高校圖書館典型用戶群體電子資源行為數據分析實證研究*
——基于創文圖書館電子資源綜合管理與利用系統
2022-08-04 12:39:40刁羽薛紅
新世紀圖書館 2022年7期
0 引言
隨著互聯網技術的發展以及大數據時代的到來,科研數據應用呈現開放共享的大趨勢,電子資源已成為用戶獲取信息的主要來源。訪問電子資源的行為數據能精準地反映出用戶在教學、科研等方面的信息需求。一般而言,用戶電子資源行為數據(以下簡稱“行為數據”)受用戶信息素養與學術素養共同影響,通過用戶瀏覽、下載、檢索等行為,既可以反映用戶在線檢索技巧的熟悉程度和意識強弱,又可以反映用戶對科研學科領域的熟悉程度,以及研究任務的學術深度。但是,行為數據的采集、整理、分析是一項艱巨的任務,目前業界很少有這方面的實證研究。為了踐行這一目標,同時降低數據采集的廣度及難度,本文通過具體案例,闡明如何通過對典型用戶群體行為數據及其學歷、職稱、科研成果等相關數據的交叉融合分析,預測用戶行為,顯性化用戶資源利用行為的規律與特征,以此實現電子資源與用戶個性化需求的精準化、精細化對接,從而為推進圖書館學科服務向縱深化發展提供有益參考與借鑒。
1 基于創文系統的行為數據研究分析介紹
目前,業界對利用大數據進行個性化學科服務的研究和實踐方興未艾,筆者在實踐中發現有以下難點:受人力、資源、技術設備等因素的制約,對于大多數高校圖書館來說,既難以廣泛搜集全體用戶的各方面數據,也難以分析處理大數據;學科館員個人所具有的學科知識儲備尚達不到用戶對嵌入式學科服務的需求;學科館員嵌入服務前沒有形成服務預案或服務預案不完備,導致科研工作者對盲目式的嵌入服務有排斥心理。對于上述情況,行為數據正是解決這些難點的利器。該數據具有類型單一、價值密度高等特點。本文從創文圖書館電子資源綜合管理系統(以下簡稱“創文系統”)入手,抽取典型用戶群體中的具體案例,通過分析、挖掘其利用電子資源的行為數據,揭示出該群體利用電子資源的偏好、使用規律及研究的學科領域等特征,緊貼用戶需求,以期為用戶提供有準備、有目標、有內容的服務。這種服務模式有利于增強用戶粘性、提高用戶滿意率,旨在在精準化、精細化、個性化的資源推薦過程中,進一步拓展圖書館學科服務的深度和廣度。
1.1 研究群體
本文所指的典型用戶群體是使用校外訪問系統的頻次位于前25%位的教師群體,并同時具備以下條件之一:在學校所屬學科領域科研工作中具有較大影響力;副高及以上職稱者;博士研究生;年度科研積分在教師群體中位于前25%。選取典型用戶群體的優點在于:第一,該群體區別于全體用戶,分析結果具有明顯的區分度和針對性,能更準確地定位用戶的需求,并在對重點群體實行重點跟蹤服務的過程中,提高服務效率,提升服務內涵;第二,該群體對電子資源的高利用率能保證有足夠的樣本數量,同時使分析結果具備統計學意義;第三,高利用率也體現出該群體對文獻資源的較高需求,利于與其建立良好的溝通機制;第四,該群體本身具備較強的科研工作能力及較高的學術影響力,能夠對本文的研究起到積極的推動作用;第五,行為數據也反映了用戶真實的信息需求,通過分析該數據,可以很好地跟蹤用戶的研究方向,并準確找到嵌入式服務的契合點。
