn)后的ResNet18模型在道路場景數(shù)據(jù)集的測試集上進(jìn)行測試,測試數(shù)據(jù)均為所有模型迭代訓(xùn)練200次后的測試結(jié)果。模型的測試結(jié)果如表1所示。

表1 模型的測試準(zhǔn)確率統(tǒng)計(jì)Table 1 Test Accuracy Statistics of Models
結(jié)合圖6和表1可以看出,LeNet5由于模型結(jié)構(gòu)簡單,在訓(xùn)練前期更容易擬合數(shù)據(jù),然而隨著迭代次數(shù)的增加開始達(dá)到模型擬合上限。與VGG16和ResNet18的訓(xùn)練結(jié)果對(duì)比可以發(fā)現(xiàn),LeNet5對(duì)于該組數(shù)據(jù)的擬合程度較低。測試結(jié)果與驗(yàn)證結(jié)果一致,其中,ResNet18相較于VGG16獲得了更好的實(shí)驗(yàn)效果。由于相對(duì)于VGG16,ResNet18的參數(shù)較少,且其殘差結(jié)構(gòu)在訓(xùn)練時(shí)更容易擬合數(shù)據(jù),所以,我們基于注意力機(jī)制對(duì)ResNet18進(jìn)行了改進(jìn)。最終實(shí)驗(yàn)效果顯示,改進(jìn)后的Attention-ResNet18在準(zhǔn)確率上提升了1.2%。
4 結(jié)束語
本文使用基于注意力機(jī)制的改進(jìn)卷積神經(jīng)網(wǎng)絡(luò)模型對(duì)道路場景分類進(jìn)行了分析、測試和研究。由于行駛車輛對(duì)前方道路場景識(shí)別的實(shí)時(shí)性要求較高,本文對(duì)比分析了多種主流深度學(xué)習(xí)算法,對(duì)網(wǎng)絡(luò)規(guī)模較小的ResNet18模型進(jìn)行改進(jìn),并加入空間注意力模塊進(jìn)行優(yōu)化,提高了圖像識(shí)別的準(zhǔn)確率,從而提升模型分類效果。實(shí)驗(yàn)結(jié)果表明,在復(fù)雜交通路況下,基于注意力機(jī)制改進(jìn)后的ResNet18模型在道路場景數(shù)據(jù)集上的識(shí)別準(zhǔn)確率達(dá)到91.5%。實(shí)驗(yàn)對(duì)3種經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò)模型和基于注意力機(jī)制改進(jìn)的模型進(jìn)行對(duì)比討論,并分析了模型結(jié)構(gòu)與數(shù)據(jù)預(yù)測的相關(guān)內(nèi)容,我們后續(xù)將不斷優(yōu)化方法,達(dá)到在實(shí)際場景下輔助駕駛的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