1.2 研究系統
四川輕化工大學圖書館于2016年引入了校外訪問系統,即創文系統。該系統可以讓廣大用戶在校外隨時隨地通過各種前端設備(PC或移動設備)訪問校圖書館購買或自建的、遠程或本地的所有電子資源,同時該系統詳細記錄了具體用戶利用電子資源時瀏覽、檢索、下載的行為數據
。現階段,絕大多數數據庫都是基于校園網IP地址作身份認證的權限訪問,學校網關Web日志中用戶訪問網絡資源行為數據又包含有大量涉及個人隱私的敏感數據,因此難以從以上兩個途徑獲取具有個體信息的訪問電子資源行為數據。創文系統數據在一定程度上能體現出用戶訪問電子資源的總體情況并符合本文對樣本數據的需求,因此,本文研究的數據源于從創文系統中提取的行為數據。與此同時,筆者前期已經實現了從創文系統的訪問日志文件中提取用戶行為數據,也詳細介紹了行為數據的數據結構,以及如何對這些數據進行清洗,并最終將其存儲在SQL Server數據庫中的技術和方法
。
1.3 研究方法
本文以圍繞典型用戶群體為選取原則,提取主要研究方向為高性能硬質合金及金屬陶瓷制備,具有高級職稱、作為特殊人才引進的某中青年教師于2019年5月至2021年5月在創文系統上的行為數據為樣本數據進行分析和挖掘。限于篇幅,涉及的重點在于該用戶多維度的檢索詞分析過程。主要分析方法有以下幾個方面:第一,通過對瀏覽、下載、訪問等用戶行為在時間軸上的計數,反映用戶的總體訪問特征;第二,分析用戶的檢索詞,對檢索詞的基本構成進行歸類,對用戶輸入的檢索詞進行分詞處理;第三,利用Python統計詞頻,利用EXCEL計算檢索詞的檢索次數、四分位數、眾數等描述性統計量;第四,利用Pythoon和WorldCloud繪制高頻檢索詞的詞云圖;第五,提取高頻檢索詞,利用Python建立共詞矩陣和相關系數矩陣,并用Gephi繪制知識圖譜,揭示用戶最感興趣的學科領域;第六,結合中圖法的相關類目進行關鍵詞分析,對用戶的檢索詞進行分析并優化,幫助用戶更加精準地獲取文獻信息;第七,通過其他相關關鍵詞分析,幫助用戶拓寬研究思路。
4.交代時間、地點、人物或中心事件。《聽潮》開頭:“一年夏天……”交代事情發生的時間、地點、人物。《故鄉》開頭:“我冒了嚴寒……”時間、地點、人物和中心事件均有所交代。記敘類的文章多以這樣的方式開頭。
2 創文系統用戶訪問的時間規律和成果產出關系
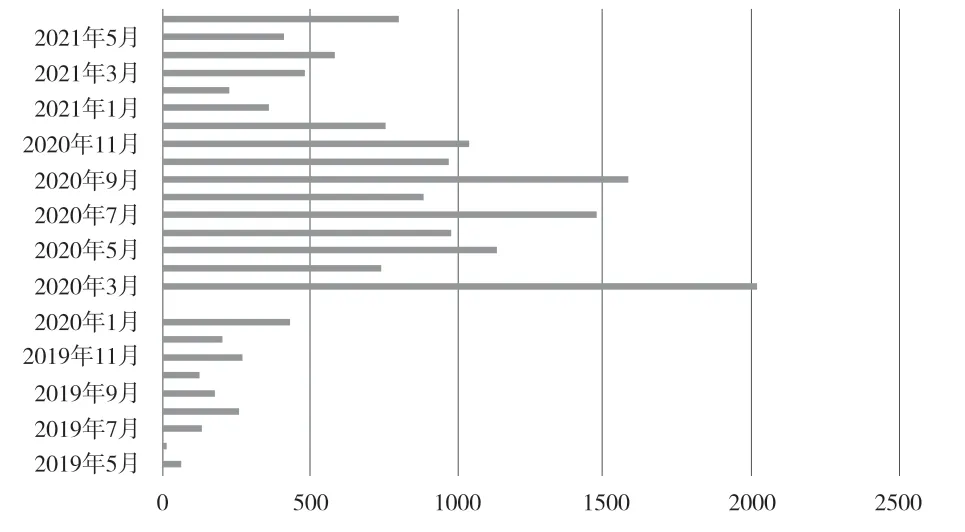
訪問量的多少是反映用戶利用電子資源意愿的直接指標。本文從時間維度進行統計,全面、直觀地揭示出用戶在2019—2021年的訪問規律。從圖1可以看出,該用戶在2019各月份的訪問次數最少,2020年各月份的訪問次數最多,高峰期主要集中在2020年2月、7月、9月,即寒暑假期間,而2021年用戶訪問次數相對于2020年呈現下降趨勢。同時,筆者在CNKI上進行檢索,發現該用戶在2019至2021年期間共計發文9篇,其中2020年5篇、2021年2篇。據呈現的狀態可以推測出該用戶的科研成果產出高峰與其年份訪問高峰基本趨于吻合。由此可見,校外訪問系統中的電子資源在用戶科研過程中起到了較大推動作用;電子資源的訪問頻率能在一定程度上反映用戶科研需求狀態及科研成果的產出效率。
第二,在制定會計準則時,考慮不到不同利益集團的需要,注重基本原則的指導,同時要相應增加實施的細則,不能只依靠會計人員的經驗。
3 創文系統用戶訪問的資源偏好
電子資源的偏好是體現用戶檢索特征的重要指標。本文通過對用戶選擇數據庫的偏好、資源語種及瀏覽、檢索、下載行為等進行統計發現如下情況。該用戶選擇的數據庫中,知網占比達到了總訪問量的96.12%;該用戶訪問的資源語種主要是中文,外文數據庫的訪問量只有0.6%。從該用戶檢索、瀏覽、下載的次數可以看出,用戶進行1次檢索后,平均只有4次查看了檢索結果的詳細頁,有1.6次下載了文獻。同時,用戶在2年多的時間內下載了近4000篇文獻。從瀏覽和下載的有效性及文獻下載量來看,該用戶的檢索結果大多不盡如人意,可預測出該用戶的檢索意圖多趨于模糊,檢索結果難以契合用戶本身的科研需求。
由此分析,需加強以下幾個方面的工作:其一,對用戶個體檢索能力及科研需求內涵進行全面評估,在此基礎上精細化培訓方案,促使用戶在有針對性的培訓過程中提高檢索效率,縮短科研周期;其二,優化電子資源的配置,加大電子資源宣傳推廣工作,提高電子資源的使用率,使其最大限度地滿足用戶科研需求;其三,對數據庫商提出意見和建議,如進一步完善數據庫檢索界面、優化及增加平臺檢索功能,以期提升資源檢索效率,促進用戶滿意度。
4 創文系統用戶使用的檢索詞分析
4.1 檢索詞的構成分析
從提取的數據可以看出,用戶的檢索詞由以下幾種形式構成:第一,純粹的專業術語,可能是一個或多個,如果是多個,使用空格、“+”“-”等符號組成,如“碳化+WC”;第二,語句式檢索詞,其包括專業術語和“如何”“淺談”“發展”等無檢索意義的詞語,如“超硬材料行業的發展”;第三,單純的以作者名為檢索詞或采用“作者+關鍵詞”這種復合檢索式,如“張立 硬質合金”;第四,文獻篇名;第五,單純以標準號檢索或采用“標準號+關鍵詞”這種復合檢索式,如“GB/T 13313-2008 軋輥肖氏、里氏硬度試驗方法”。
從檢索詞的構成分析中可以總結出該用戶檢索過程存在一些不足:使用類似百度等搜索引擎的檢索表達式在CNKI中進行檢索,導致查全率和查準率不高;檢索作者時常常只使用作者名為檢索詞,導致檢索結果過多且不精確;當有比較明確的檢索點時,使用其他關鍵詞反而會影響檢索結果,如前文提到的“標準號+關鍵詞”這種復合檢索式;從未使用中圖分類號作為檢索詞。
4.2 檢索詞的分詞處理
用戶每次檢索使用的檢索詞常常由多個關鍵詞構成,將每個關鍵詞從檢索詞中分離出來是下一步進行具體關鍵詞分析的必要前提。本文使用Python和Jieba
對用戶的檢索詞進行分詞。雖然Jieba是目前較為流行的分詞庫,但有以下幾點需要注意,否則會產生大量分詞錯誤的問題。第一,創建自定義詞表。雖然Jieba使用HMM模型和Viterbi算法讓自己具有一定的新詞識別能力,但其自主學習的功能仍很薄弱,而且用戶輸入的檢索詞含有大量其研究領域的專業術語,如拋釉磚、炭相、石墨烯等,使用Jieba自帶的語料庫不能正確識別它們,因此需要添加自定義詞典,并使用Jieba的load_userdict( )函數加載,這樣才能確保Jieba正確識別上述詞語。第二,處理特殊字符。因用戶的專業領域涉及大量的分子式,如WC-Ti(C_N)-Co。這些分子式含有大量的特殊字符,若單純地將這些分子式添加到自定義詞表并不能生效,故要對Jieba根目錄下的__init__.py文件和Jieba根目錄下posseg文件夾中的__init__.py進行修改
。如此,才能讓Jieba正確識別分子式中的特殊字符。第四,建立停用詞表。用戶檢索詞中包含大量“淺談”等無檢索意義的詞語,分詞時需要將這些詞語剔除。故需要創建一個停用詞詞表,將分詞結果與停用詞表中的詞語進行比較,然后從中刪除存在于停用詞表中的詞語。第五,反復迭代。添加自定詞典和創建停用詞表是一個比較繁瑣的工作,需要反復比較、反復迭代才能獲得較高的準確性。
4.3 檢索詞多維度分析
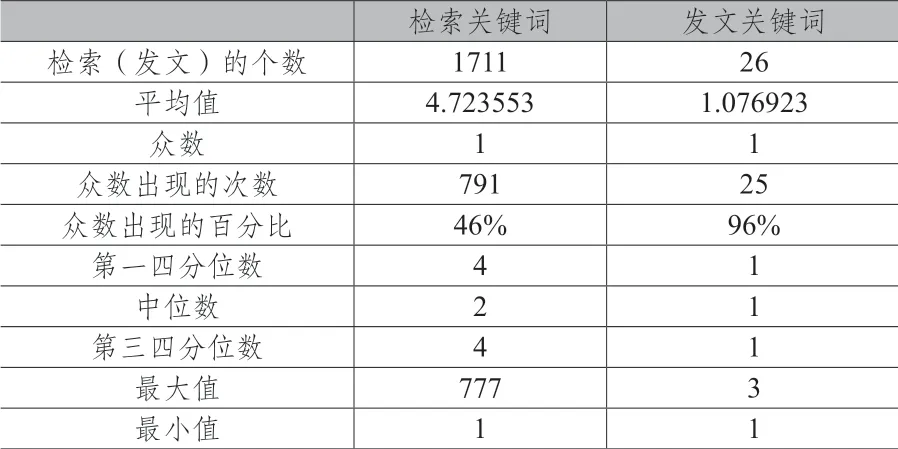
檢索、發文關鍵詞的對比分析能揭示出用戶的科研方向與其檢索文獻的吻合度。表1顯示:第一,從檢索關鍵詞看,其眾數和最小值都是1,共有791次,占總檢索關鍵詞檢索次數的46%,中位數為2,第三、四分位數是4。從發文關鍵詞看,其眾數和最小值都是1,共有25次,占總發文關鍵詞出現次數的96%,以上數據推測該用戶的研究方向可能趨于模糊;第二,用戶的檢索和發文出現最多次數的關鍵詞是相同的,同時在用戶發文關鍵詞中,通過統計有20個是其檢索文獻使用的關鍵詞,這些詞在檢索中最少出現次數是1,最多出現次數是777。通過檢索、發文關鍵詞的對比分析能幫助用戶梳理、回顧整個研究過程中關鍵詞的變化歷程,同時可參考將用戶發文關鍵詞在檢索時次數的多少作為判斷推送文獻的優先級的標準,以此實現文獻的精準推薦。
后現代主義知識觀認為,知識以其自組織性、不確定性、非線性和解釋性,能夠在教學中不斷創生。知識并非像知識本體論認為的具有確定性,也非本體論規定的具有先驗性。羅蒂(R Rorty)觀點認為:教學任務不是簡單的知識傳遞和道德教化的過程,教學該是即時創作,是師生的共同解讀,知識能在動態的即時創作中變得鮮活。即時創作的教學觀下,教師對知識的權威,學生作為知識的容器,以及教材是知識載體的看法不再成立。
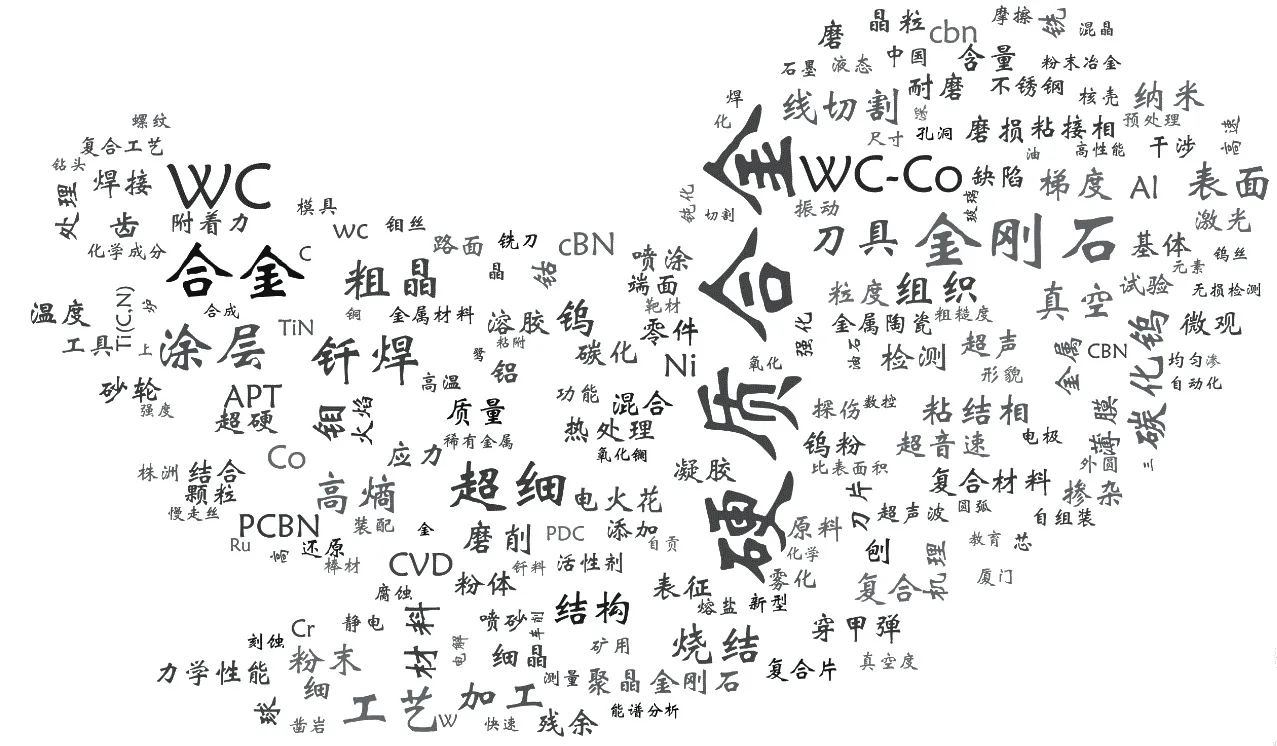
詞頻顯示了用戶對檢索詞所對應的相關學科領域的關注度。結合Python 和Pandas 模塊,可以方便地統計檢索詞分詞后的關鍵詞檢索詞頻。統計詞頻的基本原理是將分詞后的關鍵詞轉換為Series,然后調用Pandas 中的value_counts( )函數計算每個關鍵詞出現的頻次。在此基礎上,為了更形象、直觀地展示用戶檢索詞的頻次關系,本文使用Python 和WordCloud
為檢索次數≥5 的關鍵詞生成 “高頻關鍵詞詞云圖”。詞云圖中關鍵詞的字號大小代表了檢索頻次的多少。從圖2 中可以清晰、直觀地看出在該用戶訪問過程中,“硬質合金”“合金”“金剛石”“WC”“WC-Co”等是出現頻率較高的關鍵詞。將高頻檢索關鍵詞結合用戶的科研成果,可精準掌握其主要研究方向為“高性能硬質合金及金屬陶瓷的制備”。通過高頻關鍵詞分析,可精確掌握用戶研究方向,并在此基礎上提前做好工作預案,使服務做到有的放矢。
本研究采用紅茶浸泡除腥的方式,研究紅茶脫腥處理對海螺肉感官和品質特性的影響,并對海螺肉中的揮發性成分進行分析。此外,實驗以菌落總數為微生物指標,以TBA值、pH為理化指標,研究經紅茶脫腥處理的海螺肉在貯藏過程中的品質變化,評價紅茶脫腥處理對海螺肉的抑菌保鮮效果。
4.3.1 高頻關鍵詞分析,精準掌握研究方向
4.3.3 關鍵詞共現分析,發掘研究方向
共現分析揭示了檢索關鍵詞之間的共現關系,它體現了用戶感興趣的不同學科領域之間聯系的緊密程度。本文利用Python和Pandas庫創建關鍵詞共詞矩陣和關鍵詞相關系數矩陣,并選取檢索詞頻≥20的52個關鍵詞創建上述兩個矩陣。
創建共詞矩陣的主要步驟如下:
步驟一:使用set( )函數為這52個關鍵詞創建集合。
步驟二:將用戶每次輸入的檢索詞分詞后的結果存儲為list列表。
for(i in1∶2 000){x=runif(n,0,1); y=(sum(x)-n×0.5)/sqrt(n/12); A[i]=y}
步驟三:使用pd.DataFrame(0, columns=key_set, index=key_set)語句初始化全0共詞矩陣,其中的key_set參數的值為這52個高頻關鍵詞集合,目的是將它們指定為Dataframe的行、列索引。
步驟四:遍歷用戶檢索詞分詞列表,并取其與高頻詞的交集。當交集的元素個數大于1時,表示高頻詞間有共詞關系。
本文利用Ochiia系數
將共詞矩陣轉換為相關系數矩陣。Ochiia系數的計算公式如下:
其中,O
為Ochiia系數,N
代表檢索詞A和B同時出現的頻次,N
和N
分別代表A檢索詞和B檢索詞出現的總頻次。
當第一閾值在波峰1,2之間時,若不進行特征點一致性補償,則特征點t2將會提前一個周期,在波峰5下降沿的過零點處,此時若要保證特征點一致則到達特征點時間應調整為t1;當第一閾值在波峰3,4之間時,若不進行特征點一致性補償,則特征點t2將會滯后一個周期,在波峰7下降沿的過零點處,此時若要保證特征點一致則到達特征點時間應調整為t3。綜上所述,到達特征點時間T應根據第一閾值所在位置選取為:
步驟五:兩次遍歷該交集的元素,外循環從第一個元素開始直到最后一個元素,內循環從第二個元素開始直到最后一個元素。
隨著2016年我國加入華盛頓成員國,國內高校掀起工程教育國際認證的浪潮。工程教育認證中強調學生的實作技能,鼓勵課程設計/畢業設計能出實際作品,鼓勵學生以團隊合作的形式完成,這是頂石(Capstone)的基本要求。3D打印技術是實現產品從電腦屏幕到實物最為便捷的方式,具有時間和成本優勢,從而備受關注和學生喜愛。從專業認證的發展需求看,3D打印技術在高校中的應用將逐步擴大。
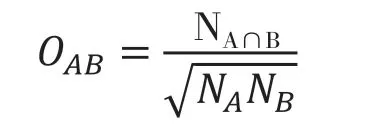
步驟六:遍歷時,首先將共詞矩陣行、列索引分別與外、內循環的元素名相同的位置元素的數值加1;然后將共詞矩陣列、行索引分別與外、內循環的元素名相同的位置元素的數值加1。
4.3.2 檢索、發文關鍵詞對比分析,精準文獻推薦
使用該公式,就是在共詞矩陣的基礎上創建相關系數矩陣。基本方法與創建共詞矩陣大同小異,要注意兩點:其一,將共詞矩陣對角線上代表高頻檢索詞的詞頻元素的數值由0改寫為相應的詞頻;其二,遍歷元素是要利用Ochiia系數公式計算相應的值。
利用式(4)通過節點域的上下邊界和期望值,得到每個指標變量的最優值如表4。綜合權重為0.520,0.292,0.188。
最后,在相關系統矩陣的基礎上,利用Gephi軟件
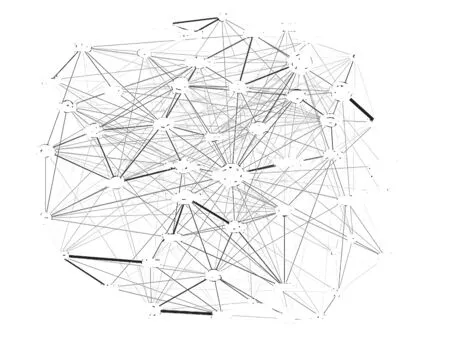
繪制用戶檢索關系詞的共現關系圖(如圖3)。圖中的每個節點代表一個高頻關鍵詞,點的大小代表了頻次的多少。節點之間的邊的粗細代表了節點相關性的大小。在圖3中,可以看出硬質合金、工藝、金剛石等是用戶檢索次數最多的關鍵詞,而金剛石與薄膜、金剛石與涂層、凝膠與溶膠等是相關性很高的關鍵詞。通過關鍵詞共現分析結果向用戶推薦相關性較高的關鍵詞進行組合檢索,可在進一步提高文獻推送準確性的同時,幫助用戶發掘新的研究方向及交叉學科增長點。
4.3.4 結合中圖法分析檢索關鍵詞,提升用戶研究成效
中圖分類號能夠有效地將檢索結果限定在需要的學科范圍,是用戶提高檢索效率的重要工具。將該用戶檢索過程中使用的高頻關鍵詞與中圖法中的學科分級類目進行比對,發現如TG135.5硬質合金、TG146.4稀有金屬及其合金、TG146.411鎢、TG146.412鉬等能對應或包含用戶使用的高頻關鍵詞。再如,“焊接”是用戶使用較為頻繁的檢索關鍵詞,比照中圖法類目,發現“TG4焊接、金屬切割及金屬粘接”與之相符,其下位類還包括焊接材料、焊接工藝、焊接設備等類目。
綜上,結合中圖分類號和檢索關鍵詞,通過中圖分類號將文獻的學科類別限制在用戶研究領域內,既能幫助用戶提高文獻檢索的查準率,又能充分拓展其研究方向,從而達到綜合提升用戶研究成效的目的。
4.3.5 其他相關關鍵詞分析,拓寬用戶思路
該用戶在檢索中還涉及到其他不直接反映學科領域的相關關鍵詞,即標準號和作者。通過這些關鍵詞分析,既可以間接圍繞用戶研究學科領域進行分析,也能夠對該用戶整個檢索詞分析體系進行完善和補充。第一,標準號。如以BS ISO 513-2012和DIN ISO 513-199為檢索點進行檢索,從檢索出來的標準名稱、中國標準分類號及國際標準分類號的類目名稱中提取對應的關鍵詞。發現有些關鍵詞如硬質合金等是用戶高頻關鍵詞之一,而有些關鍵詞如排屑等卻從未出現在用戶的檢索詞中。第二,作者。如搜索次數大于等于3次的有顏娟、廖軍、張立等,將重點關注的作者名與高頻關鍵詞相關聯進行組合檢索,發現這些作者均是從事硬質合金材料和技術研究的專家及本地企業工作者。
三是明確管護責任。針對不同工程的性質和特點,采取專業化管理、社會化管理和自主管理等多種方式,將工程管護責任落實到產權的所有者和使用者,同時健全管理制度約束管理主體,確保工程能夠正常地發揮效益,確保用水戶的利益不受損害。
為此,在為用戶提供檢索建議或文獻推送服務時,可將標準名稱、標準分類號類目名稱中從未出現的關鍵詞作為檢索點,幫助用戶擴大檢索結果,拓寬研究思路。同時,可進一步搜集用戶重點關注對象的科研背景信息及從事相關專業領域的的企業信息,為用戶衡量與對口企業合作的可行性提供決策性參考依據,并從中開拓出創造校企合作的價值空間。
“美麗中國”是黨的十九大提出作為建設社會主義現代化強國的重要目標,強調要推進綠色發展,構建清潔低碳、安全高效的能源體系。南方電網云南電網公司作為扎根云南、從事基礎產業和公共事業的中央企業,積極響應國家號召、主動承擔社會責任,全心全意為云南經濟社會發展服務,不斷加大充電基礎設施和車聯網平臺建設,全力助推云南省新能源汽車產業發展。
5 創文系統隱私保護探討
行為數據是研究用戶檢索行為和科研方向的重要信息源,也是圖書館做好學科服務的根本前提。近年來,國內外對安全、規范使用個人信息日益關注,“數據正義”(Data justice)這一理論也應運而生。目前“數據正義”作為一個發展中的理念,含義尚未定型,其中安全、規范使用個人信息是其核心思想。國家對個人信息的收集、存儲、處理做了明確規定,要求必須遵循“合法、正當、必要的原則”,特別是對利用用戶畫像等手段為用戶提供服務作了詳細、具體的信息安全規范
。另外,“數據正義”在數據可見性、用戶參與性和數據歧視三方面有著規范和約束,用戶對個人數據的采集、存儲及應用范圍須具有知情權
。《中華人民共和國國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要》強調,要統籌數據開發利用、隱私保護和公共安全,加快建立數據資源產權、交易流通、安全保護等基礎制度和標準規范
。以此為導向,本文在提取用戶個人數據的過程中特別注意保護用戶隱私,保證采集的手段、內容和用途對用戶保持透明,讓用戶自主選擇哪些行為數據、哪些時段、哪些網站的數據允許被采集,這些數據可以在哪些范圍內使用,同時用戶可以自主保存、刪除自己的數據,切實消除用戶顧慮。
6 結語
本文通過對典型用戶群體訪問創文系統行為數據多角度、多層次的分析,揭示出用戶資源利用的行為規律與特征,以期促進圖書館學科服務更具備可操作性和實踐性。本研究從反映具體用戶真實檢索意圖的檢索行為入手,如訪問時間、資源偏好、選用的檢索詞等探尋其文獻需求和檢索規律,在一定程度上可為圖書館電子資源行為數據的深入研究提供參考,對推動有效發掘用戶個性化需求及圖書館深層次服務建設具有積極意義,但還存在以下幾方面的改進之處。
第一,典型用戶群體具有一定數量,在進行檢索詞分析的時候需要反復迭代才能取得較好的分詞效果,同時需建立具有學校專業特色的分詞詞典庫,進一步提高分詞效率和準確性;第二,分析過程的思路方法與應用角度還需進一步拓展,如將本館集成管理系統數據、門禁數據及學校教務系統數據和人事系統數據,與創文系統數據進行融合,將用戶的信息行為數據與其從事的科學研究及相關專業學習相結合,進一步提升數據的維度及分析的準確性;第三,通過在線交流、面對面溝通、電話溝通和問卷調查等多種方式,對典型用戶群體進行調研,印證分析結果,并在此基礎上深入研究,構建典型用戶群體文獻信息推薦模型并建立服務工作流程,撰寫用戶檢索分析報告及資源推薦報告以此優化用戶檢索策略、提供精準文獻服務。
上述探索點將是筆者后續努力的方向,旨在更好、更全面地研究用戶數據,突出重點學科的科研價值和應用價值,為圖書館用戶提供更優質的學科服務。
[1]創文科技[EB/OL]. [2020-08-13].http://www.cwkeji.cn/html/product.html#4_3.
[2]刁羽,賀意林.用戶訪問電子資源行為數據的獲取研究:基于創文圖書館電子資源綜合管理與利用系統[J].圖書館學研究,2020(3):40-47.
[3]Jieba[EB/OL].[2020-08-04]. https://github.com/fxsjy/jieba.
[4]Jieba分詞加入特殊字符和空格[EB/OL].[2020-08-10].https://www.cnblogs.com/callyblog/p/10097 847.html.
[5]WordCloud for Python documentation[EB/OL].[2020-08-13]. http://amueller.github.io/word_cloud/.
[6]使用Ochiia系數將共詞矩陣轉換為相關矩陣(基于EXCEL+VBA的實現)[EB/OL].[2020-09-20]. https://blog.csdn.net/u010785550/article/details/107406230.
[7]The Open Graph Viz Platform[EB/OL].[2020-09-23]. https://gephi.org/.
[8]國家市場監督管理總局.信息安全技術個人信息安全規:GB/T35273—2020[S].北京:中國標準出版社,2020:2.
[9]LINET T . What is data justice? The case for connecting digital rights and freedoms globally[EB/OL].(2017-11-07)[2021-02-23]. https://journals.sagepub.com/doi/full/10.1177/2053951717736335.
[10]中華人民共和國國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要[EB/OL].[2021-3-13].http://www.gov.cn/xinwen/2021-03/13/content_5592681.htm.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
電子制作(2018年18期)2018-11-14 01:48:24
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
